
(Bild: LanKS/Shutterstock.com)
Die Hochphase agiler Methoden wie Scrum und Extreme Programming scheint vorbei zu sein – ja, es scheint sogar einen Gegentrend zu geben. Wie kommt das?
Ich bin mir nicht sicher, ob es derzeit ein allgemeines Thema ist oder ob es gerade einfach nur verstärkt in meiner eigenen Bubble auftaucht, aber ich habe immer mehr den Eindruck, dass Agilität zunehmend infrage gestellt wird. Sei es durch die dotnetpro, die in ihrer August-Ausgabe einen Leitartikel mit dem Titel "Ist Agilität tot? [1]" veröffentlicht hat. Sei es durch eine Studie aus dem Juni, die behauptet, dass agile Softwareprojekte mit einer um 268 Prozent höheren Wahrscheinlichkeit scheitern [2] würden, oder durch YouTube-Videos mit Titeln wie "It’s time to move on from Agile Software Development (it’s not working) [3]".
Egal, wohin man blickt: Agilität scheint auf einmal nicht mehr en vogue zu sein, sie hat offenbar ihren Zenit überschritten. Doch woran liegt das? Warum ist eine Methodik, die einst angetreten ist, alles besser zu machen und die über Jahre hinweg sehr beliebt war, plötzlich so verpönt?
Vielleicht sollte man zunächst die Frage stellen: Was bedeutet agil überhaupt? Was steckt hinter diesem Begriff, woher kommt er, und wie lautet seine Definition? Beschäftigt man sich damit, stellt man als erstes (und vielleicht auch etwas überrascht) fest, dass vieles von dem, was heutzutage typischerweise mit Agilität assoziiert wird, gar nicht so neu ist, wie man zunächst meint. Tatsächlich reicht nämlich beispielsweise die wichtige Erkenntnis, dass Software eher iterativ und inkrementell entwickelt werden sollte, bis ins Jahr 1957 zurück [4], als IBM erkannte, dass dies der richtige Ansatz ist. In den 1970er-Jahren entstanden dann ergänzend dazu noch das sogenannte "evolutionäre Projektmanagement" und die "adaptive Software-Entwicklung" – beides also ebenfalls schon recht früh.
Formalisiert wurde das Ganze dann schließlich im Februar 2001 unter dem Schlagwort der Agilität im Rahmen des Agilen Manifests [6]. Damals trafen sich zahlreiche Größen der Softwareentwicklung in Utah, um gemeinsam einige Erkenntnisse als Leitsätze für die Zukunft festzuhalten. Mit dabei waren unter anderem die bekannten Entwickler Kent Beck und Ron Jeffries, Ken Schwaber und Jeff Sutherland (bekannt von Scrum), Dave Thomas und Andrew Hunt (bekannt für Ihr Buch "The Pragmatic Programmer"), sowie Martin Fowler und Robert C. Martin. Insgesamt also eine ganze Reihe bedeutender Persönlichkeiten.
Sie formulierten vier Leitsätze, die beschreiben, was sie im Laufe der Zeit und in zahlreichen Projekten schätzen gelernt haben. Der erste Punkt besagt, dass Prozesse und Werkzeuge die Menschen und die Interaktion zwischen ihnen fördern sollen und dass sich die Prozesse und Werkzeuge daher an die Bedürfnisse der Menschen anzupassen haben, nicht umgekehrt. Der zweite Punkt betont, dass es wichtiger ist, am Ende des Tages eine funktionierende Software zu haben, die ein reales Problem löst, als eine umfassende Dokumentation zu erstellen.
Der dritte Punkt fordert, in enger Abstimmung mit dem Kunden zu arbeiten, statt jede Kleinigkeit im Vorfeld auszuhandeln und vertraglich festzulegen. Der vierte und letzte Punkt hebt hervor, dass es wichtiger ist, sich auf Veränderungen einzulassen und das Vorgehen entsprechend anzupassen, statt strikt einem Plan zu folgen. Wichtig ist, dass die weniger relevanten Punkte dabei nicht unwichtig sind – sie sind nur nicht so wichtig wie die anderen. Es ist also schon durchaus sinnvoll, einen Plan zu haben, aber man sollte nicht stur an ihm festhalten, wenn sich die äußeren Bedingungen geändert haben, sondern flexibel auf diese reagieren und den Plan adaptieren.
Das ist, kurz zusammengefasst, im Wesentlichen das Agile Manifest.
Das erste Problem tritt auf, wenn man einem Team sagt:
"Wir ersetzen jetzt das V-Modell durch agiles Arbeiten."
Zunächst finden das alle toll, aber letztlich weiß niemand, was sich nun konkret ändern soll, weil niemand genau weiß, was agil denn nun konkret überhaupt bedeutet. Denn selbst wenn man das Agile Manifest zur Hand nimmt, bleibt vieles vage. Was genau bedeutet der erste Punkt, "Individuals and Interactions over Processes and Tools", denn nun für die tagtägliche Praxis?
Es gibt zahlreiche Interpretationsmöglichkeiten, und welche davon die richtige ist, lässt sich schwer beantworten. Deshalb sind im Lauf der Zeit verschiedene Interpretationen entstanden, die dessen vier Grundregeln unterschiedlich auslegen. Um diese Interpretationen auseinanderhalten zu können, haben sie jeweils eigene Namen erhalten. Inhaltlich unterscheiden sie sich in ihren Ansätzen deutlich.
Extreme Programming (XP) [7] richtet sich zum Beispiel an Entwicklerinnen und Entwickler und deren Alltag. Um diesen Alltag agiler zu gestalten, führt XP Praktiken wie Test-Driven Development, einen Build-Server. Code-Reviews und Pair-Programming ein. Also alles sehr konkret auf die tatsächliche Entwicklung bezogen. Im Gegensatz dazu bewegt sich Scrum [8] eher auf einer organisatorischen Meta-Ebene, die sich mit Prozessen und Koordination befasst, während der konkrete Entwicklungsalltag kaum eine Rolle spielt. Trotzdem lässt sich nicht sagen, dass Scrum an sich besser oder schlechter sei als XP.
Natürlich gibt es neben diesen beiden agilen Methoden auch noch andere, wie Feature-Driven Development (FDD) oder Kanban [9], und am Ende des Tages ist keine dieser Methoden die einzig wahre. Sie unterscheiden sich eben in ihren Absichten und damit auch in ihrer Interpretation. Viele Teams haben im Laufe der Zeit verschiedene agile Methoden kombiniert, wie zum Beispiel Scrum und Kanban zu Scrumban oder Scrum und XP, auch wenn es dafür bis heute keinen schicken Namen gibt. Es gibt Praktiken, die sich bewährt haben und für bestimmte Arten von Projekten passen, und andere, für die das weniger gilt. Doch das hängt letztlich immer stark davon ab, was man erreichen möchte.
Und bis hierhin ist die Geschichte auch ein großer Erfolg: Die agilen Methoden, allen voran Scrum, haben praktisch die Welt erobert. Ich weiß nicht, wie viele Unternehmen ihren Teams Scrum oder eine andere agile Methode verordnet haben, aber man kann sagen, dass agile Methoden im Verlauf von zwei Jahrzehnten das V-Modell und so ziemlich jeden anderen Softwareentwicklungsansatz abgelöst haben. Wenn ein Team heutzutage bewusst auf eine agile Methode verzichtet, wirkt das oft (zumindest auf den ersten Blick) seltsam und veraltet.
Zumindest war das bis vor Kurzem so. Aber, wie ich eingangs erwähnte, scheint in den letzten Jahren etwas schiefgelaufen zu sein. Immer weniger Unternehmen scheinen noch Interesse an agilen Methoden zu haben, und immer häufiger wird die Agilität als Ganzes infrage gestellt. Da frage ich mich: Wie konnte das passieren? Was ist schiefgelaufen? Aus meiner Sicht gibt es im Wesentlichen drei Punkte, an denen Agilität scheitert und die immer wieder kritisiert werden.
Punkt Nummer eins ist, dass agile Methoden, welche auch immer verwendet werden, angeblich nicht die versprochene Verbesserung gebracht hätten. Das ist tatsächlich etwas, was ich schon oft gesehen habe: Ein Unternehmen führt zum Beispiel Scrum ein, aber es funktioniert nicht richtig. Wenn man jedoch genauer hinschaut, stellt man häufig fest, dass das, was da gemacht wird, gar kein echtes Scrum ist. Stattdessen wird etwas praktiziert, das zwar pro forma so aussieht wie Scrum, aber völlig am Ziel vorbeigeht.
Formal werden also alle Anforderungen erfüllt, und dennoch ist das Team so weit weg von einem agilen Prozess, wie man sich das nur vorstellen kann. Leider ist das tatsächlich nicht selten. Da werden dann Sprints geplant, bei denen der Product Owner den konkreten Inhalt vorgibt, und das Entwicklungsteam darf diesen Umfang nur abnicken – egal wie unrealistisch die Vorgabe auch sein mag. Sprints dauern dann drei Monate. Retrospektiven behandeln alles, nur nicht, wie es den Teammitgliedern geht. Und das Daily dauert anderthalb Stunden, weil es zu einem klassischen Statusmeeting verkommt [10]. Geht man die Liste der Scrum-Kriterien oberflächlich durch, wird man alle Elemente wiederfinden – aber jeder einzelne Punkt wird nicht so umgesetzt, wie es für den erfolgreichen Einsatz von Scrum erforderlich wäre.
In einem solchen Szenario ist es natürlich kein Wunder, dass das Ganze am Ende nicht das hält, was ursprünglich versprochen wurde. Die Frage ist: Warum passiert so etwas? Wohlwollend könnte man sagen, das jeweilige Team wusste es vielleicht nicht besser und ist eventuell über kurz oder lang wieder in alte Verhaltensmuster zurückgefallen. Vielleicht hatte das Team auch keine gute Anleitung und Unterstützung, aber es hat sich zumindest nach bestem Wissen und Gewissen bemüht.
Für dieses pseudo-agile Vorgehen gibt es sogar einen Begriff: Man nennt das Ganze Fake-Agile. Ich persönlich würde es vielleicht auch als Cargo-Kult [11] bezeichnen, aber im Grunde meinen beide Begriffe dasselbe: Nur weil man etwas tut, das wie die richtige Umsetzung aussieht, bedeutet das noch lange nicht, dass man auch tatsächlich das Richtige macht.
Punkt Nummer zwei ist zumindest in weiten Teilen praktisch dasselbe wie Punkt Nummer eins, nur mit einem anderen Hintergrund. Während ich bei Fake-Agile den meisten Teams unterstelle, dass sie es einfach nicht besser hinbekommen haben, gibt es auch jene Teams, in denen Agilität bewusst falsch praktiziert wird. Das ist dann nicht mehr Fake-Agile, sondern wird als Dark-Agile bezeichnet. Hier wird unter dem Deckmantel von Scrum, XP & Co. eine bewusst nicht-agile Vorgehensweise angewendet, meistens, um eine andere Agenda durchzusetzen, also eine irgendwie geartete Hidden-Agenda.
Das kann bedeuten, die Kontrolle über die Mitarbeiterinnen und Mitarbeiter erhöhen zu wollen, oder ein Team bewusst gegen die Wand laufen zu lassen, um dann zu sagen, dass die Methode nicht gut oder das Team ungeeignet sei, oder Ähnliches. In jedem Fall wird das Team als Bauernopfer für ein ganz anderes Vorhaben benutzt, das mit Agilität nichts zu tun hat. Das ist aus naheliegenden Gründen der viel schlimmere Fall, weil hier mit Menschen gespielt wird, mit deren Hoffnungen, Erwartungen und Engagement. Dark-Agile ist daher als sehr negativ zu bewerten.
Egal, ob es sich um Fake- oder Dark-Agile handelt: Beides trägt natürlich nicht dazu bei, das Vertrauen in agile Vorgehensweisen zu stärken. Im Gegenteil, das Vertrauen sinkt eher, und es ist am Ende leicht zu sagen:
"Tja, das habe ich euch ja gleich gesagt. Ich schlage vor, wir machen es jetzt mal anders."
Wer also eine Veränderung weg von der Agilität will, der oder dem spielen Fake- und Dark-Agile ideal in die Hände. Im einen Fall lässt man dem Schicksal seinen Lauf und greift nicht rettend ein, im anderen Fall fördert man das Ganze sogar noch. Das Ergebnis ist letztlich dasselbe: Die Agilität steht schlecht da.
Hinzu kommt noch ein weiterer Aspekt, der agile Methoden aus einer ganz anderen Richtung diskreditiert: Der, wie ich ihn in Anlehnung an die Rüstungsindustrie gerne nenne, agil-industrielle Komplex. Gemeint ist die extreme Kommerzialisierung der Agilität, was vor allem Scrum betrifft. Das Problem ist, dass Organisationen wie Scrum.org oder die Scrum Alliance damit begonnen haben, Zertifikate auszustellen, Workshops zu veranstalten und Train-the-Trainer-Konzepte zu entwickeln – alles nur mit dem Ziel, eine komplette Business-Maschinerie rund um eine agile Methode aufzubauen.
Und ganz ehrlich: Den ganzen Kram braucht niemand, um agil arbeiten zu können, am allerwenigsten Zertifikate [12]. Allerdings benötigt diese Erkenntnis Zeit, und in der Zwischenzeit wurde sich bereits an zahllosen Entwicklerinnen, Entwicklern, Managerinnen und Managern eine goldene Nase verdient. Und natürlich möchte ich hier nicht alle Agile-Coaches oder Beratungsunternehmen über einen Kamm scheren, aber gerade in diesem Bereich gibt es auffallend viele schwarze Schafe.
Damit sind wir dann auch schnell bei Agilität als vermeintlichem Allheilmittel, als angepriesenem Wundermittel, als Schlangenöl. Egal, was Sie vorhaben: Mit Scrum (oder einer anderen agilen Methode) wird es auf jeden Fall besser. Und natürlich zeigt Ihnen gegen viel Geld auch sehr gerne jemand, wie das funktioniert. Wenn es dann nicht funktioniert, haben Sie sich einfach nicht ausreichend bemüht. Vielleicht brauchen Sie noch einen weiteren Workshop oder ein weiteres Zertifikat. Und so entsteht nach und nach ein Geschäftsmodell, das sich selbst befeuert: Wenn Sie Ihr Zertifikat bestehen, ist das super, aber leider läuft es nach ein paar Jahren ab, und Sie müssen es erneuern. Es hat sich zwar inhaltlich nichts geändert, aber Sie sind auf der sicheren Seite, wenn Ihr Zertifikat aktuell bleibt. Dass Sie dafür wieder Geld bezahlen müssen, das kann man ja unter den Tisch fallen lassen. Aber hey, Sie haben wieder ein Zertifikat, das Sie an die Wand hängen können! Ist das nicht toll?
Was ist nun das Fazit? Ich glaube ehrlich gesagt, dass Scrum seine Hochzeit tatsächlich hinter sich hat. Und ich glaube auch, dass Scrum, wenn man mal ehrlich ist, gar nicht so gut und so übermäßig gelungen ist, wie oft angenommen oder dargestellt. Damit sage ich nicht, dass Scrum per se schlecht sei oder dass es keine Projekte gäbe, die sich für Scrum eignen würden, aber ich bin der festen Überzeugung, dass Scrum deutlich überbewertet ist.
Dass Scrum und Agilität heute oft gleichgesetzt werden, ist problematisch. Denn XP zum Beispiel halte ich nach wie vor für eine fantastische Arbeitsweise. Ja, vielleicht muss man das eine oder andere modernisieren, immerhin ist XP auch schon über 20 Jahre alt, aber XP halte ich persönlich für wesentlich gelungener als Scrum. Auch Kanban finde ich wesentlich gelungener als Scrum. Tatsächlich bin ich ein großer Freund von Kanban in der Verbindung mit XP, wobei ich auch dort ein paar Anpassungen vornehmen würde. Deshalb haben wir bei meinem Unternehmen, the native web [13], eine eigene Entwicklungsmethode entworfen, die zwar an Kanban und XP angelehnt ist, aber doch ein bisschen anders funktioniert.
Und ich weiß, dass jetzt viele sagen werden:
„Ja, aber damit machst du doch genau das, was du bei Scrum kritisiert hast: Du machst Kanban und XP auch nicht mehr wie im Lehrbuch.“
Und das stimmt. Aber ich habe vorhin auch nicht gesagt, dass man agile Methoden nicht adaptieren dürfe, sondern nur, dass man ein anderes Ergebnis erzielt, wenn man die Vorgehensweise ändert. Solange die Veränderung das Ergebnis verbessert, ist sie legitim. Das Problem ist nur, dass dreimonatige Sprints, fehlende Reviews und Pro-Forma-Retrospektiven das Ergebnis eher verschlechtern. Und dann war die Anpassung eben eine eher schlechte Idee. Man sollte also mit einem gewissen Augenmerk auf das Ergebnis an die Anpassung des Prozesses herangehen. Wenn man das kann, funktioniert es auch. Wenn nicht, sollte man es lieber lassen.
Langer Rede, kurzer Sinn: Ich glaube nicht, dass Agilität tot ist. Ich glaube auch nicht, dass Projekte, die einem agilen Prozess folgen, mit einer 268 Prozent höheren Wahrscheinlichkeit scheitern. Und ich glaube vor allem auch nicht, dass es Zeit ist, sich von agiler Entwicklung an sich zu verabschieden.
Ich glaube aber, dass man, wenn man agil arbeiten möchte, es dann auch richtig tun sollte. Dafür braucht man nicht zwingend Scrum, die Scrum Alliance, Scrum.org, einen zertifizierten Coach oder Ähnliches. Was man braucht, ist das Agile Manifest und jemanden, die oder der einen agilen Prozess auf dieser Basis aufbauen und betreuen kann, und die oder der wirklich versteht, was Agilität im Kern bedeutet.
URL dieses Artikels:
https://www.heise.de/-9846824
Links in diesem Artikel:
[1] https://www.dotnetpro.de/planung/agile/agilitaet-tot-2926271.html
[2] https://www.heise.de/blog/Agilitaet-fuehrt-zu-268-Prozent-mehr-Fehlschlaegen-kann-das-sein-9810522.html
[3] https://www.youtube.com/watch?v=gSVBWvoNJ-s
[4] https://www.youtube.com/watch?v=CxiPpf-Dejw
[5] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[6] https://agilemanifesto.org/
[7] https://www.youtube.com/watch?v=uyLhrO1rEyc
[8] https://www.youtube.com/watch?v=8RE68Fzjkuk
[9] https://www.youtube.com/watch?v=1JOSm5tUQmE
[10] https://www.youtube.com/watch?v=CdnP30NEKqk
[11] https://de.wikipedia.org/wiki/Cargo-Kult
[12] https://www.youtube.com/watch?v=GRZQLc1xkoo
[13] https://www.thenativeweb.io/
[14] mailto:who@heise.de
Copyright © 2024 Heise Medien
This is a quality-focussed release for the 1.24.x series meant to provide a good product to people blocked on PHP 7.4, while we will increase the requirements to PHP 8.1+ from the next 1.25.x series.
A few highlights ✨:
This release has been made by @Alkarex, @ColonelMoutarde, @den13501, @hkcomori, @math-GH
and newcomers @dservian, @crisukbot, @TomW1605
Full changelog:
OR Boolean search expressions #6672Last-Modified when content is not modified #6723cli/db-backup.php #6593
(Bild: Dilok Klaisataporn/Shutterstock.com)
Visual Studio und die .NET-Kommandozeilenwerkzeuge können nun vor Paketen mit Sicherheitslücken warnen.
Bei der Paketverwaltung können die Paketverwaltungsbefehle
dotnet add package und
dotnet restoresowie die Übersetzungsbefehle
dotnet buildund
msbuildnun Sicherheitswarnungen beim Verwenden von NuGet-Paketen mit Sicherheitslücken ausgeben (siehe Abbildungen).
Wählbar ist, ab welchem Schweregrad man Meldungen erhält, zum Beispiel
<PropertyGroup>
<NuGetAuditLevel>moderate</NuGetAuditLevel>
</PropertyGroup>Die hier einstellbaren Level sind low, moderate, high und critical.
Entwickler und Entwicklerinnen können alle NuGet-Sicherheitswarnungen mit der Projekteinstellung
<PropertyGroup>
<NuGetAudit>false</NuGetAudit>
</PropertyGroup>unterbinden. Seit .NET SDK 8.0.400 und Visual Studio 17.11 kann man alternativ auch nur einzelne Warnungen unterdrücken mit <NuGetAuditSuppress>:
<ItemGroup>
<NuGetAuditSuppress Include="https://github.com/advisories/GHSA-98g6-xh36-x2p7" />
</ItemGroup>Dieses Tag unterdrückt diese Warnung:
Warning NU1903: Package 'System.Data.SqlClient' 4.8.5 has a known high severity vulnerability, https://github.com/advisories/GHSA-98g6-xh36-x2p7 [35]
Man sieht die Warnung auch in Visual Studio:
Tipp: Die Sicherheitswarnungen erhält man auch in Projekten mit .NET 5.0, 6.0 und 7.0, sofern man das .NET 8.0 SDK verwendet.

(Bild: Screenshot (Holger Schwichtenberg))

(Bild: Screenshot (Holger Schwichtenberg))

(Bild: Screenshot (Holger Schwichtenberg))
Aktualisierung aufgrund von Änderungen in Bezug auf Sicherheitswarnungen beim Verwenden von NuGet-Paketen.
URL dieses Artikels:
https://www.heise.de/-9840301
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[32] https://www.heise.de/blog/Neu-in-NET-8-0-32-Weitere-Neuerungen-in-System-Text-Json-8-0-9821053.html
[33] https://www.heise.de/blog/Neu-in-NET-8-0-33-Erweiterung-des-AOT-Compilers-9829857.html
[34] https://www.heise.de/blog/Neu-in-NET-8-0-34-Verbesserte-Ausgaben-beim-Kompilieren-9837144.html
[35] https://github.com/advisories/GHSA-98g6-xh36-x2p7
[36] https://net.bettercode.eu/
[37] https://net.bettercode.eu/index.php#programm
[38] https://net.bettercode.eu/tickets.php
[39] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Trismegist san/Shutterstock.com)
Wer mit Node.js entwickelt, schreibt JavaScript – oder muss umständlich TypeScript konfigurieren. Doch beides hat nun bald ein Ende.
"Nie wieder JavaScript!"
Diesen Satz habe ich in den vergangenen fünfzehn Jahren, in denen ich mit Node.js gearbeitet habe, immer wieder gehört. Die Liste der Vorwürfe war lang: JavaScript sei keine richtige Programmiersprache. JavaScript sei nicht für komplexe Projekte im Enterprise-Bereich geeignet. JavaScript sei dies nicht, JavaScript sei jenes nicht. Natürlich trifft man in fünfzehn Jahren auch auf einige, die JavaScript mögen, aber die Mehrheit der Entwicklerinnen und Entwickler lehnt JavaScript rundheraus ab. Viele schreiben es nur aus Notwendigkeit, nicht aber aus Überzeugung. JavaScript sei seltsam [1], das ist eine immer noch weitverbreitete Meinung. Wenn auch Sie dieser Meinung sind, dann habe ich heute eine richtig gute Neuigkeit für Sie: Es ist vorbei, Sie werden nie wieder JavaScript schreiben müssen!
Vielleicht sagen Sie jetzt:
"Naja, eigentlich stimmt das so nicht ganz, denn auch heute schon muss ich JavaScript nicht zwingend schreiben. Schließlich gibt es TypeScript."
Und das ist richtig. Seit Microsoft vor zwölf Jahren TypeScript auf den Markt gebracht hat, ist es praktisch zur De-facto-Sprache in der modernen Webentwicklung geworden. Und das ist kein Zufall, denn TypeScript macht vieles richtig: Angefangen beim sehr guten und durchdachten optionalen statischen Typsystem bis hin zum ebenfalls sehr zuverlässigen Compiler. TypeScript können viele Entwicklerinnen und Entwickler nicht mehr aus ihrem Arbeitsalltag wegdenken. Wäre da nicht das Tooling, denn wo Licht ist, ist bekanntermaßen auch Schatten.
Ich weiß aus eigener Erfahrung, dass es Lustigeres gibt, als ein Node.js-Projekt mit TypeScript aufzusetzen. Es ist nämlich nicht damit getan, TypeScript zu installieren und zu konfigurieren, sondern es soll schließlich auch das ganze Drumherum mit TypeScript funktionieren: von der Codeformatierung über das Linting bis hin zu den Tests. Bis alle Bausteine so konfiguriert sind, dass alles zueinander passt und miteinander harmoniert, vergeht viel Zeit.
Da werde ich sicherlich nicht der Einzige sein, der sich in den vergangenen zwölf Jahren immer wieder gefragt hat, warum eigentlich Node.js nicht TypeScript nativ unterstützt. Warum muss man als Entwicklerin oder als Entwickler im Node-Universum immer diesen extrem lästigen Eiertanz aufführen, bis TypeScript endlich so läuft, wie es das soll? Wäre es nicht viel einfacher, wenn Node.js TypeScript von Haus aus unterstützen würde? Dann könnte man sich den ganzen Compiler sparen, die Tests würden automatisch mit TypeScript funktionieren, und das ganze sonstige Tooling wäre vermutlich schnell umgestellt. Denn wenn TypeScript erst einmal im Fundament richtig funktionieren würde, würde der Rest wohl rasch folgen. Also: Wäre es nicht fantastisch, wenn Node.js TypeScript nativ unterstützen würde? Wäre das nicht ein riesiger Schritt nach vorn?
Und damit kommen wir zu der versprochenen großen Neuigkeit: Seit Anfang Juli 2024 enthält Node.js native Unterstützung für TypeScript!
Weil viele jetzt wahrscheinlich neugierig sind, wie das funktioniert und vor allem auch, wie gut das funktioniert, habe ich ein paar Antworten. Zuerst einmal: Die Unterstützung für TypeScript ist aktuell noch experimentell, sie ist nur in den Nightly Builds vorhanden, und man muss beim Starten von Node.js ein passendes Flag angeben, nämlich --experimental-strip-types. Das Ganze wird sicherlich bald in einem regulären Release enthalten sein und vielleicht sogar in Node.js 23, das uns voraussichtlich im Oktober erwartet.
Die Implementierung ist zunächst ganz simpel: Die Typ-Annotationen im Code werden zur Laufzeit schlicht und ergreifend verworfen. Das heißt, es findet keinerlei Typenprüfung statt. Das war eine bewusste Entscheidung des Node-Teams. Wenn Sie die Typenprüfung haben wollen, brauchen Sie weiterhin den TypeScript-Compiler. Das ist bei Node.js in Zukunft also genauso wie bei Deno und Bun [3]. Tatsächlich ist das kein Zufall, denn unter der Haube verwendet Node.js für das Type-Stripping denselben Mechanismus wie Deno.
Dieses Type-Stripping ist dabei übrigens wörtlich zu nehmen: Es wird nämlich nicht der Code transformiert, sondern nur die Typ-Annotationen entfernt. Alles, was theoretisch von TypeScript nach JavaScript transformiert werden müsste, um zu funktionieren, wird daher aktuell nicht funktionieren. Dazu zählen etwa Features wie Enums oder Namespaces. Das heißt, zum jetzigen Zeitpunkt ist noch keine volle Unterstützung für TypeScript gegeben. Aber man darf nicht vergessen, dass wir derzeit noch über einen sehr frühen Entwicklungsstand sprechen, und dass sich im Laufe der Zeit noch einiges ändern kann. Dazu komme ich aber gleich noch.
Technisch basiert das Ganze auf dem npm-Modul @swc/wasm-typescript [4]. SWC ist dabei der Speedy Web Compiler [5], in Rust geschrieben und dementsprechend schnell. Das besagte npm-Modul enthält den TypeScript-Parser von SWC, aber nicht (wie man das vielleicht erwarten würde) als Rust-Code, sondern als WebAssembly-Code. Auf diesem Weg kann Node.js das Ganze einfach ausführen, ohne dass Rust auf dem jeweiligen System installiert sein müsste. Das finde ich persönlich sehr schlau gelöst. Und genau derselbe Mechanismus steckt übrigens auch in Deno.
Für die erste Version muss man mit einigen Einschränkungen leben wie der fehlenden Unterstützung für einige Sprachmerkmale. Dateien müssen außerdem zwingend die Dateiendung .ts tragen, sie dürfen nicht als .js benannt sein. Darüber hinaus wird TypeScript nur im Code Ihres eigenen Projekts unterstützt, nicht aber im node_modules-Verzeichnis. Man wollte verhindern, dass Entwicklerinnen und Entwickler npm-Module nur noch als reine TypeScript-Anwendung veröffentlichen, was die Abwärtskompatibilität zunichtemachen würde. Also muss beim Veröffentlichen von Modulen weiterhin kompiliert werden. Spannend finde ich übrigens, dass auch nach dem Type-Stripping Fehler zur Laufzeit mit den richtigen Zeilen- und Spaltennummern im Quellcode angegeben werden können. Das könnte darauf hindeuten, dass sogar Sourcemaps unterstützt werden – tatsächlich ist die Lösung aber weitaus einfacher: Beim Type-Stripping werden die Typannotationen nämlich einfach mit Leerzeichen überschrieben, sodass alle Positionen im Quellcode erhalten bleiben.
Auf absehbare Zeit soll das Type-Stripping dann von Node.js entkoppelt werden, sodass man nicht auf eine spezifische Node-Version mit einer spezifischen TypeScript-Version angewiesen ist. Man will zu einem Modell kommen wie mit npm, das bei Node.js mitgeliefert wird, sich aber unabhängig aktualisieren lässt. Eine Herausforderung ist, dass man TypeScript pro Projekt installieren möchte und nicht global systemweit. Wie das gelöst werden soll, ist noch offen. Es gibt zwar bereits ein npm-Modul namens amaro [6], das als Wrapper um @swc/wasm-typescript fungiert. In der Dokumentation dieses Moduls heißt es aktuell jedoch noch, dass man es global installieren solle. Das steckt also alles noch in den Kinderschuhen und wird noch seine Zeit brauchen.
Wenn dann irgendwann dafür eine Lösung gefunden ist, folgen die Schritte drei und vier der Roadmap: Zunächst wird dabei die Performance verbessert und die Kommunikation zwischen Node und dem TypeScript-Compiler effizienter gestaltet. In Schritt vier geht es dann schließlich um neue Features. Frühestens dann ist damit zu rechnen, dass weitere Sprachmerkmale von TypeScript unterstützt werden, die über das reine Type-Stripping hinausgehen. Ein Feature, das dann ebenfalls dazugehören soll, ist die Unterstützung der tsconfig.json. Ich finde es überraschend, dass ausgerechnet das noch so lange auf sich warten lassen wird. Aber gut: Es ist, wie es ist.
Insgesamt muss ich zugeben, dass ich positiv überrascht bin, dass dieses Feature nun grundsätzlich Einzug in Node.js findet. Deno und Bun hatten in den letzten Jahren einen deutlichen Vorsprung, der jetzt zunehmend kleiner wird. Ich habe an den letzten Versionen von Node.js stets viel zu kritisieren gehabt, aber das ist ein großer Schritt in die richtige Richtung. Auch wenn ich vielleicht nicht mit allen Details glücklich bin, ist das grundsätzlich dennoch ein hervorragender Schritt. Ich hoffe nur, dass das Thema nicht genauso versumpft wie andere, etwa die Single Executable Applications [7], die mit Node 19.7 eingeführt wurden. Oder die Verwendung der V8-eigenen Sandbox, um die Sicherheit bei heruntergeladenen Modulen zu verbessern [8], was in Anlehnung an das Sandbox-basierte Sicherheitsmodell von Deno erfolgte. Seit Node 20 ist daran jedoch ebenfalls nichts mehr passiert.
Deshalb bin ich zwar positiv überrascht, aber meine Begeisterung hält sich derzeit noch in Grenzen, weil ich skeptisch bin, wie viel von der angekündigten Roadmap tatsächlich umgesetzt werden wird und vor allem, wann. Denn es ist schön, wenn Deno und Bun dafür sorgen, dass wieder mehr frischer Wind in Node.js hineinkommt. Allerdings ist das nur solange schön, wie die Features auch tatsächlich fertig umgesetzt werden und nicht als angefangene Baustellen liegenbleiben. Da bin ich noch etwas verhalten. Aber: Die Zukunft wird zeigen, was das Node-Team zum Beispiel im Oktober in Version 23 veröffentlichen wird. Bis dahin müssen wir uns gedulden und uns überraschen lassen.
URL dieses Artikels:
https://www.heise.de/-9826686
Links in diesem Artikel:
[1] https://www.youtube.com/watch?v=VNYIYqqaOcc
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=WLklm8JQbjo
[4] https://www.npmjs.com/package/@swc/wasm-typescript
[5] https://swc.rs/
[6] https://www.npmjs.com/package/amaro
[7] https://www.youtube.com/watch?v=6ThplMUASJA
[8] https://www.youtube.com/watch?v=T4XakaNaMPU
[9] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Yurchanka Siarhei / Shutterstock.com)
Der neue Terminal Logger erzeugt übersichtlichere Ausgaben, aber der alte lässt sich auf Wunsch weiterhin verwenden.
Das .NET 8.0 SDK liefert seit Preview 4 einige deutliche Verbesserungen der Konsolenausgaben des Übersetzungswerkzeugs MSBuild (siehe Abbildungen 1 und 2). In Verbindung mit dem modernen Windows Terminal [1] sind die Ausgaben nun besser strukturiert.

(Bild: Screenshot (Holger Schwichtenberg))
Target Framework und Übersetzungsergebnis werden in den Farben Cyan, Grün und Rot hervorgehoben. Bei jedem Ausführungsschritt sieht man die aktuelle Dauer in Sekunden.

(Bild: Screenshot (Holger Schwichtenberg))
Dazu müssen Entwickler und Entwicklerinnen beim Übersetzen mit dotnet build oder msbuild zusätzlich den Parameter /tl (die Buchstaben stehen für den neuen "Terminal Logger") angeben:
dotnet build /tl
# beziehungsweise
msbuild /tl
Die Option prüft dann automatisch, ob das verwendete Konsolenfenster die neuen Features unterstützt und fällt gegebenenfalls auf den alten "Console Logger" zurück.
Man kann mit /tl:on oder /tl:off die Verwendung des neuen beziehungsweise alten Loggers erzwingen.
URL dieses Artikels:
https://www.heise.de/-9837144
Links in diesem Artikel:
[1] https://www.heise.de/news/Windows-Terminal-Preview-1-21-bringt-einen-experimentellen-Notizblock-9715811.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[32] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[33] https://www.heise.de/blog/Neu-in-NET-8-0-32-Weitere-Neuerungen-in-System-Text-Json-8-0-9821053.html
[34] https://www.heise.de/blog/Neu-in-NET-8-0-33-Erweiterung-des-AOT-Compilers-9829857.html
[35] https://www.heise.de/blog/Neu-in-NET-8-0-34-Verbesserte-Ausgaben-beim-Kompilieren-9837144.html
[36] https://net.bettercode.eu/
[37] https://net.bettercode.eu/index.php#programm
[38] https://net.bettercode.eu/tickets.php
[39] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Erstellt mit KI)
Das Open-Source-Projekt JSpecify zielt auf einheitlichen Standard für Null-Annotationen in Java. Beteiligt sind Firmen wie Google, JetBrains und Microsoft.
Vor einem Jahr habe ich bereits über Null-Checks in Java [1] geschrieben. Nach wie vor ist es sinnvoll, Parameter von Methoden und Konstruktoren mit Annotationen bezüglich des Verhaltens von null (z.B. @NonNull) zu versehen. Mittlerweile ist der Support jedoch deutlich besser geworden, da vor Kurzem Version 1.0 von JSpecify [2] erschienen ist. Das möchte ich für ein Update zu dem Thema nutzen.
JSpecify ist ein Open-Source-Projekt [3], in dem sich die bisherigen Anbieter von Null-Handling-Annotationen zusammengeschlossen haben, um endlich einen nutzbaren Standard zu definieren. Dazu gehören unter anderem Google, JetBrains, Meta, Microsoft und Oracle. JSpecify ist ein vollwertiges Modul im Java-Modulsystem, hat keine eigenen Abhängigkeiten und liefert mit gerade einmal vier Annotationen alles, was man in einem modernen Java-Projekt benötigt, um das Handling von null bei Parametern zu spezifizieren. Beispielcode, der die Annotationen nutzt, könnte wie folgt aussehen:
static @Nullable String emptyToNull(@NonNull String x) {
return x.isEmpty() ? null : x;
}
static @NonNull String nullToEmpty(@Nullable String x) {
return x == null ? "" : x;
}
Mehr Codebeispiele finden sich im User-Guide von JSpecify [4].
Das reine Anbringen der JSpecify-Annotation hat allerdings wenig Effekt. Der Compiler übersetzt weiterhin Code, der null an einen mit @NonNull-annotierten Parameter übergibt, und bei der Laufzeit löst der übersetzte Code nicht automatisch eine Exception aus.
Der Vorteil der Annotationen zeigt sich unter anderem im Zusammenspiel mit Entwicklungsumgebungen. IntelliJ kann die Annotations erkennen [5] und Warnungen oder Fehler bei Code anzeigen, der die Annotationen verletzt. Will man auf Nummer sicher gehen und Code mit solchen Problemen überhaupt nicht zulassen, kann man zusätzliche Hilfsmittel verwenden. Das von Uber entwickelte Open-Source-Tool NullAway [6] kann diese Annotationen zur Build-Zeit überprüfen und Fehler auszulösen, wenn die Definition der Annotationen nicht eingehalten wird. Fügt man das Ganze zu seinem Gradle- oder Maven-Build hinzu, erfolgt beim Kompilieren automatisch einen Fehler:
error: [NullAway] passing @Nullable parameter 'null' where @NonNull is required
myMethod(null);
^
Mit dieser Toolchain kann man seinen Code um einiges robuster bekommen und NullPointerExceptions zur Laufzeit vermeiden.
Muss man sich keine Gedanken mehr über NullPointerExceptions machen? So einfach ist es leider nicht. Diese Maßnahmen können nur den eigenen Code überprüfen. Hat man Abhängigkeiten, die keine solchen Annotationen nutzen, kann man nicht wissen, ob man diesen als Parameter null übergeben kann und welches Verhalten dies auslöst. Daher ist es weiterhin wichtig, an verschiedenen Stellen Variablen auf null zu überprüfen.
Wer Libraries oder Code entwickelt, der von anderen Projekten aufgerufen wird, kann nicht sicherstellen, dass Nutzer sich an die definierten Regeln halten und an einen mit @NonNull annotierten Parameter auch wirklich kein null übergeben. Daher ist es wichtig, immer Null-Checks durchzuführen, wenn man den Kontext des eigenen Codes verlässt – egal ob bei eigenen Abhängigkeiten oder bei einer öffentlichen API.
Dazu ist das aus dem OpenJDK stammende java.util.Objects.requireNonNull(obj, message) weiterhin das Mittel der Wahl. Um immer sinnvolle Exceptions zu erstellen, sollte man auf die Variante mit dem Message-Parameter setzen, da das System sonst eine NullPointerException ohne Message wirft. Das Ganze sieht für eine öffentliche API folgendermaßen aus:
public void setName(@NonNull String name) {
this.name = Objects.requireNonNull(name, “name must not be null”);
}
Wer einem performancekritischen Umfeld arbeitet, sollte auf eigene Methoden für die Checks verzichten. Der JIT-Compiler behandelt Objects.requireNonNull(...) durch die Annotation @ForceInline besonders und fügt alle Aufrufe der Methode direkt in die aufrufende Methode ein (inline), um so Performance und Stack-Größe zu optimieren.
Es hat lange gedauert, bis die Java-Community den heutigen Stand erreicht hat und es eine saubere und sinnvolle Bibliothek mit Annotationen bezüglich Null-Handling gibt. Was als JSR305 [7] im Jahr 2006 gestartet und leider schnell wieder fallengelassen wurde, könnte sich nach vielen Problemen mit unterschiedlichsten Annotationen und Umsetzungen zu einem De-facto-Standard wie SLF4J (Simple Logging Facade for Java) entwickeln.
JSpecify geht hier ganz klar den richtigen Weg. Toll wäre es, wenn nun ein Tooling wie beispielsweise NullAway sich durchsetzt und mit einer einfachen Nutzung und Best Practices es quasi jedem Projekt ermöglicht, besser mit null umzugehen. Wer bisher die Annotationen und Tools wie NullAway noch nicht im Einsatz hat, sollte sie ausprobieren. Jetzt ist der richtige Moment, um damit zu starten.
Anmerkung: Parallel zum Schreiben dieses Beitrags ist im OpenJDK mit einem neuen JEP [8] ein besserer nativer Support angekündigt worden. Da es noch einige Zeit dauern wird, bis die im JEP diskutierten Features Einzug in eine LTS Version des OpenJDK haben werden, sind die hier beschriebenen Mittel und Tools weiterhin eine klare Empfehlung. Das JEP bietet aber genug Aspekte, um es zeitnah in einem Artikel genauer zu betrachten.
URL dieses Artikels:
https://www.heise.de/-9820606
Links in diesem Artikel:
[1] https://www.heise.de/blog/Programmiersprache-Java-Null-Fehler-mit-statischer-Analyse-aufspueren-7351944.html
[2] https://jspecify.dev/
[3] https://github.com/jspecify/jspecify
[4] https://jspecify.dev/docs/user-guide/
[5] https://www.jetbrains.com/help/idea/nullable-notnull-configuration.html
[6] https://github.com/uber/NullAway
[7] https://jcp.org/en/jsr/detail?id=305
[8] https://openjdk.org/jeps/8303099
[9] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Camilo Concha / Shutterstock.com)
Wer dachte, dass nach dem Drama um Sam Altman im November 2023 Ruhe bei OpenAI eingekehrt ist, irrt. Das war erst der Anfang. Eine Analyse von Golo Roden.
Auf dem YouTube-Kanal [1] meines Unternehmens (the native web [2]) haben wir im November 2023 ein Video mit dem Titel "OpenAI + Microsoft: Alles inszeniert und manipuliert? [3]" veröffentlicht. Das war damals die Zeit, als der Vorstand von OpenAI Sam Altman unerwartet als CEO entließ, Microsoft ihm und mehreren seiner Gefolgsleute anbot, sie einzustellen und ein eigenes KI-Forschungslabor einzurichten, und Altman nur wenige Tage später wieder als CEO von OpenAI zurückkehrte, als wäre nichts geschehen.
Dieses Hin und Her gefiel insbesondere Microsoft nicht, da sie zu diesem Zeitpunkt bereits über 12 Milliarden Euro in OpenAI investiert hatten und selbstverständlich erwartet hätten, frühzeitig über Altmans Entlassung informiert zu werden. Doch das geschah offenbar nicht, und das Ergebnis war, dass sich (zumindest oberflächlich gesehen) letztlich nichts änderte – außer, dass Microsoft einen Sitz im Vorstand von OpenAI erhielt, wenn auch ohne Stimmrechte, als sogenannter "Board Observer".
Man hätte denken können, dass das Kindergartentheater um OpenAI damit abgeschlossen wr, doch weit gefehlt – tatsächlich war es nämlich erst der Anfang: Inzwischen hat die Angelegenheit nämlich in gewissem Sinne amüsante, zugleich aber auch besorgniserregende Entwicklungen genommen …
Dieses Mal beginnt die Geschichte im März 2024: Microsoft entschließt sich, eine eigene Abteilung für Künstliche Intelligenz namens "Microsoft AI" zu gründen. Als Leiter dieser Abteilung engagieren sie Mustafa Suleyman, einen der Mitbegründer von DeepMind, jenem Unternehmen, das unter anderem AlphaGo entwickelt hat – die KI, die besser Go spielt als jeder Mensch. Eine nicht nur damals durchaus beachtliche Leistung im Bereich der Künstlichen Intelligenz.
DeepMind wird 2014 dann von Google gekauft, wo Suleyman bis 2019 tätig ist, bevor er aufgrund von Vorwürfen über unangemessenes Verhalten gegenüber Mitarbeitern das Unternehmen verlässt. Man sagt ihm nach, sein Führungsstil habe nicht den Standards entsprochen, die Google im Management erwarte. Das lässt viel Spielraum für Interpretationen, aber fest steht zumindest, dass Suleyman nun Microsoft AI leitet. Aus technischer Sicht ist er sicherlich sehr begabt, menschlich allerdings nicht unumstritten.
Unabhängig von seiner Person muss man sich jedoch vor Augen führen, dass Microsoft trotz ihrer Investitionen in OpenAI auf diesem Weg eine eigene KI-Abteilung aufbaut, was durchaus als Konkurrenz zu OpenAI gewertet werden könnte.
Springen wir vor in den Juni 2024: Apple veranstaltet wie jeden Sommer die World Wide Developers Conference (WWDC) und verkündet stolz, dass zukünftig KI-Funktionalitäten direkt in die Betriebssysteme iOS, iPadOS und macOS integriert werden. Siri soll erheblich verbessert werden, nicht nur in der Erkennung und Ausgabe von Sprache, sondern auch bei der Handschrifterkennung und der Kontextualisierung von Informationen.
Die Frage ist natürlich: Wie machen sie das? Hat Apple etwas Eigenes entwickelt? Und tatsächlich: Ja, Apple kündigt auf dieser WWDC auch einen neuen Dienst namens Apple Intelligence an, doch für die zuvor genannten Funktionen greift Apple (und das kommt überraschend) auf ChatGPT zurück [5]. Das heißt, plötzlich nutzt ein weiteres großes Tech-Unternehmen neben Microsoft die Dienste von OpenAI, was Microsoft sicherlich nicht erfreut haben dürfte. Insbesondere, wenn man bedenkt, dass Microsoft innerhalb weniger Jahre über 12 Milliarden Euro in OpenAI investiert hat.
Wer denkt, Apple habe ebenfalls eine beträchtliche Summe bezahlt, irrt sich: Die Kooperation mit OpenAI kostet Apple nämlich keinen einzigen Cent [6]. Das öffentlich genannte Argument dafür lautet, dass es sich um eine Win-Win-Situation handele, da OpenAI von der massiven Verbreitung auf Apple-Geräten ebenfalls profitieren würde. Ich will nicht so weit gehen zu behaupten, dass Microsoft damit 12 Milliarden Euro in den Sand gesetzt hätte, aber dass das ein harter Schlag ins Gesicht ist, darüber müssen wir sicherlich nicht diskutieren.
Aber es kommt noch besser: Drei Wochen nach der WWDC wird bekannt, dass auch Apple einen Sitz im Vorstand von OpenAI [7] erhält, ebenfalls als Board Observer, was Microsoft natürlich ebenfalls wenig gefallen haben dürfte. Die Person, die diesen Posten für Apple übernehmen soll, ist dabei übrigens niemand Geringeres als Phil Schiller, früherer Marketing-Chef von Apple und zuletzt Leiter des App-Stores.
Genau eine Woche später, am 10. Juli, gibt Microsoft dann überraschend seinen Sitz im Vorstand von OpenAI auf. Das wirkt auf den ersten Blick wie kindisches Verhalten, ist es aber nicht, denn am selben Tag gibt auch Apple überraschend seinen Sitz im Vorstand wieder auf [8] – wohlgemerkt nach gerade einmal einer Woche.
Da fragt man sich natürlich, was dieses Hin und Her soll: Was sind die Gründe dafür? Es wirkt durchaus seltsam, dass die Vertreter von Microsoft und Apple am selben Tag den Vorstand von OpenAI verlassen, wo Apple gerade erst eine Woche dort vertreten war. Dahinter steckt, wie man inzwischen weiß, die US-amerikanische Börsenaufsicht beziehungsweise die Kartellbehörde. Denn auch wenn es den Anschein hat, dass man in der Technologiebranche in den USA mehr oder weniger tun und lassen kann, was man will, hat doch alles seine Grenzen: Und die Behörden in den USA fangen an, unruhig zu werden, weil ihnen der Einfluss der großen Tech-Konzerne (in diesem Fall also von Microsoft und Apple) auf ein für die Zukunft der Menschheit potenziell relevantes Unternehmen wie OpenAI doch etwas zu weit geht.
Wer sich einmal näher mit der Geschichte von Microsoft im Hinblick auf das Kartellrecht beschäftigt hat, weiß, dass die USA da zumindest in der Vergangenheit sehr entspannt waren. Wenn also selbst die jetzt unruhig werden, dann hat das schon etwas zu bedeuten …
Kommen wir nun zum 25. Juli 2024, also weitere zwei Wochen später. OpenAI kündigt an diesem Tag ein neues Produkt an, nämlich SearchGPT [9], eine Mischung aus Künstlicher Intelligenz und Suchmaschine, um zu demonstrieren, wie sie sich die Zukunft der Informationsbeschaffung vorstellen. Dieses Thema beschäftigt auch Google schon seit Längerem, und vermutlich arbeiten auch alle anderen Suchmaschinenbetreiber an einer sinnvollen und zielgerichteten Integration von Künstlicher Intelligenz und Suche.
OpenAI zeigt an diesem Tag jedoch noch gar nichts Konkretes, sondern veröffentlicht lediglich einen Blogpost und ein Video, in dem SearchGPT präsentiert wird. Es wird noch nicht einmal ein Prototyp gezeigt, sondern lediglich ein Video davon. Aktuell kann man sich bei OpenAI auf einer Warteliste eintragen [10], doch über kurz oder lang soll SearchGPT in ChatGPT integriert werden.
Diese Ankündigung, verbunden mit der gesamten Vorgeschichte, führt dann schließlich dazu, dass Microsoft am 1. August 2024 in ihrem neuen Jahresbericht plötzlich OpenAI als Konkurrenz in den Bereichen KI und Suche [11] aufführt. OpenAI reiht sich damit in eine illustre Gesellschaft zwischen Apple, Amazon, Google und Meta ein. Natürlich mag ich mich täuschen, aber mich beschleicht zunehmend das Gefühl, dass Microsoft die Richtung, in die sich OpenAI entwickelt, nicht mehr so recht gefällt.
OpenAI lässt es sich nicht nehmen, das Ganze prompt zu kommentieren und erklärt, Microsoft sei weiterhin ein wichtiger Partner, man sei die Partnerschaft von vornherein in dem Bewusstsein eingegangen, dass es zu Wettbewerb kommen könne, und so weiter – aber trotzdem bin ich da skeptisch.
Insgesamt erinnert mich die ganze Geschichte sehr an ein Drehbuch für ein paar Folgen "Gute Zeiten, schlechte Zeiten" (oder eine beliebige andere Soap). Auch dort gibt es regelmäßig absurde Dramen, mit viel Hin und Her, wer jetzt mit wem, und so weiter. Der einzige Unterschied ist, dass es hier nicht um eine seichte Fernsehserie geht, sondern um die weltweit mächtigsten Milliarden-Konzerne und eine der wichtigsten Zukunftstechnologien. Und ich weiß nicht, wie es Ihnen damit geht, aber mir persönlich behagt es überhaupt nicht, dass es bei diesem Hin und Her offensichtlich ausschließlich um finanzielle Interessen und Marktmacht geht, und dass es überhaupt nicht um die Frage geht, wie oder ob diese Technologie zum Wohl der Menschheit eingesetzt wird, ob sie in die richtige Richtung entwickelt wird, ob ethische Fragen berücksichtigt werden, und so weiter.
Natürlich kann man sagen, es sei auch nicht die Aufgabe von Konzernen, sich um derartige Fragen zu kümmern, aber dann muss man vielleicht auch sagen, dass das zwar richtig ist, solche Technologien dann aber vielleicht auch nicht in deren Hände gehören. Ich persönlich finde das äußerst bedenklich. Und das Schlimme daran ist, dass, als OpenAI vor fast zehn Jahren gegründet wurde, genau dies das Ziel war: Eine gemeinnützige Organisation zu schaffen, die sich mit der Entwicklung von Künstlicher Intelligenz und deren Vereinbarkeit mit dem Wohl und der Zukunft der gesamten Menschheit beschäftigt.
Davon ist heute nichts mehr übrig. Und es ist auch klar, warum: Die großen Konzerne, allen voran Microsoft, haben daran keinerlei Interesse. Am Ende des Tages geht es nämlich (wie immer) nur ums Geld. Microsoft ist die Moral dabei völlig egal, solange es eine Menge Geld zu verdienen gibt. Warum ich da nun speziell Microsoft anprangere? Ganz einfach: OpenAI erhielt als gemeinnützige Organisation kaum Forschungsgelder, auch nicht von Microsoft. Doch kaum wurde der finanziell orientierte Ableger von OpenAI gegründet, war Microsoft sofort mit Milliarden-Investitionen dabei. Das zeigt mehr als deutlich, worum es Microsoft ausschließlich geht.
Natürlich ist es völlig legitim, als Unternehmen Geld verdienen zu wollen, das ist ja sogar der Sinn eines Unternehmens. Aber man darf dabei meiner Meinung nach nicht über Leichen gehen. Und genau das werfe ich Microsoft vor: Ihnen ist alles egal, Hauptsache, ihr Stück vom Kuchen wird noch größer. Falls Sie übrigens noch einmal mehr über die Entstehungsgeschichte von OpenAI und den Wandel von einer gemeinnützigen Organisation hin zu einem finanziell ausgerichteten Unternehmen erfahren möchten, dann lege ich Ihnen das am Anfang erwähnte Video "OpenAI + Microsoft: Alles inszeniert und manipuliert? [12]" nahe.
Insofern ist es schon eine gewisse Ironie der Geschichte, dass die Kooperation von Apple und OpenAI nun ausgerechnet Microsoft auf die Füße fällt. Mein persönliches Mitleid hält sich da ehrlich gesagt sehr in Grenzen. Bitte verstehen Sie mich nicht falsch, ich halte Apple und auch die anderen großen Tech-Konzerne wie Amazon, Google, Meta, und so weiter, nicht für Heilige. Mir ist klar, dass sich all diese Unternehmen in vielen Situationen genauso verhalten, nur in diesem Fall ist es eben konkret Microsoft, deren Kartenhaus zusammenstürzt. Und irgendwie empfinde ich persönlich das nicht als ganz unverdient.
Das wirklich Besorgniserregende ist jedoch, dass hier mit einer der wichtigsten Zukunftstechnologien gespielt wird, und das hinterlässt einfach kein gutes Gefühl, wenn das in den Händen von Konzernen liegt. Tatsächlich würde es mich allerdings auch nicht beruhigen, wenn es stattdessen Staaten wären, die beteiligt sind. Dann wären es eben diese, die damit spielen. Meiner Meinung nach gehört eine solche Technologie in die Hände eines unabhängigen, idealerweise internationalen Konsortiums, in die Hände einer Stiftung, oder einer ähnlichen Organisation.
Das fordere ich übrigens nicht zum ersten Mal: Ich habe in Bezug auf kritische, weltweite Infrastruktur schon des Öfteren darauf hingewiesen, beispielsweise beim Kauf von GitHub, was damals übrigens auch Microsoft war. Auch dort hätte ich es wesentlich lieber gesehen, wenn GitHub an eine Stiftung gegangen wäre, die Microsoft gerne hätte mitfinanzieren können – aber daran besteht offensichtlich kein Interesse.
Man muss natürlich auch die Frage stellen, wer so etwas überhaupt leisten könnte. Wer wäre ein internationales Konsortium, das unabhängig von Staaten und Konzernen agiert und das Wohl der gesamten Menschheit im Blick hat? Ich habe länger darüber nachgedacht, und mit viel gutem Willen fallen mir am ehesten die Vereinten Nationen ein, insbesondere die UNESCO, da sie sich mit Bildung, Wissenschaft und Kultur befassen. Aber so richtig passt das irgendwie nicht. Man könnte auch an das IEEE denken, denn dessen Zweck ist tatsächlich die "Förderung technologischer Innovationen zum Nutzen der Menschheit". Das Problem ist nur, dass sich das IEEE stark auf die technische Seite konzentriert, auf Standards und Ähnliches, und weniger auf die ethische Seite. Zumindest in der Theorie könnte man auch noch an das World Economic Forum (WEF) denken, aber offen gesagt: Das scheint mir doch sehr wirtschaftsgetrieben zu sein und weniger vom Ideal einer besseren Welt geleitet.
Doch selbst wenn eine dieser Organisationen zuständig wäre, sind sie alle zu weit vom Alltag eines durchschnittlichen Menschen entfernt. Wenn man einfach irgendjemanden auf der Straße nach ihrer oder seiner Meinung zum Thema Künstliche Intelligenz fragt, dann haben die meisten dazu tatsächlich überhaupt keine Meinung. Denn für die meisten Menschen ist Künstliche Intelligenz eine völlig abstrakte und sehr weit entfernte Entwicklung. Künstliche Intelligenz kommt im Leben der meisten Menschen nicht bewusst vor, und wir müssen uns hüten, uns Informatikerinnen und Informatiker da als das Maß der Dinge zu sehen.
Der Durchschnittsmensch ist am ehesten noch ein Konsument von Künstlicher Intelligenz, aber selbst das ist bei vielen Menschen noch lange nicht der Fall. Und trotzdem hat Künstliche Intelligenz sehr viel mehr Auswirkungen auf die meisten Menschen, als sie glauben: Das beginnt schon beim Konsum von Nachrichten, betrifft also ganz schnell beispielsweise den politischen Bereich. Es geht um die Frage, ob Sie bei Ihrer nächsten Bewerbung den Job bekommen oder nicht. Es betrifft unsere Kinder in der Schule und in den Hochschulen. Und, und, und.
Aber das meiste davon passiert eben unsichtbar. Und das wiederum wird sich nur ändern, wenn wir aufklären und bilden: Wenn Künstliche Intelligenz in der Bildung weder verteufelt noch kritiklos in den Himmel gelobt wird. Wenn es eine ernsthafte gesellschaftliche Auseinandersetzung mit den Folgen von Künstlicher Intelligenz auf breiter Basis gibt. Doch das hat schon bei den Themen Medienkonsum und Social Media nicht funktioniert, und das war noch Themen, die im Vergleich sehr viel greifbarer waren.
Hier haben wir meiner Meinung nach ein riesiges gesellschaftliches Problem, das immer größer wird: nämlich die Unwissenheit und die daraus resultierende Gleichgültigkeit gegenüber diesen Technologien. Solange die meisten Menschen glauben, dass Künstliche Intelligenz sie nicht zu interessieren braucht, weil sie sie vermeintlich nicht betrifft, wird niemand aufstehen und versuchen, die eingeschlagene Richtung zu verändern.
Übrigens: Auch wenn ich die aktuelle Umsetzung für unglaublich schlecht und innovationsfeindlich halte, ist die einzige Institution, die mir noch einfällt und die tatsächlich versucht, etwas in dieser Richtung zu bewegen, die EU: Der AI Act ist in seiner jetzigen Form für mein Empfinden eine ziemliche Katastrophe, aber zumindest versucht dort jemand, Regeln und Richtlinien aufzustellen. Allerdings ist das, wie so oft in der EU, nur reaktiv, nicht proaktiv. Denn viel mehr passiert in der EU nicht: Es gibt keine europäische KI-Forschung im großen Stil. Und wenn ich an andere europäische IT-Projekte denke, wie das Cloud-Projekt Gaia-X, dann habe ich da leider auch keine allzu große Hoffnung.
Für mein Empfinden klafft da eine große Lücke, um die sich dringend jemand kümmern müsste – und zwar jemand, der die gesamte Menschheit vertritt. Aber ich sehe aktuell nicht, wer das sein oder wie das funktionieren könnte. Doch wenn wir nicht immer mehr zu Spielbällen der Tech-Konzerne werden wollen, wenn wir wollen, dass unsere Kinder in einer selbstbestimmten Welt leben können, dann muss sich dringend etwas ändern.
Was ich persönlich dazu beitragen kann, ist, andere Entwicklerinnen und Entwickler immer wieder einmal auf dieses Thema aufmerksam zu machen, zum Beispiel mit Blogposts wie diesem, und zu hoffen, dass der Artikel Gehör findet und sich verbreitet. Insofern: Wenn Sie mir einen großen Gefallen tun wollen, teilen Sie diesen Blogpost, schicken Sie ihn an Menschen, die Sie kennen und bei denen Sie denken, dass das Ganze auf fruchtbaren Boden fällt, und tragen Sie dazu bei, die Botschaft in die Welt hinauszutragen.
URL dieses Artikels:
https://www.heise.de/-9829408
Links in diesem Artikel:
[1] https://www.youtube.com/@thenativeweb
[2] https://www.thenativeweb.io/
[3] https://www.youtube.com/watch?v=tOegaUmPe4c
[4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[5] https://openai.com/index/openai-and-apple-announce-partnership/
[6] https://www.heise.de/news/Apple-und-OpenAI-Angeblich-fliesst-kein-Geld-fuer-ChatGPT-9764460.html
[7] https://www.heise.de/news/Phil-Schiller-als-Beobachter-im-Aufsichtsrat-OpenAI-bindet-Apple-naeher-an-sich-9787806.html
[8] https://www.heise.de/news/Kehrtwende-Apple-offenbar-doch-nicht-im-Aufsichtsrat-von-OpenAI-9796884.html
[9] https://openai.com/index/searchgpt-prototype/
[10] https://chatgpt.com/search
[11] https://www.heise.de/news/Microsoft-betrachtet-OpenAI-jetzt-als-Konkurrenten-bei-KI-und-Internet-Suche-9823628.html
[12] https://www.youtube.com/watch?v=tOegaUmPe4c
[13] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Bild erstellt mit KI)
Der AOT-Compiler kann auch Webservices und Hintergrunddienste übersetzen, aber mit einigen Einschränkungen.
Mit .NET 7.0 liefert Microsoft erstmals einen Ahead-of-Timer-Compiler (AOT), der es erlaubt, .NET-Anwendungen komplett in Maschinencode ohne Just-in-Time-Kompilierung zur Laufzeit auszuliefern. Der "Native AOT" genannte Compiler konnte in .NET 7.0 jedoch nur Konsolenanwendungen übersetzen.
Seit .NET 8.0 sind nun zusätzlich auch folgende Anwendungsarten beim AOT-Compiler möglich:
System.Text.Json im Source-Generator-Modus.Weitere Einschränkungen zeigt folgende Abbildung:

(Bild: Microsoft [1])
Hinweis: Native AOT funktioniert weiterhin dort nicht, wo es am nötigsten wäre, um die Startzeit und den RAM-Bedarf zu verringern: Windows Forms und WPF.
Den Source Generator in System.Text.Json hat Microsoft ausgebaut, sodass er nun fast alle Konfigurationsoptionen wie der Reflection-basierte Modus kennt. Zudem funktioniert der Source-Generator jetzt zusammen mit den Init Only Properties aus C# 9.0 und den Required Properties aus C# 11.0. Den alten Reflection-Modus kann man durch eine Projekteinstellung komplett deaktivieren. Den Modus prüft die Bedingung
if (JsonSerializer.IsReflectionEnabledByDefault) { … }
Neu in .NET 8.0 ist auch, dass es bei einigen Projektvorlagen nun direkt möglich ist, den AOT-Compiler mit der Kommandozeilenoption —aot oder mit einem Häkchen in Visual Studio zu aktivieren:
dotnet new console –aotdotnet new worker –aotdotnet new grpc –-aot
(Bild: Screenschot (Holger Schwichtenberg))
(Bild: Screenshot (Holger Schwichtenberg))
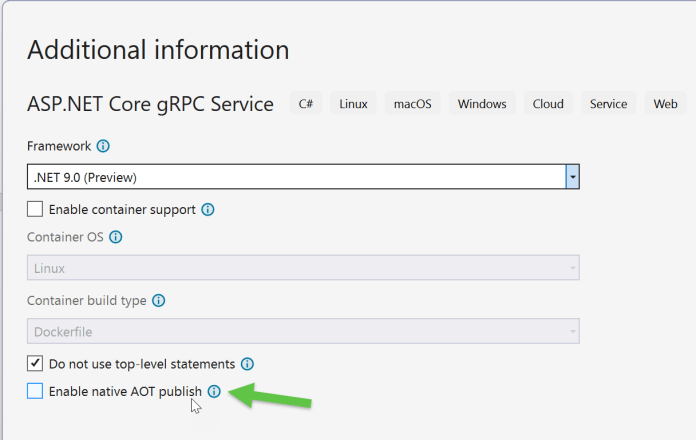
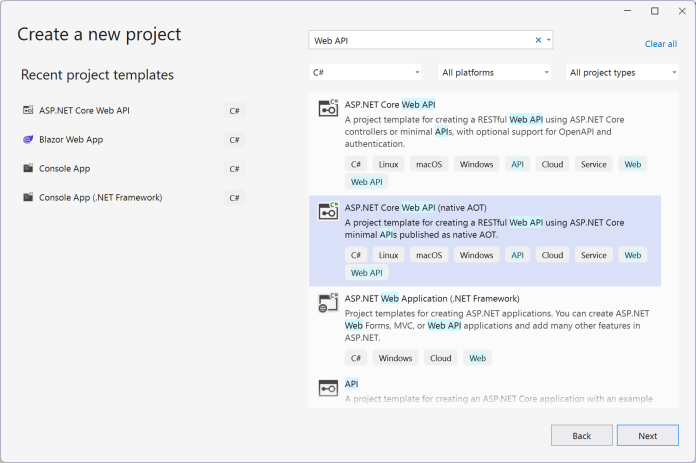
Bei der Projektvorlage für ASP.NET Core WebAPIs (Kurzname webapi) gibt es keine Option —aot und kein Häkchen in Visual Studio. Hier hat sich Microsoft entschlossen, eine eigene Projektvorlage zu bauen "ASP.NET Core WebAPI (native AOT)" mit Kurznamen webapiaot. Die verwendet auch nicht das bisher in der WebAPI-Projektvorlage übliche Beispiel mit Wetterdaten, sondern eine Aufgabenliste.
(Bild: Screenshot (Holger Schwichtenberg))
Unterschiede zum normalen Minimal WebAPI-Template sind:
WebApplication.CreateSlimBuilder() statt CreateBuilder()Folgender Code liefert eine Aufgabenliste statt einer Wettervorhersage:
using System.Text.Json.Serialization;
namespace MinimalWebAPI_AOT;
public class Program
{
public static void Main(string[] args)
{
var builder = WebApplication.CreateSlimBuilder(args);
builder.Services.ConfigureHttpJsonOptions(options =>
{
options.SerializerOptions.TypeInfoResolverChain.Insert(0, AppJsonSerializerContext.Default);
});
var app = builder.Build();
var sampleTodos = new Todo[] {
new(1, "Walk the dog"),
new(2, "Do the dishes", DateOnly.FromDateTime(DateTime.Now)),
new(3, "Do the laundry", DateOnly.FromDateTime(DateTime.Now.AddDays(1))),
new(4, "Clean the bathroom"),
new(5, "Clean the car", DateOnly.FromDateTime(DateTime.Now.AddDays(2)))
};
var todosApi = app.MapGroup("/todos");
todosApi.MapGet("/", () => sampleTodos);
todosApi.MapGet("/{id}", (int id) =>
sampleTodos.FirstOrDefault(a => a.Id == id) is { } todo
? Results.Ok(todo)
: Results.NotFound());
app.Run();
}
}
public record Todo(int Id, string? Title, DateOnly? DueBy = null, bool IsComplete = false);
[JsonSerializable(typeof(Todo[]))]
internal partial class AppJsonSerializerContext : JsonSerializerContext
{
}
Hinweis: Alternativ kann man den Native AOT Compiler auch wie bisher nachträglich per Tag in der Projektdatei aktivieren:
<PublishAot>true</PublishAot>
und konfigurieren:
<IlcOptimizationPreference>Speed</IlcOptimizationPreference>
oder:
<IlcOptimizationPreference>Size</IlcOptimizationPreference>
Auch bei dotnet publish lässt sich Native AOT noch aktivieren:
dotnet publish -r win-x64 -c Release -p:PublishAOT=true
Wer den AOT-Compiler für ein ASP.NET-Core-Projekt aktiviert, erhält seit .NET 8.0 Warnungen beim Aufruf von Methoden, die nicht kompatibel mit dem AOT-Compiler sind:

(Bild: Screenshot (Holger Schwichtenberg))
Microsoft ermöglicht es seit .NET 8.0, .NET-Anwendungen für iOS, Mac Catalyst und tvOS mithilfe des neuen .NET-Native-AOT-Compilers zu kompilieren. Diese Möglichkeit gibt es sowohl für Apps, die auf diese Plattformen beschränkt sind (.NET for iOS), als auch für das .NET Multi-Platform App UI (.NET MAUI). Dadurch laufen die Anwendungen nicht mehr auf Mono, und die App-Pakete für ".NET for iOS" werden spürbar kompakter. Hingegen verzeichnen die App-Pakete für .NET MAUI eine Zunahme in ihrer Größe.
In einem Blogeintrag [2] bestätigt Microsoft, dass die Firma das Problem erkannt hat und aktiv an einer Lösung arbeitet, die zu einem Größenvorteil von etwa 30 Prozent führen soll.

(Bild: Microsoft [3])
Datenbankzugriffe sind beim AOT-Compiler weiterhin nicht mit dem Objekt-Relationalen Mapper Entity Framework Core möglich, da dieser immer noch Laufzeitkompilierung verwendet. Gleiches gilt für den zweitwichtigsten OR-Mapper der .NET-Welt, den Micro-ORM Dapper [4]. In AOT-kompilierten Anwendungen können Entwicklerinnen und Entwickler derzeit nur DataReader, DataSet und Command-Objekte aus ADO.NET oder das GitHub-Projekt NanORM [5] verwenden.
Folgendes ist mit Native AOT auch in .NET 8.0 nicht möglich, selbst wenn man eine der oben aufgeführten Anwendungsarten erstellt:
Möglich sind dagegen unter anderem
Microsoft.Extensions.DependencyInjection) und AutoFacFür .NET 8.0 hat Microsoft Zahlen herausgegeben, welche Auswirkungen der Native-AOT-Compiler auf WebAPIs hat. Man sieht in der Grafik Folgendes:

(Bild: Microsoft)
URL dieses Artikels:
https://www.heise.de/-9829857
Links in diesem Artikel:
[1] https://learn.microsoft.com/en-us/aspnet/core/fundamentals/native-aot?view=aspnetcore-8.0&tabs=netcore-cli
[2] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6/#support-for-targeting-ios-platforms-with-nativeaot
[3] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6/#support-for-targeting-ios-platforms-with-nativeaot
[4] https://github.com/DapperLib/Dapper
[5] https://github.com/DamianEdwards/Nanorm
[6] https://net.bettercode.eu/
[7] https://net.bettercode.eu/index.php#programm
[8] https://net.bettercode.eu/tickets.php
[9] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Jose HERNANDEZ Camera 51/Shutterstock.com)
Softwareentwicklungsteams sind soziale Systeme. Auch andere Primaten bilden solche sozialen Systeme. Was können wir von den anderen Primaten lernen?
Wie Menschen soziale Organisationen bilden, hat Auswirkungen auf unsere Branche: So gibt es die Frage, wie groß ein Team oder eine Firma zu sein hat. Als Orientierung dient oft die Dunbar-Zahl [1] von 150. Sie soll angeben, mit welcher Gruppengröße Menschen typischerweise noch gut zurechtkommen. Leider ist diese Darstellung schlicht falsch. Dunbars wissenschaftliche Publikation [2] sagt etwas völlig anderes.
Er untersuchte nicht menschliche Primaten, umgangssprachlich fälschlicherweise oft als "Affen" bezeichnet. Das Verhältnis des Volumens ihres Neocortex zum Rest des Gehirns hängt mit der Gruppengröße zusammen, die diese Primaten bilden. Aus diesen Daten extrapoliert Dunbar eine Gruppengröße für Menschen von 147,8. Wie in der Wissenschaft üblich, hat der Wert eine Streuung. Mit 95 % Wahrscheinlichkeit liegt der Wert im Bereich von 100,2 bis 231,1. Ein anderes Paper [3] ergibt völlig andere Bereiche für die Zahl mit 95-%-Konfidenzintervallen im Bereich 3,8 bis 292,0. Das Paper stellt noch einige andere Datenanalysen dar, die aber alle ein Konfidenzintervall von niedrigen einstelligen Werten bis hin zu einigen Hundert aufweisen. Wenn man dieses Paper betrachtet, hat die Zahl keinen praktischen Nutzen.
Aber Dunbar geht es auch nicht so sehr um die Zahl: In Gruppen nutzen Primaten gegenseitige Fellpflege (Grooming), um unter anderem Parasiten zu entfernen, aber auch um sozialen Zusammenhalt zu stärken. Dunbar stellt ein Verhältnis zwischen der Zeit her, die für Fellpflege notwendig ist, und der Größe der Gruppe der Primaten. Größere Gruppen benötigen mehr Fellpflege. Daraus, so Dunbar, würde sich für Menschen ein Zeitaufwand ergeben, der nicht darstellbar ist. Laut Dunbar haben Menschen daher Sprache entwickelt, um effizienter sozialen Zusammenhalt herzustellen. Sprache ist also nicht, wie andere Wissenschaftler und Wissenschaftlerinnen behaupten, zur Koordinierung beim Jagen oder Herstellen von Werkzeugen entstanden, sondern zur Pflege sozialer Beziehungen.
Mit anderen Worten: Dunbars zentrale These ist nicht die Größe der Gruppe, sondern dass menschliche Sprache sich zum Stärken sozialer Beziehungen entwickelt hat.
Die Dunbar-Zahl von 150 ist nur die extrapolierte maximale Größe von Menschengruppen, die Sprache als einen der gemeinsamen Fellpflege vergleichbaren Prozess nutzt. Er spricht von Clan / Village. Daneben nennt er noch andere Gruppen: Bands (Banden) mit 30 bis 50 Personen und Tribes (Stämme) mit 1000 bis 2000 Personen.
Dementsprechend diskutiert Dunbars Paper zahlreiche Beispiele für menschliche Gruppen sehr unterschiedlicher Größe. Gruppen mit einer Größe deutlich anders 150 gehören dann eben zu einer anderen Kategorie, so Dunbar. Seine These ist also definitiv nicht die Größe der Gruppen, sondern die Mechanismen der Gruppe, um sich selbst zu erhalten – und das schreibt er auch selbst so.
Besonders interessant: Dunbar sieht die Gruppen im Militär als eine Bestätigung seiner These, denn es soll dort auch Gruppen einer Größe von 100 bis 200 Menschen geben. Aber natürlich gibt es im Militär auch wesentlich kleinere Gruppen wie einen Trupp (2 bis 8 Soldaten bei der Bundeswehr) oder größere Gruppen wie ein Bataillon (300 bis 1200 Soldaten), die er dann nicht weiter betrachtet.
Zu dem Paper gibt es umfangreiche Kritik anderer Wissenschaftler, sodass praktisch jeder Teil des Papers umstritten ist. Beispielsweise gibt es bezüglich der Gruppengröße Hinweise auf Fission-/Fusion-Verhalten unter Primaten. Das sind Gruppen, zu denen Individuen hinzustoßen und sich dann wieder entfernen. Individuen können etwa an einem Ort gemeinsam schlafen, aber den Tag getrennt verbringen. Solche Gruppen sind also nur temporär. Spezies mit solchem Verhalten benötigen aber nur wenig Zeit für die gemeinsame Fellpflege und sind teilweise deutlich größer. Offensichtlich können Primaten also auch ohne komplexe menschliche Sprache große Gruppen bilden.
Für die Organisation von menschlichen Teams kann man also aus der Dunbar-Zahl nichts lernen. Dunbar selbst sagt ja, dass es menschliche Gruppen praktisch beliebiger Größe geben kann. Man muss für diese Aussage nicht einmal auf die umfangreiche Kritik zurückgreifen.
In den Kritiken finden sich noch weitere interessante Punkte. So ist es beispielsweise überhaupt nicht klar, warum die Anzahl Menschen, die ein Mensch in irgendeiner Form kennt, eine Gruppengröße beeinflusst. Wenn wir also nur eine bestimmte Anzahl Menschen kennen und mit ihnen regelmäßig sprechen, dann kann eine Gruppe dennoch deutlich größer sein. Es reicht ja, wenn man gemeinsam koordiniert handelt. Dank Sprache können Menschen sich auch in großen Dimensionen bis hin zu Nationen oder darüber hinaus koordinieren. Dass sich Menschen unterschiedlich gut kennen und vertrauen, sollte eigentlich jedem klar sein. Im Projektalltag nutzt man das auch aus. Statt einer Person eine Information direkt zu geben, bittet man eine dritte Person darum, weil das Vertrauensverhältnis zwischen diesen beiden Personen besser ist.
Für mich ist die Fehlinterpretation der Dunbar-Zahl ein Hinweis auf ein grundlegendes Problem: Komplexes menschliches und soziales Verhalten wird simplifiziert. Am Ende steht eine Zahl mit der idealen Größe einer Gruppe. Das ist eine einfache Regel, an die man sich halten kann.
Eigentlich sollte die Intuition jedem etwas anderes sagen. Denn jeder weiß durch das eigene Leben, dass Menschen in unterschiedlichen Gruppen agieren können – im privaten und im beruflichen Kontext: die Firma, der Verein, die Nachbarschaft, die Freunde, die Familie. Die Gruppen sind unterschiedlich groß. Für besonders große Gruppen gibt es Hierarchien wie im Militär, aber auch in Unternehmen mit Team, Abteilungen, Standorten usw.
Diese Gruppen existieren oft nicht lange. Beispielsweise bei einem Training oder beim ersten Consulting-Termin müssen Trainer und Beraterinnen mit einer Gruppe zusammenarbeiten, die sie nie zuvor gesehen haben – und das funktioniert. Das ist sicher eine andere Gruppe, mit einer anderen Art von Beziehung als die eigene Familie, aber eine solche Gruppe hat auch andere Ziele.
Nun kann man argumentieren, dass unter anderem das Vertrauen erst mit der Zeit wächst. Aber auch Vertrauen kann schnell gebildet werden: Wird ein Patient ins Krankenhaus eingeliefert, wird er der behandelnden Ärzt:in im Extremfall sogar sein Leben anvertrauen, ohne die Person vorher jemals gesehen zu haben.
Sicher kann man Dunbars Forschung als Inspiration nutzen, um über Mechanismen für die Stärkung des Zusammenhalts von Gruppen nachzudenken. Dunbars These ist, dass Sprache nur entstanden ist, um sozialen Zusammenhalt zu stärken, und er präsentiert dazu Statistiken, wie viel Zeit mit dem Gespräch über soziale Beziehung und Gossip (Tratsch) verbracht wird. Maßnahmen zum Stärken des Zusammenhalts, beispielsweise durch ungezwungene Gespräche, können sinnvoll sein. Wo gibt es für ein Team ein solches Forum? Das müssen nicht erzwungene Team-Bondings sein, sondern ein regelmäßiges gemeinsames Mittagessen kann eine solche Funktion gut ausfüllen.
Die Dunbar-Zahl sagt nichts über die mögliche Größe von Teams oder Firmen aus. Sie können eine beliebige Größe haben und unterschiedlich strukturiert sein. Die Fehlinterpretation der Zahl deutet darauf hin, dass unsere Branche für Vereinfachungen anfällig ist, die der Intuition widersprechen. Teams benötigen einen Mechanismus, um einen sozialen Zusammenhalt herzustellen.
URL dieses Artikels:
https://www.heise.de/-9825599
Links in diesem Artikel:
[1] https://de.wikipedia.org/wiki/Dunbar-Zahl
[2] https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/abs/coevolution-of-neocortical-size-group-size-and-language-in-humans/4290FF4D7362511136B9A15A96E74FEF
[3] https://royalsocietypublishing.org/doi/10.1098/rsbl.2021.0158
[4] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Semisatch/Shutterstock.com)
Das Buch "Einführung in die moderne Assembler-Programmierung" von Scot W. Stevenson bietet eine solide Einführung in Assembler auf Basis der RISC-V-Architektur.
Endlich ist es so weit – heute stelle ich Ihnen ein Buch vor, auf das ich seit Monaten sehnsüchtig und gespannt gewartet habe. Das Thema des Buches ist für das Jahr 2024 allerdings ein wenig ungewöhnlich, denn es handelt sich um eine Einführung in die moderne Assembler-Programmierung. Vielleicht fragen Sie sich nun, warum Sie sich ausgerechnet mit Assembler beschäftigen sollten, doch dazu gleich mehr. Vor allem geht es mir in diesem Blogpost aber um die Frage, ob sich die Lektüre des Buches meiner Meinung nach lohnt. Legen wir los!
Das Buch heißt "Einführung in die moderne Assembler-Programmierung [1]" und trägt den Untertitel "RISC-V spielerisch und fundiert lernen". Geschrieben wurde es von Scot W. Stevenson und ist im Juli 2024 im dpunkt-Verlag [Anm. d. Red.: Ein Verlag der heise group] erschienen. Der Verlag war so freundlich, mir ein Rezensionsexemplar kostenlos zur Verfügung zu stellen. Es ist uns aber wichtig zu betonen, dass meine Meinung in diesem Blogpost nicht mit dem Verlag abgestimmt ist. Es handelt sich um meine persönliche und ehrliche Einschätzung, und ich erhalte keine Gegenleistung für die Rezension. Das ist uns wichtig offenzulegen, weil eine Rezensionen vertrauenswürdig sein sollte, und das nur dann gewährleistet ist, wenn ich frei sagen kann, was mir gefällt und was nicht. Das nur kurz vorab.
Bevor wir nun ins Buch einsteigen, vielleicht erst noch kurz die Frage: Warum sollte man sich im Jahr 2024 ausgerechnet mit Assembler-Programmierung beschäftigen? Gibt es da nichts Wichtigeres? Genau diese Frage stellt auch der Autor im Vorwort:
"Ein modernes Buch über Assembler-Programmierung, was soll das denn?"
Der Autor ist sich also bewusst, dass das Thema durchaus erklärungsbedürftig ist. Er schreibt, dass es zum einen diejenigen gebe, die im Studium dazu gezwungen würden, sich mit Assembler zu beschäftigen. Zum anderen gebe es aber auch diejenigen, die der Meinung seien, dass das Verständnis von Assembler zu einem besseren Verständnis für Computer an sich führen würde. Beides sind durchaus legitime Gründe, das Buch zu lesen, aber: Das Buch ist vor allem für eine dritte Zielgruppe geschrieben – nämlich für diejenigen, die Spaß daran haben, in die Interna abzutauchen und aus Neugier und Wissensdurst verstehen möchten, wie die Dinge unter der Haube funktionieren. Ich finde, das ist eine schöne und ehrliche Beschreibung, von der ich mich durchaus angesprochen fühle.
Nicht alles, was man lernt, muss meiner Meinung nach immer einen direkten Nutzen haben. Es macht zumindest mir auch sehr viel Spaß, mich mit gewissen Dingen um ihrer selbst willen zu beschäftigen, und Nullen und Einsen gehören für mich definitiv dazu. Insofern fördert das Buch vielleicht nicht direkt Ihre Karriere, aber es könnte Ihren intellektuellen Spieltrieb ansprechen und vielleicht sogar Ihren Horizont erweitern. Unabhängig davon glaube ich aber auch, dass ein gewisses Verständnis von Assembler dazu führt, die Maschine, mit der wir alle uns täglich beschäftigen, besser zu verstehen.
Ich selbst habe vor vielen Jahren einmal versucht, x86-Assembler zu lernen. Über ein paar Grundlagen verfüge ich daher, aber wirklich tief bin ich nie eingestiegen. Allerdings habe ich großen Respekt davor, wenn jemand Assembler wirklich beherrscht. Im März hatte ich in einem unserer Livestreams eine Entwicklerin zu Gast, die mit mir gemeinsam den Assembler-Quellcode des Computerspiels "Prince of Persia" analysiert hat [3]. Genauer gesagt, hat sie den Code analysiert und ich habe interessiert Fragen dazu gestellt. Das fand ich sehr spannend, und genau daran knüpft dieses Buch inhaltlich perfekt an. Mit anderen Worten: Falls Sie den Livestream gesehen haben und er Ihnen gefallen hat, dürfte auch das Buch Ihr Interesse wecken und Ihren Geschmack treffen.
Nun aber endlich zum Buch: Es hat etwas mehr als 250 Seiten (es ist also eher kompakt) und ist in 25 Kapitel gegliedert, die sich über fünf Teile erstrecken. Der erste Teil behandelt zunächst eine Reihe von Grundbegriffen und grundlegenden Konzepten: Wie funktionieren negative Zahlen im Binärsystem? Was ist ein Register? Was ist der Unterschied zwischen der CPU und der ALU? Was ist CISC, was ist RISC, was ist ein Opcode, was ein Mnemonic?
Auf den ersten rund 70 Seiten geht es also darum, eine gemeinsame Sprache und ein grundlegendes Verständnis für die Ebene zu schaffen, auf der man mit Assembler arbeitet, mit der man aber im Alltag nicht so oft in Berührung kommt. Vieles kannte ich von vor zig Jahren, trotzdem fand ich es spannend, es noch einmal zu lesen, weil es ein guter Überblick war. Schön herausgearbeitet wird, dass Assembler zwar prinzipiell überall ähnlich ist, die konkrete Umsetzung aber stark von der Prozessorarchitektur und dem zugehörigen Befehlssatz abhängt. Das Buch behandelt den offenen RISC-V-Standard, zeigt aber anhand von Beispielen auch, wie Dinge auf anderen Architekturen gelöst werden. Das vermittelt gut, dass man mit Assembler auf zwei Ebenen arbeitet, nämlich einer abstrakt-konzeptionellen Ebene sowie einer technisch-konkreten Ebene, die sich von Prozessor zu Prozessor unterscheidet.
Der zweite Teil startet anschließend mit einem Überblick über die einzelnen Module von RISC-V. Dabei geht es um die zur Verfügung stehenden Register, die Wortgröße, die Adressierungsarten und dann vor allem um den tatsächlichen Befehlssatz. Hier werden relativ zügig die diversen Befehle vorgestellt und erklärt, beginnend bei einfachen Aufgaben wie dem Laden und Speichern von Daten, über das Rechnen bis hin zu Vergleichen, Bedingungen und Schleifen. Auch Pseudo-Befehle und Spezialfälle werden angesprochen, sowie der interne Aufbau der Befehle. Dieser Teil geht also tief in die Materie hinein, und das ist zugleich eine Stärke und eine Schwäche des Buches: Einerseits erhält man nämlich einen kompletten Überblick über die RISC-V-Befehle, andererseits ist dieser Abschnitt eher eine Referenz als ein Lehrbuch. Man liest es, übt es aber nicht, was dazu führt, dass man später im Buch zurückblättern und ständig hin- und herspringen muss.
In Teil drei geht es dann um die Vertiefung des bis dahin Gelernten, indem man die Grundbausteine zu größeren Einheiten zusammenfügt. Natürlich könnte man dies auch auf naive Weise tun, aber es empfiehlt sich, hier von erfahreneren Entwicklerinnen und Entwicklern zu lernen. Dabei geht es um Themen wie:
Ein wenig schwierig fand ich in diesem Teil die gewählte Reihenfolge der Kapitel, die etwas willkürlich wirkt. Im Großen und Ganzen passt es aber trotzdem, denn es handelt sich letztlich ohnehin um ein Sammelsurium diverser Best Practices, die keine natürliche Reihenfolge aufweisen.
Damit sind dann auch schon 85 bis 90 Prozent des Buches gelesen, aber es gibt noch zwei weitere Teile: In Teil vier geht es um konkrete Projekte. Dieser Teil umfasst allerdings nur 25 Seiten für sage und schreibe zwei Projekte. Tatsächlich ist das für mich die größte Schwäche des Buches: Die Praxis kommt viel zu kurz. Für ein Buch mit dem Untertitel "RISC-V spielerisch und fundiert lernen" fehlt mir der spielerische Aspekt. Die ersten 225 Seiten erklären praktisch die Grammatik und Vokabeln einer neuen Fremdsprache, aber man kommt erst am Ende dazu, einen einfachen Satz zu sagen. Das finde ich schade, da hätte ich mir einen praxisorientierteren Aufbau gewünscht. Denn das Buch hat viel Potenzial, und ich finde, Assembler ist ein spannendes Thema, aber ich möchte es eben nicht nur theoretisch erlernen, sondern auch praktisch anwenden können.
Und damit wir uns hier nicht falsch verstehen: Das Buch ist nicht schlecht, aber als Lehrbuch eben nur bedingt geeignet. Es ist eher eine Referenz zum Nachschlagen, mit einem ausführlichen Teil über sauberes Programmieren in Assembler. Ich hatte nur eben aufgrund des Titels eher etwas anderes erwartet.
Teil fünf schließlich umfasst gerade einmal die letzten zehn Seiten. Es geht um typische Fehler, guten Stil und weiterführende Links. Insofern ist es kein echter fünfter Teil, sondern eher ein Anhang.
Was bleibt? Wer sich für Assembler interessiert, wissen will, wie ein Computer und insbesondere der Prozessor intern funktioniert, und wer sich nicht scheut, sich mit einem eher low-leveligen Thema auseinanderzusetzen, und außerdem viel eigenen Spieltrieb mitbringt, kann durchaus großen Spaß an dem Buch haben. Wer aus den genannten Gründen etwas mehr über Assembler lernen, aber lieber stärker an die Hand genommen werden möchte, findet in dem Buch vielleicht nicht ganz das Richtige. Nichtsdestotrotz ist es ein gutes Buch.
URL dieses Artikels:
https://www.heise.de/-9817184
Links in diesem Artikel:
[1] https://dpunkt.de/produkt/einfuehrung-in-die-moderne-assembler-programmierung/
[2] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[3] https://www.youtube.com/watch?v=hr5xQpznD0Y
[4] mailto:mai@heise.de
Copyright © 2024 Heise Medien

(Bild: rawf8/Shutterstock.com)
Die JSON-Bibliothek kann nun auch nicht öffentliche Mitglieder serialisieren und deserialisieren.
In System.Text.Json 8.0 kann man nun ein JsonNode-Objekt auch aus einem Stream erstellen:
JsonNode node = await JsonNode.ParseAsync(stream)Zudem hat die Klasse JsonNode neue Methoden wie DeepClone() und DeepEquals() erhalten:
JsonNode person = JsonNode.Parse
("{\"Experte\":{\"Name\":\"Dr. Holger Schwichtenberg\"}}");
JsonNode personClone = person.DeepClone();
bool same = JsonNode.DeepEquals(person, personClone); // true
Console.WriteLine(same);
Außerdem wird bei JsonArray nun die Schnittstelle IEnumerable angeboten, das Aufzählung mit foreach und Language Integrated Query (LINQ) ermöglicht:
JsonArray jsonArray = new JsonArray(40, 42, 43, 42);
IEnumerable<int> values =
jsonArray.GetValues<int>().Where(i => i == 42);
foreach (var v in values)
{
Console.WriteLine(v);
}
Im Namensraum System.Net.Http.Json gibt es nun eine Erweiterungsmethode GetFromJsonAsAsyncEnumerable<T>(URL), die eine Menge als IAsyncEnumerable<T> zur Iteration mit await foreach liefert.
In System.Text.Json 8.0 gibt es eine neue Annotation [JsonConverter], um einen eigenen Konverter zu registrieren. Ein Konverter ist eine Klasse, die von JsonConverter<T> erbt:
[JsonConverter(typeof(JsonStringEnumConverter<MyEnum>))]
public enum MyEnum { Value1, Value2, Value3 }
Weitere Informationen zu Konvertern finden sich auf der Learn-Plattform bei Microsoft [38].
URL dieses Artikels:
https://www.heise.de/-9821053
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[32] https://www.heise.de/blog/Neu-in-NET-8-0-32-Weitere-Neuerungen-in-System-Text-Json-8-0-9821053.html
[33] https://www.heise.de/blog/Neu-in-NET-8-0-33-Erweiterung-des-AOT-Compilers-9829857.html
[34] https://www.heise.de/blog/Neu-in-NET-8-0-34-Verbesserte-Ausgaben-beim-Kompilieren-9837144.html
[35] https://net.bettercode.eu/
[36] https://net.bettercode.eu/index.php#programm
[37] https://net.bettercode.eu/tickets.php
[38] https://learn.microsoft.com/de-de/dotnet/standard/serialization/system-text-json/converters-how-to
[39] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Yurchanka Siarhei / Shutterstock.com)
Die JSON-Bibliothek kann nun auch nicht öffentliche Mitglieder serialisieren und deserialisieren.
In System.Text.Json ermöglichen es die Annotationen [JsonInclude] und [JsonConstructor] seit Version 8.0, die Serialisierung nicht öffentlicher Klassenmitglieder zu erzwingen.
Für jedes nicht öffentliche Mitglied, das mit [JsonInclude] annotiert ist, muss im Konstruktor, der mit [JsonConstructor] annotiert ist, ein Parameter vorhanden sein, um den Wert während der Deserialisierung setzen zu können. Ein aussagekräftiges Beispiel dazu zeigt folgendes Listing:
public class Person
{
[JsonConstructor]
// ohne Annotation: 'Deserialization of types without a
// parameterless constructor, a singular parameterized
// constructor, or a parameterized constructor annotated with
// 'JsonConstructorAttribute' is not supported.
internal Person(int id, string name, string website)
{
ID = id;
Name = name;
Website = website;
}
[JsonInclude]
// ohne Annotation: 'Each parameter in the deserialization
// constructor on type 'FCL_JSON+Person' must bind to an
// object property or field on deserialization. Each parameter
// name must match with a property or field on the object.
// Fields are only considered when
// 'JsonSerializerOptions.IncludeFields' is enabled.
// The match can be case-insensitive.'
internal int ID { get; }
public string Name { get; set; }
[JsonInclude]
// ohne Annotation: 'Each parameter in the deserialization
// constructor on type 'FCL_JSON+Person' must bind to an object
// property or field on deserialization. Each parameter name must
// match with a property or field on the object. Fields are only
// considered when 'JsonSerializerOptions.IncludeFields' is
// enabled. The match can be case-insensitive.'
private string Website { get; set; }
public override string ToString()
{
return $"{this.ID}: {this.Name} ({this.Website})";
}
}
…
// Serialisierung
var p1 = new PersonWithoutParameterlessConstructor
(42, Dr. Holger Schwichtenberg", "www.dotnet-doktor.de");
string json4 = JsonSerializer.Serialize(p1);
Console.WriteLine(json4);
//{ "Name":"Dr. Holger Schwichtenberg","ID":42,"Website":"www.dotnet-doktor.de"}
// Deserialisierung
var p2 =
JsonSerializer.Deserialize<PersonWithoutParameterlessConstructor>(json4);
Console.WriteLine(p2);
//42: Dr.Holger Schwichtenberg (www.dotnet-doktor.de)
URL dieses Artikels:
https://www.heise.de/-9814260
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[32] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: LanKS/Shutterstock.com)
Agilität ist angetreten, produktiver Software zu entwickeln. Eine Studie zeigt aber mehr Fehlschläge. Das sagt mehr über unsere Branche aus als über Agilität.
Eine Studie [1] will zeigen, dass agile Softwareentwicklung angeblich eine 268 Prozent höhere Chance für Fehlschläge mit sich bringt. So ein massiver Nachteil muss eigentlich dazu führen, dass alle sofort aufhören, überhaupt irgendwelche Projekte agil durchzuführen.
Wie kommen die Zahlen zustande? Die Studie stellt zunächst fest, dass folgende Faktoren den Erfolg von Softwareentwicklungsprojekten verbessern:
Keinen erheblichen Einfluss hatte hingegen, ob Menschen an einem oder mehreren Projekten gleichzeitig arbeiten.
Die Studie definiert agile Entwicklung als Projekte, bei denen Folgendes gilt:
Zusammen führt das zu 268 Prozent mehr Fehlschlägen und 65 Prozent gescheiterten Projekten. Das Zahlenmaterial ist auch mit passenden statistischen Werten ausgestattet und wirkt daher überzeugend.
Das erste Problem der Studie ist die fehlende Definition von "Fehlschlag". Ein mögliches Kriterium wäre, dass die Projekte nicht im Budget geliefert wurden. Das ist aber ein eigentümliches Ziel für ein Individualsoftwareprojekt. Wenn man Software möglichst billig haben will, sollte man sie nicht selbst entwickeln, sondern Standardsoftware kaufen. Das ist sinnvoll für Bereiche, in denen man die Flexibilität einer eigenen Implementierung nicht benötigt. Mir wäre beispielsweise nicht klar, warum man eine Finanzbuchhaltung selbst implementieren würde.
Vielleicht sind mit höheren Kosten ein höherer Wert verbunden, weil mehr Features umgesetzt und so vielleicht sogar mehr Umsatz und Gewinn erzielt werden? Ist das Projekt dann ein Fehlschlag?
Eine weitere Möglichkeit, "Fehlschlag" zu definieren wäre, wenn der Auftraggeber am Ende des Projekts vom Ergebnis enttäuscht ist. Das ist vielleicht sinnvoll, aber kein rationales Kriterium. Kunden können aus den unterschiedlichsten Gründen enttäuscht werden. Unterschiedliche Stakeholder können unterschiedlich zufrieden mit dem Ergebnis sein.
Die Definition von "Fehlschlag" ist keine Frage ohne praktische Auswirkungen. Ich habe selbst in Projekten mitgearbeitet, die offiziell ein Erfolg waren, aber subjektiv erhebliche Probleme hatten oder vorab definierte Projektziele nicht erreicht haben. Es geht schlimmer: Einige Projekte haben gar keine echten Projektziele – wie soll man dann über einen Fehlschlag oder Erfolg entscheiden?
Eigentlich könnte man jetzt schon damit aufhören, die Studie genauer zu betrachten. Aber die Studie hat noch viele weitere Probleme.
Die Studie behauptet, dass es hilfreich ist, wenn Requirements vor dem Start des Projekts bekannt sind, die Spezifikation vollständig ist und signifikante Änderungen spät im Projekt unterbleiben. Ich muss gestehen: Mein Erstaunen darüber wie auch über die anderen Ergebnisse der Studie hält sich in engen Grenzen. Mehr Informationen am Anfang und weniger Änderungen im Verlauf des Projekts machen Projekten das Leben sicher einfacher. Man könnte so ein Projekt als langweilig bezeichnen. Aus der Sicht der Umsetzer ist das super, weil das Projekt eben mit höherer Wahrscheinlichkeit erfolgreich ist. Aus Sicht der Auftraggeber erscheint es aber unwahrscheinlich, dass ein solches Projekt einen hohen Wert hat. Wenn man etwa einen neuen Markt schneller als der Wettbewerb mit einem neuen digitalen Produkt besetzen will, sind vermutlich die Requirements nicht klar, die Spezifikation unvollständig und es werden sich auch spät im Projekt Änderungen ergeben, weil schlicht nicht klar ist, was die Kunden genau wollen und wie der Markt aussieht. Niemand kann das wissen. Die Kunden greifen erst zu, wenn ihnen das Projekt gefällt.
Genau in dem Fall kann Agilität ihre Stärken ausspielen. Ich glaube sofort, dass solche Projekte öfter von der ursprünglichen Planung abweichen und das kann man einen Fehlschlag nennen. Aber was ist die Konsequenz? Solche Projekte einfach nicht angehen und eine solche Markt-Chance nicht ergreifen? Maßnahmen ergreifen, um doch Stabilität vorzutäuschen, die dann aber das Projekt behindern?
Anders gesagt: Gerade die Projekte, die laut der Studie öfter fehlschlagen, sind vielleicht die Projekte, die einen besonders hohen Wert generieren.
Angeblich orientiert sich die Definition von Agilität aus der Studie am agilen Manifest. [2] Also sollte das agile Manifest irgendwo etwas enthalten im Sinne von: "Wenn am Anfang des Projekts Anforderungen klar sind, und eine vollständige Spezifikation vorliegt, lösche dieses Dokument und sorge dafür, dass sich niemand an die Anforderungen und die Spezifikation erinnert – sonst genügt das Projekt nicht diesem Manifest." Und ebenso müsste da irgendwo "Wenn sich im Projekt später keine signifikanten Änderungen ergeben, dann erfinde welche – sonst genügt das Projekt nicht diesem Manifest" stehen. Ich habe nachgeschaut: Das steht nicht im agilen Manifest und es gibt auch keinen Absatz, der sich so interpretieren ließe. Im Gegenteil: Das agile Manifest wägt Optionen wie das Befolgen eines Plans und das Reagieren auf Änderungen ab – und legt den Fokus auf eins, in dem Beispiel das Reagieren auf Änderungen, ohne dass die andere Option als unwichtig bewertet wird – nur eben als weniger wichtig. Auf eine Änderung zu reagieren erscheint tatsächlich sinnvoller, als an dem festen Plan festzuhalten, der die Änderung noch gar nicht betrachtet haben kann.
Die Studie basiert übrigens auf einer Umfrage unter 600 Software Engineers. Umfragen können immer nur das subjektive Bild der befragten Person abbilden – in diesem Fall also die der Software Engineers. Da eine Softwareentwicklung eine wirtschaftliche Investition ist, wäre es sinnvoll andere Gruppen, insbesondere unterschiedliche Stakeholder ebenfalls zu befragen. Schließlich geben sie die Projekte in Auftrag. Wer könnte also besser bewerten, ob das Projekt wirklich ein Fehlschlag ist.
Und die Studie lässt noch eine Frage unbeantwortet: Wie viele Projekte haben denn klare Requirements? 10 Prozent? 25 Prozent? 90 Prozent? Man kann aus der Studie nur entnehmen, dass es eine genügend große Anzahl sein muss, um statistisch signifikante Aussagen zu treffen. Wenn sehr viele Projekte unklare Requirements haben, wäre das ein Hinweis auf ein wichtiges Problem. Ob und wie man es lösen kann, ist dann die nächste Frage – und die ist nicht so einfach zu beantworten. Requirements kann man sich ja nicht einfach wünschen, sondern gegebenenfalls sind sie wie erwähnt prinzipienbedingt unklar.
Eigentlich ist die Studie keinen Blogpost wert. Sie ist ein durchsichtiges Manöver, um agile Softwareentwicklung zu diskreditieren und einen anderen Ansatz zu promoten. Aber die Studie hat dennoch Einfluss – mir sind in zwei unterschiedlichen Kontexten Hinweise auf die Studie untergekommen. Das ist nachvollziehbar: 268 Prozent ist eine krasse Zahl und das Ergebnis ist überraschend, weil Agilität ja eigentlich mehr Erfolg erreichen sollte. Da muss man einfach hineinschauen! Wenn man das wirklich tut, wird schnell klar, was für ein Unsinn da steht. Ein YouTube-Video [3] hat die Zahl genutzt, um andere Aspekte von Agilität zu kritisieren, also nicht die Probleme mit Requirements, die die Studie erläutert. Unabhängig davon, ob die Kritik berechtigt ist: Das Video nutzt die absurde Zahl aus der Studie, um Aufmerksamkeit zu generieren.
Wenn wir in unserer Branche so vorgehen, dürfen wir uns nicht wundern, wenn wir nicht lernen, was wirklich hilft und so kein Fortschritt erzielt wird. Dabei wird die kritische Arbeit mit Quellen schon in der Schule gelehrt.
Ob Agilität nun "gut" oder "schlecht" ist, können wir mit der Studie nicht beantworten. Aber: Dass wir Software in Iterationen erstellen müssen, hat sich in der Praxis historisch sehr früh gezeigt – im Prinzip als Menschen angefangen haben, Software in Teams zu entwickeln. Und zwar auch, wenn man anders als in agilen Projekten relativ stabile Anforderungen hat. Das wird klar, wenn man Pionieren und Pionierinnen wie Prof. Christiane Floyd zuhört [4]. Zu dem Thema habe ich auch einen Vortrag [5] gehalten. Dass es Projekte gibt, die gut daran tun, beispielsweise auf Änderungen zu reagieren, statt einem Plan zu folgen, sollte auch klar sein. Das wirkliche Problem ist vielleicht, dass Agilität als Begriff mittlerweile verbrannt ist, weil in der Realität "agile" Prozesse eingeführt werden, die nicht den ursprünglichen Ideen entsprechen und auch nicht sonderlich hilfreich sind.
Unsere Branche ist anfällig für tendenziöse Studien. Das ist schade. Krasse Behauptungen erzeugen Aufmerksamkeit.
URL dieses Artikels:
https://www.heise.de/-9810522
Links in diesem Artikel:
[1] https://www.engprax.com/post/268-higher-failure-rates-for-agile-software-projects-study-finds
[2] https://agilemanifesto.org/iso/de/manifesto.html
[3] https://www.youtube.com/watch?v=gSVBWvoNJ-s
[4] https://software-architektur.tv/2021/07/09/folge66.html
[5] https://software-architektur.tv/2024/04/02/folge211.html
[6] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Alexander Lukatskiy/Shutterstock.com)
System.Text.Json beherrscht nun Half, Int128, UInt128, Memory
System.Text.Json kann seit Version 8.0 neuere Zahlentypen wie Half, Int128 und UInt128 sowie die Speichertypen Memory<T> und ReadOnlyMemory<T> serialisieren.
Bei Letzteren entstehen, wenn es sich um Memory<Byte> und ReadOnlyMemory<Byte> handelt, Base64-kodierte Zeichenketten. Andere Datentypen werden als JSON-Arrays serialisiert.
Beispiel 1:
JsonSerializer.Serialize<ReadOnlyMemory<byte>>
(new byte[] { 42, 43, 44 });wird zu "Kiss"
Beispiel 2:
JsonSerializer.Serialize<Memory<Int128>>
(new Int128[] { 42, 43, 44 });wird zu [42,43,44]
Beispiel 3:
JsonSerializer.Serialize<Memory<string>>
(new string[] { "42", "43", "44" });wird zu ["42","43","44"]
URL dieses Artikels:
https://www.heise.de/-9808793
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[32] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Dilok Klaisataporn/Shutterstock.com)
Microservices sind die perfekte Lösung für gewisse Probleme. Doch unpassend eingesetzt, können sie das ganze Projekt ruinieren. Worauf gilt es zu achten?
Vor ungefähr einer Woche habe ich einen Blogpost geschrieben, zu dem ich viel Feedback erhalten habe: "12 Regeln für die perfekte (Micro-)Service-Architektur [1]". Darin habe ich zwölf Regeln vorgestellt, die sich für uns bei der the native web GmbH [2] in den vergangenen Jahren für die Konzeption, den Entwurf und die Entwicklung von Microservices bewährt haben. Sehr deutlich habe ich außerdem gesagt: "Your mileage may vary", also auf gut Deutsch: Die Tatsache, dass sich diese Regeln für uns bewährt haben, bedeutet noch lange nicht, dass sie auf Sie, Ihr Team und Ihre Anforderungen 1:1 übertragbar seien.
Des Weiteren habe ich auch nicht behauptet, dass Microservices der einzig wahre Architekturansatz seien. Aber ich gehe in einem Blogpost über die Architektur von Microservices natürlich davon aus, dass der Text primär von Menschen gelesen wird, die mit der Konzeption, dem Entwurf und der Entwicklung von Microservices zu tun haben – oder die sich zumindest zukünftig dafür interessieren werden.
Daher war ich überrascht, dass rund die Hälfte der Kommentare – sei es hier auf heise Developer, auf YouTube, per E-Mail oder im persönlichen Gespräch – den Einsatz von Microservices an sich infrage gestellt hat, sinngemäß: Ja, das könne man schon alles so machen, aber als Allererstes solle man doch gründlich hinterfragen, ob Microservices an sich eine gute Idee seien oder nicht. Überrascht war ich deshalb, weil ich es zum einen für selbstverständlich halte, dass man ein Architekturprinzip im Vorfeld auf Eignung prüft, und ebendiese Frage zum anderen gar nicht das Thema des Blogposts war.
Anscheinend besteht eine Notwendigkeit, vor dem Einsatz von Microservices zu warnen, denn damit habe man "schon schlechte Erfahrungen gemacht". Dass das gleiche auch für andere Architekturansätze wie Monolithen, Client-Server oder Peer-to-Peer gilt, fällt dabei gerne unter den Tisch. Interessant finde ich, dass ich diese Reaktion sehr häufig auf die Erwähnung von Microservices erlebe. Ich mag auch gar nicht abstreiten, dass nicht die eine oder der andere tatsächlich schon schlechte Erfahrungen mit Microservices gemacht hat – mich wundert nur, dass stets nur bei Microservices so vehement darauf hingewiesen wird.
Deshalb habe ich mir überlegt, dass es vielleicht sinnvoll sein könnte, einmal die Frage zu stellen, wann Microservices eine gute und wann sie eine schlechte Idee sind. Mit anderen Worten: Über welche Aspekte lohnt es sich nachzudenken, bevor man auf Microservices setzt, damit ein Projekt nachher nicht tatsächlich in einem Fiasko endet?
Und übrigens, bevor nun jemand argumentiert, dass selbst Amazon inzwischen auf Microservices verzichten würde [4]: Zu diesem Gerücht habe ich mich vor geraumer Zeit bereits geäußert. Also falls Sie dieses Argument hätten anbringen wollen, dann schauen Sie sich bitte vorab das Video "Microservices sind doof – sagt Amazon?! [5]" an.
Kommen wir nun zum ersten häufig genannten Argument gegen Microservices, nämlich der deutlich höheren Komplexität der Architektur. Per Definition sind Microservices eine verteilte Architektur, es handelt sich also bei einer Service-basierten Anwendung um ein verteiltes System. Der US-amerikanische Informatiker Andrew S. Tanenbaum [6] hat ein solches System wie folgt definiert [7]:
"Ein verteiltes System ist ein Zusammenschluss unabhängiger Computer, die sich für den Benutzer als ein einziges System präsentieren."
Tatsächlich gibt es von dieser Definition auch noch eine humoristische Abwandlung, und zwar:
"Ein verteiltes System ist ein System, das nicht das macht, was es soll, weil ein Computer ausgefallen ist, von dem Sie weder wussten, dass er existiert noch, dass er für irgendetwas wichtig ist."
Doch Spaß beiseite: Es liegt auf der Hand, dass verteilte Systeme in technischer Hinsicht komplexer sind als nicht-verteilte Systeme. Das hängt vor allem mit Problemen rund um die Kommunikation zwischen den einzelnen beteiligten Parteien zusammen, also mit Themen wie Konsistenz, Synchronisation, Verfügbarkeit und so weiter.
In diesen Zusammenhang fällt dann auch das sogenannte CAP-Theorem [8], das (vereinfacht ausgedrückt) besagt: Wenn in einem verteilten System ein Netzwerkausfall stattfindet und dadurch eine Partitionierung entsteht (das entspricht dem "P"), dann kann man sich aussuchen, ob man entweder die Konsistenz (also das "C") oder die Verfügbarkeit (also das "A", das hier für "Availability" steht) bewahren möchte. Beides zusammen ist nicht möglich.
Das bedeutet, dass man sich bei verteilten Systemen deutlich mehr Gedanken machen muss, wie man mit Konsistenz und Verfügbarkeit umgeht, was wiederum einiges an Wissen und Erfahrung erfordert. Vor allem benötigt man für ein verteiltes System jedoch eines, nämlich einen guten Grund, warum man ein System überhaupt als verteiltes System entwerfen möchte. Man sollte es nicht deshalb machen, weil es "interessant wirkt" oder "cool klingt".
Der vermutlich primäre Grund, ein System als verteiltes System gestalten zu wollen, ist (und das steckt sogar schon in der Definition von Andrew S. Tanenbaum), dass man eine hohe Unabhängigkeit zwischen den einzelnen Teilen anstrebt, und zwar in technischer, organisatorischer und vor allem auch in fachlicher Hinsicht. Darüber hinaus wird gerne noch genannt, dass man eine Technologie nicht systemrelevant werden lassen möchte, dass man mit Microservices eine höhere Flexibilität und eine bessere Anpassbarkeit bekäme, dass man ein verteiltes System gezielter skalieren könne und so weiter – aber die Unabhängigkeit, ist die eigentlich treibende Kraft hinter verteilten Systemen. Und wenn der Bedarf daran nicht gegeben ist, dann eignet sich ein stärker zentralisierter Ansatz höchstwahrscheinlich deutlich mehr.
Daher muss man sich die Frage stellen: Benötigt man technische, organisatorische und vor allem fachliche Unabhängigkeit?
Kommen wir zum zweiten häufig genannten Argument gegen Microservices, nämlich dem Deployment und der Infrastruktur. Klar ist, dass Microservices komplexere Deployments nach sich ziehen, und zwar nicht zuletzt deshalb, weil schlichtweg mehr zu deployen ist. Natürlich ist das XCOPY-Deployment [9] eines einfachen Monolithen, der auf einem einzigen Server mit einer einzigen Instanz läuft, bedeutend einfacher.
Allerdings funktioniert das Deployment von Microservices eigentlich immer sehr ähnlich, und zwar vollkommen unabhängig davon, um welche Anwendung es sich dabei handelt. Das bedeutet, dass man das Know-how dafür problemlos "fertig von der Stange" einkaufen kann. Weder muss man hierbei viel experimentieren noch muss man viel herausfinden – es braucht lediglich jemanden, die oder der das schon einmal gemacht hat und die oder der sich mit den entsprechenden Technologien auskennt. Also, allen voran: Container, Docker und Kubernetes.
Mich persönlich überzeugt dieses Argument nicht so richtig, denn ja, die Komplexität ist zwar höher, aber nicht nennenswert höher – und dafür bekomme ich im Umkehrschluss eine viel niedrigere Komplexität in der Fachlichkeit der einzelnen Services. Das heißt, jeder einzelne Service wird einfacher zu entwickeln, weil er deutlich kleiner und überschaubarer ist. Und da gerade das der Punkt ist, den ich nicht von der Stange kaufen kann, ist die Ersparnis hier viel mehr wert als das, was ich beim Deployment potenziell an zusätzlichen Kosten habe. Denn ja, einerseits wird eine einfache, standardisierte und immer gleiche Aufgabe etwas komplexer, doch dafür erhält man eine viel niedrigere Komplexität bei den Dingen, die ohnehin schwierig, anspruchsvoll, zeitaufwendig und individuell sind. Und das klingt für mich persönlich eigentlich nach einem ziemlich guten Handel.
Diese Gegen-Argumentation basiert natürlich auf der Annahme, dass man mit Containerisierung, Docker, Kubernetes & Co. halbwegs vertraut ist. Wer heute immer noch von Hand mit Shell-Skripten auf Bare-Metal unterwegs ist, der wird Schwierigkeiten mit dem effizienten Deployment von Microservices haben. Allerdings zeigt die Erfahrung, dass das auch für alle anderen Arten von Deployments gilt. Falls Containerisierung & Co. für Sie und Ihr Team tatsächlich noch Neuland sein sollten, dann ist das etwas, was Sie schleunigst ändern sollten – zumindest, wenn Sie im Bereich Web und Cloud tätig sind. Als Einstieg kann ich Ihnen unseren kostenlosen Docker Deep-Dive [10] empfehlen, zu dem es auch noch einige Fortsetzungen und einen gesonderten Deep-Dive zu Kubernetes [11] gibt.
Kommen wir zum dritten häufig genannten Argument gegen Microservices, nämlich zu den Herausforderungen im Bereich Konsistenz und Transaktionsmanagement. Ich hatte bereits kurz das CAP-Theorem angesprochen, und in verteilten Systemen steht hier das "A" (Verfügbarkeit) häufig weit über dem "C" (Konsistenz). Das ist deshalb so, weil die kontinuierliche und dauerhafte Lauffähigkeit des Gesamtsystems deutlich wichtiger ist, als die punktuell garantierte strenge Konsistenz.
Und das heißt übrigens nicht, dass verteilte Systeme nicht konsistent seien. Es heißt nur, dass sie nicht Strong-Consistent sind, sondern Eventual-Consistent. Mit anderen Worten: Es dauert manchmal einen kleinen Augenblick, bis die Konsistenz über mehrere Services hinweg tatsächlich hergestellt ist.
Dieser Punkt sorgt häufig für Aufregung, weil es dann rasch heißt, es ginge nicht ohne Strong-Consistency und so weiter. Und das stimmt auch – zumindest in einigen, ganz wenigen, gut begründeten Ausnahmefällen. In den meisten typischen Business-Anwendungen ist Eventual-Consistency hingegen vollkommen ausreichend. Und anders, als viele Entwicklerinnen und Entwickler häufig glauben, handelt es sich dabei nicht um ein technisches Problem oder eine technische Herausforderung. Stattdessen ist es eine Frage des Risikos und der Wahrscheinlichkeit, um die sich das Business kümmern muss.
Ein Beispiel: Falls es an einer Hochschule wegen Eventual-Consistency dazu kommen kann, dass der letzte Platz in einem Seminar doppelt vergeben wird, muss man sich die Frage stellen, wie schlimm das ist. Und diese Frage ist, wie zuvor erwähnt, nicht technischer, sondern ausschließlich fachlicher Natur. Um sie adäquat beantworten zu können, muss man zunächst wissen, wie häufig der Fall eintreten kann und was dann die Konsequenzen sind. Auf andere Art formuliert: Wie hoch ist das Risiko im Verhältnis zur Wahrscheinlichkeit und was geht im schlimmsten Fall schief? Wenn die Antwort darauf ist, dass einmal in fünf Jahren eine Person mehr im Seminar sitzen könnte, dann ist das – ehrlich gesagt – völlig in Ordnung.
Selbstverständlich möchte ich damit nicht sagen, dass es nicht Bereiche oder Themen gäbe, wo Strong-Consistency zwingend erforderlich ist. Ich sage nur, dass es in vielen typischen Web- und Cloud-Anwendungen völlig in Ordnung ist, wenn es "nur" Eventual-Consistent ist. Und das wiederum kann ich aus jahrelanger Erfahrung in der Konzeption, im Entwurf und in der Entwicklung von Microservices bestätigen: Strong-Consistency wird in 95 % der Fälle massiv überschätzt. Die Wahrheit ist, dass in nahezu allen Fällen Eventual-Consistency gänzlich ausreichend und gut genug ist. Insofern kommt es bei diesem Argument letztlich darauf an, ob man einen dieser wenigen begründeten Ausnahmefälle hat oder nicht. Pauschal betrachtet, sind Konsistenz und Transaktionalität kein Argument gegen Microservices.
Kommen wir zum fünften Argument gegen Microservices, nämlich den angeblich höheren Entwicklungs- und Betriebskosten. Häufig wird behauptet, Microservices seien ein Problem, weil ein einzelnes Team mit den zahlreichen Services zu viele Kontextwechsel hätte. Und wissen Sie was? Da bin ich ganz bei Ihnen! Es hat allerdings auch niemand gefordert, dass Sie Microservices mit einem einzigen Team umsetzen sollen.
Im Gegenteil! Eigentlich ist das Konzept der Microservices, bei dem es, wie anfangs erwähnt, um Unabhängigkeit geht, nämlich prädestiniert dafür, dass man mit unterschiedlichen Teams parallel an den verschiedenen Services arbeiten kann. Das heißt natürlich nicht, dass sich Microservices nur dann umsetzen lassen, wenn pro Service ein dediziertes Team bereitsteht. Aber es gibt ja noch etwas zwischen den Extremen. Meiner Meinung nach ist es überhaupt kein Problem, wenn ein Team eine Handvoll Services betreut (je nachdem, wie komplex und umfangreich die Services sind).
Wenn Sie aber an dem Punkt sind, wo ein einzelnes Team 20 oder gar 50 Services betreuen müsste, dann sind entweder die Services falsch geschnitten, Ihr Team ist falsch aufgestellt oder Sie haben schlicht und ergreifend zu wenige Teams. Daher sind Microservices primär dann sinnvoll, wenn es um das fachliche Zerlegen geht, wenn es um Unabhängigkeit geht, und wenn diese Unabhängigkeit sich auch in den Organisationsstrukturen widerspiegelt. Ansonsten wird es vermutlich eher schwierig werden. Wenn man aber mehrere Teams hat, dann sind Microservices ein sehr praktischer Ansatz, weil sie es dann nämlich erlauben, den Fokus auf nur einen Teil der Domäne legen zu müssen, und weil sie klare und explizite Schnittstellen erzwingen.
Und was die Betriebskosten angeht: Hier wird oft mit Monitoring, Logging, Alerting und so weiter argumentiert. Aber mal ganz ehrlich: Das brauchen Sie doch für einen Monolithen genauso? Und wo ist jetzt der große Unterschied, ob man nun 2 oder 20 oder 200 Container überwachen muss? Tatsächlich verstehe ich hier den Punkt nicht, denn der Aufwand steigt nicht linear mit der Anzahl der Container, sondern den größten Aufwand hat man damit, das ganze Monitoring & Co. an sich überhaupt einmal einzurichten und aufzusetzen. Wenn das jedoch einmal erledigt ist, stellt der Rest eher das i-Tüpfelchen dar, was den Aufwand angeht.
Und damit kommen wir zum fünften häufig genannten Argument gegen Microservices, nämlich den organisatorischen Herausforderungen. Hier wird in der Regel die zusätzlich notwendige Koordination und Kommunikation zwischen den Teams beklagt. Dabei geht es um Fragen wie:
Um diese Fragen zu klären, gibt es zahlreiche etablierte API-Patterns [12]. Tatsächlich finde ich von allen genannten Argumenten dieses das mit Abstand schwächste, denn Microservices schneidet man ja nicht irgendwie, sondern entlang fachlicher Grenzen. Und dieses Schneiden entlang fachlicher Grenzen muss ohnehin gemacht werden, auch wenn man einen Monolithen baut, denn auch bei Modulen und Komponenten muss überlegt werden, wie und wo geschnitten wird.
Würde man das einfach nicht machen, bekäme man sehr schnell den berühmt-berüchtigten "Big Ball of Mud". Das heißt, wenn dieses Schneiden ohnehin erforderlich ist und wenn man sich dazu ohnehin Gedanken machen muss über Zuständig- und Verantwortlichkeiten, dann ist auch der Aufwand in jedem Fall der gleiche. Daran ändert sich nichts, ob diese Diskussionen nun innerhalb eines einzelnen Teams oder über mehrere Teams hinweg verteilt stattfinden. Der große Vorteil von Microservices ist dann, dass sie die Teams dazu zwingen, diese Diskussionen ordentlich und sorgfältig zu führen, ganz einfach deshalb, weil eine fachliche Grenze zugleich auch eine echte technische Grenze darstellt, die sich nicht ignorieren lässt.
Es ergeben sich also folgende fünf Aspekte:
Services und insbesondere Microservices lohnen sich als Architekturansatz dann, wenn man fachlich gesehen sehr komplexe Anwendungen baut und/oder wenn man mehrere Teams hat, die an einem großen Projekt zusammenarbeiten müssen, man sich dabei jedoch eine gewisse Unabhängigkeit bewahren möchte. Und wenn das gegeben ist, dann sind Microservices höchstwahrscheinlich eine gute Idee, andernfalls wahrscheinlich eher nicht oder nur bedingt.
Und jetzt mal ganz ehrlich: Ist diese Erkenntnis wirklich eine Überraschung? Ich glaube nicht … stattdessen gilt wieder einmal, dass man das richtige Werkzeug für das vorliegende Problem auswählen sollte, und man deshalb einen gewissen Überblick über die zur Verfügung stehenden Werkzeuge haben sollte. Wer hingegen nur einen Hammer kennt, für die oder den wird jedes Problem wie ein Nagel aussehen.
URL dieses Artikels:
https://www.heise.de/-9800271
Links in diesem Artikel:
[1] https://www.heise.de/blog/Zwoelf-Regeln-fuer-die-perfekte-Micro-Services-Architektur-9792599.html
[2] https://www.thenativeweb.io/
[3] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[4] https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
[5] https://www.youtube.com/watch?v=IDTCPI3phss
[6] https://de.wikipedia.org/wiki/Andrew_S._Tanenbaum
[7] https://de.wikipedia.org/wiki/Verteiltes_System
[8] https://www.youtube.com/watch?v=aApAZMfp4Nw
[9] https://www.youtube.com/watch?v=AFRsix3jHXU
[10] https://www.youtube.com/watch?v=DESdVoKhIxY
[11] https://www.youtube.com/watch?v=1SaPfm96lY4
[12] https://www.youtube.com/watch?v=n47RSfeFIy8
[13] mailto:who@heise.de
Copyright © 2024 Heise Medien

(Bild: RossEdwardCairney/Shutterstock.com)
Der Source Generator ist in .NET 8.0 wichtiger, damit die JSON-Serialisierung und -Deserialisierung auch AOT-Anwendungen funktioniert.
System.Text.Json nimmt im Standard das Mapping von JSON auf .NET-Objekte per Laufzeitcodegenerierung vor. Schon seit der Version 6.0 gibt es in System.Text.Json auch einen Source-Generator. Dieser erzeugt den Mapping-Code bereits zur Entwicklungszeit, sodass keine Laufzeitcodegenerierung notwendig ist. Der JSON-Source-Generator war (und ist) ein wichtiges Instrument für die Leistungsoptimierung.
Mit Ausdehnung des Native-AOT-Compilers auf ASP.NET Core Web APIs ist er aber nochmals wichtiger geworden, denn bei Native AOT ist keine Laufzeitkompilierung möglich.
Der JSON-Source-Generator bietet in System.Text.Json Version 8.0 folgende neuen Möglichkeiten:
Text.Json.SourceGeneration.JsonSourceGenerator) unterstützt nun auch die in C# 9.0 eingeführten Init-Only-Properties und die in C# 11.0 eingeführten Required Properties.System.Text.Json gar keine Laufzeitcodegenerierung mehr ausführt: <JsonSerializerIsReflectionEnabledByDefault>false</JsonSerializerIsReflectionEnabledByDefault>IsReflectionEnabledByDefaultSystem.Text.Json 8.0 gehört auch, dass die Annotation [JsonSourceGenerationOptions] nun alle Optionen bietet, die auch die Klasse JsonSerializerOptions beim imperativen Programmieren mit der Klasse Text.Json. JsonSerializer erlaubt.Wenn die Laufzeitcodegenerierung im JSON-Serializer abgeschaltet ist, man aber dennoch eine Serialisierung ohne Source Generator versucht (etwa JsonSerializer.Serialize(new { value = 42 });), kassiert man folgende Fehlermeldung: "Reflection-based serialization has been disabled for this application. Either use the source generator APIs or explicitly configure the 'JsonSerializerOptions.TypeInfoResolver' property."
Wenn die Laufzeitcodegenerierung im JSON-Serializer abgeschaltet ist, muss man eine von JsonSerializerContext abgeleitete Klasse erschaffen, die per Annotation [JsonSerializable] die Verweise auf die zu (de)serialisierenden .NET-Klassen erhält. Optional kann man die Einstellung per [JsonSourceGenerationOptions] vornehmen.
Die im folgenden Code verwendeten Klassen Consultant und Person waren bereits im Beispielcode zum vorherigen Teil der Serie [35]:
[JsonSerializable(typeof(Address))]
[JsonSerializable(typeof(Person))]
[JsonSerializable(typeof(Consultant))]
[JsonSourceGenerationOptions(PreferredObjectCreationHandling
=JsonObjectCreationHandling.Populate)]
internal partial class PersonJsonContext : JsonSerializerContext
{
}
Diese Klasse muss man dann in den Serialisierungsoptionen festlegen:
var options = new JsonSerializerOptions
{
TypeInfoResolver = PersonJsonContext.Default
};
Das folgende Listing zeigt, dass in System.Text.Json nun ein erforderliches Mitglied, das beim Deserialisieren nicht befüllt wird, auch bei JSON-Source-Generator zum Laufzeitfehler führt.
try
{
var jsonString = """
{"FULL-NAME":"Holger Schwichtenberg","PERSONAL-WEBSITE":"www.dotnet-doktor.de"}
""";
Console.WriteLine("JSON: " + jsonString);
var obj = JsonSerializer.Deserialize<Consultant>(jsonString, options);
if (obj != null) CUI.Success(obj.ToString());
}
catch (Exception ex)
{
CUI.PrintError(ex.Message); // JSON deserialization for type 'NET8Konsole.Consultant' was missing required properties, including the following: ID !!! Vor .NET 8.0 wäre hier in Verbindung mit Source Generator KEIN Laufzeitfehler aufgetreten. ID war = 0
}
URL dieses Artikels:
https://www.heise.de/-9798297
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-31-Erweiterte-Serialisierung-in-System-Text-Json-8-0-9814260.html
[32] https://net.bettercode.eu/
[33] https://net.bettercode.eu/index.php#programm
[34] https://net.bettercode.eu/tickets.php
[35] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[36] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Shutterstock.com/Kenishirotie)
Services versprechen eine einfache, zielgerichtetete und fachlich adäquate Softwareentwicklung. Doch worauf sollte man bei ihrem Bau achten?
Häufig wird Entwicklerinnen und Entwicklern empfohlen, auf Services als Architektur zu setzen. Doch ist es gar nicht so einfach, Services derart zu bauen, dass sie nachher gleichermaßen schlank und skalierbar sind. Kommen dann Zweifel am eigenen Vorgehen hinzu, wird die Beschäftigung mit Services schnell zum Bremsklotz. Vor vielen Jahren gab es von Heroku für Cloud-Native-Anwendungen die Empfehlung der 12-Factor-Apps [1]: zwölf Regeln, die sich – laut Heroku – als tragfähige Basis erwiesen haben. Doch teilweise sind diese Regeln in die Jahre gekommen, außerdem wurden sie nie explizit für Services gemacht.
Was liegt also näher, als das Ganze aufzugreifen, mit der eigenen Erfahrung der vergangenen Jahre im Bereich der Konzeption und Entwicklung von Web- und Cloud-Services zu kombinieren, und zwölf aktualisierte Regeln aufzustellen? Genau das versuche ich in diesem Blogpost.
Eines sage ich jedoch direkt vorneweg: Die Auswahl der Regeln ist natürlich (wie auch damals bei Heroku) subjektiv und gefärbt. Das, was für uns bei der the native web GmbH [2] gut funktioniert, muss nicht für alle gut funktionieren. Wie es im Englischen so schön heißt: Your mileage may vary (YMMV) [3].
Die erste Regel wird vermutlich häufig belächelt, dennoch halte ich sie für die wichtigste schlechthin. Und auch, wenn viele sagen werden "das ist doch logisch, das braucht man doch nicht extra zu erwähnen", zeigt mir die Praxis, dass sie in 99 von 100 Fällen ignoriert wird. Die erste Regel lautet nämlich: Vor dem Entwickeln muss klar sein, was das fachliche Problem ist, das der Anwendung zugrunde liegt. Wer das nicht beantworten kann, wird nicht in der Lage sein, eine zielgerichtete und fachlich adäquate Lösung zu entwickeln, und zwar völlig unabhängig von der eingesetzten Technologie.
Daher: Man sollte als allererstes ein robustes, fundiertes und detailliertes fachliches Verständnis der entsprechenden Domäne aufbauen. Es ist dabei völlig zweitrangig, ob man dafür Domain-Driven Design (DDD) oder sonst irgendeine Methodik verwendet, aber man muss gedanklich von CRUD (Create, Read, Update, Delete) wegkommen, ansonsten baut man bestenfalls "Forms over Data", trifft aber nicht den eigentlichen Kern der Sache. CRUD ist ein Anti-Pattern [5], das es zu vermeiden gilt.
Die zweite Regel besagt, dass ein Service stets genau einem Betriebssystemprozess entspricht. Mit anderen Worten: Ein einzelner Service besteht nicht aus zig unterschiedlichen Programmen, sondern ein Service besteht aus einer Codebase für einen Prozess in einem Git-Repository. Wenn von diesem Service mehrere Instanzen gestartet werden sollen, dann laufen natürlich mehrere Prozesse, aber pro Instanz gibt es jeweils nur genau einen Betriebssystemprozess.
Das heißt auch, dass man nicht mehrere Services in einem gemeinsamen Git-Repository unterbringt, sondern dass jeder Service über ein eigenes Repository verfügt. Der Grund dafür ist einfach: Nur auf dem Weg ist sichergestellt, dass jeder Service unabhängig gepflegt, versioniert, dokumentiert, deployed, … werden kann. Außerdem ermöglicht das Zuordnen von Services zu Repositories ein feingranulares Verwalten der Berechtigungen auf den Code der jeweiligen Services.
Die dritte Regel fordert, dass es für das Bauen eines Services ein Skript gibt, das überall lauffähig ist. Die Technologie ist dabei völlig zweitrangig, theoretisch genügt ein einfaches Makefile. Der springende Punkt ist: Um vom Quellcode zum ausführbaren Binary zu kommen, darf nicht mehr Aufwand erforderlich sein, als einen einzigen Befehl auszuführen. Dieser Befehl kompiliert und linkt dabei nicht nur, sondern führt auch die Tests aus, die Codeanalyse und alles Weitere, was um den Build herum noch existiert.
Wichtig ist, dass dieses Skript in identischer Form auf jedem Rechner im Team lauffähig ist, das heißt, jede Entwicklerin und jeder Entwickler im Team kann eigenständig lokal bauen, und das identische Skript wird auch im Build-Schritt der CI/CD-Pipeline verwendet. Das Skript muss (abgesehen vom Einrichten gegebenenfalls erforderlicher Berechtigungen) erfolgreich ausführbar sein, nachdem man das Repository geklont und die Abhängigkeiten installiert hat. Alles, was darüber hinausgeht, ist unnötiger manueller Aufwand.
Was in den Build mit hineinspielt, ist die vierte Regel, die sich mit einer passenden Branching-Strategie beschäftigt: Konkret sieht diese Strategie so aus, dass es einen main-Branch gibt, der per definitionem als stabil angesehen wird. Jegliche Entwicklung, sei es das Hinzufügen neuer Features, das Beheben von Bugs oder sonst etwas, passiert in gesonderten Branches, die von main abzweigen und nachher wieder nach main gemerged werden (das entspricht dem klassischen Ansatz von Feature-Branches).
Der einzige Weg, einen solchen Merge nach main durchzuführen, ist per Pull Request, bei dem auch wieder sämtliche Tests, Codeanalyse & Co. laufen. Außerdem muss jeder Pull Request, bevor er nach main gemerged werden kann, gründlich gereviewed werden. Außer dem stabilen Produktions-Branch main gibt es ansonsten also ausschließlich kurzlebige Branches, die sich um main herum ranken. Und jedes Mal, wenn ein Branch nach main gemerged wird, wird dieser gesquashed, und auf der neuen Basis von main ein neues Release des Services mithilfe von Semantic Versioning [6] gebaut.
Die fünfte Regel besagt, dass jeder durch einen Pull Request erzeugte Commit auf main nicht nur eine neue Version erzeugt, sondern auch ein neues Docker-Image, das ebenfalls versioniert ist. Auf dem Weg lässt sich jeder x-beliebige Stand des Services jederzeit im Nachhinein anhand seiner Versionsnummer entweder als Binary oder als komplettes Docker-Image herunterladen und ausführen.
Wichtig dabei ist, dass der Service zügig startet, weshalb auch im Docker-Image nicht mehr gebaut werden darf. Stattdessen muss das alles bereits vorher erfolgt sein. Hier bieten sich Multi-Stage-Builds [7] an, um das finale Produktiv-Image möglichst sauber und klein zu halten. Da Container damit rechnen müssen, jederzeit abgeschossen zu werden, darf es keine speziellen Anforderungen an einen Graceful-Shutdown des Dienstes geben.
Nachdem sich die vorangegangenen Punkte im Wesentlichen auf die Infrastruktur für Services bezogen haben, kommen wir nun zum Inhaltlichen. Jeder Service verfügt über eine API, über die er von außen angesprochen werden kann. Standardmäßig handelt es sich dabei um eine ganz klassische HTTP-API, also kein GRPC, kein GraphQL, ja noch nicht einmal HTTPS. Der Grund dafür ist einfach: Solange man auf einfaches, unverschlüsseltes HTTP setzt, lässt sich die API einfach testen und debuggen. Außerdem ist HTTP kompatibel zu praktisch jeder Technologie und Plattform, man braucht keinen speziellen Client (theoretisch genügt sogar curl), und man spart sich jeglichen Aufwand mit Zertifikaten und Co.
Diese HTTP-API besteht dabei aus drei Teilen:
Wem Commands und Queries als Begriffe nicht viel sagen, schaut sich das Design-Pattern CQRS [8] an. Dort schließt sich auch der Kreis zu der ersten Regel, die fordert, die Fachlichkeit und nicht CRUD in den Vordergrund zu rücken.
Fraglos ist reines HTTP kein besonders zeitgemäßes Protokoll mehr, hier ist eher HTTPS gefragt. Für die interne Service-zu-Service-Kommunikation möchte man darüber hinaus vielleicht auch eine gRPC-Schnittstelle haben. Grundsätzlich spricht nichts dagegen, solche Schnittstellen zusätzlich zur HTTP-Schnittstelle einzubauen. Aber man sollte eben nicht mit gRPC, GraphQL & Co. starten, denn klassisches HTTP ist weitaus einfacher in der Handhabung.
Was HTTPS angeht, ist es übrigens eine Überlegung wert, es nicht direkt im Service umzusetzen, sondern den davor liegenden Reverse-Proxy die TLS-Terminierung übernehmen zu lassen: Dieser kann die TLS-Terminierung dann nämlich direkt für alle Services übernehmen, wodurch man dieses Thema an einem zentralen Punkt gebündelt hat.
Apropos Reverse Proxy: Er kann nicht nur die TLS-Terminierung übernehmen, sondern auch das Loadbalancing über mehrere Instanzen eines Services hinweg. Damit das reibungslos funktioniert, müssen Services stets zustandslos sein. Jede eingehende Anfrage wird also verarbeitet, eine Antwort wird zurückgegeben, und danach wird alles, was im Rahmen dieser Anfrage geschehen ist, von der jeweiligen Service-Instanz wieder vergessen.
Wenn Informationen tatsächlich langlebiger sein sollen, müssen sie in einer Datenbank oder einem anderen Speicher persistiert werden. Nur auf diese Art ist sichergestellt, dass es egal ist, welche Instanz des Services eine eingehende Anfrage vom Loadbalancer zugewiesen bekommt.
Die neunte Regel besagt, dass das Anbinden einer externen Ressource wie einer Datenbank oder einer Message-Queue über deren API erfolgen muss. Mit anderen Worten: Ein anderer Dienst wird stets über seine Netzwerkschnittstelle angesprochen und man verlässt sich nie darauf, dass er lokal auf anderem Wege erreichbar wäre. Außerdem erfolgt jeder Zugriff über die offizielle Schnittstelle und man greift niemals direkt auf Dateien oder andere Interna zu.
Ein anderer Service ist als Blackbox anzusehen und als solche sollte man die einzelnen Services dann auch behandeln. Das ist übrigens auch ein Grund dafür, warum ich geschrieben habe, dass jeder Service seine Funktionalität über eine API zur Verfügung stellen muss: Denn gemäß dieser Regel ist das der einzige Weg, auf dem ein Service von außen angesprochen werden darf.
Die zehnte Regel fordert, dass ein Service über Umgebungsvariablen konfiguriert wird. Theoretisch kann man auch mit Flags auf der Kommandozeile arbeiten, aber diese sollten (wenn überhaupt) nur optional unterstützt werden. Den Standardweg schlechthin bilden Umgebungsvariablen. Auch hier ist der Grund wieder sehr einfach: Umgebungsvariablen sind der einzige Mechanismus, der unabhängig von der konkreten zugrunde liegenden Plattform oder dem Betriebssystem funktioniert, und bei dem es keine syntaktischen Unterschiede zwischen den verschiedenen Ansätzen gibt.
Das ist bei Flags nicht gegeben und bei Konfigurationsdateien erst recht nicht: Hier hat man es rasch mit verschiedenen Encodings, Dateiformaten, Line-Endings, … zu tun. Außerdem lassen sich Umgebungsvariablen sowohl global als auch gezielt nur für einen einzelnen Prozess definieren (was für mehrere Instanzen auf einer Maschine ausgesprochen praktisch sein kann). Hinzu kommt, dass sie gut von Docker und Kubernetes unterstützt werden und man mit ihnen im Vergleich insgesamt sehr viel weniger Stolperfallen hat. Anders als Konfigurationsdateien kann man Umgebungsvariablen außerdem nicht aus Versehen in Git einchecken.
Die elfte Regel besagt, dass jeder Service Log-Ausgaben erzeugen sollte, damit nachvollziehbar ist, was wann vorgefallen ist. Log-Ausgaben sollten aber nicht in eine Datei geschrieben werden. Denn diese landet im Zweifelsfall innerhalb eines Docker-Containers, wo sie beim Beenden des Containers mit ihm gelöscht wird. Weitaus besser ist es, Log-Ausgaben auf die Konsole zu schreiben, da man sie dann entsprechend abfangen, umleiten und an beliebiger Stelle verarbeiten kann.
Abgesehen von der viel flexibleren und besseren Verarbeitbarkeit macht das auch den Code des Services einfacher und es funktioniert zudem auch lokal, ohne Abhängigkeit von Dateipfaden, Log-Servern oder ähnlichem. Wer hier das Nonplusultra haben möchte, kann innerhalb des Services ermitteln, ob er interaktiv aus einer Shell heraus oder per Skript gestartet wurde, und die Ausgabe dementsprechend entweder menschenlesbar oder als JSON erzeugen. Tatsächlich haben wir das bei the native web früher häufig gemacht, inzwischen begnügen wir uns aber mit JSON. Denn auch JSON ist für Menschen immer noch gut lesbar, aber es vereinfacht erneut den Code, wenn man auf diese Unterscheidung verzichten kann.
Die zwölfte Regel tangiert den Bereich der Sicherheit, auch wenn es hierzu sicherlich viel mehr zu sagen gäbe. Doch es gibt zwei Grundregeln:
Auf dem Weg erhält man die erhöhten Rechte bei Bedarf, kommt aber im normalen Alltag mit einfachen Berechtigungen aus.
Wer diese zwölf Regeln zusammennimmt, hat eine gute Vorstellung davon, wie wir bei the native web an Services herangehen. Bei meiner Beschreibung habe ich einiges gestreift, vom Repository über die Infrastruktur und CI/CD bis hin zur eigentlichen Codebasis. Wir haben mit diesem Ansatz in den vergangenen Jahren sehr, sehr gute Erfahrungen gemacht. Aber, wie eingangs schon erwähnt, muss das nicht gleichermaßen für alle gelten. Vielleicht haben andere Teams andere Arten von Services, haben ein anderes Wertesystem, oder …
Eine letzte Kleinigkeit möchte ich aber noch erwähnen, die uns schon oft geholfen hat. Wie erwähnt, sehen wir den main-Branch als stabilen und versionierten Stand an. Dementsprechend leicht lässt sich ein solcher Stand deployen, aber wir machen das nicht automatisch: Wir sind überzeugt, dass bei Produktiv-Deployments letztlich ein Mensch die Kontrolle darüber haben sollte, für welche Kunden welche konkrete Version aus welchem Grund ausgeliefert wird.
Aber: Aufgrund der beschriebenen Struktur können wir natürlich auch für jeden Pull Request ein Docker-Image bauen, das anhand der Pull-Request-ID benannt wird. Kombiniert man das mit einem automatischen Deployment auf eine ebenfalls nach der Pull-Request-ID benannten Subdomain, erhält man für jeden Feature-Branch automatisch stets aktuelle Preview-Deployments. Es gibt somit nicht eine Test-Umgebung, sondern für jeden Pull Request wird dynamisch eine eigene aufgebaut – und nach dem Schließen des Pull Request wieder verworfen. Auf dem Weg lässt sich häufig zu einer viel besseren Einschätzung kommen, ob ein Branch schon gemerged werden kann oder nicht.
Damit ein solches Deployment funktioniert, benötigt man natürlich eine entsprechende Infrastruktur, die vollkommen automatisch Subdomains und Zertifikate einrichten kann, die Datenbanken bereitstellen kann, und so weiter. Die für uns beste Infrastruktur dafür ist Kubernetes, was sich vielleicht auch in einigen unserer Design-Entscheidungen widerspiegelt.
URL dieses Artikels:
https://www.heise.de/-9792599
Links in diesem Artikel:
[1] https://www.youtube.com/watch?v=91yfdjVMSuo
[2] https://www.thenativeweb.io/
[3] https://dictionary.cambridge.org/de/worterbuch/englisch/ymmv
[4] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[5] https://www.youtube.com/watch?v=MoWynuslbBY
[6] https://www.youtube.com/watch?v=nOVZxZX5dx8
[7] https://www.youtube.com/watch?v=3YP0eUHdLc8
[8] https://www.youtube.com/watch?v=nDSwyowKYP8
[9] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: rawf8/Shutterstock.com)
System.Text.Json 8.0 bietet eine neue Einstellung zur Handhabung zusätzlicher Informationen bei der Deserialisierung von JSON in Objekten.
Bei der neu eingeführten Funktion UnmappedMemberHandling geht es darum, wie sich System.Text.Json verhält, wenn beim Deserialisieren mehr Eigenschaften vorhanden sind als Properties im Objekt.
Im folgenden Beispielcode gibt es in dieser JSON-Zeichenkette eine Eigenschaft "CITY", aber es existiert kein korrespondierendes Property City in der Klasse Consultant und deren Basisklasse Person.
Die Klassen Consultant und Person wurden im vorherigen Teil [1] schon verwendet und hier nicht noch mal wiedergegeben. Die Einstellung der Namenskonvention wurde ebenfalls besprochen.
try
{
var jsonString = """
{
"ID":42,
"FULL-NAME":"Holger Schwichtenberg",
"PERSONAL-WEBSITE":"www.dotnet-doktor.de",
"CITY":"Essen"
}
""";
Console.WriteLine("JSON: " + jsonString);
var obj = JsonSerializer.Deserialize<Consultant>(jsonString, options);
if (obj != null) CUI.Success(obj.ToString());
}
catch (Exception ex)
{
CUI.PrintError(ex.Message);
}
Bisher hätte System.Text.Json zusätzlichen Informationen einfach ignoriert. Das ist auch im Standard weiterhin so. Via Annotation [JsonUnmappedMemberHandling] auf der zu deserialisierenden Klasse oder Eigenschaft UnmappedMemberHandling im Objekt JsonSerializerOptions können Entwicklerinnen und Entwickler dies nun ändern: Erlaubte Werte sind Skip (Ignorieren wie bisher) und Disallow.
Die folgende Einstellung von Disallow löst also beim obigen Deserialize() einen Laufzeitfehler aus: "The JSON property 'CITY' could not be mapped to any .NET member contained in type 'FCL_JSON.Consultant'."
var options = new JsonSerializerOptions
{
// NEU: Enumeration JsonNamingPolicy mit Namenskonventionen
// KebabCaseLower, KebabCaseUpper, SnakeCaseLower
// und SnakeCaseUppter als Alternative zum
// bisher fest gesetzten CamelCase
PropertyNamingPolicy = JsonNamingPolicy.KebabCaseUpper,
// Standard wäre CamelCase
// NEU: Einstellungen zur Handhabung zusätzlicher Daten
// bei der Deserialisierung von JSON in Objekten
// via Annotation [JsonUnmappedMemberHandling]
// oder Eigenschaft UnmappedMemberHandling
// im Objekt JsonSerializerOptions.
UnmappedMemberHandling = JsonUnmappedMemberHandling.Disallow,
// Default wäre Skip
};
URL dieses Artikels:
https://www.heise.de/-9790704
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[2] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[3] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-16-Neue-Methoden-fuer-IP-Adressen-9670497.html
[18] https://www.heise.de/blog/Neu-in-NET-8-0-17-Zeitabstraktion-fuer-Tests-mit-Zeitangaben-9675891.html
[19] https://www.heise.de/blog/Neu-in-NET-8-0-18-Ein-Zeitraffer-mit-eigenem-FakeTimeProvider-9683197.html
[20] https://www.heise.de/blog/Neu-in-NET-8-0-19-Razor-HTML-Rendering-in-beliebigen-NET-Anwendungen-9691146.html
[21] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-NET-Basisklassen-9706875.html
[22] https://www.heise.de/blog/Neu-in-NET-8-0-20-Neue-Code-Analyzer-fuer-ASP-NET-Core-9710151.html
[23] https://www.heise.de/blog/Neu-in-NET-8-0-22-Neues-Steuerelement-OpenFolderDialog-fuer-WPF-9722901.html
[24] https://www.heise.de/blog/Neu-in-NET-8-0-23-Verbesserungen-fuer-ZipFile-zur-Arbeit-mit-Dateiarchiven-9722920.html
[25] https://www.heise.de/blog/Neu-in-NET-8-0-24-HTTPS-Proxies-bei-HttpClient-9722968.html
[26] https://www.heise.de/blog/Neu-in-NET-8-0-25-Resilienz-im-HTTP-Client-9763586.html
[27] https://www.heise.de/blog/Neu-in-NET-8-0-26-Anpassung-der-Resilienz-im-HTTP-Client-9773126.html
[28] https://www.heise.de/blog/Neu-in-NET-8-0-27-Konfigurierbare-Namenskonventionen-in-System-Text-Json-8-0-9784360.html
[29] https://www.heise.de/blog/Neu-in-NET-8-0-28-Erweiterung-fuer-die-Deserialisierung-von-JSON-Objekten-9790704.html
[30] https://www.heise.de/blog/Neu-in-NET-8-0-29-Verbesserungen-fuer-den-JSON-Source-Generator-9798297.html
[31] https://www.heise.de/blog/Neu-in-NET-8-0-30-Neue-Datentypen-in-System-Text-Json-8-0-9808793.html
[32] https://net.bettercode.eu/
[33] https://net.bettercode.eu/index.php#programm
[34] https://net.bettercode.eu/tickets.php
[35] mailto:rme@ix.de
Copyright © 2024 Heise Medien

Was genau ist am WLAN-Standard Wi-Fi 7 besser als bisher – und wer kann die Vorteile praktisch nutzen? Darum kreist Folge 2024/14 des Podcasts Bit-Rauschen.
Der Standard Wi-Fi 7 für drahtlose Netzwerke umfasst zahlreiche Neuerungen, die WLAN schneller und stabiler machen sollen. Die Spitzengeschwindigkeit steigt im Vergleich zu Wi-Fi 6 und Wi-Fi 6E. Doch die lässt sich häufig nur kurzzeitig nutzen, sowie nur dann, wenn die Entfernung zwischen WLAN-Router oder Repeater und Endgerät nicht zu groß ist.
In der Praxis wichtiger sind mehrere andere neue Funktionen. Denn die tragen dazu bei, dass sich im Durchschnitt höhere Datentransferraten ergeben.
Der c’t-Redakteur Ernst Ahlers [7] erklärt im Gespräch mit seinem Kollegen Christof Windeck [8], was Wi-Fi 7 bringt, und in welchen Einsatzbereichen sich diese Vorteile besonders bemerkbar machen: Folge 2024/14 von "Bit-Rauschen: Der Prozessor-Podcast von c’t".
Podcast Bit-Rauschen, Folge 2024/14 :
Wir freuen uns über Anregungen, Lob und Kritik zum Bit-Rauschen. Rückmeldungen gerne per E-Mail an bit-rauschen@ct.de [10].
Alle Folgen unseres Podcasts sowie die c’t-Kolumne Bit-Rauschen finden Sie unter www.ct.de/Bit-Rauschen [11]
URL dieses Artikels:
https://www.heise.de/-9747881
Links in diesem Artikel:
[1] https://ct.de/bit-rauschen
[2] https://Bit-Rauschen.podigee.io/feed/mp3
[3] https://podcasts.apple.com/de/podcast/bit-rauschen-der-prozessor-podcast-von-ct/id1549821753
[4] https://open.spotify.com/show/6JD6gwqgVR27GYZACrWOT1
[5] https://podcasts.google.com/feed/aHR0cHM6Ly9iaXQtcmF1c2NoZW4ucG9kaWdlZS5pby9mZWVkL21wMw
[6] https://www.deezer.com/de/show/2195452
[7] https://www.heise.de/autor/Ernst-Ahlers-4507618
[8] https://www.heise.de/autor/Christof-Windeck-3687176
[9] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[10] mailto:bit-rauschen@ct.de
[11] https://www.heise.de/meinung/Bit-Rauschen-Der-Prozessor-Podcast-von-c-t-4914290.html
[12] https://www.heise.de/ct/
[13] mailto:ciw@ct.de
Copyright © 2024 Heise Medien

(Bild: iX)
Lancom bringt zwei neue WiFi 7 Access-Points und diverse Switches – vom Core bis zur Access-Ebene. Auch einen Switch für Industrieumgebungen gibt es nun.
Lancom veröffentlicht neue Switches und APs: Neben dem neuen Access Point LX-7500 als Topmodell mit 4x4 Triband Antennen in den Frequenzbändern 2, 4, 5 und 6 GHz liefert der Hersteller noch den LX-7300 mit 2x2 Triband Antennen. Zudem verfügen sie über ein Scan Radio zum permanenten Umgebungsscan. Nach Angaben von Lancom ist dieses jedoch zunächst ausschließlich zum Scan der WLAN-Kanäle nutzbar und nicht für eine gesamte Spektrumsanalyse. Es soll in Kombination mit der Lancom Management Cloud (LMC) nicht nur das Funkfeld sichtbar machen, sondern es auch bewerten und Handlungsempfehlungen zur WLAN-Optimierung für den Administrator geben. Dies soll später auch automatisiert möglich sein.
Beide sollen für die effiziente Frequenznutzung auf das bekannte Multi-User Multiple In-Multiple Out (MU-MIMO) Verfahren setzen und QAM-4096 als Modulation verwenden. Die Kanalbreite beträgt bis zu 320 MHz. Als echte Neuerung gilt Multi-Link Operation, wodurch es je nach eingesetzter Variante möglich ist, parallele Verbindungen auf unterschiedliche Kanäle oder sogar unterschiedliche Frequenzbänder aufzuteilen. Zunächst unterstützt Link Enhanced Multi-Link Single Radio (MLSR). So können alle Multi-Link-fähigen Geräte und Antennen dynamisch auf einen einzigen Link umschalten – sollte das Band dann gestört sein, schaltet es dynamisch auf das zweite Band um. Hinzu kommt Simultaneous Transmit and Receive (STR): Damit können Geräte Daten gleichzeitig über mehrere Verbindungen senden und empfangen, um den Durchsatz zu erhöhen, die Latenz zu reduzieren und die Zuverlässigkeit zu verbessern. Darüber hinaus prüft der Hersteller die Integration weiterer MLO-Varianten, was aber von den Zertifizierungsbedingungen der Wi-Fi Alliance abhängt.
Es steigt aber nicht nur der maximal mögliche drahtlose Durchsatz: Um dies auch ins verkabelte Netz zu transportieren, bieten beide APs zwei Uplink-Ports mit 10G und 2,5G. Damit können die Access-Points auf Basis des Link-Aggregations-Protokolls LACP ein Aktiv/Aktiv-Paar bilden oder auf Basis von Spanning-Tree eine Aktiv/Passiv-Verbindung zu den Switchen formen. Der große Bruder LX-7500 bietet zudem Dual-PoE, wodurch selbst beim Ausfall eines Switches, beispielsweise bei Updates, das WLAN weiter bestehen kann. Aber auch falls die Switching-Infrastruktur noch nicht genügend Leistung über einen Port liefern kann, kann der Access-Point die Leistung beider Ports kombinieren.
Ein In-Service Software-Update für den eigentlichen Access-Point hat der Hersteller in Planung. Auch Secure Boot unterstützen die neuen Modelle. Die APs liefern aber auch BLE 5.1 und lassen sich über USB-Schnittstellen durch weitere IoT-Sensoren ergänzen. Die Access-Points basieren, wie die angekündigten Modelle von Mitbewerbern, auf einem Qualcomm-Chipsatz.
Ferner hat Lancom an Details geschraubt: Unter anderem wurde das Antennendesign für die Deckenmontage verbessert. Aber auch an der physischen Sicherheit wurde gearbeitet: So gibt es eine integrierte Verriegelung gegen unbefugtes Entfernen – zumindest gegen Unbedarfte, die nicht auf den Seiten des Herstellers nachlesen. Ein Neigungs- und Bewegungssensor kann bei falschen Montagewinkeln oder Entwenden warnen.
Zudem verfügt das Gerät über einen integrierten Energieverbrauchsmesser, um die Werte an zentrale Managementsysteme senden zu können. Dem Thema Energiebedarf widmet sich Lancom intensiv. So gibt es auch ein Feature namens Active Power Control, das ein intelligentes Power-Monitoring und -Management bieten soll. Beispielsweise soll perspektivisch die Uplink-Geschwindigkeit in Zeiten geringer Last reduziert werden, um Energie zu sparen. Das bedeutet gemäß Rückfrage beim Hersteller allerdings einen kurzen Link-Down von drei bis fünf Sekunden.
Die Wi-Fi 7 Access-Points [1] sollen ab September 2024 lieferbar sein und zu Listenpreisen von 899 Euro (LX-7300 [2]) und 1190 Euro (LX-7500 [3]) zu haben sein. Die Straßenpreise dürften darunter liegen.
Mit höheren Wireless-Datenraten bedarf es jedoch auch eines Redesigns in der Switching-Infrastruktur. Lancom bringt daher nun neue Switchmodelle, um alle Rollen in Campus-Netzen abdecken zu können – vom Core bis zum Access. Die zugrunde liegenden Hardware-Chips stammen von Broadcom. Im Core und der Distributionsebene positionieren sich das neue Topmodell LANCOM CS-8132F mit 32x 100G QSFP28-Slots und der LANCOM YS-7154CF mit 48x 25G SFP28-Slots und 6x 100G QSFP28. Sie unterstützen auch Virtual Port Channels (VPC bzw. MC-LAG), um in redundanten Netzen auch bei Updates die Verfügbarkeit des Netzwerks gewährleisten zu können. Im Routing unterstützen sie nach Angaben des Herstellers OSPFv2 für IPv4 und OSPFv3 für IPv6, sowie BGP4. Als First-Hop-Redundancy-Protokoll bieten sie VRRP. Netzteile und Lüfter sind redundant und Hot-swappable ausgelegt – und selbst aus Rechenzentrumsswitchen bekannte Funktionen, wie die Auswahl des Luftflusses (vorn nach hinten oder hinten nach vorn), sind mit an Bord.
Auch eine separate CPU und eine 64 GByte große SSD für Zusatzanwendungen stehen bereit – jedoch fehlen diese Funktionen zum Auslieferungsstart noch. Dafür gibt es ein In-Service Software Upgrade (ISSU), um auch bei Updates die Uptime in kritischen Umgebungen gewährleisten zu können.
Die inzwischen bei Mitbewerbern häufig gebotene MACSec-Verschlüsselung bieten sie jedoch nicht. Dazu gab der Hersteller an, dass der Mutterkonzern Rohde & Schwarz mit seinen SITline-Netzwerkverschlüsselern eine Alternative bietet, um auch diesen Anwendungsfall bis zu Link-Geschwindigkeiten von 100G abzudecken. Die Switches sollen zu Listenpreisen von 34.990 Euro (CS-8132F [4]) und 29.990 Euro (YS-7154CF [5]) ab Oktober 2024 lieferbar sein.
Auf Access-Ebene geht der Trend zum Multi-Gigabit Port und im Uplink zu 25G oder höher. So bietet der neue XS-4530YUP [6] beispielsweise 12x 2,5 Gbit/s und PoE gemäß 802.3bt (Typ 4), sowie 12x 10 Gbit/s bei gleichem PoE-Standard. Für Uplink oder Stacking stehen 4x SFP28-Ports (10G oder 25G) und 2x QSFP28 (40G oder 100G) zur Verfügung. Selbst auf Access-Ebene unterstützen die Switches bereits Virtual Port Channel sowie redundante Netzteile und Lüfter. Selbst diese Switches unterstützen ISSU.
Der neue Lancom IGS-3510XUP [7] ist ein Industrie-Switch mit erhöhtem Temperaturbereich von -40 bis +60 °C. Er besitzt ein robustes, passiv gekühltes Metallgehäuse. Im Industriebereich noch unüblich ist die Uplink-Geschwindkeit von 2x 10 Gbit/s. Für den Downlink stehen 4x 1 Gbit/s PoE+ mit bis zu 30W PoE (802.3at) und 4x 2,5 Gbit/s PoE bis zu 90W (802.3bt Type 4) bereit. Insgesamt steht eine PoE-Leistung von bis zu 360W zur Verfügung. Lancom möchte auch noch Industrieprotokolle, wie das Ring-Protokoll ERPS (ITU-T G.8032) nachreichen. Der Switch lässt sich auch zentral über die Cloud verwalten.
URL dieses Artikels:
https://www.heise.de/-9787003
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/Kurz-erklaert-Schnelleres-WLAN-mit-Wi-Fi-7-7488584.html
[2] https://www.lancom-systems.de/produkte/wireless-lan/indoor-access-points/lancom-lx-7300
[3] https://www.lancom-systems.de/produkte/wireless-lan/indoor-access-points/lancom-lx-7500
[4] https://www.lancom-systems.de/produkte/switches/core-switches/lancom-cs-8132f
[5] https://www.lancom-systems.de/produkte/switches/aggregation-switches/lancom-ys-7154cf
[6] https://www.lancom-systems.de/produkte/switches/fully-managed-access-switches/lancom-xs-4530yup
[7] https://www.lancom-systems.de/produkte/switches/fully-managed-access-switches/lancom-igs-3510xup
[8] https://www.heise.de/ix/
[9] mailto:fo@heise.de
Copyright © 2024 Heise Medien