
Blick unter die Motorhaube
(Bild: generated by DALL-E)
Die Artikelserie zeigt die internen Mechanismen großer Sprachmodelle von der Texteingabe bis zur Textgenerierung.
Ein Large Language Modell (LLM) ist darauf ausgelegt, menschliche Sprache zu verarbeiten und zu generieren. Nach der grundlegenden Einführung von LLMs im ersten [1] und den Hardwareanforderungen und vorabtrainierten Modellen im zweiten Teil [2] geht es diesmal um unterschiedliche Architekturtypen.
Fasten your seat belts!
Ein häufiges Missverständnis der Transformer-Architektur besteht darin, dass LLMs notwendig alle Teile dieser Architektur enthalten müssen. Das ist nicht der Fall. Stattdessen lassen sich in der Praxis die folgenden Architekturtypen unterscheiden:
Sequence-to-Sequence-Modelle (Seq-to-Seq) sind darauf ausgelegt, eine Eingabesequenz wie einen Satz auf eine Ausgabesequenz wie eine Übersetzung oder Antwort abzubilden. Sie implementieren die Transformer-Architektur und bestehen infolgedessen aus:
Seq-to-Seq-Modelle werden häufig für Aufgaben wie maschinelle Übersetzung, Textzusammenfassung und Textgenerierung eingesetzt. Beispiele sind das ursprüngliche Transformer-Modell von Google und T5 (Text-to-Text Transfer Transformer).
Decoder-Only-Modelle: Modelle wie GPT (Generative Pre-trained Transformer) verwenden eine reine Decoder-Architektur. Sie sind darauf trainiert, das nächste Token in einer Sequenz vorherzusagen, was sie besonders effektiv für Textgenerierung und -vervollständigung macht. Diese Modelle glänzen bei offenen Aufgaben, besitzen jedoch kein bidirektionales Kontextverständnis.
Encoder-Only-Modelle: BERT (Bidirectional Encoder Representations from Transformers) ist ein Beispiel für ein reines Encoder-Modell. Es verarbeitet Eingabetext bidirektional und erfasst Kontext sowohl aus vorangehenden als auch nachfolgenden Token. BERT eignet sich ideal für Aufgaben wie Sentimentanalyse, Named-Entity Recognition und Frage-Antwort-Systeme, kann aber keinen Text direkt generieren.
Wer Sentimentanalyse nicht kennt: Hier soll das Modell die Grundstimmung wie positiv oder negativ eines Satzes analysieren. Zum Beispiel enthält "Ich finde diesen Artikel gut." eine positive Aussage.
Hybride Architekturen: Einige Modelle wie T5 kombinieren Encoder-Decoder-Architekturen für einen einheitlichen Ansatz. T5 behandelt jede NLP-Aufgabe als ein Text-zu-Text-Problem, bei dem sowohl Eingabe als auch Ausgabe Textsequenzen sind. Diese Flexibilität macht es für vielfältige Aufgaben wie Übersetzung, Zusammenfassung und Klassifizierung geeignet.
Um LLMs zu trainieren, braucht es zunächst Daten und davon eine ganze Menge mit ausreichender Qualität. Das Training erfolgt in drei Schritten.
Das Training optimiert die gewählten Gewichte, bis die Verlustfunktion nur noch verschwindend kleine Vorhersagefehler (die Minima der Verlustfunktion) zurückmeldet.
Zur Optimierung gibt es unterschiedliche Stellgrößen und Verfahren:
Um das Training zu verbessern, hat es sich darüber hinaus als empfehlenswert herausgestellt, mit Dropouts zu arbeiten. Dropouts definieren für eine neuronale Schicht bzw. für ein neuronales Netzwerk, dass ein gewisser Prozentsatz zufällig ausgewählter Neuronen in einer Trainingsiteration inaktiv bleiben soll. Dadurch erhöht sich erfahrungsgemäß die Robustheit des Verfahrens.
In großen Sprachmodellen (LLMs) wie GPT, BERT oder T5 ist eine Residual Connection (manchmal auch Skip Connection) ein zentrales Element der Transformer-Architektur. Sie stabilisiert das Training und ermöglicht es dem Modell, effektiv über Dutzende oder Hunderte von Schichten hinweg zu lernen. Ohne Residual Connections wären moderne LLMs kaum effektiv trainierbar, insbesondere in großem Maßstab. Sie sind grundlegend für das "Deep" in Deep Learning bei Sprachmodellen!
Wie Residual Connections funktionieren:
Residual Connections sind somit aus folgenden Gründen in LLMs wichtig:
Wichtige LLMs mit Residual Connections beinhalten unter anderem:
Der Einsatz trainierter LLMs geschieht über Chatbots der Hersteller, über APIs oder für lokal verfügbare Modelle über Werkzeuge wie Ollama und llama.cpp.
In der sogenannten autoregressiven Decodierung erzeugt das Modell Schritt für Schritt neue Token:
Die genutzten Sampling-Strategien (= Tokenauswahlstrategien) umfassen dabei verschiedene Optionen:
Der vom Nutzer beeinflussbare Parameter Temperatur kontrolliert die Zufälligkeit (hohe Temperatur kreativ, niedrige konservativ) der gewählten Token.
Zu beachten sind dabei Skalierungsgesetze und Modellgrößen wie:
Normalsterbliche Nutzer von LLMs können natürlich mangels ausreichender finanzieller Mittel und Hardware keine eigenen LLMs trainieren, zumindest nicht große Frontier-Modelle wie die von OpenAI, Claude, Cohere, Meta, Google und Microsoft. Allerdings ist es möglich, die Gewichte eines Open-Source- oder Open-Weight-Modells finezutunen. Open-Weights-Modelle liefern zwar die Gewichte mit, aber im Gegensatz zu Open-Source-Modellen nicht die zum Training verwendeten Daten oder Workflows. In beiden Fällen ist es aber möglich, die meisten Gewichte des trainierten Modells einzufrieren, um danach mit eigenen Trainingsdaten die nicht eingefrorenen Gewichte zu trainieren. Das nennt man Transfer-Learning. Dazu gibt es verschiedene Werkzeuge für macOS (z. B. MLX), Linux und Windows (z. B. Unsloth). Vorteil dieses eher leichtgewichtigen Ansatzes ist der geringere Hardwarebedarf und Zeitaufwand, um LLMs mit neuen domänenspezifischen Daten anzureichern. Das ist bei kleineren Modellen auch für den "Heimgebrauch" machbar.

(Bild: Wikipedia [7])
Da Modelle immer nur die aktuellen Daten zum Zeitpunkt ihres Trainings beinhalten und meistens eine sehr breite Zahl von Domänen antrainiert bekommen, gibt es mehrere Möglichkeiten, nachträglich tagesaktuelle Daten oder domänenspezifische Daten auf Umwegen ins Modell "einzuschleusen":
RAG (Retrieval Augmented Generation): Die Benutzerin nutzt ein passendes LLM-Modell. Zusätzlich verwendet sie eine Vektordatenbank. In dieser speichert sie Embeddings. Die Generierung der Embeddings erfolgt mit Hilfe vorliegender Dokumente, die die Anwendung zunächst in Teile (Chunks) zerlegt, die Teile anschließend in Embeddings (Vektoren) umwandelt und dann in der Vektordatenbank speichert. Falls eine Benutzeranfrage eintrifft, sucht die Anwendung zunächst in der Datenbank nach zum Eingabe-Prompt ähnlichen Embeddings (z. B. mittels Cosinus-Ähnlichkeitssuche), übergibt diese mit einem dafür geeigneten Prompt an das LLM und liefert dessen Ausgabe nach optionaler Nachbearbeitung an den User zurück. Dafür ist freilich notwendig, dass RAG und LLM das gleiche Embedding-Modell verwenden. Natürlich kann ein RAG-System alternativ auch mit ElasticSearch nach passenden Informationen suchen. Letzteren Ansatz können Entwickler zusammen mit Websuchen dafür nutzen, um eine LLM-unterstützte Websuche zu implementieren. Der Dienst Perplexity ist hierfür ein interessantes Beispiel.
Knowledge Graphs: Modernere Ansätze nutzen eine Graph-Datenbank (z. B. Neo4j) aus Wissensgraphen (Knowledge Graphs), um Information strukturiert zu speichern. Bei RAG-Systemen handelt es sich hingegen bei den gespeicherten Embeddings in der Regel um unstrukturierte Daten. Strukturierte Daten führen erfahrungsgemäß zu weniger Halluzinationen und sind leichter zu analysieren. In der Zukunft könnten Wissensgraphen daher an Bedeutung gewinnen.
Sie möchten ein LLM-Modell, das nicht in den Arbeitsspeicher ihrer GPU oder CPU passt, dennoch nutzen? Normalerweise speichern die Schichten eines LLM Gewichte und Bias-Vektoren in Form von 32-Bit-Gleitkommazahlen. Diese Präzision ist aber nicht immer notwendig. Quantisierung in Large-Language-Modellen bezeichnet den Prozess, bei dem die Präzision der Modellparameter reduziert wird, um die Modellgröße und den Rechenaufwand zu verringern. Dies geschieht durch die Umwandlung von hochpräzisen Datenformaten (z. B. 32-Bit-Gleitkommazahlen) in weniger präzise Formate (z. B. 8-Bit-Ganzzahlen). Dadurch können LLMs auf Hardware mit begrenzten Ressourcen ausgeführt werden, was zu schnelleren Inferenzen und geringerem Speicherverbrauch führt. Allerdings kann die Quantisierung die Genauigkeit der Modelle beeinträchtigen. In vielen Fällen ist der Genauigkeitsverlust durch Quantisierung verschmerzbar.
Wenn sie beispielsweise in Hugging Face nach Modellen suchen, dürften Sie auf seltsame Dateinamen für Modelle stoßen, etwa auf <modelname>….Q4_K_M. Endungen von LLM-Namen wie Q4_K_M enthalten wichtige Informationen über die Quantisierung und Optimierung des Modells. Hier ist eine detaillierte Erklärung:
Q4: Dies zeigt an, dass das Modell auf eine 4-Bit-Präzision quantisiert wurde. Quantisierung reduziert die Präzision der Modellgewichte von der typischen 32-Bit-Gleitkommadarstellung auf eine niedrigere Präzision, wie 4 Bit, um Speicherplatz zu sparen und die Inferenzgeschwindigkeit zu verbessern.K: Dies bezieht sich auf die spezifische Quantisierungsmethode, die für bestimmte Teile des Modells verwendet wird, zum Beispiel die Aufmerksamkeitsmechanismen. Es beinhaltet oft die Optimierung des Kernels (K) für bessere Leistung.M: Dieser Suffix zeigt typischerweise an, dass die Quantisierungsmethode selektiv angewendet wird, oft auf bestimmte Schichten wie Einbettungen oder Aufmerksamkeitsmechanismen, während andere in der höheren Präzision bleiben. Dieser Ansatz balanciert Leistung und Speicherbedarf.Zusammenfassend bedeutet Q4_K_M, dass das Modell auf 4-Bit-Präzision quantisiert ist, wobei optimierte Kernelmethoden selektiv Anwendung finden, um die Leistung zu erhalten, während sich der Speicherbedarf reduziert.
Hier ein Überblick über gängige Kürzel der möglichen Quantisierungsstufen:
Q2 (2 Bit)Q4 (4 Bit)Q8 (8 Bit)Q16 (16 Bit)Q32 (32 Bit, typischerweise nicht quantisiert)K: Dies könnte sich auf eine spezifische Kernel- oder Optimierungsmethode beziehen. Mögliche Variationen könnten unterschiedliche Kerneloptimierungen oder Techniken umfassen, aber spezifische Werte sind nicht standardisiert.M (Gemischte Präzision): Nur eine Teilmenge der Schichten erfährt eine Quantisierung, F (Volle Präzision): Das Modell verwendet die volle Präzision sowie S (Selektive Quantisierung): Quantisierung findet nur für eine selektive Teilmenge der Schichten statt.Mögliche Kombinationen könnten also sein:
Q2_K_MQ4_K_FQ8_K_SQ16_K_MDiese Kombinationen spiegeln somit unterschiedliche Quantisierungsstufen und Optimierungsstrategien wider. Die genauen Namenskonventionen können jedoch je nach spezifischer Implementierung oder Modellarchitektur variieren.
Hinzufügungen wie _0 oder _1 bezeichnen Versionen von Quantisierungsschemata, beispielsweise unterschiedliche Algorithmen oder Techniken.
Im Umfeld von LLMs sind Modelle fast immer als GGUF/GGML-Dateien gespeichert. Auch Apple MLX unterstützt hauptsächlich das GGUF (GPT-Generated Unified Format) für Modelldateien, hat jedoch kürzlich eine begrenzte Unterstützung für Quantisierungsausgaben erhalten, was darauf hindeuten könnte, dass es indirekt mit anderen Formaten kompatibel ist. Es gibt jedoch keine explizite Erwähnung, dass MLX Formate außer GGUF für seine Kernoperationen nutzt.
Gängige Formate, die LLM-Anbieter im maschinellen Lernen und bei großen Sprachmodellen verwenden:
Tensordateien .pt und .pth:
Diese Formate erleichtern den Austausch und die Bereitstellung von Modellen auf verschiedenen Plattformen und Frameworks. In PyTorch sind .pt und .pth Dateierweiterungen, die Entwickler häufig zum Speichern von Modellen verwenden. Es gibt keinen funktionalen Unterschied zwischen ihnen; beide lassen sich nutzen, um PyTorch-Modelle oder Tensoren mithilfe des Python-pickle-Moduls über torch.save() zu speichern. Die Wahl zwischen .pt und .pth ist weitgehend eine Frage der Konvention. Allerdings wird .pt gegenüber .pth empfohlen, da .pth mit Python-Pfadkonfigurationsdateien in Konflikt geraten kann.
Beide Erweiterungen funktionieren austauschbar mit den torch.save()- und torch.load()-Funktionen. Aber was genau ist in diesen Dateien eigentlich gespeichert?
Sie speichern typischerweise serialisierte Daten, oft Modellgewichte oder andere Python-Objekte, konkret:
state_dict), das die Modellparameter enthält.Lightning-Checkpoints, die ebenfalls die Erweiterungen .pt oder .pth verwenden könnten, speichern umfassendere Informationen, darunter Modellzustand, Optimiererzustände, Lernrateplanungszustände, Callback-Zustände, Hyperparameter.
In einer .pt-Datei sind die Einträge nicht in einem menschenlesbaren Format gespeichert. Stattdessen verwendet PyTorch das Python-pickle-Modul, um Tensoren und andere Python-Objekte in ein binäres Format zu serialisieren.
Falls Sie sich über Kennzeichnungen wie "INSTRUCT" in den Modellnamen wundern, hier ein paar Erläuterungen dazu:
In LLM-Dateinamen gibt es verschiedene Namen, die auf spezifische Techniken oder Anwendungen hinweisen. Einige Beispiele sind:
Der letzte Teil dieser Blogserie wird Reasoning-Modelle vorstellen und einen Blick in die Zukunft der LLMs wagen.
URL dieses Artikels:
https://www.heise.de/-10296358
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[4] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[5] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[6] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[7] https://en.wikipedia.org/wiki/Retrieval-augmented_generation#/media/File:RAG_diagram.svg
[8] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
In .NET 9.0 kann man neuerdings einen Globally Unique Identifier in der Version 7 mit Zeitstempel erzeugen.
Die .NET-Klasse System.Guid bietet seit .NET 9.0 neben der statischen Methode NewGuid(), die einen Globally Unique Identifier (GUID), alias UUID (Universally Unique Identifier), gemäß RFC 9562 [1] mit reinen Zufallszahlen (Version 4) erzeugt, nun auch eine weitere statische Methode CreateVersion7() mit einem Timestamp und einer Zufallszahl.
Folgender Code zeigt sowohl den Einsatz von NewGuid() als auch den von CreateVersion7():
public void Run()
{
CUI.Demo(nameof(FCL9_Guid));
for (int i = 0; i < 10; i++)
{
Guid guid = Guid.NewGuid();
Console.WriteLine($"Guid v4:\t{guid}");
}
for (int i = 0; i < 10; i++)
{
Guid guid7 = Guid.CreateVersion7();
Console.WriteLine($"Guid v7:\t{guid7}");
}
CUI.Yellow("Warte 1 Sekunde...");
Thread.Sleep(1000);
for (int i = 0; i < 10; i++)
{
Guid guid7 = Guid.CreateVersion7();
Console.WriteLine($"Guid v7:\t{guid7}");
}
}

(Bild: Screenshot (Holger Schwichtenberg))
Der Timestamp ist in UTC-Zeit in den ersten 64 Bits der GUID enthalten.
Zum Extrahieren des Zeitpunkts gibt es keine eingebaute Methode, man kann ihn aber folgendermaßen extrahieren:
public DateTimeOffset GetDateTimeOffset(Guid guid)
{
byte[] bytes = new byte[8];
guid.ToByteArray(true)[0..6].CopyTo(bytes, 2);
if (BitConverter.IsLittleEndian)
{
Array.Reverse(bytes);
}
long ms = BitConverter.ToInt64(bytes);
return DateTimeOffset.FromUnixTimeMilliseconds(ms);
}
URL dieses Artikels:
https://www.heise.de/-10316051
Links in diesem Artikel:
[1] https://www.rfc-editor.org/rfc/rfc9562.html
[2] mailto:rme@ix.de
Copyright © 2025 Heise Medien
This is a bugfix release for 1.26.0, addressing some regressions 🐛
A few highlights ✨:
This release has been made by @Alkarex, @FromTheMoon85, @marienfressinaud, @math-GH
and newcomers @abackstrom, @BryanButlerGit, @culbrethj, @EricDiao, @Karvel, @ViPeR5000
Full changelog:

(Bild: Pincasso/Shutterstock)
In C# 13.0 hat Microsoft den Einsatzbereich von ref struct unter anderem zum Implementieren von Schnittstellen erweitert.
Seit C# 7.2 gibt es Strukturen, die immer auf dem Stack leben und niemals auf den Heap wandern können: ref struct. In C# 13.0 hat Microsoft den Einsatz von ref struct erweitert.
Solche Typen können nun:
where T : allows ref struct verwenden.yield verwendet werden. Allerdings darf die Struktur nicht länger leben als der aktuelle Durchlauf des Iterator.Task oder Task<T> liefern, genutzt werden.Weiterhin gilt aber: Wenn man einen Typ als ref struct deklariert, ist ein Boxing nicht mehr möglich. Der Einsatz von ref struct ist daher begrenzt. So kann man beispielsweise kein Array und keine List<T> daraus erzeugen.
Folgender Code zeigt einen eigenen Typ mit ref struct, der eine Schnittstelle implementiert:
internal interface IPerson
{
int ID { get; set; }
int Name { get; set; }
}
// NEU seit C# 13.0: ref struct kann Schnittstelle implementieren
ref struct Person : IPerson
{
public int ID { get; set; }
public int Name { get; set; }
// ToString()
public override string ToString()
{
return "Person #" + ID + " " + Name;
}
}
}
class Client
{
public void Run()
{
Person p = new Person();
p.ID = 1;
p.Name = 2;
Console.WriteLine(p.ID);
Console.WriteLine(p.Name);
// Das ist alles nicht erlaubt!
// IPerson i = p; // Casting auf Schnittstelle
// List<Person> PersonList = new(); // List<T>
// PersonList[] PersonArray = new Person[10]; // Array
}
}
URL dieses Artikels:
https://www.heise.de/-10307583
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: Erstellt mit DALL-E)
Die Artikelserie zu den internen Mechanismen großer Sprachmodelle behandelt diesmal die benötigte Hardware und pretrained Models.
Ein Large Language Model (LLM) ist darauf ausgelegt, menschliche Sprache zu verarbeiten und zu generieren. Nach der grundlegenden Übersicht zu LLMs im ersten Teil [1] geht es dieses Mal um die Hardware-Anforderungen und unterschiedliche vorab trainierte Modelle.
Fasten your seat belts!
Am Rande eine Bemerkung zu Hardware-Anforderungen: In der Beschreibung ist zu erkennen, dass im LLM sowohl für das Training als auch für die Ausführung (Inferenz) komplexe mathematische Berechnungen mit Vektoren vorkommen. Auf diese sind GPU-Kerne und neuronale Prozessoren spezialisiert. Daher benötigen LLM-Entwicklerinnen und -Nutzer leistungsvolle TPUs oder GPUs mit möglichst viel RAM. Mit normalen CPUs und wenig Arbeitsspeicher kommt man nicht weit, außer für sehr kleine Modelle. In den Speicher der GPU müssen unter anderem der Kontext und die errechneten Gewichte des LLM passen. Letztere können bis zu mehreren Hundert Gigabyte umfassen, während der Kontext von einigen Kilobytes bis zu vielen Megabytes reicht. Das Modell Deepseek R1 weist 671 Milliarden Gewichte/Tensoren und damit einen Speicherbedarf von rund 500 Gigabyte auf; OpenAI-Modelle sollen teilweise über ein Terabyte benötigen. Dafür wären etwa mehrere GPU-Beschleuniger vom Typ Nvidia H100 notwendig. Folgerichtig können Entwickler nur beschränkt Modelle auf ihren lokalen Systemen trainieren und laufen lassen, etwa bei guter Hardware-Ausstattung Modelle mit bis zu 70 Milliarden Parametern.
Vorab trainierte Modelle sind LLMs, die ihre Schöpfer auf großen Datensätzen trainiert und für spezifische Aufgaben feingetunt haben. Diese Modelle dienen als Ausgangspunkt für andere Aufgaben, um dem Modell zu ermöglichen, die während des Trainings gelernten Muster und Beziehungen zu nutzen. Beliebte vorab trainierte Modelltypen sind:
Kontextfenster beziehen sich auf die Menge an Eingabetext, die das Modell zu einem bestimmten Zeitpunkt betrachten kann. Das haben wir schon im ersten Teil der Serie [6] betrachtet, soll aber hier nochmals Erwähnung finden. Das Kontextfenster kann fest oder dynamisch sein, je nach Modellarchitektur. Ein größeres Kontextfenster ermöglicht es dem Modell, mehr Kontext zu erfassen, erhöht aber auch den Rechenaufwand. Moderne LLMs haben Kontextlängen von ein paar tausend bis zu ein paar Millionen Tokens.
Masken helfen, das Modell daran zu hindern, auf bestimmte Teile des Eingabetextes zu achten. Es gibt verschiedene Arten von Masken, darunter:
Sobald man eine Abfrage (Prompt) in ein LLM eingibt, durchläuft die Abfrage die folgenden Schritte:
Danach führt das LLM die folgenden Schritte aus:
Der nachfolgende Code demonstriert die Schritt-für-Schritt-Verarbeitung einer Abfrage, einschließlich Tokenisierung, Embedding-Erstellung, positioneller Codierung, Self-Attention, Cross-Attention, Feed-Forward-Layer, Kontextfenster und Maskierung.
