
(Bild: Vova Shevchuk / Shutterstock.com)
Psychologische Tricks werden scheinbar erfolgreich gegen ein LLM eingesetzt – aber ist das wirklich relevant?
Einem Psychologen ist es gelungen, Sicherheitsrichtlinien diverser Large Language Models (LLMs) mit Tricks auszuhebeln, die eigentlich zur Manipulation von Menschen dienen. Mit Gaslighting hat Luke Bölling LLMs [1] dazu gebracht, einen Text zu erzeugen, der scheinbar erklärt, wie man einen Molotowcocktail [2]herstellt (Siehe dazu auch der heise-Artikel [3] von Niklas Jan Engelking).
Gaslighting [4] ist ein psychologisches Konzept: Es ist "eine Form von psychischer Manipulation …, mit der Opfer gezielt desorientiert, verunsichert und in ihrem Realitäts- und Selbstbewusstsein allmählich beeinträchtigt werden". LLMs generieren jedoch lediglich Texte. Sie nehmen keine Realität wahr und haben kein Selbstbewusstsein. Der Artikel argumentiert, dass dieser Angriff trotzdem funktioniert, weil das Trainingsmaterial von Menschen geschrieben wurde und daher auch Konzepte wie Gaslighting darin vorkommen. Dennoch dürfen wir nie vergessen, dass LLMs nichts weiter als Textgeneratoren sind. Sie haben keine Emotionen, wie die zitierte Arbeit auch feststellt. Daher werde ich im weiteren Text den Begriff "Textgenerator" verwenden, da er besser beschreibt, was LLMs tatsächlich tun.
Textgeneratoren können offensichtlich einen Text erzeugen, der wie eine plausible Anleitung zur Herstellung eines Molotowcocktails erscheint – genau, wie sie scheinbar plausible Verweise auf Gerichtsentscheidungen [5] für einen Anwalt generieren können. Und obwohl diese Verweise für den Anwalt überzeugend klingen, sind sie in Wirklichkeit erfunden. Das ist eines der Probleme mit Textgeneratoren: Sie sind darauf optimiert, überzeugend zu klingen, und versuchen so, das kritische Hinterfragen ihrer Ergebnisse zu vermeiden.
Die eigentliche Frage lautet also: Würde die angebliche Anleitung zur Herstellung eines Molotowcocktails tatsächlich funktionieren? Ich habe mit Lucas Dohmen einen Stream über Textgeneratoren [6] gemacht, und eine der zentralen Erkenntnisse war: Man muss die Ergebnisse von Textgeneratoren überprüfen, um sicherzustellen, dass sie korrekt und nicht erfunden sind. Der zitierte Artikel scheint dies nicht zu tun – das heißt, die gesamte Information über Molotowcocktails könnte schlicht "halluziniert" sein. Das Problem der Generierung von Fake-Informationen durch Textgeneratoren ist nämlich so bekannt, dass es einen eigenen Begriff (Halluzination) gibt. Tatsächlich ist "halluziniert" der falsche Begriff, denn "unter Halluzination [7]versteht man eine Wahrnehmung, für die keine nachweisbare externe Reizgrundlage vorliegt". Textgeneratoren haben jedoch keine Wahrnehmungen. Daher sollten wir dieses Phänomen korrekt als "Generierung von Fake-Informationen" benennen.
Wir können die Information über den Molotowcocktail nicht überprüfen, da sie im Originalartikel unkenntlich gemacht wurde – was natürlich absolut sinnvoll ist. Ich würde mich aber nicht auf diese Informationen verlassen, um tatsächlich einen improvisierten Brandsatz zu bauen.
Der Artikel behauptet, dieses Problem sei ein Sicherheitsrisiko bei Textgeneratoren. Falls das wirklich der Fall wäre, bestünde die Lösung darin, sensible Informationen aus dem Trainingsmaterial auszuschließen. Das Anpassen der Trainingsdaten wäre ohnehin sinnvoll, beispielsweise aufgrund von Urheberrechtsproblemen. Aus irgendeinem Grund scheint Urheberrecht für Textgeneratoren nicht zu gelten, während es für Menschen schwere Folgen [8]haben kann. Warum sollte es nicht möglich sein, Anleitungen zur Herstellung von improvisierten Brand- oder Sprengsätzen aus dem Trainingsmaterial zu entfernen? Wenn das zu viel Aufwand ist, dann ist das Problem vielleicht gar nicht so groß.
Dieses "Sicherheitsproblem" wäre auch nur dann ein echtes Problem, wenn der Textgenerator keine Fake-Informationen generiert hätte – dazu sagt der Artikel jedoch nichts. Falls es Fake-Informationen sind, könnte man es vielleicht als eine Art Honeypot [9] betrachten, um Menschen von echten Informationen fernzuhalten?
Doch die eigentliche Frage ist: Wäre dies wirklich der einfachste Weg, um an solche Informationen zu gelangen? Angenommen, ich plane, einen Molotowcocktail zu bauen – würde ich komplizierte "psychologische Angriffe" auf einen Textgenerator durchführen, um eine möglicherweise falsche Antwort zu erhalten? Gibt es einfachere und präzisere Möglichkeiten? Also habe ich den naheliegenden Weg ausprobiert: eine Suche mit einer Suchmaschine. Zwei Klicks später fand ich ein Dokument, das detailliert erklärt, wie man anspruchsvolle improvisierte Sprengsätze herstellt – und ich habe guten Grund zu glauben, dass diese Anleitungen tatsächlich funktionieren. Zugegeben, dieses spezielle Dokument beschreibt nicht, wie man einen Molotowcocktail baut, aber es erklärt eine Vielzahl anderer Vorrichtungen. Diese Recherche selbst nachzuvollziehen, ist sicher spannend.
LLMs sind Textgeneratoren, die potenziell erfundene Informationen produzieren – das ist bekannt. Es mag ausgeklügelte Methoden geben, um sie dazu zu bringen, Texte zu generieren, die sensible Informationen zu enthalten scheinen – doch diese könnten schlicht Falschinformationen sein. Häufig gibt es einfachere Wege, um an sensible Informationen zu gelangen, insbesondere wenn es um improvisierte Brand- oder Sprengsätze geht. Daher sehe ich keinen Grund, "psychologische" Tricks auf Textgeneratoren anzuwenden – denn genau das sind LLMs letztlich.
URL dieses Artikels:
https://www.heise.de/-10334947
Links in diesem Artikel:
[1] https://humandataexperience.substack.com/p/librarian-bully-attack-gaslighting
[2] https://de.wikipedia.org/wiki/Molotowcocktail
[3] https://www.heise.de/news/Neuer-LLM-Jailbreak-Psychologe-nutzt-Gaslighting-gegen-KI-Filter-10332571.html
[4] https://de.wikipedia.org/wiki/Gaslighting
[5] https://news.bloomberglaw.com/litigation/lawyer-sanctioned-over-ai-hallucinated-case-cites-quotations
[6] https://www.heise.de/news/software-architektur-tv-KI-und-LLMs-kritisch-betrachtet-10287426.html
[7] https://de.wikipedia.org/wiki/Halluzination
[8] https://en.wikipedia.org/wiki/Aaron_Swartz#United_States_v._Aaron_Swartz
[9] https://de.wikipedia.org/wiki/Honeypot
[10] mailto:map@ix.de
Copyright © 2025 Heise Medien

(Bild: erzeugt mit KI durch iX)
Automatisiertes Refactoring klingt verlockend – doch lässt sich Codequalität wirklich auf Knopfdruck verbessern, oder braucht es am Ende doch den Menschen?
Heute habe ich eine große Ankündigung für Sie – eine, die für viele Entwicklerinnen und Entwickler wohl einem echten Traumszenario gleichkommt. Ein Gedanke, der so bestechend einfach klingt, dass man sich fragen könnte, warum es so etwas nicht schon längst gibt. Sicher kennen auch Sie Gespräche im Team, in denen dieser Wunsch immer wieder auftaucht – meist mit ironischem Unterton, aber manchmal durchaus mit einem Funken Hoffnung.
Stellen Sie sich vor, Sie könnten Ihren kompletten Codestand einfach in eine ZIP-Datei packen, per HTTP an einen Service hochladen – und wenige Minuten später erhalten Sie ihn vollständig refactored zurück: besser strukturiert, mit klaren Abhängigkeiten, sinnvoll modularisiert, mit sprechenden Namen, nachvollziehbarer Architektur und aussagekräftigen Tests. Inklusive aktualisierter Dokumentation, vollständig durchgelintet und formatiert. Einmal hochladen, und der Code sieht anschließend aus, als hätte ein erfahrenes Senior-Architekturteam drei Wochen intensiv daran gearbeitet. Genau das haben wir jetzt Realität werden lassen und nennen es: "Refactoring as a Service".
Die Idee ist so einfach wie genial: Haben Sie ein Repository, dessen Zustand nicht mehr ganz optimal ist? Kein Problem: Sie laden den Code einfach über unsere API hoch oder verweisen auf ein Git-Repository mit einem gültigen Token – der Rest passiert automatisch im Hintergrund. Unser Service analysiert den Code mit statischen und dynamischen Verfahren, führt eine kombinierte AST- und Graphanalyse durch, identifiziert strukturelle Schwächen, erkennt Anti-Patterns, bewertet essenzielle Metriken wie zyklomatische Komplexität, Kohäsion, Kopplung, Testabdeckung und Architekturkonformität – und erstellt daraus ein kontextsensitives, semantisch fundiertes Refactoring-Konzept, das automatisiert umgesetzt wird. Die resultierende Codebasis ist nicht nur schöner und verständlicher, sondern auch modularer, wartbarer und besser getestet. Selbstverständlich integriert sich das Ganze nahtlos in CI/CD-Prozesse und ist über eine OpenAPI-Schnittstelle vollständig automatisierbar.
Weil uns das noch nicht genug war, wird zusätzlich eine KI-gestützte Kommentierung vorgenommen, die basierend auf Codeverständnis sowie Projektkontext passgenaue Kommentare und Erläuterungen hinzufügt – sowohl auf Code- als auch auf Modul- und Architekturebene. Die Testabdeckung wird nicht nur erhöht, sondern zielgerichtet erweitert, mit besonderem Augenmerk auf Pfadabdeckung, Grenzfälle, Randbedingungen und semantisch relevante Kombinationen. All dies orchestriert ein auf Kubernetes skalierendes Service-Backend, das selbst größere Projekte in kurzer Zeit bewältigt. Für besonders kritische Projekte bieten wir zudem eine Audit-Funktion: Jede Änderung bleibt einzeln nachvollziehbar, jeder Commit wird semantisch kommentiert, jeder Refactoring-Schritt dokumentiert. Kurz gesagt: Der perfekte Begleiter für Softwareteams, die Qualität ernst nehmen, dabei aber ihren Fokus auf die eigentliche Entwicklung legen wollen.
Die eigentliche Magie entsteht durch die Kombination verschiedener Technologien und Ansätze: Statische Analyse alleine hilft wenig, wenn sie den fachlichen Kontext nicht berücksichtigt. LLMs alleine schreiben zwar Code, wissen aber nicht, ob dieser wirklich zu Ihrem Projekt passt. Clean-Code-Prinzipien sind essenziell, lösen aber nicht das grundlegende Problem der strukturellen Überarbeitung. Erst die systematische Verbindung dieser Ansätze schafft etwas, das sich wirklich als Refactoring im engeren Sinne bezeichnen lässt. Genau das macht "Refactoring as a Service" nicht nur zu einem interessanten Tool, sondern zu einem echten Gamechanger.
Natürlich – und das war uns von Anfang an bewusst – ersetzt "Refactoring as a Service" nicht den Menschen. Unser Ziel war es nie, die Expertise erfahrener Entwicklerinnen und Entwickler überflüssig zu machen. Ganz im Gegenteil: Wir wollten diese Expertise entkoppeln, also ermöglichen, dass sie unabhängig von individueller Verfügbarkeit, Projektkontext oder Zeitdruck eingesetzt werden kann. Deshalb haben wir all unser Wissen, unsere Erfahrungen und Prinzipien in diesen Service einfließen lassen – damit andere Teams davon profitieren können, ohne dass wir immer persönlich involviert sein müssen.
Das ist nicht nur für Entwicklerinnen und Entwickler spannend, sondern gleichermaßen interessant für Softwarearchitektinnen und -architekten, Teamleads und CTOs sowie alle, die sich intensiv mit Softwarequalität und Wartbarkeit auseinandersetzen. Denn Refactoring ist nicht nur ein technisches Hilfsmittel, sondern ein strategisches Instrument. Es entscheidet maßgeblich über Lebensdauer, Änderbarkeit und Erweiterbarkeit – und damit letztlich über den wirtschaftlichen Erfolg eines Projekts. Genau deshalb möchten wir mit "Refactoring as a Service" dazu beitragen, dass mehr Teams die Möglichkeit erhalten, ihre Codebasis auf ein solides und wartbares Fundament zu stellen.
An dieser Stelle fragen Sie sich vermutlich bereits: Klingt vielversprechend – doch wie viel kostet das Ganze? Wann und wie kann ich es ausprobieren? Die Antwort auf diese Fragen lautet leider: gar nicht. Denn heute ist der 1. April, und "Refactoring as a Service" existiert nicht.
Doch bevor Sie enttäuscht sind: Die Idee hinter "Refactoring as a Service" – also der Wunsch nach automatisiertem, reproduzierbarem und skalierbarem Refactoring – ist real und absolut verständlich. Wer von uns kennt nicht den Frust, sich durch Altlasten zu kämpfen, zu fragen, was sich jemand bei einem Stück Code gedacht haben könnte, und den Wunsch, einfach einen Knopf drücken zu können: "Jetzt Refactor" – klick, fertig. Leider ist es nicht ganz so einfach, und dafür gibt es gute Gründe.
Refactoring ist eben nicht nur eine technische Tätigkeit, sondern eine bewusste Entscheidung: eine Entscheidung darüber, wie Code strukturiert werden soll. Welche Konzepte getrennt, welche zusammengeführt werden müssen. Welche Benennungen welche Bedeutung tragen. Welche Architekturprinzipien zum Einsatz kommen, wann bestimmte Patterns sinnvoll sind und wann man bewusst darauf verzichten sollte. All das hängt unmittelbar mit einem fundierten fachlichen Verständnis zusammen: Sie können keine gute Struktur aufbauen, wenn Sie nicht wissen, was diese Struktur abbilden soll. Sie können keine Struktur sinnvoll bewerten, wenn Sie nicht verstehen, welche Anforderungen diese erfüllen muss. Genau deshalb ist Refactoring auch nichts, was sich rein nach Schema F automatisieren ließe. Es handelt sich eben nicht um einen rein technischen Akt, sondern um einen analytischen und diskursiven Prozess.
Natürlich gibt es Tools, Plug-ins und LLMs. Doch keines dieser Hilfsmittel kann Ihnen beantworten, ob eine Methode in einen Service oder in einen Controller gehört. Keines erkennt zuverlässig, ob eine bestimmte Implementierung noch zur aktuellen Realität passt oder lediglich ein Relikt früherer Feature-Iterationen darstellt. Keines entscheidet für Sie, ob ein Name tatsächlich treffend oder nur historisch gewachsen ist. Kein Tool abstrahiert Fachlichkeit umfassend, ersetzt Kommunikation oder übernimmt Verantwortung. All diese Dinge erfordern Erfahrung, Kontextverständnis, Empathie – also letztlich Menschen.
Deshalb ist gutes Refactoring stets gute Teamarbeit. Es bedeutet, innezuhalten, Code bewusst erneut zu lesen, zu verstehen, was er ausdrücken möchte, und anschließend in kleinen, wohlüberlegten Schritten etwas Besseres daraus zu machen. Etwas Klareres und Stabileres, das den Alltag erleichtert und nicht erschwert. Genau darin liegt auch die Verantwortung beim Refactoring. Wer refactored, entscheidet sich für langfristige Qualität – und gegen kurzfristige Bequemlichkeit. Das ist nicht immer einfach.
In vielen Teams fehlt dafür oft Zeit, Mut oder Rückendeckung. Features werden entwickelt, Stories geliefert und der Durchsatz optimiert – doch der Boden, auf dem alles steht, wird selten stabilisiert. Je länger das andauert, desto brüchiger wird das Fundament. Irgendwann wächst Refactoring dann zu einem Mammutprojekt heran, das niemand mehr anfassen möchte – obwohl anfangs nur wenige kleine Schritte nötig gewesen wären. Genau das darf nicht passieren.
Was also ist der bessere Weg? Sehen Sie Refactoring nicht als einmalige, große Aufgabe, sondern als kontinuierlichen Prozess. Machen Sie Refactoring zum festen Bestandteil Ihres Alltags, jeder Story, jedes Features, jedes Sprints. Refactoring ist nicht etwas, das man macht, wenn gerade Zeit übrig bleibt – sondern etwas, das man stets tun sollte, um sich die Zukunft deutlich einfacher zu gestalten. Das bedeutet konkret: kleine Schritte, regelmäßige Reviews, klare Verantwortlichkeiten, Mut zur Veränderung und ein gemeinsames Verständnis im Team, dass gute Software niemals Zufall ist, sondern das Ergebnis von Haltung, Prinzipien und kontinuierlicher Pflege.
URL dieses Artikels:
https://www.heise.de/-10333543
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] mailto:mai@heise.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
Eine neue Methode erlaubt die Multiplikation großer Zahlen.
