
(Bild: Pincasso/Shutterstock)
In C# 13 dürfen bei den variadischen Parametern generische Mengentypen statt eines Array verwendet werden.
Seit der ersten Version von C# gibt es Parameter-Arrays für sogenannte variadische Parameter (vgl. Wikipedia-Eintrag zu variadischen Funktionen [1]), mit denen eine Methode eine beliebig lange Liste von Parametern eines Typs empfangen kann, wenn dies mit dem Schlüsselwort params eingeleitet wird.
Der folgende Code zeigt die bisherige Variante eines variadischen Parameters mit Arrays:
public void MethodeMitBeliebigVielenParametern_Alt(string text,
params int[] args)
{
CUI.H2(nameof(MethodeMitBeliebigVielenParametern_Alt));
CUI.Print(text + ": " + args.Length);
foreach (var item in args)
{
CUI.LI(item);
}
}
Die Methode kann man beispielsweise folgendermaßen aufrufen:
MethodeMitbeliebigVielenParametern_Alt("Anzahl Zahlen", 1, 2, 3);
MethodeMitbeliebigVielenParametern_Alt("Number of numbers",
1, 2, 3, 4);Neu in C# 13.0 ist, dass statt eines Arrays bei den variadischen Parametern auch generische Mengentypen verwendet werden dürfen (sogenannte Parameter Collections) wie params Span<T>:
public void MethodeMitBeliebigVielenParametern_Neu(string text,
params Span<int> args)
{
CUI.H2(nameof(MethodeMitBeliebigVielenParametern_Neu));
CUI.Print(text + ": " + args.Length); // statt args.Length
foreach (var item in args)
{
CUI.LI(item);
}
}
Analog ist der Aufruf dann genauso flexibel möglich wie beim Parameter-Array:
MethodeMitBeliebigVielenParametern_Neu("Anzahl Zahlen", 1, 2, 3);
MethodeMitBeliebigVielenParametern_Neu("Number of numbers",
1, 2, 3, 4);Dann sind diese generischen Mengentypen bei params in C# 13.0 erlaubt:
Collections.Generic.IEnumerable<T>System.Collections.Generic.IReadOnlyCollection<T>Collections.Generic.IReadOnlyList<T>System.Collections.Generic.ICollection<T>Collections.Generic.IList<T> Collections.Generic.IEnumerable<T>implementierenSpan<T>ReadOnlySpan<T>Wenn möglich, sollte man die Parameterliste per Span<T> oder ReadOnlySpan<T> übergeben, damit die Parameterübergabe komplett per Stack erfolgt und keinerlei Speicherallokation auf dem Heap erfolgen muss.
Ebenso wie man bei einem Parameter-Array auch ein fertiges Array übergeben kann, das dann auf die Parameter verteilt wird
MethodeMitBeliebigVielenParametern_Alt(
"Anzahl Zahlen - übergeben als Int-Array",
[1, 2, 3]);kann man auch einen der obigen neuen Typen übergeben, wenn die Methode eine Parameter Collection erwartet:
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
new List<int> { 1, 2, 3 });oder
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
[1, 2, 3]);Achtung: Die folgende Syntax funktioniert aber nicht:
MethodeMitBeliebigVielenParametern_Neu(
"Anzahl Zahlen - übergeben als List<int>",
new List<int> [1, 2, 3 ]);Das ist nicht möglich, da new List<int> [1, 2, 3 ] ein dreidimensionales Array von List<int> erzeugt.
URL dieses Artikels:
https://www.heise.de/-10282100
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/Variadische_Funktion
[2] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Viele Unternehmen sparen an der Codequalität: zu aufwendig und zu teuer. Diese Argumentation ist nicht nur falsch, sondern langfristig auch gefährlich.
Ich nehme an, Sie kennen das Phänomen: Sie arbeiten an einem Softwareprojekt und entdecken einen Fehler. Eigentlich sollten Sie ihn gleich beheben, doch Sie sind derzeit mit einem Feature beschäftigt, das ohnehin schon verspätet ist. Um den Fehler zu beheben, müssten Sie zudem eine Abhängigkeit aktualisieren, was allerdings nicht ohne Weiteres möglich ist, weil Sie dann in einigen Bereichen des Codes Anpassungen vornehmen müssten.
Da Sie ohnehin schon spät dran sind, treffen Sie die einzig denkbare Entscheidung: Sie verschieben den Bugfix auf "später". Der springende Punkt dabei ist jedoch: Dieses "später" tritt nie ein. Das bedeutet, nach einiger Zeit stehen Sie vor einem großen Berg technischer Schulden und fragen sich: Wie konnte es überhaupt jemals so weit kommen?
Diese Situation ist keineswegs neu. Sie trägt sogar einen Namen: die "Broken-Windows-Theorie [1]". Damit ist nicht gemeint, dass das Betriebssystem Windows erneut defekt ist, sondern der Begriff stammt aus der Stadtplanung. Die zugehörige Idee ist simpel und zugleich wirksam: Es geht darum, warum in bestimmten Stadtteilen Kriminalität offenbar ungebremst um sich greifen kann. Die These der Broken-Windows-Theorie besagt, dass dies geschieht, wenn Stadtteile vernachlässigt werden. Wenn zum Beispiel Gebäude dauerhaft leer stehen und nicht – wie möglicherweise lange geplant – abgerissen werden.
Als Symbol dafür wählten die US-amerikanischen Sozialforscher James Wilson und George Kelling in den frühen 1980er-Jahren das zerbrochene Fenster: Wenn eine Fensterscheibe zerbricht und niemand sie ersetzt, zeigt das, dass sich niemand darum kümmert. Da jedoch niemand neben einem leer stehenden Haus mit einer dauerhaft zerbrochenen Scheibe leben möchte, ziehen bald darauf die ersten Nachbarn fort.
Daraus folgen weitere leer stehende Häuser, und jemand wirft dort vermutlich früher oder später ebenfalls eine Fensterscheibe ein. So entsteht langsam eine Kettenreaktion, in der das Viertel weiter verfällt, der soziale Zusammenhalt nachlässt und es irgendwann sehr schwierig werden kann, noch etwas zu ändern, selbst wenn es jemand möchte. Dadurch sinkt die Hemmschwelle gegenüber Kriminalität, was letztlich den gesamten Prozess nur weiter beschleunigt.
Die entscheidende Frage lautet nun, wie sich eine solche Entwicklung wieder unter Kontrolle bringen lässt. Tatsächlich gibt es darauf eine Antwort, die in der Vergangenheit bereits funktioniert hat, etwa in New York in den 1990er-Jahren. Dort beschrieb die eingangs geschilderte Lage ziemlich genau den Status quo, und der damalige Bürgermeister (von 1994 bis 2001 war dies Rudolph Giuliani, den Sie vielleicht als ehemaligen Rechtsberater von Donald Trump kennen) verfolgte eine sogenannte "Zero-Crime-Tolerance"-Strategie.
Dabei geht es, wie der Name erahnen lässt, darum, bei jeglichen Verstößen – auch bei kleineren Vergehen wie Falschparken – keinerlei Nachsicht walten zu lassen. Das hatte insofern Erfolg, als die Kriminalitätsrate in den folgenden Jahren stark sank. Allerdings sollte man nicht unterschlagen, dass diese konsequente Polizeipräsenz wiederum kritisiert wurde, da sie manchem zu weit ging. Gerade aus den USA hört man immer wieder von Polizeigewalt und rassistischem Vorgehen, was man natürlich genauso wenig möchte. Zusammengefasst ist es also schwierig, die richtige Balance zu finden, doch eine Null-Toleranz-Strategie trägt natürlich wesentlich dazu bei, wuchernde Kriminalität einzudämmen.
Was hat das nun mit Softwareentwicklung zu tun? Nun, die Broken-Windows-Theorie lässt sich hervorragend auf Softwareprojekte übertragen. Zusammengefasst: Jeder nicht behobene Fehler ist ein zerbrochenes Fenster. Jede Codezeile, die gepflegt werden müsste, aber nicht wird, ist ein zerbrochenes Fenster. Jede veraltete Abhängigkeit, die nicht aktualisiert wird, ist ein zerbrochenes Fenster. Und so weiter. Anders ausgedrückt: Wenn Sie sich nicht konsequent mit einer Null-Toleranz-Strategie um die eigene Codebasis kümmern, führt dies zwangsläufig zu einer Abwärtsspirale in Ihrem Projekt.
Warum ist das so? Weil sich Fehler und technische Schulden addieren. Das bedeutet, dass der Aufwand, sie irgendwann zu beheben, stetig größer wird. Gleichzeitig steigt auch das Risiko, dabei etwas kaputtzumachen. Beides zusammen sorgt dafür, dass niemand sich mehr an den Code wagt, was wiederum nur zu weiteren Fehlern und noch mehr technischen Schulden führt. Man errichtet so ein Fundament, das von Beginn an instabil ist, baut darauf immer weiter auf und macht dieses Gebilde dadurch noch fragiler, bis es zu einem Kartenhaus verkommt, das unweigerlich in sich zusammenfallen muss.
Zusätzlich besteht dann die Angst, bestehende Module anzupassen oder zu erweitern, weil man nicht weiß, ob eine Funktion möglicherweise eine tragende Karte dieses fragilen Konstrukts ist. Folglich umschiffen alle den vorhandenen Code, was die Entwicklung kompliziert, langsam und teuer macht. Und aufgrund dieser Instabilität will sich auch niemand mehr an externe Abhängigkeiten heranwagen, weil dies Aufwand bedeutet. Also bleibt man lieber bei jenen Versionen, die augenscheinlich funktionieren, was jedoch auf lange Sicht die Aktualisierungsmöglichkeiten verbaut und rasch zu Sicherheitslücken oder nicht behobenen Problemen führt.
Offensichtlich ist es riskant, sich nicht um die Codequalität eines Projekts zu kümmern. Doch es kommt noch ein weiterer Faktor hinzu: Denn wer sind die ersten Nachbarn, die eine Gegend mit zerbrochenen Fenstern verlassen? Das sind stets jene, die sich das problemlos leisten können. In Softwareprojekten sind es folglich häufig die besonders fähigen Entwicklerinnen und Entwickler, die als Erste gehen – und das sind leider genau die Personen, die Sie am dringendsten bräuchten, um die Situation noch zu retten, da sie über umfassendes Fachwissen und Erfahrung verfügen.
Das klingt überaus dramatisch. Aber so stellt sich die Realität dar. Selbstverständlich können Sie die Augen davor verschließen und sich einreden, bei Ihrem eigenen Projekt sei alles vollkommen anders. Vermutlich finden Sie auch zahlreiche Argumente, weshalb die Entwicklung bei Ihnen gar nicht anders laufen könne. Doch genau damit reden Sie sich die Lage schön. Die Augen zu schließen und zu glauben, andere könnten Sie dann nicht mehr sehen, das ist ein Verhalten, das vielleicht im Kindergarten Sinn ergibt, aber in der Softwareentwicklung schlicht nicht funktioniert. Erschreckend finde ich, wie viele Unternehmen genau diesen Ansatz trotzdem immer und immer wieder wählen.
Möglicherweise fragen Sie sich jetzt, woran Sie konkret erkennen, dass in Ihrem Softwareprojekt bereits einige Scheiben zerbrochen sind. Daher möchte ich Ihnen ein paar typische Anzeichen nennen. Diese Liste hat keine festgelegte Reihenfolge, ich führe sie schlicht so auf, wie sie mir in den Sinn kommt.
Indizien für zerbrochene Fenster sind beispielsweise auffallend lange und womöglich weiter ansteigende Build- und Deployment-Zeiten. Auch Code, der immer öfter Kommentare wie "TODO" oder "FIXME" enthält, sollte Sie nachdenklich stimmen. Wenn Sie regelmäßig Workarounds und provisorische Lösungen umsetzen, anstatt Probleme gründlich zu beseitigen, ist dies ein Warnsignal. Sinkt die Testabdeckung im Laufe der Zeit, treten Fehler erneut auf, die schon einmal behoben worden waren, existiert keine Dokumentation oder ist sie fehlerhaft beziehungsweise veraltet, dann sind das alles Anzeichen für zerbrochene Fenster.
Wenn es Codebereiche gibt, die niemand anfassen will, wenn Ihre Dependencies nicht auf dem neuesten Stand sind, wenn immer mehr Tickets für technische Aufgaben auflaufen – das alles sind Hinweise, dass etwas nicht stimmt. Und all diese Vorkommnisse sind wie Eisberge: Was Sie zuerst sehen, ist immer nur die Spitze, und das wahre Ausmaß bleibt verborgen. Unterschätzen Sie die Lage also nicht, indem Sie sie als unwichtige Kleinigkeiten abtun. Oft ist das tatsächliche Problem viel größer, als es zunächst scheint.
Das erste typische Gegenargument lautet:
"Ach, das sind doch alles nur Kleinigkeiten!"
Genau diesen Einwand habe ich eben schon vorweggenommen. Interessant ist aber, dass es zahlreiche solche Bedenken gibt. Hier sind wir an dem Punkt, dass sich viele Unternehmen die Problematik schönreden. Und was sind verbreitete Einwände?
Sehr verbreitet ist beispielsweise:
"Ja, grundsätzlich stimmt das alles, aber wir haben keine Zeit. Wir müssen eine Deadline einhalten."
Diese Aussage lässt sich üblicherweise auf zwei Situationen zurückführen:
Ein weiteres häufiges Gegenargument lautet:
"Regelmäßige Codepflege können wir uns nicht leisten, das wäre zu teuer!"
Auch das ist nicht haltbar, denn hier zeigt sich, dass das eigentliche Problem schon vor etlichen Jahren seinen Lauf nahm. Codepflege ist nämlich nur dann kostspielig, wenn sie zu lange hinausgezögert wurde. Natürlich gibt es Bereiche, die mehr Aufwand bedeuten, doch wenn Sie diese von Beginn an zeitnah erledigen, fallen die Kosten viel niedriger aus, als wenn Sie sie wiederholt vertagen, um sie irgendwann inmitten anderer dringender Aufgaben angehen zu müssen, ohne Zeit und Planung.
Vergleichbar ist das mit einem Haushalt, der nie aufgeräumt wird, stets mit dem Argument, es sei jetzt zu viel Aufwand, bis Sie irgendwann gar kein sauberes Geschirr mehr besitzen und die Wohnung voller Müll liegt, sodass Sie darüber stolpern, hinfallen und sich verletzen. Genau in diesem Moment stellen Sie fest, dass gerade in der Küche ein Feuer ausgebrochen ist, weil dort unbeaufsichtigt ein Topf auf dem Herd stand. Und schon wird die Angelegenheit richtig teuer, womöglich erfordert sie sogar eine Renovierung. War der Plan "sofortiges Aufräumen ist zu viel Aufwand" also wirklich so sinnvoll? Ganz bestimmt nicht.
Gerne wird auch argumentiert:
"Alles funktioniert doch im Großen und Ganzen – wir werden tätig, sobald tatsächlich etwas kaputtgeht."
Das wird gerne noch mit "Never Touch a Running System" unterstrichen. Selbstverständlich sollten Sie nicht ohne konkreten Anlass an funktionierendem Code herumbasteln. Aber es geht nicht ums bloße "Herumbasteln", sondern darum, vorhandene technische Schulden abzutragen, um langfristige Schäden zu vermeiden. Häufig steckt hinter diesem Einwand schlicht die Sorge, bei Umbauten könnte etwas kaputtgehen. Und diese Angst ist in gewisser Weise berechtigt. Doch woher rührt sie? Liegt es daran, dass zu wenige automatisierte Tests existieren? Oder vielleicht gar keine? Gibt es auch kein strukturiertes Testkonzept?
In einem solchen Kontext würde wohl niemand unnötige Änderungen riskieren. Dennoch sollte es normal sein, Code zu revidieren, zu überarbeiten und anzupassen. Die einzige Möglichkeit, sicherzustellen, dass dabei nichts zerbricht, sind umfangreiche Tests, am besten automatisiert, damit sie jederzeit effizient wiederholbar sind. Dass viele Projekte darauf weitgehend verzichten, liegt oft daran, dass jemand meinte, Tests seien zu aufwendig und deshalb nicht so wichtig.
Ein weiteres verbreitetes Argument lautet, dass es zu viel Druck aus dem Fachbereich gäbe. Meistens sind das schlicht unrealistische Erwartungen, verbunden mit wenig Verständnis für die Abläufe in der Softwareentwicklung. Das ist grundsätzlich nachvollziehbar: Denn woher soll ein Fachbereich ohne technische Vorerfahrung es besser wissen? Häufig fehlt dann eine Person, die die Interessen der Entwicklung angemessen vertritt und erklärt, wie Softwareentwicklung funktioniert.
Dieser Effekt zeigt sich meist in Unternehmen, deren Kerngeschäft nicht die Softwareentwicklung an sich ist, sondern beispielsweise in Versicherungen, Baukonzernen, dem Einzelhandel und so weiter, wo Software nur ein notwendiges, aber ungeliebtes Hilfsmittel ist. Dort gilt meist "Umsatz vor Grundsatz". Der Fachbereich setzt sich also oft durch, sodass die Softwareentwicklung mit ihren Qualitätsansprüchen außen vor bleibt. Wird dies nicht klar kommuniziert, entsteht massiver Druck von dieser Seite.
Man könnte diese Liste beliebig fortsetzen, aber ich denke, hier wird bereits ein Muster deutlich. Das Muster lautet: Kurzfristiges Denken hat zu oft Vorrang vor langfristigen Überlegungen. Viel zu häufig geht es um eine rasche, günstige Fertigstellung, ohne den Blick auf langfristige Stabilität und Wartbarkeit. Dieses Problem entsteht nicht erst nach und nach, sondern es existiert meist schon ab dem ersten Tag eines Softwareprojekts, bleibt anfangs aber unbemerkt.
Jeder Schritt, bei dem nicht auch an die spätere Weiterentwicklung gedacht wird, führt in die falsche Richtung. Das resultiert unweigerlich in zerbrochenen Fenstern. Wenn es dann wirklich brennt, möchte niemand eine abrupte Kehrtwende vornehmen, denn schließlich hat doch bis gestern scheinbar alles funktioniert. Das Hinauszögern setzt sich also fort, und das Problem verschlimmert sich noch mehr. Erst wenn irgendwann unübersehbar ist, dass es so nicht weitergehen kann, folgt das große Klagen und die Hoffnung, nun eine einfache Lösung zu finden. Doch eine solche existiert nicht – und das will dann verständlicherweise niemand hören.
Welche Lehre lässt sich aus all dem ziehen?
Erstens: Wenn Sie früh genug dran sind und Ihr Projekt noch auf der sprichwörtlichen grünen Wiese beginnt, sollten Sie von Tag 1 an eine echte Null-Toleranz-Strategie im Hinblick auf Codequalität verfolgen. Das bedeutet, Sie benötigen ein äußerst strenges Projektsetup. Dazu gehören beispielsweise streng konfigurierte Linter-Regeln, automatisierte Formatierung, angemessene Tests sowie eine CI/CD-Pipeline. Es dürfen keinerlei Warnungen von Linter oder Compiler akzeptiert werden: Entweder ist der Code rundum fehlerfrei, oder der Build schlägt fehl. Dazwischen gibt es nichts.
Ebenso sollte kontinuierliches Refactoring einen hohen Stellenwert haben, und Fehler sollten sofort beseitigt werden. Natürlich wird es niemals vollkommen fehlerfreie Software geben, doch sobald ein Fehler bekannt ist, genießt dessen Behebung oberste Priorität. Solange dieser Bug nicht korrigiert ist, wird kein neues Feature entwickelt, eben konsequent gemäß dem Prinzip "Null Toleranz".
Falls nun jemand behauptet, dies wäre ein Freibrief für die Entwicklung, sich in Details zu verlieren, ist das wahre Problem nicht die Null-Toleranz-Strategie, sondern tief sitzendes Misstrauen gegenüber dem Verantwortungsbewusstsein der Entwickler. Das ist ein viel grundlegenderes Thema, das gern ignoriert wird, weil es wesentlich einfacher scheint, Symptome zu bekämpfen als Ursachen.
Zweitens sollten Sie alles, was möglich ist, automatisieren: Tests, Deployments, Updates und so weiter. Letztlich greift hier alles ineinander. Stellen Sie sich vor, es erscheint ein Update für eine Abhängigkeit: Zunächst müssten Sie erfahren, dass es dieses Update gibt. Danach müssten Sie es testweise einspielen, prüfen, ob weiterhin alles funktioniert, einen Branch erstellen, den Commit vornehmen, pushen, einen Pull-Request anlegen und jemanden finden, der das Ganze prüft und freigibt. Natürlich wird sich niemand regelmäßig diesen Aufwand antun wollen.
Wenn jedoch ein Bot automatisch einen Pull-Request stellt, der dann eine CI/CD-Pipeline anstößt und sämtliche Tests ausführt, Sie über die Ergebnisse informiert werden, und Ihre einzige Aktion (zumindest in 95 Prozent der Fälle) darin besteht, den erfolgreich durchgelaufenen Pull-Request durchzuwinken, dann bleibt Ihr Zeitaufwand minimal. Gleichzeitig bleiben Ihre Dependencies auf dem aktuellen Stand, und Sie haben nun auch die zeitlichen Kapazitäten, sich um jene 5 Prozent zu kümmern, bei denen tatsächlich manuelles Eingreifen nötig ist, etwa wegen Breaking Changes. Dies funktioniert aber nur, wenn Sie die betreffenden Prozesse entsprechend automatisiert haben.
Damit komme ich zum letzten Punkt, den ich Ihnen heute mitgeben möchte: Code-Reviews und das Vier-Augen-Prinzip ab Tag 1. Nur so ist sichergestellt, dass jede Änderung geprüft wird und es zudem kein Inselwissen gibt. Nach einem Review haben zumindest zwei Personen den Code durchgesehen und sich damit auseinandergesetzt. Alternativ können Sie auch Pair-Programming nutzen, denn das ist im Grunde lediglich ein Live-Review. Wahrscheinlich hören Sie jetzt schon das Argument, dass dies zu kostenintensiv sei und keine Zeit dafür bleibe, wegen Deadlines, Fachbereich und so weiter. Aber vielleicht haben Sie durch diesen Blogpost ein paar Argumente an der Hand, um all dem zukünftig souveräner zu begegnen.
Unter dem Strich bleibt die Erkenntnis, dass eine dauerhafte, regelmäßige Pflege des Codes langfristig zu weit stabileren und damit auch günstigeren Projekten führt, selbst wenn es anfangs gegen die Intuition sprechen mag.
URL dieses Artikels:
https://www.heise.de/-10284004
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/Broken-Windows-Theorie
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: erzeugt mit KI durch iX)
Man hört oft, komplexe Systeme basierten auf CQRS. Doch was genau ist das eigentlich, CQRS? Was verbirgt sich hinter dem Akronym, und wie kann man es nutzen?
Vor zwei Wochen habe ich einen Blogpost als Einführung in Event-Sourcing [1] geschrieben. Das Thema ist bei vielen von Ihnen auf sehr großes Interesse gestoßen, es gab sehr viel Feedback dazu, und natürlich gab es auch eine ganze Reihe von Fragen. Im heutigen Blogpost greife ich viele dieser Fragen auf und beantworte sie. Sie bekommen aber vor allem auch eine weitere Einführung in ein mit Event-Sourcing zusammenhängendes Konzept: Heute geht es nämlich auch um ein Architektur-Pattern namens CQRS. Was das ist, wofür es gut ist, wie es funktioniert, was die Anwendungsfälle sind, wie Sie es mit Event Sourcing kombinieren können, und so weiter – all das erfahren Sie heute.
Fangen wir einmal, ganz kurz, mit einer Klarstellung an: Vielleicht haben Sie von CQRS schon gehört, und Sie würden nun gerne wissen, was genau es damit auf sich hat, aber vielleicht haben Sie den Blogpost zu Event Sourcing vor zwei Wochen nicht gelesen. Da stellt sich nun die Frage: Können Sie den heutigen Post trotzdem "einfach so" lesen, oder sollten Sie sich zuerst mit dem Thema Event Sourcing beschäftigen?
Nun, dafür ist ganz wichtig: CQRS und Event Sourcing sind zwei Konzepte, die unabhängig voneinander existieren. Das heißt, Sie können CQRS durchaus umsetzen, ohne Event Sourcing nutzen zu müssen, und Sie können Event Sourcing auch umsetzen, ohne CQRS nutzen zu müssen, und insofern könnten Sie diesen Blogpost auch als in sich geschlossenes Thema ansehen.
Aber: Die beiden Konzepte ergänzen einander ausgesprochen gut. Insofern werden Sie sie in der Praxis eher selten isoliert voneinander vorfinden, sondern in der Regel gemeinsam. Deshalb baue ich in diesem heutigen Blogpost auf dem auf, was ich vor zwei Wochen geschrieben habe. Sollten Sie jenen Blogpost [2] also noch nicht gesehen haben, dann würde ich Ihnen empfehlen, das jetzt nachzuholen. Alternativ können Sie ihn sich auch als Video [3] ansehen.
Doch was ist CQRS überhaupt? Das Akronym steht für "Command Query Responsibility Segregation", also für die Trennung der Verantwortlichkeiten für Commands und Queries.
Tatsächlich ist das sehr viel einfacher, als es zunächst klingt. Die Kernidee von CQRS ist, dass es für den Zugriff auf Anwendungen nur zwei Arten von Interaktionsmustern gibt: Entweder führt die Anwenderin oder der Anwender eine Aktion aus, mit der Absicht, im System etwas zu verändern, oder sie oder er möchte etwas wissen. Mehr Möglichkeiten gibt es nicht. Das heißt, entweder teilen Sie einer Software mit, dass sie dies oder jenes für Sie erledigen soll, dann geben Sie ihr quasi einen Befehl (das ist dann ein sogenannter "Command") – oder Sie fragen die Software nach einer Information, Sie stellen also eine Frage oder führen eine Abfrage durch (und das ist dann eine sogenannte "Query").
Das eine, also ein Command, zieht üblicherweise eine Veränderung und damit einen Schreibvorgang nach sich, das andere, also eine Query, greift hingegen nur lesend zu. Man könnte also auch sagen: Es gibt schreibende und lesende Zugriffe. Das CQRS-Entwurfsmuster besagt nun, dass Sie Ihre Anwendung zweiteilen sollten: in einen Teil, der sich um Schreibvorgänge kümmert, und in einen anderen Teil, der sich um Lesevorgänge kümmert. Sie sollen also, und genau das war meine ursprüngliche Aussage, die Verantwortlichkeit für das Schreiben von der für das Lesen trennen.
Worüber dieses Design-Pattern jedoch nichts aussagt, ist, auf welche Art Sie diese Trennung bewerkstelligen sollen. Es ist also erst einmal völlig offen, ob das einfach nur bedeutet, dass Sie gedanklich zwischen schreibenden und lesenden API-Routen trennen, oder ob Sie zwei getrennte APIs bauen, oder ob das zwei getrennte Services sind, oder sonst etwas. Das ist, wie es im Englischen so schön heißt, "up to interpretation". Darauf kommen wir nachher jedoch näher zu sprechen.
Die erst einmal viel spannendere Frage ist: Warum sollte man das überhaupt machen? Also, warum gibt es diese Empfehlung in Form des CQRS-Patterns überhaupt?
Nun, dahinter steckt eine sehr einfache Überlegung, und sie hat erst einmal sehr wenig mit APIs zu tun, sondern viel mehr mit Datenbanken: Wenn wir über klassische Architektur sprechen, haben wir normalerweise eine UI, eine irgendwie geartete API und am Ende eine Datenbank. Obwohl die Datenbank dabei buchstäblich nicht im Mittelpunkt der Entwicklung steht, beschäftigen wir uns in der Softwareentwicklung üblicherweise sehr ausführlich mit ihr, und häufig hat das in der Datenbank gewählte Datenmodell deutliche Auswirkungen darauf, wie die Geschäftslogik in der API gebaut wird. Das heißt, eine essenzielle Frage lautet: Wie sieht ein gutes Datenmodell aus?
Die akademische Welt hat darauf eine passende Antwort: In der Datenbanktheorie gibt es nämlich verschiedene Normalformen. Das kann man sich so ein bisschen vorstellen wie einen Satz von Regeln, wie man Datenmodelle gestalten sollte. Konkret gibt es davon fünf verschiedene Varianten, und die fünfte Normalform entspricht ein wenig dem heiligen Gral: Wenn man sie umsetzt, dann bedeutet das nichts anderes, als dass alles sehr sauber und ordentlich strukturiert ist, dass keinerlei Information dupliziert wird, dass es keine Redundanzen in den Daten gibt, und so weiter. Das ist deshalb erstrebenswert, weil sich dann Konsistenz- und Integritätsregeln sehr leicht umsetzen lassen. Die fünfte Normalform ist so gesehen also ein Traum, wenn es darum geht, Daten zu schreiben.
Ein wenig unglücklich ist nur, dass man Daten in der Regel auch wieder lesen muss. Das ist in der fünften Normalform natürlich möglich, nur muss man hierfür meist sehr komplexe Abfragen ausführen, und man braucht dann, um zum Beispiel etwas Simples wie die Stammdaten einer Anwenderin auszulesen, auf einmal 27 Joins. Das heißt, Lesen ist durchaus machbar, aber es ist völlig ineffizient und langsam. Das ist natürlich sehr unpraktisch und im Alltag wenig nützlich. Also, kurz gesagt: Die fünfte Normalform ist gut zum Schreiben geeignet, aber eine Katastrophe zum Lesen.
Das andere Extrem wäre die erste Normalform: Hier wird einfach für jede View, die es in der UI gibt, eine passende Tabelle angelegt, und die Daten werden überall dorthin verteilt, wo man sie gerade braucht. Das heißt, die Daten werden komplett denormalisiert, was das Lesen rasend schnell macht: Denn mehr als ein SELECT * FROM xy ist dann in der Regel nicht erforderlich, schließlich gibt es ja per Definition für jede View eine passende Tabelle. Insofern ist die erste Normalform ein Traum, wenn es um das Lesen von Daten geht.
Allerdings ist das Schreiben in diesem Fall eher schwierig, denn man muss dieselbe Information mehrfach ablegen, man muss sie mehrfach pflegen, und es ist deshalb sehr kompliziert, Konsistenz und Integrität zu wahren. Man könnte also festhalten, dass die erste Normalform genau das Gegenteil der fünften ist: Die erste ist gut zum Lesen, aber schlecht zum Schreiben.
Wie sieht es nun in der Realität aus? In der Regel nimmt man weder die fünfte noch die erste Normalform, sondern man wählt die Dritte: Das ist der übliche Kompromiss zwischen den beiden Welten, und ich persönlich würde sagen, dass man damit letztlich das Modell nimmt, das weder zum Schreiben noch zum Lesen besonders gut geeignet ist. Man hat nämlich weder einfache Abfragen mit hoher Performance noch die gewünschte Konsistenz und Integrität. Das heißt, mit anderen Worten: Man bekommt das Schlechteste der beiden Welten.
Und was hat das Ganze nun mit CQRS zu tun? Nun, die Aussage war ja, dass man das Schreiben vom Lesen trennen sollte. Und genau das kann man hier nun wunderbar auf Datenbankebene machen: Anstatt zu versuchen, die ganz unterschiedlichen Anforderungen des Schreibens und des Lesens mit einem einzigen Datenmodell zu erfüllen (was, wie gesagt, nicht besonders gut funktioniert), nimmt man schlichtweg zwei Datenmodelle – nämlich eines, das auf das Schreiben optimiert ist, und eines, das auf das Lesen optimiert ist. Dann hat man beim Schreiben die gewünschte Integrität und Konsistenz, und beim Lesen hat man effiziente und performante Abfragen. Der einzige Haken ist dabei nur, dass man natürlich die Änderungen, die im Schreib-Modell erfolgen, irgendwie in das Lese-Modell überführen muss, aber dazu kommen wir nachher noch.
Bevor wir nun weiter in die Details gehen, möchte ich erst einmal ein kleines Beispiel vorstellen, das das Ganze ein wenig veranschaulicht: In dem Blogpost vor zwei Wochen hatte ich als Fachdomäne eine Bibliothek angesprochen, also zum Beispiel eine Stadtbibliothek, in der man sich Bücher ausleihen kann. Ich hatte außerdem geschrieben, dass der Schwerpunkt beim Event Sourcing weniger auf den Substantiven liegt, sondern vielmehr auf den Verben – also mit anderen Worten: auf den Prozessen.
Und welche Prozesse gibt es in einer Bibliothek? Richtig: Man kann Bücher ausleihen, man kann die Ausleihe verlängern, man kann Bücher zurückgeben, man kann sie (aus Versehen oder absichtlich) beschädigen, und so weiter.
All diese Aktionen resultieren, wenn wir uns das als Software vorstellen, in Commands: Als Anwenderin oder Anwender möchte ich zum Beispiel ein Buch ausleihen, also suche ich es im System heraus, prüfe, ob es verfügbar ist, und wenn ja, tippe ich einen Button an, auf dem steht: "Buch ausleihen". Genau das ist mein Command: "Dieses Buch jetzt ausleihen!". Das klingt schon wie ein Befehl. Das System führt dann in Folge Geschäftslogik aus, befolgt dabei die hinterlegten Business-Regeln, prüft, ob ich das Buch ausleihen darf, und entscheidet dann, was passiert. Und damit hat sich dann der Zustand des Systems verändert, was wiederum genau die Definition eines Commands war: ein Schreibvorgang, der den Zustand des Systems ändert.
Wir haben bereits vor zwei Wochen darüber gesprochen, dass sich zum Erfassen dieser Veränderungen Event-Sourcing ganz wunderbar anbietet. Und die Datenbank, in der ich all diese Events im Lauf der Zeit sammle, also ein Append-Only-Log, ist unser Schreib-Modell.
Nun möchte die Bibliothek aber vielleicht gerne wissen, welche Bücher gerade ausgeliehen sind. Oder: Welche Bücher wurden im vergangenen Jahr am häufigsten verlängert? Oder: Gibt es Bücher, die in den vergangenen sechs Monaten gar nicht ausgeliehen wurden? Wie viel Prozent der ausgeliehenen Bücher wurden beschädigt zurückgegeben? Und so weiter.
Diese Liste an Fragen kann man beliebig verlängern.
Nun ist aber der Punkt: All diese Fragen lassen sich zwar auf Basis der Events beantworten, nur leider ist das nicht besonders effizient. Denn wenn ich zum Beispiel wissen will, welche Bücher derzeit alle verliehen sind, dann kann ich theoretisch alle Events von Anfang an durchgehen und eine Liste führen, in der ich jedes Mal, wenn ein Buch ausgeliehen wurde, einen Eintrag mache, und immer dann, wenn ein Buch zurückgegeben wurde, diesen Eintrag wieder streiche. Und wenn ich das von Anfang bis Ende durchziehe, weiß ich am Schluss, welche Bücher aktuell ausgeliehen sind.
Das Gute daran ist also: Ich bekomme diese Information aus meinen Events heraus. Das nicht ganz so Gute daran ist: Es ist ziemlich aufwendig.
All diese Fragen werden gemäß CQRS als Queries angesehen, weil ich etwas wissen möchte und dadurch nicht den Zustand des Systems verändere. Um diese Fragen effizient und performant beantworten zu können, wäre es viel einfacher, wenn ich ein dediziertes Lesemodell hätte. Stellen wir uns also ganz kurz vor, wie das am leichtesten wäre: Die einfachste Möglichkeit wäre eine Tabelle, in der alle aktuell ausgeliehenen Bücher aufgeführt sind. Wenn ich dann nämlich wissen will, welche Bücher gerade verliehen sind, wäre das wirklich nur ein SELECT * FROM xy. Oder, wenn ich wissen möchte, ob ein bestimmtes Buch gerade ausgeliehen ist, könnte ich ebenfalls auf diese Tabelle zugreifen und sagen: SELECT * FROM xy WHERE titel = abc. Entweder bekomme ich einen Treffer, und dann ist das Buch aktuell verliehen, oder eben nicht. Hier wäre also tatsächlich ein denormalisiertes Datenmodell die perfekte Lösung.
Die spannende Frage ist nun: Wo bekomme ich eine solche Tabelle her? Denn die einzigen Daten, die wir aktuell speichern, sind die Events. Die Antwort auf diese Frage ist tatsächlich sehr einfach: Wir bauen die Liste, so wie eben beschrieben, einfach nebenher auf. Also immer, wenn ein Event vom Typ "Buch wurde ausgeliehen" gespeichert wird, speichern wir nicht nur dieses Event, sondern wir tragen das Buch auf Basis der in diesem Event enthaltenen Informationen auch in unsere Liste der aktuell ausgeliehenen Bücher ein.
Immer, wenn ein Event vom Typ "Buch wurde zurückgegeben" gespeichert wird, entfernen wir das Buch wieder von der Liste der ausgeliehenen Bücher. Und immer, wenn ein Event vom Typ "Buch wurde verlängert" gespeichert wird, machen wir mit unserer Tabelle der ausgeliehenen Bücher gar nichts, denn das Verlängern eines Buches ändert nichts daran, dass es bereits verliehen ist.
Sollte nun jemand kommen und uns fragen, welche Bücher aktuell ausgeliehen sind, dann können wir diese Frage ganz einfach beantworten, denn wir haben die Antwort quasi schon vorbereitet.
Und das Beste daran ist, dass wir nicht von Anfang der Entwicklung an wissen müssen, dass uns irgendwann einmal jemand fragen wird, welche Bücher aktuell gerade ausgeliehen sind: Wir können diese Lesemodelle nämlich auch nachträglich noch aufbauen, indem wir alle bereits gespeicherten Events abspulen. Wir können ein Lesemodell also auch im Nachhinein noch anpassen und es einfach neu aufbauen lassen. Wir können auch weitere Lesemodelle ergänzen, oder auch diejenigen, die wir nicht mehr brauchen, einfach entfernen.
Das heißt, wir haben zum Lesen kein statisches Schema mehr, sondern wir können uns gezielt für die relevanten Fragen passende Antwortmodelle zurechtlegen, damit wir sie im Bedarfsfall ad-hoc griffbereit haben. Das beschleunigt das Lesen enorm.
Es wird aber noch besser: Denn nicht jeder Lesevorgang hat dieselben technischen Anforderungen. Für die Liste der gerade ausgeliehenen Bücher eignet sich zum Beispiel eine relationale oder auch eine NoSQL-Datenbank hervorragend. Wenn ich aber zum Beispiel zusätzlich noch eine Volltextsuche über alle Bücher anbieten will, dann müsste ich, immer wenn das Event "Buch wurde neu in den Bestand aufgenommen" gespeichert wird, das Buch indexieren und diese Informationen an beliebiger Stelle ablegen.
Dafür ist aber weder eine relationale noch eine NoSQL-Datenbank à la MongoDB sonderlich gut geeignet, sondern dafür würde sich vielleicht Elasticsearch empfehlen. Dem Prozess, der auf das Event reagiert und daraus ableitet, wie die Lesetabellen zu aktualisieren sind, ist es aber völlig gleichgültig, ob er das für eine, zwei oder mehr Tabellen erledigt. Außerdem ist ihm auch egal, ob diese Tabellen in derselben Datenbank liegen oder ob wir mit verschiedenen Datenbanken sprechen. Mit anderen Worten: Ich kann mir ein Lesemodell, das auf einen bestimmten Use Case abzielt, nicht nur passgenau für diesen aufbauen, sondern ich kann das sogar mit der am besten geeigneten Technologie umsetzen, ohne vorher wissen zu müssen, dass diese Anforderung irgendwann einmal auftauchen wird. Damit wird das Ganze schon sehr flexibel.
Doch man kann es sogar noch weiter treiben: Da sich die Lesemodelle jederzeit aus den Events wieder rekonstruieren lassen, müssen sie theoretisch nicht einmal persistiert werden. Man könnte, zumindest, sofern sie nicht zu groß werden, die Lesemodelle auch einfach im RAM halten. Das ist übrigens gar nicht so abwegig, wie es vielleicht zunächst klingt. Zum einen deshalb nicht, weil Lesezugriffe damit natürlich noch einmal einen enormen Performanceschub erhalten, denn technisch gesehen kann der Zugriff kaum noch schneller erfolgen.
Zum anderen, weil inzwischen einige Systeme auf dem Markt sind, die genau so arbeiten, wie zum Beispiel Memgraph [5] oder DuckDB [6] (zu dem ich vor einigen Monaten auch einen Blogpost geschrieben hatte: "Ente gut, alles gut? [7]").
Das Ganze ist übrigens auch, wenn Sie in Richtung eines Data-Meshs gehen möchten, eine unglaublich gute Ausgangsbasis: Bei einem Data-Mesh geht es ja letztlich darum, dass ein Team, das eine bestimmte fachliche Verantwortung hat, anderen Teams seine Daten passend zur Verfügung stellen kann (als sogenanntes "Data Product"). Und genau dieses "passend zur Verfügung stellen" ist häufig gar nicht so einfach, denn wie oft entspricht schon das interne Datenmodell genau dem, woran jemand anderes interessiert ist?
Das Tolle an Event Sourcing und CQRS ist nun, dass Sie für ein anderes Team einfach ein passendes Lesemodell aufbauen können. Das hat keinerlei Einfluss auf das interne Datenmodell oder auf die Datenmodelle für andere Teams. Und Sie können ein solches Datenmodell auch jederzeit wieder ändern oder entfernen, ohne befürchten zu müssen, dass Sie irgendjemandem etwas kaputtmachen, weil Sie ja einfach für jeden ein eigenes Lesemodell bereitstellen können. Insofern kann ich Ihnen nur raten, wenn das Thema Data-Mesh für Sie relevant ist, sich Event Sourcing und CQRS unbedingt genauer anzusehen.
Und übrigens, nur um es ganz kurz erwähnt zu haben: Auch unterschiedliche Zugriffsrechte lassen sich damit sehr elegant abbilden. Sie bieten für verschiedene Rollen einfach unterschiedliche Lesemodelle an, und die Rolle mit höheren Rechten erhält ein Lesemodell, das mehr Daten enthält, wohingegen die Rolle mit niedrigeren Rechten ein Lesemodell mit weniger Daten erhält. Auch hier können Sie sich das Leben deutlich vereinfachen, im Vergleich dazu, alles in einer einzigen Tabelle mit zig verschiedenen und entsprechend komplexen Abfragen steuern zu müssen.
Nun fragen Sie sich vielleicht:
"Alles schön und gut, aber das bedeutet ja, dass die Last auf meiner Leseseite unter Umständen ganz schön ansteigt. Habe ich da nicht das Problem, dass meine Lese-API mittelfristig überlastet wird?"
Die einfache Antwort lautet: Nein. Denn Sie können nicht nur verschiedene Lesemodelle parallel zueinander betreiben, sondern Sie können auch dasselbe Lesemodell auf mehrere Datenbank- und Server-Instanzen verteilen. Schließlich gilt auch hier wieder: Dem Mechanismus, der auf Events reagiert und dementsprechend die Lesetabellen aktualisiert, ist es egal, ob das unterschiedliche Lesetabellen sind oder ob es mehrere Kopien derselben Tabelle auf unterschiedlichen Servern gibt.
Das heißt, Sie können die Leseseite praktisch ohne Overhead beliebig skalieren, indem Sie einfach parallelisierte Kopien des Lesemodells vorhalten, und das sogar individuell pro Lesemodell, je nachdem, auf welches Lesemodell viel und auf welches eher wenig zugegriffen wird. Das heißt, CQRS ermöglicht es Ihnen, genau dort und nur dort zu skalieren, wo die Last am höchsten ist.
Wie auch schon bei Event Sourcing möchte ich Ihnen natürlich auch bei CQRS die Herausforderungen nicht verschweigen. Denn es ist nicht so, dass es keine gäbe: Auch CQRS ist keine magische Wunderlösung, die alle Ihre Probleme "einfach so" löst.
Das Hauptproblem ist, dass die erforderliche Synchronisation zwischen der Schreib- und der Leseseite Zeit benötigt. Ich habe Ihnen diesen Mechanismus so beschrieben, dass er auf gerade gespeicherte Events reagiert und dann die Lesemodelle anpasst. Nun ist klar, dass wenn wir hier über ein verteiltes System mit verschiedenen Datenbanken sprechen, zwischen dem Speichern des Events und dem Aktualisieren des Lesemodells ein wenig Zeit vergeht. Das wird im Normalfall nicht allzu viel sein (meist handelt es sich um ein paar Millisekunden), aber es bedeutet eben, dass die Leseseite immer ein kleines Stück hinterherhinkt.
Es ist dabei jedoch nicht so, dass die Leseseite nicht konsistent wäre: Das ist sie schon, nur ist sie das eben nicht sofort, sondern sie benötigt einen kurzen Augenblick. Das nennt man, in Abgrenzung zur "strong consistency" dann "eventual consistency". Doch da muss man aufpassen, denn das wird im Deutschen gerne als "eventuell konsistent" übersetzt – was jedoch falsch ist. Tatsächlich heißt "eventually consistent" nämlich so viel wie letztlich oder schlussendlich konsistent. Die Frage, die sich also stellt, lautet: Wie gravierend ist dieser kleine zeitliche Versatz in der Praxis?
Die Antwort lautet: "Es kommt darauf an."
Tatsächlich ist das nämlich keine technische Frage, sondern eine fachliche: Wie hoch ist die Wahrscheinlichkeit, dass dieser geringe zeitliche Versatz zu einem Problem führt, wie sähe dieses Problem aus, wie groß ist das Risiko im Falle des Falles, und was könnten wir dann unternehmen?
Je nachdem, wie Sie diese Fragen beantworten, ergibt sich, ob Eventual Consistency ein Problem darstellt oder nicht. Um es noch einmal zu betonen, weil das so gerne missverstanden wird: Das ist keine technische Frage. Das ist nichts, was Entwicklerinnen und Entwickler entscheiden könnten. Das ist etwas, was der Fachbereich entscheiden muss. Und der Punkt dabei ist natürlich, dass es durchaus Alternativen zu Eventual Consistency gibt (zum Beispiel durch eine einzige große verteilte Transaktion), nur hätte das dann andere Nachteile. Und falls Sie schon einmal mit verteilten Transaktionen in verteilten Systemen zu tun hatten, dann wissen Sie, dass das alles ist, nur kein Vergnügen.
Insofern: Es geht nicht darum, zu sagen, Eventual Consistency sei grundsätzlich gut oder schlecht, oder Strong Consistency sei grundsätzlich gut oder schlecht, sondern es geht darum, herauszufinden, welches Konsistenzmodell für den konkreten fachlichen Use Case besser geeignet ist.
Da sagen viele:
"Nein, also auf Strong Consistency können wir unter gar keinen Umständen verzichten!"
Und ja, natürlich gibt es Szenarien, in denen das so ist: Das ist aus meiner Erfahrung vor allem dann der Fall, wenn die nationale Sicherheit betroffen sein könnte oder wenn es um den Schutz von Leib und Leben geht. In 99,9 Prozent aller Business-Anwendungen ist das meiner Erfahrung nach aber völlig nebensächlich, da reicht Eventual Consistency in aller Regel mehr als aus.
Um hier das gängige Lehrbuch-Beispiel anzuführen: Ein Geldautomat, der die Netzwerkverbindung verliert, wird Ihnen trotzdem noch für eine gewisse Zeit Bargeld auszahlen. Denn die meisten Menschen heben ohnehin keine besonders hohen Beträge ab, und die meisten Menschen machen dies nur, wenn sie wissen, dass genug Geld auf ihrem Konto ist. Das heißt, die Wahrscheinlichkeit und das Risiko, dass die Bank Geld herausgibt, das Ihnen nicht zusteht, ist äußerst gering.
Selbst wenn das passiert, dann holt die Bank es sich eben mit Zinsen und Zinseszinsen zurück. Das heißt, aus dem netzwerktechnischen Ausfall zieht die Bank im Zweifelsfall sogar noch einen Vorteil. Dieses Vorgehen ist aus Geschäftssicht für die Bank weitaus besser, als die vermeintlich naheliegende technische Lösung zu wählen und den Geldautomaten offline zu schalten – denn dann würde am nächsten Tag möglicherweise auf Seite 1 der Boulevardzeitung stehen:
"Skandal! Multimilliardär stand vor dem Geldautomaten und konnte keine 50 Euro abheben! Ist das die neue Service-Wüste?"
Und das möchte garantiert niemand.
Ich glaube, damit haben Sie einen ganz guten Überblick darüber, was hinter CQRS steckt und auch, warum CQRS und Event Sourcing so gut zusammenpassen: Sie ergänzen sich einfach sehr, sehr gut, weil das Append-Only-Prinzip von Event Sourcing ein sehr einfaches Modell zum Schreiben von Daten ist, aus dem sich dann äußerst flexibel beliebige Lesemodelle generieren lassen.
Unterm Strich wirkt das Ganze vielleicht anfangs ein wenig einschüchternd. Das kann ich gut nachvollziehen, denn mir ging es vor mehr als zehn Jahren, als ich anfing, mich mit diesen Themen zu beschäftigen, nicht anders. Aber eigentlich sind diese Themen gar nicht so übermäßig kompliziert, sondern sie sind nur sehr anders als das, was die meisten von uns gewohnt sind. Und das dauert einfach, weil man sich komplett umgewöhnen muss und vieles, was man bislang über Softwareentwicklung gedacht und geglaubt hat, quasi entlernen muss.
Wenn man das aber einmal geschafft hat, wirkt diese "neue Welt" sehr viel intuitiver und sinnvoller als die klassische, herkömmliche Entwicklung. Viele, die sich daran gewöhnt haben, fragen sich hinterher, wie sie jemals der Meinung sein konnten, klassisch zu entwickeln, sei eine gute Idee gewesen. Mir ging das so, und vielen unserer Kunden, die wir bei the native web [8] bei der Einführung von Event Sourcing und CQRS beraten und unterstützt haben, ebenfalls.
Also lassen Sie sich davon bitte nicht abschrecken. Es wird Ihnen am Anfang schwierig erscheinen, weil Ihnen die Erfahrung fehlt, doch nach einer Weile werden Sie zurückblicken und denken:
"Wow, das war eine der besten Entscheidungen in meinem Leben als Entwicklerin oder Entwickler, mich auf diese Themen einzulassen."
Wenn Sie mehr wissen möchten, und Sie diesen Blogpost (und den vergangenen zu Event Sourcing) spannend fanden, dann habe ich eine gute Nachricht für Sie: Ich werde in den kommenden Wochen und Monaten noch einige weitere Blogposts zu diesen Themen schreiben, und dabei nach und nach auch mehr ins Detail und mehr in die Praxis gehen. Und wir werden auf unserem YouTube-Kanal [9] über kurz oder lang auch einen Livestream dazu machen.
In diesem Sinne: Bleiben Sie gespannt!
URL dieses Artikels:
https://www.heise.de/-10275526
Links in diesem Artikel:
[1] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[2] https://www.heise.de/blog/Event-Sourcing-Die-bessere-Art-zu-entwickeln-10258295.html
[3] https://www.youtube.com/watch?v=ss9wnixCGRY
[4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[5] https://memgraph.com/
[6] https://duckdb.org/
[7] https://www.heise.de/blog/Ente-gut-alles-gut-DuckDB-ist-eine-besondere-Datenbank-9753854.html
[8] https://www.thenativeweb.io/
[9] https://www.youtube.com/@thenativeweb
[10] mailto:mai@heise.de
Copyright © 2025 Heise Medien

(Bild: Piyawat Nandeenopparit / Shutterstock.com)
Eine neue Annotation ermöglicht es, über Prioritäten explizit festzulegen, welche Methodenüberladung der Compiler aufrufen soll.
Mit [OverloadResolutionPriority] im Namensraum System.Runtime.CompilerServices können Entwicklerinnen und Entwickler festlegen, dass bestimmte Überladungen bei der Entscheidung, welche Überladung verwendet werden soll, eine höhere Priorität erhalten. Das hilft zum Beispiel, wenn mit [Obsolet] annotierte Überladungen einer Methode existieren, um zur präferierten Implementierung zu lotsen.
Bei der neuen Annotation [OverloadResolutionPriority] gibt man eine Integer-Zahl an:
Das folgende Listing zeigt ein Beispiel: Der Aufruf von Print() mit einer Zeichenkette würde ohne [OverloadResolutionPriority] immer zur Implementierung von Print() mit einem String-Parameter gehen, auch wenn diese Überladung als [Obsolete] gekennzeichnet ist. Durch das Einfügen von [OverloadResolutionPriority] lenkt man den Compiler auf eine andere Implementierung um. Würde man in dem Beispiel sowohl der Implementierung mit Parametertyp object als auch ReadOnlySpan<char> den gleichen Prioritätswert geben, wüsste der Compiler nicht, welche Konvertierung er machen soll und verweigert die Übersetzung:
The call is ambiguous between the following methods or properties: 'CS13_OverloadResolutionPriority.Print(object, ConsoleColor)' and 'CS13_OverloadResolutionPriority.Print(ReadOnlySpan<char>, ConsoleColor)'
Mit einem abweichenden Prioritätswert kann man den Compiler zu der einen oder der anderen Implementierung lenken, hier im Listing mit Wert 10 zu public void Print(ReadOnlySpan<char> text, ConsoleColor color).
Die Implementierung public void Print(object text, ConsoleColor color) kommt aber weiterhin zum Einsatz für alle anderen Datentypen, zum Beispiel Zahlen wie 42, denn diese kann der Compiler nicht automatisch in ReadOnlySpan<char> konvertieren.
Folgender Code zeigt den Einsatz der neuen Annotation [OverloadResolutionPriority]:
using System.Runtime.CompilerServices;
namespace NET9_Console.CS13;
public class CS13_OverloadResolutionPriority
{
public void Run()
{
CUI.Demo(nameof(CS13_OverloadResolutionPriority));
// verwendet Print(ReadOnlySpan<char> text)
ReadOnlySpan<char> span = "www.IT-Visions.de".AsSpan();
Print(span);
// verwendet Print(ReadOnlySpan<char> text) wegen OverloadResolutionPriority(10)
Print("Dr. Holger Schwichtenberg");
// verwendet public void Print(object obj)
Print(42);
}
[Obsolete]
//[OverloadResolutionPriority(10)]
public void Print(string text)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Red;
// Print the text
Console.WriteLine("string: " + text);
// Reset the console color
Console.ResetColor();
}
[OverloadResolutionPriority(1)]
public void Print(object obj)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Yellow;
// Print the text
Console.WriteLine("Object: " + obj.ToString());
// Reset the console color
Console.ResetColor();
}
[OverloadResolutionPriority(10)]
public void Print(ReadOnlySpan<char> text)
{
// Set the console color
Console.ForegroundColor = ConsoleColor.Green;
// Print the text
Console.WriteLine("ReadOnlySpan<char>: " + text.ToString());
// Reset the console color
Console.ResetColor();
}
}

(Bild: Screenshot (Holger Schwichtenberg))
Wenn man bei public void Print(string text, ConsoleColor color) auch eine Overload Resolution Priority von mindestens 10 setzt
[Obsolete]
[OverloadResolutionPriority(10)]
public void Print(string text, ConsoleColor color)
{
// Set the console color
Console.ForegroundColor = color;
// Print the text
Console.WriteLine("string: " + text);
// Reset the console color
Console.ResetColor();
}
dann wird bei
Print("Dr. Holger Schwichtenberg", ConsoleColor.Yellow);die Überladung mit string-Parameter genommen, auch wenn diese mit [Obsolete] markiert ist.
URL dieses Artikels:
https://www.heise.de/-10272355
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

Dank KI können Entwickler viele neue Anwendungsfälle umsetzen. Die Built-in-AI-APIs bringen KI-Modelle auf das eigene Gerät.
(Bild: Fabio Principe/ Shutterstock.com)
Chatbots und andere Use Cases rund um natürliche Sprache laufen dank der Built-in-AI-APIs direkt im Browser. Erste APIs können Developer in Chrome testen.
Generative KI legt den Grundstein für zahlreiche Anwendungsfälle, die vorher schwierig oder gar nicht umzusetzen waren. Sie legt den Fokus auf das Verarbeiten und Erzeugen von Inhalten wie Text, Bildern, Audio und Video mithilfe von Machine-Learning-Modellen: In der Trainingsphase werden sie mit erheblichen Datenmengen trainiert und können dann aus ihnen völlig unbekannten Situationen sinnvolle Zusammenhänge schließen, in denen regelbasierte Algorithmen an ihre Grenzen stoßen.
Large Language Models (LLMs) beschränken sich auf das Verarbeiten und Erzeugen von Text in natürlicher Sprache. Sie sind bereits zu einem wichtigen Baustein in der Softwarearchitektur geworden: LLMs können Inhalte übersetzen, Daten aus unstrukturiertem Text extrahieren, längere Textabschnitte präzise zusammenfassen, Code schreiben oder interaktive Dialoge mit dem Anwender führen.
Bislang führte der Weg zur Nutzung von LLMs praktisch immer in die Cloud. Gerätehersteller sind jedoch dazu übergegangen, LLMs mit ihren Geräten und Betriebssystemen auszuliefern: Die Funktionen von Apple Intelligence wie das Zusammenfassen mehrerer Benachrichtigungen werden durch ein lokales LLM ausgeführt [1]. Google liefert High-End-Smartphones mit seinem LLM Gemini Nano aus [2] und Microsoft bringt mit der Windows Copilot Runtime sein LLM Phi Silica auf Windows-Geräte [3].
Lokal ausgeführte LLMs sind auch offline verfügbar, haben ein verlässliches Antwortverhalten unabhängig von der Netzwerkqualität und die Userdaten verlassen das Gerät nicht, was die Privatsphäre des Anwenders schützt. Da LLMs aber einen großen Speicherplatzbedarf haben, werden oftmals eher kleinere LLMs eingesetzt, die eine geringere Antwortqualität haben. Die Performance hängt zudem vom Endgerät ab.
Im Rahmen seiner Built-in-AI-Initiative [4] liefert Google KI-Modelle zu Testzwecken mit seinem Browser Google Chrome aus. Für die Installation werden Windows 10 oder 11, macOS ab Version 13 (Ventura), 6 GByte Video-RAM und mindestens 22 GByte freier Festplattenplatz auf dem Volume des Chrome-Profils vorausgesetzt, die heruntergeladenen KI-Modelle sind allerdings deutlich kleiner.
Nach dem initialen Download teilen sich sämtliche Webseiten den Zugriff auf diese Modelle über sechs Built-in-AI-APIs [5], die innerhalb der Web Machine Learning (WebML) Community Group [6] des W3C spezifiziert sind. Eine der APIs ist allgemein verwendbar, während der Rest aufgabenspezifisch ist:
Während die Prompt API und Writing Assistance APIs derzeit auf das LLM Gemini Nano 2 mit 3,25 Milliarden Parametern zurückgreifen, werden für die Translation und Language Detection API intern andere Modelle genutzt.
Das Chrome-Team stellt die APIs derzeit im Rahmen eines Origin Trial zur Verfügung. Dabei handelt es sich um eine Testphase für neue Webplattform-APIs. Entwickler müssen von Google ein Origin-Trial-Token beziehen [10] und mit ihrer Website ausliefern. Dann wird die Schnittstelle auf dieser Website aktiviert, auch wenn sie noch nicht allgemein verfügbar ist.
Auf diese Art können Interessierte die Translator API, Language Detector und Summarizer APIs bereits testen. Auch für die Prompt API gibt es eine Origin Trial, allerdings nur für Chrome-Erweiterungen.
Da sich die APIs noch alle im Spezifikationsprozess befinden und sich das KI-Feld stetig weiterbewegt, sind Änderungen an den Schnittstellen sehr wahrscheinlich. So soll etwa die Prompt API künftig multimodale Eingaben (neben Text auch Bilder oder Audiomitschnitte) verarbeiten können.
Mit dem Paket @types/dom-chromium-ai [11] stehen bereits TypeScript-Definitionen zur Verfügung, um die APIs bequem aus eigenem TypeScript-Code aufrufen zu können. Das Paket entspricht derzeit der in Chrome 128.0.6545.0 implementierten API. Änderungen werden mit neuen Chrome-Versionen nachgeliefert.
Das folgende Beispiel zeigt die Verwendung der Language Detector API in einer Webanwendung:
const languageDetector = await self.ai.languageDetector.create();
const review = "こんにちは!Hier esse ich einfach am liebsten Sushi."
+ "Immer super 美味しい!";
const result = await languageDetector.detect(review);
// result[0]: {confidence: 0.800081193447113,
detectedLanguage: 'de'}
// result[1]: {confidence: 0.0267348475754261,
detectedLanguage: 'ja'}Die Built-in-AI-APIs sind ein spannendes Experiment, das die Fähigkeiten generativer KI direkt auf das eigene Gerät bringt. Entwickler und Entwicklerinnen können im Rahmen des Early-Preview-Programms für Built-in AI [12] Feedback an das zuständige Chrome-Team richten.
Danke an Thomas Steiner für das Review dieses Blogposts.
URL dieses Artikels:
https://www.heise.de/-10256818
Links in diesem Artikel:
[1] https://www.heise.de/news/Statt-Cloud-Apples-LLM-angeblich-vollstaendig-on-device-9692827.html
[2] https://www.heise.de/news/Google-Gemini-zieht-in-Android-und-iOS-Geraete-ein-samt-Live-Funktion-9834081.html
[3] https://www.heise.de/news/Windows-Copilot-Runtime-Fundament-fuer-offene-KI-Entwicklung-mit-APIs-und-SLMs-9731468.html
[4] https://developer.chrome.com/docs/ai/built-in?hl=de
[5] https://developer.chrome.com/docs/ai/built-in-apis?hl=de
[6] https://webmachinelearning.github.io/incubations/
[7] https://github.com/webmachinelearning/prompt-api
[8] https://github.com/webmachinelearning/writing-assistance-apis
[9] https://github.com/webmachinelearning/translation-api
[10] https://developer.chrome.com/origintrials/
[11] https://www.npmjs.com/package/@types/dom-chromium-ai
[12] https://developer.chrome.com/docs/ai/built-in-apis?hl=de#participate_in_early_testing
[13] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Andrey Suslov/Shutterstock.com)
Viele Unternehmen setzen auf UI-Libraries – und kämpfen über kurz oder lang mit den damit verbundenen Nachteilen. Warum ist das so und wie macht man es besser?
Ich hätte nie gedacht, dass dieser Tag einmal kommt, aber er ist da: Wir arbeiten aktuell mit einer Behörde zusammen, und diese hat etwas geschafft, woran 99 Prozent aller Unternehmen scheitern. Sie haben eine ganz bestimmte Entscheidung strategisch richtig getroffen: Sie haben sich nämlich nicht einfach wahllos für eine UI-Library für ihre Entwicklung entschieden, sondern erst einmal ihre fachlichen Anforderungen durchdacht und darauf basierend dann technologische Entscheidungen getroffen.
Doch leider ist das die absolute Ausnahme. Denn in den meisten Fällen läuft es genau umgekehrt. Und da fangen die Probleme an. Und genau deshalb, weil das so verbreitet ist und weil man es so viel besser machen kann, als es die meisten Unternehmen da draußen tun, geht es heute um den Einsatz von UI-Libraries.
Ein typisches Szenario: Ein Unternehmen plant eine neue Software und hat bereits ein paar Ideen. Trotzdem ist es manchmal ganz gut, ein wenig Unterstützung zu haben, um von außen validieren zu lassen, dass man von vornherein in die richtige Richtung läuft. Genau dafür gibt es Beratungsunternehmen, wie ja nicht zuletzt auch wir eines sind. Da wir bei the native web [1] auf Web- und Cloud-Entwicklung spezialisiert sind, kommt natürlich auch immer wieder das Thema UI zur Sprache. Und da überlegen sich viele Unternehmen, dass sie für ihre UI doch auf eine Library setzen könnten, zum Beispiel Material UI, und sie glauben, damit wäre die Frage beantwortet, wie (also mit welcher Technologie) sie ihre UI bauen sollten.
Das scheint zunächst einmal sinnvoll zu sein: Immerhin sparen UI-Libraries in der Entwicklung einiges an Zeit und Aufwand. Zumindest scheint das auf den ersten Blick so. Und genau deshalb entscheiden sich Unternehmen auch so gerne dafür: Sie möchten die versprochenen Vorteile nutzen und ihre Entwicklung beschleunigen. Das – und das muss ich an dieser Stelle vielleicht noch einmal explizit betonen – ist ein völlig legitimer Wunsch und eine völlig legitime Überlegung.
Viele Unternehmen sehen aber nicht, dass dieser Ansatz seinen Preis hat. Konkret sind es vor allem drei Risiken, die man sich damit ungewollt einkauft:
Und nur, damit es nicht missverstanden wird: Auch wenn ich hier schon ein paar Mal Material UI erwähnt habe, liegt das Problem nicht an Material UI! Material UI ist eine tolle UI-Library, solange Sie zufällig genau das Design wünschen, das Material UI vorgibt.
Was wir regelmäßig erleben, ist, dass wir um eine Einschätzung gebeten werden, wie wir die Idee beurteilen, auf Material UI (oder eine andere UI-Library) zu setzen. Denn das wäre ja alles bereits vorhanden, wäre entsprechend günstig, und man käme damit sehr zügig voran, und so weiter. Viele Unternehmen sind dann überrascht, dass wir darauf vielleicht nicht ganz so begeistert reagieren.
Wir erklären dann oft, dass wir eher davon abraten würden, eine solche Library einzusetzen, einfach um zu vermeiden, dass man sich in eine große Abhängigkeit begibt, sich den Weg in die Zukunft verbaut und sich die Möglichkeit für individuelle Anpassungen nimmt. Das bedeutet, wir empfehlen in sehr vielen Fällen, die eigenen Controls zu entwickeln, und daraufhin kommt praktisch immer das Standard-Gegenargument, das sei ja so fürchterlich teuer: Denn man müsse ja auch Mobile berücksichtigen, und man müsse ja ebenfalls Accessibility berücksichtigen, und so weiter.
Aus eigener Erfahrung kann ich sagen, dass dies zum einen gar nicht so teuer ist, wie viele immer annehmen, und dass die größten Kosten in Bezug auf Mobile, Accessibility und so weiter nicht in der Implementierung, sondern in der Konzeption der Benutzerführung anfallen. Und diese Kosten entstehen ja ohnehin, ob nun mit oder ohne UI-Library. Nur glauben Unternehmen dies oft nicht, weil es für sie häufig nicht wirklich greifbar ist, da sie beispielsweise keine Erfahrung mit UX-Design haben. Sie wissen jedoch, dass Entwicklung teuer ist, also versuchen sie, an dieser Stelle Kosten zu sparen.
Das Ganze endet dann meist damit, dass wider den Rat von außen doch eine UI-Library eingesetzt wird. Und ironisch wird es dann (und das habe ich tatsächlich schon einige Male erlebt), wenn schon nach wenigen Wochen die ersten Wünsche laut werden: Controls sollen bewusst anders aussehen, sich bewusst anders verhalten, das Ganze soll mit einem eigentlich nicht kompatiblen CSS-Framework kombiniert werden und so weiter.
Dann geschieht genau das Gegenteil von dem, was sich das Unternehmen ursprünglich erhofft hatte: Die Entwicklungskosten steigen massiv, alles dauert sehr lange, und es treten ständig merkwürdige Fehler in der UI auf, weil versucht wird, die vorgegebene Logik der Library zu umgehen. Am Ende kann das nur scheitern. Und Sie stehen dann als Berater daneben und denken sich:
"Tja, das ist genau das, was ich Euch vorhergesagt habe, aber Ihr wolltet ja keine Beratung, sondern einen Papagei, der nur "ja" sagen kann, Und eigentlich habt Ihr nur gehofft, jemanden zu finden, der Eure fragwürdige Idee von außen absegnet."
Beratung muss ehrlich sein und auch unangenehme Antworten liefern dürfen.
All das ist leider kein Einzelfall – es kommt tatsächlich ständig vor. Wie schon erwähnt, ist das eigentliche Problem aber nicht die UI-Library an sich. Das Problem besteht vielmehr darin, dass Unternehmen sich für eine bestimmte Technologie entscheiden, bevor sie ihre Anforderungen wirklich verstanden haben. Da wird dann häufig mit Zeit und Kosten argumentiert, aber der springende Punkt ist: Wenn man noch gar nicht genau weiß, was man überhaupt will, kann man auch keine Technologie wählen, um das Ziel zu erreichen, denn man kennt dieses Ziel noch nicht.
Das ist, wie wenn Sie ein Fertighaus kaufen und dann die Wände herausreißen, weil Ihnen im Nachhinein auffällt, dass Sie eigentlich viel eher einen Loft-Charakter wollten. Man kann das natürlich trotzdem machen, aber es ist und bleibt doch eher eine schlechte Idee.
Das bedeutet, die richtige Reihenfolge sollte lauten:
Von diesen vier Punkten konzentrieren sich die meisten Unternehmen jedoch auf den letzten, und insbesondere das Thema UI/UX-Konzept wird oft übergangen. Dabei ist das so ungemein wichtig. Mit anderen Worten: Bei sehr vielen Unternehmen kommt die Technik vor dem Konzept, und das führt über kurz oder lang zu absurden Workarounds.
Nun stellt sich die Frage: Wie kann man es besser angehen? Einen Punkt habe ich schon angesprochen: Es ist oft gar nicht so sinnvoll, auf eine UI-Library zu setzen, sondern man sollte viel häufiger eigene UI-Komponenten entwickeln. Das ist sehr viel weniger aufwendig als oft angenommen. Und der Vorteil ist: Man hat die volle Kontrolle, bleibt flexibel, bleibt unabhängig und vermeidet langfristig zahlreiche Probleme.
Noch wichtiger ist allerdings etwas anderes: Denn – und das habe ich oben ebenfalls erwähnt – grundsätzlich ist nichts falsch am Einsatz von UI-Libraries. Man muss sich nur im Vorfeld genau überlegen, ob das eine gute Idee ist. Passen sie wirklich zu 100 Prozent zu den Anforderungen? Oder gibt es doch Aspekte, die man gerne anders hätte, bei denen man bewusst vom getrampelten Pfad abweichen möchte, und macht man sich damit nicht auf lange Sicht das Leben schwerer, wenn man auf eine Standardlösung setzt?
Ich kann es nur wiederholen: Die initialen Kosten und der anfängliche Entwicklungsaufwand sind langfristig nahezu zu vernachlässigen. Denn allzu oft läuft es so ab:
"Ah, großartig, wir nehmen eine UI-Library, damit wir jetzt weniger Arbeit haben und schneller vorankommen!"
Ja, und drei Monate später sitzt man dann dort mit 10.000 Zeilen CSS-Hacks, aber Hauptsache, man hat anfangs zwei Tage Arbeit gespart …
So, und da kann ich nur sagen: Begehen Sie nicht denselben Fehler! Setzen Sie sich vor einer Entscheidung für oder gegen eine Technologie intensiv mit Ihren Anforderungen auseinander und prüfen Sie dies im Hinblick auf Ihre Corporate Identity und Ihr Corporate Design. Nehmen Sie sich die Zeit, ein fundiertes UI-/UX-Konzept zu entwickeln, und beschäftigen Sie sich zumindest in einem Proof of Concept damit, wie komplex und aufwendig es tatsächlich wäre, eigene UI-Komponenten zu konzipieren und umzusetzen.
Und wie zu Beginn dieses Blogposts gesagt: Es gibt Unternehmen, die das von Anfang an richtig angehen, aber die sind leider selten. Sorgen Sie also dafür, dass Ihr Unternehmen zu diesem Kreis gehört!
URL dieses Artikels:
https://www.heise.de/-10266999
Links in diesem Artikel:
[1] https://www.thenativeweb.io/
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=uRljbIxtauA
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock.com)
Der Vortrag in Dortmund behandelt die Neuerungen in der Syntax von C# 13.0, der .NET 9.0-Basisklassenbibliothek sowie den Anwendungsmodellen.
Ich möchte Sie kurz auf meinen nächsten ehrenamtlichen User-Group-Vortrag aufmerksam machen.
Am 5. Februar 2025 von 18 Uhr bis etwa 20:30 Uhr halte ich in Dortmund den Vortrag "Was bringen C# 13.0 und .NET 9.0?"
Die Veranstaltung der .NET User Group Dortmund ist kostenlos. Sie findet bei der Adesso AG am Adessoplatz 1, 44269 Dortmund in der ersten Etage statt.
Der Vortrag hat folgende Inhalte:
Hier geht es zur Anmeldung:
Die Teilnahme ist kostenfrei. Eine Anmeldung ist jedoch zwingend erforderlich [1]. Die Teilnehmeranzahl ist durch die User Group auf 60 Personen begrenzt.
Denjenigen, die nicht persönlich zu dem Termin nach Dortmund kommen können oder mehr wissen wollen als ich an dem einen Abend vermitteln kann, empfehle ich alternativ meine vier Bücher zu .NET 9.0 zu lesen [2].Das geht besonders günstig im E-Book-Abo [3] (ab 99 Euro/Jahr). Hierin sind auch die laufenden Updates aller meiner .NET- und Web-Bücher enthalten.
URL dieses Artikels:
https://www.heise.de/-10261744
Links in diesem Artikel:
[1] https://www.it-visions.de/V11610
[2] https://www.it-visions.de/buecher/verlag.aspx
[3] https://www.it-visions.de/BuchAbo
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: sabthai/Shutterstock.com)
Event Sourcing ist ein alternativer Ansatz für das Speichern und Verwalten von Daten. Wie funktioniert Event Sourcing und was sind die Vor- und Nachteile?
Kennen Sie das? Sie entwickeln eine Software (ganz gleich, ob für einen Kunden oder für die interne Fachabteilung), und kaum ist sie fertig, kommen schon die ersten Änderungs- und Anpassungswünsche: neue Funktionen, komplexere Analysen, mehr Reports und so weiter. Und oft fehlen entweder die richtigen Daten, oder die Code-Anpassungen sind aufwendiger und fehleranfälliger, als sie sein müssten. Und das führt zu Frust: bei Ihnen und auch bei Ihren Anwenderinnen und Anwendern.
Doch was wäre, wenn sich Software so entwickeln ließe, dass solche Änderungen und Erweiterungen deutlich einfacher und flexibler möglich sind? Genau darum geht es heute: Wir schauen uns an, warum viele Systeme für diese Herausforderungen nicht gemacht sind und wie wir das besser lösen können. Und wenn Sie bei der Softwareentwicklung flexibler und effizienter werden möchten, dann sind Sie hier genau richtig.
Was ist das Problem? Völlig gleich, mit welcher Architektur Sie arbeiten, ob Sie einen Monolithen entwickeln, ein Client-Server-System, eine Peer-to-Peer-Lösung, eine verteilte servicebasierte Anwendung oder etwas anderes – eines bleibt stets gleich, nämlich die Datenhaltung. Vielleicht würden Sie jetzt entgegnen, dass das nicht stimme, denn immerhin gäbe es nicht nur relationale Datenbanken, sondern auch NoSQL-Datenbanken oder File Storage und dieses und jenes, doch eines haben all diese Storage-Ansätze gemeinsam: Sie speichern stets den Status quo.
Wenn Sie etwa eine Software für eine Bibliothek schreiben, in der man Bücher ausleihen, verlängern und zurückgeben kann, dann ist es sehr wahrscheinlich, dass für jedes Buch ein Datensatz angelegt wird, wenn das Buch in den Bestand aufgenommen wird, und dass dieser Datensatz jedes Mal aktualisiert wird, wenn das Buch ausgeliehen, verlängert oder zurückgegeben wird, und schließlich gelöscht wird, wenn das Buch irgendwann so zerfleddert ist, dass es aus dem Bestand entfernt wird. Und das erscheint so logisch und naheliegend, dass man in der Regel gar nicht hinterfragt, ob das wirklich sinnvoll ist.
Doch warum wirkt das so logisch und naheliegend? Nun, ganz einfach: Weil wir das alle von klein auf so vermittelt bekommen haben – ganz gleich, ob Sie eine Ausbildung gemacht oder studiert haben, ob Sie an einer Fachhochschule oder an einer Universität waren, oder mit welcher Programmiersprache Sie aufgewachsen sind: Die Wahrscheinlichkeit, dass Sie das Speichern von Daten genau so gelernt haben, nämlich Datensätze anzulegen, bei Bedarf zu ändern und schließlich irgendwann zu löschen, ist nahezu immer gegeben.
Für diese Art, mit Daten umzugehen, gibt es sogar einen Fachbegriff, nämlich "CRUD": Das steht für "Create", "Read", "Update" und "Delete", also die vier Verben, mit denen wir in einer Datenbank auf Daten zugreifen können. Und das findet sich tatsächlich überall, egal, ob Sie eine relationale Datenbank wie beispielsweise PostgreSQL oder Microsoft SQL Server einsetzen oder ob Sie mit einer NoSQL-Datenbank wie etwa MongoDB oder Redis arbeiten. Und genau das meine ich: Die Art und Weise, in der wir Daten speichern und mit ihnen umgehen, ist konzeptionell stets dieselbe.
Das wirkt zunächst auch gar nicht schlimm, denn es funktioniert offensichtlich seit vielen Jahrzehnten problemlos. Und Daten werden nun einmal angelegt, geändert und gelöscht. Das ist quasi ein universelles Prinzip. Aber: Wo Licht ist, ist immer auch Schatten. Und natürlich gibt es Aspekte, die mit diesem CRUD-Ansatz einfach nicht gut funktionieren. Ich bin mir sehr sicher, dass Sie selbst schon mindestens einmal ein solches Szenario erlebt haben, nämlich: Löschen ist meistens keine besonders gute Idee.
Denn wenn etwas gelöscht wird, ist es danach – Überraschung! – weg. Doch das ist oft unerwünscht, denn vielleicht hat sich die Anwenderin oder der Anwender nur verklickt und würde das Löschen gern rückgängig machen. Das Problem ist nur: Wenn die Daten bereits fort sind, lassen sie sich nicht wiederherstellen. Was tun? Nun, man löscht einfach nicht, sondern führt ein IsDeleted-Flag ein, macht also anstelle eines Delete ein Update und setzt dieses Flag auf true.
So kann man das Löschen zum einen rückgängig machen, und zum anderen lassen sich in der restlichen Anwendung derart markierte Datensätze einfach ignorieren – es wirkt also, als wären sie tatsächlich gelöscht. Das bedeutet, wir führen technisch ein Update durch, das aus fachlicher Sicht einem Delete entspricht.
Wobei das in Wahrheit nicht ganz richtig ist, denn aus fachlicher Sicht geht es gar nicht um das "Delete" eines Buches, sondern darum, ein Buch aus dem Bestand zu entfernen. Delete ist in der Datenbanksprache lediglich das Wort, das diesem Vorgang inhaltlich am nächsten kommt, doch wenn beispielsweise jemand ein Buch stiehlt, dann muss es aus technischer Sicht ebenfalls gelöscht werden, was also auch ein Delete (oder genauer genommen ein Update) wäre – fachlich gesehen sind das jedoch zwei völlig unterschiedliche Vorgänge.
Das bedeutet, wir haben jetzt schon drei Ebenen: die fachliche, in der ein Buch aus dem Bestand entfernt wird, die technische, in der wir das IsDeleted-Flag aktualisieren, und eine dritte Ebene, die sich irgendwo dazwischen befindet und eigentlich die technische Intention ausdrückt, weil wir ursprünglich ein Delete durchführen wollten.
Und? Habe ich es bereits geschafft, Sie damit zu verwirren?
Wenn ja: Herzlichen Glückwunsch! Wenn Sie an dieser Stelle denken, dass dies für einen eigentlich trivialen Vorgang ganz schön kompliziert ist, sind Sie in guter Gesellschaft, denn vielen Entwicklerinnen und Entwicklern geht es genauso: Wir haben es geschafft, für ein banales Beispiel drei unterschiedliche sprachliche Ebenen zu erzeugen, sodass wir nun jedes Mal, wenn wir über solche Vorgänge sprechen, im schlimmsten Fall zweimal ersetzen müssen. Missverständnisse sind da natürlich vorprogrammiert.
Stellen Sie sich das nun in großem Maßstab vor, in einer wirklich großen und komplexen Anwendung. Dann kommt jemand aus der Fachabteilung und erklärt, dass ein bestimmter Vorgang erweitert werden müsse, und Sie überlegen angestrengt, was diese Person damit überhaupt meint, weil Ihnen die Fachsprache nicht geläufig ist und denken:
"Ah, bestimmt geht es um die Stelle, an der wir ein Delete ausführen!"
Anschließend sprechen Sie darüber mit jemandem, der die Datenbank verwaltet, und werden angesehen, als kämen Sie von einem anderen Stern, während Ihnen gesagt wird:
"Wir machen hier kein Delete, wir führen immer nur ein Update durch."
Viel Vergnügen dabei, das alles auseinanderzufieseln und zu klären, wo im Code nun was passiert, mit welcher Intention, wieso und warum, und wie und wo sich das letztlich auswirkt. Missverständnisse sind da geradezu vorprogrammiert, weil zwar alle irgendwie vom Gleichen reden, aber niemand das jeweilige Gegenüber wirklich versteht.
Und dann kommt die Fachabteilung und sagt:
"Ja, wir hätten da noch eine Idee. Wir möchten einen Report darüber, wie oft Bücher eigentlich verspätet zurückgegeben werden, nachdem sie bereits mindestens zwei Mal verlängert wurden."
Und Sie denken sich nur:
"Alles klar, ich melde mich dann morgen krank. Sollen sich doch andere um diesen Kram kümmern."
Denn es stellt sich heraus: Natürlich liegen Ihnen die Daten für diesen Report nicht vor, weil Sie ja nicht ahnen konnten, dass irgendwann einmal jemand danach fragen würde. Also, was tun Sie? Sie passen das Schema der Datenbank an (in der Hoffnung, dabei nichts kaputtzumachen), passen dann den vorhandenen Code an, um die neuen Veränderungen überhaupt zu erfassen (wieder in der Hoffnung, dabei nichts zu zerstören), und schreiben anschließend den Code für den neuen Report. Allerdings sind Sie damit noch nicht fertig, denn jetzt müssen Sie sechs Monate warten, bis Sie zumindest erste halbwegs belastbare Zahlen haben, mit denen Sie zur Fachabteilung gehen können – ein halbes Jahr später!
Und wie reagieren diese Personen? Wenn Sie Glück haben, sind sie schlicht verärgert: Natürlich ist es toll, dass sie nun diesen Report bekommen, aber sie hätten ihn eben gerne schon vor einem halben Jahr gehabt, nicht erst jetzt. Doch immerhin haben Sie es überhaupt hinbekommen.
Wenn Sie Pech haben, bekommen Sie entweder zu hören, dass sie den Report gar nicht mehr benötigen (aber trotzdem danke für Ihre Mühe), oder man teilt Ihnen mit, dass Sie da leider etwas falsch verstanden haben. Dann war die ganze Arbeit umsonst, Sie können quasi noch mal von vorn anfangen, es dauert wieder ein halbes Jahr, und am Ende erfahren Sie vielleicht dann, dass nun niemand den Report mehr braucht.
Erinnern Sie sich noch, wie alles begann? Richtig: Sie haben das Datenbankschema angepasst. Neue Felder eingeführt, anschließend den Code geändert und so weiter. Setzen Sie das jetzt etwa alles wieder zurück? Ganz ehrlich: Sie wären die erste Person, die ich treffen würde, die das macht. Im Normalfall bleibt so etwas dann nämlich bestehen, auch wenn es niemand mehr benötigt. Weil, und das ist das Ärgerliche daran, Sie ja nie wissen, wer diese neuen Felder inzwischen vielleicht ebenfalls verwendet, und natürlich möchten Sie nicht nach einem vergeudeten Jahr auch noch diejenige oder derjenige sein, der anderen etwas kaputtmacht. Also lassen Sie lieber die Finger davon. Und so wächst und wächst das Datenschema, und nach fünf Jahren kennt sich kein Mensch mehr darin aus.
Das ist übrigens keine ausgedachte Situation, sondern genau das erlebe ich da draußen bei sehr vielen Unternehmen in der Praxis als Regelfall. Ich glaube, das Schlimmste in dieser Hinsicht war einmal eine Versicherung, die dem Ganzen vorbeugen wollte, indem sie jeder Tabelle von vornherein vierhundert Spalten verpasste – "Value1", "Value2", "Value3" und so weiter – sodass man zumindest nie das Schema anpassen musste: Man konnte sich einfach die nächste freie Spalte für die eigenen Zwecke reservieren.
Natürlich war das nirgends dokumentiert, und alle Informationen dazu wurden nur mündlich weitergegeben, nach dem Motto:
"Wenn in Spalte 312 ein Y steht, dann bedeutet Spalte 94 die Faxnummer. Wenn in Spalte 312 aber ein J steht, dann ist Spalte 94 das Geburtsdatum. Und wenn in Spalte 207 zusätzlich der Wert NULL steht, gilt das alles nicht mehr, aber wir wissen leider nicht, was dann gilt, weil der Typ, der das vor hundert Jahren mal gebaut hat, nicht mehr bei uns arbeitet."
Uff!
Also stellt sich natürlich die Frage: Wie kann man es besser machen? Denn auf so eine Situation hat eigentlich niemand Lust. Und tatsächlich (auch wenn Sie das jetzt vielleicht überrascht) ist es eigentlich recht einfach. Der Fehler besteht nämlich darin, dass überhaupt erst der Status quo gespeichert wird. Denn wenn man das macht, muss man sich logischerweise festlegen, welche Felder man zum Status quo speichert und wann man diese Felder aktualisiert.
Das Problem dabei ist, dass man das im Vorfeld eigentlich gar nicht wissen kann. Denn Sie wissen nie, welche Fragen Ihnen morgen gestellt werden und welche Daten Sie dafür bräuchten, um diese Fragen sinnvoll beantworten zu können. Tja, und vielleicht fragen Sie sich jetzt, wie man das dann anders machen soll, schließlich kann niemand in die Zukunft blicken – und trotzdem lässt sich die Sache deutlich intelligenter angehen.
Dazu schauen wir uns an, wie ein Girokonto funktioniert. Ich wähle dieses Beispiel ganz bewusst, weil es jede und jeder von Ihnen aus eigener praktischer Erfahrung kennt.
Offensichtlich speichert die Bank nicht einfach nur zu Ihrer Kontonummer den Kontostand (also den Saldo), denn dann könnte sie Ihnen nicht erklären, wie dieser Kontostand überhaupt zustande gekommen ist. Man möchte das jedoch manchmal unbedingt wissen, wenn man sich fragt:
"Warum ist am Ende des Geldes noch so viel Monat übrig?"
Spaß beiseite: Den meisten Menschen ist es sehr wichtig, transparent nachvollziehen zu können, wofür sie Geld ausgegeben haben und wie sich der Kontostand zusammensetzt.
Und was macht die Bank dafür konkret? Zunächst einmal verzichtet sie auf das Delete, denn wir haben ja bereits festgestellt, dass es in den meisten Fällen keine gute Idee ist, Daten zu löschen, also streichen wir das einfach. Dann zeigt sich allerdings, dass auch ein Update genauso wenig geeignet ist, weil dabei ebenfalls Daten verloren gehen – nämlich die, die vorher da waren. Genau das ist der springende Punkt: Man überschreibt den bisherigen Status quo durch einen neuen Status quo. Und der alte ist anschließend weg.
Deshalb verzichtet die Bank folgerichtig auch aufs Update. Das ist übrigens in beiderlei Hinsicht hervorragend, denn so bleiben nur noch Create und Read übrig. Das bedeutet, dass eine Bank technisch gesehen einen einmal angelegten Datensatz nie wieder verändern oder gar löschen kann. Und genau das ist extrem wichtig für den Vertrauensaufbau: Stellen Sie sich einmal vor, eine Bank könnte bereits ausgeführte Buchungen nachträglich ändern! Sie würden wahrscheinlich niemals Ihr Geld dorthin bringen!
Nun stellt sich natürlich die Frage: Was lässt sich mit Create und Read schon Großartiges anfangen? Denn Daten müssen ja manchmal geändert werden. Und hier kommt der entscheidende Punkt: Wir speichern nicht mehr den Status quo, sondern stattdessen die einzelnen kleinen Veränderungen, die im Laufe der Zeit zum Status quo geführt haben. Genau das ist es, was Sie auf Ihrem Kontoauszug sehen: Die Bank erzeugt für jede Transaktion, die auf Ihrem Konto stattfindet, einen neuen, unveränderlichen Eintrag. Per Create.
Und diese immer länger werdende Liste können Sie sich anschließend per Read ausgeben lassen – das ist Ihr Kontoauszug. Wenn ich dann wissen möchte, wie Ihr aktueller Kontostand ist, kann ich hingehen und all Ihre Kontoauszüge seit der Eröffnung des Kontos nehmen und Transaktion für Transaktion durchrechnen, bis ich am Ende weiß, wie Ihr heutiger Saldo ausfällt.
Und was passiert nun, wenn etwas schiefläuft? Dann kann man Daten doch gar nicht korrigieren, oder? Doch, kann man! Denn die Bank versucht gar nicht erst, eine fehlgeschlagene Transaktion zu ändern, sondern sie kompensiert diese einfach mit einer passenden Gegentransaktion. Wenn Sie also versuchen, 100 Euro auf ein Konto zu überweisen, das nicht existiert, streicht die Bank nicht Ihre fehlgeschlagene Überweisung aus der Historie, sondern Sie erhalten kurz darauf einfach eine Gutschrift über 100 Euro, sodass der Effekt ausgeglichen wird.
Das ändert natürlich nichts daran, dass die fehlgeschlagene Überweisung versucht wurde, aber genau so hat es sich ja auch wirklich zugetragen. Das bedeutet, die Historie wird nicht verfälscht, sondern nur die Effekte werden kompensiert.
Dieses Modell hat einen enormen Vorteil: Aus Sicht des Datenmodells ist es sehr, sehr simpel. Aber weil Sie alle Rohdaten besitzen, können Sie sämtliche Fragen beantworten, von denen Sie bis vor Kurzem nicht einmal wussten, dass sie jemals gestellt werden würden. Und das können Sie nicht nur ad hoc tun, sondern Sie können es auch ad hoc über sämtliche Daten der Vergangenheit tun!
Also zum Beispiel: Wie viel Prozent Ihres Gehalts geben Sie für die Miete aus? Nun, wenn Sie mir Ihren Kontoauszug geben, kann ich das einfach ausrechnen, auch wenn es dafür kein eigenes Feld gibt. Sie möchten wissen, ob sich Lottospielen lohnt? Dann geben Sie mir bitte Ihren Kontoauszug, und ich rechne das für Sie gern aus. Sie möchten wissen, ob der durchschnittliche Kontostand des Jahres 2024 höher oder niedriger war als der von 2023 und falls ja, um wie viel? Nun, geben Sie mir Ihren Kontoauszug, und ich rechne Ihnen das gerne aus. Wie oft im Monat gehen Sie essen? Leben Sie eher sparsam oder eher verschwenderisch? Geben Sie direkt nach Geldeingang größere Beträge aus, oder warten Sie bis zum Monatsende, wenn Sie wissen, wie viel übrig ist? Haben Sie einen Zweitwohnsitz? Wie viel sind Ihre Ausgaben für Lebensmittel im Vergleich zu vor fünf Jahren gestiegen? Und so weiter und so fort …
Ich könnte diese Liste praktisch endlos erweitern. Und das Entscheidende ist: Ich kann Ihnen jede dieser Fragen beantworten, nur mithilfe der vorhandenen Transaktionen der vergangenen Jahre, ohne dass wir dazu das Datenmodell anpassen müssten. Ohne dass wir dafür den Code ändern müssen, der die Transaktionen ausführt. Ohne dass wir sechs Monate warten müssen. Ohne dieses, ohne jenes.
Und das gilt nicht nur für Banken. Das funktioniert ebenfalls für unsere eingangs erwähnte Bibliothek: Statt für jedes Buch einen Datensatz zu führen, den wir immer wieder aktualisieren und am Ende trotzdem nichts Genaues wissen, legen wir einfach für jede Veränderung einen Datensatz an: Ein Buch wurde neu in den Bestand aufgenommen, ein Buch wurde ausgeliehen, ein Buch wurde verlängert, ein Buch wurde zurückgegeben, ein Buch wurde beschädigt und so weiter.
Auch daraus können Sie alle möglichen Fragen ableiten: Wie oft wird ein Buch pro Jahr ausgeliehen? Wie oft wird es verlängert? Welches sind die Top 10 der am häufigsten ausgeliehenen Bücher? Welcher Anteil der Bücher wird mehr als einmal von derselben Person ausgeliehen? Und so weiter. All das funktioniert in jeder Fachdomäne.
Vielleicht ist es Ihnen bereits aufgefallen: Wir haben uns, ganz nebenbei, vom rein technischen Vokabular entfernt und reden nicht mehr von Create, Update und Delete, sondern plötzlich von der Fachlichkeit – Ausleihen, Verlängern, Zurückgeben und so weiter.
Das bedeutet, wenn jetzt jemand aus der Fachabteilung mit einem Wunsch hinsichtlich der Rückgabe von Büchern zu Ihnen kommt, wissen Sie sofort, worum es geht, weil Sie dasselbe Vokabular verwenden. Und wenn Sie nun sagen:
"Na gut, man müsste das ja nicht so machen, ich kann doch weiterhin mit Create, Read, Update und Delete arbeiten."
dann bekämen Sie sinngemäß einen Kontoauszug, auf dem steht:
Da erkennt man, wie unglaublich dünn das übliche, verbreitete Vokabular in Anwendungen ist. Und man merkt, wie hilfreich und sinnvoll es sein kann, nicht immer nur dieselben vier technischen Verben zu verwenden, sondern endlich einmal semantisch gehaltvolle Begriffe aus der Fachlichkeit einzuführen. Das Ganze steht und fällt also damit, dass man inhaltlich sinnvolle Begriffe wählt. Und genau das ist in der Softwareentwicklung ohnehin von essenzieller Bedeutung: Dinge richtig zu benennen.
Wenn man das nicht macht, entsteht solcher Unsinn wie der böse Wolf, der das IsDeleted-Flag des Rotkäppchens aktualisiert, weil er es ja nicht löschen darf, sonst könnte der Jäger kein "Undelete" durchführen. Dabei geht es eigentlich doch um Gefressen- und Gerettet-Werden, aber hey – ein rein technisches Update und Delete sind so viel einfacher.
Übrigens: Ich habe mich schon häufiger über CRUD ausgelassen, und wenn Sie sich das CRUD-Märchen tatsächlich einmal in voller Länge ansehen wollen, empfehle ich Ihnen dieses Video [2].
Jetzt wissen Sie, wie das System konzeptionell funktioniert. Was noch fehlt, ist ein Name für das Ganze. Die einzelnen Einträge in dieser immer weiter wachsenden Liste (übrigens nennt man sie eine "Append-Only-Liste", weil stets nur am Ende angehängt werden darf) stehen in der Vergangenheitsform, denn sie sind ja bereits geschehen: Ein Buch wurde ausgeliehen, ein Buch wurde verlängert, ein Buch wurde zurückgegeben und so weiter. Und weil das Ereignisse sind, die stattgefunden haben und nicht mehr rückgängig gemacht werden können (wie gesagt, man kann nur ihre Effekte kompensieren), spricht man hier von "Events".
Da diese Events sozusagen die Quelle für sämtliche Auswertungen, Abfragen, Analysen, Reports und Co. sind, sind sie die "Source" von allem, weshalb man bei diesem Datenhaltungskonzept von "Event Sourcing" spricht. Vielleicht haben Sie den Begriff schon einmal gehört und sich gefragt, was das eigentlich ist. Die kurze Antwort lautet: Das, was Ihr Girokonto macht, das ist Event Sourcing, beziehungsweise, das ist ein Beispiel dafür. Das heißt, Sie verwenden es tagtäglich, und zwar schon seit Jahren, nur kannten Sie vermutlich den Namen nicht.
Allerdings ist die historische Analysemöglichkeit von Daten nicht der einzige Vorteil, den Event Sourcing bietet. Sie erhalten, ohne dafür aktiv etwas machen zu müssen, quasi "kostenlos" ein Audit-Log: Sie können jederzeit nachvollziehen, welches Event (also welche fachlich relevante Aktion) wann und von wem und mit welchen Parametern ausgelöst wurde. Das ist natürlich generell schon sehr praktisch, aber besonders interessant wird es, wenn Sie Software für eine Branche entwickeln, in der das Führen eines Audit-Logs vorgeschrieben ist, etwa aus Sicherheitsgründen.
Wenn Sie dann sagen können, dass das Audit-Log nicht nachträglich angeflanscht wurde, sondern von Anfang an im Kernkonzept der Datenhaltung mitgedacht ist, verschafft es Ihnen einen deutlichen Wettbewerbsvorteil.
Sie interessieren sich für "Was-wäre-wenn"-Analysen? Kein Problem: Beim Abspielen der Events (was man übrigens "Replay" nennt) müssen Sie nicht zwangsläufig alle Events berücksichtigen. Sie können auch einige davon weglassen und sehen, wie sich dadurch das Ergebnis verändert. Oder Sie fügen bei einem Replay simulierte Events hinzu und beobachten, was im Laufe der Zeit geschehen wäre.
Das kann Ihnen helfen, weit bessere Einblicke zu gewinnen, Ihr (auch wenn sich das merkwürdig anhören mag) Business besser zu verstehen und auf dieser Grundlage möglicherweise bessere Entscheidungen zu treffen. Allein die Möglichkeit, die Vergangenheit auf unterschiedliche Weise zu interpretieren, ist so mächtig, dass Sie sich das, falls Sie es noch nie erlebt haben, kaum vorstellen können.
Bevor ich es vergesse: Auch für Fehlersuche und Debugging ist Event Sourcing hervorragend geeignet. Mit Events können Sie problemlos nachvollziehen, wie ein System bei einem Kunden in diesen merkwürdigen Zustand geraten ist, in dem es sich gerade befindet.
Und das ist keineswegs eine neue Idee: Es gibt ein Interview mit John Carmack, dem ehemaligen leitenden Entwickler bei id Software, der maßgeblich an DOOM beteiligt war, und in diesem Interview erwähnt er, dass DOOM im Kern mit Event Sourcing arbeitet (auch wenn er es nicht so nennt, weil der Begriff damals noch nicht existierte, es aber de facto genau das ist).
Übrigens ist das zum Beispiel auch für Maschinensteuerung oder ganz allgemein IoT- und Industriebereiche interessant: Wie ist eine Maschine in den Zustand geraten, in dem sie sich befindet, und was können wir daraus lernen?
Und natürlich können Sie aus den Events jede beliebige andere Darstellung erzeugen, denn letztlich ist das nur eine Frage der Interpretation. Wenn Sie zum Beispiel häufig den aktuellen Kontostand benötigen, wäre es sehr ineffizient, jedes Mal ein komplettes Replay durchzuführen – stattdessen können Sie zusätzlich eine kleine Tabelle mit dem Kontostand pflegen, die Sie ganz klassisch nach CRUD aktualisieren, sobald ein Event auftritt, das Auswirkungen auf den Kontostand hat.
Theoretisch müssten Sie diese Tabelle nicht einmal auf der Festplatte sichern, denn falls das System abstürzt, könnten Sie sie jederzeit aus dem Replay neu aufbauen. Das bedeutet natürlich auch, dass Sie das gleiche Prinzip für jede beliebige andere Tabelle oder Darstellung anwenden können: Die Events bleiben stets Ihre Single Source of Truth, und was Sie daraus an speziell optimierten Lesemodellen ableiten, liegt ganz bei Ihnen.
Es gilt natürlich: Wo Licht ist, ist stets auch Schatten. Ich möchte Event Sourcing nicht als eine Lösung darstellen, in der es nichts gibt, worüber man nachdenken sollte, und spreche deshalb kurz einige typische Einwände an. Erstens wird oft angeführt, dass eine Append-Only-Liste im Laufe der Zeit zunehmend mehr Speicher verbraucht. Das stimmt grundsätzlich, aber zum einen sollen Sie ja nicht jeden einzelnen Sensormesswert als Event erfassen, sondern nur geschäftsrelevante Fachereignisse. Davon haben Sie in der Regel nicht 100.000 pro Sekunde.
Zweitens sind Events meist deutlich kleiner, als man intuitiv annimmt, weil man nur die Deltas speichern muss.
Und drittens ist Speicherplatz heutzutage praktisch kein Kostenfaktor mehr. Letztlich ist das eine einfache Rechenaufgabe, und natürlich hängt die Antwort stark von der jeweiligen Fachdomäne ab, doch erfahrungsgemäß sind das oft weit weniger Daten als zunächst vermutet. Und außerdem könnte man alte Events irgendwann archivieren. Natürlich ließen sich dann deren Historien nicht mehr abrufen, aber das ginge bei einem klassischen Datenhaltungsmodell ebenfalls nicht.
Der zweite häufige Einwand lautet, dass Replays im Laufe der Zeit immer länger dauern: Das ist logisch, denn wenn das System rege genutzt wird, sammeln sich immer mehr Events an, und ein Replay benötigt dann naturgemäß mehr Zeit. Der springende Punkt ist jedoch, dass man dem mit sogenannten Snapshots hervorragend entgegenwirken kann: Ein Replay über die ersten 10.000 Events führt ja stets zum gleichen Ergebnis, gerade weil es kein Update und kein Delete gibt, das heißt, anstatt dieses Ergebnis immer wieder neu zu berechnen, lässt es sich in einem Cache als bereits vorgefertigter Wert hinterlegen.
Im Zweifelsfall müssen Sie dann lediglich ein Replay ab dem letzten Snapshot durchführen, was bei regelmäßig erzeugten Snapshots flott geht. Außerdem haben Sie es in der Hand, wie schnell das Ganze sein soll: Letztlich ist das nur eine Frage der Häufigkeit, mit der Sie Snapshots erzeugen.
Der dritte Einwand betrifft häufig die DSGVO: Wie kann ein System, das darauf ausgelegt ist, Daten niemals zu ändern oder zu löschen, überhaupt mit der DSGVO vereinbar sein, insbesondere mit Artikel 17 zum Recht auf Vergessenwerden? Tatsächlich existieren dafür verschiedene Lösungswege, die unterschiedlich aufwendig zu implementieren sind, aber auch unterschiedlich hohen Anforderungen und Datenschutzklassen gerecht werden.
Was jeweils der richtige Ansatz ist, muss individuell für das jeweilige Projekt erarbeitet werden. Das lässt sich nicht pauschal beantworten, weil es beispielsweise einen Unterschied macht, ob Sie hochsensible medizinische Daten verarbeiten oder nur die Stammdaten des örtlichen Kanarienvogel-Züchtervereins. Das sind einfach verschiedene Welten.
Und vielleicht denken Sie jetzt:
"Klasse, das klingt alles sehr vielversprechend, besonders das mit den historischen Daten, dem Audit-Log, der stärkeren Fokussierung auf die Fachlichkeit, den vielfältigen Analysemöglichkeiten und Reports und so weiter – das möchte ich unbedingt einmal ausprobieren. Aber wo fange ich an?"
Dann ist mein allerwichtigster Rat: Beginnen Sie mit einem kleinen Projekt. Event Sourcing ist ein unglaublich mächtiges Werkzeug, das Ihnen völlig neue Türen öffnen kann, doch wie bei jedem mächtigen Werkzeug sollte man nicht gleich mit dem größten Projekt starten, das man hat. Suchen Sie sich also zuerst etwas wirklich Kleines heraus und beschäftigen Sie sich, bevor Sie mit einer Implementierung beginnen, zunächst einmal mit der Frage, welche Events überhaupt existieren. Denn das ist der Dreh- und Angelpunkt: Da Sie nichts mehr ändern oder löschen können, sollten Sie zumindest halbwegs sicherstellen, dass Sie in die richtige Richtung loslaufen.
Welches Tooling Sie dann später nutzen, welche Datenbank Sie verwenden und so weiter, ist im ersten Schritt völlig unerheblich. Natürlich wird das später eine sehr wichtige Frage sein, aber zuerst sollten Sie sich mit der Fachlichkeit befassen und erst dann mit den technischen Fragen, nicht umgekehrt. Nach einer Weile werden Sie dann irgendwann feststellen: Event Sourcing ist am Ende gar nicht so kompliziert, wie Sie vielleicht zunächst vermuten – es fehlt häufig einfach an Übung und Erfahrung, aber die sammelt man mit der Zeit.
URL dieses Artikels:
https://www.heise.de/-10258295
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] https://www.youtube.com/watch?v=MoWynuslbBY
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Valtenint Agapov / Shutterstock)
C# 13.0 bietet ein neues Escape-Zeichen \e für die Formatierung von ANSI/VT100 Terminal Control Escape Sequences.
Mit den uralten VT100/ANSI-Escape-Codes [1] kann man auch heute noch in Konsolenanwendungen zahlreiche Formatierungen auslösen, darunter 24-Bit-Farben, Fettschrift, Unterstreichen, Durchstreichen und Blinken. Die VT100/ANSI-Codes werden durch das Escape-Zeichen (ASCII-Zeichen 27, hexadezimal: 0x1b) eingeleitet.
Vor C# 13.0 konnte man dieses Escape-ASCII-Zeichen 27 in .NET-Konsolenanwendungen bei Console.WriteLine() nur umständlich ausdrücken über \u001b, \U0000001b oder \x1b, wobei Letzteres nicht empfohlen ist [2]: "Wenn Sie die Escapesequenz \x verwenden, weniger als vier Hexadezimalziffern angeben und es sich bei den Zeichen, die der Escapesequenz unmittelbar folgen, um gültige Hexadezimalziffern handelt (z. B. 0–9, A–F und a–f), werden diese als Teil der Escapesequenz interpretiert. \xA1 erzeugt beispielsweise "¡" (entspricht dem Codepunkt U+00A1). Wenn das nächste Zeichen jedoch "A" oder "a" ist, wird die Escapesequenz stattdessen als \xA1A interpretiert und der Codepunkt "ਚ" erzeugt (entspricht dem Codepunkt U+0A1A). ਚ ist ein Panjabi-Schriftzeichen. Panjabi ist eine in Pakistan und Indien gesprochene Sprache. In solchen Fällen können Fehlinterpretationen vermieden werden, indem Sie alle vier Hexadezimalziffern (z. B. \x00A1) angeben."
Typischerweise sahen Ausgaben mit VT100/ANSI-Escape-Codes vor C# 13.0 folgendermaßen aus:
Console.WriteLine("This is a regular text");
Console.WriteLine("\u001b[1mThis is a bold text\u001b[0m");
Console.WriteLine("\u001b[2mThis is a dimmed text\u001b[0m");
Console.WriteLine("\u001b[3mThis is an italic text\u001b[0m");
Console.WriteLine("\u001b[4mThis is an underlined text\u001b[0m");
Console.WriteLine("\u001b[5mThis is a blinking text\u001b[0m");
Console.WriteLine("\u001b[6mThis is a fast blinking text\u001b[0m");
Console.WriteLine("\u001b[7mThis is an inverted text\u001b[0m");
Console.WriteLine("\u001b[8mThis is a hidden text\u001b[0m");
Console.WriteLine("\u001b[9mThis is a crossed-out text\u001b[0m");
Console.WriteLine("\u001b[21mThis is a double-underlined text\u001b[0m");
Console.WriteLine("\u001b[38;2;255;0;0mThis is a red text\u001b[0m");
Console.WriteLine("\u001b[48;2;255;0;0mThis is a red background\u001b[0m");
Console.WriteLine("\u001b[38;2;0;0;255;48;2;255;255;0mThis is a blue text with a yellow background\u001b[0m");
Seit C# 13.0 gibt es nun \e als Kurzform für das Escape-Zeichen ASCII 27, sodass die Zeichenfolgen deutlich kompakter und übersichtlicher werden:
Console.WriteLine("This is a regular text");
Console.WriteLine("\e[1mThis is a bold text\e[0m");
Console.WriteLine("\e[2mThis is a dimmed text\e[0m");
Console.WriteLine("\e[3mThis is an italic text\e[0m");
Console.WriteLine("\e[4mThis is an underlined text\e[0m");
Console.WriteLine("\e[5mThis is a blinking text\e[0m");
Console.WriteLine("\e[6mThis is a fast blinking text\e[0m");
Console.WriteLine("\e[7mThis is an inverted text\e[0m");
Console.WriteLine("\e[8mThis is a hidden text\e[0m");
Console.WriteLine("\e[9mThis is a crossed-out text\e[0m");
Console.WriteLine("\e[21mThis is a double-underlined text\e[0m");
Console.WriteLine("\e[38;2;255;0;0mThis is a red text\e[0m");
Console.WriteLine("\e[48;2;255;0;0mThis is a red background\e[0m");
Console.WriteLine("\e[38;2;0;0;255;48;2;255;255;0mThis is a blue text with a yellow background\e[0m");

(Bild: Screenshot (Holger Schwichtenberg))
URL dieses Artikels:
https://www.heise.de/-10255344
Links in diesem Artikel:
[1] https://en.wikipedia.org/wiki/ANSI_escape_code
[2] https://learn.microsoft.com/de-de/dotnet/csharp/programming-guide/strings/
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Wer in Visual Basic programmiert, wird gerne belächelt, immerhin sei Basic eine "schlechte" Programmiersprache. Warum ist das eigentlich so und was ist da dran?
Vor ein paar Tagen habe ich einen Entwickler kennengelernt, und natürlich (wie das unter Entwicklern eben so ist) kam relativ schnell die Frage auf, mit welcher Programmiersprache man denn jeweils unterwegs sei. Ich habe dann ein bisschen erzählt, was wir bei the native web [1] so machen, womit wir uns beschäftigen und womit wir arbeiten.
Und natürlich habe ich ihn dann gefragt, wie das denn bei ihm sei. Da kam dann ein leicht verschämtes:
"Naja, ich arbeite nur mit Visual Basic."
Diese Antwort war ihm sichtlich unangenehm, und ich habe ihn dann gefragt, warum das so sei. Er erzählte mir, dass er schon oft die Erfahrung gemacht hätte, dass andere Entwicklerinnen und Entwickler ihn nach dieser Antwort nicht mehr so ganz ernst nehmen, sondern ihn eher belächeln würden. So nach dem Motto:
"Ach guck mal, wie niedlich, da arbeitet jemand tatsächlich noch mit Visual Basic!"
Zugegeben: Visual Basic hat keinen besonders guten Ruf. Eher im Gegenteil: Die Sprache gilt als veraltet, als minderwertig, kurzum als "schlecht". Doch da stellt sich natürlich die Frage: Was ist da dran? Ist Visual Basic wirklich so eine katastrophal schlechte Sprache? Um das beantworten zu können, muss man die Frage etwas allgemeiner stellen, nämlich: Was zeichnet eine gute oder eine schlechte Programmiersprache überhaupt aus?
Bevor wir loslegen, möchte ich noch ein paar Hinweise geben. Zuallererst: Auf diese Frage gibt es nicht die eine wissenschaftlich fundierte und absolut objektive Antwort. Schon die Definition von "gut" und "schlecht" ist eine Frage der Interpretation. Ich werde mir daher zwar große Mühe geben, das Ganze objektiv anzugehen, nicht emotional zu argumentieren und meine Behauptungen an Fakten festzumachen. Dennoch ist das, was hier steht, meine persönliche Sicht der Dinge. Bevor Du also in den Kommentaren mit Kritik um Dich wirfst, wäre es nett, wenn Du das berücksichtigen könntest.
Zweitens: Es geht mir in diesem Blogpost nicht speziell um Visual Basic. Vielmehr versuche ich, zu erklären, woran ich festmache, ob ich eine Sprache als gut oder schlecht empfinde. Dabei liefere ich die Kriterien, die ich für wichtig halte, und erkläre, aus welchen Gründen ich sie für wichtig erachte. Es ist völlig in Ordnung, wenn Du sagst, dass diese Kriterien für Dich nicht greifen oder Du sie anders bewertest. Denn immer da, wo es um Qualität geht, spielt auch das eigene Wertesystem eine Rolle. Und das sieht bei Dir sicher anders aus als bei mir, allein schon deshalb, weil wir unterschiedliche Erfahrungen gemacht haben.
Drittens: Generell möchte ich darum bitten, in den Kommentaren nett zueinander zu sein und konstruktiv miteinander umzugehen. Auch wenn Dir die Sprache, die jemand anderes bevorzugt, nicht gefällt, macht das die entsprechende Person nicht zu einem schlechten Menschen. Es ist völlig in Ordnung, Technologien kritisch zu hinterfragen. Anderen Menschen sollten wir trotz Kritik respektvoll begegnen.
Damit kommen wir nun endlich zum eigentlichen Thema: Was macht eine Programmiersprache gut oder schlecht?
Eine häufig genannte Antwort lautet: Eine Sprache ist dann gut, wenn man mit ihr das jeweils gesteckte Ziel erreichen kann. Nach dem Motto: Wenn eine Sprache den Zweck erfüllt, dann kann sie nicht schlecht sein. Für mich persönlich ist das allerdings kein besonders überzeugendes Argument. Denn bloß, weil ein Werkzeug eine Aufgabe erfüllt, ist es noch lange kein gutes Werkzeug – es ist dann zunächst einmal nur ein für diese Aufgabe passendes oder geeignetes Werkzeug.
Ob es auch gut ist, steht auf einem anderen Blatt. Das merkt man spätestens dann, wenn es mehrere Werkzeuge für dieselbe Aufgabe gibt. Denn dann gibt es oft Unterschiede. Insofern gilt für mich, dass "gut" und "geeignet" zwei verschiedene Paar Schuhe sind. Umgekehrt ist eine Sprache nicht per se schlecht, nur weil sie für ein Problem ungeeignet ist. Sie ist dann einfach nur für dieses Problem ungeeignet. "Gut" oder "schlecht" sind für mich Begriffe, die sich auf eine qualitative Bewertung der Sprache an sich beziehen, unabhängig von ihrer Tauglichkeit für ein bestimmtes Problem.
Ein ähnlicher Punkt ist das Feature-Set einer konkreten Implementierung einer Sprache. Es hieß früher zum Beispiel oft, dass C# eine schlechte Sprache sei, weil sie nur unter Windows lauffähig war. Das ist falsch. Die Sprache an sich ist zunächst nur eine Syntax mit einer Semantik, wie man sich ausdrücken kann. Ob es dafür eine passende Laufzeitumgebung oder einen passenden Compiler für eine konkrete Plattform gibt, ist unabhängig von der Idee der Sprache. Heute ist es ja problemlos möglich, C# auch auf macOS oder Linux auszuführen. Insofern sind auch das keine Kriterien dafür, ob eine Sprache gut oder schlecht gestaltet wurde. Es sagt nur etwas über die Verfügbarkeit von Implementierungen aus.
Ein weiterer Punkt: Eine Sprache ist nicht dasselbe wie ihre Funktions- oder Klassenbibliothek. Auch das ist ein Implementierungsdetail. Es kann für ein und dieselbe Sprache unterschiedliche Umgebungen geben, die unterschiedlich viel an "Drumherum" zur Verfügung stellen. Das kennt man zum Beispiel aus .NET oder Java mit unterschiedlich umfangreichen Runtimes. Es geht mir also wirklich nur um das, was direkt zur Sprache an sich gehört.
Allein darüber könnte man nun lange diskutieren, ob diese Abgrenzung sinnvoll ist oder nicht. Für heute möchte ich sie so machen, weil es in meinen Augen die sinnvollste Definition ist, wenn man über das Design einer Sprache sprechen will.
Damit ist umrissen, was ich überhaupt bewerten will. Jetzt ist die Frage, was geeignete Kriterien sind. Das wichtigste Kriterium für mich ist die Ausdrucksstärke einer Sprache. Eine Programmiersprache ist ein Werkzeug, um das umzusetzen, was eine Entwicklerin oder ein Entwickler im Sinn hat. Das sollte möglichst zielgerichtet und ohne unnötige Umstände möglich sein. Das macht das Schreiben und Lesen von Code einfacher. Je weniger eine Sprache mich zwingt, Konzepte umzuformulieren, desto einfacher und direkter lassen sich Ideen ausdrücken. Sprachen, die für jedes gedankliche Konzept ein entsprechendes Konzept in der Sprache bieten, empfinde ich als gelungen.
Ein Beispiel: In der Mathematik ist 1 die Fakultät von 1, und die Fakultät von n ist n * fac(n - 1). Hier handelt es sich also um eine rekursive Definition. Eine Sprache ist dann ausdrucksstark, wenn sie Rekursion unterstützt, weil ich die Fakultät dann genau so ausdrücken kann, wie sie in meinem Kopf definiert ist. Das klingt trivial, aber Rekursion gab es tatsächlich nicht schon immer in Programmiersprachen. Sie musste erst einmal eingeführt werden, und das war mit Lisp im Jahr 1958 [3]. Das im Jahr zuvor entstandene Fortran kannte keine Rekursion. Und genau das meine ich mit Konzepten: Eine gute Sprache holt mich auf der konzeptionellen Ebene dort ab, wo ich stehe, und bürdet mir keine unnötige Denkarbeit auf.
Die Ausdrucksstärke ist aber nicht das einzige Kriterium. Das zweite wichtige Kriterium aus meiner Sicht ist Minimalismus: Für jedes Konzept sollte es nur genau einen einzigen Weg geben, um ans Ziel zu kommen. Ich will mich nicht zwischen mehreren gleichwertigen Wegen entscheiden müssen. Zu viele Alternativen führen nämlich zu Inkonsistenzen im Code und erhöhen die Komplexität. Ein Beispiel: JavaScript kennt zig Wege, eine Iteration auszudrücken – unter anderem sieben verschiedene Schleifentypen:
for als klassische Zählschleifefor ... in um über Objekte zu iterierenfor ... of eine Art for … eachfor await ... of als asynchrone Variante davonwhile als abweisende Schleifedo ... while als nicht abweisende SchleifeforEach als Schleifen-Funktion an ArraysIch bin mir sicher, dass ich die eine oder andere Variante vergessen habe, aber dass es überhaupt sieben verschiedene Schleifentypen in JavaScript gibt, die im Prinzip alle das Gleiche machen und sich lediglich in Details unterscheiden, das ist schon erschreckend. Vergleicht man das mit Go, dann kommt Go mit einer einzigen Schleife aus – nämlich der for-Schleife, die gegebenenfalls noch um das range-Schlüsselwort ergänzt wird. Das war's, und das führt zu viel weniger Diskussionen und Verwirrung.
Das dritte Kriterium ist Konsistenz: Konzeptionell gleiche Dinge sollten syntaktisch gleich formuliert werden. Das senkt die kognitive Belastung und fördert die Lesbarkeit. In Go (nachdem ich die Sprache gerade positiv erwähnt habe, nenne ich nun auch ein Manko) stolpere ich regelmäßig darüber, dass Parameter einer Funktion per Komma separiert werden, Felder eines Struct jedoch nicht. Das ist unlogisch, weil man in beiden Fällen eine Auflistung von Namen und Typen vornimmt, und warum dieses – aus konzeptioneller Sicht – gleiche Muster mit unterschiedlichen Syntaxvarianten ausgeführt wird, erschließt sich mir nicht.
Viertens ist mir eine gewisse Explizitheit wichtig. Sprachen sollten dazu führen, dass man sich präzise ausdrücken muss. Ich bin ein großer Fan von expliziten Konvertierungen und kein Freund von impliziten. Explizitheit sorgt für mehr Klarheit und weniger Fehler. Je gefährlicher eine Aktion ist, desto expliziter sollte sie sein. Und hier kann man Go wieder als Positivbeispiel nennen: Der unsichere (weil direkte) Zugriff auf den Speicher erfolgt hier über das unsafe-Paket, das heißt, man muss explizit hinschreiben, dass es sich um unsicheren Code handelt.
Nun gehen da natürlich manchmal die Meinungen auseinander, was gut und was schlecht ist. Und da fragt man sich dann vielleicht, wie sehr Sprachdesigner auf die Community hören sollten. Meine klare Antwort ist: Eigentlich gar nicht. Denn es äußern sich oft nur wenige aus der Community, die dann aber sehr lautstark auftreten. Wirklich gutes Sprachdesign ist unglaublich schwer, und bloß weil es einige laute Schreihälse gibt, heißt das noch lange nicht, dass ihre Forderungen sinnvoll oder durchdacht seien. Tatsächlich denken viele Entwicklerinnen und Entwickler an der Stelle zu kurz und übersehen langfristige Konsequenzen, die eine Sprache aufweichen, verwässern und inkonsistent machen können.
Außerdem gilt: Wenn man zu einem neuen Feature erst einmal "ja" gesagt hat, kann man es nicht wieder entfernen, ohne einen Breaking-Change zu haben. Deshalb sollte man sich sehr genau im Vorfeld überlegen, welche Features wirklich in eine Sprache aufgenommen werden sollten. Mit anderen Worten: Weniger Optionen fördern die Standardisierung von Code und damit seine Lesbarkeit. Letztlich geht es um die richtige Balance zwischen Ausdrucksstärke, Minimalismus, Explizitheit und Konsistenz. Vielleicht auch noch um Fehlervermeidung.
Und eine Sprache, die das alles vereint, würde ich persönlich als gelungen bezeichnen.
Wenn ich auf meine eigene Reise zurückblicke, sehe ich, wie sich die von mir genutzten Sprachen entwickelt haben. Meine erste große Sprache war Basic: Zunächst GW-Basic, später QuickBasic und schließlich Basic PDS, alles unter MS-DOS. Und Basic ist eigentlich das Gegenteil von dem, was ich beschrieben habe. Es ist nicht ausdrucksstark, nicht minimalistisch, nicht explizit. Es war bestenfalls halbwegs konsistent. Fehlervermeidend war es schon gar nicht, man denke nur an das unsägliche ON ERROR GOTO NEXT.
Danach habe ich zehn Jahre lang sehr intensiv mit C# gearbeitet. C# ist in fast allen Belangen besser als Basic: Es ist ausdrucksstärker, expliziter und weniger fehleranfällig. Nur minimalistisch ist es nicht, auch in C# gibt es zu viele Wege, dasselbe zu machen. Aber im Vergleich zu Basic war es trotzdem eine deutliche Verbesserung.
Dann kam JavaScript, mit dem ich wiederum zehn Jahre sehr viel gearbeitet habe. JavaScript kann tatsächlich minimalistisch genutzt werden, das macht es aber nicht zu einer minimalistischen Sprache. Tatsächlich gibt es auch in JavaScript sehr viele Schlüsselwörter und es ist weniger konsistent und gleichzeitig deutlich fehleranfälliger als C#. Unterm Strich sind die beiden Sprachen also durchaus unterschiedlich, aber ich würde sie letztlich als "gleichwertig" bezeichnen, nur eben als "anders".
Seit einigen Jahren arbeite ich nun hauptsächlich mit Go. Go ist eine viel kleinere Sprache als alle zuvor genannten: Es ist minimalistischer, konsistenter, weniger fehleranfällig und trotzdem ausdrucksstark. Ich fühle mich momentan mit Go sehr wohl, aber es wird wohl nicht die letzte Sprache sein, mit der ich mich jemals beschäftigen werde.
Wenn ich diese Reise von Basic über C# und JavaScript zu Go Revue passieren lasse, dann sehe ich, wie die von mir bevorzugten Sprachen immer mehr in die Richtung dessen gehen, was ich als gutes Sprachdesign empfinde. Das sagt allerdings absolut noch nichts über die Standardbibliothek, das Tooling oder ähnliches aus – es geht nur um die Sprache an sich.
Und: Was für mich funktioniert, muss nicht für jeden passen. Ich habe versucht, objektive Kriterien zu nennen, aber die Frage, ob eine Sprache gut oder schlecht ist, hängt immer vom eigenen Wertesystem ab. Selbst wenn Du die gleichen Kriterien anwendest wie ich, musst Du nicht zum gleichen Ergebnis kommen. Unterschiedliche Sprachen haben unterschiedliche Stärken und Schwächen.
Ich nehme aber an, dass niemand sagen würde, alle Sprachen seien gleich gut, denn sonst würden wir alle immer noch dieselbe Sprache nutzen, mit der wir irgendwann einmal angefangen haben. Die Tatsache, dass wir das nicht tun, zeigt, dass wir eine andere Sprache für gelungener hielten (oder dass wir uns in eine Nische weiterentwickelt haben, in der wir um eine bestimmte Sprache nicht herumkommen, unabhängig davon, ob wir sie gut oder schlecht finden).
Was für mich bleibt, sind vor allem zwei Dinge: Erstens kann ich auf Basis meines persönlichen Wertesystems argumentativ erläutern, warum ich bestimmte Sprachen gegenüber anderen bevorzuge, und warum ich zum Beispiel Go für gelungener halte als C#. Zweitens ist mir bewusst, dass diese qualitative Einschätzung von jeder Entwicklerin und jedem Entwickler anders getroffen werden kann, da der eigene Hintergrund jeweils ein anderer ist – und das macht eine objektive Darstellung so schwierig.
Hinzu kommt noch, dass man eine Sprache letztlich nur nach diesen Kriterien auswählt, sondern eben auch nach Tauglichkeit für das vorliegende Problem, nach Tooling, nach Funktions- und Klassenbibliothek, und, und, und.
Und deshalb macht man es sich zu leicht, wenn man jemanden belächelt, weil sie oder er mit Visual Basic programmiert: Ja, auch in meinen Augen ist Visual Basic keine besonders gelungene Sprache. Trotzdem kann es sein, dass sie für den eingangs erwähnten Entwickler genau das Richtige ist, aus einer Vielzahl von Gründen. Und statt darüber zu urteilen, sollten wir vielleicht eher neugierig und überrascht nachfragen: Warum? Denn vielleicht können wir dabei etwas lernen.
URL dieses Artikels:
https://www.heise.de/-10248069
Links in diesem Artikel:
[1] https://www.thenativeweb.io/
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=JxF5cv9LNIc
[4] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX-Redaktion)
Je erfahrener ein Entwickler oder eine Architektin ist, desto besser die Ergebnisse – sollte man meinen. Doch tatsächlich ist häufig das Gegenteil der Fall.
Vielleicht kennen Sie die Situation: Sie öffnen ein Projekt, das jemand anderes entwickelt hat, und schon nach wenigen Minuten denken Sie sich:
"Das ist aber ganz schön kompliziert implementiert!"
Je mehr Code Sie lesen, desto stärker beschleicht Sie das Gefühl, dass vieles unnötig komplex ist. Häufig sind es Abstraktionsebenen, die Dinge verschleiern, die eigentlich pragmatisch und einfach hätten gelöst werden können. Solche Ansätze machen den Code schwer verständlich – und das gilt nicht nur für den Code, sondern auch für die Architektur eines Projekts. Vielleicht haben auch Sie schon einmal das Gefühl gehabt, dass weniger darauf geachtet wurde, guten Code zu schreiben, sondern dass jemand sich an einer übertriebenen Komplexität verkünstelt hat.
Genau darum geht es heute: Architektur sollte im Idealfall unsichtbar sein. Doch was bedeutet das genau? Und wie können Sie dieses Prinzip für sich nutzen?
Fangen wir mit der Frage an, was es bedeutet, dass eine gute Architektur unsichtbar ist. Ein Vergleich mit der Realität hilft, das zu verdeutlichen. Denken Sie an beeindruckende Bauwerke: vielleicht an eine moderne Villa, bei der jedes Detail passt und alle Entscheidungen nahtlos ineinanderfließen. Oder an ein historisches Bauwerk wie den Kölner Dom, das architektonisch ebenfalls fasziniert. Der entscheidende Punkt ist: Sie bewundern in beiden Fällen das Bauwerk als Ganzes. Sie wissen zwar, dass dahinter eine durchdachte Architektur steckt, diese drängt sich Ihnen aber nicht auf. Vielmehr wirkt alles wie ein schlüssiges Gesamtbild, bei dem man spürt, dass alle Details durchdacht sind. Das heißt, gute Architektur tritt in den Hintergrund und fordert nicht ständig Ihre Aufmerksamkeit.
Natürlich ließe sich alternativ auch ein Bauwerk schaffen, bei dem jede architektonische Entscheidung überdeutlich sichtbar wird. Das mag zwar schick aussehen, würde aber den Eindruck einer überambitionierten Studie vermitteln, die mehr Selbstzweck als Grundlage für ein großartiges Bauwerk ist. Und genau das meine ich, wenn ich sage: Gute Architektur ist unsichtbar. Sie schafft Strukturen, ohne sich in den Vordergrund zu drängen.
Dieses Prinzip gilt nicht nur für Bauwerke, sondern auch für Software. Auch hier ist Architektur kein Selbstzweck. Sie sollte ein solides Fundament liefern, auf dem eine gut strukturierte, wartbare und langfristig nutzbare Software entstehen kann. Wenn eine Architektur diese Ziele erfüllt, ohne sich selbst zu wichtig zu nehmen, ist sie gelungen. Wenn sie diese Ziele hingegen verfehlt oder unnötig in den Vordergrund rückt, ist sie schlecht.
Bis hierhin klingt das alles vielleicht recht einleuchtend. Doch wenn es so einfach wäre, würden wir nicht so häufig auf Projekte stoßen, bei denen wir uns denken:
"Was ist das denn? Was hat sich da bloß jemand gedacht?"
Über die Jahre fällt dann ein Muster auf: Menschen, die gerade erst mit der Programmierung beginnen, entwickeln oft einfache und pragmatische Lösungen – allein schon deshalb, weil sie es nicht anders können. Mit wachsendem Wissen neigen Entwicklerinnen und Entwickler jedoch dazu, Probleme immer stärker zu abstrahieren. Das wird uns in der Ausbildung schließlich so beigebracht: Der Versand einer Word-Datei wird abstrahiert zu "Dateiversand", dieser wiederum zur Nachricht eines Senders an einen Empfänger – und am Ende reden wir nur noch abstrakt über "Messaging". Dabei wollte man ursprünglich einfach nur eine Word-Datei per E-Mail versenden.
Das Problem dabei ist oft zu viel und vor allem zu frühe Abstraktion. Jede Abstraktion führt zu einer weiteren Indirektion, die den Code schwerer verständlich macht. Statt den eigentlichen Gedankengang der Entwicklerin oder des Entwicklers im Code nachvollziehen zu können, muss man diesen gedanklich zunächst auf eine andere Ebene übersetzen. Je mehr solche Ebenen es gibt, desto schwieriger wird es, den Code zu verstehen. Dabei wird Code jedoch nur einmal geschrieben, aber viele Male gelesen. Der Fokus sollte daher viel eher auf Lesbarkeit, Nachvollziehbarkeit und Verständlichkeit liegen, nicht auf möglichst vielen Abstraktionen. Das "You Ain’t Gonna Need It"-Prinzip (YAGNI) ist nicht ohne Grund ein Leitmotiv in der Softwareentwicklung: Keep it simple! Dieses Prinzip gilt für Code genauso wie für Architektur.
Ein zentraler Aspekt ist die klare Definition von Verantwortlichkeiten: Welche Funktion, Klasse oder welcher Service ist wofür zuständig? Die Prinzipien der niedrigen Kopplung und der hohen Kohäsion helfen hier: Einzelne Elemente sollten möglichst unabhängig voneinander existieren, während alles, was zu einer Aufgabe gehört, an einem Ort zusammengeführt wird. Wenn Sie also einen Fehler beheben müssen, sollte die Änderung an einer Stelle genügen, ohne andere Teile des Systems zu beeinflussen.
Ein Beispiel aus der Praxis verdeutlicht das: In einem Code-Review stieß ich auf eine unnötige Abstraktion in einer Go-Codebasis. Anstatt einen Pointer zu verwenden, um auszudrücken, dass ein Wert optional ist, hatte die Entwicklerin einen Maybe-Typ eingeführt – ein Konzept aus der funktionalen Programmierung. Dieser Typ war jedoch nur an einer einzigen Stelle im Code verwendet worden, was weder konsistent noch sinnvoll war. Ein einfacher Pointer hätte denselben Zweck erfüllt und wäre deutlich verständlicher und weniger fehleranfällig gewesen.
Das Problem unnötiger Abstraktion tritt nicht nur auf Code-, sondern auch auf Architekturebene auf. So wird manchmal ein Microservice eingeführt, nicht weil er notwendig ist, sondern um das Konzept eines Microservices umzusetzen. Das führt zu unnötiger Komplexität und verfehlt das eigentliche Ziel, die Struktur und Verständlichkeit der Software zu verbessern.
Warum verkünsteln sich erfahrene Entwicklerinnen und Entwickler so oft? Ein Grund ist der Wunsch nach Perfektion, ein anderer das Streben nach Anerkennung. Es ist wichtig, sich diesen Effekt bewusst zu machen und den eigenen Code und die eigene Architektur zu reflektieren. Code-Reviews und Pair-Programming können hier helfen, denn sie fördern pragmatische Ansätze und die Verständlichkeit für andere.
Architektur und Code sind Mittel zum Zweck, kein Selbstzweck. Sie sollten die fachlichen Anforderungen und die Bedürfnisse des Teams in den Mittelpunkt stellen. Lösungen sollten iterativ und pragmatisch entwickelt werden. Fragen Sie sich stets: Braucht das Team diese Abstraktion wirklich, oder verkompliziert sie die Dinge nur unnötig?
URL dieses Artikels:
https://www.heise.de/-10225156
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock)
C# 13.0 bietet neben partiellen Klassen und Methoden jetzt auch die lang erwartete Umsetzung für partielle Properties und Indexer.
Eine wichtige Neuerung in C# 13.0 sind partielle Properties und Indexer. Auf dieses Sprachfeature warten viele Entwicklerinnen und Entwickler bereits seit der Einführung der partiellen Methoden in C# 3.0. Das C#-Schlüsselwort partial gibt es sogar bereits seit C# 2.0 für Klassen.
Mit partiellen Klassen kann man den Programmcode einer einzigen Klasse auf mehrere Codedateien aufspalten – ohne dafür Vererbung zu nutzen. Das ist nicht nur sinnvoll für mehr Übersichtlichkeit bei umfangreichen Klassen, sondern wird vor allem verwendet, wenn ein Teil der Klasse automatisch generiert und der andere Teil der Klasse manuell geschrieben wird. Diese Vorgehensweise kommt in .NET zum Beispiel bei GUI-Bibliotheken wie ASP.NET Webforms und Blazor, beim Reverse Engineering von Datenbanken mit Entity Framework und Entity Framework Core sowie bei Source-Generatoren (z.B. für reguläre Ausdrücke und JSON-Serialisierung) zum Einsatz.
In C# 13.0 können Entwicklerinnen und Entwickler auch Property- und Indexer-Definition sowie deren Implementierung mit partial in zwei Dateien trennen. Dabei müssen beide Teile jeweils die gleiche Kombination von Getter und Setter mit den gleichen Sichtbarkeiten sowie dem gleichen Typ realisieren.
Ein konkretes Beispiel: Wenn in einem Teil der Klasse eine Property sowohl einen öffentlichen Getter als auch einen öffentlichen Setter besitzt, müssen diese auch im anderen Teil vorhanden und öffentlich sein. Aber während in einem Teil ein automatisches Property verwendet wird, kann im anderen Teil eine explizite Implementierung vorhanden sei.
Partielle Properties und partielle Indexer können genau wie partielle Klassen und partielle Methoden NICHT aus mehreren Projekten/Assemblies zusammengeführt werden. Alle Teile müssen in dem gleichen Projekt sein!
Die folgenden Listings zeigen ein Beispiel einer aufgeteilten Klasse mit partieller Methode und partiellem Property sowie einem partieller Indexer.
Der erste Codeausschnitt zeigt den ersten Teil der partiellen Klasse nur mit Definitionen von Property ID, Indexer und Print():
using System.Text.Json.Serialization;
namespace NET9_Console.CS13;
/// <summary>
/// Erster Teil der partiellen Klasse nur mit Definitionen
/// </summary>
public partial class PersonWithAutoID
{
// NEU: Partielles Property --> kein "Convert to Full Property"
public partial int ID { get; set; }
// NEU: Partieller Indexer
public partial string this[int index] { get; }
// "Normales Property"
public string Name { get; set; }
// Partielle Methode (gab es vorher schon)
public partial void Print();
}
Im zweiten Teil der partiellen Klasse werden Getter und Setter für ID und den Indexer sowie die Methode Print() implementiert:
/// <summary>
/// Implementierung der Getter und Setter für ID, der Getter für den Indexer sowie die Methode Print()
/// </summary>
public partial class PersonWithAutoID
{
int counter = 0;
// Implementierung des Partial Property
private int iD;
public partial int ID
{
get
{
if (iD == 0) iD = ++counter;
return iD;
}
set
{
if (ID > 0) throw new ApplicationException("ID ist bereits gesetzt");
iD = value;
}
}
// Implementierung des Partial Indexer
public partial string this[int index]
{
get
{
return index switch
{
0 => ID.ToString(),
1 => Name,
_ => throw new IndexOutOfRangeException()
};
}
}
// Implementierung der Partial Method
public partial void Print()
{
Console.WriteLine($"{this.ID}: {this.Name}");
}
}
Folgender Code implementiert den Nutzer der zusammengesetzten Klasse PersonWithAutoID:
/// <summary>
/// Client-Klasse für die Demo
/// </summary>
public class CS13_PartialPropertyAndIndexerDemoClient
{
public void Run()
{
CUI.Demo(nameof(CS13_PartialPropertyAndIndexerDemoClient));
CS13.PersonWithAutoID p = new() { Name = "Holger Schwichtenberg" };
p.Print(); // 1: Holger Schwichtenberg
CUI.H2("Versuch, die ID neu zu setzen, führt zum Fehler:");
try
{
p.ID = 42;
}
catch (Exception ex)
{
CUI.Error(ex); // System.ApplicationException: ID ist bereits gesetzt
}
CUI.Print($"Nutzung des Indexers: {p[0]}: {p[1]} ");
}
}
URL dieses Artikels:
https://www.heise.de/-10237499
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: Pincasso/Shutterstock)
Die Programmiersprache C# 13.0 ist zusammen mit Visual Studio 2022 Version 17.12 und .NET 9.0 am 12. November 2024 erschienen.
Das neue C# 13.0 unterstützt Microsoft offiziell erst ab .NET 9.0 ("C# 13.0 is supported only on .NET 9 and newer vesions.").
Man kann allerdings die meisten Sprachfeatures aus C# auch in älteren .NET-Versionen einschließlich .NET Framework, .NET Core und Xamarin nutzen. Dazu muss man die verwendete Compilerversion per Tag <LangVersion> in der Projektdatei (.csproj) auf "13.0" erhöhen.
<LangVersion>13.0</LangVersion>
Damit Sprachfeatures auch in Versionen vor .NET 9.0 funktionieren, dürfen sie keine Abhängigkeit von in .NET 9.0 eingeführten Basisbibliotheksklassen haben. Sofern man <LangVersion>latest</LangVersion> in der Projektdatei setzt, sind in älteren Versionen folgende neuen Sprachfeatures von C# 13.0 möglich:
ref struct, außer der Verwendung als Typargument\eZu beachten ist aber, dass es für den Einsatz der neuen Sprachfeatures in .NET-Versionen vor 9.0 keinen technischen Support von Microsoft gibt, man also bei Problemen nicht den Support-Vertrag nutzen kann, um Microsoft um Hilfe zu ersuchen. Dennoch ist der Einsatz höherer C#-Versionen in älteren .NET-Projekten in einigen Unternehmen gängige und problemlose Praxis.
In C# 13.0 sind folgende neue Sprachfeatures erschienen, die ich in den kommenden Wochen in dieser Blogserie besprechen werde:
\e für ANSI/VT100 Terminal Control Escape Sequences,params,Threading.Lock für lock-Anweisungen undref structs (auf Stack).Ein weiteres Sprachfeature ist in C# 13.0 in experimenteller Form enthalten: halbautomatische Properties mit dem neuen Schlüsselwort field. Dieses Schlüsselwort ist nur verfügbar, wenn man in einer Projektdatei entweder <EnablePreviewFeatures>True</EnablePreviewFeatures> oder <LangVersion>preview</LangVersion> setzt.
Folgende Sprachfeatures waren für C# 13.0 geplant und zum Teil schon als Prototyp verfügbar, wurden aber dann auf C# 14.0 vertagt [1], das im November 2025 erscheinen soll :
(int x, string y) = default statt (default, default)Array, Span<T> und ReadOnlySpan<T>extensioneinführen.Es gibt einige wenige Breaking Changes [2] im Verhalten des Compilers in C# 13.0 gegenüber C# 12.0. Dabei handelt es sich jedoch um Sonderfälle von geringer Bedeutung, beispielsweise das Verbot der Annotation [InlineArray] auf record struct).
URL dieses Artikels:
https://www.heise.de/-10217343
Links in diesem Artikel:
[1] https://github.com/dotnet/roslyn/blob/main/docs/Language%20Feature%20Status.md
[2] https://learn.microsoft.com/en-us/dotnet/csharp/whats-new/breaking-changes/compiler%20breaking%20changes%20-%20dotnet%209
[3] mailto:rme@ix.de
Copyright © 2025 Heise Medien

(Bild: TippaPatt/Shutterstock)
.NET 9.0 ist eine Version mit Standard-Term-Support (STS) für 18 Monate. Für einige Bibliotheken ist der Support aber deutlich kürzer.
Während die vorherige, im November 2023 erschiene Version 8.0 noch 36 Monate Support erhalten hat und daher noch bis zum November 2026 mit Updates versorgt wird, bietet Microsoft Aktualisierungen und technische Hilfe für .NET 9.0 für die Dauer von 18 Monaten, also nur bis Mai 2026 an.
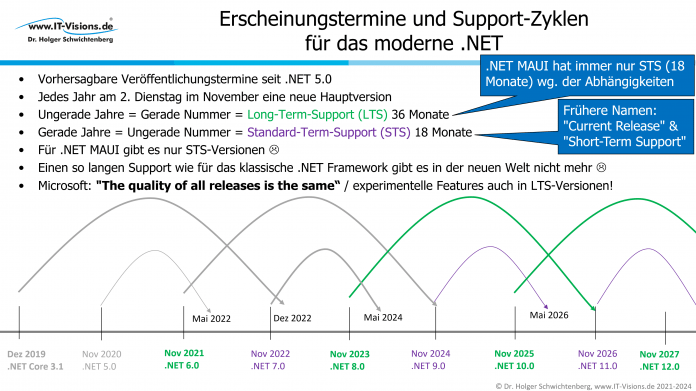
(Bild: Microsoft)
Für einige von Microsoft veröffentlichte .NET-NuGet-Pakete, die nicht Teil des .NET-SDKs sind, gilt eine andere Support-Richtlinie.
Das betrifft folgende Paketfamilien:
Für diese Pakete gilt:
Die Liste der betroffenen NuGet-Pakete findet man auf der Seite zu den Extensions [1].

(Bild: Microsoft [2])
URL dieses Artikels:
https://www.heise.de/-10215755
Links in diesem Artikel:
[1] https://dotnet.microsoft.com/en-us/platform/support/policy/extensions
[2] https://dotnet.microsoft.com/en-us/platform/support/policy/extensions
[3] mailto:rme@ix.de
Copyright © 2024 Heise Medien
In this release, the coding focus has been on moving to PHP 8.1+ and refactoring the integration of the SimplePie library (which was long due). At the same time, plenty of new features have been added. Enjoy! 🎄
Breaking changes 💥:
A few highlights ✨:
search:UserQueryA date:P1dCache-Control: max-age and ExpiresThis release has been made by @aledeg, @Alkarex, @Art4, @ColonelMoutarde, @Frenzie, @math-GH, @ramazansancar
and newcomers @DevGrohl, @UserRoot-Luca, @aarnej, @andrey-utkin, @bhj, @christophehenry, @davralin, @drego85, @ev-gor, @killerog, @kwarraich, @minna-xD, @mtalexan, @oshaposhnyk, @patHyatt
Full changelog:
search:UserQueryA date:P1d #6851Cache-Control: max-age and Expires #6812, FreshRSS/simplepie#26Authorization) #6820&state=96 (no UI button yet)phpgt/cssxpath library with improved CSS selectors #6618
:last-child, :first-of-type, :last-of-type, ^=, |=("a b") or (!c) #6818v mode #7009+ #7033
Referer #6822, FreshRSS/simplepie#27
Referer: https://example.net/ to the custom HTTP headers of the feed #6820windows.open noopener (to avoid flash of white page in dark mode) #7077, #7089aria-hidden bug, and use HTML5 hidden #6910<pre> and <code> #6770<template> instead of duplicated HTML code #6751, #7113<template> #6864? to show shortcut page and help #6981simplepie_after_init #7007Minz_Request::paramArray() #6800booleansInConditions #6793phpstan.dist.neon to allow custom configuration in phpstan.neon #6892ControlSignature #6896
(Bild: Pincasso/Shutterstock.com)
Auch für das aktuelle .NET-Release wird der Dotnet-Doktor-Blog die Neuerungen in einer Artikelserie detailliert beschreiben.
Mit diesem Beitrag beginne ich die neue Blogserie zu .NET 9.0. Wie im letzten Jahr zu .NET 8.0 [1] werde ich in zahlreichen kleineren Beiträgen die Neuerungen in .NET 9.0 vorstellen.
.NET 9.0 steht seit dem 12. November 2024 auf der Downloadseite [2] kostenfrei zur Verfügung. Für .NET 9.0 benötigen Entwicklerinnen und Entwickler die Entwicklungsumgebungen Visual Studio 2022 [3] mindestens in der Version 17.12.
Entwickelt wurde .NET 9.0 in den letzten 12 Monaten. Seitdem hat Microsoft sieben Preview-Versionen und zwei Release-Candidate-Versionen veröffentlicht, über ich für heise developer jeweils berichtete.
Wie schon bei .NET 6.0/C# 10.0 und .NET 7.0/C# 11.0 sowie .NET 8.0/C# 12.0 verwendet Microsoft an einigen Stellen eine Schreibweise ohne ".0" (.NET 9/C# 13) und an anderen mit ".0" (.NET 9.0/C# 13.0). Ich werde einheitlich die Schreibweise mit ".0" verwenden, wie es auf der Downloadseite [4] steht.

(Bild: Microsoft [5])
Meine Serie wird in den kommenden Wochen und Monaten über diese Aspekte von .NET 9.0 berichten:
Meine Beiträge erheben dabei nicht den Anspruch, die Dokumentation zu ersetzen oder zu überbieten. Leserinnen und Leser können meine Beiträge als Impulsgeber verstehen, sich zu entscheiden, ob eine Neuerung für ihre Anwendungsfälle Sinn ergibt und sie sich damit dann näher beschäftigen wollen.
Ich werde die Beiträge der Serie jeweils so weit im Voraus schreiben, dass eine wöchentliche Veröffentlichung gewährleistet ist. Aufgrund von redaktionellen Engpässen kann es dennoch vorkommen, dass einmal eine Woche kein Beitrag erscheint.
URL dieses Artikels:
https://www.heise.de/-10215673
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://dotnet.microsoft.com/en-us/download/dotnet/9.0
[3] https://visualstudio.microsoft.com/
[4] https://dotnet.microsoft.com/en-us/download/dotnet/9.0
[5] https://dotnet.microsoft.com/en-us/download/dotnet/9.0
[6] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: incrediblephoto / Shutterstock.com)
Künstliche Intelligenz könnte zu einem enormen Produktivitätssprung in der Softwareentwicklung führen. Welche Auswirkungen kann das haben?
Nehmen wir einmal an, dass wir es schaffen, die Produktivität in der Softwareentwicklung um eine Größenordnung – also um den Faktor zehn – zu verbessern. Um es ganz konkret zu machen, ein Gedankenexperiment: Eine Projektleiterin wacht morgens auf und weiß, dass in ihrem Projekt statt 100 Menschen nur 10 Menschen notwendig sind. Sie weiß auch, welche Menschen das sind. Das ist absolut sicher, so wie der Himmel blau ist.
Was wird die Projektleiterin nun tun?
Die erste Option wäre, das Projekt mit zehn Personen fortzusetzen und den restlichen 90 Personen andere Aufgaben zu geben oder sie gar zu entlassen. Diese Option umzusetzen ist schwierig, weil die Projektleiterin sich und anderen damit eingesteht, dass zu viele Menschen an dem Projekt gearbeitet haben. Außerdem ist das Management eines 100-Personen-Projekts prestigeträchtiger als die Leitung eines Projekts mit zehn Personen. Das Vorgehen birgt auch ein Risiko, weil man die Personen nicht so einfach wiederbekommt, wenn man doch eine sinnvolle Aufgabe für sie findet.
Eine andere Option ist, die zehn Personen an dem ursprünglichen Projekt arbeiten zu lassen und den anderen eine andere Aufgabe zu geben. Dazu könnte man den Scope des Projekts vergrößern. Das ist gegebenenfalls relativ einfach möglich, denn der Wunsch nach mehr Features ist eher die Regel. Oder man sucht für die Menschen ein anderes Projekt. Am Ende steht bei beiden Optionen mehr Wert für die Organisation und damit mehr Prestige für alle Beteiligten.
Vielleicht könnte man das Projekt auch durch die zusätzlichen Personen beschleunigen. Das erscheint aber schwierig, da mehr Menschen ein Projekt sogar verlangsamen können, weil Einarbeitung und mehr Kommunikation notwendig sind. Fred Brooks hat genau darauf in seinem Buch "The Mythical Man Month" hingewiesen.
Aber ist ein solches Gedankenexperiment überhaupt realistisch? Auch hier hat Fred Brooks eine Antwort: In seinem Paper "No Silver Bullet" [1] stellt er die Behauptung auf, dass keine einzelne Maßnahme alleine die Produktivität in der Softwareentwicklung um eine Größenordnung verbessern kann. Das lässt aber Raum dafür, dass eine Kombination von Maßnahmen dieses Ziel erreichen kann. Und außerdem ist es – so wie dieser Blog-Post – auch eine Hypothese, die er nicht weiter belegt.
Ein Grund, warum das Szenario vielleicht doch realistisch ist: Wie schon erwähnt, bedeuten mehr Menschen in einem Projekt mehr Prestige und somit gibt es einen Drang dazu, Projekte möglichst mit vielen Menschen durchzuführen. Das Gesetz von Parkinson besagt nun, dass alle verfügbaren Menschen auch an dem Projekt mitarbeiten werden. Da Softwareentwicklung viel Kommunikation bedeutet, kann diese Vielzahl an Menschen zu erschwerter Kommunikation führen. Weil die Kommunikation sich auch in der Architektur niederschlägt, bricht dann auch die Architektur zusammen. Die Beziehung zwischen Kommunikation und Architektur geht auf Conway und sein Gesetz zurück. Er hat auch die These von aufgeblasenen Projekten mit schlechter Kommunikation und am Ende schlechter Architektur aufgestellt, die bereits Thema eines anderen Blog-Posts [2] war.
Dann kommt man aber mit einer sauberen Architektur, weniger Menschen und damit weniger Kommunikation und Kommunikationsproblemen vielleicht genauso schnell zum Ergebnis, sodass das Gedankenexperiment vielleicht doch nicht ganz unrealistisch ist.
Motivator für das Gedankenexperiment ist aber eine andere Entwicklung: Es kann sein, dass wir durch künstliche Intelligenz bei der Produktion von Code deutlich effizienter werden, wie ein anderer Blog-Post [3] diskutiert hat. Dann ist die Frage, was bei einer Verbesserung von Produktivität um einen Faktor 10 passiert, sehr relevant.
Das Gedankenexperiment legt den Verdacht nahe, dass selbst bei einem solchen Fortschritt eher mehr Software produziert wird und in der Konsequenz Software auch für Bereiche genutzt wird, für die es sich im Moment noch nicht lohnt.
Tatsächlich gibt es in der Ökonomie für dieses Phänomen: Rebound-Effekt [4]. Wenn beispielsweise Autos effizienter werden, werden sie für mehr Fahrten genutzt, sodass am Ende nicht etwa der Verbrauch sinkt, sondern gegebenenfalls sogar steigt. Vielleicht führt KI zu einem ähnlichen Effekt: Softwareentwicklung wird damit zwar effizienter, aber Software wird dann auch für andere Einsatzzwecke genutzt, sodass am Ende der investierte Aufwand derselbe bleibt. Tatsächlich unterstützt Software immer mehr Bereiche und KI könnte diesen Trend dann noch verstärken.
Im Extremfall können Menschen Software entwickeln, denen das technische Skillset eigentlich fehlt. Auch dieses Versprechen gab es schon mehrfach, mit Technologien wie COBOL, aber auch Low- oder No-Code. Aber selbst wenn KI hier erfolgreich ist: Andere Branchen zeigen, welche Effekte solche Disruptionen haben. Mit Desktop-Publishing können im Vergleich mit den Achtzigerjahren nun viel mehr Menschen Druckerzeugnisse erstellen, aber die Qualität ist eher schlechter geworden und Profis haben immer noch ihr Betätigungsfeld.
Das mag nun so wirken, als sei die Zukunft der Softwarebranche auch gegen KI abgesichert. Aber natürlich ist die Zukunft schwer vorhersagbar. Man hätte auch argumentieren können, dass die aktuelle Krise am IT-Markt nur ein Vorbote von dem ist, was KI anrichten wird. Die Zukunft ist offen.
Selbst eine Verzehnfachung der Produktivität in der Softwareentwicklung, wie sie KI vielleicht hervorbringt, bedeutet nicht unbedingt, dass weniger Menschen in dem Bereich arbeiten werden, sondern vielleicht eher, dass Software für noch mehr Einsatzzwecke genutzt wird.
URL dieses Artikels:
https://www.heise.de/-10189960
Links in diesem Artikel:
[1] https://software-architektur.tv/2024/02/02/folge201.html
[2] https://www.heise.de/blog/Beten-wir-Komplexitaet-an-4170914.html
[3] https://www.heise.de/blog/KI-in-der-Softwareentwicklung-Ueberschaetzt-9336902.html
[4] https://de.wikipedia.org/wiki/Rebound-Effekt_(%C3%96konomie)
[5] https://genai.bettercode.eu/?wt_mc=intern.academy.dpunkt.konf_dpunkt_bcc_genai.empfehlung-ho.link.link
[6] https://genai.bettercode.eu/?wt_mc=intern.academy.dpunkt.konf_dpunkt_bcc_genai.empfehlung-ho.link.link#programm
[7] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Erstellt mit KI (Midjourney) durch iX)
Architektur wirkt oft wie eine dunkle Magie, die nur in den elitären Kreisen der Wissenden diskutiert wird. Das ist nicht nur falsch, sondern auch gefährlich.
"Architektur ist überbewertet" wirkt auf den ersten Blick wie ein typischer Clickbait-Titel, aber ich will kurz erklären, was genau ich mit diesem Titel meine. Architektur hat ein Problem, über das meiner Meinung nach viel zu wenig gesprochen wird, das aber auf uns als Entwicklerinnen und Entwickler gravierende Auswirkungen hat.
Es geht um die ständige Idealisierung und die überhöhte Wahrnehmung von Architektur, von Architekten und all dem, was damit zusammenhängt und einhergeht, wie zum Beispiel einer ganzen Reihe von Prinzipien, Konzepten und nicht zuletzt auch von einigen Personen.
Das schreckt ab, denn auf dem Weg wird Architektur nicht mehr als das wahrgenommen, was sie eigentlich ist – nämlich als die Kunst, Software adäquat zu strukturieren –, sondern sie wird auf einmal als Selbstzweck wahrgenommen. Das jedoch ist nicht nur falsch, sondern auch gefährlich.
Architektur hat ein Problem: Sie wird idealisiert und überhöht. Wenn Sie nicht genau wissen, was ich damit meine, stellen Sie sich vor, wie über typische Prinzipien und Konzepte aus der Architektur gesprochen wird: Da geht es nicht um ein paar hilfreiche Leitplanken und nützliche Wegweiser, die Sie bei Ihren Bemühungen zu einer gut strukturierten Software unterstützen. Nein, da geht es zum Beispiel um Clean Code (und ja, mir ist bewusst, dass das Thema für viele nicht unter Architektur fällt, im Sinne einer besseren Strukturierung von Software gehört aber auch Clean Code dazu).
Allein durch die Namensgebung sprechen wir nicht mehr nur auf einer technischen Ebene, sondern es schwingt noch etwas ganz anderes mit, etwas Emotionalisiertes: Wenn Sie sich nicht an diese Regeln halten, dann schreiben Sie Code, der schmutzig, ungepflegt und minderwertig ist. Wollen Sie so etwas etwa wirklich? Wo die Frage nach gut strukturiertem Code explizit auf der emotionalen Ebene exkludiert, fällt eine rein sachliche Diskussion schwierig.
Ein weiteres Beispiel sind die SOLID-Prinzipien. Auch suggeriert allein der Name bereits ein stabiles Fundament, ein Fels in der Brandung. Und wehe, Sie setzen sie nicht ein: Dann stehen Sie da wie ein Grashalm, der beim leichtesten Windhauch umknickt. Wollen Sie das?
Bei diesen Beispielen kann man sich sehr gut den erhobenen Zeigefinger vorstellen: Passen Sie bloß auf, sonst enden Sie wie all die anderen vor Ihnen – als Versager.
Tatsächlich ist es jedoch nicht die Namensgebung allein: Das ist nur das, was als Erstes auffällt. Es geht noch weiter: Versuchen Sie einmal, Clean Code zu kritisieren. Sofort kommen zahlreiche Befürworterinnen und Befürworter, die Clean Code mit Leidenschaft verteidigen und als das Nonplusultra darstellen. So nach dem Motto:
"Wie können Sie es wagen, Clean Code zu hinterfragen, zu kritisieren oder gar infrage zu stellen? Was bildet Sie sich ein, wer Sie sind? Und übrigens: Sie haben damit auch Uncle Bob beleidigt, also entschuldigen Sie sich gefälligst!"
Vielleicht finden Sie das jetzt übertrieben, und natürlich verhält sich nicht jede Anhängerin und jeder Anhänger von Clean Code, SOLID & Co. derart. Das Problem ist jedoch: Es lässt sich nicht leugnen, dass um diese Themen ein gewisser Kult betrieben wird, inklusive eines ausgeprägten Personenkults. Ich behaupte nicht, dass das nur Uncle Bob alias Robert C. Martin betrifft, aber bei ihm ist es besonders auffällig. Und so etwas ist immer problematisch, denn dann wird nicht mehr sachlich über die Inhalte diskutiert. Stattdessen werden diese mit unsachlichen Emotionen und persönlichen Befindlichkeiten aufgeladen und untrennbar verknüpft.
Wenn sich das über Jahre und Jahrzehnte verfestigt, hat das natürlich Folgen. Architektur und lesbarer Code werden dann nicht mehr als etwas wahrgenommen, womit sich jede und jeder beschäftigen sollte, sondern als etwas für die Eliten. Genau so erlebe ich oft die Meinung von weniger erfahrenen Entwicklerinnen und Entwicklern: Sie sagen, sie hätten von Architektur keine Ahnung, aber eines Tages würden sie das gerne in ihrem Jobtitel stehen haben, "Distinguished Senior Solution Architect" oder etwas Ähnliches.
So entsteht eine mystische Aura um dieses Thema, als wäre es nur für sehr erfahrene Menschen zugänglich, die es geschafft haben, Teil dieses elitären Kreises zu werden. Was genau eine Architektin oder ein Architekt eigentlich macht, wird dabei oft nicht mehr klar. Es scheint nur eines sicher: Es handelt sich um eine intellektuell anspruchsvolle Aufgabe, der Normalsterbliche vermeintlich nicht gewachsen sind. Dementsprechend beschäftigt man sich nicht mit Architektur, überlässt es den Weisen, entwickelt sich nicht weiter und bleibt jahrelang in dem Traum gefangen, selbst irgendwann ein Teil dieses elitären Zirkels zu sein, ohne den Weg dorthin zu kennen.
Das eigentliche Problem ist, dass Architektur oft als Selbstzweck betrachtet wird: Sie wird um ihrer selbst willen betrieben und nicht als praktisches Werkzeug, das einer größeren Aufgabe dient. Nein, die Architektur selbst wird zur höheren Aufgabe erhoben. Das ist jedoch Unsinn. Clean Code kann durchaus kritisiert werden, und Robert C. Martin ist kein Heiliger. Die SOLID-Prinzipien sind, wenn wir ehrlich sind, fünf relativ beliebig ausgewählte Prinzipien, die in der Objektorientierung mehr oder weniger sinnvoll und manchmal nützlich sind.
Warum es ausgerechnet diese fünf Prinzipien geworden sind und nicht irgendwelche anderen, bleibt Spekulation. Vermutlich hat sich jemand ein schickes Akronym ausgedacht (eben "SOLID") und dazu Prinzipien zusammengesucht, die ansatzweise sinnvoll erschienen. Wenn man sich diese Prinzipien genauer anschaut, sind die meisten davon weder besonders elegant formuliert (im Sinne von anschaulich und greifbar), noch sind sie besonders hilfreich im Alltag. Ich kann mich zumindest nicht erinnern, wann ich das letzte Mal dachte:
"Wie praktisch, dass ich das Liskovsche Substitutionsprinzip kenne, ohne das wäre diese Struktur deutlich schlechter."
Dennoch wird vermittelt, dass die SOLID-Prinzipien die fünf wichtigsten Prinzipien der objektorientierten Programmierung seien. Das sind sie jedoch nicht, da die meisten viel zu spezifisch sind.
Das heißt, sie sind keine absolute Wahrheit, die nicht hinterfragt werden dürfte. Sie sind nur Mittel zum Zweck. Architektur (und dazu zähle ich Clean Code und diese Prinzipien wie oben schon erwähnt) hat letztlich nämlich nur ein einziges konkretes Ziel: Sie soll helfen, eine gute Struktur für Code zu schaffen, sodass dieser langfristig verständlich, überschaubar, wartbar und erweiterbar bleibt.
Wann hat Code diese Struktur? Eigentlich ist das ganz einfach: immer dann, wenn zwei Grundprinzipien erfüllt sind. Code ist gut strukturiert, wenn er zum einen eine geringe Kopplung und zum anderen eine hohe Kohäsion aufweist. In dem Video zu Kopplung und Kohäsion [2] erkläre ich die beiden Prinzipien im Detail.
Diese beiden Prinzipien – geringe Kopplung und hohe Kohäsion – sind der Leitstern, der uns überall im Code Orientierung gibt, egal ob bei Funktionen und Klassen im Kleinen oder im Großen bei den zahlreichen Microservices einer verteilten Anwendung. Diese Prinzipien machen eine gute Architektur aus. Darüber nachzudenken und daran zu arbeiten erfordert keinen Titel wie "Distinguished Senior Solution Architect". Auch Praktikantinnen und Praktikanten können sich damit beschäftigen. Vielleicht fehlt ihnen etwas Erfahrung, aber sie sind durchaus intellektuell in der Lage, darüber nachzudenken.
Die entscheidende Frage lautet: Wo sollte ich mich um was kümmern, wer ist wofür verantwortlich? Das ist letztlich alles.
Die Entscheidungen müssen ein höheres Ziel unterstützen: die Fachlichkeit. Denn genau darum geht es in der Softwareentwicklung. Wir entwickeln nicht deshalb Software, weil es Spaß macht (auch wenn es tatsächlich Spaß macht), sondern um ein tieferliegendes fachliches Problem zu lösen. Software ist kein Selbstzweck, sondern ein Werkzeug, um einen fachlichen Zweck zu erfüllen. Und Architektur muss sich daran messen lassen.
Es geht nicht darum, ob wir alle fünf SOLID-Prinzipien umgesetzt oder möglichst viele Design-Patterns verwendet haben. Was am Ende zählt, ist, dass die Architektur das fachliche Problem unterstützt und es uns erleichtert, die Software langfristig zu warten und weiterzuentwickeln. Apropos Design-Patterns: Auch diese halte ich für überbewertet [3].
Mit diesem Mindset trifft man jedoch oft auf Projekte, in denen die Architektur schon feststand, bevor die fachlichen Anforderungen bekannt waren. Das halte ich für eine schlechte Idee, genauso wie die Wahl von Technologien, bevor Architektur und Anforderungen klar sind. Was ich in Teams oft erlebe, sind Argumente wie:
"Wir sind aber nicht Netflix. Wir brauchen keine Microservices, kein CQRS, kein Event-Sourcing, keine komplexe Architektur."
Stattdessen setzt man auf eine einfache Drei-Schichten-Architektur mit einem Monolithen und Dependency Injection. Missverstehen Sie mich nicht: Es gibt Projekte, wo das angemessen ist. Viel zu oft werden solche Entscheidungen jedoch mit unpassenden Argumenten und aus den falschen Gründen getroffen. Bei Microservices etwa ist die Frage nicht:
"Sind Sie Netflix?"
Stattdessen geht es (eigentlich) um geringe Kopplung und hohe Kohäsion bei ausreichend komplexer Fachlichkeit. Diese Anforderungen kann auch ein Drei-Personen-Start-up haben. Das hängt nicht davon ab, ob man Netflix ist, sondern vom jeweiligen Business.
Die klassische Drei-Schichten-Architektur im Monolithen hat einige gravierende Nachteile: Fachlicher und technischer Code sind oft nicht sauber getrennt, was Anpassungen erschwert. Beim Testen merkt man das besonders: Es ist kaum möglich, die Geschäftslogik zu testen, weil immer die Datenbank mit dranhängt. Statt die Architektur zu hinterfragen, setzen viele dann auf Mocking. Doch Mocking ist eine der schlechtesten Ideen im Testen, weil es grüne Tests liefert, ohne sicherzustellen, dass die Mocks die Realität abbilden. Mit anderen Worten: Mocking wird zum Workaround für schlechte Architekturentscheidungen.
Tatsache ist: Es gibt deutlich bessere Ansätze. Gerade bei komplexer Geschäftslogik bietet sich etwa eine hexagonale Architektur an, die die Fachlichkeit in den Mittelpunkt rückt – ohne Abhängigkeiten zu externen Ressourcen. Doch auch hier heißt es oft:
"Wir sind doch nicht Netflix."
Solche Aussagen basieren oft auf Angst vor Veränderung. Das Problem sind nicht sachliche Argumente, sondern emotionale Bedenken:
"Das haben wir noch nie gemacht, also bleibt alles beim Alten."
Oft bekommen dann Berater den Auftrag, die beruhigende Botschaft zu verbreiten, ein Monolith reiche aus, denn man sei nicht Netflix. Das wird dann nach und nach zum gefährlichen Mantra.
Jahre später stellt man dann fest, dass die Technologie veraltet ist, aber ein Wechsel kaum möglich ist, weil alles miteinander verwoben ist. Technologiewechsel werden so zu Alles-oder-Nichts-Entscheidungen. Dabei treten viele Probleme auf: schlechte Testbarkeit, keine Skalierbarkeit, fehlende APIs für externe Systeme oder unklare Verantwortlichkeiten bei Master-Data-Management. All das hätte man vermeiden können, wenn man früher über eine fachlich sinnvolle Architektur nachgedacht hätte.
Der Sinn einer Architektur liegt darin, eine tragfähige Struktur für die Software zu schaffen, die geringe Kopplung und hohe Kohäsion gewährleistet. Wie man das erreicht, ist zweitrangig. Wichtig ist, dass die Fachlichkeit unterstützt wird. Unsachliche Diskussionen über Werkzeuge wie Clean Code, SOLID oder Design-Patterns helfen dabei nicht. Stattdessen sollten wir mehr darüber sprechen, warum wir Software entwickeln und wie die Fachlichkeit unsere Entscheidungen beeinflusst. Wer sich weiterhin hinter emotionalen und unsachlichen Argumenten versteckt, wird langfristig viel Schaden anrichten.
Fragen Sie sich daher immer, ob Ihre Architektur das fachliche Problem löst oder eher behindert. Und wenn Letzteres der Fall ist, denken Sie über Alternativen nach – losgelöst von dem, was in Lehrbüchern steht oder als Standard gilt. Architektur ist mehr als das. Jede Entwicklerin und jeder Entwickler kann dazu beitragen, denn Programmieren bedeutet, Strukturen zu schaffen.
URL dieses Artikels:
https://www.heise.de/-10191624
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] https://www.youtube.com/watch?v=kWP432pXP-U
[3] https://www.youtube.com/watch?v=oC-9HZ0r3e4
[4] https://shop.heise.de/ix-developer-praxis-softwarearchitektur-2024/print?wt_mc=intern.shop.shop.ix-dev-softwarearchitektur24.dos.textlink.textlink
[5] mailto:rme@ix.de
Copyright © 2024 Heise Medien

Der 2024 Web Almanac ist seit wenigen Tagen verfügbar
(Bild: HTTP Archive, Apache 2.0)
98 Prozent aller Requests nutzen HTTPS, 25 Prozent der Websites setzen keinerlei Caching ein: Nach einer Pause in 2023 meldet sich der Web Almanac zurück.
Der Web Almanac 2024 [1] ist da! Das kostenlose Jahrbuch bietet tiefgehende Einblicke in die aktuellen Entwicklungen des World Wide Web. Das in diverse Sprachen übersetzte Nachschlagewerk identifiziert Trends, aber auch Herausforderungen und richtet sich an alle, die das moderne Web verstehen und mitgestalten möchten.
78 führende Webexperten aus der ganzen Welt haben ehrenamtlich 21 Kapitel verfasst, die unterschiedliche Aspekte des Web beleuchten: Dazu gehören Markup [2], Performance [3], E-Commerce [4] oder Cookies [5]. Alle Kapitel haben ein Peer-Review durchlaufen und die Rohdaten sind jeweils am Ende eines Artikels verlinkt. Die Analysen basieren auf den umfangreichen Daten des HTTP Archive [6].
Das Jahrbuch erschien vergangenes Jahr nicht, da sich der Projektleiter in Elternzeit befand und keine halbherzige Durchführung wollte. Verglichen zur Ausgabe von 2022 [7] hat sich das Rohdatenmaterial verdoppelt: Über 17 Millionen Websites wurden analysiert und über 83 TByte Daten verarbeitet. Das Jahrbuch wurde auf Basis der Daten des Juli-Crawls geschrieben.
Auch die diesjährige Ausgabe fördert wieder viele interessante, aber auch einige kuriose Erkenntnisse zutage:
h1-Element (bei 6 Prozent davon ist es leer, Quelle [11])divs (Quelle [14])Um die Veröffentlichung des Web Almanac 2024 zu feiern, laden die Autoren zu einem Online-Event ein, das am 10. Dezember 2024 um 19 Uhr stattfindet. Interessierte können sich unter folgendem Link zuschalten: The Web Almanac Live Stream (YouTube) [17].
URL dieses Artikels:
https://www.heise.de/-10186758
Links in diesem Artikel:
[1] https://almanac.httparchive.org/en/2024/
[2] https://almanac.httparchive.org/en/2024/markup
[3] https://almanac.httparchive.org/en/2024/performance
[4] https://almanac.httparchive.org/en/2024/ecommerce
[5] https://almanac.httparchive.org/en/2024/cookies
[6] https://httparchive.org/
[7] https://www.heise.de/blog/HTTP-Archive-legt-Web-Jahrbuch-2022-vor-mit-einigen-kuriosen-Erkenntnissen-7286733.html
[8] https://almanac.httparchive.org/en/2024/security#fig-1
[9] https://almanac.httparchive.org/en/2024/third-parties#prevalence
[10] https://almanac.httparchive.org/en/2024/third-parties#fig-6
[11] https://almanac.httparchive.org/en/2024/seo#header-elements
[12] https://almanac.httparchive.org/en/2024/cdn#fig-3
[13] https://almanac.httparchive.org/en/2024/cookies#fig-2
[14] https://almanac.httparchive.org/en/2024/markup#fig-13
[15] https://almanac.httparchive.org/en/2024/sustainability#fig-28
[16] https://almanac.httparchive.org/en/2024/sustainability#how-many-of-the-sites-listed-in-the-http-archive-run-on-green-hosting
[17] https://www.youtube.com/live/cdYR0ZmplIM
[18] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Sergey Nivens/Shutterstock.com)
Low-Code- und No-Code-Plattformen versprechen Fachabteilungen, geschäftsrelevante Software selbst entwickeln zu können. Doch ist das wahr?
Stellen Sie sich für einen kurzen Augenblick vor, Sie würden nicht in der Softwareentwicklung arbeiten, sondern wären vielleicht Domänenexpertin oder -experte für Versicherungs-Policen. Sie arbeiten bei einer Versicherung in der Fachabteilung. Programmierung und Softwareentwicklung sind so gar nicht Ihre Themen, aber Sie kennen sich dafür bestens mit all den inhaltlichen Aspekten wie Policen, Schäden, Haftung und Regress aus.
Nun benötigen Sie ein kleines Stück Software: Vielleicht ein einfaches Tool, um die Daten von Kundinnen und Kunden effizienter zu erfassen, oder einen Report, der Ihnen ermöglicht, Ihre Policen für das nächste Jahr besser zu optimieren. Was es konkret ist, spielt letztlich keine Rolle. Es geht um etwas Kleines und Einfaches, das Ihnen und Ihren Kolleginnen und Kollegen das Leben erleichtert und Ihr Business voranbringt.
Wie kommen Sie nun zu dieser Software? Klar, Sie könnten natürlich zur hausinternen IT-Abteilung gehen und nett fragen. Wenn Sie Glück haben, sagt Ihnen die freundliche Kollegin aus der IT, dass das kein Problem sei. Sie würde sich darum kümmern und Ihnen das nebenbei bauen. Natürlich stellt sich nachher heraus, dass sie leider nicht ganz so viel Zeit erübrigen kann wie gedacht, und sie wusste vielleicht auch nicht ganz so genau, was Sie eigentlich im Detail wollten.
Deshalb macht die Software am Ende nicht ganz das, was sie sollte. Aber hey, beschweren Sie sich nicht: Immerhin haben Sie überhaupt etwas bekommen! Es hätte nämlich auch schlimmer kommen können: Wären Sie statt an die freundliche und hilfsbereite Kollegin an ihren grummeligen Kollegen geraten, hätte er Ihnen wahrscheinlich sehr deutlich zu verstehen gegeben, dass für so einen Quatsch keine Zeit da sei, die IT ohnehin völlig überlastet sei und Sie ohne eine um 27 Ecken eingeholte Budgetfreigabe gar nicht erst wieder ankommen bräuchten.
Wie schön wäre es, wenn Sie die IT einfach gar nicht bräuchten, sondern sich das, was Sie benötigen, einfach selbst hätten zusammenbauen können – ganz ohne jegliche Programmierkenntnisse? Willkommen bei der Welt der Low-Code- und No-Code-Plattformen!
Das, was ich Ihnen gerade geschildert habe, beschreibt letztlich das Werbeversprechen von Low-Code- und No-Code-Umgebungen. Die Idee dahinter ist, dass viele Vorgänge in Fachanwendungen mehr oder weniger immer gleich ablaufen: Formulareingaben, Datenabrufe aus einem SharePoint, tabellarische oder grafische Visualisierungen – all das sind immer wiederkehrende Muster. Die Plattform stellt nun solche Aktivitäten als Bausteine zur Verfügung, und Sie können sich daraus Ihre eigene Anwendung zusammenbauen, ohne wissen zu müssen, wie die technischen Details funktionieren.
Ich selbst habe das vor einiger Zeit einmal ausprobiert, gemeinsam mit einem Freund, auf Basis der Microsoft Power Platform, genauer gesagt mit Power Automate. Es ging um einen simplen Anwendungsfall: Daten von einer HTTP-API abrufen und anzeigen. Nach drei bis vier Stunden hatten wir dann allerdings keine Lust mehr, weil wir immer wieder auf Probleme stießen. Entweder waren wir zu zweit zu unfähig (was ich bezweifle), oder unser Anwendungsfall lag geringfügig außerhalb der vorgesehenen Nutzungspfade. Schlussendlich zogen wir einen Kollegen hinzu – einen zertifizierten "Microsoft Power Platform Developer". Ein Entwickler also für eine Plattform, die Entwickler angeblich überflüssig machen soll – an Absurdität lässt sich das kaum überbieten!
Dieser Vorfall ist natürlich nicht repräsentativ für alle Low- und No-Code-Plattformen. Aber er zeigt ein grundlegendes Problem auf: Die Plattformen machen große Versprechungen, schüren hohe Erwartungen – und die Realität bleibt dahinter zurück: Fachabteilungen können nicht plötzlich auf magische Weise alles selbst lösen. Sie können nicht auf die IT-Abteilung und Entwickler verzichten. Und sie sparen am Ende oft weder Zeit noch Geld. Im ungünstigsten Fall passiert sogar genau das Gegenteil.
Woran liegt das? Programmieren bedeutet, eine Sprache zu beherrschen. Egal, ob Sie Französisch oder eine Programmiersprache lernen: Sie müssen Vokabeln und Grammatik lernen, lesen, schreiben, sprechen – und üben. Entwicklerinnen und Entwickler haben sich all dieses Wissen in jahrelanger, mühsamer Arbeit angeeignet. Und nun kommt eine Plattform daher, die behauptet:
"Das brauchen Sie alles nicht!"
Stattdessen bekommen Sie Bausteine, die Sie anordnen sollen. Aber diese Bausteine reichen oft nicht aus, um komplexe Anforderungen abzubilden. Die fachliche und technische Komplexität bleibt bestehen – sie wird nur unsichtbar. Und spätestens, wenn eine Anwendung nicht performant läuft, Race Conditions auftreten oder der Datenverkehr das Netzwerk lahmlegt, kommen Sie ohne grundlegende Programmierkenntnisse nicht weiter.
Hinzu kommt, dass viele Plattformen proprietär sind. Sobald Sie eine Anwendung auf Basis einer solchen Plattform entwickeln, schaffen Sie einen Vendor-Lock-in. Die IT wird sich hüten, solche Anwendungen zu supporten. Das erinnert nämlich zu sehr an Microsoft Access, das in vielen Unternehmen bis heute Probleme verursacht. Das Problem ist also nicht neu – nur die Technologien haben sich geändert.
Darüber hinaus wissen Fachabteilungen oft selbst nicht, wie ihre Prozesse im Detail aussehen oder was sie genau wollen. Deshalb gibt es Business-Analysten und Requirements Engineers, die diese Anforderungen gemeinsam mit den Fachabteilungen erarbeiten. Fachabteilungen haben das fachliche Know-how, aber sie sind meist nicht darauf vorbereitet, dieses Wissen zielführend und nachhaltig in digitale Prozesse umzusetzen.
Trotz aller Kritik haben Low-Code-Plattformen aber natürlich auch ihre Berechtigung. Sie können die Kommunikation zwischen Entwicklung und Fachabteilung erleichtern, indem die Fachabteilung beispielsweise eigenständig Prototypen erstellt. Für einfache Anforderungen – wie "Formular ausfüllen und Daten per E-Mail senden" – können sie zudem durchaus ausreichen. Bei komplexeren Aufgaben würde ich jedoch zur Vorsicht raten.
Was mich an dem ganzen Thema aber mit Abstand am meisten stört, ist das Narrativ von "Entwicklung gegen Fachabteilung". Es geht nicht um "wir gegen die", und dieses Narrativ war noch nie konstruktiv oder gar zielführend, sondern führt stets nur zu Zwist und Schuldzuweisungen. Am Ende des Tages sind wir doch eigentlich dann erfolgreich, wenn wir unsere unterschiedlichen Fähigkeiten und Kenntnisse konstruktiv zusammenbringen und gemeinsam und partnerschaftlich auf ein gemeinsames Ziel hinarbeiten: Es geht um Partnerschaft auf Augenhöhe. Und Low-Code-Plattformen sollten diese Partnerschaft unterstützen, nicht spalten – doch genau das ist es, was sie letztlich machen.
Langer Rede, kurzer Sinn: Gehen Sie kritisch mit solchen Plattformen um. Verstehen Sie deren Grenzen und setzen Sie auf eine solide Zusammenarbeit zwischen Entwicklung und Fachabteilung. Nur so profitieren letztlich alle Beteiligten – außer vielleicht der Hersteller der Plattform.
URL dieses Artikels:
https://www.heise.de/-10184237
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] mailto:rme@ix.de
Copyright © 2024 Heise Medien