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# Laden Sie das vorab trainierte Modell und den Tokenizer
modell = AutoModelForMaskedLM.from_pretrained("bert-base-uncased")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Definieren Sie eine Abfrage
abfrage = "Erläutere die Geschichte des Heise-Verlags."
# Tokenisieren Sie die Abfrage
eingabe = tokenizer(abfrage, return_tensors="pt")
# Erstellen Sie die Embeddings
embedded_abfrage = modell.embeddings(eingabe["input_ids"])
# Fügen Sie die positionale Kodierung hinzu
positionale_kodierung = modell.positional_encodings(embedded_abfrage)
embedded_abfrage = embedded_abfrage + positionale_kodierung
# Wenden Sie die Self-Attention an
kontextualisierte_darstellung = modell.self_attention(embedded_abfrage)
# Wenden Sie die Cross-Attention an
hoeher_ebene_darstellung = modell.cross_attention(kontextualisierte_darstellung)
# Wenden Sie die Feed-Forward-Layer an
transformierte_darstellung = modell.feed_forward_layers(hoeher_ebene_darstellung)
# Wenden Sie das Kontextfenster an
endgueltige_ausgabe = modell.context_window(transformierte_darstellung)
# Maskieren Sie die Ausgabe
antwort = modell.masking(endgueltige_ausgabe)
print(antwort)Die folgenden Dateien erstellt oder modifiziert das Modell während der Ausführung:
Hinweis: Dies ist ein stark vereinfachtes Beispiel. Reale Anwendungen mit LLMs sind in der Praxis viel komplexer und vielschichtiger.
In meinem nächsten Blogbeitrag gehe ich auf unterschiedliche Architekturtypen von LLMs ein.
URL dieses Artikels:
https://www.heise.de/-10296098
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[4] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[5] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[6] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[7] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Java wird im Jahr 2025 schon 30 Jahre alt. Das ist ein guter Zeitpunkt, zurück, aber auch nach vorn zu blicken.

Der Softwarearchitekt und -entwickler Adam Bien hat sich in der internationalen Java-Szene einen Namen gemacht. Er ist Java Champion und wurde 2010 zum Java Developer of the Year gekürt [1]. Auf Konferenzen begeistert er seit Jahren sein Publikum und wurde für seine Vorträge unter anderem auf der Java One seit 2009 mehrmals zu den RockStars gewählt.
Adam wird bei der JavaLand 2025 eine Keynote zu 30 Jahren Java [2] halten, und wir haben ihm vorab schon einige Fragen gestellt.
Falk Sippach: Adam, du bist eine Schlüsselfigur in der Java-Community und hast die Evolution der Plattform und der Sprache schon relativ früh bis zur Gegenwart aktiv mitgestaltet. Wann und mit welcher Version bist du erstmals mit Java in Berührung gekommen?
Adam Bien: Ich habe Java kurz vor der Veröffentlichung des JDK 1.0 evaluiert und war nicht begeistert. Ich war damals ein C++-Fan und hatte viel Spaß mit Operator Overloading und Include-Dateien. Beides fehlte mir in Java. Das war etwa 1995.
Falk Sippach: Wenn man sich deine bisherigen Veröffentlichungen (Bücher, Vorträge, Workshops, ...) anschaut, fallen dabei viele relevante Meilensteine des Java-Ökosystems ins Auge. Was waren für dich in deiner Laufbahn die bemerkenswertesten Sprachfeatures, Bibliotheken, Standards und Werkzeuge?
Adam Bien: Alles begann mit Applets. Mein erstes kommerzielles Projekt war ein Chat-Applet mit Remote Method Invocation (RMI) Backend. Aber ich konnte es kaum erwarten, bis Servlets verfügbar wurden. Ich sollte eine serverseitige CMS-Anwendung mit Common Gateway Interface (CGI) implementieren. Ich hatte keine Erfahrung mit CGI und wartete ungeduldig auf die erste Version des JavaWebServers von Sun Microsystems um 1997.
Das nächste Projekt, wieder mit JavaWebServer, war eine E-Commerce-Lösung. Hier haben wir das gesamte Backend mit JavaBeans und JDBC implementiert. Die Produktvielfalt war eine echte Herausforderung. Die Applikationsserver waren kaum vergleichbar und die Programmiererfahrung nicht übertragbar. Mit der Einführung von J2EE wurde dieses Problem durch die Standardisierung der APIs gelöst. Fortan konnte ich produktiv mit verschiedenen Produkten entwickeln.
Die Idee von Quarkus hat mich ebenfalls überrascht. Die APIs beizubehalten und gleichzeitig das Deployment zur Laufzeit zu eliminieren, war revolutionär. In den meisten Projekten haben mir die Patterns bei der "Don't Make Me Think"-Entwicklung geholfen und mir Hunderte von überflüssigen Meetings erspart. Wir haben uns auf die Patterns verlassen, um die Anwendung zu strukturieren und uns auf die Implementierung des Mehrwerts konzentriert.
Falk Sippach: Welche Rolle spielt Java deiner Meinung nach in der modernen Softwareentwicklung, insbesondere im Vergleich zu anderen Sprachen und Technologien?
Adam Bien: Java wird immer einfacher und die Entwicklung immer produktiver. Die Typsicherheit von Java wurde mit der wachsenden Popularität von Ruby on Rails um 2006 belächelt, "Duck Typing" mit zusätzlichen Unit Tests sollte die Produktivität und Lesbarkeit des Codes erhöhen. Daraufhin folgten einige schwer wartbare Projekte, die versuchten, zu Java zurückzukehren. Heute versuchen die meisten Programmiersprachen typsicher zu sein. Selbst JavaScript und Python wollen die Typsicherheit.
Auch ORMs wie JPA wurden als überflüssig abgestempelt – NoSQL sollte agiler und leichter verständlich sein. Heute sind ORMs in JavaScript-Frameworks sehr beliebt. Ich habe das Gefühl, dass alle Java-Hypes, die vor 10 Jahren populär waren, heute in anderen Programmiersprachen zu finden sind.
Es wurde sogar argumentiert, dass Java eine Low-Level-Programmiersprache ist, die unnötig schnell ist. Statt Java sollte man lieber höhere, aber weniger performante Programmiersprachen verwenden. Tatsächlich ist Java sehr schnell. Es ist um Faktoren schneller als JavaScript oder Python und vergleichbar mit C.
Java ist langweilig, gut lesbar und eine "No-Magic"-Programmiersprache mit einem sehr guten Tooling und Ökosystem. Daher eignet sich Java besonders für große Projekte. Neue Java-Features wie die direkte Ausführbarkeit von Quelldateien machen Java auch für kleinere Anwendungen und Scripting interessant.
Falk Sippach: Was hat dich motiviert, Java nahezu 30 Jahre lang die Treue zu halten?
Adam Bien: Anfangs wollte ich möglichst viele Programmiersprachen verwenden. Aufgrund der großen Nachfrage nach Java musste ich diese Strategie schnell aufgeben. Sun Microsystems hat früh auf Standards und Herstellervielfalt gesetzt. Ich habe mich auf Standards konzentriert und konnte inkrementell lernen und Erfahrungen sammeln. Um mich herum wurden viele Frameworks gehypt, eingesetzt und wieder verworfen. Dann kam wieder ein ganz anderes Framework zum Einsatz. Man musste sich die Idiome neu aneignen, die Erfahrung war selten übertragbar.
Erst kürzlich habe ich ein etwa 15 Jahre altes Projekt modernisiert. Es war viel einfacher, als ich dachte. Mit Java konnte ich einfachen und langweiligen Produktionscode schreiben und in meiner Freizeit viel Spaß mit JINI, JavaSpaces, JXTA, RMI, JIRO, FreeTTS, Hazelcast und unzähligen anderen Frameworks haben. Java macht mir immer noch Spaß und meine Kunden sind zufrieden. Ich sehe keinen Grund, zu wechseln. Lediglich im Frontend verwende ich reine "Webstandards" und Web Components gepaart mit reinem JavaScript ohne Abhängigkeiten oder externe Bibliotheken. "The Java way". Auch dieser Ansatz wird übrigens immer populärer.
In den letzten Jahren konnten wir mit Java, Quarkus und serverlosen Architekturen einfache Anwendungen bauen, die im Betrieb sehr kostengünstig, in einigen Fällen sogar kostenlos waren. Sogar die Kommentare zu meinen (>800) YouTube-Shorts sind überraschend positiv – Java ist immer noch sehr populär und viele sind immer noch überrascht von den Java-Features.
Falk Sippach: Welche Tipps kannst du aktuellen Java-Entwicklern geben, um in der sich schnell verändernden Technologielandschaft am Ball zu bleiben und sich mit Java weiterzuentwickeln?
Adam Bien: Hypes wiederholen sich. Das Wichtigste ist, möglichst einfachen Code zu schreiben. Der Mehrwert für den Kunden sollte immer im Vordergrund stehen.
Falk Sippach: Zu guter Letzt wollen wir noch einen Blick in die Zukunft wagen. Welche Herausforderungen und Chancen siehst du für Java in den nächsten fünf bis zehn Jahren?
Adam Bien: In Java gibt es derzeit viele Innovationen. GraalVM ermöglicht die Ausführung von JavaScript, Python und sogar WebAssembly auf der JVM und mit optionaler Übersetzung in Maschinencode, Graal OS sieht aus wie ein "Pure Java"-Kubernetes, Project Babylon ermöglicht die Transformation von Code – auch für den Betrieb auf GPUs, Valhalla hilft mit Performancegewinnen bei der Model Inference, Leyden macht die Dauer von Kaltstarts konfigurierbar. Es sieht also ausgezeichnet aus - vielleicht gibt es bald einen neuen Java-Hype.
Wollt Ihr Adam Bien live erleben, dann kommt auf die JavaLand [3], die vom 1. bis 3. April am Nürburgring stattfindet.
URL dieses Artikels:
https://www.heise.de/-10304215
Links in diesem Artikel:
[1] https://in.relation.to/2010/10/11/adam-bien-java-developer-of-the-year-2010/
[2] https://meine.doag.org/events/javaland/2025/agenda/#agendaId.5162
[3] https://www.javaland.eu/
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock)
C# 13.0 führt die neue Klasse Lock ein, um Codeblöcke vor dem Zugriff durch weitere Threads zu sperren.
Ab .NET 9.0/C# 13.0 gibt es für das Sperren von Codeblöcken vor dem Zugriff durch weitere Threads die neue Klasse System.Threading.Lock, die man nun im Standard in Verbindung mit dem lock-Statement in C# verwenden sollte, "for best performance" wie Microsoft in der Dokumentation [1] schreibt.
Folgender Code aus der C#-Dokumentation auf Microsoft Learn [2] zeigt ein Beispiel mit dem Schlüsselwort lock und der Klasse System.Threading.Lock:
using System;
using System.Threading.Tasks;
namespace NET9_Console.CS13;
public class Account
{
// Vor .NET 9.0/C# 13.0 wurde hier System.Object verwendet statt
// System.Threading.Lock
private readonly System.Threading.Lock _balanceLock = new();
private decimal _balance;
public Account(decimal initialBalance) => _balance = initialBalance;
public decimal Debit(decimal amount)
{
if (amount < 0)
{
throw new ArgumentOutOfRangeException(nameof(amount), "The debit amount cannot be negative.");
}
decimal appliedAmount = 0;
lock (_balanceLock)
{
if (_balance >= amount)
{
_balance -= amount;
appliedAmount = amount;
}
}
return appliedAmount;
}
public void Credit(decimal amount)
{
if (amount < 0)
{
throw new ArgumentOutOfRangeException(nameof(amount), "The credit amount cannot be negative.");
}
lock (_balanceLock)
{
_balance += amount;
}
}
public decimal GetBalance()
{
lock (_balanceLock)
{
return _balance;
}
}
}
class AccountTest
{
static async Task Main()
{
var account = new Account(1000);
var tasks = new Task[100];
for (int i = 0; i < tasks.Length; i++)
{
tasks[i] = Task.Run(() => Update(account));
}
await Task.WhenAll(tasks);
Console.WriteLine($"Account's balance is {account.GetBalance()}");
// Output:
// Account's balance is 2000
}
static void Update(Account account)
{
decimal[] amounts = [0, 2, -3, 6, -2, -1, 8, -5, 11, -6];
foreach (var amount in amounts)
{
if (amount >= 0)
{
account.Credit(amount);
}
else
{
account.Debit(Math.Abs(amount));
}
}
}
}
Der C#-13.0-Compiler generiert dann aus
lock (_balanceLock)
{
_balance += amount;
}
einen Aufruf der EnterScope()-Methode in der Klasse System.Threading.Lock:
using (balanceLock.EnterScope())
{
_balance += amount;
}
URL dieses Artikels:
https://www.heise.de/-10299439
Links in diesem Artikel:
[1] https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/statements/lock
[2] https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/statements/lock
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Blick unter die Motorhaube
(Bild: generated by DALL-E)
Die Artikelserie zeigt die internen Mechanismen großer Sprachmodelle von der Texteingabe bis zur Textgenerierung.
Stellen Sie sich eine magische Wissensdatenbank vor, in der Einträge nicht nur statische Sammlungen von Wörtern sind, sondern lebendige Entitäten, die menschliche Texte verstehen und generieren können. Willkommen in der Welt der Large Language Models (LLMs), die die Grenzen der natürlichen Sprachverarbeitung auf verblüffende Weise erweitern. Als Softwareentwickler sind wir gerade dabei, eine faszinierende Reise zu beginnen, die uns durch die inneren Strukturen dieser linguistischen Mechanismen führt. Immerhin haben Large Language Models wie GPT-4, Claude oder Llama die KI-Landschaft in den letzten Jahren revolutioniert.
Fasten your Seat Belts!
Ein Large Language Modell ist eine Art künstliche Intelligenz (KI), die darauf ausgelegt ist, menschliche Sprache zu verarbeiten und zu generieren. Es handelt sich um ein Lernmodell, das tiefschichtige neuronale Netze verwendet, um Muster und Beziehungen innerhalb von Sprachdaten zu lernen. Das "Large" in LLM bezieht sich auf die enorme Menge an Trainingsdaten und die enorme Anzahl an Parametern, die sich als justierbare Knöpfe betrachten lassen und die das Modell verwendet, um Vorhersagen zu treffen.
LLMs basieren auf der Transformer-Architektur, die 2017 in „Attention Is All You Need [4]“ eingeführt wurde. Im Gegensatz zu RNNs oder CNNs nutzt der Transformer Self-Attention-Mechanismen, um Kontextbeziehungen zwischen allen Wörtern in einem Text parallel zu erfassen.
Schlüsselkomponenten des Transformers sind unter anderem:
Klingt alles wie böhmische Dörfer? Ich versuche, die Konzepte näher zu erläutern.
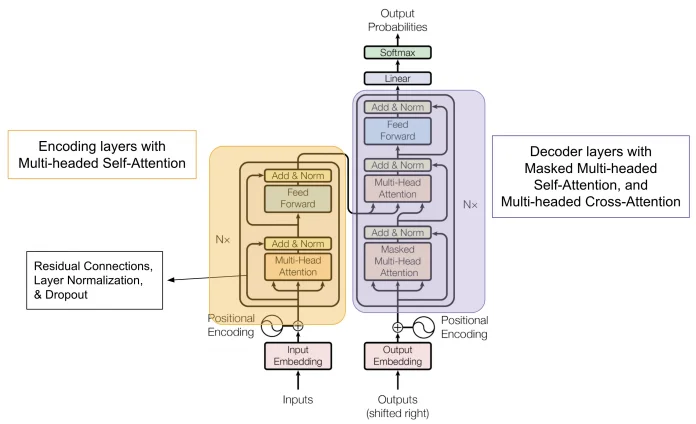
(Bild: Wikipedia)
Ein LLM setzt sich vereinfacht aus den folgenden Komponenten zusammen:
Jedes LLM besteht aus einem Stapel neuronaler Schichten – genau genommen aus Dutzenden bis Hunderten identischer Transformer-Schichten für eine hierarchische Merkmalsverarbeitung:
Beispiel: GPT-3 hat 96 Schichten, LLaMA 2 bis zu 70 Schichten.
Ziel eines Tokenizers ist die Umwandlung von Rohtext in diskrete Einheiten (Token). Dafür gibt es mehrere Methoden:
Beispiel: Der Satz „KI ist faszinierend!“ könnte in Tokens wie `["KI", " ist", " fas", "zin", "ierend", "!"]` zerlegt werden.
Embeddings sind die Grundlage der LLMs, die es dem Modell ermöglichen, Tokens (Wörter, Subwörter oder Zeichen) als numerische Vektoren darzustellen. Jeder Token wird in einen hochdimensionalen Vektor (z. B. 768 oder 4096 Dimensionen) umgewandelt. Diese Vektoren lernt das Modell während des Trainings und erfasst die semantische Bedeutung der Eingabe-Token. Es gibt verschiedene Arten von Embeddings, darunter:
Wichtig an dieser Stelle ist, dass wir Entwickler die Dimensionen nicht selbst definieren. Das macht das Modell beim Training ganz ohne unser Zutun. Eine Dimension könnte etwa Farbe sein, eine andere Länge. Jedenfalls liegen ähnliche Begriffe wie "Kater" und "Katze" in dem mehrdimensionalen Vektorraum ganz nahe beieinander. Begriffe wie "Eiscreme" und "Weltall" liegen hingegen weit auseinander.
Positionelle Codierungen, im Englischen als positional embeddings bezeichnet, spielen eine entscheidende Rolle bei LLMs, indem sie die Reihenfolge der Eingabe-Token erhalten. LLMs zerlegen den Eingabetext in eine Folge von Token und wandeln jedes Token in eine numerische Darstellung um. Allerdings geht bei dieser Umwandlung die Reihenfolge der Token verloren, die für das Verständnis des Kontexts und der Beziehungen zwischen Token essenziell ist. Um dieses Problem zu lösen, führt man positionelle Codierungen zu den embedded Token hinzu, um sich die Reihenfolge der Token zu merken. Das LLM lernt die positionellen Codierungen während des Trainings. Sie dienen dazu, die Position jedes Tokens in der Sequenz zu codieren. Dies ermöglicht es dem Modell, die Beziehungen zwischen Token und ihrer Position in der Sequenz zu verstehen.
Es gibt verschiedene Arten positioneller Codierungen:
Feed-Forward-Layer (vollständig verbundene Layer) sind die Arbeitstiere der LLMs. Sie nehmen die Embeddings als Eingabe und generieren eine kontinuierliche Darstellung des Eingabetextes. Feed-Forward-Layer bestehen aus:
In Sätzen wie „Der Hund jagte die verschlagene Katze durch das ganze Haus. Sie konnte sich aber rechtzeitig verstecken“ kommen verschiedene Wörter vor, von denen jedes einzelne nicht einfach isoliert im Raum steht. Im ersten Satz bezieht sich „Hund“ unter anderem auf eine Tätigkeit „jagte“ und die gejagte „Katze“. Uns liegen also starke Verbindungen des Wortes „Hund“ zu zwei weiteren Wörtern im selben Satz vor. Jedes dieser Wortpaare definiert die Beziehung eines Wortes im Satz zu einem anderen. Diese Verbindungen können stärker oder schwächer sein. Ein LLM berechnet die Beziehungen für jedes Wort im Satz zu jedem anderen Wort im Satz. Das nennt sich Self-Attention. Sie bezeichnet, wie stark sich Token gegenseitig „beachten“.
Weil das LLM parallel an mehreren Stellen eines Textes die entsprechenden Attentions erstellt, haben wir es mit Multi-Head-Attentions zu tun. Ohne ausreichenden Weitblick gehen einem LLM allerdings wichtige satzübergreifende Beziehungen verloren. Würden LLMs also Text in Sätze zerlegen und jeden Satz für sich bearbeiten, ginge im zweiten Satz verloren, dass sich das „Sie“ auf „Katze“ im ersten Satz bezieht. Cross-Attention dient dazu, um Attention/Beziehungen auch über einen größeren Kontext festzustellen. Wichtig dabei ist: LLMs sind in der Größe des betrachteten Kontexts beschränkt. Je größer der Kontext, desto größer der benötigte Arbeitsspeicher. Die Kontextgrößen reichen von wenigen Kilobytes (ein paar Schreibmaschinenseiten) bis zu mehreren Megabytes (ganze Buchinhalte). Wenn das LLM bereits zu viel Kontextinformation gemerkt hat und der Speicher "überläuft", beginnt es vorangegangenen Kontext zu "vergessen".
Self-Attention ist ein Mechanismus, der es dem Modell ermöglicht, auf verschiedene Teile des Eingabetextes zu achten und eine kontextualisierte Darstellung zu generieren. Zu welchem anderen Wort hat das gerade betrachtete Wort die größte Beziehung (Attention).
Multi-Head-Attention ist ein Mechanismus, der es dem Modell ermöglicht, auf verschiedene Teile des Eingabetextes von geschiedenen Perspektiven gleichzeitig zu achten. Statt einer einzigen Attention-Operation verwendet der Transformer mehrere „Heads“: Heads erfassen unterschiedliche Beziehungen (z. B. Syntax vs. Semantik). Die Outputs der Heads werden konkateniert und linear projiziert.
Vorteil: Das Modell lernt gleichzeitig diversifizierte Kontextabhängigkeiten.
Cross-Attention ist ein Mechanismus, der es dem Modell ermöglicht, über weitere Entfernung von Tokens auf externe Informationen zu achten wie den Eingabetext (Prompt) oder andere Modelle. Das hat insbesondere auch für den Übergang von der Encoder- zur Decoder-Schicht eine Bedeutung.
Das erreicht das Modell durch die folgenden Schritte:
Nach der grundlegenden Übersicht zu LLMs geht es im nächsten Beitrag um die Hardwareanforderungen und unterschiedliche pretrained Models.
URL dieses Artikels:
https://www.heise.de/-10283768
Links in diesem Artikel:
[1] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-1-10283768.html
[2] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-2-10296098.html
[3] https://www.heise.de/blog/Per-Anhalter-durch-die-KI-Galaxie-LLM-Crashkurs-Teil-3-10296358.html
[4] https://arxiv.org/abs/1706.03762
[5] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: tomertu/Shutterstock.com)
Wer Software entwickelt, muss die zugrunde liegende Fachlichkeit verstehen. Dabei hilft eine geeignete Modellierung der Fachdomäne.