Die Klassen für Ganzzahltypen Int32, UInt32, Int64 und UInt64 bieten jeweils eine neue Methode BigMul() für die Multiplikation, die die Ergebnisse als Int64 und UInt64 bzw. Int128 und UInt128 zurückliefert (ohne Überlauf).
public void BigMul()
{
CUI.Demo();
long Value1 = long.MaxValue;
ulong Value2 = ulong.MaxValue;
Console.WriteLine("Value1: " + Value1.ToString("#,0"));
Console.WriteLine("Value2: " + Value2.ToString("#,0"));
CUI.H1("Normale Multiplikation");
Int128 e1 = Value1 * 2; // Überlauf! -2
UInt128 e2 = Value2 * 2; // Überlauf! 18446744073709551614
Console.WriteLine(e1.ToString("#,0")); // Überlauf! -2
Console.WriteLine(e2.ToString("#,0")); // Überlauf! 18446744073709551614
CUI.H1("Multiplikation mit BigMul()");
Int128 e3 = Int64.BigMul(Value1, 2); // 18.446.744.073.709.551.614
UInt128 e4 = UInt64.BigMul(Value2, 2); // 36.893.488.147.419.103.230
Console.WriteLine(e3.ToString("#,0")); // 18.446.744.073.709.551.614
Console.WriteLine(e4.ToString("#,0")); // 36.893.488.147.419.103.230
}
URL dieses Artikels:
https://www.heise.de/-10331981
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Shutterstock/Milos Milosevic)
CloudEvents schafft Interoperabilität für Event-basierte Systeme. Warum der Standard sinnvoll ist und wie er funktioniert, behandelt dieser Blogpost.
Es heißt oft, Event-basierte Systeme seien besonders leistungsfähig, weil sich Events hervorragend dazu eignen, Informationen über fachliche Ereignisse zwischen verschiedenen Systemen auszutauschen und diese so zu integrieren. In der Realität zeigt sich jedoch häufig ein ganz anderes Bild: Jedes System verwendet seine eigene Variante von Events, die Formate sind nicht kompatibel, und die erhoffte Integration über Events scheitert dadurch schnell. Was hier eindeutig fehlt, ist ein standardisiertes Format – ein allgemeingültiger Standard, der definiert, welche Daten ein Event enthalten soll, wie es strukturiert ist und wie es übermittelt wird.
Glücklicherweise hat sich die Cloud Native Computing Foundation [1] (CNCF) dieser Herausforderung angenommen und genau einen solchen Standard geschaffen: CloudEvents [2]. Für jede Entwicklerin und jeden Entwickler, die mit Event-basierten Systemen arbeiten, ist dieses Thema von großer Relevanz. Daher möchte ich Ihnen in diesem Blogpost einen genaueren Einblick geben.
Vielleicht fragen Sie sich zunächst, was ich überhaupt unter dem Begriff "Event" verstehe. Eine präzise Antwort würde an dieser Stelle den Rahmen sprengen. Daher empfehle ich Ihnen meinen Blogpost zum Thema Event Sourcing [3], der vor einigen Wochen erschienen ist. Es lohnt sich, sich zunächst damit vertraut zu machen und erst anschließend hier weiterzulesen.
Wenn Sie bereits wissen, was mit Events gemeint ist, dann kennen Sie vermutlich auch das Problem: Jedes Event-getriebene System definiert sein eigenes Format für Events, was den Austausch und die Integration zwischen verschiedenen Systemen erheblich erschwert. Der theoretische Vorteil einer gemeinsamen Kommunikationsform durch Events bleibt in der Praxis oft ungenutzt, da die Formate schlicht nicht zueinander passen. Solange es keinen verbindlichen Standard gibt, bleibt der Nutzen solcher Events für die Systemintegration begrenzt.
Genau hier setzt das Konzept von CloudEvents an. Die dahinterstehende Idee ist einfach: Es geht darum, ein standardisiertes Format für Events zu schaffen, um die Interoperabilität zwischen verschiedenen Systemen zu ermöglichen. Entwickelt wurde dieser Standard, wie gesagt, von der Cloud Native Computing Foundation, einer gemeinnützigen Organisation, die von nahezu allen großen Cloud-Anbietern wie Microsoft, Amazon und Google unterstützt wird.
Das Ziel von CloudEvents ist es, einheitliche Metadaten für Events zu definieren, damit diese zumindest in ihrer äußeren Struktur kompatibel zueinander gestaltet werden können. Zusätzlich sollen plattform- und transportschichtunabhängige Strukturen ermöglicht werden – zum Beispiel soll JSON über HTTPS genauso einsetzbar sein wie XML über MQTT. Der Standard definiert dabei zentrale Begriffe wie "ID", "Source", "Type" und weitere essenzielle Felder.
Warum sollte man auf diesen Standard setzen? Der naheliegende Vorteil liegt in der Reduktion des Aufwands für Konvertierungen und Parsings sowie in einer deutlich verbesserten Interoperabilität zwischen Systemen. Zudem unterstützt CloudEvents verschiedene Protokolle und lässt sich dadurch flexibel transportieren – unabhängig vom konkreten Übertragungsweg. Das ist nicht nur für Anwendungen relevant, sondern auch für Router und Broker, da sich Events durch die standardisierten Metadaten wesentlich besser analysieren, filtern und verteilen lassen. Außerdem verbessert sich durch die strukturierte Beschreibung der Events die Nachvollziehbarkeit, etwa hinsichtlich Ursprung und Zeitpunkt des Ereignisses. Auf dieser Basis lassen sich generische Werkzeuge für Events realisieren – ein Aspekt, der insbesondere für Microservices, Serverless-Funktionen und vergleichbare Architekturen von Bedeutung ist. Und wenn man diesen Gedanken weiterführt, dann wäre CloudEvents sogar als Persistenzformat für Event Sourcing gut geeignet.
Natürlich stellt sich die Frage, welche Herausforderungen oder Einwände gegen die Nutzung von CloudEvents sprechen könnten. Ein zentrales Problem besteht darin, dass bisher noch nicht viele Systeme diesen Standard unterstützen. Das heißt, es existieren derzeit nur wenige Anwendungen, die direkt kompatibel sind. Bestehende, proprietäre Event-Formate müssen daher weiterhin unterstützt werden – zumindest ergänzend. Das verursacht zusätzlichen Aufwand, den man eigentlich vermeiden möchte. Dies betrifft nicht nur kleinere Systeme, sondern auch Dienste wie die Amazon EventBridge von AWS oder das Event Grid von Microsoft Azure.
Ein weiterer Punkt ist, dass CloudEvents lediglich die Metadaten vereinheitlicht. Die Nutzdaten – also die Payload – bleiben weiterhin spezifisch für die jeweilige Anwendung. Das ist systemimmanent, denn der fachliche Inhalt eines Events lässt sich nicht generisch definieren. Hinzu kommt, dass CloudEvents durch ihre strukturierte Form möglicherweise mehr Overhead verursachen als einfachere proprietäre Formate, insbesondere wenn nicht alle vorgesehenen Felder genutzt werden.
Trotzdem halte ich CloudEvents für einen großen Schritt in die richtige Richtung. Ohne klare Regeln ist es unnötig aufwendig, Event-basierte Systeme miteinander zu koppeln. Ein gemeinsames Vokabular erscheint hier ausgesprochen sinnvoll. Positiv hervorzuheben ist auch, dass sich CloudEvents gut mit anderen Standards kombinieren lässt – etwa mit AsyncAPI [5] oder OpenTelemetry [6]. Alles in allem ist der Standard darauf ausgelegt, den Einstieg möglichst einfach zu gestalten und die Integration in bestehende Systeme zu erleichtern.
Daraus ergibt sich die Frage, wie man CloudEvents sinnvoll umsetzt. Zunächst sollte man klären, ob der Einsatz für die eigene Anwendung überhaupt sinnvoll ist. Meiner persönlichen Einschätzung nach lautet die Antwort eindeutig: Sobald Sie mit Events arbeiten und sobald Sie auch nur ansatzweise darüber nachdenken, Ihre Software mit anderen Systemen zu koppeln oder zu integrieren, sollten Sie CloudEvents in Betracht ziehen. Natürlich können Sie auch ein eigenes Format definieren – gewinnen werden Sie dadurch allerdings wenig. Der einzige "Nachteil" besteht darin, dass man sich einmal mit dem CloudEvents-Standard vertraut machen muss. Nach meiner Erfahrung ist das sehr gut machbar: Der Standard ist verständlich und überschaubar.
Wenn Sie sich dafür entscheiden, CloudEvents zu nutzen, dann sollten Sie es auch korrekt tun. Das bedeutet vor allem, sich mit der Bedeutung und dem Format der einzelnen Felder auseinanderzusetzen. Es wäre wenig hilfreich, das Format formal zu unterstützen, dabei aber inkorrekte Werte zu verwenden – insbesondere, wenn sich solche Fehler erst Monate später im Integrationsfall zeigen. Felder wie "source", "subject" oder "type" erfordern dabei besondere Aufmerksamkeit. Es ist nicht kompliziert, erfordert jedoch eine sorgfältige Lektüre der Spezifikation [7].
Falls Sie bereits ein Event-basiertes System im Einsatz haben, das den CloudEvents-Standard bislang nicht berücksichtigt, ist das kein Grund, das Thema abzulehnen. Sie können mit vergleichsweise geringem Aufwand Wrapper, Konverter oder Middleware einsetzen, um zwischen bestehenden Formaten und dem Standard zu übersetzen. Das lohnt sich vor allem langfristig, da Sie auf diese Weise einen einheitlichen Austauschstandard etablieren und den Bedarf an individuellen Adaptern reduzieren. Besonders relevant wird das, wenn Sie CloudEvents auch als Basis für Event Sourcing nutzen – dann sind die Events bereits im Kern standardisiert.
Bleibt abschließend die Frage, ob sich CloudEvents langfristig als Standard etablieren wird. Ich bin in dieser Hinsicht optimistisch. Die Unterstützung durch Cloud-Anbieter wächst, ebenso wie die Verbreitung in Open- und Closed-Source-Anwendungen. Darüber hinaus dient CloudEvents bereits als Grundlage für weitere Standards, etwa CDEvents [8], die sich speziell auf Continuous-Delivery-Prozesse konzentrieren. Diese Entwicklung verdeutlicht, dass CloudEvents als tragfähige und zukunftsfähige Basis angesehen werden.
Ich kann Ihnen daher nur empfehlen, sich intensiv mit CloudEvents zu beschäftigen. Der Standard ist hilfreich, durchdacht und vor allem praxisnah. Je stärker Sie mit Event-basierten Architekturen arbeiten – sei es in der Entwicklung, in der Infrastruktur oder in anderen Bereichen –, desto relevanter wird dieses Konzept für Sie.
Wenn Sie bereits Erfahrungen mit CloudEvents gesammelt haben oder planen, sich damit auseinanderzusetzen, freue ich mich über Ihre Rückmeldung. Und falls Sie generell mehr über Event-basierte Systeme lernen möchten: Neben der bereits erwähnten Einführung in Event Sourcing finden Sie weiterführende Informationen auch in dem Blogpost "CQRS als Grundlage für moderne, flexible und skalierbare Anwendungsarchitektur [9]".
URL dieses Artikels:
https://www.heise.de/-10325241
Links in diesem Artikel:
[1] https://www.cncf.io/
[2] https://cloudevents.io/
[3] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[5] https://www.asyncapi.com/
[6] https://opentelemetry.io/
[7] https://github.com/cloudevents/spec
[8] https://cdevents.dev/
[9] https://www.heise.de/blog/CQRS-als-Grundlage-fuer-moderne-flexible-und-skalierbare-Anwendungsarchitektur-10275526.html
[10] https://www.mastering-gitops.de/?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[11] https://www.mastering-gitops.de/veranstaltung-83006-se-0-gitops-auf-allen-ebenen-mit-crossplane-&-argocd.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[12] https://www.mastering-gitops.de/veranstaltung-83394-se-0-gitops-evolution-moderne-infrastruktur-pipelines-mit-pulumi-und-argo-cd.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[13] https://www.mastering-gitops.de/veranstaltung-83008-se-0-praxisbericht-zwei-jahre-gitops-mit-fluxcd-in-produktion.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[14] https://www.mastering-gitops.de/veranstaltung-83446-se-0-effiziente-multi-tenant-architekturen-gitops-mit-argo-cd-in-der-praxis.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[15] https://www.mastering-gitops.de/veranstaltung-83445-se-0-gitops-pattern-fuer-verteilte-deployment-pipelines-mit-kargo.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[16] https://www.mastering-gitops.de/tickets.php?wt_mc=intern.academy.dpunkt.konf_dpunkt_clc_gitops.empfehlung-ho.link.link
[17] mailto:mai@heise.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
Die Zeitkonvertierungsmethoden haben in .NET 9.0 neue Überladungen für mehr Genauigkeit erhalten.
Die Datenstruktur System.TimeSpan gibt es schon seit der ersten Version des .NET Frameworks aus dem Jahr 2002. In .NET 9.0 adressiert Microsoft jetzt eine kleine Herausforderung, die es in all den Jahren gab: Die Konvertierungsmethoden FromMicroseconds(), FromSeconds(), FromMinutes(), FromHours() und FromDays() erwarten als Parameter einen Double-Wert, der als Fließkommazahl aber ungenau ist.
Microsoft führt daher in .NET 9.0 zusätzlich neue Überladungen dieser Methoden ein, die Ganzzahlen – int beziehungsweise long – als Parameter erwarten:
public static TimeSpan FromDays(int days);public static TimeSpan FromDays(int days, int hours = 0, long minutes = 0, long seconds = 0, long milliseconds = 0, long microseconds = 0);public static TimeSpan FromHours(int hours);public static TimeSpan FromHours(int hours, long minutes = 0, long seconds = 0, long milliseconds = 0, long microseconds = 0);public static TimeSpan FromMinutes(long minutes);public static TimeSpan FromMinutes(long minutes, long seconds = 0, long milliseconds = 0, long microseconds = 0);public static TimeSpan FromSeconds(long seconds);public static TimeSpan FromSeconds(long seconds, long milliseconds = 0, long microseconds = 0);public static TimeSpan FromMilliseconds(long milliseconds, long microseconds = 0);public static TimeSpan FromMicroseconds(long microseconds);Das folgende Beispiel beweist die größere Genauigkeit der neuen Überladungen am Beispiel FromSeconds():
public class FCL9_TimeSpanFrom
{
public void Run()
{
CUI.Demo(nameof(FCL9_TimeSpanFrom));
// bisher
TimeSpan timeSpan1a = TimeSpan.FromSeconds(value: 123.456);
Console.WriteLine($"TimeSpan +123.456sec alt = {timeSpan1a}");
// 00:02:03.4560000
// bisher
TimeSpan timeSpan2a = TimeSpan.FromSeconds(value: 101.832);
Console.WriteLine($"TimeSpan +101.832sec alt = {timeSpan2a}");
// 00:01:41.8319999
Console.WriteLine();
// neu
TimeSpan timeSpan1n = TimeSpan.FromSeconds(seconds: 123,
milliseconds: 456);
Console.WriteLine($"TimeSpan +123.456sec neu = {timeSpan1n}");
// 00:02:03.4560000
// neu
TimeSpan timeSpan2n = TimeSpan.FromSeconds(seconds: 101,
milliseconds: 832);
Console.WriteLine($"TimeSpan +101.832sec neu = {timeSpan2n}");
// 00:01:41.8320000
}
}

(Bild: Screenshot (Holger Schwichtenberg))
URL dieses Artikels:
https://www.heise.de/-10324526
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Natalia Hanin / Shutterstock.com)
Gerade ist das OpenJDK 24 mit 24 Java Enhancement Proposals erschienen. Dabei ist einiges unter der Haube passiert, und es gibt neue Sicherheitsfunktionen.
In einem früheren Post [1] haben wir uns bereits die zehn, insbesondere für Entwicklerinnen und Entwickler relevanten Neuerungen angeschaut. In diesem zweiten Teil werfen wir einen Blick auf die restlichen JEPs.
Viele Neuerungen beziehen sich auf Themen unter der Haube (z. B. Garbage Collector), auf Optimierungen beim Start bzw. im laufenden Betrieb von Java-Anwendungen und Maßnahmen, die die Robustheit der Java-Plattform steigern. So erhält im JEP 404 der Shenandoah Garbage Collector ähnlich wie der Z Garbage Collector (ZGC) einen "Generational Mode". Dabei wird zwischen neuen und alten Objekten unterschieden. Die junge Generation enthält eher kurzlebige Objekte und wird häufiger bereinigt. Die alte Generation muss dagegen nur selten aufgeräumt werden. Damit verbessert sich der Durchsatz sowie die Widerstandsfähigkeit gegen Lastspitzen, und die Speichernutzung wird optimiert. Beim Z Garbage Collector wird mit dem JEP 490 der nicht generationale Modus nun entfernt, da der generationale Modus inzwischen leistungsfähiger und für die meisten Anwendungen besser geeignet ist. Die Maßnahme soll den Wartungsaufwand reduzieren und die Weiterentwicklung des generationalen Modus beschleunigen. Das reflektiert den Fokus auf modernere Ansätze bei der Speicherbereinigung, die sowohl Effizienz als auch Wartbarkeit erhöhen sollen.
Der JEP 475 (Late Barrier Expansion for G1) führt eine Optimierung für den Standard Garbage Collector G1 ein, indem Speicherbarrieren später im Kompilierungsprozess generiert werden. Diese Änderung verbessert die Qualität der maschinennahen Instruktionen, reduziert die Komplexität in der Implementierung und erleichtert die Pflege. Die Motivation liegt in der Identifizierung von Schwächen bei der bisherigen Platzierung von Barrieren, insbesondere im Hinblick auf ihren Einfluss auf die Leistung und den Speicherverbrauch. Durch diese spätere Platzierung können unnötige Barrieren eliminiert werden, was zu einer effizienteren Programmausführung beiträgt. Diese Optimierung stellt einen weiteren Schritt dar, die Performance und Wartbarkeit des G1-Garbage-Collectors zu verbessern und langfristig die Anpassungsfähigkeit an moderne Hardwarearchitekturen sicherzustellen.
Der JEP 450 führt kompakte Objekt-Header in Java ein, um Speicherplatz effizienter zu nutzen und den Speicherverbrauch von Java-Objekten zu reduzieren. Der Header, der bisher 128 Bit auf 64-Bit-Plattformen einnahm, wird auf 64 Bit verkleinert. Das geschieht durch komprimierte Klassenreferenzen und eine optimierte Verwaltung von Synchronisierungsinformationen. Der Ansatz zielt darauf ab, die Speicherbelastung bei datenintensiven Anwendungen mit vielen kleinen Objekten zu minimieren, ohne die Leistung der JVM zu beeinträchtigen. Da jedoch tiefgreifende Änderungen an grundlegenden Datenstrukturen vorgenommen werden, bleibt das Feature zunächst experimentell, um mögliche Probleme zu identifizieren und Feedback zu sammeln. Dies könnte langfristig die Grundlage für eine noch effizientere Speicherverwaltung in zukünftigen Java-Versionen schaffen.
Der JEP 483 führt das Konzept des Ahead-of-Time (AOT) Class Loading & Linking ein, das die Startzeit und die Effizienz von Java-Anwendungen verbessern soll. Die Idee besteht darin, häufig genutzte Klassen bereits zur Build-Zeit vorzubereiten, statt sie erst zur Laufzeit zu laden und zu verlinken. Das geschieht durch die Integration einer AOT-Caching-Lösung, in der Metadaten wie Konstanten, Methoden-Handles oder Lambda-Ausdrücke vorgeladen und gespeichert werden. Ziel ist es, die Kosten und Latenzen des dynamischen Ladens zur Laufzeit zu minimieren, was insbesondere bei wiederkehrenden Anwendungsfällen in Cloud-nativen oder ressourcenbeschränkten Umgebungen Vorteile bringt. Die Motivation hinter dieser Änderung liegt in der zunehmenden Bedeutung von schnell startenden Anwendungen, die oft auf Containerplattformen wie Kubernetes ausgeführt werden. In solchen Umgebungen ist die Optimierung von Startzeiten und Speicherverbrauch entscheidend. Durch die Verwendung eines Cache-Mechanismus wird die Effizienz deutlich gesteigert, ohne die Flexibilität des Java-Ökosystems zu beeinträchtigen.
JEP 491 verbessert die Skalierbarkeit von Java-Anwendungen, die synchronized-Methoden und -Blöcke verwenden. Derzeit führt das Synchronisieren von virtuellen Threads dazu, dass auch die darunter liegenden Plattform-Threads blockiert werden. Viele parallel existierende virtuelle Threads können ihre Vorteile nicht mehr ausspielen, und das kann die Performance und Skalierbarkeit erheblich beeinträchtigen. Bei der Einführung der Virtual Threads in Java 21 ist man diesen Kompromiss bewusst eingegangen, um sie möglichst schnell auf die Straße bringen zu können. Mit dem JEP 491 wurde die Architektur der virtuellen Threads aber nun nochmals angepasst. Threads, die auf Monitore warten, können den zugrunde liegenden Plattform-Thread nun wieder freigeben, ohne die Funktionalität von synchronized zu beeinträchtigen. Das bedeutet, dass virtuelle Threads, die in synchronized-Blöcke eintreten oder darauf warten, nicht mehr die zugehörigen Plattform-Threads blockieren, wodurch die Anzahl der verfügbaren virtuellen Threads für die Bearbeitung von Aufgaben maximiert wird. Diese Änderungen wird die Effizienz bei der Nutzung von virtuellen Threads erheblich steigern. Es werden jetzt fast alle Fälle von Thread-Pinning vermieden, die bisher die Skalierbarkeit begrenzt haben.
JEP 478 führt eine API für Key Derivation Functions (KDFs) als Preview ein, um sichere Ableitungen von kryptografischen Schlüsseln zu unterstützen. Diese werden aus einem geheimen Schlüssel und zusätzlichen Informationen generiert, basierend auf Standards wie RFC 5869 (HMAC-based Extract-and-Expand Key Derivation Function, HKDF). Ziel ist es, eine standardisierte, gut integrierte Lösung für Java-Entwickler bereitzustellen, die interoperabel und vielseitig einsetzbar ist. Bestehende Methoden für Verschlüsselung, Authentifizierung und digitale Signaturen beruhen oft auf benutzerdefinierten Implementierungen, die potenziell unsicher oder weniger effizient sind. Die API bietet ein standardisiertes Framework, das die Sicherheit und Benutzerfreundlichkeit erhöht, während es gleichzeitig mit den aktuellen Sicherheitsbibliotheken von Java kompatibel bleibt.
Die JEPs 496 (Quantum-Resistant Module-Lattice-Based Key Encapsulation Mechanism – ML-KEM) und 497 (Quantum-Resistant Module-Lattice-Based Digital Signature Algorithm – ML-DSA) führen Implementierungen von Algorithmen für Schlüsselaustauschverfahren und digitale Signaturen ein. ML-KEM ist ein von NIST (National Institute of Standards and Technology) in FIPS 203 (Federal Information Processing Standard) standardisierter Algorithmus, der sichere Schlüsselaustauschverfahren gegen zukünftige Angriffe durch Quantencomputer ermöglicht. Dies ist besonders relevant, da Quantencomputer herkömmliche kryptografische Verfahren wie RSA und Diffie-Hellman in Zukunft brechen werden. Java 24 unterstützt ML-KEM mit den Parametern ML-KEM-512, ML-KEM-768 und ML-KEM-1024, um die Sicherheit von Anwendungen langfristig zu gewährleisten. ML-DSA ist ein von NIST in FIPS 204 standardisierter Algorithmus zur digitalen Signatur, der ebenfalls gegen zukünftige Angriffe durch Quantencomputer abgesichert ist. Digitale Signaturen werden zur Authentifizierung und zur Erkennung von Datenmanipulationen genutzt. Java 24 unterstützt ML-DSA mit den Parametern ML-DSA-44, ML-DSA-65 und ML-DSA-87, um eine langfristig sichere Signaturprüfung zu ermöglichen.
Der JEP 472 (Prepare to Restrict the Use of JNI) zielt darauf ab, die Nutzung der Java Native Interface (JNI) zu beschränken, um die Integrität und Sicherheit der Java-Plattform zu erhöhen. JNI erlaubt den Zugriff auf private Felder und Methoden sowie den direkten Speicherzugriff, was grundlegende Prinzipien wie Kapselung und Speichersicherheit untergräbt. Ziel ist es, die Verwendung von JNI standardmäßig einzuschränken, es jedoch für Anwendungen explizit aktivieren zu können, die es benötigen. Dies folgt dem langfristigen Ansatz, Java von unsicheren APIs zu befreien und alternative Mechanismen wie die Foreign Function & Memory API zu fördern. Die Motivation liegt in der Verbesserung der Robustheit, Wartbarkeit und Sicherheit der Plattform, um Risiken wie Speicherkorruption und unvorhergesehenes Verhalten zu minimieren und die Modernisierung von Java-Programmen zu erleichtern.
Der JEP 479 (Remove the Windows 32-bit x86 Port) entfernt den Windows 32-Bit-x86-Port aus dem OpenJDK, da diese Architektur zunehmend veraltet ist und keine neue Hardware mit diesem Format mehr produziert wird. Windows 10, das letzte Betriebssystem mit Unterstützung für 32-Bit-Betrieb, erreicht 2025 das Ende seines Lebenszyklus, was die Relevanz dieser Plattform weiter verringert. Durch das Entfernen dieses Ports können Ressourcen bei der Weiterentwicklung von Java effizienter genutzt werden. Gleichzeitig wird die Wartung durch die Reduzierung von Komplexität vereinfacht. Diese Änderung entspricht den aktuellen Trends in der Industrie, bei der 64-Bit-Architekturen klar dominieren. Anwender können weiterhin ältere Versionen des JDK nutzen oder durch den Einsatz von Remote-APIs für 32-Bit-Funktionen migrieren. Neben Windows müssen bald auch andere 32-bit-Implementierungen dran glauben: Mit dem JEP 501 (Deprecate the 32-bit x86 Port for Removal) wird der 32-Bit-x86-Port in Java 24 als veraltet markiert und auf dessen Entfernung in einer zukünftigen Version vorbereitet. Betroffen ist insbesondere die letzte verbliebene Implementierung für Linux auf 32-Bit-x86. Die Wartung dieses Ports verursacht ebenfalls hohe Kosten und blockiert die Implementierung neuer Features wie Project Loom, das Foreign Function & Memory API oder die Vector API. Nach der Entfernung bleibt als einzige Möglichkeit zur Ausführung von Java-Programmen auf 32-Bit-x86-Prozessoren der architekturunabhängige Zero-Port.
Durch den JEP 498 (Warn upon Use of Memory-Access Methods in sun.misc.Unsafe) gibt Java 24 eine Laufzeitwarnung aus, wenn erstmals eine der unsicheren Speicherzugriffsmethoden in sun.misc.Unsafe aufgerufen wird. Diese Methoden wurden bereits in JDK 23 zur Entfernung markiert. Sie wurden durch sicherere Alternativen ersetzt, z. B. VarHandle (JEP 193, JDK 9) für Speicherzugriffe auf dem Heap und MemorySegment (JEP 454, JDK 22) für Off-Heap-Speicher. Das Ziel ist es, Entwickler frühzeitig auf die Entfernung dieser Methoden in zukünftigen JDK-Versionen vorzubereiten und sie zum Umstieg auf standardisierte APIs zu bewegen.
Mit dem JEP 493 (Linking Run-Time Images without JMODs) wird die Größe einer vom Benutzer erstellten Laufzeitumgebung (JRE) mit jlink um etwa 25 % verringert. Bei der Erzeugung der Images werden keine JMOD-Dateien inkludiert. Diese Funktion muss allerdings bei der Erstellung des JDKs aktiviert werden. Und einige JDK-Anbieter entscheiden sich möglicherweise dafür, diese Option nicht umzusetzen. Als Motivation wird darauf verwiesen, dass in Cloud-Umgebungen die installierte Größe des JDK auf dem Dateisystem wichtig ist. Gerade Container-Images, die ein installiertes JDK enthalten, werden automatisch und häufig über das Netzwerk aus Container-Registries kopiert heruntergeladen. Eine Verringerung der Größe des JDK würde die Effizienz dieser Vorgänge verbessern.
Java 24 ist ein spannendes Release mit vielen neuen Features – auch wenn für uns Entwickler auf den ersten Blick scheinbar gar nicht so viel Neues dabei ist. Vieles sind Wiedervorlagen aus früheren Preview-Versionen. Aber genau das zeigt, wie stabil und durchdacht sich Java weiterentwickelt. Und außerdem ist enorm viel unter der Haube passiert: von Performance-Optimierungen über Sicherheitsverbesserungen bis hin zu Weichenstellungen für die Zukunft, etwa in der Kryptografie und der Speicherverwaltung. Java bleibt damit eine moderne, leistungsfähige Plattform. Und im September 2025 steht mit dem OpenJDK 25 die nächste LTS-Version vor der Tür.
Zum Vertiefen der hier genannten Features empfiehlt sich als Startpunkt die OpenJDK 24-Projektseite [2]. Und es gibt natürlich auch eine ausführliche Liste aller Änderungen in den Release Notes [3].
URL dieses Artikels:
https://www.heise.de/-10322221
Links in diesem Artikel:
[1] https://www.heise.de/blog/Java-Rekord-beim-bevorstehenden-Release-des-OpenJDK-24-10051629.html
[2] https://openjdk.org/projects/jdk/24
[3] https://jdk.java.net/24/release-notes
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: generated by DALL-E)
Der letzte Teil der Serie betrachtet Reasoning-Modelle und gibt einen Ausblick auf die mögliche Zukunft der LLMs.
Ein Large Language Model (LLM) ist darauf ausgelegt, menschliche Sprache zu verarbeiten und zu generieren. Nach der grundlegenden Einführung von LLMs im ersten [1], den Hardwareanforderungen und vorab trainierten Modellen im zweiten [2] sowie den Architekturtypen im dritten Teil [3] geht es zum Abschluss um Reasoning-Modelle.
Fasten your seat belts!
Wer moderne LLMs wie Deepseek R1 oder OpenAI o3 nutzt, dürfte öfter Ausgaben wie "thinking" oder "reasoning" zu Gesicht bekommen. Das Sprachmodell ist also in der Lage, strukturiert und systematisch auf eine Anfrage zu reagieren. Daher nennt man sie Reasoning-Modelle.
Argumentationen beziehungsweise Schlussfolgerungen in Large Language Models werden durch verschiedene Techniken umgesetzt, die ihre Fähigkeit verbessern, komplexe Probleme in handhabbare Schritte zu zerlegen und logische Erklärungen zu liefern. Zu den wichtigsten Methoden gehören:
Diese Methoden zielen darauf ab, die Fähigkeit von LLMs zur Argumentation zu verbessern und transparente Denkprozesse bereitzustellen, obwohl Experten den Umfang, in dem sie tatsächlich argumentieren, weiterhin diskutieren.
Chain-of-Thought-(CoT)-Prompting verbessert die Argumentationsfähigkeiten von Large Language Models, indem es sie dazu anregt, komplexe Aufgaben in eine Reihe logischer Schritte zu zerlegen. Dieser Ansatz spiegelt menschliches Denken wider und ermöglicht es Modellen, Probleme systematischer und transparenter anzugehen. Zu den wichtigsten Vorteilen gehören:
Große Sprachmodelle haben das Feld der natürlichen Sprachverarbeitung revolutioniert und ermöglichen Anwendungen wie Sprachübersetzung, Textzusammenfassung und Chatbots. Die Zukunft der LLMs ist aufregend, mit möglichen Anwendungen in Bereichen wie Bildung, Gesundheitswesen und Unterhaltung.
Eine innovative Lösung ist die Einführung von MoE-Verfahren (MoE = Mixture of Experts) in LLMs. Diese Modelle bestehen aus LLM-Komponenten, von denen jedes auf einer gewissen Domäne spezialisiert ist. Durch einen Gating-Mechanismus leitet das Modell Benutzeranfragen an die jeweils passende LLM-Komponente weiter.
Unter Agentic AI sind LLM-Agenten zu verstehen, die in der Lage sind, auf ihre Umgebung zuzugreifen, etwa um Funktionen zu starten oder die UI zu bedienen.
Multi-Agent-Systeme enthalten unterschiedliche LLM-Agenten, die ihrerseits verschiedene Rollen innehaben und miteinander agieren, um eine gemeinsame Aufgabe zu lösen, was an das bereits genannte Mixture of Experts erinnert.
Inzwischen sind auch immer mehr multimodale Modelle verfügbar, die neben Text auch Bilder, Videos, Audios oder Symbole verstehen und/oder generieren können. Vision-Modellen kann man ein Bild vorlegen, um danach Fragen zu dem Bild zu stellen. Einige Modelle erlauben die Eingabe von Prompts über gesprochene Sprache statt über Text. Modelle wie OpenAI Sora generieren realistische Videos aus Sprach-Prompts. Midjourney, DALL-E und ähnliche Modelle können Bilder aus Benutzeranforderungen (Prompts) erzeugen. Die Architektur der Modelle ähnelt der in diesem Artikel vorgestellten Architektur sehr stark. Nur dass die Modelle neben Text-Tokens auch andere Elemente wie Pixelsegmente verarbeiten und generieren können.
In Anbetracht dieser rasanten Entwicklung ist es essenziell, sich als Entwicklerin oder Nutzer intensiv mit dem Thema LLM und Generative AI zu beschäftigen. Ebenso wichtig sollte es sein, die neuen LLM-Technologien kritisch zu hinterfragen, speziell was ihre Auswirkungen auf unser Leben und unsere Gesellschaft betrifft. Das gilt insbesondere in Bezug auf ethische Grundsätze und Werte. Nur wer die Technologien kennt und versteht, kann die Chancen und Risiken einschätzen und abwägen.
Für diejenigen, die mehr über LLMs erfahren möchten, sind hier einige zusätzliche Ressourcen:
Hier ist ein Glossar einiger der in dieser Artikelserie verwendeten Begriffe:
URL dieses Artikels:
https://www.heise.de/-10296366
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[4] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[5] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[6] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[7] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[8] https://arxiv.org/abs/1706.03762
[9] https://huggingface.co/docs/transformers/index
[10] https://en.m.wikipedia.org/wiki/BERT_(language_model)
[11] https://huggingface.co/docs/transformers/model_doc/roberta
[12] https://arxiv.org/abs/1906.08237
[13] https://nlp.stanford.edu/
[14] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX)
Der TypeScript-Compiler wird ab Version 7 nicht mehr in TypeScript, sondern in Go geschrieben sein. Was verspricht sich Microsoft davon, und warum gerade Go?
Seit Microsoft TypeScript im Oktober 2012 vorgestellt und veröffentlicht hat, ist die Sprache aus der modernen Webentwicklung nicht mehr wegzudenken. Kaum jemand, der an Web-basierten UIs arbeitet, dürfte in den vergangenen zehn Jahren an TypeScript vorbeigekommen sein. Doch die Kritik an TypeScript wächst: Immer häufiger werden Stimmen laut, die die schlechte Performance des TypeScript-Compilers bemängeln.
Immerhin war ursprünglich ein wesentlicher Aspekt der Webentwicklung, dass man nicht ständig auf einen Compiler warten musste. TypeScript hat das erfolgreich zunichtegemacht. TypeScript hat den Umgang mit JavaScript – gerade in großen Teams und in komplexen Anwendungen – zwar deutlich verbessert, aber zugleich auch die Geschwindigkeit und die Leichtigkeit der Webentwicklung gebremst.
Doch damit ist jetzt Schluss! Microsoft hat am 11. März angekündigt [2], die Performance des TypeScript-Compilers um den Faktor zehn zu beschleunigen. Und zwar, indem sie ihn komplett neu schreiben oder besser gesagt, portieren. Überraschenderweise jedoch nicht nach Rust, C# oder C++, sondern nach Go. Das wirft die Frage auf: Warum ausgerechnet Go?
Microsoft hat vor rund einer Woche unter dem Titel "A 10x Faster TypeScript" einen Blogpost [3] und auch ein Video [4] veröffentlicht, in dem Anders Hejlsberg erläutert, was Microsoft mit dem TypeScript-Compiler in der nahen bis mittleren Zukunft plant. Anders Hejlsberg ist dabei nicht irgendein Entwickler bei Microsoft, sondern federführender Sprachdesigner für TypeScript und C#. Er hat also umfassende Erfahrung in der Entwicklung von Programmiersprachen und im Compilerbau. Er kündigte an, dass der TypeScript-Compiler, wie wir ihn heute kennen, durch eine neue Implementierung in Go ersetzt werden wird. Microsoft wird dabei jedoch nicht alles von Grund auf neu schreiben, sondern die bestehende Codebasis – die derzeit in TypeScript geschrieben ist – nach Go portieren.
Ja, Sie haben richtig gelesen: TypeScript ist aktuell in TypeScript geschrieben, zukünftig wird es in Go geschrieben sein. Microsoft verspricht sich davon eine um den Faktor zehn bessere Performance, eine weitaus höhere Speichereffizienz sowie bessere Stabilität und Verlässlichkeit. Das wirft direkt Fragen auf: Was bedeutet das für mich? Warum gerade Go? Wie sieht es nach dem Umbau mit bestehenden Werkzeugen und generell dem Ökosystem aus?
Um diese Fragen zu beantworten, muss zunächst die bisherige Situation betrachtet werden. Der TypeScript-Compiler ist aktuell in TypeScript geschrieben. Das ist einerseits ein Vorteil, weil ein Compiler damit quasi direkt beweist, dass er funktioniert, indem er sich selbst übersetzt. Andererseits bedeutet es aber auch, dass der TypeScript-Compiler wie jede in TypeScript geschriebene Anwendung nach JavaScript übersetzt wird und in einer entsprechenden Laufzeitumgebung wie Node.js ausgeführt werden muss. Das ist zwar nicht interpretiert, sondern immerhin JIT-kompiliert, aber dennoch nicht so schnell, wie es mit nativem Code sein könnte.
Vor allem bei großen und komplexen Anwendungen führt das dazu, dass das Kompilieren unnötig langsam wird, weil der Compiler selbst langsam ist beziehungsweise zumindest nicht so schnell, wie er theoretisch sein könnte. Das zeigt sich deutlich an Visual Studio Code: Microsoft gibt für ein Referenzsystem eine Kompilierzeit von rund 78 Sekunden an – fast anderthalb Minuten. Visual Studio Code ist zwar ein großes Projekt, umfasst aber trotzdem "nur" 1,5 Millionen Zeilen Code, was für ein Real-World-Projekt nicht allzu umfangreich ist.
Mit dem neuen Compiler, der aktuell als Vorabversion verfügbar ist, dauert der gleiche Vorgang nur noch 7,5 Sekunden – eine Beschleunigung um den Faktor zehn. Dieser Effekt ist reproduzierbar: So benötigt das Kompilieren von Playwright statt 11 Sekunden nur noch eine Sekunde. Bei date-fns sinkt die Zeit von 6,5 auf 0,7 Sekunden. Mal ist der Effekt etwas stärker, mal etwas schwächer, doch im Schnitt entspricht er dem Faktor zehn. Und das ist erst die erste Preview – es könnte also noch weitere Optimierungspotenziale geben.
Zusätzlich sinkt der RAM-Bedarf durch den neuen Compiler um rund 50 Prozent. Das mag auf einem lokalen Entwicklungsrechner nicht besonders relevant sein, aber für CI/CD-Pipelines ist das ein massiver Gewinn. Der neue Compiler ist also nicht nur schneller, sondern auch deutlich sparsamer. Das ist beeindruckend.
Doch wie erreicht Microsoft diese Verbesserung? Die Antwort ist einfach: Nativer Code läuft deutlich schneller und sparsamer als Code, der zur Laufzeit von einem JIT-Compiler übersetzt werden muss.
Dennoch war die Ankündigung überraschend: Viele hätten erwartet, dass Microsoft TypeScript in Rust neu implementiert. Die Wahl von Go sorgt daher für Diskussionen. Microsoft begründet die Entscheidung klar: Rust bietet zwar hervorragende Performance, doch seine Speicherverwaltung mit Konzepten wie Borrowing und Ownership wäre für eine 1:1-Portierung des bestehenden Codes ein unnötiges Hindernis. Ähnlich verhält es sich mit C++: Obwohl C++ bezüglich Performance kaum zu schlagen ist, gilt die Sprache als altmodisch, fehleranfällig und schwer wartbar. C# hätte wiederum den Nachteil, dass der Compiler auf die .NET-Runtime angewiesen wäre, was unpraktisch ist, da ein Compiler idealerweise als statisch gelinkte Binary lauffähig sein sollte. Der AOT-Compiler von .NET würde zudem nicht alle gewünschten Zielplattformen unterstützen. Daher fiel auch C# aus der Auswahl.
Warum also Go? Vor allem, weil es konzeptionell TypeScript ähnelt und die Portierung daher vereinfacht. Die Speicherverwaltung erfolgt über eine Garbage Collection, sodass keine manuelle Speicherverwaltung erforderlich ist. Go kann zudem statisch gelinkte Binaries für alle gängigen Plattformen erzeugen, die keine weiteren Abhängigkeiten zur Laufzeit haben. Zudem ist Go auf Performance und Parallelisierung optimiert – essenzielle Aspekte für einen Compiler.
Microsoft hat sich also nicht deshalb für Go entschieden, weil es die "beste" oder "schnellste" Sprache wäre, sondern weil es die beste Balance zwischen Performance, Wartbarkeit und einfacher Portierung bietet. Das ist eine nachvollziehbare Entscheidung, die sachlich fundiert ist.
Was bedeutet das für Sie als TypeScript-Entwicklerin oder -Entwickler? Kurzfristig bleibt alles wie gewohnt. Als Nächstes erscheint TypeScript 5.9. Die darauffolgende 6er-Reihe wird schrittweise einige Features als "deprecated" markieren und Breaking Changes einführen – als Vorbereitung auf den neuen Compiler. Dieser wird mit TypeScript 7.0 veröffentlicht. Ein konkretes Datum gibt es noch nicht, doch bisher lagen zwischen zwei Major Releases meist zwei bis drei Jahre. Daher ist frühestens 2027 mit der Veröffentlichung zu rechnen. Das ist zwar noch lange hin, gibt aber ausreichend Zeit für eine schrittweise Migration. Vorausgesetzt, man ignoriert nicht alle kommenden Versionen bis zur 7.0 und handelt erst, wenn der Wechsel unvermeidlich ist.
Was bringt die Umstellung? In erster Linie schnellere Builds – sowohl lokal als auch in der CI/CD-Pipeline. Auch das Feedback des TypeScript-Language-Servers dürfte spürbar schneller erfolgen, was eine bessere IDE-Performance ermöglicht. Zudem wird ab TypeScript 7 kein installiertes Node.js mehr für den Compiler benötigt – ein theoretischer Vorteil, der in bestimmten Situationen jedoch tatsächlich hilfreich sein könnte.
Allerdings sind noch Fragen offen. Wie wird TypeScript künftig in andere Anwendungen und Webbrowser integriert? Bisher war das kein Problem, da der Compiler zu JavaScript kompiliert wurde. Theoretisch könnte dies über WebAssembly erfolgen, was Go unterstützt, doch die praktische Umsetzung bleibt abzuwarten. Zudem müssen Entwicklerinnen und Entwickler von Erweiterungen für den TypeScript-Compiler ihre Tools anpassen. Noch ist unklar, ob es nach Version 7 eine JavaScript-basierte Variante des Compilers geben wird oder ob Microsoft einen harten Wechsel durchführt.
Die Ankündigung war überraschend, insbesondere der Wechsel zu Go. Microsoft hat jedoch klargemacht, dass diese Entscheidung endgültig ist. Die Wahl von Go ist ein intelligenter Kompromiss zwischen Performance und Wartbarkeit.
Was halten Sie von dieser Entwicklung? Begrüßen Sie die Portierung? Und wie stehen Sie zur Wahl von Go? Schreiben Sie Ihre Meinung in die Kommentare!
URL dieses Artikels:
https://www.heise.de/-10317343
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] https://www.heise.de/news/Microsoft-Native-Portierung-nach-Go-soll-TypeScript-zehnmal-schneller-machen-10312947.html
[3] https://devblogs.microsoft.com/typescript/typescript-native-port/
[4] https://www.youtube.com/watch?v=pNlq-EVld70
[5] https://enterjs.de/index.php?wt_mc=intern.academy.dpunkt.konf_dpunkt_vo_enterJS.empfehlung-ho.link.link
[6] https://enterjs.de/veranstaltung-78876-0-typescript--eine-anleitung-zum-ungluecklichsein.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_vo_enterJS.empfehlung-ho.link.link
[7] https://enterjs.de/veranstaltung-72524-0-4-kritische-antipatterns-in-derreact-typescript-entwicklung.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_vo_enterJS.empfehlung-ho.link.link
[8] https://enterjs.de/veranstaltung-78869-0-von-der-vision-zum-code-functional-domain-modeling-mit-typescript.html?wt_mc=intern.academy.dpunkt.konf_dpunkt_vo_enterJS.empfehlung-ho.link.link
[9] https://enterjs.de/tickets.php?wt_mc=intern.academy.dpunkt.konf_dpunkt_vo_enterJS.empfehlung-ho.link.link
[10] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pavel Ignatov/Shutterstock.com)
Softwareentwickler und Softwarearchitektinnen müssen sparsam mit Daten umgehen. Sonst entstehen Risiken, die niemand absehen kann.
Ende letzten Jahres ging der VW-Datenskandal [1] durch die Medienlandschaft: Der VW-Konzern sammelt und speichert Bewegungsdaten von sehr vielen seiner Autos. Aufgrund einer Fehlkonfiguration von Spring Boot konnte man über einen bestimmten Link einen Heap Dump einer Anwendung erstellen. Diese Anwendung hat Zugriff auf den Cloud-Speicher mit den Bewegungsdaten. Der Heap Dump enthielt die Schlüssel für den Zugriff auf die Daten – und so konnten die Angreifer die Daten herunterladen.
Was lernen wir daraus? Scheinbar ist das Ergebnis klar: Man sollte öffentlich zugängliche Anwendungen ausreichend absichern. Das ist zwar richtig, aber ich habe durch die Präsentation auf dem Chaos Communication Congress [2] etwas anderes gelernt: Wenn man die vergangenen Standorte eines Autos kennt, kann man daraus interessante Schlüsse ziehen. Nehmen wir beispielsweise an, dass ein Auto regelmäßig auf dem Parkplatz eines Geheimdienstes wie dem BND steht, dann regelmäßig nachts an einem festen Parkplatz in einem Wohngebiet und ab und zu auf einem Parkplatz eines Bordells. Das ist wertvolles Wissen. Man kann damit nämlich wahrscheinlich einen einfach zu identifizierenden Geheimdienstmitarbeiter erpressen. Insgesamt waren bei diesem Skandal 800.000 Autos betroffen und es gab ein Terabyte Daten. Da bieten sich genügend Chancen, so wertvolle Datenschätze zu finden.
Solche Probleme sind älter als Digitalcomputer: Die Niederlande hatten im Rahmen einer Volkszählung die Religionszugehörigkeit ihrer Bürger erfasst. Das haben die Nazis dann genutzt [3], um nach dem Einmarsch alle Juden zu deportieren.
Diese Datensätze sind so interessant, dass Geheimdienste versuchen werden, sie zu erbeuten. IT-Systeme kann man gegen solche Gegner nicht absichern. Ein Beispiel: Stuxnet [4]war ein Angriff auf die iranischen Ultrazentrifugen zur Herstellung von waffenfähigem Uran. Dabei sind unter anderem mehrere unbekannte Sicherheitslücken ("Zero-Day Exploits") in Windows genutzt worden. Gegen solche Angriffe kann man sich nicht schützen, weil die Sicherheitsprobleme unbekannt sind und es daher keine Gegenmaßnahmen geben kann. Das gilt sogar für Systeme von Atomanlagen, die wahrscheinlich nicht über Netzwerke wie das Internet zugreifbar sind und bei denen der physische Zugang wahrscheinlich kontrolliert wird.
Erwiesenermaßen sind auch die Daten unseres Parlaments nicht vor russischen Hackern sicher [5].
VW hat die Daten ungenügend gesichert, aber selbst wenn es das getan hätte: Das bedeutet nur, dass es schwieriger wird, auf die Daten zuzugreifen. Aber wenn ein Geheimdienst wirklich diese Daten haben will, wird ihm das gelingen.
Wichtig dabei: Es ist unwahrscheinlich, dass VW das einzige Unternehmen ist, das solche Daten speichert. Tesla sammelt beispielsweise Telemetriedaten und Videos und kann außerdem die Türen von Autos öffnen [6]. Diese Daten sind dann Menschen zugänglich, die einige für rechtsextrem [7]halten. Bei anderen Herstellern werden die Daten in autoritären Ländern gespeichert – sicher ebenfalls nicht optimal.
Aber nehmen wir an, dass die Daten nicht von vorneherein schon in problematischen Händen liegen, sondern "nur" gesichert werden müssen. Wie schwierig es ist, Daten zu sichern, zeigen Kryptowährungen. Wer den privaten Krypto-Schlüssel für ein Wallet hat, kann auf die entsprechenden Gelder zugreifen – egal, ob die Person das zu Recht tut oder das Geld gerade stiehlt. Daher müssen diese Schlüssel wirklich gut abgesichert werden. Es gibt aber eine Website [8], die ständig davon berichtet, dass wieder Kryptowährungsgelder verloren gegangen sind – meist viele Millionen, in einem Fall sogar 1,5 Milliarden US-Dollar [9]. Selbst wenn es also um bares Geld geht, können die Daten nicht ausreichend gesichert werden. Und auch in diesem Bereich sind Geheimdienste aktiv. Beispielsweise finanziert Nordkorea mit Krypto-Diebstählen seine Diktatur [10]und unter anderem sein Atomwaffenprogramm [11].
Absicherung der Daten ist also nicht die Lösung. Damit bleibt nur eine Lösung übrig: Diese Daten gar nicht zu erheben und zu speichern. Hier setzt Datenvermeidung und Datensparsamkeit [12] an: Beim Speichern von Daten muss man sich die Frage stellen, für welche Funktionalitäten sie erforderlich sind und nur die notwendigen Daten speichern. Wenn man sein Auto suchen will, benötigt man beispielsweise nur den aktuellen Ort, an dem das Auto steht. Dazu muss man keine historischen Daten speichern. Gegebenenfalls kann man sogar erst bei einer Anfrage Kontakt mit dem Auto aufnehmen und dann den aktuellen Standort des Autos ermitteln. Auf die Weise muss die Anwendung gar keine Daten speichern. Auf den ersten Blick ist nicht zu erkennen, wofür ein Unternehmen die historischen Bewegungsdaten eines Autos speichern will.
Zusätzlich könnte man Benutzerinnen und Benutzer fragen, ob bestimmte Funktionalitäten überhaupt aktiviert werden sollen. Dem BND ist es gegebenenfalls lieber, auf Komfortfunktionen eines Autos zu verzichten, als das Kompromittieren seiner Mitarbeiterinnen und Mitarbeiter zu vereinfachen. Das mag für andere anders sein. Wenn man aber nie klar fragt, sondern standardmäßig die Daten speichert und den Opt-out versteckt, macht es das schwierig, einen solchen Trade-off zu treffen und entmündigt die User.
Vor allem muss Schluss mit der Idee sein, dass Daten das neue Öl sind. Sonst ist das Speichern auf Vorrat für spätere Analyse völlig logisch und erzeugt Probleme wie den VW-Datenskandal.
Solche Phänomene gibt es auch an anderen Stellen: Will man wirklich die Gesundheitsdaten aller Deutschen sammeln und über ein Verfahren zugreifbar machen? Wie wertvoll sind diese Daten? Kann man sie dann überhaupt ausreichend schützen [13]?
Aber es gibt auch positive Beispiele: Bei der Corona-Warn-App ging es "nur" um Kontaktdaten, und dort hat man mit einer dezentralen Speicherung ein Konzept umgesetzt, das selbst der Chaos Computer Club "sehr gut" [14] fand.
Softwareentwicklerinnen und Softwarearchitekten müssen sich damit auseinandersetzen, was man mit den Daten aus ihrer Software anfangen kann. Ich fand es vor dem VW-Hack nicht offensichtlich, wie wertvoll diese Daten für interessierte Parteien sein können. Und das, obwohl schon zuvor Smartwatches die Position von Militärbasen verraten [15] haben. Daher müssen sich Entwicklungsteams immer die Frage stellen, ob man die Daten überhaupt sammeln will.
In den USA bekommt Elon Musks DOGE (das sogenannte "Department of Government Efficiency") Zugriff auf große Mengen von Daten [16]. Die Öffentlichkeit wird damit beruhigt, dass es nur um das Lesen der Daten ginge. Das zeugt von einer gewaltigen Naivität über den Wert von Daten. DOGEs eigene Website ist völlig unsicher [17]. Die Mitarbeiterinnen und Mitarbeiter versagen dabei, ihre eigenen Daten abzusichern [18]. Man muss also bezweifeln, ob Daten bei DOGE sicher sind. Es ist sicher eine gute Idee, sich auch die Frage zu stellen, was passiert, wenn gespeicherte Daten im Internet frei zugreifbar sind oder sie Rechtsextremisten oder einer undemokratischen Regierung in die Hände fallen.
Daten sind nur sicher, wenn man sie nicht speichert und erhebt. Developer-Teams sollten daher nur die Daten speichern, die unbedingt gespeichert werden müssen.
URL dieses Artikels:
https://www.heise.de/-10318961
Links in diesem Artikel:
[1] https://www.heise.de/meinung/Kommentar-zur-VW-Datenpanne-DSGVO-zeig-deine-Zaehne-10245938.html
[2] https://media.ccc.de/v/38c3-wir-wissen-wo-dein-auto-steht-volksdaten-von-volkswagen
[3] https://www.heise.de/hintergrund/Zahlen-bitte-Die-Lochkarte-Mit-80-Zeichen-wegweisend-in-die-EDV-4274778.html
[4] https://de.wikipedia.org/wiki/Stuxnet
[5] https://de.wikipedia.org/wiki/Hackerangriffe_auf_den_Deutschen_Bundestag
[6] https://www.heise.de/news/Explosion-in-Las-Vegas-Tesla-oeffnet-Cybertruck-aus-der-Ferne-und-sammelt-Videos-10223798.html
[7] https://de.wikipedia.org/wiki/Elon_Musk#Einordnung_im_politischen_Spektrum
[8] https://www.web3isgoinggreat.com/
[9] https://www.web3isgoinggreat.com/?id=bybit-hack
[10] https://edition.cnn.com/2025/02/24/politics/north-korean-hackers-crypto-hack/index.html
[11] https://apnews.com/article/technology-crime-business-hacking-south-korea-967763dc88e422232da54115bb13f4dc
[12] https://de.wikipedia.org/wiki/Datenvermeidung_und_Datensparsamkeit
[13] https://www.heise.de/news/38C3-Weitere-Sicherheitsmaengel-in-elektronischer-Patientenakte-fuer-alle-10220617.html
[14] https://www.tagesschau.de/inland/coronavirus-app-107.html
[15] https://www.gq-magazin.de/leben-als-mann/fitness/fitness-app-entdeckt-militaerbasen-180130
[16] https://www.telepolis.de/features/DOGE-und-Trump-Wie-Elon-Musk-den-US-Staat-umkrempeln-will-10281056.html
[17] https://www.derstandard.de/consent/tcf/story/3000000257396/zusammengeschustert-behoerden-website-von-doge-gehackt
[18] https://www.businessinsider.com/doge-nasa-google-calendar-public-2025-3
[19] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: generated by DALL-E)
Die Artikelserie zeigt die internen Mechanismen großer Sprachmodelle von der Texteingabe bis zur Textgenerierung.
Ein Large Language Modell (LLM) ist darauf ausgelegt, menschliche Sprache zu verarbeiten und zu generieren. Nach der grundlegenden Einführung von LLMs im ersten [1] und den Hardwareanforderungen und vorabtrainierten Modellen im zweiten Teil [2] geht es diesmal um unterschiedliche Architekturtypen.
Fasten your seat belts!
Ein häufiges Missverständnis der Transformer-Architektur besteht darin, dass LLMs notwendig alle Teile dieser Architektur enthalten müssen. Das ist nicht der Fall. Stattdessen lassen sich in der Praxis die folgenden Architekturtypen unterscheiden:
Sequence-to-Sequence-Modelle (Seq-to-Seq) sind darauf ausgelegt, eine Eingabesequenz wie einen Satz auf eine Ausgabesequenz wie eine Übersetzung oder Antwort abzubilden. Sie implementieren die Transformer-Architektur und bestehen infolgedessen aus:
Seq-to-Seq-Modelle werden häufig für Aufgaben wie maschinelle Übersetzung, Textzusammenfassung und Textgenerierung eingesetzt. Beispiele sind das ursprüngliche Transformer-Modell von Google und T5 (Text-to-Text Transfer Transformer).
Decoder-Only-Modelle: Modelle wie GPT (Generative Pre-trained Transformer) verwenden eine reine Decoder-Architektur. Sie sind darauf trainiert, das nächste Token in einer Sequenz vorherzusagen, was sie besonders effektiv für Textgenerierung und -vervollständigung macht. Diese Modelle glänzen bei offenen Aufgaben, besitzen jedoch kein bidirektionales Kontextverständnis.
Encoder-Only-Modelle: BERT (Bidirectional Encoder Representations from Transformers) ist ein Beispiel für ein reines Encoder-Modell. Es verarbeitet Eingabetext bidirektional und erfasst Kontext sowohl aus vorangehenden als auch nachfolgenden Token. BERT eignet sich ideal für Aufgaben wie Sentimentanalyse, Named-Entity Recognition und Frage-Antwort-Systeme, kann aber keinen Text direkt generieren.
Wer Sentimentanalyse nicht kennt: Hier soll das Modell die Grundstimmung wie positiv oder negativ eines Satzes analysieren. Zum Beispiel enthält "Ich finde diesen Artikel gut." eine positive Aussage.
Hybride Architekturen: Einige Modelle wie T5 kombinieren Encoder-Decoder-Architekturen für einen einheitlichen Ansatz. T5 behandelt jede NLP-Aufgabe als ein Text-zu-Text-Problem, bei dem sowohl Eingabe als auch Ausgabe Textsequenzen sind. Diese Flexibilität macht es für vielfältige Aufgaben wie Übersetzung, Zusammenfassung und Klassifizierung geeignet.
Um LLMs zu trainieren, braucht es zunächst Daten und davon eine ganze Menge mit ausreichender Qualität. Das Training erfolgt in drei Schritten.
Das Training optimiert die gewählten Gewichte, bis die Verlustfunktion nur noch verschwindend kleine Vorhersagefehler (die Minima der Verlustfunktion) zurückmeldet.
Zur Optimierung gibt es unterschiedliche Stellgrößen und Verfahren:
Um das Training zu verbessern, hat es sich darüber hinaus als empfehlenswert herausgestellt, mit Dropouts zu arbeiten. Dropouts definieren für eine neuronale Schicht bzw. für ein neuronales Netzwerk, dass ein gewisser Prozentsatz zufällig ausgewählter Neuronen in einer Trainingsiteration inaktiv bleiben soll. Dadurch erhöht sich erfahrungsgemäß die Robustheit des Verfahrens.
In großen Sprachmodellen (LLMs) wie GPT, BERT oder T5 ist eine Residual Connection (manchmal auch Skip Connection) ein zentrales Element der Transformer-Architektur. Sie stabilisiert das Training und ermöglicht es dem Modell, effektiv über Dutzende oder Hunderte von Schichten hinweg zu lernen. Ohne Residual Connections wären moderne LLMs kaum effektiv trainierbar, insbesondere in großem Maßstab. Sie sind grundlegend für das "Deep" in Deep Learning bei Sprachmodellen!
Wie Residual Connections funktionieren:
Residual Connections sind somit aus folgenden Gründen in LLMs wichtig:
Wichtige LLMs mit Residual Connections beinhalten unter anderem:
Der Einsatz trainierter LLMs geschieht über Chatbots der Hersteller, über APIs oder für lokal verfügbare Modelle über Werkzeuge wie Ollama und llama.cpp.
In der sogenannten autoregressiven Decodierung erzeugt das Modell Schritt für Schritt neue Token:
Die genutzten Sampling-Strategien (= Tokenauswahlstrategien) umfassen dabei verschiedene Optionen:
Der vom Nutzer beeinflussbare Parameter Temperatur kontrolliert die Zufälligkeit (hohe Temperatur kreativ, niedrige konservativ) der gewählten Token.
Zu beachten sind dabei Skalierungsgesetze und Modellgrößen wie:
Normalsterbliche Nutzer von LLMs können natürlich mangels ausreichender finanzieller Mittel und Hardware keine eigenen LLMs trainieren, zumindest nicht große Frontier-Modelle wie die von OpenAI, Claude, Cohere, Meta, Google und Microsoft. Allerdings ist es möglich, die Gewichte eines Open-Source- oder Open-Weight-Modells finezutunen. Open-Weights-Modelle liefern zwar die Gewichte mit, aber im Gegensatz zu Open-Source-Modellen nicht die zum Training verwendeten Daten oder Workflows. In beiden Fällen ist es aber möglich, die meisten Gewichte des trainierten Modells einzufrieren, um danach mit eigenen Trainingsdaten die nicht eingefrorenen Gewichte zu trainieren. Das nennt man Transfer-Learning. Dazu gibt es verschiedene Werkzeuge für macOS (z. B. MLX), Linux und Windows (z. B. Unsloth). Vorteil dieses eher leichtgewichtigen Ansatzes ist der geringere Hardwarebedarf und Zeitaufwand, um LLMs mit neuen domänenspezifischen Daten anzureichern. Das ist bei kleineren Modellen auch für den "Heimgebrauch" machbar.

(Bild: Wikipedia [7])
Da Modelle immer nur die aktuellen Daten zum Zeitpunkt ihres Trainings beinhalten und meistens eine sehr breite Zahl von Domänen antrainiert bekommen, gibt es mehrere Möglichkeiten, nachträglich tagesaktuelle Daten oder domänenspezifische Daten auf Umwegen ins Modell "einzuschleusen":
RAG (Retrieval Augmented Generation): Die Benutzerin nutzt ein passendes LLM-Modell. Zusätzlich verwendet sie eine Vektordatenbank. In dieser speichert sie Embeddings. Die Generierung der Embeddings erfolgt mit Hilfe vorliegender Dokumente, die die Anwendung zunächst in Teile (Chunks) zerlegt, die Teile anschließend in Embeddings (Vektoren) umwandelt und dann in der Vektordatenbank speichert. Falls eine Benutzeranfrage eintrifft, sucht die Anwendung zunächst in der Datenbank nach zum Eingabe-Prompt ähnlichen Embeddings (z. B. mittels Cosinus-Ähnlichkeitssuche), übergibt diese mit einem dafür geeigneten Prompt an das LLM und liefert dessen Ausgabe nach optionaler Nachbearbeitung an den User zurück. Dafür ist freilich notwendig, dass RAG und LLM das gleiche Embedding-Modell verwenden. Natürlich kann ein RAG-System alternativ auch mit ElasticSearch nach passenden Informationen suchen. Letzteren Ansatz können Entwickler zusammen mit Websuchen dafür nutzen, um eine LLM-unterstützte Websuche zu implementieren. Der Dienst Perplexity ist hierfür ein interessantes Beispiel.
Knowledge Graphs: Modernere Ansätze nutzen eine Graph-Datenbank (z. B. Neo4j) aus Wissensgraphen (Knowledge Graphs), um Information strukturiert zu speichern. Bei RAG-Systemen handelt es sich hingegen bei den gespeicherten Embeddings in der Regel um unstrukturierte Daten. Strukturierte Daten führen erfahrungsgemäß zu weniger Halluzinationen und sind leichter zu analysieren. In der Zukunft könnten Wissensgraphen daher an Bedeutung gewinnen.
Sie möchten ein LLM-Modell, das nicht in den Arbeitsspeicher ihrer GPU oder CPU passt, dennoch nutzen? Normalerweise speichern die Schichten eines LLM Gewichte und Bias-Vektoren in Form von 32-Bit-Gleitkommazahlen. Diese Präzision ist aber nicht immer notwendig. Quantisierung in Large-Language-Modellen bezeichnet den Prozess, bei dem die Präzision der Modellparameter reduziert wird, um die Modellgröße und den Rechenaufwand zu verringern. Dies geschieht durch die Umwandlung von hochpräzisen Datenformaten (z. B. 32-Bit-Gleitkommazahlen) in weniger präzise Formate (z. B. 8-Bit-Ganzzahlen). Dadurch können LLMs auf Hardware mit begrenzten Ressourcen ausgeführt werden, was zu schnelleren Inferenzen und geringerem Speicherverbrauch führt. Allerdings kann die Quantisierung die Genauigkeit der Modelle beeinträchtigen. In vielen Fällen ist der Genauigkeitsverlust durch Quantisierung verschmerzbar.
Wenn sie beispielsweise in Hugging Face nach Modellen suchen, dürften Sie auf seltsame Dateinamen für Modelle stoßen, etwa auf <modelname>….Q4_K_M. Endungen von LLM-Namen wie Q4_K_M enthalten wichtige Informationen über die Quantisierung und Optimierung des Modells. Hier ist eine detaillierte Erklärung:
Q4: Dies zeigt an, dass das Modell auf eine 4-Bit-Präzision quantisiert wurde. Quantisierung reduziert die Präzision der Modellgewichte von der typischen 32-Bit-Gleitkommadarstellung auf eine niedrigere Präzision, wie 4 Bit, um Speicherplatz zu sparen und die Inferenzgeschwindigkeit zu verbessern.K: Dies bezieht sich auf die spezifische Quantisierungsmethode, die für bestimmte Teile des Modells verwendet wird, zum Beispiel die Aufmerksamkeitsmechanismen. Es beinhaltet oft die Optimierung des Kernels (K) für bessere Leistung.M: Dieser Suffix zeigt typischerweise an, dass die Quantisierungsmethode selektiv angewendet wird, oft auf bestimmte Schichten wie Einbettungen oder Aufmerksamkeitsmechanismen, während andere in der höheren Präzision bleiben. Dieser Ansatz balanciert Leistung und Speicherbedarf.Zusammenfassend bedeutet Q4_K_M, dass das Modell auf 4-Bit-Präzision quantisiert ist, wobei optimierte Kernelmethoden selektiv Anwendung finden, um die Leistung zu erhalten, während sich der Speicherbedarf reduziert.
Hier ein Überblick über gängige Kürzel der möglichen Quantisierungsstufen:
Q2 (2 Bit)Q4 (4 Bit)Q8 (8 Bit)Q16 (16 Bit)Q32 (32 Bit, typischerweise nicht quantisiert)K: Dies könnte sich auf eine spezifische Kernel- oder Optimierungsmethode beziehen. Mögliche Variationen könnten unterschiedliche Kerneloptimierungen oder Techniken umfassen, aber spezifische Werte sind nicht standardisiert.M (Gemischte Präzision): Nur eine Teilmenge der Schichten erfährt eine Quantisierung, F (Volle Präzision): Das Modell verwendet die volle Präzision sowie S (Selektive Quantisierung): Quantisierung findet nur für eine selektive Teilmenge der Schichten statt.Mögliche Kombinationen könnten also sein:
Q2_K_MQ4_K_FQ8_K_SQ16_K_MDiese Kombinationen spiegeln somit unterschiedliche Quantisierungsstufen und Optimierungsstrategien wider. Die genauen Namenskonventionen können jedoch je nach spezifischer Implementierung oder Modellarchitektur variieren.
Hinzufügungen wie _0 oder _1 bezeichnen Versionen von Quantisierungsschemata, beispielsweise unterschiedliche Algorithmen oder Techniken.
Im Umfeld von LLMs sind Modelle fast immer als GGUF/GGML-Dateien gespeichert. Auch Apple MLX unterstützt hauptsächlich das GGUF (GPT-Generated Unified Format) für Modelldateien, hat jedoch kürzlich eine begrenzte Unterstützung für Quantisierungsausgaben erhalten, was darauf hindeuten könnte, dass es indirekt mit anderen Formaten kompatibel ist. Es gibt jedoch keine explizite Erwähnung, dass MLX Formate außer GGUF für seine Kernoperationen nutzt.
Gängige Formate, die LLM-Anbieter im maschinellen Lernen und bei großen Sprachmodellen verwenden:
Tensordateien .pt und .pth:
Diese Formate erleichtern den Austausch und die Bereitstellung von Modellen auf verschiedenen Plattformen und Frameworks. In PyTorch sind .pt und .pth Dateierweiterungen, die Entwickler häufig zum Speichern von Modellen verwenden. Es gibt keinen funktionalen Unterschied zwischen ihnen; beide lassen sich nutzen, um PyTorch-Modelle oder Tensoren mithilfe des Python-pickle-Moduls über torch.save() zu speichern. Die Wahl zwischen .pt und .pth ist weitgehend eine Frage der Konvention. Allerdings wird .pt gegenüber .pth empfohlen, da .pth mit Python-Pfadkonfigurationsdateien in Konflikt geraten kann.
Beide Erweiterungen funktionieren austauschbar mit den torch.save()- und torch.load()-Funktionen. Aber was genau ist in diesen Dateien eigentlich gespeichert?
Sie speichern typischerweise serialisierte Daten, oft Modellgewichte oder andere Python-Objekte, konkret:
state_dict), das die Modellparameter enthält.Lightning-Checkpoints, die ebenfalls die Erweiterungen .pt oder .pth verwenden könnten, speichern umfassendere Informationen, darunter Modellzustand, Optimiererzustände, Lernrateplanungszustände, Callback-Zustände, Hyperparameter.
In einer .pt-Datei sind die Einträge nicht in einem menschenlesbaren Format gespeichert. Stattdessen verwendet PyTorch das Python-pickle-Modul, um Tensoren und andere Python-Objekte in ein binäres Format zu serialisieren.
Falls Sie sich über Kennzeichnungen wie "INSTRUCT" in den Modellnamen wundern, hier ein paar Erläuterungen dazu:
In LLM-Dateinamen gibt es verschiedene Namen, die auf spezifische Techniken oder Anwendungen hinweisen. Einige Beispiele sind:
Der letzte Teil dieser Blogserie wird Reasoning-Modelle vorstellen und einen Blick in die Zukunft der LLMs wagen.
URL dieses Artikels:
https://www.heise.de/-10296358
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[4] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[5] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[6] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[7] https://en.wikipedia.org/wiki/Retrieval-augmented_generation#/media/File:RAG_diagram.svg
[8] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
In .NET 9.0 kann man neuerdings einen Globally Unique Identifier in der Version 7 mit Zeitstempel erzeugen.
Die .NET-Klasse System.Guid bietet seit .NET 9.0 neben der statischen Methode NewGuid(), die einen Globally Unique Identifier (GUID), alias UUID (Universally Unique Identifier), gemäß RFC 9562 [1] mit reinen Zufallszahlen (Version 4) erzeugt, nun auch eine weitere statische Methode CreateVersion7() mit einem Timestamp und einer Zufallszahl.
Folgender Code zeigt sowohl den Einsatz von NewGuid() als auch den von CreateVersion7():
public void Run()
{
CUI.Demo(nameof(FCL9_Guid));
for (int i = 0; i < 10; i++)
{
Guid guid = Guid.NewGuid();
Console.WriteLine($"Guid v4:\t{guid}");
}
for (int i = 0; i < 10; i++)
{
Guid guid7 = Guid.CreateVersion7();
Console.WriteLine($"Guid v7:\t{guid7}");
}
CUI.Yellow("Warte 1 Sekunde...");
Thread.Sleep(1000);
for (int i = 0; i < 10; i++)
{
Guid guid7 = Guid.CreateVersion7();
Console.WriteLine($"Guid v7:\t{guid7}");
}
}

(Bild: Screenshot (Holger Schwichtenberg))
Der Timestamp ist in UTC-Zeit in den ersten 64 Bits der GUID enthalten.
Zum Extrahieren des Zeitpunkts gibt es keine eingebaute Methode, man kann ihn aber folgendermaßen extrahieren:
public DateTimeOffset GetDateTimeOffset(Guid guid)
{
byte[] bytes = new byte[8];
guid.ToByteArray(true)[0..6].CopyTo(bytes, 2);
if (BitConverter.IsLittleEndian)
{
Array.Reverse(bytes);
}
long ms = BitConverter.ToInt64(bytes);
return DateTimeOffset.FromUnixTimeMilliseconds(ms);
}
URL dieses Artikels:
https://www.heise.de/-10316051
Links in diesem Artikel:
[1] https://www.rfc-editor.org/rfc/rfc9562.html
[2] mailto:rme@ix.de
Copyright © 2025 Heise Medien
This is a bugfix release for 1.26.0, addressing some regressions 🐛
A few highlights ✨:
This release has been made by @Alkarex, @FromTheMoon85, @marienfressinaud, @math-GH
and newcomers @abackstrom, @BryanButlerGit, @culbrethj, @EricDiao, @Karvel, @ViPeR5000
Full changelog:

(Bild: Pincasso/Shutterstock)
In C# 13.0 hat Microsoft den Einsatzbereich von ref struct unter anderem zum Implementieren von Schnittstellen erweitert.
Seit C# 7.2 gibt es Strukturen, die immer auf dem Stack leben und niemals auf den Heap wandern können: ref struct. In C# 13.0 hat Microsoft den Einsatz von ref struct erweitert.
Solche Typen können nun:
where T : allows ref struct verwenden.yield verwendet werden. Allerdings darf die Struktur nicht länger leben als der aktuelle Durchlauf des Iterator.Task oder Task<T> liefern, genutzt werden.Weiterhin gilt aber: Wenn man einen Typ als ref struct deklariert, ist ein Boxing nicht mehr möglich. Der Einsatz von ref struct ist daher begrenzt. So kann man beispielsweise kein Array und keine List<T> daraus erzeugen.
Folgender Code zeigt einen eigenen Typ mit ref struct, der eine Schnittstelle implementiert:
internal interface IPerson
{
int ID { get; set; }
int Name { get; set; }
}
// NEU seit C# 13.0: ref struct kann Schnittstelle implementieren
ref struct Person : IPerson
{
public int ID { get; set; }
public int Name { get; set; }
// ToString()
public override string ToString()
{
return "Person #" + ID + " " + Name;
}
}
}
class Client
{
public void Run()
{
Person p = new Person();
p.ID = 1;
p.Name = 2;
Console.WriteLine(p.ID);
Console.WriteLine(p.Name);
// Das ist alles nicht erlaubt!
// IPerson i = p; // Casting auf Schnittstelle
// List<Person> PersonList = new(); // List<T>
// PersonList[] PersonArray = new Person[10]; // Array
}
}
URL dieses Artikels:
https://www.heise.de/-10307583
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: Erstellt mit DALL-E)
Die Artikelserie zu den internen Mechanismen großer Sprachmodelle behandelt diesmal die benötigte Hardware und pretrained Models.
Ein Large Language Model (LLM) ist darauf ausgelegt, menschliche Sprache zu verarbeiten und zu generieren. Nach der grundlegenden Übersicht zu LLMs im ersten Teil [1] geht es dieses Mal um die Hardware-Anforderungen und unterschiedliche vorab trainierte Modelle.
Fasten your seat belts!
Am Rande eine Bemerkung zu Hardware-Anforderungen: In der Beschreibung ist zu erkennen, dass im LLM sowohl für das Training als auch für die Ausführung (Inferenz) komplexe mathematische Berechnungen mit Vektoren vorkommen. Auf diese sind GPU-Kerne und neuronale Prozessoren spezialisiert. Daher benötigen LLM-Entwicklerinnen und -Nutzer leistungsvolle TPUs oder GPUs mit möglichst viel RAM. Mit normalen CPUs und wenig Arbeitsspeicher kommt man nicht weit, außer für sehr kleine Modelle. In den Speicher der GPU müssen unter anderem der Kontext und die errechneten Gewichte des LLM passen. Letztere können bis zu mehreren Hundert Gigabyte umfassen, während der Kontext von einigen Kilobytes bis zu vielen Megabytes reicht. Das Modell Deepseek R1 weist 671 Milliarden Gewichte/Tensoren und damit einen Speicherbedarf von rund 500 Gigabyte auf; OpenAI-Modelle sollen teilweise über ein Terabyte benötigen. Dafür wären etwa mehrere GPU-Beschleuniger vom Typ Nvidia H100 notwendig. Folgerichtig können Entwickler nur beschränkt Modelle auf ihren lokalen Systemen trainieren und laufen lassen, etwa bei guter Hardware-Ausstattung Modelle mit bis zu 70 Milliarden Parametern.
Vorab trainierte Modelle sind LLMs, die ihre Schöpfer auf großen Datensätzen trainiert und für spezifische Aufgaben feingetunt haben. Diese Modelle dienen als Ausgangspunkt für andere Aufgaben, um dem Modell zu ermöglichen, die während des Trainings gelernten Muster und Beziehungen zu nutzen. Beliebte vorab trainierte Modelltypen sind:
Kontextfenster beziehen sich auf die Menge an Eingabetext, die das Modell zu einem bestimmten Zeitpunkt betrachten kann. Das haben wir schon im ersten Teil der Serie [6] betrachtet, soll aber hier nochmals Erwähnung finden. Das Kontextfenster kann fest oder dynamisch sein, je nach Modellarchitektur. Ein größeres Kontextfenster ermöglicht es dem Modell, mehr Kontext zu erfassen, erhöht aber auch den Rechenaufwand. Moderne LLMs haben Kontextlängen von ein paar tausend bis zu ein paar Millionen Tokens.
Masken helfen, das Modell daran zu hindern, auf bestimmte Teile des Eingabetextes zu achten. Es gibt verschiedene Arten von Masken, darunter:
Sobald man eine Abfrage (Prompt) in ein LLM eingibt, durchläuft die Abfrage die folgenden Schritte:
Danach führt das LLM die folgenden Schritte aus:
Der nachfolgende Code demonstriert die Schritt-für-Schritt-Verarbeitung einer Abfrage, einschließlich Tokenisierung, Embedding-Erstellung, positioneller Codierung, Self-Attention, Cross-Attention, Feed-Forward-Layer, Kontextfenster und Maskierung.
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# Laden Sie das vorab trainierte Modell und den Tokenizer
modell = AutoModelForMaskedLM.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Definieren Sie eine Abfrage
abfrage = "Erläutere die Geschichte des Heise-Verlags."
# Tokenisieren Sie die Abfrage
eingabe = tokenizer(abfrage, return_tensors="pt")
# Erstellen Sie die Embeddings
embedded_abfrage = modell.embeddings(eingabe["input_ids"])
# Fügen Sie die positionale Kodierung hinzu
positionale_kodierung = modell.positional_encodings(embedded_abfrage)
embedded_abfrage = embedded_abfrage + positionale_kodierung
# Wenden Sie die Self-Attention an
kontextualisierte_darstellung = modell.self_attention(embedded_abfrage)
# Wenden Sie die Cross-Attention an
hoeher_ebene_darstellung = modell.cross_attention(kontextualisierte_darstellung)
# Wenden Sie die Feed-Forward-Layer an
transformierte_darstellung = modell.feed_forward_layers(hoeher_ebene_darstellung)
# Wenden Sie das Kontextfenster an
endgueltige_ausgabe = modell.context_window(transformierte_darstellung)
# Maskieren Sie die Ausgabe
antwort = modell.masking(endgueltige_ausgabe)
print(antwort)Die folgenden Dateien erstellt oder modifiziert das Modell während der Ausführung:
Hinweis: Dies ist ein stark vereinfachtes Beispiel. Reale Anwendungen mit LLMs sind in der Praxis viel komplexer und vielschichtiger.
In meinem nächsten Blogbeitrag gehe ich auf unterschiedliche Architekturtypen von LLMs ein.
URL dieses Artikels:
https://www.heise.de/-10296098
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[4] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[5] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[6] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[7] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Java wird im Jahr 2025 schon 30 Jahre alt. Das ist ein guter Zeitpunkt, zurück, aber auch nach vorn zu blicken.

Der Softwarearchitekt und -entwickler Adam Bien hat sich in der internationalen Java-Szene einen Namen gemacht. Er ist Java Champion und wurde 2010 zum Java Developer of the Year gekürt [1]. Auf Konferenzen begeistert er seit Jahren sein Publikum und wurde für seine Vorträge unter anderem auf der Java One seit 2009 mehrmals zu den RockStars gewählt.
Adam wird bei der JavaLand 2025 eine Keynote zu 30 Jahren Java [2] halten, und wir haben ihm vorab schon einige Fragen gestellt.
Falk Sippach: Adam, du bist eine Schlüsselfigur in der Java-Community und hast die Evolution der Plattform und der Sprache schon relativ früh bis zur Gegenwart aktiv mitgestaltet. Wann und mit welcher Version bist du erstmals mit Java in Berührung gekommen?
Adam Bien: Ich habe Java kurz vor der Veröffentlichung des JDK 1.0 evaluiert und war nicht begeistert. Ich war damals ein C++-Fan und hatte viel Spaß mit Operator Overloading und Include-Dateien. Beides fehlte mir in Java. Das war etwa 1995.
Falk Sippach: Wenn man sich deine bisherigen Veröffentlichungen (Bücher, Vorträge, Workshops, ...) anschaut, fallen dabei viele relevante Meilensteine des Java-Ökosystems ins Auge. Was waren für dich in deiner Laufbahn die bemerkenswertesten Sprachfeatures, Bibliotheken, Standards und Werkzeuge?
Adam Bien: Alles begann mit Applets. Mein erstes kommerzielles Projekt war ein Chat-Applet mit Remote Method Invocation (RMI) Backend. Aber ich konnte es kaum erwarten, bis Servlets verfügbar wurden. Ich sollte eine serverseitige CMS-Anwendung mit Common Gateway Interface (CGI) implementieren. Ich hatte keine Erfahrung mit CGI und wartete ungeduldig auf die erste Version des JavaWebServers von Sun Microsystems um 1997.
Das nächste Projekt, wieder mit JavaWebServer, war eine E-Commerce-Lösung. Hier haben wir das gesamte Backend mit JavaBeans und JDBC implementiert. Die Produktvielfalt war eine echte Herausforderung. Die Applikationsserver waren kaum vergleichbar und die Programmiererfahrung nicht übertragbar. Mit der Einführung von J2EE wurde dieses Problem durch die Standardisierung der APIs gelöst. Fortan konnte ich produktiv mit verschiedenen Produkten entwickeln.
Die Idee von Quarkus hat mich ebenfalls überrascht. Die APIs beizubehalten und gleichzeitig das Deployment zur Laufzeit zu eliminieren, war revolutionär. In den meisten Projekten haben mir die Patterns bei der "Don't Make Me Think"-Entwicklung geholfen und mir Hunderte von überflüssigen Meetings erspart. Wir haben uns auf die Patterns verlassen, um die Anwendung zu strukturieren und uns auf die Implementierung des Mehrwerts konzentriert.
Falk Sippach: Welche Rolle spielt Java deiner Meinung nach in der modernen Softwareentwicklung, insbesondere im Vergleich zu anderen Sprachen und Technologien?
Adam Bien: Java wird immer einfacher und die Entwicklung immer produktiver. Die Typsicherheit von Java wurde mit der wachsenden Popularität von Ruby on Rails um 2006 belächelt, "Duck Typing" mit zusätzlichen Unit Tests sollte die Produktivität und Lesbarkeit des Codes erhöhen. Daraufhin folgten einige schwer wartbare Projekte, die versuchten, zu Java zurückzukehren. Heute versuchen die meisten Programmiersprachen typsicher zu sein. Selbst JavaScript und Python wollen die Typsicherheit.
Auch ORMs wie JPA wurden als überflüssig abgestempelt – NoSQL sollte agiler und leichter verständlich sein. Heute sind ORMs in JavaScript-Frameworks sehr beliebt. Ich habe das Gefühl, dass alle Java-Hypes, die vor 10 Jahren populär waren, heute in anderen Programmiersprachen zu finden sind.
Es wurde sogar argumentiert, dass Java eine Low-Level-Programmiersprache ist, die unnötig schnell ist. Statt Java sollte man lieber höhere, aber weniger performante Programmiersprachen verwenden. Tatsächlich ist Java sehr schnell. Es ist um Faktoren schneller als JavaScript oder Python und vergleichbar mit C.
Java ist langweilig, gut lesbar und eine "No-Magic"-Programmiersprache mit einem sehr guten Tooling und Ökosystem. Daher eignet sich Java besonders für große Projekte. Neue Java-Features wie die direkte Ausführbarkeit von Quelldateien machen Java auch für kleinere Anwendungen und Scripting interessant.
Falk Sippach: Was hat dich motiviert, Java nahezu 30 Jahre lang die Treue zu halten?
Adam Bien: Anfangs wollte ich möglichst viele Programmiersprachen verwenden. Aufgrund der großen Nachfrage nach Java musste ich diese Strategie schnell aufgeben. Sun Microsystems hat früh auf Standards und Herstellervielfalt gesetzt. Ich habe mich auf Standards konzentriert und konnte inkrementell lernen und Erfahrungen sammeln. Um mich herum wurden viele Frameworks gehypt, eingesetzt und wieder verworfen. Dann kam wieder ein ganz anderes Framework zum Einsatz. Man musste sich die Idiome neu aneignen, die Erfahrung war selten übertragbar.
Erst kürzlich habe ich ein etwa 15 Jahre altes Projekt modernisiert. Es war viel einfacher, als ich dachte. Mit Java konnte ich einfachen und langweiligen Produktionscode schreiben und in meiner Freizeit viel Spaß mit JINI, JavaSpaces, JXTA, RMI, JIRO, FreeTTS, Hazelcast und unzähligen anderen Frameworks haben. Java macht mir immer noch Spaß und meine Kunden sind zufrieden. Ich sehe keinen Grund, zu wechseln. Lediglich im Frontend verwende ich reine "Webstandards" und Web Components gepaart mit reinem JavaScript ohne Abhängigkeiten oder externe Bibliotheken. "The Java way". Auch dieser Ansatz wird übrigens immer populärer.
In den letzten Jahren konnten wir mit Java, Quarkus und serverlosen Architekturen einfache Anwendungen bauen, die im Betrieb sehr kostengünstig, in einigen Fällen sogar kostenlos waren. Sogar die Kommentare zu meinen (>800) YouTube-Shorts sind überraschend positiv – Java ist immer noch sehr populär und viele sind immer noch überrascht von den Java-Features.
Falk Sippach: Welche Tipps kannst du aktuellen Java-Entwicklern geben, um in der sich schnell verändernden Technologielandschaft am Ball zu bleiben und sich mit Java weiterzuentwickeln?
Adam Bien: Hypes wiederholen sich. Das Wichtigste ist, möglichst einfachen Code zu schreiben. Der Mehrwert für den Kunden sollte immer im Vordergrund stehen.
Falk Sippach: Zu guter Letzt wollen wir noch einen Blick in die Zukunft wagen. Welche Herausforderungen und Chancen siehst du für Java in den nächsten fünf bis zehn Jahren?
Adam Bien: In Java gibt es derzeit viele Innovationen. GraalVM ermöglicht die Ausführung von JavaScript, Python und sogar WebAssembly auf der JVM und mit optionaler Übersetzung in Maschinencode, Graal OS sieht aus wie ein "Pure Java"-Kubernetes, Project Babylon ermöglicht die Transformation von Code – auch für den Betrieb auf GPUs, Valhalla hilft mit Performancegewinnen bei der Model Inference, Leyden macht die Dauer von Kaltstarts konfigurierbar. Es sieht also ausgezeichnet aus - vielleicht gibt es bald einen neuen Java-Hype.
Wollt Ihr Adam Bien live erleben, dann kommt auf die JavaLand [3], die vom 1. bis 3. April am Nürburgring stattfindet.
URL dieses Artikels:
https://www.heise.de/-10304215
Links in diesem Artikel:
[1] https://in.relation.to/2010/10/11/adam-bien-java-developer-of-the-year-2010/
[2] https://meine.doag.org/events/javaland/2025/agenda/#agendaId.5162
[3] https://www.javaland.eu/
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock)
C# 13.0 führt die neue Klasse Lock ein, um Codeblöcke vor dem Zugriff durch weitere Threads zu sperren.
Ab .NET 9.0/C# 13.0 gibt es für das Sperren von Codeblöcken vor dem Zugriff durch weitere Threads die neue Klasse System.Threading.Lock, die man nun im Standard in Verbindung mit dem lock-Statement in C# verwenden sollte, "for best performance" wie Microsoft in der Dokumentation [1] schreibt.
Folgender Code aus der C#-Dokumentation auf Microsoft Learn [2] zeigt ein Beispiel mit dem Schlüsselwort lock und der Klasse System.Threading.Lock:
using System;
using System.Threading.Tasks;
namespace NET9_Console.CS13;
public class Account
{
// Vor .NET 9.0/C# 13.0 wurde hier System.Object verwendet statt
// System.Threading.Lock
private readonly System.Threading.Lock _balanceLock = new();
private decimal _balance;
public Account(decimal initialBalance) => _balance = initialBalance;
public decimal Debit(decimal amount)
{
if (amount < 0)
{
throw new ArgumentOutOfRangeException(nameof(amount), "The debit amount cannot be negative.");
}
decimal appliedAmount = 0;
lock (_balanceLock)
{
if (_balance >= amount)
{
_balance -= amount;
appliedAmount = amount;
}
}
return appliedAmount;
}
public void Credit(decimal amount)
{
if (amount < 0)
{
throw new ArgumentOutOfRangeException(nameof(amount), "The credit amount cannot be negative.");
}
lock (_balanceLock)
{
_balance += amount;
}
}
public decimal GetBalance()
{
lock (_balanceLock)
{
return _balance;
}
}
}
class AccountTest
{
static async Task Main()
{
var account = new Account(1000);
var tasks = new Task[100];
for (int i = 0; i < tasks.Length; i++)
{
tasks[i] = Task.Run(() => Update(account));
}
await Task.WhenAll(tasks);
Console.WriteLine($"Account's balance is {account.GetBalance()}");
// Output:
// Account's balance is 2000
}
static void Update(Account account)
{
decimal[] amounts = [0, 2, -3, 6, -2, -1, 8, -5, 11, -6];
foreach (var amount in amounts)
{
if (amount >= 0)
{
account.Credit(amount);
}
else
{
account.Debit(Math.Abs(amount));
}
}
}
}
Der C#-13.0-Compiler generiert dann aus
lock (_balanceLock)
{
_balance += amount;
}
einen Aufruf der EnterScope()-Methode in der Klasse System.Threading.Lock:
using (balanceLock.EnterScope())
{
_balance += amount;
}
URL dieses Artikels:
https://www.heise.de/-10299439
Links in diesem Artikel:
[1] https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/statements/lock
[2] https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/statements/lock
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: generated by DALL-E)
Die Artikelserie zeigt die internen Mechanismen großer Sprachmodelle von der Texteingabe bis zur Textgenerierung.
Stellen Sie sich eine magische Wissensdatenbank vor, in der Einträge nicht nur statische Sammlungen von Wörtern sind, sondern lebendige Entitäten, die menschliche Texte verstehen und generieren können. Willkommen in der Welt der Large Language Models (LLMs), die die Grenzen der natürlichen Sprachverarbeitung auf verblüffende Weise erweitern. Als Softwareentwickler sind wir gerade dabei, eine faszinierende Reise zu beginnen, die uns durch die inneren Strukturen dieser linguistischen Mechanismen führt. Immerhin haben Large Language Models wie GPT-4, Claude oder Llama die KI-Landschaft in den letzten Jahren revolutioniert.
Fasten your Seat Belts!
Ein Large Language Modell ist eine Art künstliche Intelligenz (KI), die darauf ausgelegt ist, menschliche Sprache zu verarbeiten und zu generieren. Es handelt sich um ein Lernmodell, das tiefschichtige neuronale Netze verwendet, um Muster und Beziehungen innerhalb von Sprachdaten zu lernen. Das "Large" in LLM bezieht sich auf die enorme Menge an Trainingsdaten und die enorme Anzahl an Parametern, die sich als justierbare Knöpfe betrachten lassen und die das Modell verwendet, um Vorhersagen zu treffen.
LLMs basieren auf der Transformer-Architektur, die 2017 in „Attention Is All You Need [4]“ eingeführt wurde. Im Gegensatz zu RNNs oder CNNs nutzt der Transformer Self-Attention-Mechanismen, um Kontextbeziehungen zwischen allen Wörtern in einem Text parallel zu erfassen.
Schlüsselkomponenten des Transformers sind unter anderem:
Klingt alles wie böhmische Dörfer? Ich versuche, die Konzepte näher zu erläutern.
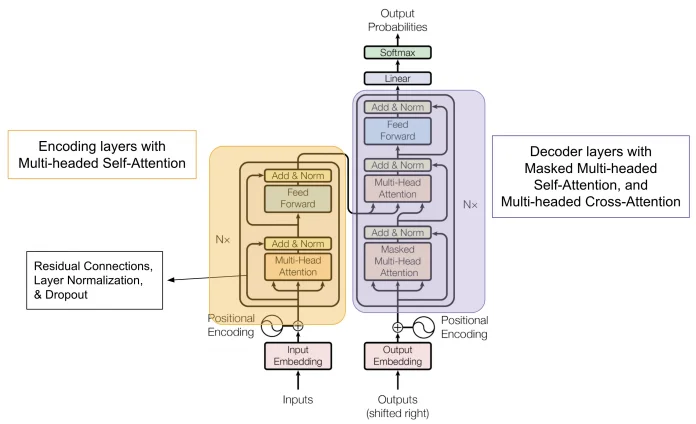
(Bild: Wikipedia)
Ein LLM setzt sich vereinfacht aus den folgenden Komponenten zusammen:
Jedes LLM besteht aus einem Stapel neuronaler Schichten – genau genommen aus Dutzenden bis Hunderten identischer Transformer-Schichten für eine hierarchische Merkmalsverarbeitung:
Beispiel: GPT-3 hat 96 Schichten, LLaMA 2 bis zu 70 Schichten.
Ziel eines Tokenizers ist die Umwandlung von Rohtext in diskrete Einheiten (Token). Dafür gibt es mehrere Methoden:
Beispiel: Der Satz „KI ist faszinierend!“ könnte in Tokens wie `["KI", " ist", " fas", "zin", "ierend", "!"]` zerlegt werden.
Embeddings sind die Grundlage der LLMs, die es dem Modell ermöglichen, Tokens (Wörter, Subwörter oder Zeichen) als numerische Vektoren darzustellen. Jeder Token wird in einen hochdimensionalen Vektor (z. B. 768 oder 4096 Dimensionen) umgewandelt. Diese Vektoren lernt das Modell während des Trainings und erfasst die semantische Bedeutung der Eingabe-Token. Es gibt verschiedene Arten von Embeddings, darunter:
Wichtig an dieser Stelle ist, dass wir Entwickler die Dimensionen nicht selbst definieren. Das macht das Modell beim Training ganz ohne unser Zutun. Eine Dimension könnte etwa Farbe sein, eine andere Länge. Jedenfalls liegen ähnliche Begriffe wie "Kater" und "Katze" in dem mehrdimensionalen Vektorraum ganz nahe beieinander. Begriffe wie "Eiscreme" und "Weltall" liegen hingegen weit auseinander.
Positionelle Codierungen, im Englischen als positional embeddings bezeichnet, spielen eine entscheidende Rolle bei LLMs, indem sie die Reihenfolge der Eingabe-Token erhalten. LLMs zerlegen den Eingabetext in eine Folge von Token und wandeln jedes Token in eine numerische Darstellung um. Allerdings geht bei dieser Umwandlung die Reihenfolge der Token verloren, die für das Verständnis des Kontexts und der Beziehungen zwischen Token essenziell ist. Um dieses Problem zu lösen, führt man positionelle Codierungen zu den embedded Token hinzu, um sich die Reihenfolge der Token zu merken. Das LLM lernt die positionellen Codierungen während des Trainings. Sie dienen dazu, die Position jedes Tokens in der Sequenz zu codieren. Dies ermöglicht es dem Modell, die Beziehungen zwischen Token und ihrer Position in der Sequenz zu verstehen.
Es gibt verschiedene Arten positioneller Codierungen:
Feed-Forward-Layer (vollständig verbundene Layer) sind die Arbeitstiere der LLMs. Sie nehmen die Embeddings als Eingabe und generieren eine kontinuierliche Darstellung des Eingabetextes. Feed-Forward-Layer bestehen aus:
In Sätzen wie „Der Hund jagte die verschlagene Katze durch das ganze Haus. Sie konnte sich aber rechtzeitig verstecken“ kommen verschiedene Wörter vor, von denen jedes einzelne nicht einfach isoliert im Raum steht. Im ersten Satz bezieht sich „Hund“ unter anderem auf eine Tätigkeit „jagte“ und die gejagte „Katze“. Uns liegen also starke Verbindungen des Wortes „Hund“ zu zwei weiteren Wörtern im selben Satz vor. Jedes dieser Wortpaare definiert die Beziehung eines Wortes im Satz zu einem anderen. Diese Verbindungen können stärker oder schwächer sein. Ein LLM berechnet die Beziehungen für jedes Wort im Satz zu jedem anderen Wort im Satz. Das nennt sich Self-Attention. Sie bezeichnet, wie stark sich Token gegenseitig „beachten“.
Weil das LLM parallel an mehreren Stellen eines Textes die entsprechenden Attentions erstellt, haben wir es mit Multi-Head-Attentions zu tun. Ohne ausreichenden Weitblick gehen einem LLM allerdings wichtige satzübergreifende Beziehungen verloren. Würden LLMs also Text in Sätze zerlegen und jeden Satz für sich bearbeiten, ginge im zweiten Satz verloren, dass sich das „Sie“ auf „Katze“ im ersten Satz bezieht. Cross-Attention dient dazu, um Attention/Beziehungen auch über einen größeren Kontext festzustellen. Wichtig dabei ist: LLMs sind in der Größe des betrachteten Kontexts beschränkt. Je größer der Kontext, desto größer der benötigte Arbeitsspeicher. Die Kontextgrößen reichen von wenigen Kilobytes (ein paar Schreibmaschinenseiten) bis zu mehreren Megabytes (ganze Buchinhalte). Wenn das LLM bereits zu viel Kontextinformation gemerkt hat und der Speicher "überläuft", beginnt es vorangegangenen Kontext zu "vergessen".
Self-Attention ist ein Mechanismus, der es dem Modell ermöglicht, auf verschiedene Teile des Eingabetextes zu achten und eine kontextualisierte Darstellung zu generieren. Zu welchem anderen Wort hat das gerade betrachtete Wort die größte Beziehung (Attention).
Multi-Head-Attention ist ein Mechanismus, der es dem Modell ermöglicht, auf verschiedene Teile des Eingabetextes von geschiedenen Perspektiven gleichzeitig zu achten. Statt einer einzigen Attention-Operation verwendet der Transformer mehrere „Heads“: Heads erfassen unterschiedliche Beziehungen (z. B. Syntax vs. Semantik). Die Outputs der Heads werden konkateniert und linear projiziert.
Vorteil: Das Modell lernt gleichzeitig diversifizierte Kontextabhängigkeiten.
Cross-Attention ist ein Mechanismus, der es dem Modell ermöglicht, über weitere Entfernung von Tokens auf externe Informationen zu achten wie den Eingabetext (Prompt) oder andere Modelle. Das hat insbesondere auch für den Übergang von der Encoder- zur Decoder-Schicht eine Bedeutung.
Das erreicht das Modell durch die folgenden Schritte:
Nach der grundlegenden Übersicht zu LLMs geht es im nächsten Beitrag um die Hardwareanforderungen und unterschiedliche pretrained Models.
URL dieses Artikels:
https://www.heise.de/-10283768
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[4] https://arxiv.org/abs/1706.03762
[5] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: tomertu/Shutterstock.com)
Wer Software entwickelt, muss die zugrunde liegende Fachlichkeit verstehen. Dabei hilft eine geeignete Modellierung der Fachdomäne.
75 Prozent aller Softwareprojekte scheitern! Dazu habe ich im vergangenen Oktober bereits einen Beitrag geschrieben [1]. Darin habe ich auch ein essenzielles und grundlegendes Problem angesprochen: Viele Softwareprojekte scheitern nämlich nicht an der Technik, sondern viel eher an einem fehlenden Verständnis der zugrunde liegenden Fachlichkeit. Denn es kommt äußerst selten vor, dass Entwicklerinnen und Entwickler sowie Fachexpertinnen und Fachexperten die gleiche Sprache sprechen. Allerdings ist damit nicht eine natürliche Sprache wie Deutsch, Englisch oder Französisch gemeint, sondern vielmehr das Fehlen einer gemeinsamen Fachsprache (und letztlich eines gemeinsamen Verständnisses, worum es bei der zu entwickelnden Software inhaltlich überhaupt geht).
Dass dies zu impliziten Annahmen, zu Missverständnissen und zu fehlerhaften Interpretationen führt, haben wir in dem erwähnten Video ausführlich erläutert. Das bedeutet letztlich nichts anderes, als dass Entwicklerinnen und Entwickler eine Software immer so bauen, wie sie diese verstehen – und nicht unbedingt so, wie das Business die Software benötigt. Folglich stellt sich die Frage, was man dagegen unternehmen kann: Eine mögliche Antwort ist eine wirklich gute Modellierung der Fachlichkeit. Wie eine solche Modellierung entwickelt wird, das erläutere ich Ihnen heute in diesem Blogpost.
Als allererstes sollte man zunächst verstehen, wo das Problem der fehlenden gemeinsamen Sprache und des fehlenden gemeinsamen Verständnisses überhaupt herkommt. Denn eigentlich sollte man meinen, dass es nicht so übermäßig schwierig sein kann, miteinander zu sprechen. Das Problem ist jedoch, dass hier unterschiedliche Welten aufeinandertreffen, die beide nie gelernt haben, mit der jeweils anderen Disziplin zu kommunizieren:
Das Problem lautet jedoch: Wie entwickeln Sie eine Software, die ein fachliches Problem lösen soll, wenn das fachliche Problem gar nicht verstanden wurde? Ganz einfach: Das funktioniert nicht.
Das Erschreckende ist jedoch, dass zu viele Teams und Unternehmen dies einfach ignorieren oder, was ich persönlich noch viel schlimmer finde, dass ihnen diese Diskrepanz nicht einmal bewusst ist. Da wird dann wochen- oder monatelang diskutiert, ob man Programmiersprache X oder doch lieber Framework Y einsetzen sollte, aber niemand kommt auf den Gedanken, sich einmal gezielt mit der Fachlichkeit auseinanderzusetzen.
Dann wird irgendwann drauflos entwickelt, und das geht ein paar Monate oder vielleicht auch ein oder zwei Jahre gut, aber schließlich erkennt man über kurz oder lang, dass die Software nicht genau das tut, was ursprünglich einmal gewünscht war. Und dann muss nachgebessert werden: Alles dauert auf einmal länger, alles wird teurer, und selbstverständlich ist das Fundament (weil falsche Annahmen getroffen wurden) in eine völlig unpassende Richtung entwickelt worden, sodass die Anpassungen jetzt nur sehr umständlich und damit auch wieder äußerst kostspielig möglich sind.
Mit hoher Wahrscheinlichkeit kommt dann jemand um die Ecke und behauptet:
"Ich hab’s Euch ja von vornherein gesagt: Hätten wir nicht auf Technologie X, sondern auf Technologie Y gesetzt, dann hätten wir das Problem jetzt nicht!"
Der Punkt ist jedoch: Das Problem wäre genauso vorhanden, nur auf einer anderen technologischen Basis. Denn das ist der springende Punkt: In den seltensten Fällen ist die Technologie an sich das Problem (womit ich nicht sagen möchte, dass es nicht bessere und schlechtere Technologieentscheidungen gäbe, in der Regel wird nur der Einfluss der Technologiewahl auf den Erfolg eines Projekts massiv überschätzt).
Das bedeutet: Wenn Sie sicherstellen möchten, dass Sie eine zum zugrunde liegenden fachlichen Problem passende Software entwickeln, und das sogar noch zielgerichtet, funktioniert es letztlich nur, wenn Sie von Anfang an verstehen, worum es aus fachlicher Sicht überhaupt geht. Das mag trivial erscheinen – die Praxis sieht leider allzu oft anders aus.
Oft steht uns Entwicklerinnen und Entwicklern nämlich etwas im Weg, das wir leider von klein auf beigebracht bekommen haben: Das Denken in Datenbanktabellen. Wir alle haben in unserer Ausbildung oder in unserem Studium gelernt, Daten in relationalen Strukturen abzulegen. Um mit diesen Strukturen zu arbeiten, kennen wir vier Verben, nämlich Create, Read, Update und Delete, häufig abgekürzt als CRUD. Wir haben gelernt, dass wir damit de facto alles modellieren können, und aus technischer Sicht ist das auch durchaus korrekt.
Aber das ändert selbstverständlich nichts daran, dass es sich bei diesen Wörtern um die Fachsprache der Datenbank handelt. Create, Read, Update und Delete sind nämlich rein technische Begriffe, die von Datenbanken genutzt werden. Da wir häufig mit Code zu tun haben, der auf Datenbanken zugreift, sind wir dazu übergegangen, diese vier Verben auch in unserem Code zu verwenden: So entstehen dann Funktionen mit Namen wie beispielsweise UpdateBook.
Aus technischer Sicht mag das sogar durchaus passend sein, wenn diese Funktion den Datensatz für ein Buch in der Datenbank aktualisiert. Das Problem besteht jedoch darin, dass dies nicht den fachlichen Use Case widerspiegelt. Denn warum wird das Buch beziehungsweise dessen Datensatz aktualisiert? Diese Information liefert der Funktionsname leider nicht. Das Problem ist außerdem, dass sich hinter diesem Update alles Mögliche verbergen kann. Ich bin mir sicher, dass wenn Sie an dieser Stelle kurz innehalten und sich überlegen, wie viele Gründe Ihnen spontan einfallen, warum man ein Buch aktualisieren können sollte, Sie keine Schwierigkeit haben, rasch auf zehn oder zwanzig unterschiedliche Gründe zu kommen.
Ich bin mir außerdem sicher, dass Sie – je nachdem, für welche Fachlichkeit Sie sich entscheiden – die Anwendung durchaus unterschiedlich entwickeln würden: Ein System zum Verwalten der ausgeliehenen Bücher in einer Bibliothek unterscheidet sich klar von einem System für einen großen Onlineshop, und beide sind wiederum etwas ganz anderes als ein System, das Autorinnen und Autoren beim Schreiben von Romanen unterstützen soll.
In allen drei Fällen kann es notwendig sein, ein Buch früher oder später zu aktualisieren, doch der gesamte Workflow darum ist jeweils ein völlig anderer, und abhängig davon würden vermutlich einige Dinge auch unterschiedlich gehandhabt. Ohne vertiefte Kenntnisse des umgebenden Prozesses ist es daher schwierig, Code zu schreiben, der das Richtige tut, und es greift zu kurz, einfach nur UpdateBook umzusetzen.
Langer Rede, kurzer Sinn: Wenn wir ohne die Prozesse zu kennen den Code für die Anwendung nicht adäquat und zielgerichtet schreiben können, sollten wir dann nicht vielleicht versuchen, diese Prozesse zunächst besser zu verstehen? Zu verstehen, worum es bei der gesamten Thematik überhaupt geht? Wer etwas macht? Was diese Person macht? Warum sie das macht? Wann und wie oft sie es macht? Welchen Zweck das Ganze hat? Welche Konsequenzen es nach sich zieht? Und so weiter.
Falls Sie jetzt denken:
"Stimmt, das wäre sinnvoll!"
Dann müssten wir als Nächstes überlegen, wie man Prozesse angemessen beschreiben kann. Eines kann ich Ihnen schon vorab verraten: Die Begriffe Create, Read, Update und Delete sind dabei ziemlich fehl am Platz. Tatsächlich ist die Denkweise in diesen vier Verben sogar ein Antipattern [3].
Doch wenn wir CRUD nicht verwenden können, um fachliche Prozesse zu beschreiben, was machen wir dann stattdessen? Benötigt wird dafür eine Methode, um Geschäftsprozesse als das darzustellen, was sie wirklich sind – nämlich eine Abfolge von Ereignissen. Stellen Sie sich vor, Sie kommen abends nach Hause und Ihre Partnerin oder Ihr Partner fragt, wie Ihr Tag war, woraufhin Sie erzählen, dass zuerst dieses und dann jenes geschehen sei. Sie berichten von Ereignissen, die Sie im Laufe des Tages erlebt haben – und genau das geschieht auch in einem Geschäftsprozess.
Nehmen wir als Beispiel die vorhin bereits kurz erwähnte Bibliothek. Wir können überlegen, welche Prozesse dort überhaupt auftreten: Welche Aktionen finden aus fachlicher Sicht in einer Bibliothek statt?
Man erkennt rasch, dass einer der wichtigsten Vorgänge darin besteht, dorthin zu gehen, um ein Buch zu leihen. Geliehene Bücher müssen über kurz oder lang natürlich auch wieder zurückgegeben werden, doch die Ausleihe kann verlängert werden, sofern niemand anderes das Buch vorbestellt hat. Wer zu spät mit der Rückgabe ist, muss möglicherweise eine Strafe zahlen, und die Bibliothek nimmt regelmäßig neue Bücher in den Bestand auf und entfernt alte, die nicht mehr in gutem Zustand sind.
Hier bemerken Sie bereits, wie reichhaltig die Sprache an dieser Stelle ist und wie viele Verben wir dabei verwenden: Ausleihen, zurückgeben, verlängern, vorbestellen, bezahlen, aufnehmen, entfernen und so weiter.
Vielleicht denken Sie jetzt, es sei doch logisch, auf diese Weise darüber zu sprechen, und im Grunde stimmt das auch. Doch warum findet man dann im Code höchstwahrscheinlich nur eine technisch benannte Funktion (nämlich UpdateBook) und nicht fachlich benannte Funktionen, etwa BorrowBook, RenewBook und ReturnBook?
Das ist eine berechtigte Frage, denn hätten wir diese Funktionen, könnten sie intern selbstverständlich immer noch ein Update oder eine andere Datenbankoperation ausführen, doch unser Code würde plötzlich eine fachliche Geschichte erzählen. Es wäre sehr viel einfacher, im Gespräch mit einer Fachexpertin oder einem Fachexperten nachzuvollziehen, was gemeint ist, weil sich die verwendeten Begriffe auch im Code wiederfinden würden.
Und das möglicherweise nicht nur im Code, sondern sogar auch in der API und in der UI. Wie viel besser könnte ein System gestaltet sein, wenn es auf diesen Begriffen basieren würde, anstatt stets nur von UpdateBook zu sprechen? Wie viel besser könnte eine UI sein? Wie viel effektiver könnte man Anwenderinnen und Anwender in ihrer Intention abholen und unterstützen?
An dieser Stelle kommen wir zum entscheidenden Punkt: Wenn wir zu der Erkenntnis gelangen, dass es besser ist, in unserem Code, in der API, in der UI und auch überall sonst mit fachlichen Begriffen zu arbeiten, anstatt mit technischen, warum modellieren wir dann nicht einfach die fachlichen Ereignisse so, wie sie wirklich stattfinden?
Was in der Realität geschieht, sind nämlich keine Updates, sondern Ereignisse, die wir in der Software nachbilden möchten. Genau aus diesem Grund sollten wir nicht nur in fachlichen Funktionen denken, sondern auch in fachlichen Events. Wenn wir unsere Software so gestalten, dass sie von echten Events angetrieben wird, verfügen wir nämlich plötzlich über eine Architektur und eine Codebasis, die die Realität widerspiegeln, anstatt nur ein unzureichendes technisches Abbild zu sein, das eine sprachliche Kluft und viel Raum für Missverständnisse und Interpretationen hinterlässt.
Genau an dieser Stelle setzt die Event-Modellierung an. Wenn wir akzeptieren, dass unsere Software die fachliche Realität widerspiegeln sollte und dass Events dafür das Mittel der Wahl sind, müssen wir uns zwangsläufig fragen: Wie finden wir die richtigen Events? Welche Ereignisse sind tatsächlich relevant? Welche beschreiben eine Veränderung? Auf welche Weise schneide ich meine Events so, dass sie fachlich sinnvoll sind?
Deshalb möchte ich das Ganze nun anhand eines konkreten Beispiels erläutern, nämlich an unserer bereits bekannten Stadtbibliothek.
Bevor Sie dort überhaupt etwas leihen dürfen, benötigen Sie zunächst einen Ausweis, eine sogenannte Library Card. Viele Entwicklerinnen und Entwickler würden vermutlich damit beginnen, dass man eine Library Card erstellen muss, also mit CreateLibraryCard – und schon befindet man sich wieder in der Denkweise von Create, Read, Update und Delete. Auch wenn das technisch später vielleicht korrekt sein mag, geht es zunächst doch darum, den Prozess aus fachlicher Sicht zu beschreiben.
Niemand würde eine Bibliothek betreten und sagen:
"Created mir bitte einen Bibliotheksausweis!"
Stattdessen würde man wohl fragen, wie ein solcher Ausweis beantragt werden kann. Genau dies ist der erste Schritt unseres Prozesses. Die Frage lautet also: Welcher Begriff trifft das Ganze fachlich am besten? Die Formulierung "Ausweis beantragen" passt aus meiner Sicht schon recht gut. Allerdings ist "Ausweis beantragen" noch kein Event. Es müsste nämlich in der Vergangenheitsform stehen, also "Ausweis wurde beantragt".
Das ergibt Sinn, denn wenn Sie sich vorstellen, abends nach Hause zu kommen und gefragt zu werden, wie Ihr Tag war, würden Sie ebenfalls in der Vergangenheitsform erzählen. Bei Bedarf lässt sich das Ganze dann schlussendlich noch ins Englische übertragen, was dann einem "Applied for a Library Card"-Event entsprechen würde.
Als Nächstes würde der Ausweis vermutlich ausgestellt. Vielleicht denken Sie jetzt:
"Alles klar, dann haben wir aber jetzt ein Create."
In der Vergangenheitsform wäre das ein "Library Card Created"-Event. Rein sprachlich wäre das korrekt, allerdings hatte ich erwähnt, dass der Ausweis ausgestellt wird. Einen Ausweis auszustellen bedeutet jedoch nicht "Create a Library Card", sondern eher "Issue a Library Card". Daher hätten wir also eher ein "Library Card Issued"-Event.
Vielleicht wenden Sie nun ein, dass das letztlich Wortklauberei sei. Ob nun create oder issue – das sei doch egal, man wisse schließlich, was gemeint ist. Der springende Punkt ist jedoch: Das weiß man eben gerade leider nicht. Wir hatten gerade selbst die Situation, dass wir zwei verschiedene Ereignisse – nämlich das Beantragen und das Ausstellen des Ausweises – zunächst beide als create bezeichnen wollten. Hätten wir das getan, hätten wir nun bereits zwei Prozessschritte, die wir sprachlich nicht voneinander unterscheiden könnten.
Indem wir versuchen, fachlich passende und semantisch ausdrucksstarke Wörter zu finden, präzisieren wir unsere Sprache. Wir erhalten dadurch nicht nur ein genaueres Verständnis darüber, worum es fachlich geht, sondern nähern uns sprachlich auch der Fachabteilung an. Genau diese Kombination führt dazu, dass wir besser miteinander kommunizieren, Wünsche und Anforderungen besser verstehen und auf diese Weise letztlich in der Lage sind, bessere Software in kürzerer Zeit zu entwickeln.
Wie viel hilfreicher ist nämlich bitte die Frage:
"Okay, wir haben jetzt implementiert, dass man Ausweise beantragen kann und dass diese anschließend ausgestellt werden können, was ist der nächste Schritt?"
im Vergleich zu der Aussage:
"Wir haben jetzt CreateAusweis implementiert, wir machen dann als Nächstes UpdateAusweis.“
Ersteres bietet eine hervorragende Basis für ein zielgerichtetes Gespräch mit einer fachkundigen Person, während Letzteres eine vage, technische Äußerung darstellt, die kaum etwas aussagt und wahrscheinlich jede weitere Kommunikation verhindert.
Dieses Prinzip, sprachlich präzise zu sein und fachliche statt technischer Begriffe zu verwenden, sollten wir konsequent fortführen: Ein Bibliotheksausweis allein bringt noch nicht viel, er bildet lediglich die Voraussetzung dafür, dass wir überhaupt Bücher ausleihen dürfen. Und genau das wäre vermutlich der nächste Schritt im Prozess: Ein Buch auszuleihen.
Nun stellt sich erneut die Frage, wie dieses Event genannt werden sollte. Sprechen wir einfach von einem BookBorrowed-Event? Oder existieren möglicherweise Unterschiede? Wird ein Buch beispielsweise sofort ausgeliehen, oder muss es erst reserviert werden, um es später abzuholen? Welche Bedingungen müssen erfüllt sein, damit die Ausleihe tatsächlich stattfindet? All das sind Überlegungen, die wir nur anstellen, wenn wir sprachlich präzise bleiben und uns eng an der Fachsprache orientieren, da uns genau das dazu zwingt, uns inhaltlich mit der Fachlichkeit auseinanderzusetzen. Dies ist gut. Auf diese Weise entstehen nach und nach die verschiedenen Events, die in der jeweiligen Fachdomäne eine Rolle spielen.
Ein weiterer Vorteil besteht darin, dass sich dies wunderbar gemeinsam umsetzen lässt: Die Entwicklungsabteilung und die Fachabteilung kommen zusammen, sodass ein Gespräch entsteht und beide in eine gemeinsame Richtung arbeiten. Es handelt sich nicht um ein Gegeneinander (wie es sonst so häufig der Fall ist), sondern um ein Miteinander. Die Fachabteilung hat schließlich ein Interesse daran, dass die Entwicklung versteht, worum es geht, denn nur dann kann sie eine adäquate und zielgerichtete Software erstellen. Dies gilt selbstverständlich auch in umgekehrter Richtung. Genau diese Herangehensweise – die Fachlichkeit in den Vordergrund zu rücken – macht das Prinzip so mächtig.
Vielleicht fragen Sie sich jetzt, ob es dafür nicht bereits einige fertige Workshop-Formate gibt. Tatsächlich existiert eine ganze Reihe, etwa Event Storming, Event Modeling oder Domain Storytelling. Diese Formate verfolgen jeweils einen etwas anderen Ansatz: Domain Storytelling eignet sich beispielsweise sehr gut dafür, überhaupt erst einmal einen Fuß in eine Fachdomäne zu setzen, während Event Storming und Event Modeling sehr in die Tiefe gehen und teils auch technische Details beleuchten.
Deshalb würde ich zumindest anfangs zu Domain Storytelling raten: Es ist zum Glück leicht zu erlernen, und es gibt ein interessantes Buch zu diesem Thema [4].
Letztlich spielt es jedoch keine große Rolle, welche dieser Methoden Sie verwenden oder ob Sie überhaupt eine davon nutzen. Wichtig ist nur, dass Sie eine gemeinsame Basis schaffen – mit einer gemeinsamen Sprache und einem gemeinsamen Verständnis. Der Weg dorthin ist letztlich zweitrangig. Nehmen Sie daher einfach das, was Ihnen am ehesten zusagt. Wählen Sie das, womit Sie sich wohlfühlen. Entscheiden Sie sich für das, wo Sie möglicherweise schon jemanden kennen oder finden, der Sie dabei unterstützt und den Prozess anleitet oder moderiert.
Vielleicht fragen Sie sich zum Schluss noch, warum Sie das alles speziell in dieser Event-Form gestalten sollten. Man könnte anstelle von "Ausweis wurde beantragt", "Ausweis wurde ausgestellt", "Buch wurde ausgeliehen" und so weiter ebenso gut Formulierungen im Indikativ verwenden, also in der Grundform, beispielsweise "Ausweis beantragen", "Ausweis ausstellen", "Buch ausleihen" und so weiter.
Die fachlichen Verben wären dort schließlich ebenfalls enthalten. Das ist im Grundsatz richtig, aber es gibt gewissermaßen noch einen Bonus, wenn Sie die Event-Form verwenden. Es ist sozusagen die sprichwörtliche Kirsche auf der Torte. Sobald Sie diese geschäftlichen Ereignisse in der Event-Form ausdrücken, erhalten Sie die ideale Ausgangsbasis, um die Events in einem geeigneten Protokoll zu speichern, ähnlich einem Logbuch.
Dies wiederum bietet eine Vielzahl von Vorteilen von einer deutlich besseren Transparenz darüber, was wann und warum von wem durchgeführt wurde, über ein integriertes Audit-Log bis hin zu sehr flexiblen Möglichkeiten für Analysen und Reports. Das kann man sich leicht vorstellen: Wenn Sie nur wissen, dass ein Buch gerade ausgeliehen ist, kennen Sie diesen Zustand, aber sonst nichts. Wenn Sie jedoch die komplette Historie kennen, die im Laufe der Zeit zum aktuellen Status quo geführt hat, können Sie unzählige Fragen beantworten, auch wenn Ihnen zuvor nicht klar war, dass diese Informationen später von Interesse sein würden. Dazu zählen Fragen wie:
Diese Art der Datenspeicherung nennt man Event Sourcing, und dazu habe ich vor einigen Wochen bereits einen Beitrag geschrieben [5]. Der Vorteil daran ist, dass Sie gleich drei Fliegen mit einer Klappe schlagen, wenn Sie fachliche Prozesse konsequent als Events formulieren:
Übrigens war ich vor ungefähr zehn Tagen in einem sehr interessanten Podcast zu Gast – dem Engineering Kiosk [7] –, wo wir uns eineinhalb Stunden lang ausführlich über das Zusammenspiel all dieser Themen unterhalten haben. Wenn Sie das interessiert, schauen oder hören Sie dort gerne einmal vorbei.
URL dieses Artikels:
https://www.heise.de/-10292363
Links in diesem Artikel:
[1] https://www.heise.de/blog/75-Prozent-aller-Softwareprojekt-scheitern-was-tun-9979648.html
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=MoWynuslbBY
[4] https://www.youtube.com/watch?v=EaKWQ1rsaqQ
[5] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[6] https://www.youtube.com/watch?v=hP-2ojGfd-Q
[7] https://engineeringkiosk.dev/podcast/episode/183-event-sourcing-die-intelligente-datenarchitektur-mit-semantischer-historie-mit-golo-roden/
[8] mailto:rme@ix.de
Copyright © 2025 Heise Medien
In this release, we have restarted to focus on features. A long-awaited feature has been added, namely sorting articles by various criteria: received date (existing, default), publication date, title, link, random.
A few highlights ✨:
&get=A, and also those archived with &get=Z
This release has been made by @Alkarex, @b-reich, @hkcomori, @math-GH, @UserRoot-Luca
and newcomers @a6software, @aftix, @bl00dy1837, @brtmax, @Roan-V, @ShaddyDC, @UncleArya
Full changelog:
&get=A, and also those archived with &get=Z #7144
intext: #7228force-https.txt #7259
(Bild: Pincasso/Shutterstock)
Man kann in C# 13.0 neuerdings auch mit dem Index vom Ende ein Array initialisieren.
Bisher schon konnte eine Initialisierung von Mengen wie Arrays mit Indexer × = y erfolgen. In C# 13.0 ist eine Array-Initialisierung auch mit Index vom Ende [^x] = y möglich mit dem Index-Operator ^, den es seit C# 8.0 gibt.
Die neue Syntax ist allerdings nur bei der Erstinitialisierung des Objekts möglich, nicht bei anderen Zuweisungen.
Folgendes Codebeispiel zeigt die Objektmengen-Initialisierung mit Index von vorne × und vom Ende [^x]:
namespace NET9_Console.CS13;
internal class CS13_Indexer
{
class ZahlenGenerator
{
public string[] Ziffern = new string[10];
}
/// <summary>
/// C# 13.0: Objekt-Initialisierung mit Index vom Ende [^x] ("Implicit Indexer Access in Object Initializers")
/// </summary>
public void Run()
{
CUI.Demo(nameof(CS13_Indexer));
CUI.H2("Array-Initialisierung mit Indexer von vorne nach hinten");
var dAlt = new ZahlenGenerator()
{
Ziffern = {
[0] = "null",
[1] = "eins",
[2] = "zwei",
[3] = "drei",
[4] = "vier",
[5] = "fünf",
[6] = "sechs",
[7] = "sieben",
[8] = "acht",
[9] = "neun",
}
};
foreach (var z in dAlt.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Initialisierung mit Indexer von hinten nach vorne");
var dNeu = new ZahlenGenerator()
{
Ziffern = {
[^1] = "neun",
[^2] = "acht",
[^3] = "sieben",
[^4] = "sechs",
[^5] = "fünf",
[^6] = "vier",
[^7] = "drei",
[^8] = "zwei",
[^9] = "eins",
[^10] = "null"
}
};
foreach (var z in dNeu.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Initialisierung mit Indexer in beide Richtungen");
var dNeu2 = new ZahlenGenerator()
{
Ziffern = {
[^1] = "neun",
[^2] = "acht",
[^3] = "sieben",
[^4] = "sechs",
[^5] = "fünf",
[4] = "vier",
[3] = "drei",
[2] = "zwei",
[1] = "eins",
[0] = "null"
}
};
foreach (var z in dNeu2.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Befüllung zu einem späteren Zeitpunkt");
// erstelle ein Array von int mit 10 Elementen
int[] array1 = new int[10] { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
// das geht nicht, Syntax nur bei Objektinitialisierung im Rahmen der Instanziierung erlaubt
//array1 = {
// [^1] = 9,
// [^2] = 8,
// [^3] = 7,
// [^4] = 6,
// [^5] = 5,
// [0] = 0,
// [1] = 1,
// [2] = 2,
// [3] = 3,
// [4] = 4
// }
// hier geht nur das:
array1[^1] = 9;
array1[^2] = 8;
array1[^3] = 7;
array1[^4] = 6;
array1[^5] = 5;
array1[0] = 0;
array1[1] = 1;
array1[2] = 2;
array1[3] = 3;
array1[4] = 4;
foreach (var item in array1)
{
CUI.LI(item);
}
}
}
URL dieses Artikels:
https://www.heise.de/-10290670
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien