
(Bild: Daniel Tadevosyan/Shutterstock.com)
Eine Menge des Typs FrozenSet gewinnt beim tausendmaligen Aufruf von Contains() gegenüber anderen Objektmengen.
Im vorherigen Teil dieser Serie [1] habe ich die Klasse FrozenSet<T> im Namensraum System.Collections.Frozen vorgestellt, die neu in .NET 8.0 ist. Es stellt sich die Frage, warum denn Microsoft FrozentSet<T> zusätzlich eingeführt hat. Die Antwort der Frage ist – wie so oft – Performance.
Diesmal bewerte ich anhand eines typischen Einsatzbeispiels die Geschwindigkeit.
Gegeben sei eine unsortierte Menge der Zahlen zwischen 1 und 10.000. Wie schnell kann man eine einzelne Zahl in der Menge finden?
Für die Leistungsmessung kommt die Bibliothek BenchmarkDotNet von Microsoft [2] zum Einsatz.
using System.Collections.Frozen;
using System.Collections.Immutable;
using System.Collections.ObjectModel;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Jobs;
using BenchmarkDotNet.Toolchains.InProcess.NoEmit;
namespace NET8_Console.Collections_Benchmark;
public class AntiVirusFriendlyConfig : ManualConfig
{
public AntiVirusFriendlyConfig()
{
AddJob(Job.MediumRun
.WithToolchain(InProcessNoEmitToolchain.Instance));
}
}
[Config(typeof(AntiVirusFriendlyConfig))]
public class Collections_Contains_Benchmark
{
private const int Iterations = 1000;
private readonly List<int> list;
private readonly ReadOnlyCollection<int> roCollection;
private readonly FrozenSet<int> frozenSet;
private readonly HashSet<int> hashSet;
private readonly ImmutableList<int> immutableList;
private readonly ImmutableHashSet<int> immutableHashSet;
public Collections_Contains_Benchmark()
{
var array = Enumerable.Range(1, 10000).ToArray();
Random.Shared.Shuffle<int>(array);
list = array.ToList();
// liefert ReadOnlyCollection<T>:
roCollection = list.AsReadOnly();
frozenSet = list.ToFrozenSet();
hashSet = list.ToHashSet();
immutableList = list.ToImmutableList();
immutableHashSet = list.ToImmutableHashSet();
}
[Benchmark(Baseline = true)]
public void ListContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = list.Contains(i);
}
}
[Benchmark]
public void ReadOnlyCollectionContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = roCollection.Contains(i);
}
}
[Benchmark]
public void FrozenSetContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = frozenSet.Contains(i);
}
}
[Benchmark]
public void HashSetContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = hashSet.Contains(i);
}
}
[Benchmark]
public void ImmutableListContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = immutableList.Contains(i);
}
}
[Benchmark]
public void ImmutableHashSetContains()
{
for (var i = 0; i < Iterations; i++)
{
var b = immutableHashSet.Contains(i);
}
}
}
Der in der folgenden Abbildung dargestellte Benchmark ruft 1000-mal die Methode Contains() auf einer unsortierten Liste mit 10.000 Zahlen auf. Die Menge des Typs FrozenSet gewinnt beim 1000-maligen Aufruf von Contains() gegenüber anderen Objektmengen.

(Bild: Screenshot (Holger Schwichtenberg))
URL dieses Artikels:
https://www.heise.de/-9649523
Links in diesem Artikel:
[1] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[2] https://github.com/dotnet/BenchmarkDotNet
[3] https://www.heise.de/blog/Neu-in-NET-8-0-1-Start-der-neuen-Blogserie-9574680.html
[4] https://www.heise.de/blog/Neu-in-NET-8-0-2-Neue-Anwendungsarten-9581213.html
[5] https://www.heise.de/blog/Neu-in-NET-8-0-3-Primaerkonstruktoren-in-C-12-0-9581346.html
[6] https://www.heise.de/blog/Neu-in-NET-8-0-4-Collection-Expressions-in-C-12-0-9581392.html
[7] https://www.heise.de/blog/Neu-in-NET-8-0-5-Typaliasse-in-C-12-0-9594693.html
[8] https://www.heise.de/blog/Neu-in-NET-8-0-6-ref-readonly-in-C-12-0-9602188.html
[9] https://www.heise.de/blog/Neu-in-NET-8-0-7-Optionale-Parameter-in-Lambda-Ausdruecken-in-C-12-0-9609780.html
[10] https://www.heise.de/blog/Neu-in-NET-8-0-8-Verbesserungen-fuer-nameof-in-C-12-0-9616685.html
[11] https://www.heise.de/blog/Neu-in-NET-8-0-9-Neue-und-erweiterte-Datenannotationen-9623061.html
[12] https://www.heise.de/blog/Neu-in-NET-8-0-10-Plattformneutrale-Abfrage-der-Privilegien-9630577.html
[13] https://www.heise.de/blog/Neu-in-NET-8-0-11-Neue-Zufallsfunktionen-9637003.html
[14] https://www.heise.de/blog/Neu-in-NET-8-0-12-Eingefrorene-Objektmengen-9643310.html
[15] https://www.heise.de/blog/Neu-in-NET-8-0-12-Leistung-von-FrozenSet-9649523.html
[16] https://www.heise.de/blog/Neu-in-NET-8-0-14-Neue-Waechtermethoden-fuer-Parameter-9656153.html
[17] https://www.heise.de/blog/Neu-in-NET-8-0-15-Geschluesselte-Dienste-bei-der-Dependency-Injection-9662004.html
[18] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: peampath2812/Shutterstock.com)
Die JavaLand-Konferenz steht kurz bevor, wir haben mit einigen Community-Vertretern über die Konferenz gesprochen.
Zum runden JavaLand-Jubiläum haben wir mit Gregor Trefs, Sandra Ahlgrimm, Thomas Much und Gerd Aschemann gesprochen. Sie berichten über ihre bisherigen Erfahrungen und warum sie auch in diesem Jahr wieder dabei sein werden.
Javaland 2024 - Warum bist du dabei?
Gregor Trefs: Meinen ersten Vortrag auf einer Konferenz habe ich tatsächlich auf dem JavaLand [1] gehalten. Und über mehrere Jahre hinweg habe ich zusammen mit Falk einen Workshop durchgeführt, der Java-Programmierern die Grundlagen der funktionalen Programmierung näherbringen sollte. Die Offenheit und positive Atmosphäre der Veranstaltung haben mich immer beeindruckt. Die lebhaften Diskussionen und vielfältigen Perspektiven empfinde ich als äußerst bereichernd. Deshalb habe ich in diesem Jahr eine Deep Dive Session zum Thema "Stateful Property Based Testing und Refactoring" eingereicht. Über einfache Beispiele hinaus zeige ich, wie Property Based Testing in zustandsbehafteten Umgebungen eingesetzt werden kann und wie man jqwik geschickt für Refactoring-Zwecke nutzt.
Sandra Ahlgrimm: Mit die wichtigste Java-Community-Konferenz wollte ich nicht verpassen.
Thomas Much: JavaLand macht einfach Spaß! Die lockere Atmosphäre, die abwechslungsreichen Formate, die Speaker und Teilnehmer aus dem In- und Ausland – das ist jedes Jahr wieder schön zu erleben, und zwar sowohl als Teilnehmer als auch als Speaker. Die Lockerheit und Vielfalt trägt vielleicht auch dazu bei, dass man nicht nur alte Bekannte gerne wieder trifft, sondern dass man auch regelmäßig mit neuen Menschen in den Austausch kommt.
Außerdem findet das JavaLand immer früh im Jahr statt, nach der Winter-Verschnaufpause, wenn der persönliche Akku wieder aufgeladen ist und die neuen Ideen sprudeln. Mit der Verschiebung in diesem Jahr ist das gerade noch so im Zeitrahmen.
Gerd Aschemann: JavaLand ist für mich immer einer der Höhepunkt des Konferenzjahres. Ich freue mich neben spannenden Vorträgen vor allem auch auf die abwechslungsreichen Community-Events. Ich genieße es, mit Gleichgesinnten Neues zu entdecken und mich in entspannter Atmosphäre austauschen zu können.
Dieses Jahr feiert das Javaland sein 10-jähriges Bestehen. Du bist ja jetzt schon seit einigen Jahren quasi Stammgast. Wie hat sich das JavaLand in den 10 Jahren entwickelt?
Gregor Trefs: Seit meinem ersten Besuch im Jahr 2016 hat sich das JavaLand wirklich gut entwickelt. Die Anzahl der Besucher ist gestiegen, es gibt mehr Attraktionen und Highlights im Rahmenprogramm. Die Möglichkeit, Vorträge online zu verfolgen, macht die Teilnahme flexibler. Es ist schön zu sehen, wie die Konferenz wächst und sich weiterentwickelt.
Sandra Ahlgrimm: Meine erste JavaLand-Konferenz musste noch als CyberLand abgehalten werden. Nun habe ich sie bereits im Phantasialand erlebt und bin gespannt, was der neue Standort bereithält. Thematisch war die JavaLand-Konferenz schon immer topaktuell. Daher freue ich mich auch dieses Jahr wieder auf spannende „Aimpulse“.
Thomas Much: Ich bin seit 2016 dabei, die ersten beiden Jahre habe ich also (leider!) verpasst. Größer geworden ist es auf jeden Fall! Gleich geblieben ist die Quirligkeit; man spürt förmlich die Energie auf dem Konferenzgelände. Und damit diese Energie erhalten bleibt, muss sich die Konferenz in vielen kleinen, vielleicht gar nicht so auffälligen Dingen weiterentwickelt haben.
Eine Entwicklung möchte ich dann aber doch hervorheben: Das Newcomer-Programm, bei dem erstmaligen Konferenz-Speakern eine Bühne geboten wird, damit sie Erfahrung sammeln können. Das sorgt für Bodenhaftung bei der Konferenz, bietet den Zuhörern Abwechslung (die Newcomer-Vorträge waren in den letzten Jahren absolut sehenswert!) – und nebenbei zieht sich das JavaLand dadurch die nächste Generation Top-Speaker heran.
Besonders freut mich, dass ich dieses Jahr meinem Kollegen Karl als Newcomer-Mentor zur Seite stehen darf. Karl bringt Bühnenerfahrung als Musiker mit, das merkt man bei den Vorbereitungen. Nun zu erleben, wie akribisch er sich auf seinen ersten Konferenzvortrag vorbereitet, lässt jedem Mentor das Herz aufgehen (@Karl: No pressure! 😉)
Gerd Aschemann: Die JavaLand-Konferenz war schon von Anfang an auf einem hohen Niveau, hat aber auch immer wieder Neues gewagt, manches hat funktioniert, anderes auch mal nicht. Es ist wie im realen Leben der Softwareentwicklung: JavaLand stößt immer wieder in unbekannte Regionen des kollaborativen Austauschs vor. Besonders freue ich mich, dass letztes Jahr unsere “Unkonferenz in der Konferenz” so besonders gut ankam, dass alle Beteiligten quasi von Tobias und mir verlangt haben, dass wir das wiederholen.
Das JavaLand hat dieses Jahr ja eine neue Location. Wie sind hier deine Erwartungen?
Gregor Trefs: Ich bin neugierig darauf, wie JavaLand am Nürburgring ablaufen wird. Ich kann mir gut vorstellen, dass die Wege zu den verschiedenen Vortragsorten jetzt etwas kürzer ausfallen werden im Vergleich zum Phantasialand, wo man am Ende des Tages oft genug seine 10.000 Schritte erreicht hatte. In Bezug auf Konferenzen habe ich immer die Erwartung, etwas Neues zu lernen, selbst wenn es nur eine Kleinigkeit ist. Außerdem war ich bisher noch nie am Nürburgring und bin wirklich gespannt darauf, die Rennstrecke zu erleben.
Sandra Ahlgrimm: Es wird schwierig sein, mit dem Phantasialand mitzuhalten - aber unmöglich ist es nicht!
Thomas Much: Ich hoffe, dass auch die neue Location am Nürburgring einen kreativen Rahmen zum Lernen und Netzwerken bietet – gerne wieder mit einer Mischung von drinnen und draußen, von großen Vortragssälen, wuseligen Plätzen und ruhigen Rückzugsmöglichkeiten. Und wenn am Abend wieder ein nettes Get-together mit guter Musik geboten wird, habe ich da auch nichts gegen.
Die Anfahrt ist allerdings für einen ÖPNV- und Bahnfahrer wie mich in diesem Jahr eine besondere Herausforderung, zumindest fühlt sich das ein wenig so an. Ich habe aber volles Vertrauen in das Orga-Team, dass das mit den Shuttle-Bussen hin und zurück gut klappen wird (und natürlich habe ich meine Shuttle-Tickets schon gekauft).
Alles in allem: Ich erwarte nichts weniger, als dass es einfach wieder richtig gut wird.
Gerd Aschemann: Es ist natürlich ein wenig schade, dass wir hier das gewohnte Umfeld mit seinen Attraktionen, Fahrgeschäften und Plätzen zum Austausch (Cafés, Hackergarten, …) verlassen. Da wir im Vorfeld Räume für unsere eigene Community-Veranstaltung gesucht haben, konnte ich mir aber einen sehr guten Überblick über die Location verschaffen, die viele neue Optionen bietet. Ich freue mich, dass die JavaLand auch hier offen ist.
Das JavaLand versucht sich, als Communty-Konferenz ja immer wieder von anderen Konferenzen abzuheben. Was fällt dir in diesem Zusammenhang besonders auf?
Gregor Trefs: Das JavaLand bemüht sich immer sehr um Feedback, nimmt Kritik an, probiert sich stetig zu verbessern und experimentiert. Ein Jahr blieb in meiner Erinnerung haften, als hinter dem Karussell ein eigens für die Community konzipiertes Zelt aufgebaut wurde. Aufgrund der doch kühlen Märztemperaturen wurde es, im nächsten Jahr, wieder entfernt. Dennoch empfand ich es als bemerkenswert, dass dieses Experiment eingegangen wurde, um aus den gewohnten Mustern auszubrechen.
In den iJUG-Versammlungen wird transparent über bestehende Herausforderungen berichtet und welche Unterstützung benötigt wird. Die engagierte Betreuung der User Groups durch das JavaLand beeindruckt mich besonders. Es gibt das JUG Café, wo man mit verschiedenen Java User Groups in Kontakt kommen kann. Nicht zu vergessen ist, dass der gesamte Stream von der Community gestaltet wird. So eine Beteiligung der Community bietet meines Erachtens keine andere Konferenz.
Sandra Ahlgrimm: Die Wahl der Location ist außergewöhnlich. Leider ist der Zeitraum dieses Jahr etwas ungünstig gewählt, da sie mit einer großen anderen Java Community-Konferenz zusammenfällt (Anmerkung der Redaktion: Das ist dem Weggang aus dem Phantasialand geschuldet).
Thomas Much: Es gibt Community-Events! Und zwar, ohne dass es nur "Open Space" oder andere Formate sind, bei denen sich alle – aber eher spontan – einbringen können. Sondern fest eingeplante, vorbereitete Events, bei denen in kleineren Runden oft sehr spezielle Themen diskutiert und ausprobiert werden. Und obwohl klar ist, dass diese Events keine Massen anziehen, bleiben sie seit Jahren im Programm und tragen auch dadurch zur Vielfalt vom JavaLand bei.
Gerd Aschemann: Die Community bedeutet für mich, dass Leute mit unterschiedlichsten Erfahrungen aufeinandertreffen und zu einem Austausch kommen. Die JavaLand-Konferenz hat von ihrem Aufbau und den abwechslungsreichen Veranstaltungsformen her immer schon diesen Austausch besonders gefördert.
Vielen Dank fürs Beantworten der Fragen. Wir freuen uns auf das Wiedersehen bei der JavaLand-Konferenz vom 09. bis 11. April 2024 [2] erstmals am Nürburgring.
URL dieses Artikels:
https://www.heise.de/-9621993
Links in diesem Artikel:
[1] https://www.javaland.eu/de/home/
[2] https://www.javaland.eu/de/home/
[3] mailto:rme@ix.de
Copyright © 2024 Heise Medien

Progressive Web Apps bleiben in der EU-Ausgabe von iOS nun doch erhalten.
(Bild: Apple)
Apple wird PWAs in der EU-Version von iOS doch nicht abschalten. Zuvor unterzeichneten fast 5.000 Personen und Organisationen einen offenen Brief an Tim Cook.
Mit iOS 17.4 sollte für Anwender innerhalb der Europäischen Union die Möglichkeit entfallen, Webanwendungen auf dem Home-Bildschirm des Gerätes zu installieren [1]. Damit hätten Entwickler von Webanwendungen Zugriff auf kritische Funktionen verloren, darunter die Möglichkeit, Web-Apps vollflächig anzuzeigen, Pushbenachrichtigungen an die Anwender zu senden oder Badges auf dem Homebildschirm-Icon darzustellen [2]. Eine ausführliche Übersicht bietet Thomas Steiners Artikel: So, what exactly did Apple break in the EU? [3]
Nun hat Apple eingelenkt und angekündigt, dass Homescreen-Web-Apps in der EU doch erhalten bleiben [4]. Entwickler können davon ausgehen, dass mit der finalen Ausgabe von iOS 17.4 die Möglichkeit, Webanwendungen auf dem Home-Bildschirm hinzuzufügen, wieder vorhanden sein wird. In den Beta-Versionen von iOS 17.4 wurde die Funktion für EU-Nutzer entfernt.
Begründet wurde die ursprüngliche Entscheidung durch die Änderungen im Rahmen des Digital Markets Act (DMA) der EU. Das Gesetz über digitale Märkte verpflichtet Apple zur Öffnung seines Betriebssystems iOS für alternative App-Stores und Browser-Engines. Bei iPadOS ändert sich zunächst nichts [5].
Apple argumentierte, dass es das Sicherheitsmodell von iOS derzeit nicht zulasse, die Installation von Webanwendungen durch fremde Browser-Engines zu ermöglichen und wollte die Funktion daher grundsätzlich abschalten.
Als Kompromiss bleiben installierbare Webanwendungen in iOS nun erhalten, setzen dann aber wie gehabt auf WebKit als Browser-Engine auf. Somit kann das bestehende Sicherheitsmodell von iOS weiterverwendet werden und Anwender können Web-Apps auch weiterhin installieren.
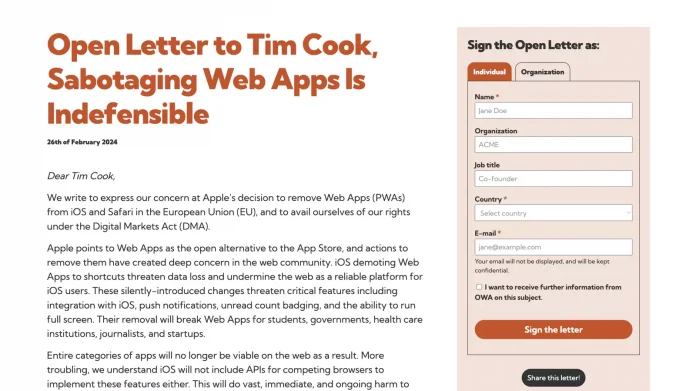
Der Umentscheidung vorausgegangen war die Veröffentlichung eines offenen Briefs der Open Web Advocacy [6] (OWA) an Apple-CEO Tim Cook, der Apple aufforderte, die Installation von Webanwendungen in iOS zu erhalten. Innerhalb weniger Tage haben fast 5.000 Webentwickler und Organisationen den offenen Brief unterzeichnet, darunter viele Community-Mitglieder, Mitarbeiter von Branchengrößen wie Google, Microsoft, Adobe oder des W3C sowie Mitglieder des Europäischen Parlaments.
URL dieses Artikels:
https://www.heise.de/-9641325
Links in diesem Artikel:
[1] https://www.heise.de/news/Apple-bestaetigt-Keine-Progressive-Web-Apps-mehr-fuer-iOS-in-der-EU-9630089.html
[2] https://www.heise.de/news/Web-Push-und-Badging-in-iOS-16-4-Beta-1-Mega-Update-fuer-Progressive-Web-Apps-7521127.html
[3] https://blog.tomayac.com/2024/02/so-what-exactly-did-apple-break-in-the-eu.md/
[4] https://developer.apple.com/support/dma-and-apps-in-the-eu/#:~:text=Why%20don%E2%80%99t%20users%20in%20the%20EU%20have%20access%20to%20Home%20Screen%20web%20apps
[5] https://www.heise.de/hintergrund/Digital-Markets-Act-Neue-Freiheiten-und-Herausforderungen-fuer-iOS-Entwickler-9637241.html
[6] https://letter.open-web-advocacy.org/
[7] mailto:rme@ix.de
Copyright © 2024 Heise Medien

Künstliche Intelligenz hat auch das World Wide Web erreicht.
(Bild: metamorworks/Shutterstock.com)
Braucht es für KI-Funktionen immer die Cloud? Nicht zwingend, denn KI-Modelle laufen auch direkt im Browser – gute Performance und viel Speicher vorausgesetzt.
Künstliche Intelligenz (KI) ist in aller Munde: Keine Woche vergeht ohne die Ankündigung eines neuen Produkts, Chatbots oder eines verbesserten KI-Modells. Zeitgleich hält generative KI in die großen Produktivitätsanwendungen Einzug: Adobe Photoshop erlaubt das Ersetzen von Objekten in einem Bild per einfacher Texteingabe [1] und in Office und Windows steht der Microsoft Copilot [2] dem Anwender zur Seite. Kein Wunder, dass auch viele Anwendungsentwickler derzeit beabsichtigen, generative KI in die eigene Anwendung zu bringen.
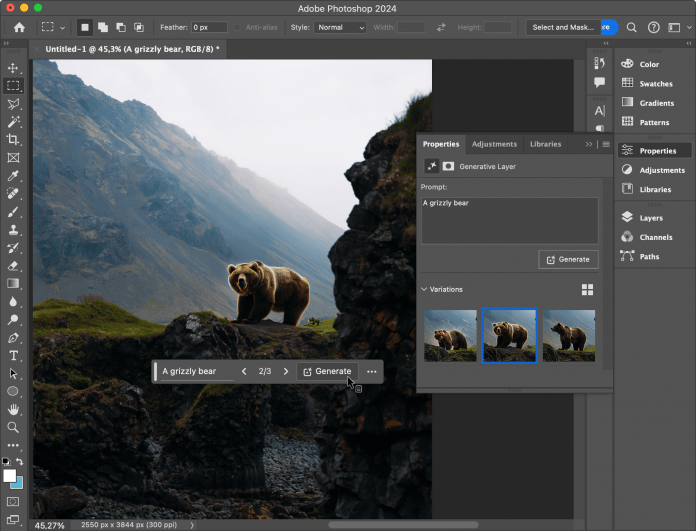
Bislang führt dieser Weg fast ausschließlich in die Cloud. Alle großen Cloudanbieter halten einfach verwendbare Schnittstellen bereit, um KI-Funktionen in die eigenen Anwendungen zu integrieren.
Doch das muss nicht zwingend so sein: Der KI-Trend hat auch das World Wide Web erreicht. Fast zeitgleich zum Hype wurde mit Chromium 113 (April 2023) die Schnittstelle WebGPU unter Windows und macOS verfügbar gemacht. Diese API gibt Webanwendungen einen Low-Level-Zugriff auf die Graphics Processing Unit (GPU) des Systems, die sich nicht nur für Grafikanwendungen, sondern auch für die erforderlichen Berechnungen im Bereich Machine Learning (ML) gut eignet. Darüber lassen sich ML-Modelle effizient im Browser ausführen.
Zwei Showcases von Machine Learning Compilation [3] machen von dieser Schnittstelle bereits Gebrauch:

Beide Showcases sind quelloffen, im Falle von WebLLM gibt es sogar das npm-Paket @mlc-ai/web-llm [6], das Entwickler in die eigene App integrieren können.
In beiden Fällen müssen die KI-Modelle zuerst auf das Endanwendergerät übertragen werden. Diese Modelle sind allerdings mehrere Gigabyte groß, sodass eine schnelle Internetverbindung ebemso erforderlich ist wie ausreichend viel Speicherplatz. Auch die Ausführung des Modells ist anspruchsvoll, setzt viel Arbeitsspeicher und Rechenleistung voraus.
Im Gegenzug sind die Modelle nach dem initialen Download auch offline oder bei unzuverlässiger Internetverbindung verfügbar. Die Daten verlassen das Gerät des Anwenders zudem nicht, sodass sich dieser Ansatz auch für kritische Daten eignet. Ferner fallen keine Kosten an, da die Modelle quelloffen sind. Allerdings sind kommerzielle Modelle wie OpenAI GPT-4 noch deutlich leistungsfähiger. Doch auch in diesem Bereich tut sich viel, und Open-Source-Modelle werden kontinuierlich besser – und kleiner.
Mit WebGPU ist das Ende der Fahnenstange zudem noch nicht erreicht: Die Web Neural Network API [7] (WebNN) befindet sich derzeit beim World Wide Web Consortium (W3C) in Spezifikation. Diese Schnittstelle wird die Ausführung von Machine-Learning-Modellen im Webbrowser noch einmal beschleunigen, indem sie Webanwendungen zusätzlich Zugriff auf die plattformspezifischen ML-Schnittstellen und somit auf die Neural Processing Unit (NPU) gewähren, sofern diese auf der Zielplattform verfügbar sind.
Schon heute lassen sich anspruchsvolle KI-Modelle direkt im Webbrowser verwenden. In Kombination mit den übrigen Schnittstellen aus dem Umfeld der Progressive Web Apps [8] lassen sich damit komplett offlinefähige KI-Webanwendungen bauen. Zweifelsohne steht diese Entwicklung aber noch ziemlich am Anfang: So befindet sich WebGPU in WebKit (Safari) und Gecko (Firefox) noch in Implementierung; auch in Chromium-basierten Browsern ist die Schnittstelle unter Android und Linux noch nicht verfügbar. WebNN ist noch in keinem Browser nutzbar.

KI in Webanwendungen dürfte aber zunehmend an Relevanz gewinnen: Zu viele Anwendungsfälle lassen sich mit klassischer regelbasierter Entwicklung nicht sinnvoll abdecken. Das Web geht dieser Entwicklung jedenfalls vorbereitet entgegen.
URL dieses Artikels:
https://www.heise.de/-7520733
Links in diesem Artikel:
[1] https://www.adobe.com/de/products/photoshop/generative-fill.html
[2] https://adoption.microsoft.com/de-de/copilot/
[3] https://mlc.ai/
[4] https://webllm.mlc.ai/
[5] https://websd.mlc.ai/
[6] https://www.npmjs.com/package/@mlc-ai/web-llm
[7] https://webmachinelearning.github.io/webnn-intro/
[8] https://www.heise.de/blog/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html
[9] mailto:rme@ix.de
Copyright © 2024 Heise Medien

(Bild: Diki Prayogo/ Shutterstock.com)
Die einen lieben HTMX, die anderen hassen es. Was ist dran am Hype um HTMX, was spricht für und was gegen die Bibliothek?
Eine Frage wird mir derzeit täglich gestellt. Von der Community, von Kunden, per E-Mail, telefonisch, auf Discord, in den Kommentaren und in persönlichen Gesprächen, um nur einige Beispiele zu nennen. Seit meinem kürzlich veröffentlichten Beitrag Vanilla Web: Der Frontend-Trend 2024? [1] hat das Interesse noch einmal spürbar zugenommen. Die Frage lautet: "Was ist Ihre Meinung zu HTMX?"
Diese Frage versuche ich aus meiner persönlichen Sicht umfassend und fundiert zu beantworten. Und falls Sie – was unwahrscheinlich, aber möglich ist – noch nie von HTMX gehört haben sollten: Lesen Sie diesen Blogeintrag dennoch. Ich bin überzeugt, dass auch in Ihrem Team früher oder später die Frage aufkommen wird: "Sollten wir uns nicht einmal HTMX genauer anschauen?" Damit Sie nicht völlig unvorbereitet sind, sondern bereits eine grobe Vorstellung haben, worum es bei HTMX geht, und um vielleicht auch das eine oder andere Argument parat zu haben, empfehle ich Ihnen die Lektüre der folgenden Zeilen.
HTMX ist eine kompakte Bibliothek für Web-Benutzeroberflächen und trug ursprünglich den Namen Intercooler.js. Mit der Einführung der Version 2 erfolgte die Umbenennung in HTMX [2], sodass HTMX 1.0 im Grunde Intercooler 2.0 entspricht. Der wesentliche Unterschied ist, dass sich HTMX als eine Neuentwicklung betrachten lässt, die – im Gegensatz zu Intercooler – nicht auf jQuery basiert. HTMX schlägt diesbezüglich einen neuen Weg ein.
Auf npm verzeichnet HTMX derzeit etwa 50.000 Downloads pro Woche. Zur Einordnung: Svelte erreicht knapp eine Million Downloads, Vue fast fünf Millionen und React über 20 Millionen. Warum HTMX dennoch keine Nischentechnik ist, werden wir später noch erläutern. Bis dahin ist es ratsam, bei der Interpretation der Download-Statistiken von HTMX auf npm eine gewisse Vorsicht walten zu lassen.
Was zeichnet HTMX im Vergleich zu anderen Technologien wie beispielsweise React aus? Der grundlegende Unterschied liegt in der Herangehensweise: HTMX setzt darauf, Web-Benutzeroberflächen weiterhin in HTML zu definieren, anstatt in JavaScript, wie es beispielsweise bei React der Fall ist. HTMX verfolgt eine HTML-zentrierte Architektur, im Gegensatz zu vielen anderen Bibliotheken und Frameworks, die sich auf JavaScript konzentrieren. Sie arbeiten also mit regulärem HTML und erweitern es durch spezielle, von HTMX definierte Attribute. Auf diese Weise lassen sich viele Standardaufgaben, für die sonst JavaScript erforderlich wäre, vollständig deklarativ in HTML realisieren.
Einige Entwicklerinnen und Entwickler betrachten diesen Ansatz als etwas völlig Neuartiges. Doch in Wahrheit ist das Konzept nicht neu. Ähnliche Ansätze gab es bereits in der Vergangenheit, wie zum Beispiel bei Knockout.js [4] im Jahr 2010. Auch Angular 1, die ursprüngliche Version von Angular, folgte diesem Prinzip im Jahr 2013. Interessanterweise stammt Intercooler, der Vorläufer von HTMX, ebenfalls aus dem Jahr 2013. Somit greift HTMX eine Denkweise auf, die etwa ein Jahrzehnt alt ist. Da viele Entwicklerinnen und Entwickler diese Phase entweder nicht selbst miterlebt oder sie schlicht vergessen haben, erscheint der Ansatz, HTML in den Vordergrund zu rücken und deklarativ zu erweitern, einigen nun als radikal anders und neuartig, obwohl er das faktisch nicht ist.
HTMX funktioniert im Kern durch den Einsatz benutzerdefinierter Attribute. Um ein einfaches Beispiel anzuführen: Stellen Sie sich ein div-Element vor, dem Sie das Attribut hx-post hinzufügen, konkret hx-post="/articles". Normalerweise würde der Browser dieses Attribut ignorieren, da er unbekannte HTML-Elemente und -Attribute üblicherweise nicht beachtet. HTMX jedoch belebt dieses Attribut: Wenn Sie auf das div klicken, wird dank HTMX im Hintergrund eine HTTP-POST-Anfrage an die URL /articles gesendet. Auf diese Weise kann jedes beliebige HTML-Element einen POST-Request auslösen, wobei dies meist durch Klicken geschieht. Bei Formularen wird ein Request üblicherweise durch das Absenden ausgelöst. So lässt sich jedes Element zur Interaktion mit dem Netzwerk nutzen. Diese Funktionalität beschränkt sich nicht nur auf POST-Requests, sondern umfasst auch GET, PUT und DELETE. Demnach kann jedes HTML-Element jede Art von HTTP-Request initiieren.
Nun stellt sich die Frage, was mit dem Ergebnis, also der vom Server zurückgesendeten Antwort, geschieht. HTMX fängt diese ab und setzt, um bei dem div-Beispiel zu bleiben, das Ergebnis als neuen Inhalt dieses div-Elements ein. Somit wird die Serverantwort direkt angezeigt. Optional kann das Ergebnis auch in einem anderen Element dargestellt werden. Hierfür verwendet man zusätzlich das Attribut hx-target und gibt als Wert einen CSS-Selektor an, der das Element bestimmt, in dem das Ergebnis erscheinen soll. Mit anderen Worten, HTMX ermöglicht es, mit nur zwei Attributen einen AJAX-Request auszuführen, ohne auch nur eine einzige Zeile JavaScript schreiben zu müssen.
Es ist auch möglich, das gesamte Element komplett zu ersetzen: Geben Sie einfach das hx-swap-Attribut an. Damit können Sie auswählen, wie das Ergebnis gerendert werden soll: als Inner- oder als Outer-HTML, vor dem bestehenden Inhalt, nach dem bestehenden Inhalt, gar nicht und so weiter. Allein diese wenigen Attribute machen HTMX bereits äußerst flexibel in der Anwendung.
Es wäre natürlich praktisch, während des Ladeprozesses einen Ladeindikator angezeigt zu bekommen. Tatsächlich ermöglicht HTMX, jedes beliebige Element als Ladeindikator zu definieren. Wünschen Sie sich eine Animation beim Einblenden des neuen Inhalts? Auch das ist mit HTMX kein Problem, da es entsprechende Animationen unterstützt. Soll die Kommunikation nicht über einen einmaligen HTTP-Request ablaufen, sondern periodisch, um beispielsweise Daten zu aktualisieren, also über Polling? Auch das ist mit HTMX machbar, indem Sie ein Zeitintervall festlegen. Bevorzugen Sie eine Push-Kommunikation? HTMX ermöglicht ebenfalls, WebSockets zu nutzen. Alternativ können Sie auf Server-Sent Events (SSE) zurückgreifen, die mit HTML5 eingeführt wurden. Und das ist nur ein Ausschnitt der Möglichkeiten. Für viele Standardanwendungen müssen Sie kein JavaScript mehr schreiben, sondern fügen lediglich ein paar Attribute in Ihr HTML ein, und HTMX erledigt den Rest im Hintergrund.
Übrigens, HTMX funktioniert dabei auch vollständig ohne npm. Es reicht aus, ein Script-Tag in Ihr HTML einzufügen und HTMX von einem Content Delivery Network (CDN) zu laden. Dabei beträgt die Größe lediglich etwa 14 KByte. Das System ist sogar mit dem Internet Explorer kompatibel, um nur einige Vorteile zu nennen. Es wird Ihnen also wirklich leicht gemacht, HTMX zu verwenden. Die Tatsache, dass sich HTMX einfach über ein CDN einbinden lässt, ist auch der Grund, warum ich zuvor erwähnte, dass die Download-Statistiken von npm mit Vorsicht zu betrachten sind. Denn diese spiegeln lediglich wider, wie oft HTMX über npm heruntergeladen wurde, nicht aber, wie oft es von einem CDN geladen oder möglicherweise direkt in Webseiten eingebettet wird – so wie es vor zehn Jahren üblich war. Daher ist es schwierig, die tatsächliche Verbreitung von HTMX zu ermitteln.
Allerdings dürfte die Verbreitung bei Weitem nicht so groß sein, wie die Menge an Fragen, die ich derzeit dazu erhalte, vermuten lässt. Es gibt einen gewissen Hype um HTMX, der aber eher kurz und überschaubar bleiben dürfte. Wie lange er anhalten und wie nachhaltig er sein wird, muss sich noch zeigen.
Wenn das Ergebnis eines HTTP-Requests direkt als Inner-HTML gerendert wird, wie verhält es sich dann mit APIs? Schließlich muss aus dem JSON, XML oder einem anderen Datenformat, das eine API liefert, etwas entstehen, das in HTML darstellbar ist. Es müsste also eine Art Templating oder Ähnliches geben, oder? Doch das ist nicht der vorgesehene Weg. Tatsächlich ist es so, dass der Server fertige HTML-Fragmente liefern muss. Zugegebenermaßen gibt es Plug-ins für HTMX, um unter anderem auch JSON verarbeiten zu können, allerdings macht die Dokumentation klar deutlich, welcher Stellenwert diesem Ansatz zugedacht wird – nämlich ein äußerst geringer.
Das bedeutet, HTMX arbeitet im Kern nicht mit einer klassischen API zusammen, sondern der Server muss speziell für HTMX um Routen erweitert werden, die fertiges HTML zurückgeben. Folglich hebt HTMX die Trennung von Präsentation und Daten auf – es sei denn, man entwickelt ein dediziertes Backend für HTMX. Das entspräche dem Ansatz des BFF-Patterns (Backend For Frontend), bedeutet aber zugleich auch zusätzlichen Aufwand.
Optional ist es übrigens möglich, dass der Server komplette Seiten zurückgibt und HTMX clientseitig mittels eines Attributs angewiesen wird, nur einen Ausschnitt dieser Seite zu rendern. Das sichert Kompatibilität zu Backends, die vollständig serverseitig rendern. Allerdings ist das ziemlich ineffizient, da bei jedem Aufruf zunächst eine komplette Seite geladen werden muss, von der dann möglicherweise der Großteil umgehend wieder verworfen wird. HTMX arbeitet demnach ausschließlich mit HTML und nicht mit herkömmlichen APIs.
Damit komme ich zu meinem ersten Kritikpunkt: Dieser Ansatz verlangt, dass ich als Entwicklerin oder Entwickler das Backend an das Frontend anpassen muss. Aus meiner Sicht ist das eine eher schlechte Praxis, die man vermeiden sollte, sofern es keine wirklich guten Gründe dafür gibt. Es verletzt eine grundlegende Regel der Softwarearchitektur, nach der Abhängigkeiten stets von oben nach unten verlaufen sollten und nicht umgekehrt. Denn dadurch wird Ihr Backend faktisch an Ihr Frontend gebunden. Noch problematischer ist, dass Ihr Backend an die spezifische Wahl einer UI-Technologie gekoppelt wird, was grundsätzlich keine gute Idee ist.
An dieser Stelle führen HTMX-Anhängerinnen und -Anhänger häufig das erwähnte BFF-Pattern (Backend For Frontend) an. Folgt man diesem Pattern, ist eine spezielle API für ein konkretes Frontend kein schlechter, sondern vielmehr sogar ein erstrebenswerter Ansatz. Ich sehe das zwiegespalten. Prinzipiell spricht nichts gegen das BFF-Pattern. Aber ich finde den Gedanken seltsam, ein zusätzliches Backend zu entwickeln, um eine Frontend-Bibliothek nutzen zu können, die vor allem damit beworben wird, dass alles so einfach sei und man kaum noch programmieren müsse. Tatsächlich verlagert das Pattern viel Aufwand und Komplexität in das Backend. Das ist legitim, aber damit ist es eben nicht mehr so einfach, HTMX "mal eben" zu verwenden – wie die Befürworter gerne implizieren.
Hinzu kommt, dass Sie um eine JSON-basierte API vermutlich kaum herumkommen werden, wenn Sie zusätzlich beispielsweise auch noch eine Mobile-App, eine Desktop-Anwendung oder andere Dienste anbinden möchten. Das missfällt mir. Da ich erwähnte, dass das Backend an HTMX als spezifische Technologie gebunden wird: HTMX erwartet in bestimmten Situationen spezielle, nicht standardisierte HTTP-Statuscodes, wie zum Beispiel den Statuscode 286, der HTMX-eigen ist. Sie werden diesen Statuscode nirgendwo anders finden oder nutzen können, was einfach keine gute Idee ist.
HTMX zwingt Sie zudem dazu, sich eine weitere framework- oder bibliotheksspezifische, proprietäre Syntax aneignen zu müssen. Die von HTMX eingeführten Attribute und deren Wertestrukturen folgen nämlich ebenfalls keinem Standard. Das ist im Grunde das Gleiche, was bereits bei Technologien wie Knockout oder Angular 1 der Fall war. Wenn Sie in der Vergangenheit mit einer dieser Technologien gearbeitet haben, könnten Sie sich fragen: Hat Ihnen das Erlernen der spezifischen HTML-Attribute von Knockout oder Angular auf lange Sicht einen Nutzen gebracht? Können Sie das damals erworbene Wissen heute überhaupt noch nutzen?
Wenn nicht, warum sollte es mit der HTMX-spezifischen Syntax in ein paar Jahren anders sein? Kurz gesagt: Wenn HTMX nicht zum langfristigen Standard wird, investieren Sie Zeit und Mühe in etwas, das schon heute absehbar morgen überflüssig sein wird. Ich weiß nicht, wie Sie dazu stehen, aber auf mich wirkt das wenig ansprechend.
Zu den bereits genannten Punkten kommt hinzu, dass Sie mit den hx-Attributen technisch gesehen ungültiges HTML schreiben. Wenn Sie eine mit HTMX erstellte Webseite durch einen Validator laufen lassen, werden Sie zahlreiche Fehlermeldungen erhalten. Ich behaupte, dass beispielsweise Google es nicht besonders schätzt, wenn Webseiten offensichtlich kein syntaktisch valides HTML verwenden, was sich möglicherweise negativ auf das Suchmaschinenranking auswirken könnte. Technisch gesehen handelt es sich um Data-Attribute: Sie könnten also beispielsweise hx-post in data-hx-post umwandeln, um syntaktisch valides HTML zu erhalten. Aber wer tut das schon, insbesondere da auch die Dokumentation von HTMX und sämtliche Beispiele hier mit schlechtem Vorbild vorangehen?
Ferner sind Sie mit dem Problem der fehlenden Typsicherheit konfrontiert. Ein einziger Tippfehler genügt, Ihre Webseite lahmzulegen, woraufhin Sie manuell mit der Fehlersuche beginnen müssen. Das erinnert stark an die Erfahrungen mit Knockout: Ein Fehler im Data-Binding und nichts funktionierte mehr. Aber man erhielt auch keine Fehlermeldung, sondern nur eine nicht funktionierende Webseite. Sie können sich sicherlich vorstellen, wie wenig Vergnügen die Fehlersuche in solchen Fällen bereitet. Effektives Debugging ist praktisch nicht möglich. Zudem bieten die gängigen Editoren und IDEs (noch) keine Unterstützung für diese Syntax, was bedeutet, dass Ihnen Funktionen wie IntelliSense fehlen. Zwar könnten entsprechende Plug-ins Abhilfe schaffen, doch das grundlegende Problem der mangelhaften Debugging-Erfahrung bleibt.
Mit viel Wohlwollen könnte man sagen, dass HTMX bestenfalls für sehr kleine Webseiten geeignet ist. Allerdings gibt es so viele Aspekte, die HTMX für größere, komplexere Projekte vollkommen ungeeignet machen: HTMX missachtet bewährte Architekturprinzipien, widerspricht gängigen Standards, missachtet die Trennung von UI und Daten und legt dem Backend Restriktionen auf, weil das Frontend es so verlangt. Es lässt sich nicht vernünftig debuggen oder testen.
Ich halte also nichts von HTMX. Aus meiner Perspektive ist es eine miserable Idee, auf HTMX zu setzen – es fühlt sich wie ein Rückschritt um zehn Jahre an.
Ich möchte damit nicht behaupten, dass React, Angular, Vue, Svelte oder irgendein anderes UI-Framework die unangefochtene Lösung für alles sei. Es gibt auch dort viele Kritikpunkte, die Frontend-Entwicklung ist insgesamt unnötig kompliziert geworden und es bedarf dringend einiger Veränderungen, um die Arbeit wieder spaßvoll und effizienter zu gestalten. Der Weg zu einer besseren Zukunft sollte jedoch über Standards führen und nicht über den nächsten proprietären Ansatz, der uns dazu verführt, uns erneut auf ein Framework zu verlassen, das in zehn Jahren niemand mehr kennt oder verwendet. Und wir sollten uns sicherlich nicht auf eine Lösung einlassen, die dieselben Fehler wiederholt, die wir bereits vor zehn Jahren gemacht haben. HTMX gehört zu den letzten Technologien, zu deren Einsatz ich raten würde.
Der richtige Ansatz besteht meiner Meinung nach darin, uns von der Notwendigkeit eines Frameworks oder einer Bibliothek zu lösen und stattdessen stärker auf Standards und native Web-Technologien zu setzen. Denn nur so können wir der Abhängigkeitsfalle entkommen. Wie genau dieser Weg aussehen wird, weiß auch ich noch nicht. Aber dass dies der Weg ist, den wir einschlagen sollten, davon bin ich überzeugt. In dieser Hinsicht hat sich bereits einiges getan. – wie ich in meinem Blogeintrag Vanilla-Web: Der Frontend-Trend 2024? [5] ausgeführt habe.
Trotz aller ausgeführten Argumente kann es natürlich sein, dass Sie oder Ihr Team dennoch überzeugt sind, dass HTMX für Ihren speziellen Anwendungsfall geeignet sein könnte. In diesem Fall bitte ich Sie um einen Gefallen: Lassen Sie uns darüber sprechen, nehmen Sie Kontakt mit uns (www.thenativeweb.io) [6] auf. Vielleicht stellen wir gemeinsam fest, dass HTMX tatsächlich in Ihrem speziellen Fall sinnvoll ist.
URL dieses Artikels:
https://www.heise.de/-9633960
Links in diesem Artikel:
[1] https://www.heise.de/blog/Vanilla-Web-Der-Frontend-Trend-2024-9611002.html
[2] https://htmx.org/
[3] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[4] https://www.heise.de/hintergrund/Model-View-ViewModel-mit-Knockout-js-1928690.html
[5] https://www.heise.de/blog/Vanilla-Web-Der-Frontend-Trend-2024-9611002.html
[6] https://www.thenativeweb.io/
[7] mailto:map@ix.de
Copyright © 2024 Heise Medien