75 Prozent aller Softwareprojekte scheitern! Dazu habe ich im vergangenen Oktober bereits einen Beitrag geschrieben [1]. Darin habe ich auch ein essenzielles und grundlegendes Problem angesprochen: Viele Softwareprojekte scheitern nämlich nicht an der Technik, sondern viel eher an einem fehlenden Verständnis der zugrunde liegenden Fachlichkeit. Denn es kommt äußerst selten vor, dass Entwicklerinnen und Entwickler sowie Fachexpertinnen und Fachexperten die gleiche Sprache sprechen. Allerdings ist damit nicht eine natürliche Sprache wie Deutsch, Englisch oder Französisch gemeint, sondern vielmehr das Fehlen einer gemeinsamen Fachsprache (und letztlich eines gemeinsamen Verständnisses, worum es bei der zu entwickelnden Software inhaltlich überhaupt geht).
Dass dies zu impliziten Annahmen, zu Missverständnissen und zu fehlerhaften Interpretationen führt, haben wir in dem erwähnten Video ausführlich erläutert. Das bedeutet letztlich nichts anderes, als dass Entwicklerinnen und Entwickler eine Software immer so bauen, wie sie diese verstehen – und nicht unbedingt so, wie das Business die Software benötigt. Folglich stellt sich die Frage, was man dagegen unternehmen kann: Eine mögliche Antwort ist eine wirklich gute Modellierung der Fachlichkeit. Wie eine solche Modellierung entwickelt wird, das erläutere ich Ihnen heute in diesem Blogpost.
Als allererstes sollte man zunächst verstehen, wo das Problem der fehlenden gemeinsamen Sprache und des fehlenden gemeinsamen Verständnisses überhaupt herkommt. Denn eigentlich sollte man meinen, dass es nicht so übermäßig schwierig sein kann, miteinander zu sprechen. Das Problem ist jedoch, dass hier unterschiedliche Welten aufeinandertreffen, die beide nie gelernt haben, mit der jeweils anderen Disziplin zu kommunizieren:
Das Problem lautet jedoch: Wie entwickeln Sie eine Software, die ein fachliches Problem lösen soll, wenn das fachliche Problem gar nicht verstanden wurde? Ganz einfach: Das funktioniert nicht.
Das Erschreckende ist jedoch, dass zu viele Teams und Unternehmen dies einfach ignorieren oder, was ich persönlich noch viel schlimmer finde, dass ihnen diese Diskrepanz nicht einmal bewusst ist. Da wird dann wochen- oder monatelang diskutiert, ob man Programmiersprache X oder doch lieber Framework Y einsetzen sollte, aber niemand kommt auf den Gedanken, sich einmal gezielt mit der Fachlichkeit auseinanderzusetzen.
Dann wird irgendwann drauflos entwickelt, und das geht ein paar Monate oder vielleicht auch ein oder zwei Jahre gut, aber schließlich erkennt man über kurz oder lang, dass die Software nicht genau das tut, was ursprünglich einmal gewünscht war. Und dann muss nachgebessert werden: Alles dauert auf einmal länger, alles wird teurer, und selbstverständlich ist das Fundament (weil falsche Annahmen getroffen wurden) in eine völlig unpassende Richtung entwickelt worden, sodass die Anpassungen jetzt nur sehr umständlich und damit auch wieder äußerst kostspielig möglich sind.
Mit hoher Wahrscheinlichkeit kommt dann jemand um die Ecke und behauptet:
"Ich hab’s Euch ja von vornherein gesagt: Hätten wir nicht auf Technologie X, sondern auf Technologie Y gesetzt, dann hätten wir das Problem jetzt nicht!"
Der Punkt ist jedoch: Das Problem wäre genauso vorhanden, nur auf einer anderen technologischen Basis. Denn das ist der springende Punkt: In den seltensten Fällen ist die Technologie an sich das Problem (womit ich nicht sagen möchte, dass es nicht bessere und schlechtere Technologieentscheidungen gäbe, in der Regel wird nur der Einfluss der Technologiewahl auf den Erfolg eines Projekts massiv überschätzt).
Das bedeutet: Wenn Sie sicherstellen möchten, dass Sie eine zum zugrunde liegenden fachlichen Problem passende Software entwickeln, und das sogar noch zielgerichtet, funktioniert es letztlich nur, wenn Sie von Anfang an verstehen, worum es aus fachlicher Sicht überhaupt geht. Das mag trivial erscheinen – die Praxis sieht leider allzu oft anders aus.
Oft steht uns Entwicklerinnen und Entwicklern nämlich etwas im Weg, das wir leider von klein auf beigebracht bekommen haben: Das Denken in Datenbanktabellen. Wir alle haben in unserer Ausbildung oder in unserem Studium gelernt, Daten in relationalen Strukturen abzulegen. Um mit diesen Strukturen zu arbeiten, kennen wir vier Verben, nämlich Create, Read, Update und Delete, häufig abgekürzt als CRUD. Wir haben gelernt, dass wir damit de facto alles modellieren können, und aus technischer Sicht ist das auch durchaus korrekt.
Aber das ändert selbstverständlich nichts daran, dass es sich bei diesen Wörtern um die Fachsprache der Datenbank handelt. Create, Read, Update und Delete sind nämlich rein technische Begriffe, die von Datenbanken genutzt werden. Da wir häufig mit Code zu tun haben, der auf Datenbanken zugreift, sind wir dazu übergegangen, diese vier Verben auch in unserem Code zu verwenden: So entstehen dann Funktionen mit Namen wie beispielsweise UpdateBook.
Aus technischer Sicht mag das sogar durchaus passend sein, wenn diese Funktion den Datensatz für ein Buch in der Datenbank aktualisiert. Das Problem besteht jedoch darin, dass dies nicht den fachlichen Use Case widerspiegelt. Denn warum wird das Buch beziehungsweise dessen Datensatz aktualisiert? Diese Information liefert der Funktionsname leider nicht. Das Problem ist außerdem, dass sich hinter diesem Update alles Mögliche verbergen kann. Ich bin mir sicher, dass wenn Sie an dieser Stelle kurz innehalten und sich überlegen, wie viele Gründe Ihnen spontan einfallen, warum man ein Buch aktualisieren können sollte, Sie keine Schwierigkeit haben, rasch auf zehn oder zwanzig unterschiedliche Gründe zu kommen.
Ich bin mir außerdem sicher, dass Sie – je nachdem, für welche Fachlichkeit Sie sich entscheiden – die Anwendung durchaus unterschiedlich entwickeln würden: Ein System zum Verwalten der ausgeliehenen Bücher in einer Bibliothek unterscheidet sich klar von einem System für einen großen Onlineshop, und beide sind wiederum etwas ganz anderes als ein System, das Autorinnen und Autoren beim Schreiben von Romanen unterstützen soll.
In allen drei Fällen kann es notwendig sein, ein Buch früher oder später zu aktualisieren, doch der gesamte Workflow darum ist jeweils ein völlig anderer, und abhängig davon würden vermutlich einige Dinge auch unterschiedlich gehandhabt. Ohne vertiefte Kenntnisse des umgebenden Prozesses ist es daher schwierig, Code zu schreiben, der das Richtige tut, und es greift zu kurz, einfach nur UpdateBook umzusetzen.
Langer Rede, kurzer Sinn: Wenn wir ohne die Prozesse zu kennen den Code für die Anwendung nicht adäquat und zielgerichtet schreiben können, sollten wir dann nicht vielleicht versuchen, diese Prozesse zunächst besser zu verstehen? Zu verstehen, worum es bei der gesamten Thematik überhaupt geht? Wer etwas macht? Was diese Person macht? Warum sie das macht? Wann und wie oft sie es macht? Welchen Zweck das Ganze hat? Welche Konsequenzen es nach sich zieht? Und so weiter.
Falls Sie jetzt denken:
"Stimmt, das wäre sinnvoll!"
Dann müssten wir als Nächstes überlegen, wie man Prozesse angemessen beschreiben kann. Eines kann ich Ihnen schon vorab verraten: Die Begriffe Create, Read, Update und Delete sind dabei ziemlich fehl am Platz. Tatsächlich ist die Denkweise in diesen vier Verben sogar ein Antipattern [3].
Doch wenn wir CRUD nicht verwenden können, um fachliche Prozesse zu beschreiben, was machen wir dann stattdessen? Benötigt wird dafür eine Methode, um Geschäftsprozesse als das darzustellen, was sie wirklich sind – nämlich eine Abfolge von Ereignissen. Stellen Sie sich vor, Sie kommen abends nach Hause und Ihre Partnerin oder Ihr Partner fragt, wie Ihr Tag war, woraufhin Sie erzählen, dass zuerst dieses und dann jenes geschehen sei. Sie berichten von Ereignissen, die Sie im Laufe des Tages erlebt haben – und genau das geschieht auch in einem Geschäftsprozess.
Nehmen wir als Beispiel die vorhin bereits kurz erwähnte Bibliothek. Wir können überlegen, welche Prozesse dort überhaupt auftreten: Welche Aktionen finden aus fachlicher Sicht in einer Bibliothek statt?
Man erkennt rasch, dass einer der wichtigsten Vorgänge darin besteht, dorthin zu gehen, um ein Buch zu leihen. Geliehene Bücher müssen über kurz oder lang natürlich auch wieder zurückgegeben werden, doch die Ausleihe kann verlängert werden, sofern niemand anderes das Buch vorbestellt hat. Wer zu spät mit der Rückgabe ist, muss möglicherweise eine Strafe zahlen, und die Bibliothek nimmt regelmäßig neue Bücher in den Bestand auf und entfernt alte, die nicht mehr in gutem Zustand sind.
Hier bemerken Sie bereits, wie reichhaltig die Sprache an dieser Stelle ist und wie viele Verben wir dabei verwenden: Ausleihen, zurückgeben, verlängern, vorbestellen, bezahlen, aufnehmen, entfernen und so weiter.
Vielleicht denken Sie jetzt, es sei doch logisch, auf diese Weise darüber zu sprechen, und im Grunde stimmt das auch. Doch warum findet man dann im Code höchstwahrscheinlich nur eine technisch benannte Funktion (nämlich UpdateBook) und nicht fachlich benannte Funktionen, etwa BorrowBook, RenewBook und ReturnBook?
Das ist eine berechtigte Frage, denn hätten wir diese Funktionen, könnten sie intern selbstverständlich immer noch ein Update oder eine andere Datenbankoperation ausführen, doch unser Code würde plötzlich eine fachliche Geschichte erzählen. Es wäre sehr viel einfacher, im Gespräch mit einer Fachexpertin oder einem Fachexperten nachzuvollziehen, was gemeint ist, weil sich die verwendeten Begriffe auch im Code wiederfinden würden.
Und das möglicherweise nicht nur im Code, sondern sogar auch in der API und in der UI. Wie viel besser könnte ein System gestaltet sein, wenn es auf diesen Begriffen basieren würde, anstatt stets nur von UpdateBook zu sprechen? Wie viel besser könnte eine UI sein? Wie viel effektiver könnte man Anwenderinnen und Anwender in ihrer Intention abholen und unterstützen?
An dieser Stelle kommen wir zum entscheidenden Punkt: Wenn wir zu der Erkenntnis gelangen, dass es besser ist, in unserem Code, in der API, in der UI und auch überall sonst mit fachlichen Begriffen zu arbeiten, anstatt mit technischen, warum modellieren wir dann nicht einfach die fachlichen Ereignisse so, wie sie wirklich stattfinden?
Was in der Realität geschieht, sind nämlich keine Updates, sondern Ereignisse, die wir in der Software nachbilden möchten. Genau aus diesem Grund sollten wir nicht nur in fachlichen Funktionen denken, sondern auch in fachlichen Events. Wenn wir unsere Software so gestalten, dass sie von echten Events angetrieben wird, verfügen wir nämlich plötzlich über eine Architektur und eine Codebasis, die die Realität widerspiegeln, anstatt nur ein unzureichendes technisches Abbild zu sein, das eine sprachliche Kluft und viel Raum für Missverständnisse und Interpretationen hinterlässt.
Genau an dieser Stelle setzt die Event-Modellierung an. Wenn wir akzeptieren, dass unsere Software die fachliche Realität widerspiegeln sollte und dass Events dafür das Mittel der Wahl sind, müssen wir uns zwangsläufig fragen: Wie finden wir die richtigen Events? Welche Ereignisse sind tatsächlich relevant? Welche beschreiben eine Veränderung? Auf welche Weise schneide ich meine Events so, dass sie fachlich sinnvoll sind?
Deshalb möchte ich das Ganze nun anhand eines konkreten Beispiels erläutern, nämlich an unserer bereits bekannten Stadtbibliothek.
Bevor Sie dort überhaupt etwas leihen dürfen, benötigen Sie zunächst einen Ausweis, eine sogenannte Library Card. Viele Entwicklerinnen und Entwickler würden vermutlich damit beginnen, dass man eine Library Card erstellen muss, also mit CreateLibraryCard – und schon befindet man sich wieder in der Denkweise von Create, Read, Update und Delete. Auch wenn das technisch später vielleicht korrekt sein mag, geht es zunächst doch darum, den Prozess aus fachlicher Sicht zu beschreiben.
Niemand würde eine Bibliothek betreten und sagen:
"Created mir bitte einen Bibliotheksausweis!"
Stattdessen würde man wohl fragen, wie ein solcher Ausweis beantragt werden kann. Genau dies ist der erste Schritt unseres Prozesses. Die Frage lautet also: Welcher Begriff trifft das Ganze fachlich am besten? Die Formulierung "Ausweis beantragen" passt aus meiner Sicht schon recht gut. Allerdings ist "Ausweis beantragen" noch kein Event. Es müsste nämlich in der Vergangenheitsform stehen, also "Ausweis wurde beantragt".
Das ergibt Sinn, denn wenn Sie sich vorstellen, abends nach Hause zu kommen und gefragt zu werden, wie Ihr Tag war, würden Sie ebenfalls in der Vergangenheitsform erzählen. Bei Bedarf lässt sich das Ganze dann schlussendlich noch ins Englische übertragen, was dann einem "Applied for a Library Card"-Event entsprechen würde.
Als Nächstes würde der Ausweis vermutlich ausgestellt. Vielleicht denken Sie jetzt:
"Alles klar, dann haben wir aber jetzt ein Create."
In der Vergangenheitsform wäre das ein "Library Card Created"-Event. Rein sprachlich wäre das korrekt, allerdings hatte ich erwähnt, dass der Ausweis ausgestellt wird. Einen Ausweis auszustellen bedeutet jedoch nicht "Create a Library Card", sondern eher "Issue a Library Card". Daher hätten wir also eher ein "Library Card Issued"-Event.
Vielleicht wenden Sie nun ein, dass das letztlich Wortklauberei sei. Ob nun create oder issue – das sei doch egal, man wisse schließlich, was gemeint ist. Der springende Punkt ist jedoch: Das weiß man eben gerade leider nicht. Wir hatten gerade selbst die Situation, dass wir zwei verschiedene Ereignisse – nämlich das Beantragen und das Ausstellen des Ausweises – zunächst beide als create bezeichnen wollten. Hätten wir das getan, hätten wir nun bereits zwei Prozessschritte, die wir sprachlich nicht voneinander unterscheiden könnten.
Indem wir versuchen, fachlich passende und semantisch ausdrucksstarke Wörter zu finden, präzisieren wir unsere Sprache. Wir erhalten dadurch nicht nur ein genaueres Verständnis darüber, worum es fachlich geht, sondern nähern uns sprachlich auch der Fachabteilung an. Genau diese Kombination führt dazu, dass wir besser miteinander kommunizieren, Wünsche und Anforderungen besser verstehen und auf diese Weise letztlich in der Lage sind, bessere Software in kürzerer Zeit zu entwickeln.
Wie viel hilfreicher ist nämlich bitte die Frage:
"Okay, wir haben jetzt implementiert, dass man Ausweise beantragen kann und dass diese anschließend ausgestellt werden können, was ist der nächste Schritt?"
im Vergleich zu der Aussage:
"Wir haben jetzt CreateAusweis implementiert, wir machen dann als Nächstes UpdateAusweis.“
Ersteres bietet eine hervorragende Basis für ein zielgerichtetes Gespräch mit einer fachkundigen Person, während Letzteres eine vage, technische Äußerung darstellt, die kaum etwas aussagt und wahrscheinlich jede weitere Kommunikation verhindert.
Dieses Prinzip, sprachlich präzise zu sein und fachliche statt technischer Begriffe zu verwenden, sollten wir konsequent fortführen: Ein Bibliotheksausweis allein bringt noch nicht viel, er bildet lediglich die Voraussetzung dafür, dass wir überhaupt Bücher ausleihen dürfen. Und genau das wäre vermutlich der nächste Schritt im Prozess: Ein Buch auszuleihen.
Nun stellt sich erneut die Frage, wie dieses Event genannt werden sollte. Sprechen wir einfach von einem BookBorrowed-Event? Oder existieren möglicherweise Unterschiede? Wird ein Buch beispielsweise sofort ausgeliehen, oder muss es erst reserviert werden, um es später abzuholen? Welche Bedingungen müssen erfüllt sein, damit die Ausleihe tatsächlich stattfindet? All das sind Überlegungen, die wir nur anstellen, wenn wir sprachlich präzise bleiben und uns eng an der Fachsprache orientieren, da uns genau das dazu zwingt, uns inhaltlich mit der Fachlichkeit auseinanderzusetzen. Dies ist gut. Auf diese Weise entstehen nach und nach die verschiedenen Events, die in der jeweiligen Fachdomäne eine Rolle spielen.
Ein weiterer Vorteil besteht darin, dass sich dies wunderbar gemeinsam umsetzen lässt: Die Entwicklungsabteilung und die Fachabteilung kommen zusammen, sodass ein Gespräch entsteht und beide in eine gemeinsame Richtung arbeiten. Es handelt sich nicht um ein Gegeneinander (wie es sonst so häufig der Fall ist), sondern um ein Miteinander. Die Fachabteilung hat schließlich ein Interesse daran, dass die Entwicklung versteht, worum es geht, denn nur dann kann sie eine adäquate und zielgerichtete Software erstellen. Dies gilt selbstverständlich auch in umgekehrter Richtung. Genau diese Herangehensweise – die Fachlichkeit in den Vordergrund zu rücken – macht das Prinzip so mächtig.
Vielleicht fragen Sie sich jetzt, ob es dafür nicht bereits einige fertige Workshop-Formate gibt. Tatsächlich existiert eine ganze Reihe, etwa Event Storming, Event Modeling oder Domain Storytelling. Diese Formate verfolgen jeweils einen etwas anderen Ansatz: Domain Storytelling eignet sich beispielsweise sehr gut dafür, überhaupt erst einmal einen Fuß in eine Fachdomäne zu setzen, während Event Storming und Event Modeling sehr in die Tiefe gehen und teils auch technische Details beleuchten.
Deshalb würde ich zumindest anfangs zu Domain Storytelling raten: Es ist zum Glück leicht zu erlernen, und es gibt ein interessantes Buch zu diesem Thema [4].
Letztlich spielt es jedoch keine große Rolle, welche dieser Methoden Sie verwenden oder ob Sie überhaupt eine davon nutzen. Wichtig ist nur, dass Sie eine gemeinsame Basis schaffen – mit einer gemeinsamen Sprache und einem gemeinsamen Verständnis. Der Weg dorthin ist letztlich zweitrangig. Nehmen Sie daher einfach das, was Ihnen am ehesten zusagt. Wählen Sie das, womit Sie sich wohlfühlen. Entscheiden Sie sich für das, wo Sie möglicherweise schon jemanden kennen oder finden, der Sie dabei unterstützt und den Prozess anleitet oder moderiert.
Vielleicht fragen Sie sich zum Schluss noch, warum Sie das alles speziell in dieser Event-Form gestalten sollten. Man könnte anstelle von "Ausweis wurde beantragt", "Ausweis wurde ausgestellt", "Buch wurde ausgeliehen" und so weiter ebenso gut Formulierungen im Indikativ verwenden, also in der Grundform, beispielsweise "Ausweis beantragen", "Ausweis ausstellen", "Buch ausleihen" und so weiter.
Die fachlichen Verben wären dort schließlich ebenfalls enthalten. Das ist im Grundsatz richtig, aber es gibt gewissermaßen noch einen Bonus, wenn Sie die Event-Form verwenden. Es ist sozusagen die sprichwörtliche Kirsche auf der Torte. Sobald Sie diese geschäftlichen Ereignisse in der Event-Form ausdrücken, erhalten Sie die ideale Ausgangsbasis, um die Events in einem geeigneten Protokoll zu speichern, ähnlich einem Logbuch.
Dies wiederum bietet eine Vielzahl von Vorteilen von einer deutlich besseren Transparenz darüber, was wann und warum von wem durchgeführt wurde, über ein integriertes Audit-Log bis hin zu sehr flexiblen Möglichkeiten für Analysen und Reports. Das kann man sich leicht vorstellen: Wenn Sie nur wissen, dass ein Buch gerade ausgeliehen ist, kennen Sie diesen Zustand, aber sonst nichts. Wenn Sie jedoch die komplette Historie kennen, die im Laufe der Zeit zum aktuellen Status quo geführt hat, können Sie unzählige Fragen beantworten, auch wenn Ihnen zuvor nicht klar war, dass diese Informationen später von Interesse sein würden. Dazu zählen Fragen wie:
Diese Art der Datenspeicherung nennt man Event Sourcing, und dazu habe ich vor einigen Wochen bereits einen Beitrag geschrieben [5]. Der Vorteil daran ist, dass Sie gleich drei Fliegen mit einer Klappe schlagen, wenn Sie fachliche Prozesse konsequent als Events formulieren:
Übrigens war ich vor ungefähr zehn Tagen in einem sehr interessanten Podcast zu Gast – dem Engineering Kiosk [7] –, wo wir uns eineinhalb Stunden lang ausführlich über das Zusammenspiel all dieser Themen unterhalten haben. Wenn Sie das interessiert, schauen oder hören Sie dort gerne einmal vorbei.
URL dieses Artikels:
https://www.heise.de/-10292363
Links in diesem Artikel:
[1] https://www.heise.de/blog/75-Prozent-aller-Softwareprojekt-scheitern-was-tun-9979648.html
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=MoWynuslbBY
[4] https://www.youtube.com/watch?v=EaKWQ1rsaqQ
[5] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[6] https://www.youtube.com/watch?v=hP-2ojGfd-Q
[7] https://engineeringkiosk.dev/podcast/episode/183-event-sourcing-die-intelligente-datenarchitektur-mit-semantischer-historie-mit-golo-roden/
[8] mailto:rme@ix.de
Copyright © 2025 Heise Medien
In this release, we have restarted to focus on features. A long-awaited feature has been added, namely sorting articles by various criteria: received date (existing, default), publication date, title, link, random.
A few highlights ✨:
&get=A, and also those archived with &get=Z
This release has been made by @Alkarex, @b-reich, @hkcomori, @math-GH, @UserRoot-Luca
and newcomers @a6software, @aftix, @bl00dy1837, @brtmax, @Roan-V, @ShaddyDC, @UncleArya
Full changelog:
&get=A, and also those archived with &get=Z #7144
intext: #7228force-https.txt #7259
(Bild: Pincasso/Shutterstock)
Man kann in C# 13.0 neuerdings auch mit dem Index vom Ende ein Array initialisieren.
Bisher schon konnte eine Initialisierung von Mengen wie Arrays mit Indexer × = y erfolgen. In C# 13.0 ist eine Array-Initialisierung auch mit Index vom Ende [^x] = y möglich mit dem Index-Operator ^, den es seit C# 8.0 gibt.
Die neue Syntax ist allerdings nur bei der Erstinitialisierung des Objekts möglich, nicht bei anderen Zuweisungen.
Folgendes Codebeispiel zeigt die Objektmengen-Initialisierung mit Index von vorne × und vom Ende [^x]:
namespace NET9_Console.CS13;
internal class CS13_Indexer
{
class ZahlenGenerator
{
public string[] Ziffern = new string[10];
}
/// <summary>
/// C# 13.0: Objekt-Initialisierung mit Index vom Ende [^x] ("Implicit Indexer Access in Object Initializers")
/// </summary>
public void Run()
{
CUI.Demo(nameof(CS13_Indexer));
CUI.H2("Array-Initialisierung mit Indexer von vorne nach hinten");
var dAlt = new ZahlenGenerator()
{
Ziffern = {
[0] = "null",
[1] = "eins",
[2] = "zwei",
[3] = "drei",
[4] = "vier",
[5] = "fünf",
[6] = "sechs",
[7] = "sieben",
[8] = "acht",
[9] = "neun",
}
};
foreach (var z in dAlt.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Initialisierung mit Indexer von hinten nach vorne");
var dNeu = new ZahlenGenerator()
{
Ziffern = {
[^1] = "neun",
[^2] = "acht",
[^3] = "sieben",
[^4] = "sechs",
[^5] = "fünf",
[^6] = "vier",
[^7] = "drei",
[^8] = "zwei",
[^9] = "eins",
[^10] = "null"
}
};
foreach (var z in dNeu.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Initialisierung mit Indexer in beide Richtungen");
var dNeu2 = new ZahlenGenerator()
{
Ziffern = {
[^1] = "neun",
[^2] = "acht",
[^3] = "sieben",
[^4] = "sechs",
[^5] = "fünf",
[4] = "vier",
[3] = "drei",
[2] = "zwei",
[1] = "eins",
[0] = "null"
}
};
foreach (var z in dNeu2.Ziffern)
{
Console.WriteLine(z);
}
CUI.H2("NEU: Array-Befüllung zu einem späteren Zeitpunkt");
// erstelle ein Array von int mit 10 Elementen
int[] array1 = new int[10] { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
// das geht nicht, Syntax nur bei Objektinitialisierung im Rahmen der Instanziierung erlaubt
//array1 = {
// [^1] = 9,
// [^2] = 8,
// [^3] = 7,
// [^4] = 6,
// [^5] = 5,
// [0] = 0,
// [1] = 1,
// [2] = 2,
// [3] = 3,
// [4] = 4
// }
// hier geht nur das:
array1[^1] = 9;
array1[^2] = 8;
array1[^3] = 7;
array1[^4] = 6;
array1[^5] = 5;
array1[0] = 0;
array1[1] = 1;
array1[2] = 2;
array1[3] = 3;
array1[4] = 4;
foreach (var item in array1)
{
CUI.LI(item);
}
}
}
URL dieses Artikels:
https://www.heise.de/-10290670
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock)
In C# 13 dürfen bei den variadischen Parametern generische Mengentypen statt eines Array verwendet werden.
Seit der ersten Version von C# gibt es Parameter-Arrays für sogenannte variadische Parameter (vgl. Wikipedia-Eintrag zu variadischen Funktionen [1]), mit denen eine Methode eine beliebig lange Liste von Parametern eines Typs empfangen kann, wenn dies mit dem Schlüsselwort params eingeleitet wird.
Der folgende Code zeigt die bisherige Variante eines variadischen Parameters mit Arrays:
public void MethodeMitBeliebigVielenParametern_Alt(string text,
params int[] args)
{
CUI.H2(nameof(MethodeMitBeliebigVielenParametern_Alt));
CUI.Print(text + ": " + args.Length);
foreach (var item in args)
{
CUI.LI(item);
}
}
Die Methode kann man beispielsweise folgendermaßen aufrufen:
MethodeMitbeliebigVielenParametern_Alt("Anzahl Zahlen", 1, 2, 3);
MethodeMitbeliebigVielenParametern_Alt("Number of numbers",
1, 2, 3, 4);Neu in C# 13.0 ist, dass statt eines Arrays bei den variadischen Parametern auch generische Mengentypen verwendet werden dürfen (sogenannte Parameter Collections) wie params Span<T>:
public void MethodeMitBeliebigVielenParametern_Neu(string text,
params Span<int> args)
{
CUI.H2(nameof(MethodeMitBeliebigVielenParametern_Neu));
CUI.Print(text + ": " + args.Length); // statt args.Length
foreach (var item in args)
{
CUI.LI(item);
}
}
Analog ist der Aufruf dann genauso flexibel möglich wie beim Parameter-Array:
MethodeMitBeliebigVielenParametern_Neu("Anzahl Zahlen", 1, 2, 3);
MethodeMitBeliebigVielenParametern_Neu("Number of numbers",
1, 2, 3, 4);Dann sind diese generischen Mengentypen bei params in C# 13.0 erlaubt:
Collections.Generic.IEnumerable<T>System.Collections.Generic.IReadOnlyCollection<T>Collections.Generic.IReadOnlyList<T>System.Collections.Generic.ICollection<T>Collections.Generic.IList<T> Collections.Generic.IEnumerable<T>implementierenSpan<T>ReadOnlySpan<T>Wenn möglich, sollte man die Parameterliste per Span<T> oder ReadOnlySpan<T> übergeben, damit die Parameterübergabe komplett per Stack erfolgt und keinerlei Speicherallokation auf dem Heap erfolgen muss.
Ebenso wie man bei einem Parameter-Array auch ein fertiges Array übergeben kann, das dann auf die Parameter verteilt wird
MethodeMitBeliebigVielenParametern_Alt(
"Anzahl Zahlen - übergeben als Int-Array",
[1, 2, 3]);kann man auch einen der obigen neuen Typen übergeben, wenn die Methode eine Parameter Collection erwartet:
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
new List<int> { 1, 2, 3 });oder
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
[1, 2, 3]);Achtung: Die folgende Syntax funktioniert aber nicht:
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
new List<int> [1, 2, 3 ]);Das ist nicht möglich, da new List<int> [1, 2, 3 ] ein dreidimensionales Array von List<int> erzeugt.
URL dieses Artikels:
https://www.heise.de/-10282100
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/Variadische_Funktion
[2] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Viele Unternehmen sparen an der Codequalität: zu aufwendig und zu teuer. Diese Argumentation ist nicht nur falsch, sondern langfristig auch gefährlich.
Ich nehme an, Sie kennen das Phänomen: Sie arbeiten an einem Softwareprojekt und entdecken einen Fehler. Eigentlich sollten Sie ihn gleich beheben, doch Sie sind derzeit mit einem Feature beschäftigt, das ohnehin schon verspätet ist. Um den Fehler zu beheben, müssten Sie zudem eine Abhängigkeit aktualisieren, was allerdings nicht ohne Weiteres möglich ist, weil Sie dann in einigen Bereichen des Codes Anpassungen vornehmen müssten.
Da Sie ohnehin schon spät dran sind, treffen Sie die einzig denkbare Entscheidung: Sie verschieben den Bugfix auf "später". Der springende Punkt dabei ist jedoch: Dieses "später" tritt nie ein. Das bedeutet, nach einiger Zeit stehen Sie vor einem großen Berg technischer Schulden und fragen sich: Wie konnte es überhaupt jemals so weit kommen?
Diese Situation ist keineswegs neu. Sie trägt sogar einen Namen: die "Broken-Windows-Theorie [1]". Damit ist nicht gemeint, dass das Betriebssystem Windows erneut defekt ist, sondern der Begriff stammt aus der Stadtplanung. Die zugehörige Idee ist simpel und zugleich wirksam: Es geht darum, warum in bestimmten Stadtteilen Kriminalität offenbar ungebremst um sich greifen kann. Die These der Broken-Windows-Theorie besagt, dass dies geschieht, wenn Stadtteile vernachlässigt werden. Wenn zum Beispiel Gebäude dauerhaft leer stehen und nicht – wie möglicherweise lange geplant – abgerissen werden.
Als Symbol dafür wählten die US-amerikanischen Sozialforscher James Wilson und George Kelling in den frühen 1980er-Jahren das zerbrochene Fenster: Wenn eine Fensterscheibe zerbricht und niemand sie ersetzt, zeigt das, dass sich niemand darum kümmert. Da jedoch niemand neben einem leer stehenden Haus mit einer dauerhaft zerbrochenen Scheibe leben möchte, ziehen bald darauf die ersten Nachbarn fort.
Daraus folgen weitere leer stehende Häuser, und jemand wirft dort vermutlich früher oder später ebenfalls eine Fensterscheibe ein. So entsteht langsam eine Kettenreaktion, in der das Viertel weiter verfällt, der soziale Zusammenhalt nachlässt und es irgendwann sehr schwierig werden kann, noch etwas zu ändern, selbst wenn es jemand möchte. Dadurch sinkt die Hemmschwelle gegenüber Kriminalität, was letztlich den gesamten Prozess nur weiter beschleunigt.
Die entscheidende Frage lautet nun, wie sich eine solche Entwicklung wieder unter Kontrolle bringen lässt. Tatsächlich gibt es darauf eine Antwort, die in der Vergangenheit bereits funktioniert hat, etwa in New York in den 1990er-Jahren. Dort beschrieb die eingangs geschilderte Lage ziemlich genau den Status quo, und der damalige Bürgermeister (von 1994 bis 2001 war dies Rudolph Giuliani, den Sie vielleicht als ehemaligen Rechtsberater von Donald Trump kennen) verfolgte eine sogenannte "Zero-Crime-Tolerance"-Strategie.
Dabei geht es, wie der Name erahnen lässt, darum, bei jeglichen Verstößen – auch bei kleineren Vergehen wie Falschparken – keinerlei Nachsicht walten zu lassen. Das hatte insofern Erfolg, als die Kriminalitätsrate in den folgenden Jahren stark sank. Allerdings sollte man nicht unterschlagen, dass diese konsequente Polizeipräsenz wiederum kritisiert wurde, da sie manchem zu weit ging. Gerade aus den USA hört man immer wieder von Polizeigewalt und rassistischem Vorgehen, was man natürlich genauso wenig möchte. Zusammengefasst ist es also schwierig, die richtige Balance zu finden, doch eine Null-Toleranz-Strategie trägt natürlich wesentlich dazu bei, wuchernde Kriminalität einzudämmen.
Was hat das nun mit Softwareentwicklung zu tun? Nun, die Broken-Windows-Theorie lässt sich hervorragend auf Softwareprojekte übertragen. Zusammengefasst: Jeder nicht behobene Fehler ist ein zerbrochenes Fenster. Jede Codezeile, die gepflegt werden müsste, aber nicht wird, ist ein zerbrochenes Fenster. Jede veraltete Abhängigkeit, die nicht aktualisiert wird, ist ein zerbrochenes Fenster. Und so weiter. Anders ausgedrückt: Wenn Sie sich nicht konsequent mit einer Null-Toleranz-Strategie um die eigene Codebasis kümmern, führt dies zwangsläufig zu einer Abwärtsspirale in Ihrem Projekt.
Warum ist das so? Weil sich Fehler und technische Schulden addieren. Das bedeutet, dass der Aufwand, sie irgendwann zu beheben, stetig größer wird. Gleichzeitig steigt auch das Risiko, dabei etwas kaputtzumachen. Beides zusammen sorgt dafür, dass niemand sich mehr an den Code wagt, was wiederum nur zu weiteren Fehlern und noch mehr technischen Schulden führt. Man errichtet so ein Fundament, das von Beginn an instabil ist, baut darauf immer weiter auf und macht dieses Gebilde dadurch noch fragiler, bis es zu einem Kartenhaus verkommt, das unweigerlich in sich zusammenfallen muss.
Zusätzlich besteht dann die Angst, bestehende Module anzupassen oder zu erweitern, weil man nicht weiß, ob eine Funktion möglicherweise eine tragende Karte dieses fragilen Konstrukts ist. Folglich umschiffen alle den vorhandenen Code, was die Entwicklung kompliziert, langsam und teuer macht. Und aufgrund dieser Instabilität will sich auch niemand mehr an externe Abhängigkeiten heranwagen, weil dies Aufwand bedeutet. Also bleibt man lieber bei jenen Versionen, die augenscheinlich funktionieren, was jedoch auf lange Sicht die Aktualisierungsmöglichkeiten verbaut und rasch zu Sicherheitslücken oder nicht behobenen Problemen führt.
Offensichtlich ist es riskant, sich nicht um die Codequalität eines Projekts zu kümmern. Doch es kommt noch ein weiterer Faktor hinzu: Denn wer sind die ersten Nachbarn, die eine Gegend mit zerbrochenen Fenstern verlassen? Das sind stets jene, die sich das problemlos leisten können. In Softwareprojekten sind es folglich häufig die besonders fähigen Entwicklerinnen und Entwickler, die als Erste gehen – und das sind leider genau die Personen, die Sie am dringendsten bräuchten, um die Situation noch zu retten, da sie über umfassendes Fachwissen und Erfahrung verfügen.
Das klingt überaus dramatisch. Aber so stellt sich die Realität dar. Selbstverständlich können Sie die Augen davor verschließen und sich einreden, bei Ihrem eigenen Projekt sei alles vollkommen anders. Vermutlich finden Sie auch zahlreiche Argumente, weshalb die Entwicklung bei Ihnen gar nicht anders laufen könne. Doch genau damit reden Sie sich die Lage schön. Die Augen zu schließen und zu glauben, andere könnten Sie dann nicht mehr sehen, das ist ein Verhalten, das vielleicht im Kindergarten Sinn ergibt, aber in der Softwareentwicklung schlicht nicht funktioniert. Erschreckend finde ich, wie viele Unternehmen genau diesen Ansatz trotzdem immer und immer wieder wählen.
Möglicherweise fragen Sie sich jetzt, woran Sie konkret erkennen, dass in Ihrem Softwareprojekt bereits einige Scheiben zerbrochen sind. Daher möchte ich Ihnen ein paar typische Anzeichen nennen. Diese Liste hat keine festgelegte Reihenfolge, ich führe sie schlicht so auf, wie sie mir in den Sinn kommt.
Indizien für zerbrochene Fenster sind beispielsweise auffallend lange und womöglich weiter ansteigende Build- und Deployment-Zeiten. Auch Code, der immer öfter Kommentare wie "TODO" oder "FIXME" enthält, sollte Sie nachdenklich stimmen. Wenn Sie regelmäßig Workarounds und provisorische Lösungen umsetzen, anstatt Probleme gründlich zu beseitigen, ist dies ein Warnsignal. Sinkt die Testabdeckung im Laufe der Zeit, treten Fehler erneut auf, die schon einmal behoben worden waren, existiert keine Dokumentation oder ist sie fehlerhaft beziehungsweise veraltet, dann sind das alles Anzeichen für zerbrochene Fenster.
Wenn es Codebereiche gibt, die niemand anfassen will, wenn Ihre Dependencies nicht auf dem neuesten Stand sind, wenn immer mehr Tickets für technische Aufgaben auflaufen – das alles sind Hinweise, dass etwas nicht stimmt. Und all diese Vorkommnisse sind wie Eisberge: Was Sie zuerst sehen, ist immer nur die Spitze, und das wahre Ausmaß bleibt verborgen. Unterschätzen Sie die Lage also nicht, indem Sie sie als unwichtige Kleinigkeiten abtun. Oft ist das tatsächliche Problem viel größer, als es zunächst scheint.
Das erste typische Gegenargument lautet:
"Ach, das sind doch alles nur Kleinigkeiten!"
Genau diesen Einwand habe ich eben schon vorweggenommen. Interessant ist aber, dass es zahlreiche solche Bedenken gibt. Hier sind wir an dem Punkt, dass sich viele Unternehmen die Problematik schönreden. Und was sind verbreitete Einwände?
Sehr verbreitet ist beispielsweise:
"Ja, grundsätzlich stimmt das alles, aber wir haben keine Zeit. Wir müssen eine Deadline einhalten."
Diese Aussage lässt sich üblicherweise auf zwei Situationen zurückführen:
Ein weiteres häufiges Gegenargument lautet:
"Regelmäßige Codepflege können wir uns nicht leisten, das wäre zu teuer!"
Auch das ist nicht haltbar, denn hier zeigt sich, dass das eigentliche Problem schon vor etlichen Jahren seinen Lauf nahm. Codepflege ist nämlich nur dann kostspielig, wenn sie zu lange hinausgezögert wurde. Natürlich gibt es Bereiche, die mehr Aufwand bedeuten, doch wenn Sie diese von Beginn an zeitnah erledigen, fallen die Kosten viel niedriger aus, als wenn Sie sie wiederholt vertagen, um sie irgendwann inmitten anderer dringender Aufgaben angehen zu müssen, ohne Zeit und Planung.
Vergleichbar ist das mit einem Haushalt, der nie aufgeräumt wird, stets mit dem Argument, es sei jetzt zu viel Aufwand, bis Sie irgendwann gar kein sauberes Geschirr mehr besitzen und die Wohnung voller Müll liegt, sodass Sie darüber stolpern, hinfallen und sich verletzen. Genau in diesem Moment stellen Sie fest, dass gerade in der Küche ein Feuer ausgebrochen ist, weil dort unbeaufsichtigt ein Topf auf dem Herd stand. Und schon wird die Angelegenheit richtig teuer, womöglich erfordert sie sogar eine Renovierung. War der Plan "sofortiges Aufräumen ist zu viel Aufwand" also wirklich so sinnvoll? Ganz bestimmt nicht.
Gerne wird auch argumentiert:
"Alles funktioniert doch im Großen und Ganzen – wir werden tätig, sobald tatsächlich etwas kaputtgeht."
Das wird gerne noch mit "Never Touch a Running System" unterstrichen. Selbstverständlich sollten Sie nicht ohne konkreten Anlass an funktionierendem Code herumbasteln. Aber es geht nicht ums bloße "Herumbasteln", sondern darum, vorhandene technische Schulden abzutragen, um langfristige Schäden zu vermeiden. Häufig steckt hinter diesem Einwand schlicht die Sorge, bei Umbauten könnte etwas kaputtgehen. Und diese Angst ist in gewisser Weise berechtigt. Doch woher rührt sie? Liegt es daran, dass zu wenige automatisierte Tests existieren? Oder vielleicht gar keine? Gibt es auch kein strukturiertes Testkonzept?
In einem solchen Kontext würde wohl niemand unnötige Änderungen riskieren. Dennoch sollte es normal sein, Code zu revidieren, zu überarbeiten und anzupassen. Die einzige Möglichkeit, sicherzustellen, dass dabei nichts zerbricht, sind umfangreiche Tests, am besten automatisiert, damit sie jederzeit effizient wiederholbar sind. Dass viele Projekte darauf weitgehend verzichten, liegt oft daran, dass jemand meinte, Tests seien zu aufwendig und deshalb nicht so wichtig.
Ein weiteres verbreitetes Argument lautet, dass es zu viel Druck aus dem Fachbereich gäbe. Meistens sind das schlicht unrealistische Erwartungen, verbunden mit wenig Verständnis für die Abläufe in der Softwareentwicklung. Das ist grundsätzlich nachvollziehbar: Denn woher soll ein Fachbereich ohne technische Vorerfahrung es besser wissen? Häufig fehlt dann eine Person, die die Interessen der Entwicklung angemessen vertritt und erklärt, wie Softwareentwicklung funktioniert.
Dieser Effekt zeigt sich meist in Unternehmen, deren Kerngeschäft nicht die Softwareentwicklung an sich ist, sondern beispielsweise in Versicherungen, Baukonzernen, dem Einzelhandel und so weiter, wo Software nur ein notwendiges, aber ungeliebtes Hilfsmittel ist. Dort gilt meist "Umsatz vor Grundsatz". Der Fachbereich setzt sich also oft durch, sodass die Softwareentwicklung mit ihren Qualitätsansprüchen außen vor bleibt. Wird dies nicht klar kommuniziert, entsteht massiver Druck von dieser Seite.
Man könnte diese Liste beliebig fortsetzen, aber ich denke, hier wird bereits ein Muster deutlich. Das Muster lautet: Kurzfristiges Denken hat zu oft Vorrang vor langfristigen Überlegungen. Viel zu häufig geht es um eine rasche, günstige Fertigstellung, ohne den Blick auf langfristige Stabilität und Wartbarkeit. Dieses Problem entsteht nicht erst nach und nach, sondern es existiert meist schon ab dem ersten Tag eines Softwareprojekts, bleibt anfangs aber unbemerkt.
Jeder Schritt, bei dem nicht auch an die spätere Weiterentwicklung gedacht wird, führt in die falsche Richtung. Das resultiert unweigerlich in zerbrochenen Fenstern. Wenn es dann wirklich brennt, möchte niemand eine abrupte Kehrtwende vornehmen, denn schließlich hat doch bis gestern scheinbar alles funktioniert. Das Hinauszögern setzt sich also fort, und das Problem verschlimmert sich noch mehr. Erst wenn irgendwann unübersehbar ist, dass es so nicht weitergehen kann, folgt das große Klagen und die Hoffnung, nun eine einfache Lösung zu finden. Doch eine solche existiert nicht – und das will dann verständlicherweise niemand hören.
Welche Lehre lässt sich aus all dem ziehen?
Erstens: Wenn Sie früh genug dran sind und Ihr Projekt noch auf der sprichwörtlichen grünen Wiese beginnt, sollten Sie von Tag 1 an eine echte Null-Toleranz-Strategie im Hinblick auf Codequalität verfolgen. Das bedeutet, Sie benötigen ein äußerst strenges Projektsetup. Dazu gehören beispielsweise streng konfigurierte Linter-Regeln, automatisierte Formatierung, angemessene Tests sowie eine CI/CD-Pipeline. Es dürfen keinerlei Warnungen von Linter oder Compiler akzeptiert werden: Entweder ist der Code rundum fehlerfrei, oder der Build schlägt fehl. Dazwischen gibt es nichts.
