
(Bild: iX)
With Hypershield, Cisco wants to completely revolutionize IT security - and take a lot of work off admins' hands. We show you what's behind the buzzwords.
Cisco wants nothing less than to revolutionize IT security with Hypershield. The manufacturer mentions exploit protection without patches, software upgrades without downtime and autonomous network segmentation. Hypershield is supposed to detect malicious behavior and automatically reconfigure networks to eliminate threats. But what is really behind this grandiose announcement?
In essence, it is about a security product based on eBPF, which is the result of the acquisition of Isovalent. Cisco wants to integrate eBPF into components such as switches and servers, including VMs and containers. The provider calls this Enforcement Points – it is therefore not an entirely new approach [1] in terms of methodology, but rather the familiar "centralized management, decentralized enforcement" approach that has been used for years in network access control (NAC [2]), for example.
The difference lies more in the enforcement points, which are intended to act as a kind of tiny firewall and therefore regulate data flows and behavior as early as possible at the point of origin. These should be able to run based on data processing units (DPUs), i.e. special network cards – also known as SmartNICs – that are installed in servers or network hardware. Cisco points out that these do not have to be special Cisco DPUs.
To be able to detect anomalies, Hypershield should first learn the normal behavior of the applications used via baselining. This will be enriched with information from Cisco's security intelligence team (Talos) about new attacks. The team evaluates the data collected online with the help of AI to detect malicious behavior more quickly.
The decision on how to deal with potentially malicious behavior can vary. One option is to provide basic information to administrators about which applications they need to patch. Another option is to implement compensating protection that protects the application. This could, for example, be a new network segment that does not allow any suspicious traffic. Specifically, certain communication patterns – such as known malicious URLs or lateral movements in the data center – could be blocked or isolation could be carried out after a successful attack. Hypershield's approach is to intercept these communication relationships as close as possible to the application. This should also make it easier to control data traffic in Kubernetes environments, for example.
The enforcement points should contain two data paths: One for productive and positively tested communications and a shadow path. The latter receives live data and, according to Cisco, uses AI to test whether the update works as expected. If the automated tests are successful, Hypershield switches the shadow path to productive.
The enforcement points rely on eBPF for this purpose. The extended Berkeley Packet Filter [3] allows programs to be loaded from user space and run in the kernel without changing the kernel source code or loading kernel modules. As this generates some load, this process can be outsourced to DPUs/SmartNICs to minimize the impact on productive workloads. Cisco is also aiming to develop switches with dedicated DPUs for these functions. However, these are not yet available.
Hypershield is managed in the cloud-based security policy manager Cisco Defense Orchestrator [4]. It displays CVEs, for example. An AI assistant provides additional information and suggests solutions, such as segmentation due to missing patches. According to Cisco, protection should also be able to run completely autonomously in the future.
The announcement [5] seems a little early, as many components such as the special switches for applying the security guidelines are not yet available. Nevertheless, the approach seems quite interesting, although the use of AI in the security environment, especially in the autonomous operation Cisco is aiming for, is likely to cause many administrators and security managers to break out in a sweat.
URL dieses Artikels:
https://www.heise.de/-9693576
Links in diesem Artikel:
[1] https://www.heise.de/news/l-f-Cisco-erfindet-die-Security-neu-9691102.html?from-en=1
[2] https://www.heise.de/hintergrund/Network-Access-Control-Die-Technik-hinter-Zero-Trust-4702937.html?from-en=1
[3] https://www.heise.de/tests/Beobachtungstool-Coroot-im-Test-Telemetriedaten-in-Erkenntnisse-umwandeln-9622639.html?from-en=1
[4] https://www.heise.de/news/Cisco-baut-KI-Features-in-seine-Firewalls-9548462.html?from-en=1
[5] https://newsroom.cisco.com/c/r/newsroom/en/us/a/y2024/m04/cisco-hypershield-security-reimagined.html
[6] https://www.heise.de/ix/
[7] mailto:dahe@heise.de
Copyright © 2024 Heise Medien

(Bild: iX)
Mit Hypershield will Cisco die IT-Sicherheit komplett umkrempeln – und Admins viel Arbeit abnehmen. Wir zeigen, was hinter den Schlagwörtern steckt.
Cisco möchte mit Hypershield nicht weniger, als die IT-Sicherheit revolutionieren. Der Hersteller nennt dabei einen Exploit-Schutz ohne Patches, Software-Upgrades ohne Ausfallzeit, bis hin zur autonomen Netzwerk-Segmentierung. So soll Hypershield bösartiges Verhalten erkennen und Netzwerke automatisch neu konfigurieren, um Bedrohungen zu eliminieren. Doch was steckt wirklich hinter dieser vollmundigen Ankündigung?
Im Kern geht es um ein auf eBPF aufbauendes Sicherheitsprodukt, das aus der Übernahme von Isovalent hervorgeht. Cisco möchte eBPF in Komponenten wie Switches und Servern inklusive VMs und Containern integrieren. Der Anbieter nennt dies Enforcement Points – es handelt sich methodisch also nicht um einen komplett neuen Ansatz [1], sondern den altbekannten Weg "zentrales Management, dezentrales Enforcement", wie man ihn beispielsweise in der Netzwerkzugriffskontrolle (NAC) [2] bereits seit Jahren einsetzt.
Der Unterschied liegt eher an den Enforcement Points, die als eine Art winzige Firewall agieren sollen und folglich Datenflüsse und Verhalten möglichst früh am Entstehungspunkt reglementieren. Diese sollen auf Basis von Data Processing Units (DPUs), also speziellen Netzwerkkarten – auch als SmartNIC bezeichnet – laufen können, die in Servern oder Netzwerkhardware installiert sind. Cisco weist darauf hin, dass dies keine speziellen Cisco DPUs sein müssen.
Um Anomalien erkennen zu können, soll Hypershield zunächst über Baselining das Normalverhalten der eingesetzten Applikationen erlernen. Das soll mit Informationen aus Ciscos Security-Intelligence-Team (Talos) über neue Attacken angereichert werden. Das Team wertet KI-unterstützt die online gesammelten Daten aus, um bösartiges Verhalten schneller zu erkennen.
Die Entscheidung über den Umgang mit potenziell bösartigem Verhalten kann sich unterscheiden. Eine Option ist die grundlegende Information an die Administratoren, welche Anwendungen sie patchen müssen. Eine weitere Option besteht darin, einen kompensierenden Schutz zu implementieren, der die Anwendung schützt. Das kann beispielsweise die ein neues Netzwerksegment sein, das keinen verdächtigen Verkehr zulässt. Konkret könnten also beispielsweise bestimmte Kommunikationsmuster – wie zu bekannt bösartigen URLs oder Seitwärtsbewegungen im Rechenzentrum – geblockt oder Isolierungen nach einer erfolgreichen Attacke durchgeführt werden. Ansatz von Hypershield ist es, diese Kommunikationsbeziehungen möglichst nah an der Applikation abzugreifen. So sollen sich beispielsweise auch den Datenverkehr in Kubernetes-Umgebungen besser kontrollieren lassen.
Die Enforcement Points sollen zwei Datenpfade beinhalten: Einer für produktive und positiv getestete Kommunikationen und einen Schattenpfad. Letzterer erhält gespielte Live-Daten und nutzt laut Cisco KI, um zu testen, ob die Aktualisierung wie erwartet funktioniert. Sollten die automatisierten Tests erfolgreich sein, schaltet Hypershield den Schattenpfad produktiv.
Dazu setzen die Enforcement Points auf eBPF. Der extended Berkeley Packet Filter [4] erlaubt es, Programme aus dem Userspace zu laden und im Kernel ablaufen zu lassen, ohne hierfür den Kernel-Quellcode zu ändern oder Kernel-Module zu laden. Da das etwas Last erzeugt, kann dieser Prozess auf DPUs/SmartNICs ausgelagert werden, um produktive Arbeitslasten möglichst wenig zu beeinflussen. Zudem strebt Cisco an, Switche mit dedizierten DPUs für diese Funktionen zu entwickeln. Sie stehen jedoch noch nicht zur Verfügung.
Die Verwaltung von Hypershield läuft im Cloud-basierten Sicherheitsrichtlinienmanager Cisco Defense Orchestrator [5]. Er zeigt beispielsweise CVEs an. Ein KI-Assistent gibt zusätzliche Informationen dazu und schlägt Lösungsansätze vor, beispielsweise eine Segmentierung aufgrund nicht vorhandenen Patches. Perspektivisch soll der Schutz gemäß Cisco auch vollkommen autonom laufen können.
Die Ankündigung [6] erscheint etwas früh, da viele Bestandteile wie die speziellen Switche zur Anwendung der Sicherheitsrichtlinien noch nicht bereitstehen. Trotzdem erscheint der Ansatz recht interessant, obgleich der Einsatz von KI, insbesondere im von Cisco angestrebten autonomen Betrieb, im Security-Umfeld vielen Administratoren und Sicherheitsverantwortlichen Schweißperlen auf die Stirn treiben dürfte.
URL dieses Artikels:
https://www.heise.de/-9693337
Links in diesem Artikel:
[1] https://www.heise.de/news/l-f-Cisco-erfindet-die-Security-neu-9691102.html
[2] https://www.heise.de/hintergrund/Network-Access-Control-Die-Technik-hinter-Zero-Trust-4702937.html
[3] https://heise.de/s/NY1E
[4] https://www.heise.de/tests/Beobachtungstool-Coroot-im-Test-Telemetriedaten-in-Erkenntnisse-umwandeln-9622639.html
[5] https://www.heise.de/news/Cisco-baut-KI-Features-in-seine-Firewalls-9548462.html
[6] https://newsroom.cisco.com/c/r/newsroom/en/us/a/y2024/m04/cisco-hypershield-security-reimagined.html
[7] https://www.heise.de/ix/
[8] mailto:fo@heise.de
Copyright © 2024 Heise Medien

(Bild: GaudiLab/Shutterstock.com)
Fast alle Unternehmen setzen auf das Daily als Meetingformat. Und fast alle Dailys sind eine Katastrophe: Langweilig, ineffizient und überflüssig. Warum?
Es gibt eine Beobachtung, die mir immer wieder auffällt. Viele Unternehmen setzen bei ihrer Entwicklung auf Scrum (oder zumindest auf das, was sie dafür halten) und führen im Zuge dessen auch tägliche Meetings, sogenannte Dailys, durch. Dabei muss ich ehrlich zugeben, dass ich bisher noch kein Unternehmen kennengelernt habe, bei dem ich die Dailys als produktiv oder gar hilfreich empfunden hätte. Meistens hatte ich stattdessen genau die gegenteilige Meinung: Die Dailys waren langweilig und ineffizient und aus meiner Sicht komplett überflüssig.
Natürlich möchte ich mich dabei nicht als das Maß der Dinge darstellen, doch nachdem ich wirklich viele Unternehmen von innen gesehen habe, fällt mir eben auf, dass zwar das Konzept des Daily-Meetings einerseits weitverbreitet zu sein scheint, die Umsetzung andererseits jedoch häufig keinen guten Eindruck hinterlässt. Hier liegt anscheinend ein Problem vor, über das man mal sprechen sollte. Denn: Warum sind Dailys denn so oft eine Katastrophe? Warum werden sie dennoch durchgeführt? Und gibt es Möglichkeiten, sie besser zu gestalten? Auf all diese Fragen möchte ich in diesem Artikel eingehen.
Wenn man sich fragt, wo eigentlich die ursprüngliche Idee für ein Daily-Meeting herkommt, werden vermutlich viele Entwicklerinnen und Entwickler antworten, dass es sich dabei um ein Konzept aus Scrum handelt. Ob die Idee der Dailys wirklich für Scrum erfunden wurde oder ob Scrum die Idee lediglich populär gemacht hat, weiß ich nicht, aber es lässt sich sicherlich festhalten, dass ein Zusammenhang zwischen der Verbreitung von Scrum und der Durchführung von Dailys zu bestehen scheint.
Die Frage, die sich nun stellt, lautet: Was ist eigentlich ein Daily? Ich habe einige Quellen zurate gezogen, darunter auch die Website scrum-master.de [2], welche das Daily als "kurzes, tägliches Statusmeeting des Teams" definiert. Im Vergleich dazu erwähnt der offizielle Scrum-Guide [3] das Wort "Status" nicht, beschreibt das Daily aber als ein 15-minütiges Treffen des Scrum-Teams. Ziel sei es, einen Einblick in den Fortschritt bezüglich des Sprint-Ziels zu bekommen und das Backlog auf Basis neuer Erkenntnisse für zukünftige Sprints anzupassen. Obwohl der Begriff "Status" dort also nicht explizit verwendet wird, zielt die Fragestellung im Kern dennoch darauf ab: "Wie steht es um den Fortschritt?"
Hier beginnen meiner Meinung nach bereits die Probleme. Nehmen wir diese beiden Definitionen als Ausgangspunkt, so ergibt sich die Frage: Wer nimmt an einem solchen Daily eigentlich teil? Die Antwort ist in beiden Fällen ziemlich klar: das "Team" beziehungsweise das "Scrum-Team". Bloß, was versteht man unter einem Team in Scrum? Es handelt sich um eine Gruppe von Personen, die für die Erstellung des Produkts essenziell sind und bewusst aus verschiedenen Disziplinen – von der Entwicklung über Design und Marketing bis hin zur Planung und Organisation – zusammengesetzt ist. Laut dem offiziellen Scrum-Guide gehören zu diesem Team [4] ausdrücklich die Rollen des Product Owners und des Scrum Masters.
Es könnte natürlich sein, dass dies in Ihrem Unternehmen anders gehandhabt wird, als ich es bisher kennengelernt habe. Möglicherweise ist bei Ihnen die Rolle des Product Owners tatsächlich darauf beschränkt, an der initialen Sprint-Planung teilzunehmen und später den Review durchzuführen. Aber in den meisten Fällen ist der Product Owner sehr daran interessiert zu erfahren, wer gerade woran arbeitet und wie die Projekte voranschreiten. Das geht so weit, dass diese Fragestellung des Product Owners in der Regel sogar die treibende Kraft hinter dem Daily ist. Wie zuvor erwähnt, es mag bei Ihnen anders sein, ich spreche hier nur von meinen Erfahrungen.
Das Hauptproblem dabei ist, dass das Daily auf diesem Weg in erster Linie zu einem Statusmeeting für Product Owner avanciert. Statt dass sich die Teammitglieder auf Augenhöhe austauschen, erfolgt oft ein Bericht an die – gefühlte oder tatsächliche – nächsthöhere Hierarchieebene. Bedenkt man, dass ein Team nach Scrum-Definition 7 +/- 2 Mitglieder umfassen sollte, so mag ein Meeting zwar auf der Uhr nur 15 Minuten dauern. Doch in Wirklichkeit sind, rein kostenmäßig betrachtet, bei 7 Teammitgliedern ganze 105 Minuten Arbeitszeit investiert worden – also fast zwei Stunden pro Tag.
Rechnet man das hoch, summiert sich das auf rund 10 Stunden pro Woche und annähernd 40 Stunden im Monat, die allein für die Dailys aufgewendet werden. Das bedeutet, dass durch die Dailys jeden Monat die Arbeitskraft einer ganzen Personenwoche verloren geht. Für ein bloßes Statusmeeting sind das aus meiner Sicht unverhältnismäßig hohe Kosten. Es handelt sich schlichtweg um eine Verschwendung von Zeit und Geld.
Aber das ist nicht das einzige Problem. Wenn ein solches Meeting zu einem Statusreportmeeting wird, entstehen für alle Teammitglieder Stress und Druck, weil sie das Gefühl haben, ständig etwas berichten zu müssen. Niemand möchte den Eindruck erwecken, nicht zu arbeiten. Deshalb wird notfalls irgendetwas erzählt, um irgendeinen Fortschritt vorzeigen zu können. Oft sind es dann tiefgehende technische Details, die für niemanden sonst im Team von echtem Interesse sind. Es scheint besser, irgendetwas Kompliziertes zu sagen, als einzuräumen: "Eigentlich gibt es gerade nichts Neues bei mir."
Wer das bezweifelt, sollte es einfach mal ausprobieren: Berichten Sie einige Tage lang nichts Neues und beobachten Sie, wie lange es dauert, bis Sie darauf angesprochen werden, warum es nicht vorangeht, was Sie derzeit überhaupt machen, und so weiter. Und hier zeigt sich die wahre Problematik: Aus einem harmlos wirkenden Statusreport wird schnell ein Kontrollmeeting, in dem geprüft wird, ob jede und jeder auch wirklich arbeitet. Es scheint, als könnte man nicht einfach darauf vertrauen, dass Sie eigenständig und diszipliniert arbeiten und sich melden, wenn es etwas zu berichten gibt – sei es positiv oder negativ.
Bezüglich dessen, was man in einem Daily Meeting idealerweise sagt, hat sich in vielen Unternehmen ein festes Muster etabliert, nämlich die berühmten drei Fragen: Was hast du gestern gemacht? Was machst du heute? Wo gibt es Probleme?
Diese werden von jedem Teilnehmer des Meetings routinemäßig beantwortet: "Ich habe gestern dies und das gemacht, heute werde ich jenes tun, und es läuft gut, ich habe aktuell keine Probleme." Es ist äußerst ermüdend, wenn diese Formel täglich von jeder und jedem ohne Variation wiederholt wird und der Informationsgehalt für die anderen Teammitglieder meistens gering ist.
Ich frage mich an der Stelle oft: Warum sollte ich, wenn ich etwas Wichtiges mitzuteilen habe, bis zum nächsten Daily warten? Das erscheint mir ineffizient, und es verzögert alles. Zudem nimmt es, zumindest bei guten Neuigkeiten, auch die Begeisterung. Wenn ich etwas Bedeutendes erreicht habe, das für das Team wichtig ist, möchte ich das doch gerne sofort teilen und nicht erst am nächsten Montag, weil das Daily am heutigen Freitag leider schon vorbei ist.
Gleiches gilt, wenn ein Problem auftritt – warum sollte ich Stunden bis zum nächsten Tag warten, um es anzusprechen? Und offen gesagt: Wenn jemand wissen möchte, woran ich derzeit arbeite, kann sie oder er mich einfach direkt fragen, oder einfach selbst nachsehen, beispielsweise im Projekt-Board – dafür ist es doch schließlich da. In der Mehrzahl der Tage gibt es aber einfach nicht viel Neues zu berichten, und alles, was ich dann wirklich möchte, ist, ungestört arbeiten zu können und nicht aus meiner Konzentration herausgerissen zu werden, weil das nächste unnötige Statusreportmeeting ansteht. Kurz gesagt: Ich habe meine Zweifel am Nutzen von Dailys.
Wie bereits erwähnt, kann es natürlich sein, dass das bei Ihnen alles komplett anders läuft. Persönlich habe ich Dailys allerdings noch nie als positiv erlebt, und das gilt unabhängig von der Art des Unternehmens. Die Probleme, die ich beschrieben habe, sind mir sowohl aus Start-ups als auch aus Großkonzernen bekannt, ebenso aus Unternehmen mit flachen Hierarchien wie aus solchen mit stark ausgeprägten Hierarchiestrukturen. Und diese Erfahrungen sind unabhängig davon, wie agil ein Unternehmen arbeitet (oder zu arbeiten glaubt, denn oft sind die vermeintlich agilen Unternehmen gar nicht wirklich agil). Falls Sie jetzt denken, dass es in Ihrem Unternehmen tatsächlich anders zugeht, würde ich mich freuen, wenn Sie Ihre Erfahrungen in den Kommentaren zu diesem Artikel teilen würden.
Nun ist es natürlich immer einfacher, Kritik zu üben, als konstruktive Verbesserungsvorschläge zu machen. Aber ich glaube, es ist an dieser Stelle gar nicht so schwierig, eine Verbesserung vorzuschlagen. Wie ich schon angedeutet habe: Ich möchte im Bedarfsfall nicht warten müssen, bis das nächste Daily stattfindet. Daher erscheint es mir sinnvoller, Kommunikation nach Bedarf zu ermöglichen. Haben Sie etwas erreicht, das das gesamte Team interessieren und freuen wird? Teilen Sie es direkt mit. Stehen Sie vor einem Problem, bei dem Sie schon länger feststecken, und würden gerne mit jemand anderem darüber sprechen? Suchen Sie direkt nach Unterstützung. Müssen Sie ein Konzept diskutieren, um weiterzukommen? Warten Sie nicht auf das nächste Daily, sondern sprechen Sie es direkt an. Ad-hoc-Kommunikation halte ich in einem Team von 7 +/- 2 Personen für weitaus sinnvoller, effektiver und effizienter als die üblichen, ineffektiven Dailys.
Natürlich könnten Sie jetzt einwenden: Nicht jede Person hat immer sofort Zeit. Das ist korrekt, und genau deshalb ist asynchrone Kommunikation so entscheidend. Ich meine also nicht, dass Sie, wenn Sie etwas Interessantes zu berichten haben, alle sofort zusammenrufen sollten. Vielmehr: Wenn Sie etwas Spannendes zu berichten haben, dann teilen Sie das beispielsweise im Team-Chat. Oder, wenn es sich um ein Feature handelt, das sich in der Benutzeroberfläche zeigt, machen Sie ein kurzes Video oder einen Screenshot und posten Sie das. Wenn Sie ein Problem haben, fragen Sie im Team-Chat, ob jemand, der sich in dem Bereich auskennt, Zeit hat, um sich mit Ihnen zusammenzusetzen. Und so weiter.
Direkt zu handeln, statt im Daily zu berichten, bedeutet nicht, dass Sie immer alle sofort informieren müssen. Es ist völlig in Ordnung, wenn Ihr Team die Nachricht vielleicht erst einige Stunden später oder sogar erst am nächsten Tag sieht – ähnlich wie bei einem Post in sozialen Medien, den nicht alle Ihre Freundinnen und Freunde sofort sehen. Und wenn wirklich dringender Handlungsbedarf besteht, dann können Sie immer noch alle zusammentrommeln. Aber selbst dann ist es sinnvoller, das direkt zu tun, statt auf das nächste Daily zu warten. Also, ganz egal, wie man es betrachtet: Ich persönlich sehe keinen Sinn darin, warum ich etwas bis zum nächsten Daily aufschieben sollte. Ich persönlich halte das schlichtweg für Quatsch.
Entsprechend dem, was ich bis hierhin geschrieben habe, haben wir bei the native web [5] keine Dailys. Tatsächlich haben wir überhaupt keine regelmäßigen Meetings, mit einer Ausnahme, auf die ich gleich noch kommen werde. Bei uns erfolgt immer alles ad-hoc, und damit sind wir seit nunmehr etwa 12 Jahren insgesamt sehr erfolgreich und zufrieden. Der große Vorteil dabei ist, dass wenn Sie etwas direkt ansprechen, Sie sich auch aussuchen können, wen Sie damit ansprechen. Das bedeutet, die Relevanz des Themas für die Personen, die ad-hoc zusammenkommen, ist wahrscheinlich viel größer als in einem Daily, wo alle sich stets alles anhören müssen. Und da ich erwähnte, wie wichtig asynchrone Kommunikation ist: Bei uns läuft das hauptsächlich über Slack.
Die einzige Ausnahme ist ein informelles wöchentliches Treffen, bei dem wir uns einfach zum informellen Austausch treffen, und wo gegebenenfalls noch Themen angesprochen werden können, die wirklich für alle relevant sind und die nicht bereits dringend waren. Und damit sind wir, wie zuvor erwähnt, sehr zufrieden.
Eines möchte ich jedoch noch klarstellen: Ich gebe mich nicht der Illusion hin, dass unsere Methode die magische Lösung für alle Probleme darstellt, egal in welchem Unternehmen Sie tätig sind. Was es jedoch definitiv zeigt, ist, dass es Alternativen gibt. Das bedeutet: Führen Sie keine Dailys durch, nur weil "man das in Scrum eben so macht" oder weil "es jeder macht". Entscheiden Sie sich stattdessen für Vorgehensweisen, die zu Ihnen passen und die tatsächlich einen Mehrwert für alle im Team bieten, und nicht nur für den Product Owner.
Wenn ein Großteil des Teams das Gefühl hat, ein Meeting sei eher Zeitverschwendung, dann sollten Sie darüber nachdenken, warum Sie dieses abhalten, welchen Zweck es erfüllen soll und welche Intention dahintersteckt, um dann alternative Wege zur Erreichung dieser Ziele zu suchen. Denn – und das ist das Wesentliche – Sie sind nicht dazu da, Scrum & Co. zufriedenzustellen. Vielmehr sollten Scrum & Co. dazu dienen, Sie zu unterstützen.
Stellen Sie Ihre Bedürfnisse und Anforderungen als Team also nicht zurück, nur weil ein Prozess oder ein Werkzeug dies von Ihnen verlangt. Die Prozesse und Werkzeuge sind da, um Ihnen zu helfen, nicht umgekehrt. Das ist übrigens der Kerngedanke der gesamten Agilität und tatsächlich der erste Punkt des Agilen Manifests [6]: „Menschen und deren Interaktionen sind wichtiger als Prozesse und Werkzeuge.“ Auf Englisch: „Individuals and interactions over processes and tools.“ Und das sollten Sie nie vergessen.
URL dieses Artikels:
https://www.heise.de/-9684706
Links in diesem Artikel:
[1] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[2] https://scrum-master.de/Scrum-Meetings/Daily_Scrum_Meeting
[3] https://scrumguides.org/scrum-guide.html#daily-scrum
[4] https://scrumguides.org/scrum-guide.html#scrum-team
[5] https://www.thenativeweb.io/
[6] https://agilemanifesto.org/iso/de/manifesto.html
[7] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Pavel Ignatov/Shutterstock.com)
Das HTML-Rendern mit Razor-Komponenten ist in .NET 8.0 auch außerhalb von Blazor-Anwendungen möglich, beispielsweise für HTML-formatierte E-Mails.
Die Razor-Template-Syntax hat Microsoft schon im Jahr 2010 vorgestellt und in ASP.NET MVC Classic Version 3 am 13.11.2011eingeführt, siehe Blogeintrag von Scott Guthrie vom 3.7.2010 [1]. Sie wurde auch in ASP.NET Webpages verwendet und später in ASP.NET Core MVC und ASP.NET Core Razor Pages übernommen. In Blazor gibt es eine erweiterte Version mit einem vereinfachten Modell für wiederverwendbare Razor-Komponenten.
Das Rendern der in Blazor verwendeten Razor-Komponenten ist in .NET 8.0 auch außerhalb von Blazor-Anwendungen möglich. Somit steht die gleiche Syntax, die in Blazor für Web- und Hybridanwendungen zum Einsatz kommt, nun auch für HTML-Rendering für E-Mails im HTML-Format oder andere HTML-Einsatzgebiete zur Verfügung.
Dazu gibt es in .NET 8.0 die neue Klasse Microsoft.AspNetCore.Components.Web.HtmlRenderer [2] im NuGet-Paket Microsoft.AspNetCore.Components.Web.
Für das folgende Beispiel gibt es zunächst drei Razor-Komponenten. EMailTemplate.razor bindet Headline.razor und Footer.razor per Tags ein: <Headline> und <Footer>. Bei Headline wird ein Parameter übergeben. Bei Footer kann man ein Razor-Fragment übergeben.
Alle Styles sind im HTML-Dokument in <style>-Tags enthalten. Externe Style-Sheet-Dateien wie EMailTemplate.razor.css werden nicht wie Blazor automatisch integriert, sondern müssen explizit per <link rel="stylesheet" type="text/css" href="EMailTemplate.razor.css"> referenziert werden. Das funktioniert gut beim Rendering ins Dateisystem, ist aber nicht möglich bei E-Mails.
Der Code für EMailTemplate.razor sieht folgendermaßen aus:
<html>
<body>
<style>
body { font-family: Arial}
</style>
<Headline Text="Terminbestätigung"></Headline>
<p>Guten Tag @Name,</p>
<p>.NET 8.0 ist am <b>@Datum.ToLongDateString()</b> erschienen.</p>
@{
var url = "https://www.IT-Visions.de";
}
@* Einbinden einer weiteren Razor-Komponente mit Child Content *@
<Footer>
<p>
Ihr Team von<br />
<a href="@url">www.IT-Visions.de</a></p>
</Footer>
</body>
</html>
@code {
[Parameter]
public string Name { get; set; }
[Parameter]
public DateTime Datum { get; set; } = new(2023, 11, 14);
}
Dies ist der Code für Headline.razor:
@* Razor Component mit einfachem Parameter *@
<style>
.headline {
color: white;
background-color: #12B4FF;
padding: 10px;
}
</style>
<h3 class="headline">@Text</h3>
@code {
[Parameter]
public string Text { get; set; }
}
Und im Folgenden ist der Code für Footer.razor zu sehen:
@* Razor Component mit Template *@
<p>Mit freundlichen Grüßen</p>
@ChildContent
@code
{
[Parameter]
public RenderFragment ChildContent { get; set; }
}
Der Code im folgenden Listing rendert in einer Konsolenanwendung die E-Mail. Das entstandene HTML-Dokument gibt er auf der Konsole aus, speichert ihn in einer Datei und verwendet ihn zum Versand einer E-Mail:
using System.Diagnostics;
using ITVisions;
using Microsoft.AspNetCore.Components;
using Microsoft.AspNetCore.Components.Web;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
namespace NET8_Console;
class FCL_RazorRendering
{
public async Task Run()
{
CUI.H1(nameof(FCL_RazorRendering));
#region Vorbereiten des Renderns mit Razor Templates
IServiceCollection services = new ServiceCollection();
services.AddLogging((loggingBuilder) => loggingBuilder
.SetMinimumLevel(LogLevel.Trace)
.AddConsole()
);
IServiceProvider serviceProvider = services.BuildServiceProvider();
ILoggerFactory loggerFactory = serviceProvider.GetRequiredService<ILoggerFactory>();
#endregion
#region HTML Rendering using a Razor Component
// Klasse HtmlRenderer neu in .NET 8.0
await using var renderer = new HtmlRenderer(serviceProvider, loggerFactory);
var html = await renderer.Dispatcher.InvokeAsync(async () =>
{
// Parameter zusammenstellen
var name = "Dr. Holger Schwichtenberg";
CUI.Print("Parameter 'Name' = " + name);
var pdic = new Dictionary<string, object>() { { "Name", name } };
var pv = ParameterView.FromDictionary(pdic); // oder: var pv = ParameterView.Empty;
// Nun EMailTemplate.razor rendern
var output = await renderer.RenderComponentAsync<Razor_EMailTemplates.EMailTemplate>(pv);
return output.ToHtmlString();
});
#endregion
#region HTML anzeigen
CUI.H2("Gerendertes HTML");
CUI.PrintYellow(html);
#endregion
#region HTML speichern
var path = Path.GetTempFileName();
path = Path.ChangeExtension(path, ".html");
System.IO.File.AppendAllText(path, html);
// Start new Process to open the File in the default Browser
Process.Start(new ProcessStartInfo(path) { UseShellExecute = true });
#endregion
#region HTML-E-Mail senden
new ITVisions.Network.MailUtil().SendMail("absender@IT-Visions.de",
"empfänger@IT-Visions.de",
"Terminbestätigung .NET 8.0",
html, HTML: true);
#endregion
}
}

(Bild: Screenshot (Holger Schwichtenberg))
URL dieses Artikels:
https://www.heise.de/-9691146
Links in diesem Artikel:
[1] https://weblogs.asp.net/scottgu/introducing-razor
[2] https://learn.microsoft.com/en-us/dotnet/api/microsoft.aspnetcore.components.web.htmlrenderer
[3] https://net.bettercode.eu/
[4] https://net.bettercode.eu/tickets.php
[5] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Lightspring/Shutterstock.com)
Nicht nur Putzfrauen sollen gezwungen werden, Kunden für US-Dienste auszuspionieren, etwa durch Hardware-Manipulation. Nicht zufällig drängt im Senat die Zeit.
Schnell, schnell muss es gehen im US-Senat. Denn am Freitag läuft der berüchtigte Abschnitt 702 des Überwachungsgesetzes FISA (Foreign Intelligence Surveillance Act) aus. Das darf nicht passieren, meinen beide US-Parteien – obwohl Donald Trump, Präsidentschaftskandidat der Republikaner, gegenwärtig für die Abschaffung dieses Überwachungsgesetzes ist. Das Unterhaus hat eine Verlängerung um zwei Jahre beschlossen, einen "Stasi-Paragraphen" hinzugefügt und gleichzeitig den Spionageauftrag erweitert. Der US-Senat muss noch zustimmen, mit Betonung auf "muss".
Die in Washington als Stasi-Paragraph bekannte Norm folgt eigentlich dem Beispiel der Volksrepublik China: Immer mehr Dritte sollen legal dazu gezwungen werden, heimlich für US-Geheimdienste zu spionieren. Bereits seit Jahren betroffen sind Netzbetreiber (electronic communication service provider). Doch das reicht den Spionen nicht mehr. Fortan sollen (mit wenigen Ausnahmen) alle und jeder dazu gezwungen werden können, die irgendwie Zugang zu Kabeln oder Geräten haben, über die Kommunikation laufen oder auf der Kommunikation gespeichert werden könnte. Das reicht vom Händler, der ein Netzwerkkabel verkauft, über den Bürovermieter bis zur Reinigungskraft, die einen Router abstauben kommt.
Sie alle können fortan legal dazu gezwungen werden, Daten abzusaugen, Spyware zu installieren oder Hardware zu manipulieren – so sieht es die vom US-Unterhaus verabschiedete Reform des FISA vor. Ausgenommen sind lediglich Vermieter bestimmten Wohnraums, Restaurants, und bestimmte öffentliche Einrichtungen wie Wasser- und Abwasserwerke, Müllentsorger, Polizei und Feuerwehr, Spitäler und Bibliotheken. Schon die Ausnahmeregeln zeigen, wie weitreichend der Spionagezwang ist.
Und es gibt eine große Ausnahme von der Ausnahme: Hat jemand von den Ausgenommenen ein Gerät oder Kabel zur Aufbewahrung oder Verwaltung inne, kann auch er zur Spionage gezwungen werden. Man denke an ein Krankenhaus, das eigentlich ausgenommen ist, das aber auf das Handy eines Patienten aufpasst, während er behandelt oder operiert wird.
Eine weitere Änderung weitet die Definition der zu sammelnden Daten aus. Es geht schon lange nicht mehr nur um Terrorismus und die Spionageabwehr. Nun kommen auch Drogen expliziert hinzu, und sogar deren Vorläufersubstanzen, die nicht selten alltägliche und harmlose Anwendungen haben. Informationen über Produktion, Verteilung und Finanzierung (!) solcher Substanzen sollen fortan offizielles Ziel der US-Auslandsspionage sein.
Ausgedehnt wird auch die Verwendung der gewonnenen Daten: Sie sollen fortan in vollem Umfang zur Überwachung [1] jeder ausländischen Person genutzt werden dürfen, die vorhat, in die USA einzureisen.
Der Begriff Auslandsspionage ist mit Anführungszeichen zu verstehen. Offiziell sind Ausländer völliges Freiwild, US-Personen dürfen aber im Inland nicht ausspioniert werden. Offiziell. Tatsächlich ist diese Einschränkung so dicht wie ein Maschendrahtzaun. Kommunikation von US-Personen im Inland [2] mit Ausländern wird ebenso überwacht, wie inländische Kommunikation zwischen US-Personen, in der ausländische Ziele bloß erwähnt werden. Letzteres ist als "abouts-communication" bekannt und soll fortan nicht mehr zulässig sein – das wäre die einzige Einschränkung dieser FISA-"Reform". Die Einschränkung gilt allerdings nur für vorsätzliche Überwachung, die auf "abouts-communication" abzielt.
Ist sie Beifang anderer Überwachung, darf sie auch weiterhin ausgewertet werden. Das gilt überhaupt für alle Informationen von oder über US-Personen, die von den Geheimdiensten gesammelt wurde. Sie darf auch Jahre später noch für völlig andere Zwecke genutzt werden. Zwar gab es im Unterhaus einen Abänderungsantrag, der dem FBI auferlegt hätte, solche Datenbankabfragen nur mit richterlicher Genehmigung durchzuführen. Doch ist dieser Antrag mit 212 zu 212 Stimmen gescheitert.
Bei der Erneuerung des FISA-Abschnitts 702 hat man sich so viel Zeit gelassen, dass der US-Senat nun unter Zugzwang steht. Er muss bis Freitag ebenfalls zustimmen, sonst fällt die Rechtsgrundlage für ganz viel Spionage, und das will in Washington niemand. Zeit, mit dem Unterhaus über Änderungen der Novelle zu beraten, bleibt kaum. Die abschließende Unterschrift durch US-Präsident Biden ist reine Formsache, ist doch das Weiße Haus eine der treibenden Kräfte hinter der Reform.
URL dieses Artikels:
https://www.heise.de/-9687201
Links in diesem Artikel:
[1] https://www.heise.de/thema/Ueberwachung
[2] https://www.heise.de/news/USA-Auslandsueberwachung-trifft-auch-US-Buerger-3568157.html
[3] https://www.congress.gov/bill/118th-congress/house-bill/7888/text
[4] mailto:ds@heise.de
Copyright © 2024 Heise Medien
[unable to retrieve full-text content]

(Bild: Maksim Shmeljov/Shutterstock.com)
Japan hat seine Pole-Position in der Chipproduktion seit den 1990er-Jahren verloren. Doch ein Großprojekt soll das ändern.
Die japanische Regierung hat ehrgeizige Pläne, um das Land wieder zu einem führenden Standort für die Chipproduktion zu machen. Anfang des Monats erhöhte sie die Subventionen für das Start-up Rapidus um 3,3 Milliarden auf etwa 6 Milliarden Euro. Das Investitions-Projekt gilt als einer der gewagtesten Versuche für eine technologische Aufholjagd, da Japan damit mehrere Chipgenerationen überspringen will.
Das Land ist zwar laut einer Analyse des Aktienhauses Morgan Stanley MUFG mit einem Anteil von 20 Prozent an der weltweiten Chipproduktion eine der größten Herstellernationen für Halbleiter. Doch dabei handelt es sich ausschließlich um alte Technologien mit Strukturen im zweistelligen Nanometerbereich. Moderne Chips stammen inzwischen zum großen Teil von TSMC aus Taiwan [1].
Das 2022 von japanischen Unternehmen wie Toyota und dem Technikkonzern NEC gegründete Rapidus [2] will hingegen Chips mit 2-Nanometer-Strukturen fertigen und damit zu den technologischen Weltmarktführern TSMC, Samsung aus Südkorea und Intel aufschließen.
Experten der US-Denkfabrik Center for International & Strategic Studies sehen darin "eine beispiellose technologische Leistung", wenn es den Japanern denn gelingt. Die Voraussetzungen sind so gut, wie sie nur sein können. Rapidus arbeitet eng mit anderen Unternehmen zusammen. Expertise bei fortschrittlicher Fertigungstechnik und Chipdesign stammt von IBM [3], die Belichtungstechnik von Imec in Belgien, während die Japaner letztlich die Produktionstechnik entwickeln. Trotzdem ist das Ganze alles andere als ein einfaches Unterfangen – es gilt, weit mehr als ein Jahrzehnt Entwicklungsrückstand aufzuholen.
Für Japans Regierung wäre es die Krönung ihrer Strategie, die Chipindustrie der einst führenden Halbleiternation wiederzubeleben. In den 1980er- und 1990er-Jahren stammten mehr als die Hälfte aller Computerchips aus der ältesten Industrienation Asiens. Doch als die Chipproduktion mit dem Start der digitalen Epoche und dann erst recht mit Smartphones richtig losging, konnten die Elektronikkonzerne beim Investitionswettrennen nicht mit ihren asiatischen Rivalen mithalten.
Zum einen war Japans Chipindustrie zu fragmentiert und damit die Sparten der Konzerne jede für sich zu klein. Zum anderen steckten viele Konzerne in Krisen und waren daher finanziell klamm, während Taiwan und Südkorea lokale Chipfertiger stark subventioniert haben. Daher überlebte die japanische Produktion nur in Nischen.
Toshibas ehemalige Speicherchip-Sparte leistet nun als Kioxia Samsung und SK Hynix Konkurrenz. Renesas, eine Auffanggesellschaft für die Chipsparten mehrerer Unternehmen, baut Chips für automobile und industrielle Anwendungen. Darüber hinaus sind die Japaner auch bei Sensoren stark, insbesondere bei Bildsensoren für Kameras und Smartphones. Zudem konnten die Hersteller von Anlagen, Bauteilen und Chemikalien bisher ihre starke Stellung in der globalen Chiplieferkette verteidigen.
Ende des vorigen Jahrzehnts beschloss die Regierung dann, die überlastete eigene Chipindustrie als Grundlage für eine industrielle Aufholjagd zu nutzen. Der Grund: Der wachsende Großmachtkonflikt zwischen China und den USA sowie Chinas Drohung, die Chip-Hochburg Taiwan anzugreifen, schürte die Angst, dass die Chip-Lieferungen für die eigene Industrie abreißen könnten.
Japans Ministerium für Wirtschaft, Handel und Industrie (METI) ging bei ihrer Wiederbelebungsstrategie sehr strategisch vor. Im Gegensatz zur Europäischen Union oder den USA verzichtete die japanische Regierung darauf, große Subventionspakete in Höhe von Milliarden Euro zu versprechen. Stattdessen werden staatliche Beihilfen projekt- und schrittweise vergeben. Zudem verfolgte die Regierung eine Etappenstrategie.
Zuerst konzentrierte sich das Ministerium darauf, TSMC zum Bau von Werken für relativ große Chips zu gewinnen [4], die Japans Industrie hauptsächlich benötigt. Damit wollten die Wirtschaftsplaner dafür sorgen, dass es für die Chips auch wirklich einen Absatzmarkt gibt.
Die Japaner überzeugten die Taiwaner sogar davon, mit dem Elektronikkonzern Sony und dem Automobilzulieferer Denso ein Joint Venture zu gründen. Dieses Modell steht auch für das Engagement von TSMC in Dresden [5] Pate.
Der Aufbau der ersten Fabrik, die Anfang des Jahres eingeweiht wurde, lief sogar so glatt, dass TSMC bereits ein zweites Werk plant. Dort sollen 6-Nanometer-Chips für autonomes Fahren hergestellt werden. Gerüchten zufolge denken die Taiwaner sogar über ein drittes Werk nach.
Der frühe Erfolg der Ansiedlungsstrategie stärkte die Bereitschaft der Wirtschaftsplaner, mit Rapidus eine wirklich große technologische Wette zu wagen. Die Regierung ist sich sehr wohl bewusst, dass dies Japans letzte Chance ist, mit einem japanischen Unternehmen in der Weltspitze mitzuspielen. METI-Minister Ken Saito sagte daher im vergangenen Jahr: "Das Projekt darf auf keinen Fall scheitern."
URL dieses Artikels:
https://www.heise.de/-9680421
Links in diesem Artikel:
[1] https://www.heise.de/thema/TSMC
[2] https://www.heise.de/news/Halbleiter-Wettrennen-Japan-gruendet-Rapidus-fuer-neue-2-Nanometer-Fertigung-7337319.html
[3] https://www.heise.de/thema/IBM
[4] https://www.heise.de/news/TSMC-Werke-Japan-subventioniert-angeblich-40-Prozent-9637437.html
[5] https://www.heise.de/news/TSMC-kommt-als-ESMC-nach-Deutschland-9237991.html
[6] https://www.instagram.com/technologyreview_de/
[7] mailto:jle@heise.de
Copyright © 2024 Heise Medien

(Bild: Stokkete/Shutterstock.com)
In den vergangenen Tagen sind wir mit sehr viel Glück dem wohl größten Fiasko in der Geschichte des Internets gerade so entgangen. Wie konnte das passieren?
Man darf wohl ohne Übertreibung behaupten, dass etwas Derartiges nicht alle Tage passiert. Wahrscheinlich haben Sie zumindest am Rande mitbekommen, dass wir in den vergangenen zehn Tagen nur mit äußerst viel Glück einer der größten Katastrophen in der Geschichte des Internets knapp entkommen [1] sind. Die Vorkommnisse lesen sich tatsächlich wie ein überaus spannender High-Tech-Kriminalroman. Doch was genau ist eigentlich geschehen? Wie konnte es dazu kommen? Welche Schritte sind nun erforderlich? Und vor allem: Wie lassen sich ähnliche Vorfälle in der Zukunft verhindern?
Auf den ersten Blick schien es sich um einen Angriff auf das XZ-Projekt zu handeln, doch tatsächlich sind wir nur knapp einer digitalen Katastrophe unvorstellbaren Ausmaßes entkommen: Im Kern geht es bei dem Ganzen um nichts Geringeres als den Kampf um die digitale Weltherrschaft. Um zu verstehen, was genau passiert ist, werfen wir zunächst einen Blick auf einen kurzen historischen Abriss der Ereignisse.
Bevor wir damit jedoch beginnen, sollten wir kurz klären, was XZ eigentlich ist: Falls Ihnen das nichts sagt, XZ ist eine Sammlung von Werkzeugen zum Komprimieren von Dateien [2], ähnlich wie ZIP, und bezeichnet ebenso das dazugehörige Kompressionsformat. Im Gegensatz zu ZIP handelt es sich bei XZ jedoch nicht um ein Archivformat, das heißt, es werden nicht mehrere Dateien zu einer einzelnen zusammengefasst, sondern jede Datei wird für sich komprimiert. Wichtig zu erwähnen ist dabei auch, dass es eine zugehörige Bibliothek namens liblzma gibt. Das steht für "Lempel Ziv Markov Algorithm", also den Namen des Algorithmus, den XZ intern verwendet.
Springen wir in das Jahr 2021, denn der Ursprung der ganzen Geschichte reicht tatsächlich bereits drei Jahre zurück. Damals ereignete sich zwar zunächst eigentlich nichts, was besonders ins Auge fiele oder für Aufregung gesorgt hätte, jedoch legte im Laufe des Jahres jemand namens Jia Tan ein GitHub-Konto mit dem Benutzernamen JiaT75 [3] an. Außerdem reichte Jia Tan einen Pull Request bei der Bibliothek libarchive [4] ein, der darauf abzielte, eine Fehlermeldung zu verbessern.
Zumindest scheint das auf den ersten Blick der Zweck des Pull Requests gewesen zu sein. Bei genauerer Betrachtung des zugehörigen Commits fällt jedoch auf, dass nicht nur eine Fehlermeldung verbessert werden, sondern auch die Funktion zur Ausgabe, safe_fprintf, durch eine unsichere Variante, nämlich einfach nur fprintf, ersetzt werden sollte. Dieser Pull Request wurde ohne Einwände akzeptiert und hatte vermutlich keine weitreichenden Folgen. Doch vor dem Hintergrund der aktuellen Geschehnisse gerät der Vorgang erneut in den Fokus. Kurz gesagt: Jia Tan betritt die Bühne.
Im darauffolgenden Jahr 2022 legt Jia Tan erstmalig einen Patch für XZ vor. Im Gegensatz zum üblichen Vorgehen wird dieser Patch allerdings nicht als Pull Request eingereicht, sondern über eine Mailingliste verteilt. Der Patch selbst ist eher unscheinbar und weckt wenig Interesse. Doch es ereignet sich etwas anderes, weit spannenderes: Eine zweite Person, die sich Jigar Kumar nennt, beginnt, den Entwickler von XZ zu drängen, den Patch so schnell wie möglich zu integrieren.
Der Druck steigt weiter an, als eine dritte Person, unter dem Namen Dennis Ens, ebenfalls auf eine rasche Übernahme des Patches drängt. Sowohl Jigar Kumar als auch Dennis Ens verschwinden nach diesen Ereignissen spurlos und hinterlassen keinerlei digitale Spuren. Beide Konten scheinen außerdem speziell für diesen einmaligen Zweck angelegt worden zu sein. Bemerkenswert dabei ist, dass alle drei E-Mail-Adressen einem ähnlichen Muster folgen.
Der Hauptentwickler von XZ, Lasse Collin, gibt dem Druck nach und nimmt den Patch auf. Es ist ein Paradebeispiel dafür, wie die Dinge oft laufen: Lasse Collin betreibt die Arbeit an XZ nebenbei. Wie so häufig ist die Beteiligung an Open-Source-Projekten für ihn als Einzelperson kaum nachhaltig. Die Last, die XZ mit sich bringt, ist für ihn allein eigentlich zu groß. Er ist überfordert und überarbeitet, wie er damals selbst schreibt.
Leider ist diese Situation typisch für viele Entwicklerinnen und Entwickler weitverbreiteter Open-Source-Bibliotheken, die wesentlich zur kritischen Infrastruktur beitragen, ohne dass sich jemand ernsthaft um ihre finanzielle oder psychische Gesundheit kümmert. Open Source leidet unter einem gravierenden Nachhaltigkeitsproblem. Und es ist nicht das erste Mal, dass so etwas geschieht. Erinnern wir uns nur an die jüngste Sicherheitslücke in Log4J [6].
Im Klartext: Die Open-Source-Ideologie hat es über die Jahre und Jahrzehnte geschafft, den Wert unserer Zeit als Entwicklerinnen und Entwickler zu untergraben. Denn seien wir ehrlich: Für die meisten geht es bei Open Source nicht primär um den Zugang zum Quellcode, sondern um die Kostenfreiheit. Dass dabei Menschen wie Lasse Collin auf der Strecke bleiben können, wird als bedauerlicher, aber akzeptabler Kollateralschaden angesehen. Hauptsache, Open-Source-Software bleibt sowohl für die breite Masse als auch Unternehmen kostenfrei verfügbar …
Vor diesem Hintergrund überrascht es wenig, dass Lasse Collin die Unterstützung, die Jia Tan ihm anbietet, dankend annimmt. Denn endlich scheint einmal jemand bereit zu sein, nicht nur Forderungen zu stellen, sondern sich auch aktiv einzubringen. Dass er dabei unwissentlich einem umfassenden Social-Engineering-Angriff zum Opfer fällt, kann Collin zu diesem Zeitpunkt natürlich nicht erahnen. Und Jia Tan engagiert sich tatsächlich: Sie oder er wird zu einem regelmäßigen Mitwirkenden bei XZ, steigt im Laufe der Zeit sogar zum zweithäufigsten Beitragenden auf und wird 2022 schließlich zum offiziellen Co-Maintainer ernannt, mit den entsprechenden Berechtigungen.
Von dieser neu gewonnenen Vertrauensstellung macht Jia Tan erstmals am 7. Januar 2023 Gebrauch und integriert eigenständig Code in das XZ-Projekt. Von diesem Zeitpunkt an genießt Jia Tan das vollständige Vertrauen von Lasse Collin. Zwei Monate später, im März, wird die Kontaktadresse für XZ beim Open-Source-Sicherheitsscanner OSS-Fuzz auf Jia Tans Adresse umgestellt. Ab diesem Zeitpunkt gehen sicherheitsrelevante Benachrichtigungen, die XZ betreffen, primär an Jia Tan, Lasse Collin bleibt lediglich in CC.
Diese Änderung erweist sich wenige Monate später als bedeutsam, als eine neue Person, Hans Jansen, auf den Plan tritt. Hans Jansen schlägt eine Methode vor, um Prüfsummen schneller zu berechnen, indem der hierfür verwendete Algorithmus zur Laufzeit ausgetauscht werden kann – ein Konzept, das einem Plug-in-System ähnelt. Nach diesem Vorschlag verschwindet Hans Jansen zunächst wieder aus dem Geschehen, wird aber später erneut eine Rolle spielen.
Jia Tan stimmt dem Änderungsvorschlag zunächst zu und erhält daraufhin prompt eine Sicherheitswarnung von OSS-Fuzz – Lasse Collin hingegen erhält diese Warnung nicht. Die Warnung ist gerechtfertigt, denn die vorgeschlagene Änderung würde es ermöglichen, Code nachträglich auszutauschen – eine Möglichkeit, die normalerweise vermieden werden sollte. Jia Tan wendet sich jedoch an OSS-Fuzz und behauptet, dass diese Änderung legitim sei und die Warnung somit unbegründet. Und OSS-Fuzz stimmt dieser Einschätzung schließlich zu. Damit ist in XZ nun theoretisch die Möglichkeit geschaffen, Code zur Laufzeit zu manipulieren.
Nach einer dreijährigen Vorbereitungsphase wird es dann im Jahr 2024 schließlich ernst: Jia Tan reicht bei XZ einen Pull Request ein, um scheinbar neue Testdateien hinzuzufügen. Konkret handelt es sich um zwei Binärdateien, deren Inhalt auf den ersten Blick nicht unmittelbar ersichtlich ist. Sie sollen angeblich dem Testen des Entpackungsvorgangs dienen, wobei eine der Dateien vermeintlich korrupt ist, die andere hingegen nicht.
Auf den ersten Blick mag dieses Vorgehen legitim erscheinen, da solche Testszenarien in der Praxis durchaus üblich sind. Andererseits lässt sich sicherlich darüber streiten, ob es eine gute Idee ist, direkt Binärdateien einzupflegen, oder ob diese nicht eher durch einen transparenten und nachvollziehbaren Prozess erzeugt werden sollten. Das eigentliche Problem besteht jedoch darin, dass diese "Test"-Dateien nicht einfach nur beliebige Binärdateien sind, sondern Skripte und ausführbaren Code enthalten. Beim Ausführen der Tests werden sie entpackt und in der Folge durch eine Reihe komplexer Befehle ausgeführt, was zu einer Manipulation des XZ-Builds führt. Ab diesem Zeitpunkt existieren somit kompromittierte Versionen von XZ.
Am 25. März 2024 taucht Hans Jansen schließlich erneut auf und setzt sich unter anderem beim Debian-Projekt dafür ein, auf die neue – und somit kompromittierte – Version von XZ umzusteigen. Das Debian-Projekt führt auch tatsächlich ein Upgrade durch, zunächst zwar nur in einer Vorabversion, aber Hans Jansen erzielt damit einen Erfolg. Auch andere Linux-Distributionen wie Kali-Linux, Arch-Linux und Fedora nehmen das Upgrade vor. Einige Distributionen, darunter Ubuntu, entscheiden sich gegen das Upgrade oder schieben eine Entscheidung auf. So gelangt die kompromittierte Version von XZ aber in eine Reihe von Linux-Distributionen.
Besagte Vorabversion von Debian fand nun ihren Weg zu Andres Freund, einem Mitarbeiter von Microsoft, der an der Entwicklung von PostgreSQL beteiligt ist. Er wollte einige seiner Änderungen an PostgreSQL testen und entschied sich daher für die neueste Debian-Version. Dadurch kam er bereits sehr früh mit dem Schadcode in Berührung – deutlich früher als die meisten Nutzer. Bei seinen Tests bemerkte er, dass der Login über SSH ungewöhnlich lange dauerte, nämlich eine dreiviertel Sekunde anstelle der üblichen Viertelsekunde.
Während die meisten Entwicklerinnen und Entwickler dies wahrscheinlich übersehen oder ignoriert hätten, wurde Freund skeptisch und begann, der Sache auf den Grund zu gehen. Seine Nachforschungen führten ihn immer tiefer in den Kaninchenbau, was mich persönlich an Clifford Stoll erinnert, der in den 1980er-Jahren aufgrund eines minimalen Abrechnungsfehlers den KGB-Hack aufdeckte [7]. Schließlich geht Andres Freund am 29. März, also vier Tage später, mit seinen Erkenntnissen an die Öffentlichkeit.
Nun stellt sich die Frage: Was genau ist das Problem und wo liegt die Gefahr? Es steht fest, dass XZ kompromittiert wurde, aber welche Auswirkungen hat das? Die Bedrohung ist tatsächlich nur indirekt mit XZ verbunden. Es ist wichtig zu verstehen, dass XZ unter Linux eine essenzielle Rolle spielt: So wird unter anderem der Kernel üblicherweise mit XZ komprimiert, ebenso das Initramfs und auch RPM- sowie DEB-Pakete. XZ ist somit schon früh im Systemstartprozess von Bedeutung.
Viele Linux-Distributionen verwenden heutzutage Systemd als Init-Prozess, der oft auch dazu dient, den SSH-Dienst zu starten. Die meisten Distributionen bieten dafür allerdings nicht die offizielle OpenSSH-Version an, sondern eigene, modifizierte Varianten mit zusätzlichen Funktionen. Die Integration von SSH mit Systemd ist eine solche typische Erweiterung. Hier setzt der Angriff an: Wenn Systemd startet, lädt es XZ, und XZ leitet – noch bevor SSH gestartet wird – die Funktion zur Authentifizierung von SSH-Schlüsseln auf sich um. Sobald SSH aktiviert wird, kommt die manipulierte Version zum Einsatz.
Und die hat es in sich: Die manipulierte Version der Authentifizierungsfunktion verhält sich zwar fast immer so, wie man es erwarten würde. Doch bei manchen SSH-Schlüsseln tritt ein Sonderfall in Kraft: Statt sie zu überprüfen, extrahiert der Backdoor-Code daraus Befehle, die er auf dem Zielsystem ausführt. Anstelle der regulären SSH-Authentifizierung muss dabei die Befehlssequenz eine digitale Signatur tragen, die nur die Angreifer erstellen können. Es ist tatsächlich ziemlich beeindruckend, dass so etwas überhaupt möglich ist. Der Clou dabei ist, dass sich SSH damit für praktisch alle Nutzerinnen und Nutzer vollkommen normal verhalten würde, nur nicht für Angreiferinnen oder Angreifer, die im Besitz des entsprechenden privaten Schlüssels wären. Das hätte die Sicherheitslücke extrem gut verbergen können.
Das Besondere an diesem Angriff ist seine Komplexität. Er basiert darauf, die Lieferkette von SSH über mehrere Ebenen hinweg zu attackieren: Von XZ über liblzma und Systemd bis hin zu SSH. Ein solches Unterfangen erfordert umfassendes Spezialwissen aus verschiedenen internen Bereichen des Betriebssystems, der betroffenen Werkzeuge und insbesondere ihrer Wechselwirkungen. Die Vorbereitungen für diesen Angriff hatten eine lange Vorlaufzeit, beginnend im Jahr 2021, und es handelt sich um einen sogenannten NOBUS-Angriff ("Nobody but us"), bei dem ausschließlich die Angreiferin oder der Angreifer die Sicherheitslücke hätte ausnutzen können. Die Möglichkeit, in XZ dynamisch Code nachzuladen, legt sogar die Grundlage für weitere Exploits. Dies zeugt von einer komplexen und sorgfältig durchdachten Vorgehensweise.
Angesichts der hochtechnischen Natur dieses Angriffs stellt sich daher die Frage, warum er so schnell entdeckt wurde. Warum lief der SSH-Login merklich langsamer als üblich, was letztlich den ersten Verdacht bei Andres Freund weckte? Warum wurde dies, trotz des beträchtlichen Aufwands, der in die Planung des Angriffs floss, nicht umfassender getestet?
Möglicherweise hatten wir alle einfach nur enormes Glück: Denn am 29. Februar, also vor gerade einmal fünf Wochen, wurde bei Systemd der Vorschlag eingebracht, das Laden von XZ zu einem deutlich späteren Zeitpunkt im Systemstartprozess zu initiieren, um diesen zu beschleunigen. Wäre dieser Vorschlag umgesetzt worden, hätte XZ nicht mehr die Möglichkeit gehabt, unbemerkt Veränderungen an SSH vorzunehmen.
Mit anderen Worten: Diese Änderung in Systemd hätte den sorgfältig über Jahre geplanten Angriff zunichtegemacht. Daher könnte es sein, dass die Angreifenden unter Druck gerieten, ihre Pläne vorzeitig in die Tat umzusetzen – selbst auf das Risiko hin, dass der Angriff bislang nicht ausgereift war. Dieser glückliche Zufall hat uns möglicherweise davor bewahrt, dass 80 bis 90 Prozent aller Server im Internet kompromittiert worden wären. Bedenkt man, dass Linux auf einem Großteil aller Server im Web und in der Cloud läuft, sind die potenziellen Konsequenzen kaum zu überschauen. Das hätte dann wirklich einer Übernahme der digitalen Weltherrschaft gleichkommen können, wie eine Szene aus "Fight Club", nur eben im echten Leben.
Zum aktuellen Stand: Der spezifische Exploit wird noch von zahlreichen Expertinnen und Experten untersucht. Das GitHub-Repository von XZ ist momentan gesperrt, während der ursprüngliche Hauptentwickler, Lasse Collin, mit den Aufräumarbeiten beschäftigt ist. An dieser Stelle möchte ich noch einmal betonen, wie sehr mir Lasse Collin leidtut. Er hat viel Zeit und Engagement in die Entwicklung von etwas gesteckt, das der Allgemeinheit zugutekommt, nur um dann Opfer eines hinterlistigen Angriffs zu werden. Dass er einem so gut geplanten Social-Engineering-Angriff zum Opfer gefallen ist, kann und darf ihm nicht angelastet werden. Es ist zutiefst bedauerlich, dass jemand, der Gutes bewirken wollte, von anderen ausgenutzt wird, mit der erkennbaren Absicht, enormen Schaden anrichten zu wollen.
Ob die wahren Drahtzieher dieses komplexen Angriffs jemals ermittelt werden können, bleibt ungewiss. Es gibt Stimmen, die aufgrund der Komplexität und der langen Vorbereitungszeit auf die Beteiligung von Geheimdiensten verweisen. Allerdings könnte es genauso gut ein Einzelner mit ausgeprägter technischer Expertise und Durchhaltevermögen gewesen sein. Die bisher einzige Spur, ein IRC-Chat, den Jia Tan genutzt hat, führt zu einer IP-Adresse in Singapur, die jedoch zu einem VPN-Anbieter gehört – wahrscheinlich also eine Sackgasse. Eventuell könnte eines Tages eine Kombination aus Quellcodeanalyse, Auswertung der Tageszeiten und weiteren Indizien zu Erkenntnissen führen – allerdings halte ich das persönlich für eher unwahrscheinlich.
Was lässt sich nun konkret unternehmen? Kurzfristig ist es sicherlich ratsam, alle verfügbaren Updates einzuspielen und gegebenenfalls zu überprüfen, ob die eigene Infrastruktur von der Schwachstelle betroffen ist. Weitere Informationen dazu finden sich im CVE-2024-3094 [8].
Langfristig betrachtet handelt es sich hierbei jedoch weniger um ein technisches als vielmehr um ein gesellschaftliches und kulturelles Problem, das verschiedene Ebenen betrifft: Dazu zählt das blinde Vertrauen in Open-Source-Projekte, die anhaltende Nachhaltigkeitsproblematik in der Open-Source-Welt und die sorglose Integration externer Abhängigkeiten in eigene Projekte. Das gesamte System des Internets basiert im Wesentlichen auf gegenseitigem Vertrauen, oft jedoch, ohne wirklich zu wissen, wem dieses Vertrauen eigentlich geschenkt wird. Es ist daher erstaunlich, dass nicht noch mehr Zwischenfälle geschehen.
Die eigentlich spannende Frage ist jedoch, was vielleicht tatsächlich bereits unbemerkt passiert, ohne dass wir davon Kenntnis erlangen. Ich sehe den aktuellen Open-Source-Ansatz daher kritisch, denn die Verlockung, etwas kostenlos zu erhalten, macht viele Entwicklerinnen und Entwickler und auch Unternehmen offenbar blind für alles andere. In einer idealen Welt wäre das unproblematisch, aber angesichts der Existenz von Akteuren mit bösartigen Absichten – inklusive feindlicher Organisationen und Staaten – muss man sich fragen, ob das blinde Vertrauen in Open Source tatsächlich langfristig tragbar ist.
Und nur, damit das nicht falsch verstanden wird: Ich möchte damit nicht sagen, dass Closed Source die Lösung sei. Ein ähnlicher Angriff wäre dort genauso möglich. Doch wird die Anfälligkeit von Open Source durch das bestehende Problem verstärkt, dass Open-Source-Entwicklung in der Regel nicht nachhaltig ist: Solange Software für kritische Infrastrukturen wie das Internet von einzelnen Personen in ihrer Freizeit nebenher und unbezahlt erfolgt, solange wird es auf einfachstem Wege möglich sein, sich deren Vertrauen zu erschleichen. Würde die Entwicklung von Open-Source-Software hingegen angemessen bezahlt, wäre die Notwendigkeit, aus einer akuten Notlage heraus auf von Fremden angebotene Hilfe zurückzugreifen, deutlich niedriger.
Selbstverständlich weist Open Source sehr viele positive Aspekte auf, das möchte ich nicht abstreiten. Aber wo Licht ist, ist bekanntermaßen leider auch Schatten – und von diesen Schattenseiten der Open Source haben wir vermutlich gerade erst den Anfang gesehen.
Aufgrund von Hinweisen unter anderem aus dem Forum haben wir zwei missverständliche Passagen im Blogbeitrag aktualisiert. Sie betreffen einerseits das Zusammenwirken von XZ und Systemd, sowie zweitens die Authentifizierung von SSH-Schlüsseln mit der manipulierten Version der Authentifizierungsfunktion.
URL dieses Artikels:
https://www.heise.de/-9678531
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/Die-xz-Hintertuer-das-verborgene-Oster-Drama-der-IT-9673038.html
[2] https://de.wikipedia.org/wiki/XZ_Utils
[3] https://github.com/JiaT75
[4] https://www.libarchive.org/
[5] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[6] https://www.heise.de/blog/Log4j-warum-Open-Source-kaputt-ist-6317678.html
[7] https://www.heise.de/blog/RTFM-1-Kuckucksei-4999968.html
[8] https://nvd.nist.gov/vuln/detail/CVE-2024-3094
[9] mailto:map@ix.de
Copyright © 2024 Heise Medien

(Bild: artjazz/Shutterstock.com)
Der EU-Politiker Dragoş Tudorache glaubt, dass die KI-Verordnung, an deren Verabschiedung er mitgewirkt hat, den KI-Sektor zum Besseren verändert.
Dragoş Tudorache hat derzeit viel Grund zur Freude. Er sitzt in einem Konferenzraum in einem Chateau mit Blick auf einen See außerhalb von Brüssel und schlürft ein Glas Cava. Der liberale Abgeordnete des Europäischen Parlaments hat den Tag damit zugebracht, einer Konferenz über KI, Verteidigung und Geopolitik vorzustehen, an der fast 400 VIP-Gäste teilgenommen haben.
Der ehemalige rumänische Innenminister gilt als einer der wichtigsten Akteure in der europäischen KI-Politik. Er war einer der beiden federführenden Verhandlungsführer für den AI Act im Europäischen Parlament [1]. Die Verordnung, die weltweit erste umfassende KI-Gesetzgebung ihrer Art, wird noch in diesem Jahr in Kraft treten. Vor zwei Jahren wurde er in seine Position berufen.
Das Interesse an KI begann jedoch bei ihm schon viel früher, im Jahr 2015. Er sagt, die Lektüre von Nick Bostroms Buch "Superintelligenz" [2] habe ihn geprägt. Darin wird geschildert, wie eine allgemeine Künstliche Intelligenz geschaffen werden könnte und welche Auswirkungen diese haben könnte. Das Werk habe ihm das Potenzial und die Gefahren der KI und die Notwendigkeit ihrer Regulierung vor Augen geführt. (Bostrom selbst ist derzeit in einen Skandal verwickelt [3], weil er in E-Mails aus den Neunzigerjahren rassistische Ansichten geäußert haben soll. Tudorache sagt, er wisse nichts über die weitere Karriere des Philosophen nach der Veröffentlichung des Buches.) Als Tudorache dann 2019 in das Europäische Parlament gewählt wurde, war er entschlossen, an der Regulierung von KI zu arbeiten, wenn sich die Gelegenheit bieten würde.
"Als ich [Ursula] von der Leyen in ihrer ersten Rede vor dem Parlament sagen hörte, dass es eine KI-Regulierung geben wird, sagte ich: 'Juhu, das ist mein Moment'", erinnert er sich. Seitdem hat Tudorache den Vorsitz des Sonderausschusses für KI inne und den AI Act durch das Europäische Parlament und in seine endgültige Form nach Verhandlungen mit anderen EU-Institutionen gebracht.
Es war ein wilder Ritt, mit intensiven Verhandlungen, dem Aufstieg von ChatGPT, der Lobbyarbeit von Technologieunternehmen [4] und einem Hin und Her einiger der größten europäischen Volkswirtschaften. Doch nun, da der AI Act verabschiedet wurde, ist Tudoraches Arbeit daran erledigt und er sagt, dass er es nicht bereut. Obwohl das Gesetz kritisiert wurde – sowohl aus der Zivilgesellschaft, weil es die Menschenrechte nicht ausreichend schützen soll, als auch von der Industrie, die es für zu restriktiv hält – sagt Tudorache, dass die endgültige Form die Art von Kompromiss war, die er erwartet hatte. Politik sei nun einmal die Kunst des Kompromisses.
"Es wird viel an dem Flugzeug herumgebastelt, während es in der Luft ist, und wir lernen viel von diesem Flug", sagt er. "Aber wenn der wahre Geist dessen, was wir mit der Gesetzgebung gemeint haben, von allen Beteiligten gut verstanden wird, glaube ich, dass das Ergebnis positiv ausfallen kann." Es sei aber noch zu früh – das Gesetz tritt erst in zwei Jahren vollständig in Kraft. Tudorache ist jedoch davon überzeugt, dass es die Technologiebranche zum Besseren verändern und einen Prozess in Gang setzen wird, bei dem die Unternehmen beginnen, verantwortungsvolle KI ernst zu nehmen, da die KI-Unternehmen rechtlich verpflichtet sind, transparenter zu machen, wie ihre Modelle aufgebaut sind.
"Die Tatsache, dass wir jetzt eine Blaupause dafür haben, wie man die richtigen Grenzen setzt und gleichzeitig Raum für Innovationen lässt, ist etwas, das der Gesellschaft dienen wird", sagt Tudorache. Es wird auch den Firmen nützen, weil es einen vorhersehbaren Weg bietet, was man mit KI anstellen darf und was nicht. Aber das KI-Gesetz ist erst der Anfang, und es gibt noch vieles, was Tudorache nachts wach hält. KI werde in allen Branchen und in der gesamten Gesellschaft große Veränderungen herbeiführen. [5]
Sie wird seiner Ansicht nach alles verändern, von der Gesundheitsversorgung über Bildung, Arbeit und Verteidigung bis hin zur menschlichen Kreativität. Die meisten Länder haben noch nicht begriffen, was KI für sie bedeuten wird, sagt Tudorache, und es liegt nun in der Verantwortung der Regierungen, dafür zu sorgen, dass die Bürger und die Gesellschaft im weiteren Sinne für das KI-Zeitalter bereit sind. "Die Crunchtime beginnt jetzt", sagt er.
URL dieses Artikels:
https://www.heise.de/-9678623
Links in diesem Artikel:
[1] https://www.heise.de/news/AI-Act-Mitgliedstaaten-stimmen-Kompromiss-einstimmig-zu-9617206.html
[2] https://www.heise.de/hintergrund/Unsere-letzte-Erfindung-3152050.html
[3] https://www.vice.com/en/article/z34dm3/prominent-ai-philosopher-and-father-of-longtermism-sent-very-racist-email-to-a-90s-philosophy-listserv
[4] https://www.heise.de/news/KI-Regulierung-Wie-Google-und-Microsoft-Stimmung-gegen-den-AI-Act-machen-7531687.html
[5] https://www.heise.de/hintergrund/Arbeit-Bildung-Kunst-Wie-grosse-KI-Modelle-unsere-Gesellschaft-veraendern-8987587.html
[6] https://www.instagram.com/technologyreview_de/
[7] mailto:jle@heise.de
Copyright © 2024 Heise Medien

(Bild: Shutterstock/Phonlamai Photo)
In einer Studie überzeugte GPT-4 Freiwillige in kurzen Online-Chats zu politischen und ethischen Fragen, ihren Standpunkt zu ändern.
Dass von großen Sprachmodellen produzierte Texte Menschen politisch beeinflussen können, ist bereits in verschiedenen wissenschaftlichen Studien gezeigt worden – allerdings waren die Effekte nicht sehr groß [1]. Forschende der Eidgenössischen Polytechnischen Hochschule in Lausanne (EPFL) und der italienischen Forschungseinrichtung Fondazione Bruno Kessler [2] haben nun allerdings herausgefunden, dass GPT-4 im Dialog mit Menschen sehr viel überzeugender sein kann – zumindest unter speziellen Bedingungen. Das Sprachmodell konnte Menschen mit einer Wahrscheinlichkeit von knapp 82 Prozent (81,7 Prozent) häufiger von deren eigenen Standpunkten abbringen, als ein menschlicher Diskussionspartner. Das funktionierte allerdings nur dann so gut, wenn das Sprachmodell persönliche Informationen seines menschlichen Dialogpartners bekam, schreiben Francesco Salvi und Kollegen in einem Paper [3] auf der Preprint-Plattform Arxive.
Für ihre Studie bauten die Forschenden eine Online-Plattform, in der die Teilnehmer einen zufälligen Gesprächspartner – einen anderen Menschen oder ein Sprachmodell – ein Diskussionsthema und die eigene Position zu dem Thema zugewiesen bekamen. Ob Mensch oder Maschine wurde dabei nicht verraten. Die Themen sollten keine speziellen Kenntnisse erfordern und hinreichend kontrovers sein – diskutiert wurden also Fragen wie "Machen Social Media dumm?" oder "Sollten Abtreibungen legal sein?". Zuerst mussten die Testpersonen kurze Fragebogen ausfüllen, in denen sie angaben, wie sie persönlich zu der diskutierten Frage stehen (zustimmend oder ablehnend). Darüber hinaus waren Angaben zu Alter, Geschlecht, Bildungsstand, beruflicher Situation und politischer Orientierung erforderlich. Dann hatten dann die beiden Teilnehmer nacheinander jeweils einige Minuten Zeit ihre Argumente darzulegen, und in einer zweiten Runde auf die Argumente der Gegenseite einzugehen. Zum Schluss wurden sie noch einmal gefragt, wie sie jetzt zu der diskutierten These stehen.
Insgesamt prüften die Forschenden vier mögliche Kombinationen: Mensch diskutiert mit Mensch, Mensch mit Mensch, der persönliche Informationen über sein Gegenüber bekommt, Mensch diskutiert mit KI und und Mensch diskutiert mit KI, die über persönliche Informationen verfügt. Ohne persönliche Informationen schnitt GPT-4 in den Diskussionen nicht besser ab als der menschliche Durchschnitt. Mit mehr persönlichem Kontext nahm die Wahrscheinlichkeit, dass die KI ihre Diskussionspartner überzeugen konnte jedoch um rund 80 Prozent zu. Dabei hatten die Forschenden dem Sprachmodell im Prompt lediglich ganz allgemein aufgegeben, die Informationen zu Alter, Geschlecht etc. zu berücksichtigen, um so den Gesprächspartner besser zu überzeugen.
"Wir betonen, dass der Effekt der Personalisierung besonders aussagekräftig ist, wenn man bedenkt, wie wenig persönliche Informationengesammelt wurden und trotz der relativen Einfachheit der Aufforderung an die LLMs, solche Informationen aufzunehmen", schreiben die Autoren. "Daher könnten böswillige Akteure, die daran interessiert sind die Chatbots für groß angelegte Desinformationskampagnen einzusetzen, noch stärkere Effekte erzielen, indem sie feinkörnige digitale Spuren und Verhaltensdaten ausnutzen". So können LLMs beispielsweise aus Äußerungen psychologische Profile [4] anlegen. "Wir argumentieren, dass Online-Plattformen und soziale Medien solche Bedrohungen ernsthaft in Betracht ziehen sollten und Maßnahmen gegen die Verbreitung von LLM-gesteuerter Überzeugungsarbeit ergreifen."
Wie gut sich die Ergebnisse verallgemeinern lassen, muss allerdings noch geprüft werden. Denn erstens rekrutieren sich die Testpersonen nur aus den USA – die als besonders stark polarisierte Gesellschaft gelten. Und zweitens wurden den Teilnehmern ihre jeweiligen Debatten-Standpunkte zufällig zugewiesen, ohne zu berücksichtigen, ob sie die jeweils wirklich auch teilen. Zudem war der Ablauf der Debatten klar strukturiert und sehr formal – anders als in echten, oft sehr emotionalen und unstrukturierten Online-Diskussionen.
URL dieses Artikels:
https://www.heise.de/-9680085
Links in diesem Artikel:
[1] file:///Users/wst/Downloads/AI_Persuasion_MS_and_SI.pdf
[2] https://www.fbk.eu/en/about-fbk/
[3] https://arxiv.org/pdf/2403.14380.pdf
[4] https://arxiv.org/pdf/2309.08631.pdf
[5] https://www.instagram.com/technologyreview_de/
[6] mailto:wst@technology-review.de
Copyright © 2024 Heise Medien

(Bild: Statista)
In Deutschland ist ein Zuwachs an Wäldern zu verzeichnen. Damit hat sich auch der Anteil an gebundenem CO₂ gesteigert, wie die Infografik zeigt.
Etwa 30 Prozent der Bodenfläche Deutschlands sind von Wäldern bedeckt. Diese Wälder sind nicht nur Lebensraum für Flora und Fauna, sondern sie regulieren auch das Klima in der Bundesrepublik.
Gegenüber 2016 hat sich die Waldfläche der Bundesrepublik um mehr als 50.000 Hektar vergrößert – besonders große Zuwächse gab es in Niedersachsen und Thüringen. Die Statista-Grafik [1] zeigt den Waldanteil nach Bundesländern. Das waldreichste Land ist demnach Rheinland-Pfalz (40,7 Prozent der Gesamtfläche), dicht gefolgt von Hessen (40 Prozent) und Baden-Württemberg (37,9 Prozent). Nur wenige waldbedeckte Flächen gibt es dagegen in Mecklenburg-Vorpommern (21,3 Prozent), Schleswig-Holstein (10,3 Prozent) und den Stadtstaaten.
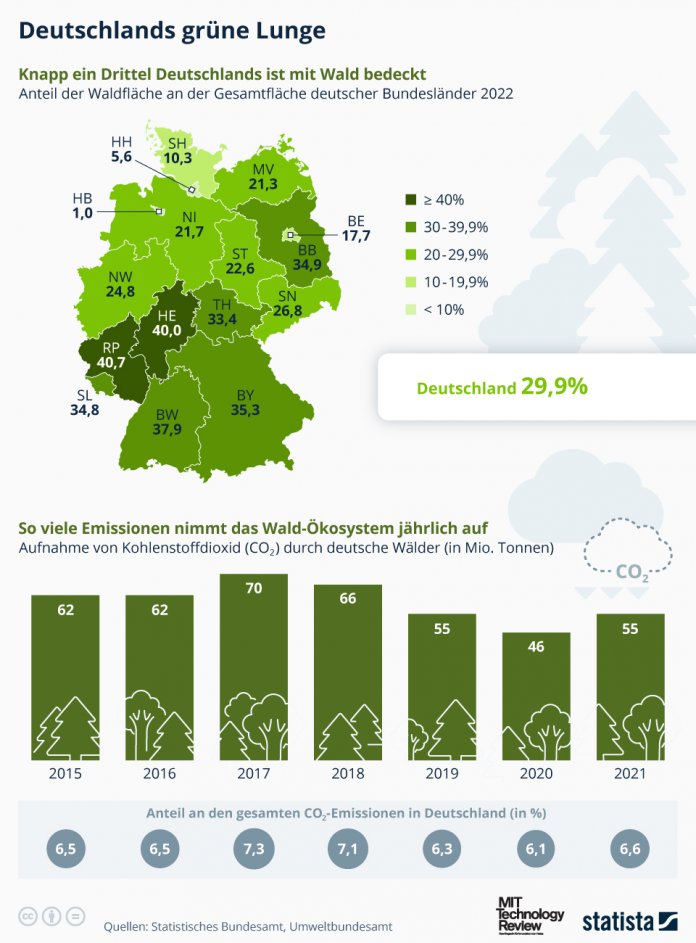
(Bild: Statista)
Nach Angaben des Statistischen Bundesamtes [2] haben die Wälder im Jahr 2021 circa 15 Millionen Tonnen an Kohlenstoff gebunden, was etwa 55 Millionen Tonnen Kohlenstoffdioxid entspricht. Dem gegenüber steht eine Emissionsbilanz von nahezu 829 Millionen Tonnen Kohlendioxid durch private Haushalte und Wirtschaft. Das bedeutet, dass die deutschen Wälder rein rechnerisch knapp sieben Prozent der jährlichen CO₂-Emissionen in Deutschland kompensieren.
Die Kapazität zur CO₂-Aufnahme hat sich im Vergleich zu 2020 etwas gesteigert. Gründe hierfür könnten Aufforstungsmaßnahmen sein, welche auf die Schäden durch Trockenheit und Schädlingsbefall der Vorjahre folgten. Diese zusätzliche Speicherung teilt sich auf das Waldökosystem auf. Besonders hervorzuheben ist jedoch die Speicherung im Waldboden, welcher den Großteil des Kohlenstoffs absorbiert.
URL dieses Artikels:
https://www.heise.de/-9679585
Links in diesem Artikel:
[1] https://de.statista.com/infografik/
[2] https://www.destatis.de/DE/Presse/Pressemitteilungen/Zahl-der-Woche/2024/PD24_12_p002.html
[3] https://www.heise.de/tr/thema/Statistik-der-Woche
[4] https://www.instagram.com/technologyreview_de/
[5] mailto:jle@heise.de
Copyright © 2024 Heise Medien

Wie gut es GPT-4 gelingt, Menschen von ihrer Meinung abzubringen und wie die neue Hyperloop-Teststrecke funktioniert, klären wir in der neuen Podcast-Folge.
Ein Forscherteam hat die Fähigkeiten von GPT-4 in Sachen Meinungsmache geprüft. In einem Experiment haben sie das Sprachmodell gegen Menschen antreten lassen. Das Ziel für die KI war es, die Testpersonen von ihren eigenen Standpunkten abzubringen. Fragestellungen waren zum Beispiel: Sollten Abtreibungen legal sein? oder: Machen Social Media die Menschen dumm? TR-Redakteur Wolfgang Stieler hat sich das Paper dazu angesehen und berichtet, wie erfolgreich GPT-4 in seiner Mission war.
Außerdem im Weekly:
Wenn auch ihr, liebe Zuhörerinnen und Zuhörer, mal Empfehlungen habt für Serien, Bücher, Games, Podcasts oder sonstige Medien, die neu oder irgendwie noch nicht zu dem Ruhm gekommen sind, den sie Eurer Meinung nach verdienen, dann schreibt uns doch eine Mail an info@technology-review.de [2] oder lasst Euren Tipp da auf unseren Social-Media-Konten von MIT Technology Review: Wir sind auf Facebook, Instagram, X, LinkedIn, TikTok und ganz neu: auf Mastodon [3] und Bluesky [4]. Oder kontaktiert uns auf Mastodon persönlich: Wolfgang Stieler [5], Gregor Honsel [6], Jenny Lepies [7].
Mehr dazu in der ganzen Folge – als Audio-Stream (RSS-Feed [8]):
URL dieses Artikels:
https://www.heise.de/-9679537
Links in diesem Artikel:
[1] https://www.heise.de/hintergrund/Hyperloop-Was-die-neue-Teststrecke-mit-Weiche-kann-9676370.html
[2] mailto:info@technology-review.de
[3] https://social.heise.de/@techreview_de
[4] https://bsky.app/profile/technologyreview.de
[5] https://social.tchncs.de/@wstieler
[6] https://social.heise.de/@ghonsel
[7] https://mstdn.social/@Kultanaamio
[8] https://tech2go.podigee.io/feed/mp3
[9] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[10] https://podcasts.apple.com/de/podcast/tech2go-der-technology-review-podcast/id1511589900
[11] https://www.heise.de/tr/rss/tech2go.rss
[12] https://open.spotify.com/show/5sQ717mamQbJVvvOZT6p2y
[13] https://www.heise.de/thema/mit-technology-review-podcast
[14] https://www.instagram.com/technologyreview_de/
[15] mailto:jle@heise.de
Copyright © 2024 Heise Medien

François Englert (links) und Peter Higgs auf der Konferenz, auf der das CERN 2012 erste Ergebnisse zum Nachweis des Higgs-Bosons vorstellte.
(Bild: CERN)
Der britische Physiker Peter W. Higgs ist gestorben. Für die Theorie der "Herkunft von Masse" erhielt er gemeinsam mit François Englert 2013 den Nobelpreis.
Worüber denken Sie beim Wandern nach? Peter Ware Higgs dachte dabei vor sechzig Jahren über Grundlagen der Elementarteilchenphysik nach, und entwickelte die revolutionäre Theorie eines bestimmten omnipräsenten Feldes. Beim Urknall, so die Theorie, sind unterschiedliche Elementarteilchen entstanden, allesamt masselos. Einen Sekundenbruchteil später haben bestimmte Teilchen mit dem Feld interagiert und sich dabei Masse "zugezogen". Nicht alle – zum Beispiel gelten Photonen (Lichtteilchen) im Standardmodell der Elementarteilchenphysik als masselos. Dank Masse gibt es Quarks, Atome und damit das Universum, wie wir es wahrnehmen können.
Higgs Idee war so radikal, dass die europäische Fachzeitschrift Physics Letters die Publikation von Higgs Text ablehnte. Bei der US-amerikanischen Publikation Physical Review Letters hatte der 1929 im englischen Newcastle upon Tyne geborene Mann mehr Glück. Doch war der Brite mit seiner Idee nicht alleine. Ungefähr zur gleichen Zeit hatten andere Physiker sehr ähnliche Ideen. Das waren die in Brüssel tätigen Physiker Robert Brout und François Englert sowie die in London forschenden Gerald Guralnik, Carl R. Hagen und Thomas W. B. Kibble. Somit erschienen innerhalb weniger Wochen gleich drei Aufsätze zum Thema in den Physical Review Letters.
Sie beschreiben, wie die winzigen Bausteine des Universums, die Materieteilchen, ihre Masse erhalten. Vereinfacht ausgedrückt fungiert das Higgs-Feld wie eine kosmische Sirupflasche von der Größe des gesamten Universums. Bewegen sich Teilchen durch das Feld, bleibt der "Sirup" an ihnen haften und verleiht ihnen ihre Masse.
Brout und Englerts Arbeit wurde vor Higgs’ Beitrag abgedruckt, weil die beiden vor Higgs eingereicht hatten. Dennoch setzte sich später Higgs Name als Bezeichnung für das Higgs-Feld durch. Und weil in der Quantenfeldtheorie die Interaktion eines Elementarteilchens mit einem Feld eine Welle zeigt, und jede Welle in einem Feld auch als subatomares Teilchen beschrieben werden kann (sie bewegen sich wie Wellen, tauschen Energie aber wie Teilchen aus), muss es ein entsprechendes Teilchen geben: Das Brout-Englert-Higgs-Teilchen, das zur Teilchenart der Bosonen zählt (Wechselwirkungsteilchen, nicht Materieteilchen). Bekannt geworden ist es als Higgsches Boson oder Higgs-Boson.
Das Problem: Der Nachweis ist nicht simpel, zumal die Higgs-Teilchen nicht nur subatomar, sondern auch sehr instabil sind. Nach Bildung zerfallen sie ~sofort wieder, und dieser Verfall kann zu unterschiedlichen Teilchen als Zerfallsprodukt führen. Zunächst waren die Theorien zu Higgs-Feld und -Boson umstritten. Erst 48 Jahre nach Veröffentlichung der wissenschaftlichen Theorien gelang der experimentelle Nachweis.
Damals, 2012, konnten Physiker am europäischen Kernforschungszentrum CERN das "neue" Higgs-Boson nachweisen [1]. Da war Brout bereits verstorben, Higgs und Englert emeritiert. Im Jahr darauf erhielten die beiden Letztgenannten für ihre Theorie mit den Higgs-Bosonen den Physiknobelpreis [2]. Weitere zwei Jahre später folgte die Copley-Medaille. Die komplette Liste der Auszeichnungen und Ehren ist ellenlang, die Erhebung in den Adelsstand als Sir soll Higgs allerdings aus grundsätzlichen Erwägungen abgelehnt haben.
Populärwissenschaftlich wird das Higgs-Boson auch als "Gottesteilchen" bezeichnet. Diese Bezeichnung lehnte der Atheist Higgs ab. Zudem betonte er, dass die Entwicklung der berühmten Theorie nur ein sehr kleiner Teil seines Lebenswerks gewesen sei.
Nun ist sein Lebenswerk zu Ende. Am Montag ist Higgs im Alter von 94 Jahren in Schottland verstorben. Er hinterlässt seine um sieben Jahre jüngere Witwe Jody sowie zwei Söhne.
URL dieses Artikels:
https://www.heise.de/-9679774
Links in diesem Artikel:
[1] https://www.heise.de/news/Higgs-Boson-CERN-weist-neues-Elementarteilchen-nach-1631922.html
[2] https://www.heise.de/news/Physik-Nobelpreis-fuer-Higgs-Boson-1974686.html
[3] mailto:ds@heise.de
Copyright © 2024 Heise Medien

Schwarz auf weiß: Die Marken t3n und MIT Technology Review sind unter einem Dach.
(Bild: MIT Technology Review)
Zwei starke Marken, eine starke Tech-Berichterstattung: Ab 15. April finden die Inhalte der MIT Technology Review auf t3n.de statt. Das sind die Hintergründe.
Das Magazin und Online-Portal t3n bekommt Zuwachs: Ab sofort sind neben t3n-Artikeln auch Texte der MIT Technology Review auf t3n.de [1] zu lesen. Das passt deshalb so gut zusammen, weil beide Marken ähnliche Themen aufgreifen, diese aber aus unterschiedlichen journalistischen Perspektiven beleuchten. Während sich t3n vor allem mit aktuellen Entwicklungen in der digitalen Wirtschaft beschäftigt, berichtet MIT Technology Review über die neuesten technologischen und wissenschaftlichen Trends, die das Potenzial haben, unsere Gesellschaft und unser Leben zu verändern.
Ein gutes Beispiel ist das aktuelle Trend-Thema schlechthin: Künstliche Intelligenz. t3n zeigt in der täglichen Berichterstattung auf [2], welche neuen Systeme auf den Markt kommen, wie sie sich voneinander unterscheiden und wie Einzelpersonen und Unternehmen KI sinnvoll einsetzen können. MIT Technology Review erklärt die Hintergründe: Wie funktionieren große Sprachmodelle wie GPT oder Claude eigentlich genau? Was sind die nächsten Entwicklungsschritte? Und welchen Einfluss hat KI auf Wirtschaft, Arbeit und Gesellschaft?
In der engeren Zusammenarbeit unter einem Dach erreichen wir gemeinsam eine breitere Leserschaft und können ihre Bedürfnisse besser bedienen. Denn es wird immer wichtiger, zu einzelnen Themen und Nachrichten die Hintergründe zu verstehen. Was bedeuten einzelne technische Durchbrüche wirklich? Trends zu identifizieren, aber auch ihre Relevanz und Bedeutungen zu bewerten – das wollen wir in Zukunft noch stärker tun als bisher.
Die Artikel der MIT Technology Review erscheinen im News-Stream von t3n.de und sind an einem kleinen Label an der Überschrift zu erkennen. Unter t3n.de/technology-review sind alle Artikel der MIT Technology Review zu finden, die auf t3n.de veröffentlicht werden. Damit verlässt die MIT Technology Review das Portal heise online und wird inhaltlicher Bestandteil von t3n.de.
Zum Hintergrund: Die MIT Technology Review ist die deutsche Lizenzausgabe der US-amerikanischen Zeitschrift [3], die seit 130 Jahren am weltberühmten technischen Institut MIT in Boston erscheint. Als unabhängiges wissenschaftsjournalistisches Medium hat es sich die Marke zur Aufgabe gemacht, wissenschaftliche Erkenntnisse und technische Trends einem breiten Publikum zu vermitteln.
URL dieses Artikels:
https://www.heise.de/-9677845
Links in diesem Artikel:
[1] https://t3n.de/
[2] https://t3n.de/tag/kuenstliche-intelligenz/
[3] https://www.technologyreview.com/
[4] https://www.instagram.com/technologyreview_de/
[5] mailto:lca@heise.de
Copyright © 2024 Heise Medien

Nokia und Vodafone drücken in einem Glasfasernetz die Latenz mit dem Buffer-Manager L4S deutlich. Das soll bald Echtzeit-Anwendungen beflügeln.
Geringere Latenz bei Datenübertragungen soll das neue Verfahren L4S (Low Latency Low Loss Scalable) bescheren. Theoretisch. Nokia Bell Labs meldet nun praktischen Fortschritt: Die Nokia-Tochter hat nach eigenen Angaben die weltweit erste Ende-zu-Ende-Demonstration von L4S (Low Latency Low Loss Scalable) durchgeführt. Latenz beschreibt die Laufzeit eines Datenpakets und wird generell in Millisekunden angegeben.
L4S soll durch besseres Management von Warteschlangen (Buffer) die Gesamtlatenz senken. Genutzt wurde ein gängiger Glasfaseranschluss in Form eines passiven optischen Netzwerks (PON) in einem Testzentrum Vodafones im britischen Newbury. Dabei sei es gelungen, die Übertragungsverzögerung deutlich zu verkürzen: "Über eine maximal ausgelastete WLAN-Breitbandverbindung verringerte sich die Zugriffszeit auf eine Internetseite von 550 auf 12 Millisekunden", teilten die Unternehmen am Montag mit. "Die Latenz reduzierte sich auf 1,05 Millisekunden, wenn anstelle von WLAN ein Ethernet-Kabel verwendet wurde."
Bei dem Test sei ein handelsüblicher Laptop samt Glasfaseranschluss genutzt worden. Prinzipiell kann bereits eine Signallaufzeit von 100 Millisekunden bei kritischen bildlastigen Anwendungen zu einer spürbaren Verzögerung führen.
Die Beteiligten werten ihren Versuch daher als vollen Erfolg. Er zeigt für Tanja Richter, Netz-Chefin bei Vodafone Deutschland, "dass Echtzeit-Kommunikation auch unter schwierigen Bedingungen in einem stark belasteten Netz technisch möglich ist". Die Managerin geht davon aus, dass L4S in einigen Jahren in deutschen FTTH-, TV-Kabel- und Mobilfunk-Infrastrukturen verwendbar sein wird. Das mache – bei entsprechender Weiterentwicklung – verzögerungsfreies Online-Gaming, Videokonferenzen sowie Echtzeit-Anwendungen im Bereich der Telemedizin und beim autonomen Fahren realistisch.
L4S ist eine Entwicklung der Nokia Bell Labs. Die Technik wird von der Standardisierungsorganisation Internet Engineering Task Force (IETF) unterstützt [1] und soll künftig unerwünschte Verzögerungen bei der Datenübertragung reduzieren. Der aktuelle Test mit einem optischen PON-Leitungsterminal (OLT), mehreren optischen PON-Netzwerkterminals (ONTs) und WLAN-Zugangspunkten hat den Beteiligten zufolge [2] "extrem niedrige und konsistente Ende-zu-Ende-Latenzen bei der Übertragung durch jedes Element des Netzwerks" veranschaulicht. Dabei habe L4S durchgängig eine "Paketwarteschlangenverzögerung von nahezu null" erreicht, unabhängig von der Verkehrslast im Netzwerk.
L4S kann über jede beliebige Zugangsverbindung zum Internet verwendet werden. Im November haben Nokia Bell Labs und der auf Lösungen für erweiterte Realität (XR) spezialisierte Anbieter Hololight bereits einen Machbarkeitsnachweis erbracht [3], wonach der Beschleuniger mehrere gleichzeitige XR-Nutzer über dieselbe drahtlose Verbindung ohne Leistungseinbußen unterstützen kann. Das Berliner Start-up Vay hat vor einem guten Jahr mit der Deutschen Telekom und Ericsson über 5G gezeigt [4], dass L4S die Signallaufzeiten auch bei Netzauslastung prinzipiell niedrig genug zum Fernsteuern von Autos halten kann. Konzerne wie Comcast, Nvidia, Apple und Google setzen ebenfalls auf die Technik.
URL dieses Artikels:
https://www.heise.de/-9678539
Links in diesem Artikel:
[1] https://datatracker.ietf.org/doc/rfc9330
[2] https://www.vodafone.com/news/technology/no-lag-gaming-vodafone-and-nokia-test-new-technology-to-eliminate-gaming-and-video-lag
[3] https://www.nokia.com/about-us/news/releases/2023/11/02/nokia-collaborates-with-hololight-to-deliver-reliable-immersive-xr-experiences-with-latency-improving-technology-l4s
[4] https://www.heise.de/news/Vay-Telefahr-Auto-von-Barcelona-aus-durch-Berlin-gesteuert-7529750.html
[5] mailto:ds@heise.de
Copyright © 2024 Heise Medien

(Bild: New Africa/Shutterstock.com)
In .NET 8.0 existiert mit der abstrakten Klasse TimeProvider ein einfacher Weg, Zeitangaben inklusive Zeitzone beliebig im Rahmen von Tests vorzutäuschen.
In der Basisklassenbibliothek hat Microsoft .NET 8.0 mit der abstrakten Klasse TimeProvider eine einfache Möglichkeit ergänzt, Zeitangaben inklusive Zeitzone beliebig im Rahmen von Tests vorzutäuschen.
Eine Abstraktion für die aktuelle Zeit anstelle der Nutzung von System.DateTime.Now, System.DateTime.UtcNow und System.DateTimeOffset.Now haben schon viele Entwicklerinnen und Entwickler geschrieben, denn echte Unit Tests für Programmcode, der von der Zeit oder dem Datum abhängig ist, braucht eine Abstraktion. Ansonsten müsste man bis zu einer bestimmten Uhrzeit oder einem Datum warten, um die Tests zu starten.
Microsoft liefert in .NET 8.0 nun eine eingebaute Abstraktion. Auch die Zeitangaben in Task.Delay() und Task.Async() können darauf zurückgreifen.
Das folgende Listing zeigt mehrere Aspekte:
TimeProvider.System liefert einen TimeProvider mit der realen Zeit laut Systemuhr.FakeTimeProvider ist eine Klasse von Microsoft, die im NuGet-Paket Microsoft.Extensions.TimeProvider.Testing [1] geliefert wird. Diese Klasse erlaubt eine feste Zeitvorgabe, die man manuell mit Advance() unter Angabe eines TimeSpan-Objekts oder bei jedem Auslesen vorstellen kann, beispielsweise fakeTime.AutoAdvanceAmount = TimeSpan.FromHours(1).class FCL_TimeProvider
{
public async Task Run()
{
void PrintTime(TimeProvider timeProvider)
{
Console.Write("Lokale Zeit: " + timeProvider.GetLocalNow());
Console.WriteLine(" | UTC: " + timeProvider.GetUtcNow());
}
void Callback(TimeProvider timeProvider)
{
Console.WriteLine("Time mit " + timeProvider.GetType());
PrintTime(timeProvider);
}
CUI.H2("Reguläre Systemzeit");
PrintTime(TimeProvider.System);
// https://www.nuget.org/packages/\
// Microsoft.Extensions.TimeProvider.Testing/
CUI.H2("Vorgetäuschte Zeit Time-Provider aus “+
“Microsoft.Extensions.TimeProvider.Testing");
var fakeTime = new
FakeTimeProvider(new(DateTime.Parse("14.11.2023 18:00:00")));
PrintTime(fakeTime); // 14.11.2023 18 Uhr
Console.WriteLine("Wir stellen die Zeit nun 30 Minuten vor");
fakeTime.Advance(TimeSpan.FromMinutes(30));
// 14.11.2023 18:30 Uhr:
Console.WriteLine("UTC: " + fakeTime.GetUtcNow());
Console.WriteLine("Wir stellen die Zeit bei jedem Lesen " +
"der Zeit 1 Stunde vor");
fakeTime.AutoAdvanceAmount = TimeSpan.FromHours(1);
// 14.11.2023 19:30 Uhr:
Console.WriteLine("UTC: " + fakeTime.GetUtcNow());
// 14.11.2023 20:30 Uhr:
Console.WriteLine("UTC: " + fakeTime.GetUtcNow());
// 14.11.2023 21:30 Uhr:
Console.WriteLine("UTC: " + fakeTime.GetUtcNow());
async Task Wait5Seconds(TimeProvider t)
{
CUI.Cyan("Warten beginnt");
PrintTime(TimeProvider.System);
await t.Delay(new TimeSpan(0, 0, 6));
// oder
//await Task.Delay(new TimeSpan(0, 0, 5), fakeTimeProvider);
PrintTime(TimeProvider.System);
CUI.Cyan("Warten beendet!");
}
CUI.H2("6 Sekunden warten auf TimeProvider.System");
await Wait5Seconds(TimeProvider.System);
CUI.H2("6 Sekunden warten auf FakeTimeProvider von Microsoft");
var ErhoeheZeitNachEinerSekundeUm10Sekunden = async () =>
{
await Task.Delay(new TimeSpan(0, 0, 1));
fakeTime.Advance(TimeSpan.FromSeconds(10));
};
#pragma warning disable CS4014
ErhoeheZeitNachEinerSekundeUm10Sekunden();
#pragma warning restore CS4014
//--> das endet nie, wenn man Advance() nicht aufruft!:
await Wait5Seconds(fakeTime);
}
}
URL dieses Artikels:
https://www.heise.de/-9675891
Links in diesem Artikel:
[1] https://www.nuget.org/packages/Microsoft.Extensions.TimeProvider.Testing
[2] https://net.bettercode.eu/
[3] https://net.bettercode.eu/tickets.php
[4] mailto:rme@ix.de
Copyright © 2024 Heise Medien
 [6]
[6] [6]
[6] [5]
[5] [4]
[4] [14]
[14] [4]
[4]