Ebenso sollte kontinuierliches Refactoring einen hohen Stellenwert haben, und Fehler sollten sofort beseitigt werden. Natürlich wird es niemals vollkommen fehlerfreie Software geben, doch sobald ein Fehler bekannt ist, genießt dessen Behebung oberste Priorität. Solange dieser Bug nicht korrigiert ist, wird kein neues Feature entwickelt, eben konsequent gemäß dem Prinzip "Null Toleranz".
Falls nun jemand behauptet, dies wäre ein Freibrief für die Entwicklung, sich in Details zu verlieren, ist das wahre Problem nicht die Null-Toleranz-Strategie, sondern tief sitzendes Misstrauen gegenüber dem Verantwortungsbewusstsein der Entwickler. Das ist ein viel grundlegenderes Thema, das gern ignoriert wird, weil es wesentlich einfacher scheint, Symptome zu bekämpfen als Ursachen.
Zweitens sollten Sie alles, was möglich ist, automatisieren: Tests, Deployments, Updates und so weiter. Letztlich greift hier alles ineinander. Stellen Sie sich vor, es erscheint ein Update für eine Abhängigkeit: Zunächst müssten Sie erfahren, dass es dieses Update gibt. Danach müssten Sie es testweise einspielen, prüfen, ob weiterhin alles funktioniert, einen Branch erstellen, den Commit vornehmen, pushen, einen Pull-Request anlegen und jemanden finden, der das Ganze prüft und freigibt. Natürlich wird sich niemand regelmäßig diesen Aufwand antun wollen.
Wenn jedoch ein Bot automatisch einen Pull-Request stellt, der dann eine CI/CD-Pipeline anstößt und sämtliche Tests ausführt, Sie über die Ergebnisse informiert werden, und Ihre einzige Aktion (zumindest in 95 Prozent der Fälle) darin besteht, den erfolgreich durchgelaufenen Pull-Request durchzuwinken, dann bleibt Ihr Zeitaufwand minimal. Gleichzeitig bleiben Ihre Dependencies auf dem aktuellen Stand, und Sie haben nun auch die zeitlichen Kapazitäten, sich um jene 5 Prozent zu kümmern, bei denen tatsächlich manuelles Eingreifen nötig ist, etwa wegen Breaking Changes. Dies funktioniert aber nur, wenn Sie die betreffenden Prozesse entsprechend automatisiert haben.
Damit komme ich zum letzten Punkt, den ich Ihnen heute mitgeben möchte: Code-Reviews und das Vier-Augen-Prinzip ab Tag 1. Nur so ist sichergestellt, dass jede Änderung geprüft wird und es zudem kein Inselwissen gibt. Nach einem Review haben zumindest zwei Personen den Code durchgesehen und sich damit auseinandergesetzt. Alternativ können Sie auch Pair-Programming nutzen, denn das ist im Grunde lediglich ein Live-Review. Wahrscheinlich hören Sie jetzt schon das Argument, dass dies zu kostenintensiv sei und keine Zeit dafür bleibe, wegen Deadlines, Fachbereich und so weiter. Aber vielleicht haben Sie durch diesen Blogpost ein paar Argumente an der Hand, um all dem zukünftig souveräner zu begegnen.
Unter dem Strich bleibt die Erkenntnis, dass eine dauerhafte, regelmäßige Pflege des Codes langfristig zu weit stabileren und damit auch günstigeren Projekten führt, selbst wenn es anfangs gegen die Intuition sprechen mag.
URL dieses Artikels:
https://www.heise.de/-10284004
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/Broken-Windows-Theorie
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: erzeugt mit KI durch iX)
Man hört oft, komplexe Systeme basierten auf CQRS. Doch was genau ist das eigentlich, CQRS? Was verbirgt sich hinter dem Akronym, und wie kann man es nutzen?
Vor zwei Wochen habe ich einen Blogpost als Einführung in Event-Sourcing [1] geschrieben. Das Thema ist bei vielen von Ihnen auf sehr großes Interesse gestoßen, es gab sehr viel Feedback dazu, und natürlich gab es auch eine ganze Reihe von Fragen. Im heutigen Blogpost greife ich viele dieser Fragen auf und beantworte sie. Sie bekommen aber vor allem auch eine weitere Einführung in ein mit Event-Sourcing zusammenhängendes Konzept: Heute geht es nämlich auch um ein Architektur-Pattern namens CQRS. Was das ist, wofür es gut ist, wie es funktioniert, was die Anwendungsfälle sind, wie Sie es mit Event Sourcing kombinieren können, und so weiter – all das erfahren Sie heute.
Fangen wir einmal, ganz kurz, mit einer Klarstellung an: Vielleicht haben Sie von CQRS schon gehört, und Sie würden nun gerne wissen, was genau es damit auf sich hat, aber vielleicht haben Sie den Blogpost zu Event Sourcing vor zwei Wochen nicht gelesen. Da stellt sich nun die Frage: Können Sie den heutigen Post trotzdem "einfach so" lesen, oder sollten Sie sich zuerst mit dem Thema Event Sourcing beschäftigen?
Nun, dafür ist ganz wichtig: CQRS und Event Sourcing sind zwei Konzepte, die unabhängig voneinander existieren. Das heißt, Sie können CQRS durchaus umsetzen, ohne Event Sourcing nutzen zu müssen, und Sie können Event Sourcing auch umsetzen, ohne CQRS nutzen zu müssen, und insofern könnten Sie diesen Blogpost auch als in sich geschlossenes Thema ansehen.
Aber: Die beiden Konzepte ergänzen einander ausgesprochen gut. Insofern werden Sie sie in der Praxis eher selten isoliert voneinander vorfinden, sondern in der Regel gemeinsam. Deshalb baue ich in diesem heutigen Blogpost auf dem auf, was ich vor zwei Wochen geschrieben habe. Sollten Sie jenen Blogpost [2] also noch nicht gesehen haben, dann würde ich Ihnen empfehlen, das jetzt nachzuholen. Alternativ können Sie ihn sich auch als Video [3] ansehen.
Doch was ist CQRS überhaupt? Das Akronym steht für "Command Query Responsibility Segregation", also für die Trennung der Verantwortlichkeiten für Commands und Queries.
Tatsächlich ist das sehr viel einfacher, als es zunächst klingt. Die Kernidee von CQRS ist, dass es für den Zugriff auf Anwendungen nur zwei Arten von Interaktionsmustern gibt: Entweder führt die Anwenderin oder der Anwender eine Aktion aus, mit der Absicht, im System etwas zu verändern, oder sie oder er möchte etwas wissen. Mehr Möglichkeiten gibt es nicht. Das heißt, entweder teilen Sie einer Software mit, dass sie dies oder jenes für Sie erledigen soll, dann geben Sie ihr quasi einen Befehl (das ist dann ein sogenannter "Command") – oder Sie fragen die Software nach einer Information, Sie stellen also eine Frage oder führen eine Abfrage durch (und das ist dann eine sogenannte "Query").
Das eine, also ein Command, zieht üblicherweise eine Veränderung und damit einen Schreibvorgang nach sich, das andere, also eine Query, greift hingegen nur lesend zu. Man könnte also auch sagen: Es gibt schreibende und lesende Zugriffe. Das CQRS-Entwurfsmuster besagt nun, dass Sie Ihre Anwendung zweiteilen sollten: in einen Teil, der sich um Schreibvorgänge kümmert, und in einen anderen Teil, der sich um Lesevorgänge kümmert. Sie sollen also, und genau das war meine ursprüngliche Aussage, die Verantwortlichkeit für das Schreiben von der für das Lesen trennen.
Worüber dieses Design-Pattern jedoch nichts aussagt, ist, auf welche Art Sie diese Trennung bewerkstelligen sollen. Es ist also erst einmal völlig offen, ob das einfach nur bedeutet, dass Sie gedanklich zwischen schreibenden und lesenden API-Routen trennen, oder ob Sie zwei getrennte APIs bauen, oder ob das zwei getrennte Services sind, oder sonst etwas. Das ist, wie es im Englischen so schön heißt, "up to interpretation". Darauf kommen wir nachher jedoch näher zu sprechen.
Die erst einmal viel spannendere Frage ist: Warum sollte man das überhaupt machen? Also, warum gibt es diese Empfehlung in Form des CQRS-Patterns überhaupt?
Nun, dahinter steckt eine sehr einfache Überlegung, und sie hat erst einmal sehr wenig mit APIs zu tun, sondern viel mehr mit Datenbanken: Wenn wir über klassische Architektur sprechen, haben wir normalerweise eine UI, eine irgendwie geartete API und am Ende eine Datenbank. Obwohl die Datenbank dabei buchstäblich nicht im Mittelpunkt der Entwicklung steht, beschäftigen wir uns in der Softwareentwicklung üblicherweise sehr ausführlich mit ihr, und häufig hat das in der Datenbank gewählte Datenmodell deutliche Auswirkungen darauf, wie die Geschäftslogik in der API gebaut wird. Das heißt, eine essenzielle Frage lautet: Wie sieht ein gutes Datenmodell aus?
Die akademische Welt hat darauf eine passende Antwort: In der Datenbanktheorie gibt es nämlich verschiedene Normalformen. Das kann man sich so ein bisschen vorstellen wie einen Satz von Regeln, wie man Datenmodelle gestalten sollte. Konkret gibt es davon fünf verschiedene Varianten, und die fünfte Normalform entspricht ein wenig dem heiligen Gral: Wenn man sie umsetzt, dann bedeutet das nichts anderes, als dass alles sehr sauber und ordentlich strukturiert ist, dass keinerlei Information dupliziert wird, dass es keine Redundanzen in den Daten gibt, und so weiter. Das ist deshalb erstrebenswert, weil sich dann Konsistenz- und Integritätsregeln sehr leicht umsetzen lassen. Die fünfte Normalform ist so gesehen also ein Traum, wenn es darum geht, Daten zu schreiben.
Ein wenig unglücklich ist nur, dass man Daten in der Regel auch wieder lesen muss. Das ist in der fünften Normalform natürlich möglich, nur muss man hierfür meist sehr komplexe Abfragen ausführen, und man braucht dann, um zum Beispiel etwas Simples wie die Stammdaten einer Anwenderin auszulesen, auf einmal 27 Joins. Das heißt, Lesen ist durchaus machbar, aber es ist völlig ineffizient und langsam. Das ist natürlich sehr unpraktisch und im Alltag wenig nützlich. Also, kurz gesagt: Die fünfte Normalform ist gut zum Schreiben geeignet, aber eine Katastrophe zum Lesen.
Das andere Extrem wäre die erste Normalform: Hier wird einfach für jede View, die es in der UI gibt, eine passende Tabelle angelegt, und die Daten werden überall dorthin verteilt, wo man sie gerade braucht. Das heißt, die Daten werden komplett denormalisiert, was das Lesen rasend schnell macht: Denn mehr als ein SELECT * FROM xy ist dann in der Regel nicht erforderlich, schließlich gibt es ja per Definition für jede View eine passende Tabelle. Insofern ist die erste Normalform ein Traum, wenn es um das Lesen von Daten geht.
Allerdings ist das Schreiben in diesem Fall eher schwierig, denn man muss dieselbe Information mehrfach ablegen, man muss sie mehrfach pflegen, und es ist deshalb sehr kompliziert, Konsistenz und Integrität zu wahren. Man könnte also festhalten, dass die erste Normalform genau das Gegenteil der fünften ist: Die erste ist gut zum Lesen, aber schlecht zum Schreiben.
Wie sieht es nun in der Realität aus? In der Regel nimmt man weder die fünfte noch die erste Normalform, sondern man wählt die Dritte: Das ist der übliche Kompromiss zwischen den beiden Welten, und ich persönlich würde sagen, dass man damit letztlich das Modell nimmt, das weder zum Schreiben noch zum Lesen besonders gut geeignet ist. Man hat nämlich weder einfache Abfragen mit hoher Performance noch die gewünschte Konsistenz und Integrität. Das heißt, mit anderen Worten: Man bekommt das Schlechteste der beiden Welten.
Und was hat das Ganze nun mit CQRS zu tun? Nun, die Aussage war ja, dass man das Schreiben vom Lesen trennen sollte. Und genau das kann man hier nun wunderbar auf Datenbankebene machen: Anstatt zu versuchen, die ganz unterschiedlichen Anforderungen des Schreibens und des Lesens mit einem einzigen Datenmodell zu erfüllen (was, wie gesagt, nicht besonders gut funktioniert), nimmt man schlichtweg zwei Datenmodelle – nämlich eines, das auf das Schreiben optimiert ist, und eines, das auf das Lesen optimiert ist. Dann hat man beim Schreiben die gewünschte Integrität und Konsistenz, und beim Lesen hat man effiziente und performante Abfragen. Der einzige Haken ist dabei nur, dass man natürlich die Änderungen, die im Schreib-Modell erfolgen, irgendwie in das Lese-Modell überführen muss, aber dazu kommen wir nachher noch.
Bevor wir nun weiter in die Details gehen, möchte ich erst einmal ein kleines Beispiel vorstellen, das das Ganze ein wenig veranschaulicht: In dem Blogpost vor zwei Wochen hatte ich als Fachdomäne eine Bibliothek angesprochen, also zum Beispiel eine Stadtbibliothek, in der man sich Bücher ausleihen kann. Ich hatte außerdem geschrieben, dass der Schwerpunkt beim Event Sourcing weniger auf den Substantiven liegt, sondern vielmehr auf den Verben – also mit anderen Worten: auf den Prozessen.
Und welche Prozesse gibt es in einer Bibliothek? Richtig: Man kann Bücher ausleihen, man kann die Ausleihe verlängern, man kann Bücher zurückgeben, man kann sie (aus Versehen oder absichtlich) beschädigen, und so weiter.
All diese Aktionen resultieren, wenn wir uns das als Software vorstellen, in Commands: Als Anwenderin oder Anwender möchte ich zum Beispiel ein Buch ausleihen, also suche ich es im System heraus, prüfe, ob es verfügbar ist, und wenn ja, tippe ich einen Button an, auf dem steht: "Buch ausleihen". Genau das ist mein Command: "Dieses Buch jetzt ausleihen!". Das klingt schon wie ein Befehl. Das System führt dann in Folge Geschäftslogik aus, befolgt dabei die hinterlegten Business-Regeln, prüft, ob ich das Buch ausleihen darf, und entscheidet dann, was passiert. Und damit hat sich dann der Zustand des Systems verändert, was wiederum genau die Definition eines Commands war: ein Schreibvorgang, der den Zustand des Systems ändert.
Wir haben bereits vor zwei Wochen darüber gesprochen, dass sich zum Erfassen dieser Veränderungen Event-Sourcing ganz wunderbar anbietet. Und die Datenbank, in der ich all diese Events im Lauf der Zeit sammle, also ein Append-Only-Log, ist unser Schreib-Modell.
Nun möchte die Bibliothek aber vielleicht gerne wissen, welche Bücher gerade ausgeliehen sind. Oder: Welche Bücher wurden im vergangenen Jahr am häufigsten verlängert? Oder: Gibt es Bücher, die in den vergangenen sechs Monaten gar nicht ausgeliehen wurden? Wie viel Prozent der ausgeliehenen Bücher wurden beschädigt zurückgegeben? Und so weiter.
Diese Liste an Fragen kann man beliebig verlängern.
Nun ist aber der Punkt: All diese Fragen lassen sich zwar auf Basis der Events beantworten, nur leider ist das nicht besonders effizient. Denn wenn ich zum Beispiel wissen will, welche Bücher derzeit alle verliehen sind, dann kann ich theoretisch alle Events von Anfang an durchgehen und eine Liste führen, in der ich jedes Mal, wenn ein Buch ausgeliehen wurde, einen Eintrag mache, und immer dann, wenn ein Buch zurückgegeben wurde, diesen Eintrag wieder streiche. Und wenn ich das von Anfang bis Ende durchziehe, weiß ich am Schluss, welche Bücher aktuell ausgeliehen sind.
Das Gute daran ist also: Ich bekomme diese Information aus meinen Events heraus. Das nicht ganz so Gute daran ist: Es ist ziemlich aufwendig.
All diese Fragen werden gemäß CQRS als Queries angesehen, weil ich etwas wissen möchte und dadurch nicht den Zustand des Systems verändere. Um diese Fragen effizient und performant beantworten zu können, wäre es viel einfacher, wenn ich ein dediziertes Lesemodell hätte. Stellen wir uns also ganz kurz vor, wie das am leichtesten wäre: Die einfachste Möglichkeit wäre eine Tabelle, in der alle aktuell ausgeliehenen Bücher aufgeführt sind. Wenn ich dann nämlich wissen will, welche Bücher gerade verliehen sind, wäre das wirklich nur ein SELECT * FROM xy. Oder, wenn ich wissen möchte, ob ein bestimmtes Buch gerade ausgeliehen ist, könnte ich ebenfalls auf diese Tabelle zugreifen und sagen: SELECT * FROM xy WHERE titel = abc. Entweder bekomme ich einen Treffer, und dann ist das Buch aktuell verliehen, oder eben nicht. Hier wäre also tatsächlich ein denormalisiertes Datenmodell die perfekte Lösung.
Die spannende Frage ist nun: Wo bekomme ich eine solche Tabelle her? Denn die einzigen Daten, die wir aktuell speichern, sind die Events. Die Antwort auf diese Frage ist tatsächlich sehr einfach: Wir bauen die Liste, so wie eben beschrieben, einfach nebenher auf. Also immer, wenn ein Event vom Typ "Buch wurde ausgeliehen" gespeichert wird, speichern wir nicht nur dieses Event, sondern wir tragen das Buch auf Basis der in diesem Event enthaltenen Informationen auch in unsere Liste der aktuell ausgeliehenen Bücher ein.
Immer, wenn ein Event vom Typ "Buch wurde zurückgegeben" gespeichert wird, entfernen wir das Buch wieder von der Liste der ausgeliehenen Bücher. Und immer, wenn ein Event vom Typ "Buch wurde verlängert" gespeichert wird, machen wir mit unserer Tabelle der ausgeliehenen Bücher gar nichts, denn das Verlängern eines Buches ändert nichts daran, dass es bereits verliehen ist.
Sollte nun jemand kommen und uns fragen, welche Bücher aktuell ausgeliehen sind, dann können wir diese Frage ganz einfach beantworten, denn wir haben die Antwort quasi schon vorbereitet.
Und das Beste daran ist, dass wir nicht von Anfang der Entwicklung an wissen müssen, dass uns irgendwann einmal jemand fragen wird, welche Bücher aktuell gerade ausgeliehen sind: Wir können diese Lesemodelle nämlich auch nachträglich noch aufbauen, indem wir alle bereits gespeicherten Events abspulen. Wir können ein Lesemodell also auch im Nachhinein noch anpassen und es einfach neu aufbauen lassen. Wir können auch weitere Lesemodelle ergänzen, oder auch diejenigen, die wir nicht mehr brauchen, einfach entfernen.
Das heißt, wir haben zum Lesen kein statisches Schema mehr, sondern wir können uns gezielt für die relevanten Fragen passende Antwortmodelle zurechtlegen, damit wir sie im Bedarfsfall ad-hoc griffbereit haben. Das beschleunigt das Lesen enorm.
Es wird aber noch besser: Denn nicht jeder Lesevorgang hat dieselben technischen Anforderungen. Für die Liste der gerade ausgeliehenen Bücher eignet sich zum Beispiel eine relationale oder auch eine NoSQL-Datenbank hervorragend. Wenn ich aber zum Beispiel zusätzlich noch eine Volltextsuche über alle Bücher anbieten will, dann müsste ich, immer wenn das Event "Buch wurde neu in den Bestand aufgenommen" gespeichert wird, das Buch indexieren und diese Informationen an beliebiger Stelle ablegen.
Dafür ist aber weder eine relationale noch eine NoSQL-Datenbank à la MongoDB sonderlich gut geeignet, sondern dafür würde sich vielleicht Elasticsearch empfehlen. Dem Prozess, der auf das Event reagiert und daraus ableitet, wie die Lesetabellen zu aktualisieren sind, ist es aber völlig gleichgültig, ob er das für eine, zwei oder mehr Tabellen erledigt. Außerdem ist ihm auch egal, ob diese Tabellen in derselben Datenbank liegen oder ob wir mit verschiedenen Datenbanken sprechen. Mit anderen Worten: Ich kann mir ein Lesemodell, das auf einen bestimmten Use Case abzielt, nicht nur passgenau für diesen aufbauen, sondern ich kann das sogar mit der am besten geeigneten Technologie umsetzen, ohne vorher wissen zu müssen, dass diese Anforderung irgendwann einmal auftauchen wird. Damit wird das Ganze schon sehr flexibel.
Doch man kann es sogar noch weiter treiben: Da sich die Lesemodelle jederzeit aus den Events wieder rekonstruieren lassen, müssen sie theoretisch nicht einmal persistiert werden. Man könnte, zumindest, sofern sie nicht zu groß werden, die Lesemodelle auch einfach im RAM halten. Das ist übrigens gar nicht so abwegig, wie es vielleicht zunächst klingt. Zum einen deshalb nicht, weil Lesezugriffe damit natürlich noch einmal einen enormen Performanceschub erhalten, denn technisch gesehen kann der Zugriff kaum noch schneller erfolgen.
Zum anderen, weil inzwischen einige Systeme auf dem Markt sind, die genau so arbeiten, wie zum Beispiel Memgraph [5] oder DuckDB [6] (zu dem ich vor einigen Monaten auch einen Blogpost geschrieben hatte: "Ente gut, alles gut? [7]").
Das Ganze ist übrigens auch, wenn Sie in Richtung eines Data-Meshs gehen möchten, eine unglaublich gute Ausgangsbasis: Bei einem Data-Mesh geht es ja letztlich darum, dass ein Team, das eine bestimmte fachliche Verantwortung hat, anderen Teams seine Daten passend zur Verfügung stellen kann (als sogenanntes "Data Product"). Und genau dieses "passend zur Verfügung stellen" ist häufig gar nicht so einfach, denn wie oft entspricht schon das interne Datenmodell genau dem, woran jemand anderes interessiert ist?
Das Tolle an Event Sourcing und CQRS ist nun, dass Sie für ein anderes Team einfach ein passendes Lesemodell aufbauen können. Das hat keinerlei Einfluss auf das interne Datenmodell oder auf die Datenmodelle für andere Teams. Und Sie können ein solches Datenmodell auch jederzeit wieder ändern oder entfernen, ohne befürchten zu müssen, dass Sie irgendjemandem etwas kaputtmachen, weil Sie ja einfach für jeden ein eigenes Lesemodell bereitstellen können. Insofern kann ich Ihnen nur raten, wenn das Thema Data-Mesh für Sie relevant ist, sich Event Sourcing und CQRS unbedingt genauer anzusehen.
Und übrigens, nur um es ganz kurz erwähnt zu haben: Auch unterschiedliche Zugriffsrechte lassen sich damit sehr elegant abbilden. Sie bieten für verschiedene Rollen einfach unterschiedliche Lesemodelle an, und die Rolle mit höheren Rechten erhält ein Lesemodell, das mehr Daten enthält, wohingegen die Rolle mit niedrigeren Rechten ein Lesemodell mit weniger Daten erhält. Auch hier können Sie sich das Leben deutlich vereinfachen, im Vergleich dazu, alles in einer einzigen Tabelle mit zig verschiedenen und entsprechend komplexen Abfragen steuern zu müssen.
Nun fragen Sie sich vielleicht:
"Alles schön und gut, aber das bedeutet ja, dass die Last auf meiner Leseseite unter Umständen ganz schön ansteigt. Habe ich da nicht das Problem, dass meine Lese-API mittelfristig überlastet wird?"
Die einfache Antwort lautet: Nein. Denn Sie können nicht nur verschiedene Lesemodelle parallel zueinander betreiben, sondern Sie können auch dasselbe Lesemodell auf mehrere Datenbank- und Server-Instanzen verteilen. Schließlich gilt auch hier wieder: Dem Mechanismus, der auf Events reagiert und dementsprechend die Lesetabellen aktualisiert, ist es egal, ob das unterschiedliche Lesetabellen sind oder ob es mehrere Kopien derselben Tabelle auf unterschiedlichen Servern gibt.
Das heißt, Sie können die Leseseite praktisch ohne Overhead beliebig skalieren, indem Sie einfach parallelisierte Kopien des Lesemodells vorhalten, und das sogar individuell pro Lesemodell, je nachdem, auf welches Lesemodell viel und auf welches eher wenig zugegriffen wird. Das heißt, CQRS ermöglicht es Ihnen, genau dort und nur dort zu skalieren, wo die Last am höchsten ist.
Wie auch schon bei Event Sourcing möchte ich Ihnen natürlich auch bei CQRS die Herausforderungen nicht verschweigen. Denn es ist nicht so, dass es keine gäbe: Auch CQRS ist keine magische Wunderlösung, die alle Ihre Probleme "einfach so" löst.
Das Hauptproblem ist, dass die erforderliche Synchronisation zwischen der Schreib- und der Leseseite Zeit benötigt. Ich habe Ihnen diesen Mechanismus so beschrieben, dass er auf gerade gespeicherte Events reagiert und dann die Lesemodelle anpasst. Nun ist klar, dass wenn wir hier über ein verteiltes System mit verschiedenen Datenbanken sprechen, zwischen dem Speichern des Events und dem Aktualisieren des Lesemodells ein wenig Zeit vergeht. Das wird im Normalfall nicht allzu viel sein (meist handelt es sich um ein paar Millisekunden), aber es bedeutet eben, dass die Leseseite immer ein kleines Stück hinterherhinkt.
Es ist dabei jedoch nicht so, dass die Leseseite nicht konsistent wäre: Das ist sie schon, nur ist sie das eben nicht sofort, sondern sie benötigt einen kurzen Augenblick. Das nennt man, in Abgrenzung zur "strong consistency" dann "eventual consistency". Doch da muss man aufpassen, denn das wird im Deutschen gerne als "eventuell konsistent" übersetzt – was jedoch falsch ist. Tatsächlich heißt "eventually consistent" nämlich so viel wie letztlich oder schlussendlich konsistent. Die Frage, die sich also stellt, lautet: Wie gravierend ist dieser kleine zeitliche Versatz in der Praxis?
Die Antwort lautet: "Es kommt darauf an."
Tatsächlich ist das nämlich keine technische Frage, sondern eine fachliche: Wie hoch ist die Wahrscheinlichkeit, dass dieser geringe zeitliche Versatz zu einem Problem führt, wie sähe dieses Problem aus, wie groß ist das Risiko im Falle des Falles, und was könnten wir dann unternehmen?
Je nachdem, wie Sie diese Fragen beantworten, ergibt sich, ob Eventual Consistency ein Problem darstellt oder nicht. Um es noch einmal zu betonen, weil das so gerne missverstanden wird: Das ist keine technische Frage. Das ist nichts, was Entwicklerinnen und Entwickler entscheiden könnten. Das ist etwas, was der Fachbereich entscheiden muss. Und der Punkt dabei ist natürlich, dass es durchaus Alternativen zu Eventual Consistency gibt (zum Beispiel durch eine einzige große verteilte Transaktion), nur hätte das dann andere Nachteile. Und falls Sie schon einmal mit verteilten Transaktionen in verteilten Systemen zu tun hatten, dann wissen Sie, dass das alles ist, nur kein Vergnügen.
Insofern: Es geht nicht darum, zu sagen, Eventual Consistency sei grundsätzlich gut oder schlecht, oder Strong Consistency sei grundsätzlich gut oder schlecht, sondern es geht darum, herauszufinden, welches Konsistenzmodell für den konkreten fachlichen Use Case besser geeignet ist.
Da sagen viele:
"Nein, also auf Strong Consistency können wir unter gar keinen Umständen verzichten!"
Und ja, natürlich gibt es Szenarien, in denen das so ist: Das ist aus meiner Erfahrung vor allem dann der Fall, wenn die nationale Sicherheit betroffen sein könnte oder wenn es um den Schutz von Leib und Leben geht. In 99,9 Prozent aller Business-Anwendungen ist das meiner Erfahrung nach aber völlig nebensächlich, da reicht Eventual Consistency in aller Regel mehr als aus.
Um hier das gängige Lehrbuch-Beispiel anzuführen: Ein Geldautomat, der die Netzwerkverbindung verliert, wird Ihnen trotzdem noch für eine gewisse Zeit Bargeld auszahlen. Denn die meisten Menschen heben ohnehin keine besonders hohen Beträge ab, und die meisten Menschen machen dies nur, wenn sie wissen, dass genug Geld auf ihrem Konto ist. Das heißt, die Wahrscheinlichkeit und das Risiko, dass die Bank Geld herausgibt, das Ihnen nicht zusteht, ist äußerst gering.
Selbst wenn das passiert, dann holt die Bank es sich eben mit Zinsen und Zinseszinsen zurück. Das heißt, aus dem netzwerktechnischen Ausfall zieht die Bank im Zweifelsfall sogar noch einen Vorteil. Dieses Vorgehen ist aus Geschäftssicht für die Bank weitaus besser, als die vermeintlich naheliegende technische Lösung zu wählen und den Geldautomaten offline zu schalten – denn dann würde am nächsten Tag möglicherweise auf Seite 1 der Boulevardzeitung stehen:
"Skandal! Multimilliardär stand vor dem Geldautomaten und konnte keine 50 Euro abheben! Ist das die neue Service-Wüste?"
Und das möchte garantiert niemand.
Ich glaube, damit haben Sie einen ganz guten Überblick darüber, was hinter CQRS steckt und auch, warum CQRS und Event Sourcing so gut zusammenpassen: Sie ergänzen sich einfach sehr, sehr gut, weil das Append-Only-Prinzip von Event Sourcing ein sehr einfaches Modell zum Schreiben von Daten ist, aus dem sich dann äußerst flexibel beliebige Lesemodelle generieren lassen.
Unterm Strich wirkt das Ganze vielleicht anfangs ein wenig einschüchternd. Das kann ich gut nachvollziehen, denn mir ging es vor mehr als zehn Jahren, als ich anfing, mich mit diesen Themen zu beschäftigen, nicht anders. Aber eigentlich sind diese Themen gar nicht so übermäßig kompliziert, sondern sie sind nur sehr anders als das, was die meisten von uns gewohnt sind. Und das dauert einfach, weil man sich komplett umgewöhnen muss und vieles, was man bislang über Softwareentwicklung gedacht und geglaubt hat, quasi entlernen muss.
Wenn man das aber einmal geschafft hat, wirkt diese "neue Welt" sehr viel intuitiver und sinnvoller als die klassische, herkömmliche Entwicklung. Viele, die sich daran gewöhnt haben, fragen sich hinterher, wie sie jemals der Meinung sein konnten, klassisch zu entwickeln, sei eine gute Idee gewesen. Mir ging das so, und vielen unserer Kunden, die wir bei the native web [8] bei der Einführung von Event Sourcing und CQRS beraten und unterstützt haben, ebenfalls.
Also lassen Sie sich davon bitte nicht abschrecken. Es wird Ihnen am Anfang schwierig erscheinen, weil Ihnen die Erfahrung fehlt, doch nach einer Weile werden Sie zurückblicken und denken:
"Wow, das war eine der besten Entscheidungen in meinem Leben als Entwicklerin oder Entwickler, mich auf diese Themen einzulassen."
Wenn Sie mehr wissen möchten, und Sie diesen Blogpost (und den vergangenen zu Event Sourcing) spannend fanden, dann habe ich eine gute Nachricht für Sie: Ich werde in den kommenden Wochen und Monaten noch einige weitere Blogposts zu diesen Themen schreiben, und dabei nach und nach auch mehr ins Detail und mehr in die Praxis gehen. Und wir werden auf unserem YouTube-Kanal [9] über kurz oder lang auch einen Livestream dazu machen.
In diesem Sinne: Bleiben Sie gespannt!
URL dieses Artikels:
https://www.heise.de/-10275526
Links in diesem Artikel:
[1] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[2] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[3] https://www.youtube.com/watch?v=ss9wnixCGRY
[4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[5] https://memgraph.com/
[6] https://duckdb.org/
[7] https://www.heise.de/blog/Ente-gut-alles-gut-DuckDB-ist-eine-besondere-Datenbank-9753854.html
[8] https://www.thenativeweb.io/
[9] https://www.youtube.com/@thenativeweb
[10] mailto:mai@heise.de
Copyright © 2025 Heise Medien

(Bild: Piyawat Nandeenopparit / Shutterstock.com)
Eine neue Annotation ermöglicht es, über Prioritäten explizit festzulegen, welche Methodenüberladung der Compiler aufrufen soll.
Mit [OverloadResolutionPriority] im Namensraum System.Runtime.CompilerServices können Entwicklerinnen und Entwickler festlegen, dass bestimmte Überladungen bei der Entscheidung, welche Überladung verwendet werden soll, eine höhere Priorität erhalten. Das hilft zum Beispiel, wenn mit [Obsolet] annotierte Überladungen einer Methode existieren, um zur präferierten Implementierung zu lotsen.
Bei der neuen Annotation [OverloadResolutionPriority] gibt man eine Integer-Zahl an:
Das folgende Listing zeigt ein Beispiel: Der Aufruf von Print() mit einer Zeichenkette würde ohne [OverloadResolutionPriority] immer zur Implementierung von Print() mit einem String-Parameter gehen, auch wenn diese Überladung als [Obsolete] gekennzeichnet ist. Durch das Einfügen von [OverloadResolutionPriority] lenkt man den Compiler auf eine andere Implementierung um. Würde man in dem Beispiel sowohl der Implementierung mit Parametertyp object als auch ReadOnlySpan<char> den gleichen Prioritätswert geben, wüsste der Compiler nicht, welche Konvertierung er machen soll und verweigert die Übersetzung:
The call is ambiguous between the following methods or properties: 'CS13_OverloadResolutionPriority.Print(object, ConsoleColor)' and 'CS13_OverloadResolutionPriority.Print(ReadOnlySpan<char>, ConsoleColor)'
Mit einem abweichenden Prioritätswert kann man den Compiler zu der einen oder der anderen Implementierung lenken, hier im Listing mit Wert 10 zu public void Print(ReadOnlySpan<char> text, ConsoleColor color).
Die Implementierung public void Print(object text, ConsoleColor color) kommt aber weiterhin zum Einsatz für alle anderen Datentypen, zum Beispiel Zahlen wie 42, denn diese kann der Compiler nicht automatisch in ReadOnlySpan<char> konvertieren.
Folgender Code zeigt den Einsatz der neuen Annotation [OverloadResolutionPriority]:
using System.Runtime.CompilerServices;
namespace NET9_Console.CS13;
public class CS13_OverloadResolutionPriority
{
public void Run()
{
CUI.Demo(nameof(CS13_OverloadResolutionPriority));
// verwendet Print(ReadOnlySpan<char> text)
ReadOnlySpan<char> span = "www.IT-Visions.de".AsSpan();
Print(span);
// verwendet Print(ReadOnlySpan<char> text) wegen OverloadResolutionPriority(10)
Print("Dr. Holger Schwichtenberg");
// verwendet public void Print(object obj)
Print(42);
}
[Obsolete]
//[OverloadResolutionPriority(10)]
public void Print(string text)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Red;
// Print the text
Console.WriteLine("string: " + text);
// Reset the console color
Console.ResetColor();
}
[OverloadResolutionPriority(1)]
public void Print(object obj)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Yellow;
// Print the text
Console.WriteLine("Object: " + obj.ToString());
// Reset the console color
Console.ResetColor();
}
[OverloadResolutionPriority(10)]
public void Print(ReadOnlySpan<char> text)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Green;
// Print the text
Console.WriteLine("ReadOnlySpan<char>: " + text.ToString());
// Reset the console color
Console.ResetColor();
}
}

(Bild: Screenshot (Holger Schwichtenberg))
Wenn man bei public void Print(string text, ConsoleColor color) auch eine Overload Resolution Priority von mindestens 10 setzt
[Obsolete]
[OverloadResolutionPriority(10)]
public void Print(string text, ConsoleColor color)
{
// Set the console color
Console.ForegroundColor = color;
// Print the text
Console.WriteLine("string: " + text);
// Reset the console color
Console.ResetColor();
}
dann wird bei
Print("Dr. Holger Schwichtenberg", ConsoleColor.Yellow);die Überladung mit string-Parameter genommen, auch wenn diese mit [Obsolete] markiert ist.
URL dieses Artikels:
https://www.heise.de/-10272355
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Dank KI können Entwickler viele neue Anwendungsfälle umsetzen. Die Built-in-AI-APIs bringen KI-Modelle auf das eigene Gerät.
(Bild: Fabio Principe/ Shutterstock.com)
Chatbots und andere Use Cases rund um natürliche Sprache laufen dank der Built-in-AI-APIs direkt im Browser. Erste APIs können Developer in Chrome testen.
Generative KI legt den Grundstein für zahlreiche Anwendungsfälle, die vorher schwierig oder gar nicht umzusetzen waren. Sie legt den Fokus auf das Verarbeiten und Erzeugen von Inhalten wie Text, Bildern, Audio und Video mithilfe von Machine-Learning-Modellen: In der Trainingsphase werden sie mit erheblichen Datenmengen trainiert und können dann aus ihnen völlig unbekannten Situationen sinnvolle Zusammenhänge schließen, in denen regelbasierte Algorithmen an ihre Grenzen stoßen.
Large Language Models (LLMs) beschränken sich auf das Verarbeiten und Erzeugen von Text in natürlicher Sprache. Sie sind bereits zu einem wichtigen Baustein in der Softwarearchitektur geworden: LLMs können Inhalte übersetzen, Daten aus unstrukturiertem Text extrahieren, längere Textabschnitte präzise zusammenfassen, Code schreiben oder interaktive Dialoge mit dem Anwender führen.
Bislang führte der Weg zur Nutzung von LLMs praktisch immer in die Cloud. Gerätehersteller sind jedoch dazu übergegangen, LLMs mit ihren Geräten und Betriebssystemen auszuliefern: Die Funktionen von Apple Intelligence wie das Zusammenfassen mehrerer Benachrichtigungen werden durch ein lokales LLM ausgeführt [1]. Google liefert High-End-Smartphones mit seinem LLM Gemini Nano aus [2] und Microsoft bringt mit der Windows Copilot Runtime sein LLM Phi Silica auf Windows-Geräte [3].
Lokal ausgeführte LLMs sind auch offline verfügbar, haben ein verlässliches Antwortverhalten unabhängig von der Netzwerkqualität und die Userdaten verlassen das Gerät nicht, was die Privatsphäre des Anwenders schützt. Da LLMs aber einen großen Speicherplatzbedarf haben, werden oftmals eher kleinere LLMs eingesetzt, die eine geringere Antwortqualität haben. Die Performance hängt zudem vom Endgerät ab.
Im Rahmen seiner Built-in-AI-Initiative [4] liefert Google KI-Modelle zu Testzwecken mit seinem Browser Google Chrome aus. Für die Installation werden Windows 10 oder 11, macOS ab Version 13 (Ventura), 6 GByte Video-RAM und mindestens 22 GByte freier Festplattenplatz auf dem Volume des Chrome-Profils vorausgesetzt, die heruntergeladenen KI-Modelle sind allerdings deutlich kleiner.
Nach dem initialen Download teilen sich sämtliche Webseiten den Zugriff auf diese Modelle über sechs Built-in-AI-APIs [5], die innerhalb der Web Machine Learning (WebML) Community Group [6] des W3C spezifiziert sind. Eine der APIs ist allgemein verwendbar, während der Rest aufgabenspezifisch ist:
Während die Prompt API und Writing Assistance APIs derzeit auf das LLM Gemini Nano 2 mit 3,25 Milliarden Parametern zurückgreifen, werden für die Translation und Language Detection API intern andere Modelle genutzt.
Das Chrome-Team stellt die APIs derzeit im Rahmen eines Origin Trial zur Verfügung. Dabei handelt es sich um eine Testphase für neue Webplattform-APIs. Entwickler müssen von Google ein Origin-Trial-Token beziehen [10] und mit ihrer Website ausliefern. Dann wird die Schnittstelle auf dieser Website aktiviert, auch wenn sie noch nicht allgemein verfügbar ist.
Auf diese Art können Interessierte die Translator API, Language Detector und Summarizer APIs bereits testen. Auch für die Prompt API gibt es eine Origin Trial, allerdings nur für Chrome-Erweiterungen.
Da sich die APIs noch alle im Spezifikationsprozess befinden und sich das KI-Feld stetig weiterbewegt, sind Änderungen an den Schnittstellen sehr wahrscheinlich. So soll etwa die Prompt API künftig multimodale Eingaben (neben Text auch Bilder oder Audiomitschnitte) verarbeiten können.
Mit dem Paket @types/dom-chromium-ai [11] stehen bereits TypeScript-Definitionen zur Verfügung, um die APIs bequem aus eigenem TypeScript-Code aufrufen zu können. Das Paket entspricht derzeit der in Chrome 128.0.6545.0 implementierten API. Änderungen werden mit neuen Chrome-Versionen nachgeliefert.
Das folgende Beispiel zeigt die Verwendung der Language Detector API in einer Webanwendung:
const languageDetector = await self.ai.languageDetector.create();
const review = "こんにちは!Hier esse ich einfach am liebsten Sushi."
+ "Immer super 美味しい!";
const result = await languageDetector.detect(review);
// result[0]: {confidence: 0.800081193447113,
detectedLanguage: 'de'}
// result[1]: {confidence: 0.0267348475754261,
detectedLanguage: 'ja'}Die Built-in-AI-APIs sind ein spannendes Experiment, das die Fähigkeiten generativer KI direkt auf das eigene Gerät bringt. Entwickler und Entwicklerinnen können im Rahmen des Early-Preview-Programms für Built-in AI [12] Feedback an das zuständige Chrome-Team richten.
Danke an Thomas Steiner für das Review dieses Blogposts.
URL dieses Artikels:
https://www.heise.de/-10256818
Links in diesem Artikel:
[1] https://www.heise.de/news/Statt-Cloud-Apples-LLM-angeblich-vollstaendig-on-device-9692827.html
[2] https://www.heise.de/news/Google-Gemini-zieht-in-Android-und-iOS-Geraete-ein-samt-Live-Funktion-9834081.html
[3] https://www.heise.de/news/Windows-Copilot-Runtime-Fundament-fuer-offene-KI-Entwicklung-mit-APIs-und-SLMs-9731468.html
[4] https://developer.chrome.com/docs/ai/built-in?hl=de
[5] https://developer.chrome.com/docs/ai/built-in-apis?hl=de
[6] https://webmachinelearning.github.io/incubations/
[7] https://github.com/webmachinelearning/prompt-api
[8] https://github.com/webmachinelearning/writing-assistance-apis
[9] https://github.com/webmachinelearning/translation-api
[10] https://developer.chrome.com/origintrials/
[11] https://www.npmjs.com/package/@types/dom-chromium-ai
[12] https://developer.chrome.com/docs/ai/built-in-apis?hl=de#participate_in_early_testing
[13] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Andrey Suslov/Shutterstock.com)
Viele Unternehmen setzen auf UI-Libraries – und kämpfen über kurz oder lang mit den damit verbundenen Nachteilen. Warum ist das so und wie macht man es besser?
Ich hätte nie gedacht, dass dieser Tag einmal kommt, aber er ist da: Wir arbeiten aktuell mit einer Behörde zusammen, und diese hat etwas geschafft, woran 99 Prozent aller Unternehmen scheitern. Sie haben eine ganz bestimmte Entscheidung strategisch richtig getroffen: Sie haben sich nämlich nicht einfach wahllos für eine UI-Library für ihre Entwicklung entschieden, sondern erst einmal ihre fachlichen Anforderungen durchdacht und darauf basierend dann technologische Entscheidungen getroffen.
Doch leider ist das die absolute Ausnahme. Denn in den meisten Fällen läuft es genau umgekehrt. Und da fangen die Probleme an. Und genau deshalb, weil das so verbreitet ist und weil man es so viel besser machen kann, als es die meisten Unternehmen da draußen tun, geht es heute um den Einsatz von UI-Libraries.
Ein typisches Szenario: Ein Unternehmen plant eine neue Software und hat bereits ein paar Ideen. Trotzdem ist es manchmal ganz gut, ein wenig Unterstützung zu haben, um von außen validieren zu lassen, dass man von vornherein in die richtige Richtung läuft. Genau dafür gibt es Beratungsunternehmen, wie ja nicht zuletzt auch wir eines sind. Da wir bei the native web [1] auf Web- und Cloud-Entwicklung spezialisiert sind, kommt natürlich auch immer wieder das Thema UI zur Sprache. Und da überlegen sich viele Unternehmen, dass sie für ihre UI doch auf eine Library setzen könnten, zum Beispiel Material UI, und sie glauben, damit wäre die Frage beantwortet, wie (also mit welcher Technologie) sie ihre UI bauen sollten.
Das scheint zunächst einmal sinnvoll zu sein: Immerhin sparen UI-Libraries in der Entwicklung einiges an Zeit und Aufwand. Zumindest scheint das auf den ersten Blick so. Und genau deshalb entscheiden sich Unternehmen auch so gerne dafür: Sie möchten die versprochenen Vorteile nutzen und ihre Entwicklung beschleunigen. Das – und das muss ich an dieser Stelle vielleicht noch einmal explizit betonen – ist ein völlig legitimer Wunsch und eine völlig legitime Überlegung.
Viele Unternehmen sehen aber nicht, dass dieser Ansatz seinen Preis hat. Konkret sind es vor allem drei Risiken, die man sich damit ungewollt einkauft:
Und nur, damit es nicht missverstanden wird: Auch wenn ich hier schon ein paar Mal Material UI erwähnt habe, liegt das Problem nicht an Material UI! Material UI ist eine tolle UI-Library, solange Sie zufällig genau das Design wünschen, das Material UI vorgibt.
Was wir regelmäßig erleben, ist, dass wir um eine Einschätzung gebeten werden, wie wir die Idee beurteilen, auf Material UI (oder eine andere UI-Library) zu setzen. Denn das wäre ja alles bereits vorhanden, wäre entsprechend günstig, und man käme damit sehr zügig voran, und so weiter. Viele Unternehmen sind dann überrascht, dass wir darauf vielleicht nicht ganz so begeistert reagieren.
Wir erklären dann oft, dass wir eher davon abraten würden, eine solche Library einzusetzen, einfach um zu vermeiden, dass man sich in eine große Abhängigkeit begibt, sich den Weg in die Zukunft verbaut und sich die Möglichkeit für individuelle Anpassungen nimmt. Das bedeutet, wir empfehlen in sehr vielen Fällen, die eigenen Controls zu entwickeln, und daraufhin kommt praktisch immer das Standard-Gegenargument, das sei ja so fürchterlich teuer: Denn man müsse ja auch Mobile berücksichtigen, und man müsse ja ebenfalls Accessibility berücksichtigen, und so weiter.
Aus eigener Erfahrung kann ich sagen, dass dies zum einen gar nicht so teuer ist, wie viele immer annehmen, und dass die größten Kosten in Bezug auf Mobile, Accessibility und so weiter nicht in der Implementierung, sondern in der Konzeption der Benutzerführung anfallen. Und diese Kosten entstehen ja ohnehin, ob nun mit oder ohne UI-Library. Nur glauben Unternehmen dies oft nicht, weil es für sie häufig nicht wirklich greifbar ist, da sie beispielsweise keine Erfahrung mit UX-Design haben. Sie wissen jedoch, dass Entwicklung teuer ist, also versuchen sie, an dieser Stelle Kosten zu sparen.
Das Ganze endet dann meist damit, dass wider den Rat von außen doch eine UI-Library eingesetzt wird. Und ironisch wird es dann (und das habe ich tatsächlich schon einige Male erlebt), wenn schon nach wenigen Wochen die ersten Wünsche laut werden: Controls sollen bewusst anders aussehen, sich bewusst anders verhalten, das Ganze soll mit einem eigentlich nicht kompatiblen CSS-Framework kombiniert werden und so weiter.
Dann geschieht genau das Gegenteil von dem, was sich das Unternehmen ursprünglich erhofft hatte: Die Entwicklungskosten steigen massiv, alles dauert sehr lange, und es treten ständig merkwürdige Fehler in der UI auf, weil versucht wird, die vorgegebene Logik der Library zu umgehen. Am Ende kann das nur scheitern. Und Sie stehen dann als Berater daneben und denken sich:
"Tja, das ist genau das, was ich Euch vorhergesagt habe, aber Ihr wolltet ja keine Beratung, sondern einen Papagei, der nur "ja" sagen kann, Und eigentlich habt Ihr nur gehofft, jemanden zu finden, der Eure fragwürdige Idee von außen absegnet."
Beratung muss ehrlich sein und auch unangenehme Antworten liefern dürfen.
All das ist leider kein Einzelfall – es kommt tatsächlich ständig vor. Wie schon erwähnt, ist das eigentliche Problem aber nicht die UI-Library an sich. Das Problem besteht vielmehr darin, dass Unternehmen sich für eine bestimmte Technologie entscheiden, bevor sie ihre Anforderungen wirklich verstanden haben. Da wird dann häufig mit Zeit und Kosten argumentiert, aber der springende Punkt ist: Wenn man noch gar nicht genau weiß, was man überhaupt will, kann man auch keine Technologie wählen, um das Ziel zu erreichen, denn man kennt dieses Ziel noch nicht.
Das ist, wie wenn Sie ein Fertighaus kaufen und dann die Wände herausreißen, weil Ihnen im Nachhinein auffällt, dass Sie eigentlich viel eher einen Loft-Charakter wollten. Man kann das natürlich trotzdem machen, aber es ist und bleibt doch eher eine schlechte Idee.
Das bedeutet, die richtige Reihenfolge sollte lauten:
Von diesen vier Punkten konzentrieren sich die meisten Unternehmen jedoch auf den letzten, und insbesondere das Thema UI/UX-Konzept wird oft übergangen. Dabei ist das so ungemein wichtig. Mit anderen Worten: Bei sehr vielen Unternehmen kommt die Technik vor dem Konzept, und das führt über kurz oder lang zu absurden Workarounds.
Nun stellt sich die Frage: Wie kann man es besser angehen? Einen Punkt habe ich schon angesprochen: Es ist oft gar nicht so sinnvoll, auf eine UI-Library zu setzen, sondern man sollte viel häufiger eigene UI-Komponenten entwickeln. Das ist sehr viel weniger aufwendig als oft angenommen. Und der Vorteil ist: Man hat die volle Kontrolle, bleibt flexibel, bleibt unabhängig und vermeidet langfristig zahlreiche Probleme.
Noch wichtiger ist allerdings etwas anderes: Denn – und das habe ich oben ebenfalls erwähnt – grundsätzlich ist nichts falsch am Einsatz von UI-Libraries. Man muss sich nur im Vorfeld genau überlegen, ob das eine gute Idee ist. Passen sie wirklich zu 100 Prozent zu den Anforderungen? Oder gibt es doch Aspekte, die man gerne anders hätte, bei denen man bewusst vom getrampelten Pfad abweichen möchte, und macht man sich damit nicht auf lange Sicht das Leben schwerer, wenn man auf eine Standardlösung setzt?
Ich kann es nur wiederholen: Die initialen Kosten und der anfängliche Entwicklungsaufwand sind langfristig nahezu zu vernachlässigen. Denn allzu oft läuft es so ab:
"Ah, großartig, wir nehmen eine UI-Library, damit wir jetzt weniger Arbeit haben und schneller vorankommen!"
Ja, und drei Monate später sitzt man dann dort mit 10.000 Zeilen CSS-Hacks, aber Hauptsache, man hat anfangs zwei Tage Arbeit gespart …
So, und da kann ich nur sagen: Begehen Sie nicht denselben Fehler! Setzen Sie sich vor einer Entscheidung für oder gegen eine Technologie intensiv mit Ihren Anforderungen auseinander und prüfen Sie dies im Hinblick auf Ihre Corporate Identity und Ihr Corporate Design. Nehmen Sie sich die Zeit, ein fundiertes UI-/UX-Konzept zu entwickeln, und beschäftigen Sie sich zumindest in einem Proof of Concept damit, wie komplex und aufwendig es tatsächlich wäre, eigene UI-Komponenten zu konzipieren und umzusetzen.
Und wie zu Beginn dieses Blogposts gesagt: Es gibt Unternehmen, die das von Anfang an richtig angehen, aber die sind leider selten. Sorgen Sie also dafür, dass Ihr Unternehmen zu diesem Kreis gehört!
URL dieses Artikels:
https://www.heise.de/-10266999
Links in diesem Artikel:
[1] https://www.thenativeweb.io/
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=uRljbIxtauA
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
Der Vortrag in Dortmund behandelt die Neuerungen in der Syntax von C# 13.0, der .NET 9.0-Basisklassenbibliothek sowie den Anwendungsmodellen.
Ich möchte Sie kurz auf meinen nächsten ehrenamtlichen User-Group-Vortrag aufmerksam machen.
Am 5. Februar 2025 von 18 Uhr bis etwa 20:30 Uhr halte ich in Dortmund den Vortrag "Was bringen C# 13.0 und .NET 9.0?"
Die Veranstaltung der .NET User Group Dortmund ist kostenlos. Sie findet bei der Adesso AG am Adessoplatz 1, 44269 Dortmund in der ersten Etage statt.
Der Vortrag hat folgende Inhalte:
Hier geht es zur Anmeldung:
Die Teilnahme ist kostenfrei. Eine Anmeldung ist jedoch zwingend erforderlich [1]. Die Teilnehmeranzahl ist durch die User Group auf 60 Personen begrenzt.
Denjenigen, die nicht persönlich zu dem Termin nach Dortmund kommen können oder mehr wissen wollen als ich an dem einen Abend vermitteln kann, empfehle ich alternativ meine vier Bücher zu .NET 9.0 zu lesen [2].Das geht besonders günstig im E-Book-Abo [3] (ab 99 Euro/Jahr). Hierin sind auch die laufenden Updates aller meiner .NET- und Web-Bücher enthalten.
URL dieses Artikels:
https://www.heise.de/-10261744
Links in diesem Artikel:
[1] https://www.it-visions.de/V11610
[2] https://www.it-visions.de/buecher/verlag.aspx
[3] https://www.it-visions.de/BuchAbo
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: sabthai/Shutterstock.com)
Event Sourcing ist ein alternativer Ansatz für das Speichern und Verwalten von Daten. Wie funktioniert Event Sourcing und was sind die Vor- und Nachteile?
Kennen Sie das? Sie entwickeln eine Software (ganz gleich, ob für einen Kunden oder für die interne Fachabteilung), und kaum ist sie fertig, kommen schon die ersten Änderungs- und Anpassungswünsche: neue Funktionen, komplexere Analysen, mehr Reports und so weiter. Und oft fehlen entweder die richtigen Daten, oder die Code-Anpassungen sind aufwendiger und fehleranfälliger, als sie sein müssten. Und das führt zu Frust: bei Ihnen und auch bei Ihren Anwenderinnen und Anwendern.
Doch was wäre, wenn sich Software so entwickeln ließe, dass solche Änderungen und Erweiterungen deutlich einfacher und flexibler möglich sind? Genau darum geht es heute: Wir schauen uns an, warum viele Systeme für diese Herausforderungen nicht gemacht sind und wie wir das besser lösen können. Und wenn Sie bei der Softwareentwicklung flexibler und effizienter werden möchten, dann sind Sie hier genau richtig.
Was ist das Problem? Völlig gleich, mit welcher Architektur Sie arbeiten, ob Sie einen Monolithen entwickeln, ein Client-Server-System, eine Peer-to-Peer-Lösung, eine verteilte servicebasierte Anwendung oder etwas anderes – eines bleibt stets gleich, nämlich die Datenhaltung. Vielleicht würden Sie jetzt entgegnen, dass das nicht stimme, denn immerhin gäbe es nicht nur relationale Datenbanken, sondern auch NoSQL-Datenbanken oder File Storage und dieses und jenes, doch eines haben all diese Storage-Ansätze gemeinsam: Sie speichern stets den Status quo.
Wenn Sie etwa eine Software für eine Bibliothek schreiben, in der man Bücher ausleihen, verlängern und zurückgeben kann, dann ist es sehr wahrscheinlich, dass für jedes Buch ein Datensatz angelegt wird, wenn das Buch in den Bestand aufgenommen wird, und dass dieser Datensatz jedes Mal aktualisiert wird, wenn das Buch ausgeliehen, verlängert oder zurückgegeben wird, und schließlich gelöscht wird, wenn das Buch irgendwann so zerfleddert ist, dass es aus dem Bestand entfernt wird. Und das erscheint so logisch und naheliegend, dass man in der Regel gar nicht hinterfragt, ob das wirklich sinnvoll ist.
Doch warum wirkt das so logisch und naheliegend? Nun, ganz einfach: Weil wir das alle von klein auf so vermittelt bekommen haben – ganz gleich, ob Sie eine Ausbildung gemacht oder studiert haben, ob Sie an einer Fachhochschule oder an einer Universität waren, oder mit welcher Programmiersprache Sie aufgewachsen sind: Die Wahrscheinlichkeit, dass Sie das Speichern von Daten genau so gelernt haben, nämlich Datensätze anzulegen, bei Bedarf zu ändern und schließlich irgendwann zu löschen, ist nahezu immer gegeben.
Für diese Art, mit Daten umzugehen, gibt es sogar einen Fachbegriff, nämlich "CRUD": Das steht für "Create", "Read", "Update" und "Delete", also die vier Verben, mit denen wir in einer Datenbank auf Daten zugreifen können. Und das findet sich tatsächlich überall, egal, ob Sie eine relationale Datenbank wie beispielsweise PostgreSQL oder Microsoft SQL Server einsetzen oder ob Sie mit einer NoSQL-Datenbank wie etwa MongoDB oder Redis arbeiten. Und genau das meine ich: Die Art und Weise, in der wir Daten speichern und mit ihnen umgehen, ist konzeptionell stets dieselbe.
Das wirkt zunächst auch gar nicht schlimm, denn es funktioniert offensichtlich seit vielen Jahrzehnten problemlos. Und Daten werden nun einmal angelegt, geändert und gelöscht. Das ist quasi ein universelles Prinzip. Aber: Wo Licht ist, ist immer auch Schatten. Und natürlich gibt es Aspekte, die mit diesem CRUD-Ansatz einfach nicht gut funktionieren. Ich bin mir sehr sicher, dass Sie selbst schon mindestens einmal ein solches Szenario erlebt haben, nämlich: Löschen ist meistens keine besonders gute Idee.
Denn wenn etwas gelöscht wird, ist es danach – Überraschung! – weg. Doch das ist oft unerwünscht, denn vielleicht hat sich die Anwenderin oder der Anwender nur verklickt und würde das Löschen gern rückgängig machen. Das Problem ist nur: Wenn die Daten bereits fort sind, lassen sie sich nicht wiederherstellen. Was tun? Nun, man löscht einfach nicht, sondern führt ein IsDeleted-Flag ein, macht also anstelle eines Delete ein Update und setzt dieses Flag auf true.
So kann man das Löschen zum einen rückgängig machen, und zum anderen lassen sich in der restlichen Anwendung derart markierte Datensätze einfach ignorieren – es wirkt also, als wären sie tatsächlich gelöscht. Das bedeutet, wir führen technisch ein Update durch, das aus fachlicher Sicht einem Delete entspricht.
Wobei das in Wahrheit nicht ganz richtig ist, denn aus fachlicher Sicht geht es gar nicht um das "Delete" eines Buches, sondern darum, ein Buch aus dem Bestand zu entfernen. Delete ist in der Datenbanksprache lediglich das Wort, das diesem Vorgang inhaltlich am nächsten kommt, doch wenn beispielsweise jemand ein Buch stiehlt, dann muss es aus technischer Sicht ebenfalls gelöscht werden, was also auch ein Delete (oder genauer genommen ein Update) wäre – fachlich gesehen sind das jedoch zwei völlig unterschiedliche Vorgänge.
Das bedeutet, wir haben jetzt schon drei Ebenen: die fachliche, in der ein Buch aus dem Bestand entfernt wird, die technische, in der wir das IsDeleted-Flag aktualisieren, und eine dritte Ebene, die sich irgendwo dazwischen befindet und eigentlich die technische Intention ausdrückt, weil wir ursprünglich ein Delete durchführen wollten.
Und? Habe ich es bereits geschafft, Sie damit zu verwirren?
Wenn ja: Herzlichen Glückwunsch! Wenn Sie an dieser Stelle denken, dass dies für einen eigentlich trivialen Vorgang ganz schön kompliziert ist, sind Sie in guter Gesellschaft, denn vielen Entwicklerinnen und Entwicklern geht es genauso: Wir haben es geschafft, für ein banales Beispiel drei unterschiedliche sprachliche Ebenen zu erzeugen, sodass wir nun jedes Mal, wenn wir über solche Vorgänge sprechen, im schlimmsten Fall zweimal ersetzen müssen. Missverständnisse sind da natürlich vorprogrammiert.
Stellen Sie sich das nun in großem Maßstab vor, in einer wirklich großen und komplexen Anwendung. Dann kommt jemand aus der Fachabteilung und erklärt, dass ein bestimmter Vorgang erweitert werden müsse, und Sie überlegen angestrengt, was diese Person damit überhaupt meint, weil Ihnen die Fachsprache nicht geläufig ist und denken:
"Ah, bestimmt geht es um die Stelle, an der wir ein Delete ausführen!"
Anschließend sprechen Sie darüber mit jemandem, der die Datenbank verwaltet, und werden angesehen, als kämen Sie von einem anderen Stern, während Ihnen gesagt wird:
"Wir machen hier kein Delete, wir führen immer nur ein Update durch."
Viel Vergnügen dabei, das alles auseinanderzufieseln und zu klären, wo im Code nun was passiert, mit welcher Intention, wieso und warum, und wie und wo sich das letztlich auswirkt. Missverständnisse sind da geradezu vorprogrammiert, weil zwar alle irgendwie vom Gleichen reden, aber niemand das jeweilige Gegenüber wirklich versteht.
Und dann kommt die Fachabteilung und sagt:
"Ja, wir hätten da noch eine Idee. Wir möchten einen Report darüber, wie oft Bücher eigentlich verspätet zurückgegeben werden, nachdem sie bereits mindestens zwei Mal verlängert wurden."
Und Sie denken sich nur:
"Alles klar, ich melde mich dann morgen krank. Sollen sich doch andere um diesen Kram kümmern."
Denn es stellt sich heraus: Natürlich liegen Ihnen die Daten für diesen Report nicht vor, weil Sie ja nicht ahnen konnten, dass irgendwann einmal jemand danach fragen würde. Also, was tun Sie? Sie passen das Schema der Datenbank an (in der Hoffnung, dabei nichts kaputtzumachen), passen dann den vorhandenen Code an, um die neuen Veränderungen überhaupt zu erfassen (wieder in der Hoffnung, dabei nichts zu zerstören), und schreiben anschließend den Code für den neuen Report. Allerdings sind Sie damit noch nicht fertig, denn jetzt müssen Sie sechs Monate warten, bis Sie zumindest erste halbwegs belastbare Zahlen haben, mit denen Sie zur Fachabteilung gehen können – ein halbes Jahr später!
Und wie reagieren diese Personen? Wenn Sie Glück haben, sind sie schlicht verärgert: Natürlich ist es toll, dass sie nun diesen Report bekommen, aber sie hätten ihn eben gerne schon vor einem halben Jahr gehabt, nicht erst jetzt. Doch immerhin haben Sie es überhaupt hinbekommen.
Wenn Sie Pech haben, bekommen Sie entweder zu hören, dass sie den Report gar nicht mehr benötigen (aber trotzdem danke für Ihre Mühe), oder man teilt Ihnen mit, dass Sie da leider etwas falsch verstanden haben. Dann war die ganze Arbeit umsonst, Sie können quasi noch mal von vorn anfangen, es dauert wieder ein halbes Jahr, und am Ende erfahren Sie vielleicht dann, dass nun niemand den Report mehr braucht.
Erinnern Sie sich noch, wie alles begann? Richtig: Sie haben das Datenbankschema angepasst. Neue Felder eingeführt, anschließend den Code geändert und so weiter. Setzen Sie das jetzt etwa alles wieder zurück? Ganz ehrlich: Sie wären die erste Person, die ich treffen würde, die das macht. Im Normalfall bleibt so etwas dann nämlich bestehen, auch wenn es niemand mehr benötigt. Weil, und das ist das Ärgerliche daran, Sie ja nie wissen, wer diese neuen Felder inzwischen vielleicht ebenfalls verwendet, und natürlich möchten Sie nicht nach einem vergeudeten Jahr auch noch diejenige oder derjenige sein, der anderen etwas kaputtmacht. Also lassen Sie lieber die Finger davon. Und so wächst und wächst das Datenschema, und nach fünf Jahren kennt sich kein Mensch mehr darin aus.
Das ist übrigens keine ausgedachte Situation, sondern genau das erlebe ich da draußen bei sehr vielen Unternehmen in der Praxis als Regelfall. Ich glaube, das Schlimmste in dieser Hinsicht war einmal eine Versicherung, die dem Ganzen vorbeugen wollte, indem sie jeder Tabelle von vornherein vierhundert Spalten verpasste – "Value1", "Value2", "Value3" und so weiter – sodass man zumindest nie das Schema anpassen musste: Man konnte sich einfach die nächste freie Spalte für die eigenen Zwecke reservieren.
Natürlich war das nirgends dokumentiert, und alle Informationen dazu wurden nur mündlich weitergegeben, nach dem Motto:
"Wenn in Spalte 312 ein Y steht, dann bedeutet Spalte 94 die Faxnummer. Wenn in Spalte 312 aber ein J steht, dann ist Spalte 94 das Geburtsdatum. Und wenn in Spalte 207 zusätzlich der Wert NULL steht, gilt das alles nicht mehr, aber wir wissen leider nicht, was dann gilt, weil der Typ, der das vor hundert Jahren mal gebaut hat, nicht mehr bei uns arbeitet."
Uff!
Also stellt sich natürlich die Frage: Wie kann man es besser machen? Denn auf so eine Situation hat eigentlich niemand Lust. Und tatsächlich (auch wenn Sie das jetzt vielleicht überrascht) ist es eigentlich recht einfach. Der Fehler besteht nämlich darin, dass überhaupt erst der Status quo gespeichert wird. Denn wenn man das macht, muss man sich logischerweise festlegen, welche Felder man zum Status quo speichert und wann man diese Felder aktualisiert.
Das Problem dabei ist, dass man das im Vorfeld eigentlich gar nicht wissen kann. Denn Sie wissen nie, welche Fragen Ihnen morgen gestellt werden und welche Daten Sie dafür bräuchten, um diese Fragen sinnvoll beantworten zu können. Tja, und vielleicht fragen Sie sich jetzt, wie man das dann anders machen soll, schließlich kann niemand in die Zukunft blicken – und trotzdem lässt sich die Sache deutlich intelligenter angehen.
Dazu schauen wir uns an, wie ein Girokonto funktioniert. Ich wähle dieses Beispiel ganz bewusst, weil es jede und jeder von Ihnen aus eigener praktischer Erfahrung kennt.
Offensichtlich speichert die Bank nicht einfach nur zu Ihrer Kontonummer den Kontostand (also den Saldo), denn dann könnte sie Ihnen nicht erklären, wie dieser Kontostand überhaupt zustande gekommen ist. Man möchte das jedoch manchmal unbedingt wissen, wenn man sich fragt:
"Warum ist am Ende des Geldes noch so viel Monat übrig?"
Spaß beiseite: Den meisten Menschen ist es sehr wichtig, transparent nachvollziehen zu können, wofür sie Geld ausgegeben haben und wie sich der Kontostand zusammensetzt.
Und was macht die Bank dafür konkret? Zunächst einmal verzichtet sie auf das Delete, denn wir haben ja bereits festgestellt, dass es in den meisten Fällen keine gute Idee ist, Daten zu löschen, also streichen wir das einfach. Dann zeigt sich allerdings, dass auch ein Update genauso wenig geeignet ist, weil dabei ebenfalls Daten verloren gehen – nämlich die, die vorher da waren. Genau das ist der springende Punkt: Man überschreibt den bisherigen Status quo durch einen neuen Status quo. Und der alte ist anschließend weg.
Deshalb verzichtet die Bank folgerichtig auch aufs Update. Das ist übrigens in beiderlei Hinsicht hervorragend, denn so bleiben nur noch Create und Read übrig. Das bedeutet, dass eine Bank technisch gesehen einen einmal angelegten Datensatz nie wieder verändern oder gar löschen kann. Und genau das ist extrem wichtig für den Vertrauensaufbau: Stellen Sie sich einmal vor, eine Bank könnte bereits ausgeführte Buchungen nachträglich ändern! Sie würden wahrscheinlich niemals Ihr Geld dorthin bringen!
Nun stellt sich natürlich die Frage: Was lässt sich mit Create und Read schon Großartiges anfangen? Denn Daten müssen ja manchmal geändert werden. Und hier kommt der entscheidende Punkt: Wir speichern nicht mehr den Status quo, sondern stattdessen die einzelnen kleinen Veränderungen, die im Laufe der Zeit zum Status quo geführt haben. Genau das ist es, was Sie auf Ihrem Kontoauszug sehen: Die Bank erzeugt für jede Transaktion, die auf Ihrem Konto stattfindet, einen neuen, unveränderlichen Eintrag. Per Create.
Und diese immer länger werdende Liste können Sie sich anschließend per Read ausgeben lassen – das ist Ihr Kontoauszug. Wenn ich dann wissen möchte, wie Ihr aktueller Kontostand ist, kann ich hingehen und all Ihre Kontoauszüge seit der Eröffnung des Kontos nehmen und Transaktion für Transaktion durchrechnen, bis ich am Ende weiß, wie Ihr heutiger Saldo ausfällt.
Und was passiert nun, wenn etwas schiefläuft? Dann kann man Daten doch gar nicht korrigieren, oder? Doch, kann man! Denn die Bank versucht gar nicht erst, eine fehlgeschlagene Transaktion zu ändern, sondern sie kompensiert diese einfach mit einer passenden Gegentransaktion. Wenn Sie also versuchen, 100 Euro auf ein Konto zu überweisen, das nicht existiert, streicht die Bank nicht Ihre fehlgeschlagene Überweisung aus der Historie, sondern Sie erhalten kurz darauf einfach eine Gutschrift über 100 Euro, sodass der Effekt ausgeglichen wird.
Das ändert natürlich nichts daran, dass die fehlgeschlagene Überweisung versucht wurde, aber genau so hat es sich ja auch wirklich zugetragen. Das bedeutet, die Historie wird nicht verfälscht, sondern nur die Effekte werden kompensiert.
Dieses Modell hat einen enormen Vorteil: Aus Sicht des Datenmodells ist es sehr, sehr simpel. Aber weil Sie alle Rohdaten besitzen, können Sie sämtliche Fragen beantworten, von denen Sie bis vor Kurzem nicht einmal wussten, dass sie jemals gestellt werden würden. Und das können Sie nicht nur ad hoc tun, sondern Sie können es auch ad hoc über sämtliche Daten der Vergangenheit tun!
Also zum Beispiel: Wie viel Prozent Ihres Gehalts geben Sie für die Miete aus? Nun, wenn Sie mir Ihren Kontoauszug geben, kann ich das einfach ausrechnen, auch wenn es dafür kein eigenes Feld gibt. Sie möchten wissen, ob sich Lottospielen lohnt? Dann geben Sie mir bitte Ihren Kontoauszug, und ich rechne das für Sie gern aus. Sie möchten wissen, ob der durchschnittliche Kontostand des Jahres 2024 höher oder niedriger war als der von 2023 und falls ja, um wie viel? Nun, geben Sie mir Ihren Kontoauszug, und ich rechne Ihnen das gerne aus. Wie oft im Monat gehen Sie essen? Leben Sie eher sparsam oder eher verschwenderisch? Geben Sie direkt nach Geldeingang größere Beträge aus, oder warten Sie bis zum Monatsende, wenn Sie wissen, wie viel übrig ist? Haben Sie einen Zweitwohnsitz? Wie viel sind Ihre Ausgaben für Lebensmittel im Vergleich zu vor fünf Jahren gestiegen? Und so weiter und so fort …
Ich könnte diese Liste praktisch endlos erweitern. Und das Entscheidende ist: Ich kann Ihnen jede dieser Fragen beantworten, nur mithilfe der vorhandenen Transaktionen der vergangenen Jahre, ohne dass wir dazu das Datenmodell anpassen müssten. Ohne dass wir dafür den Code ändern müssen, der die Transaktionen ausführt. Ohne dass wir sechs Monate warten müssen. Ohne dieses, ohne jenes.
Und das gilt nicht nur für Banken. Das funktioniert ebenfalls für unsere eingangs erwähnte Bibliothek: Statt für jedes Buch einen Datensatz zu führen, den wir immer wieder aktualisieren und am Ende trotzdem nichts Genaues wissen, legen wir einfach für jede Veränderung einen Datensatz an: Ein Buch wurde neu in den Bestand aufgenommen, ein Buch wurde ausgeliehen, ein Buch wurde verlängert, ein Buch wurde zurückgegeben, ein Buch wurde beschädigt und so weiter.
Auch daraus können Sie alle möglichen Fragen ableiten: Wie oft wird ein Buch pro Jahr ausgeliehen? Wie oft wird es verlängert? Welches sind die Top 10 der am häufigsten ausgeliehenen Bücher? Welcher Anteil der Bücher wird mehr als einmal von derselben Person ausgeliehen? Und so weiter. All das funktioniert in jeder Fachdomäne.
Vielleicht ist es Ihnen bereits aufgefallen: Wir haben uns, ganz nebenbei, vom rein technischen Vokabular entfernt und reden nicht mehr von Create, Update und Delete, sondern plötzlich von der Fachlichkeit – Ausleihen, Verlängern, Zurückgeben und so weiter.
Das bedeutet, wenn jetzt jemand aus der Fachabteilung mit einem Wunsch hinsichtlich der Rückgabe von Büchern zu Ihnen kommt, wissen Sie sofort, worum es geht, weil Sie dasselbe Vokabular verwenden. Und wenn Sie nun sagen:
"Na gut, man müsste das ja nicht so machen, ich kann doch weiterhin mit Create, Read, Update und Delete arbeiten."
dann bekämen Sie sinngemäß einen Kontoauszug, auf dem steht:
Da erkennt man, wie unglaublich dünn das übliche, verbreitete Vokabular in Anwendungen ist. Und man merkt, wie hilfreich und sinnvoll es sein kann, nicht immer nur dieselben vier technischen Verben zu verwenden, sondern endlich einmal semantisch gehaltvolle Begriffe aus der Fachlichkeit einzuführen. Das Ganze steht und fällt also damit, dass man inhaltlich sinnvolle Begriffe wählt. Und genau das ist in der Softwareentwicklung ohnehin von essenzieller Bedeutung: Dinge richtig zu benennen.
Wenn man das nicht macht, entsteht solcher Unsinn wie der böse Wolf, der das IsDeleted-Flag des Rotkäppchens aktualisiert, weil er es ja nicht löschen darf, sonst könnte der Jäger kein "Undelete" durchführen. Dabei geht es eigentlich doch um Gefressen- und Gerettet-Werden, aber hey – ein rein technisches Update und Delete sind so viel einfacher.
Übrigens: Ich habe mich schon häufiger über CRUD ausgelassen, und wenn Sie sich das CRUD-Märchen tatsächlich einmal in voller Länge ansehen wollen, empfehle ich Ihnen dieses Video [2].
Jetzt wissen Sie, wie das System konzeptionell funktioniert. Was noch fehlt, ist ein Name für das Ganze. Die einzelnen Einträge in dieser immer weiter wachsenden Liste (übrigens nennt man sie eine "Append-Only-Liste", weil stets nur am Ende angehängt werden darf) stehen in der Vergangenheitsform, denn sie sind ja bereits geschehen: Ein Buch wurde ausgeliehen, ein Buch wurde verlängert, ein Buch wurde zurückgegeben und so weiter. Und weil das Ereignisse sind, die stattgefunden haben und nicht mehr rückgängig gemacht werden können (wie gesagt, man kann nur ihre Effekte kompensieren), spricht man hier von "Events".
Da diese Events sozusagen die Quelle für sämtliche Auswertungen, Abfragen, Analysen, Reports und Co. sind, sind sie die "Source" von allem, weshalb man bei diesem Datenhaltungskonzept von "Event Sourcing" spricht. Vielleicht haben Sie den Begriff schon einmal gehört und sich gefragt, was das eigentlich ist. Die kurze Antwort lautet: Das, was Ihr Girokonto macht, das ist Event Sourcing, beziehungsweise, das ist ein Beispiel dafür. Das heißt, Sie verwenden es tagtäglich, und zwar schon seit Jahren, nur kannten Sie vermutlich den Namen nicht.
Allerdings ist die historische Analysemöglichkeit von Daten nicht der einzige Vorteil, den Event Sourcing bietet. Sie erhalten, ohne dafür aktiv etwas machen zu müssen, quasi "kostenlos" ein Audit-Log: Sie können jederzeit nachvollziehen, welches Event (also welche fachlich relevante Aktion) wann und von wem und mit welchen Parametern ausgelöst wurde. Das ist natürlich generell schon sehr praktisch, aber besonders interessant wird es, wenn Sie Software für eine Branche entwickeln, in der das Führen eines Audit-Logs vorgeschrieben ist, etwa aus Sicherheitsgründen.
Wenn Sie dann sagen können, dass das Audit-Log nicht nachträglich angeflanscht wurde, sondern von Anfang an im Kernkonzept der Datenhaltung mitgedacht ist, verschafft es Ihnen einen deutlichen Wettbewerbsvorteil.
Sie interessieren sich für "Was-wäre-wenn"-Analysen? Kein Problem: Beim Abspielen der Events (was man übrigens "Replay" nennt) müssen Sie nicht zwangsläufig alle Events berücksichtigen. Sie können auch einige davon weglassen und sehen, wie sich dadurch das Ergebnis verändert. Oder Sie fügen bei einem Replay simulierte Events hinzu und beobachten, was im Laufe der Zeit geschehen wäre.
Das kann Ihnen helfen, weit bessere Einblicke zu gewinnen, Ihr (auch wenn sich das merkwürdig anhören mag) Business besser zu verstehen und auf dieser Grundlage möglicherweise bessere Entscheidungen zu treffen. Allein die Möglichkeit, die Vergangenheit auf unterschiedliche Weise zu interpretieren, ist so mächtig, dass Sie sich das, falls Sie es noch nie erlebt haben, kaum vorstellen können.
Bevor ich es vergesse: Auch für Fehlersuche und Debugging ist Event Sourcing hervorragend geeignet. Mit Events können Sie problemlos nachvollziehen, wie ein System bei einem Kunden in diesen merkwürdigen Zustand geraten ist, in dem es sich gerade befindet.
Und das ist keineswegs eine neue Idee: Es gibt ein Interview mit John Carmack, dem ehemaligen leitenden Entwickler bei id Software, der maßgeblich an DOOM beteiligt war, und in diesem Interview erwähnt er, dass DOOM im Kern mit Event Sourcing arbeitet (auch wenn er es nicht so nennt, weil der Begriff damals noch nicht existierte, es aber de facto genau das ist).
Übrigens ist das zum Beispiel auch für Maschinensteuerung oder ganz allgemein IoT- und Industriebereiche interessant: Wie ist eine Maschine in den Zustand geraten, in dem sie sich befindet, und was können wir daraus lernen?
Und natürlich können Sie aus den Events jede beliebige andere Darstellung erzeugen, denn letztlich ist das nur eine Frage der Interpretation. Wenn Sie zum Beispiel häufig den aktuellen Kontostand benötigen, wäre es sehr ineffizient, jedes Mal ein komplettes Replay durchzuführen – stattdessen können Sie zusätzlich eine kleine Tabelle mit dem Kontostand pflegen, die Sie ganz klassisch nach CRUD aktualisieren, sobald ein Event auftritt, das Auswirkungen auf den Kontostand hat.
Theoretisch müssten Sie diese Tabelle nicht einmal auf der Festplatte sichern, denn falls das System abstürzt, könnten Sie sie jederzeit aus dem Replay neu aufbauen. Das bedeutet natürlich auch, dass Sie das gleiche Prinzip für jede beliebige andere Tabelle oder Darstellung anwenden können: Die Events bleiben stets Ihre Single Source of Truth, und was Sie daraus an speziell optimierten Lesemodellen ableiten, liegt ganz bei Ihnen.
Es gilt natürlich: Wo Licht ist, ist stets auch Schatten. Ich möchte Event Sourcing nicht als eine Lösung darstellen, in der es nichts gibt, worüber man nachdenken sollte, und spreche deshalb kurz einige typische Einwände an. Erstens wird oft angeführt, dass eine Append-Only-Liste im Laufe der Zeit zunehmend mehr Speicher verbraucht. Das stimmt grundsätzlich, aber zum einen sollen Sie ja nicht jeden einzelnen Sensormesswert als Event erfassen, sondern nur geschäftsrelevante Fachereignisse. Davon haben Sie in der Regel nicht 100.000 pro Sekunde.
Zweitens sind Events meist deutlich kleiner, als man intuitiv annimmt, weil man nur die Deltas speichern muss.
Und drittens ist Speicherplatz heutzutage praktisch kein Kostenfaktor mehr. Letztlich ist das eine einfache Rechenaufgabe, und natürlich hängt die Antwort stark von der jeweiligen Fachdomäne ab, doch erfahrungsgemäß sind das oft weit weniger Daten als zunächst vermutet. Und außerdem könnte man alte Events irgendwann archivieren. Natürlich ließen sich dann deren Historien nicht mehr abrufen, aber das ginge bei einem klassischen Datenhaltungsmodell ebenfalls nicht.
Der zweite häufige Einwand lautet, dass Replays im Laufe der Zeit immer länger dauern: Das ist logisch, denn wenn das System rege genutzt wird, sammeln sich immer mehr Events an, und ein Replay benötigt dann naturgemäß mehr Zeit. Der springende Punkt ist jedoch, dass man dem mit sogenannten Snapshots hervorragend entgegenwirken kann: Ein Replay über die ersten 10.000 Events führt ja stets zum gleichen Ergebnis, gerade weil es kein Update und kein Delete gibt, das heißt, anstatt dieses Ergebnis immer wieder neu zu berechnen, lässt es sich in einem Cache als bereits vorgefertigter Wert hinterlegen.
Im Zweifelsfall müssen Sie dann lediglich ein Replay ab dem letzten Snapshot durchführen, was bei regelmäßig erzeugten Snapshots flott geht. Außerdem haben Sie es in der Hand, wie schnell das Ganze sein soll: Letztlich ist das nur eine Frage der Häufigkeit, mit der Sie Snapshots erzeugen.
Der dritte Einwand betrifft häufig die DSGVO: Wie kann ein System, das darauf ausgelegt ist, Daten niemals zu ändern oder zu löschen, überhaupt mit der DSGVO vereinbar sein, insbesondere mit Artikel 17 zum Recht auf Vergessenwerden? Tatsächlich existieren dafür verschiedene Lösungswege, die unterschiedlich aufwendig zu implementieren sind, aber auch unterschiedlich hohen Anforderungen und Datenschutzklassen gerecht werden.
Was jeweils der richtige Ansatz ist, muss individuell für das jeweilige Projekt erarbeitet werden. Das lässt sich nicht pauschal beantworten, weil es beispielsweise einen Unterschied macht, ob Sie hochsensible medizinische Daten verarbeiten oder nur die Stammdaten des örtlichen Kanarienvogel-Züchtervereins. Das sind einfach verschiedene Welten.
Und vielleicht denken Sie jetzt:
"Klasse, das klingt alles sehr vielversprechend, besonders das mit den historischen Daten, dem Audit-Log, der stärkeren Fokussierung auf die Fachlichkeit, den vielfältigen Analysemöglichkeiten und Reports und so weiter – das möchte ich unbedingt einmal ausprobieren. Aber wo fange ich an?"
Dann ist mein allerwichtigster Rat: Beginnen Sie mit einem kleinen Projekt. Event Sourcing ist ein unglaublich mächtiges Werkzeug, das Ihnen völlig neue Türen öffnen kann, doch wie bei jedem mächtigen Werkzeug sollte man nicht gleich mit dem größten Projekt starten, das man hat. Suchen Sie sich also zuerst etwas wirklich Kleines heraus und beschäftigen Sie sich, bevor Sie mit einer Implementierung beginnen, zunächst einmal mit der Frage, welche Events überhaupt existieren. Denn das ist der Dreh- und Angelpunkt: Da Sie nichts mehr ändern oder löschen können, sollten Sie zumindest halbwegs sicherstellen, dass Sie in die richtige Richtung loslaufen.
Welches Tooling Sie dann später nutzen, welche Datenbank Sie verwenden und so weiter, ist im ersten Schritt völlig unerheblich. Natürlich wird das später eine sehr wichtige Frage sein, aber zuerst sollten Sie sich mit der Fachlichkeit befassen und erst dann mit den technischen Fragen, nicht umgekehrt. Nach einer Weile werden Sie dann irgendwann feststellen: Event Sourcing ist am Ende gar nicht so kompliziert, wie Sie vielleicht zunächst vermuten – es fehlt häufig einfach an Übung und Erfahrung, aber die sammelt man mit der Zeit.
URL dieses Artikels:
https://www.heise.de/-10258295
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] https://www.youtube.com/watch?v=MoWynuslbBY
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Valtenint Agapov / Shutterstock)
C# 13.0 bietet ein neues Escape-Zeichen \e für die Formatierung von ANSI/VT100 Terminal Control Escape Sequences.
Mit den uralten VT100/ANSI-Escape-Codes [1] kann man auch heute noch in Konsolenanwendungen zahlreiche Formatierungen auslösen, darunter 24-Bit-Farben, Fettschrift, Unterstreichen, Durchstreichen und Blinken. Die VT100/ANSI-Codes werden durch das Escape-Zeichen (ASCII-Zeichen 27, hexadezimal: 0x1b) eingeleitet.
Vor C# 13.0 konnte man dieses Escape-ASCII-Zeichen 27 in .NET-Konsolenanwendungen bei Console.WriteLine() nur umständlich ausdrücken über \u001b, \U0000001b oder \x1b, wobei Letzteres nicht empfohlen ist [2]: "Wenn Sie die Escapesequenz \x verwenden, weniger als vier Hexadezimalziffern angeben und es sich bei den Zeichen, die der Escapesequenz unmittelbar folgen, um gültige Hexadezimalziffern handelt (z. B. 0–9, A–F und a–f), werden diese als Teil der Escapesequenz interpretiert. \xA1 erzeugt beispielsweise "¡" (entspricht dem Codepunkt U+00A1). Wenn das nächste Zeichen jedoch "A" oder "a" ist, wird die Escapesequenz stattdessen als \xA1A interpretiert und der Codepunkt "ਚ" erzeugt (entspricht dem Codepunkt U+0A1A). ਚ ist ein Panjabi-Schriftzeichen. Panjabi ist eine in Pakistan und Indien gesprochene Sprache. In solchen Fällen können Fehlinterpretationen vermieden werden, indem Sie alle vier Hexadezimalziffern (z. B. \x00A1) angeben."
Typischerweise sahen Ausgaben mit VT100/ANSI-Escape-Codes vor C# 13.0 folgendermaßen aus:
Console.WriteLine("This is a regular text");
Console.WriteLine("\u001b[1mThis is a bold text\u001b[0m");
Console.WriteLine("\u001b[2mThis is a dimmed text\u001b[0m");
Console.WriteLine("\u001b[3mThis is an italic text\u001b[0m");
Console.WriteLine("\u001b[4mThis is an underlined text\u001b[0m");
Console.WriteLine("\u001b[5mThis is a blinking text\u001b[0m");
Console.WriteLine("\u001b[6mThis is a fast blinking text\u001b[0m");
Console.WriteLine("\u001b[7mThis is an inverted text\u001b[0m");
Console.WriteLine("\u001b[8mThis is a hidden text\u001b[0m");
Console.WriteLine("\u001b[9mThis is a crossed-out text\u001b[0m");
Console.WriteLine("\u001b[21mThis is a double-underlined text\u001b[0m");
Console.WriteLine("\u001b[38;2;255;0;0mThis is a red text\u001b[0m");
Console.WriteLine("\u001b[48;2;255;0;0mThis is a red background\u001b[0m");
Console.WriteLine("\u001b[38;2;0;0;255;48;2;255;255;0mThis is a blue text with a yellow background\u001b[0m");
Seit C# 13.0 gibt es nun \e als Kurzform für das Escape-Zeichen ASCII 27, sodass die Zeichenfolgen deutlich kompakter und übersichtlicher werden:
Console.WriteLine("This is a regular text");
Console.WriteLine("\e[1mThis is a bold text\e[0m");
Console.WriteLine("\e[2mThis is a dimmed text\e[0m");
Console.WriteLine("\e[3mThis is an italic text\e[0m");
Console.WriteLine("\e[4mThis is an underlined text\e[0m");
Console.WriteLine("\e[5mThis is a blinking text\e[0m");
Console.WriteLine("\e[6mThis is a fast blinking text\e[0m");
Console.WriteLine("\e[7mThis is an inverted text\e[0m");
Console.WriteLine("\e[8mThis is a hidden text\e[0m");
Console.WriteLine("\e[9mThis is a crossed-out text\e[0m");
Console.WriteLine("\e[21mThis is a double-underlined text\e[0m");
Console.WriteLine("\e[38;2;255;0;0mThis is a red text\e[0m");
Console.WriteLine("\e[48;2;255;0;0mThis is a red background\e[0m");
Console.WriteLine("\e[38;2;0;0;255;48;2;255;255;0mThis is a blue text with a yellow background\e[0m");

(Bild: Screenshot (Holger Schwichtenberg))
URL dieses Artikels:
https://www.heise.de/-10255344
Links in diesem Artikel:
[1] https://en.wikipedia.org/wiki/ANSI_escape_code
[2] https://learn.microsoft.com/de-de/dotnet/csharp/programming-guide/strings/
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien