
Das Java Module System ist in der Entwicklung von Anwendungen und Bibliotheken noch immer eine selten genutzte Funktion. Dabei ist der Einstieg oft leicht.
In den letzten Jahren hat man immer wieder viele unterschiedliche Meinungen zum Java-Modulsystem gehört. Während viele Entwicklerinnen und Entwickler der standardisierten Möglichkeit zur Definition von Modulen positiv entgegenstehen, gibt es viele kritische Meinungen, die der Definition beispielsweise fehlende Features wie die Unterstützung von Versionen ankreiden. Diese Diskussion möchte ich hier allerdings überhaupt nicht aufmachen. Ich selber sehe viele Vorteile im Modulsystem und kann verstehen, dass vor allem Framework und Bibliotheksentwickler das Ganze nutzen (wollen).
Ein großer Nachteil ist hier allerdings, dass eine (transitive) Abhängigkeit, die in keiner Weise auf das Java Modulsystem angepasst ist, möglicherweise nicht zu den Definitionen und Einschränkungen des Modulsystems passt und somit nicht zum Modul-Path hinzugefügt werden kann. Das Java-Modulsystem erstellt automatisch ein Modul für jedes JAR, das es auf dem Modul Path findet. Hierbei kann es zu einigen Problemen kommen, die man allerdings oft durch kleine Anpassungen in einer Bibliothek beheben kann.
Diese Probleme möchte ich in mehreren Posts einmal genauer betrachten und mögliche Lösungen aufzeigen. Dieser Beitrag geht auf die Nutzung und Definition von automatischen Modulen einmal genauer ein.
Eine wichtige Definition des Modulsystems ist, dass jedes Modul einen eindeutigen Namen benötigt. Hierbei wird zwischen explizit deklarierten Modulen, die über eine module-info.java verfügen, und automatischen Modulen, die implizit deklariert werden, unterschieden. Weitere Infos lassen sich der JavaSE Spec [1] entnehmen. Wenn man in seinem Projekt nicht die Vorteile des Modulsystems durch die Nutzung einer module-info.java nutzen möchte, reicht es völlig aus, wenn man die eigene Bibliothek als automatisches Modul definiert.
Die einzige Voraussetzung hierfür ist, dass das Modul über einen eindeutigen Namen verfügt. Zwar kann Java für JARs auf dem Module Path zur Not sogar einen Namen aus dem Namen des JAR extrahieren, was aber ganz klar nicht empfohlen ist. Vor allem, da die Definition eines Namens für ein automatisches Modul wirklich sehr einfach ist. Es muss lediglich die Automatic-Module-Name Property in der MANIFEST.MF des JARs definiert werden. Wenn Maven oder Gradle als Buildtool genutzt werden, kann man dies über ein Plug-in sogar voll automatisiert erstellen.
Wie man im folgenden Beispiel sehen kann, muss bei einem Maven Build nur das maven-jar-plugin entsprechend konfiguriert werden:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<archive>
<manifestEntries>
<Automatic-Module-Name>com.example.lib</Automatic-Module-Name>
</manifestEntries>
</archive>
</configuration>
</plugin>
In Gradle lässt sich das Ganze einfach durch Nutzung des Java-Library-Plug-ins umsetzen, das Bestandteil jedes Java Builds sein sollte. Eine ausführliche Dokumentation zum Einsatz in Gradle kann man hier [2] finden, während der folgende Code eine einfache Einbindung in ein Projekt zeigt:
tasks.jar {
manifest {
attributes("Automatic-Module-Name" to "com.example.lib")
}
}
Da die Änderungen wirklich sehr einfach sind, eignen sie sich auch hervorragend, um das Ganze für Open Source Libraries als Pull Request anzubieten. In einem Beispiel [3] habe ich einen PR zur Definition eines Automatic-Module-Name zu einer Open Source-Java-Bibliothek hinzugefügt. Vielleicht liest ja eine oder ein Open Source Developer mit und erstellt für eine solche Umstellung der eigenen Bibliotheken ein „Good First Issue“, das beispielsweise zum Hacktoberfest [4] von Neulingen umgesetzt werden kann.
URL dieses Artikels:
https://www.heise.de/-7434695
Links in diesem Artikel:
[1] https://docs.oracle.com/javase/specs/jls/se16/html/jls-7.html#jls-7.7.1
[2] https://docs.gradle.org/current/userguide/java_library_plugin.html#sec:java_library_modular_auto
[3] https://github.com/offbynull/portmapper/pull/48
[4] https://hacktoberfest.com
[5] https://heise-academy.de/schulungen/virtual-threads?wt_mc=intern.academy.ix.ws_virtualthreads.newsticker.link.link
[6] mailto:rme@ix.de
Copyright © 2024 Heise Medien
This is a bug-fix release for the 1.23.0 release, addressing several regressions.
This release has been made by @Alkarex, @andris155, @math-GH, @yzqzss, @zhzy0077
Full changelog:
base_url being cleared when saving settings #5992.dockerignore #5996A few highlights ✨:
Breaking changes 💥:
amd64, arm32v7, arm64v8 with automatic detection #5808
-arm suffix anymoreThis release has been made by several contributors: @Alkarex, @ColonelMoutarde, @FireFingers21, @Frenzie, @kasimircash, @andris155, @b-reich, @foux, @jaden, @jan-vandenberg, @joestump, @jtracey, @mark-monteiro, @martinrotter, @math-GH, @passbe
Full changelog:
VARCHAR) text fields length to maximum possible #5788CRON_MIN if any environment variable contains a single quote #5795TRUSTED_PROXY environment variable used in combination with trusted sources #5853
(Bild: Andrey Suslov/Shutterstock.com)
Electron ist nicht nur sprichwörtlich das Schwergewicht in der Cross-Plattform-Entwicklung. Kleiner und sicherer will Tauri sein, das im Backend auf Rust setzt.
Viele Anwendungen wie Signal, Slack, WhatsApp, Discord oder Visual Studio Code nutzen unter der Haube Electron [1], ein Framework zur plattformübergreifenden Ausführung von Anwendungen. Die App selbst wird dabei mithilfe von Webtechnologien wie HTML, CSS, JavaScript und WebAssembly [2] implementiert. Electron verpackt die Anwendungen gemeinsam mit dem Webbrowser Chromium und der Runtime Node.js in ein plattformspezifisches Bündel. Über das sogenannte Backend in Node.js kann die Webanwendung sämtliche Schnittstellen des Betriebssystems aufrufen.
Entwickler sparen bei diesem Ansatz viel Zeit, Geld und Aufwand, da sie ihre Anwendung nur einmal mit Webtechnologien entwickeln müssen und auf einer Vielzahl von Plattformen vertreiben können, Webbrowser eingeschlossen.

Allerdings sind Electron-Anwendungen aufgrund der Bündelung gleich zweier Laufzeitumgebungen leider auch sehr groß: Schon eine einfache Hello-World-Anwendung wird in Electron verpackt rund 100 MByte groß.
Jede ausgeführte Instanz führt zu einem Mehrverbrauch an Arbeitsspeicher, und veraltete Node.js- und Chromium-Versionen innerhalb eines Anwendungsbündels können zu Sicherheitsproblemen führen. Entwickler müssen Updates nicht nur bei Aktualisierungen ihrer App vertreiben, sondern auch, wenn sich Electron aktualisiert hat.

(Bild: Tauri.app)
Hier kommt Tauri [4] ins Spiel: Der Electron-Herausforderer erlaubt ebenfalls das Verpacken von Webanwendungen in Form eines plattformspezifischen Bündels. Allerdings fügt Tauri keinen eigenen Webbrowser hinzu, sondern nutzt die Web-View des Betriebssystems, auf dem die Anwendung ausgeführt wird: WebView2 auf Windows, WebKit unter macOS und WebKitGTK auf Linux.
In Tauri 2.0, das sich derzeit noch in der Alpha-Phase befindet, sollen sich iOS und Android zur Liste der unterstützten Plattformen hinzugesellen. Diese Plattformen können mit Electron nicht adressiert werden. Tauri würde damit auch Wrapper für mobile Betriebssysteme wie Cordova oder Capacitor [5] ersetzen.

Im Backend greift Tauri nicht auf JavaScript zurück, sondern auf Rust. Insofern muss auch Node.js nicht mit der Anwendung verpackt werden. Eine Hello-World-Anwendung ist mit Tauri gerade einmal 600 KByte groß. Mithilfe von Sidecars können Anwendungen mit externen Binärdateien ausgeliefert werden, die nochmal in anderen Sprachen verfasst sind.
Und auch das Thema Security nimmt bei Tauri einen hohen Stellenwert [6] ein: So können die benötigten Programmierschnittstellen gezielt aktiviert werden. Nur dann wird der dafür erforderliche Code überhaupt in das Bündel aufgenommen. Tauri bringt auch viele erweiterte Funktionen wie einen Auto-Updater oder die Integration in das Benachrichtigungssystem der Plattform mit.
Der Nachteil von Tauri besteht allerdings gerade darin, dass die Webanwendung nun in verschiedenen Ausführungsumgebungen ausgeführt wird: Die Unterstützung bestimmter Webschnittstellen oder CSS-Features variiert zwischen unterschiedlichen Web-Engines, sodass die Anwendung auf allen Zielumgebungen getestet werden muss.
Während Electron von GitHub herausgegeben wird, ist Tauri ein Community-getriebenes Projekt. Finanziell unterstützt wird Tauri etwa von 1Password, deren Passwortmanager zumindest derzeit noch auf Electron basiert.
Auch wenn die erste Version von Tauri schon länger erschienen ist, bleibt es noch das "New Kid on the Block". Große Namen finden sich unter den Tauri-Verwendern [7] derzeit noch nicht. Nicht nur aufgrund der deutlich geringeren Bundle-Größe sollte das Framework jedoch in Betracht gezogen werden, vielleicht sogar noch vor dem Platzhirsch Electron. Eine neue Tauri-App lässt sich über den npm-Befehl npm create tauri-app , auf der Bash mit sh <(curl https://create.tauri.app/sh oder auf der Powershell mit irm https://create.tauri.app/ps | iex erstellen.
URL dieses Artikels:
https://www.heise.de/-9538237
Links in diesem Artikel:
[1] https://www.electronjs.org/
[2] https://www.heise.de/blog/WebAssembly-Das-Web-wird-nativ-er-4023451.html
[3] http://paint.js.org/
[4] https://tauri.app/%E2%80%8B
[5] https://www.heise.de/blog/Capacitor-oder-Cordova-Welche-Plattform-sollten-Entwickler-webbasierter-Mobilapps-waehlen-4690975.html
[6] https://tauri.app/v1/references/architecture/security%E2%80%8B
[7] https://github.com/tauri-apps/awesome-tauri#applications%E2%80%8B
[8] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Pixelvario/Shutterstock.com)
Um eine Webanwendung in Chromium-basierten Browsern installieren zu können, musste diese ursprünglich offlinefähig sein. Diese Bedingung ist entfallen.
Progressive Web Apps [1] sind Webanwendungen, die auf dem Gerät des Anwenders installiert werden können. Voraussetzung dafür war in Google Chrome und Microsoft Edge lange Zeit, dass die Anwendung offlinefähig sein muss. Für die User Experience ist eine Bedienbarkeit auch dann wünschenswert, wenn der Anwender offline ist – zumindest im Rahmen der Möglichkeiten. Wer also den zusätzlichen Aufwand auf sich nahm, dies umzusetzen, wurde mit der Installierbarkeit der Anwendung belohnt.

Zur Implementierung der Offlinefähigkeit bei Webanwendungen kommen Service Worker [3] zum Einsatz. Dabei handelt es sich um ein durch die Website registriertes Stück JavaScript, das als Proxy zwischen Webanwendung und Netzwerk agiert und Zugriff auf einen clientseitigen, programmierbaren Cache besitzt. Speichert man die erforderlichen Quelldateien der Anwendung im Cache zwischen und liefert sie im Offline-Fall von dort aus, lässt sich die Anwendung auch ohne Internetverbindung betreiben.
Findige Webentwickler haben um diese Anforderung jedoch herummanövriert: Manche setzten einen leeren Service Worker ein, um die Bedingung zu erfüllen. Google zog daraufhin nach und erforderte einen fetch-Ereignishandler, sodass der Service Worker zumindest theoretisch in der Lage war, die Website offline verfügbar zu machen. Also setzten Seiten einfach diesen Ereignis-Handler ein und leiteten sämtliche Anfragen gegen das Netzwerk um. Folglich war das Ziel wieder nicht erreicht, und aufseiten des Browsers führte die zusätzliche Prüfung zu einem erheblichen Mehraufwand.
Mit Chromium 109 (mobil) und 110 (Desktop) wurden daher im Januar 2023 neue Offline-Fallbackansichten für installierte Webanwendungen [4] implementiert: Die Offlineerfahrung wird automatisch generiert, indem das Icon der Anwendung und der Hinweis "You're offline" angezeigt wird.

Die Notwendigkeit eines Service Worker und damit der Offlinefähigkeit ist seitdem komplett entfallen. Damit nähern sich Chrome und Edge auch an Safari an: Denn die Installation von Websites ist auf dem iPhone seit den frühen Tagen möglich, ganz ohne Bedingungen. Im Fall von Chrome und Edge wird zunächst jedoch auch weiterhin ein Web Application Manifest gefordert sowie die Übertragung der Website über HTTPS (siehe Installationskriterien [5]).
Service Worker haben den Nachteil, dass sie in JavaScript geschrieben und erst hochgefahren werden müssen, um Websites auszuliefern oder Pushbenachrichtigungen entgegenzunehmen. Um dem entgegenzuwirken, wurde für die Beschleunigung von Netzwerkabfragen beim Service-Worker-Start Navigation Preloads [6] entwickelt, während es für Pushbenachrichtigungen einen alternativen Vorschlag gibt, Declarative Web Push [7]. Für Webentwickler ist das Verfassen von solchem Infrastrukturcode zudem recht ungewohnt.
Die Implementierung einer sinnvoll bedienbaren Offlinevariante bleibt jedoch ein zentraler Baustein einer guten User Experience. PWA-Entwickler sollten diese daher auch in Zukunft anbieten, um ihre Anwender glücklich zu machen.
URL dieses Artikels:
https://www.heise.de/-9356942
Links in diesem Artikel:
[1] https://developer.mozilla.org/en-US/docs/Web/Progressive_web_apps
[2] http://pwapraxis.liebel.io/
[3] https://www.heise.de/blog/Progressive-Web-Apps-Teil-2-Die-Macht-des-Service-Workers-3740464.html
[4] https://developer.chrome.com/blog/default-offline/
[5] https://web.dev/articles/install-criteria
[6] https://web.dev/blog/navigation-preload
[7] https://github.com/w3c/push-api/issues/360
[8] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Für Apple so wichtig, dass es sogar in den Top-Neuerungen von macOS Sonoma erscheint: Die Installation von Webanwendungen aus Safari heraus.
(Bild: Apple)
Was auf dem iPhone seit der ersten Version funktioniert, geht nun endlich auch mit Safari unter macOS: Webanwendungen lassen sich auf dem Gerät installieren.
Mit der Veröffentlichung von Safari 17 [1] und macOS Sonoma sind Progressive Web Apps [2] nun auch unter Verwendung des Apple-Browsers unter macOS installierbar. Dies war unter macOS mit Chromium-basierten Browsern wie Google Chrome und Microsoft Edge schon seit einigen Jahren [3] möglich, mit Safari auf dem iPhone bereits seit Januar 2008, als iPhone OS 1.1.3 veröffentlicht wurde.
Bei der Installation wird eine Verknüpfung zur Website auf dem Dock (auf Mobilgeräten auf dem Home-Bildschirm) hinterlegt. Webentwickler können das Icon und den Namen der Verknüpfung vordefinieren und dabei auch festlegen, dass die von der Verknüpfung geöffnete Website im Standalone-Modus ausgeführt wird, also in einem eigenständigen Fenster (auf Mobilgeräten vollflächig, also ohne Browser-Steuerelemente). Dies wird über das Web Application Manifest [4] definiert. Ist kein Manifest vorhanden, werden Titel und Icon aus anderen Quellen bezogen.
Die Installation erfolgt analog zu iOS und iPadOS aus dem Teilen-Menü heraus, das sich neben der Adresszeile befindet. Darin muss der Eintrag "Add to Dock" ausgewählt werden. Als Beispiel soll hier die Produktivitäts-PWA [5] paint.js.org [6] dienen.

Die Installation müssen Anwender in einem separaten Dialog bestätigen. Safari erlaubt dabei das Ändern der Bezeichnung. Wer davon Gebrauch macht, kann mehr als eine Instanz der Anwendung auf dem Gerät installieren – etwa, um eine Anwendung mit unterschiedlichen Benutzerprofilen zu verwenden, denn Cookies werden zwischen den Instanzen nicht geteilt. Dies ist bei Chrome oder Edge in dieser Form so nicht möglich.

Beim Zustimmen zur Aufforderung wird die Verknüpfung dem Dock hinzugefügt und dort zugleich angeheftet. Außerdem erscheint die Anwendung auch im Launchpad und ist im Applications-Ordner des Benutzerverzeichnisses zu finden. Von dort kann die Webanwendung auch wieder gelöscht werden [7]. Von der Verknüpfung aus gestartet, erscheint die Webanwendung dann wie plattformspezifische Apps in einem eigenen Fenster.

Damit sind Webanwendungen nun unter Safari auf sämtlichen Plattformen offline-fähig, installierbar und können Pushbenachrichtigungen entgegennehmen: Installierte Anwendungen können wie auch unter iOS und iPadOS Pushbenachrichtigungen empfangen und Badges auf dem Anwendungs-Icon anzeigen [8]. Als einziger der großen Browser unterstützt Firefox keine Installation von Webanwendungen auf dem Desktop.
Der nächste logische Schritt wäre nun die Bereitstellung der File System Access API [9] in Safari. Diese Webschnittstelle, die bereits seit 2019 mit Chromium-basierten Browsern ausgeliefert wird, erlaubt die Bearbeitung von Dateien aus dem lokalen Dateisystem. Über die Erweiterung File Handling API können sich installierte Webanwendungen sogar als Bearbeitungsprogramm für bestimmte Dateitypen hinterlegen. Dass das interessant sein könnte, merkten Apple-Vertreter auf der vergangenen Jahreskonferenz des W3C [10] bereits an.
URL dieses Artikels:
https://www.heise.de/-9356873
Links in diesem Artikel:
[1] https://webkit.org/blog/14445/webkit-features-in-safari-17-0/#:~:text=and%20error%20handling.-,Web%20apps%20on%20Mac,-Safari%2017.0%20for
[2] https://www.heise.de/blog/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html
[3] https://www.heise.de/blog/Chrome-76-PWA-Installation-wird-einfacher-4481046.html
[4] https://www.heise.de/blog/Progressive-Web-Apps-Teil-3-Wie-die-Web-App-zur-App-App-wird-3464603.html
[5] https://www.heise.de/blog/paint-js-org-MS-Paint-Remake-als-PWA-mit-Web-Components-und-modernen-Web-Capabilities-6058723.html
[6] http://paint.js.org/
[7] https://support.apple.com/en-us/104996
[8] https://www.heise.de/blog/Web-Push-und-Badging-in-iOS-16-4-Beta-1-Mega-Update-fuer-Progressive-Web-Apps-7518359.html
[9] https://www.heise.de/blog/Produktivitaets-PWAs-auf-Desktop-Niveau-dank-File-System-Access-und-File-Handling-API-4963752.html
[10] https://blog.tomayac.com/2023/09/25/w3c-tpac-2023-trip-report/#:~:text=Apple%20noted%20that%20a%20launch%20handling%20feature%20is%20something%20that%20they%20would%20probably%20need.
[11] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Login/ Shutterstock.com)
Das Ende ist nah: Bald wird KI die Softwareentwicklung übernehmen. Das ist übertrieben und zeigt, wie unklar ist, worum es Softwareentwicklung wirklich geht.
Zunächst: KI hilft beim Produzieren von Code. Das ist zweifellos ein signifikanter Fortschritt und wird vieles ändern. Jeder kann die zahlreichen Werkzeuge ausprobieren und sich davon selber überzeugen, wie mächtig diese Werkzeuge sind.
Aber auch wenn es zunächst paradox erscheint: Code zu produzieren, ist nicht das wesentliche Problem bei der Entwicklung von Software. Das wirkliche Problem ist, herauszufinden, welcher Code geschrieben werden muss. Dazu müssten die fachlichen Anforderungen bekannt sein. Anforderungen sind in der Praxis aber meist viel zu unklar, um daraus erfolgreich Software entwickeln zu können. Selbst wenn sie klar scheinen, stellt sich oft später im Prozess heraus, dass es doch Missverständnisse gab. So kommt der Interaktion mit Domänenfachkundige eine zentrale Rolle zu. Entwickler und Entwicklerinnen müssen so viel über die Domäne lernen, dass sie die passende Software für die fachlichen Fragestellungen entwickeln können.
Außerdem ändern sich die Anforderungen. Durch die Entwicklung der Software, den Einsatz der neuen Software und den damit zusammenhängenden Diskussionen reflektieren User und Domänenfachleute über die Nutzung der Software und kommen so zu neuen Anforderungen. Auch an diesem Prozesse müssen Developer teilnehmen, um zu verstehen, was zu entwickeln ist. Zudem können sie Feedback geben, falls Anforderungen besonders leicht oder schwierig umsetzbar sind - oder Änderungen an den Anforderungen die Umsetzung deutlich vereinfachen.
Bei den Anforderungen erkennt man schon die Bedeutung des Faktors Mensch. Er ist ebenfalls zentral: Softwareentwicklung findet immer im Team statt. So ein Team besteht üblicherweise aus mehreren Developern, aber auch andere Rollen wie UX-Experten, Architektinnen oder POs. Damit kommt der Kommunikation eine zentrale Rolle bei der Entwicklung zu: Aufgaben müssen verteilt und organisiert werden. Und die Organisation beeinflusst auch die Software: Das Gesetz von Conway besagt, dass die Architektur der Software den Kommunikationsbeziehungen des Teams entspricht. Wenn das soziale Gefüge so einen starken Einfluss auf die Entwicklung hat, dann sind in diesem Bereich auch die zentralen Herausforderungen. Und so haben die meisten Probleme in den Projekten auch ihre Ursache in der menschlichen Ebene. Hier kann KI nicht helfen.
Es wäre möglich, dass durch KI die Produktivität so sehr erhöht wird, dass eine Person statt eines Teams für ein Softwareprojekt ausreicht und so der Faktor Mensch weniger wichtig wird. Das erscheint unwahrscheinlich. Und die Interaktion mit Menschen zur Klärung von Anforderungen ist immer noch notwendig. Außerdem gab es auch schon vor den KI-Tools Fortschritte bei der Produktivität. Das hat aber nicht zu kleineren Teams geführt. Die Größe der Software-Teams steigt subjektiv eher, um noch kompliziertere Systeme zu realisieren und noch mehr Bereiche mit Software zu unterstützen. Wenn sich der Trend fortsetzt, werden wir mit KI ebenfalls noch komplexere Systeme bauen und nicht etwas kleinere Teams.
Das Produzieren von Code zu vereinfachen, ist auch nichts Neues. Im Gegenteil: Es gibt eine lange Historie von technischen Ansätzen, um Softwareentwicklung zu vereinfachen. Typischerweise heben diese Ansätze die Entwicklung auf eine neue Abstraktionsebene. Begonnen hat Softwareentwicklung damit, dass man Binärcode direkt in den Speicher der Computer geschrieben hat. Assembler hat dann Befehle definiert, die den Binärcodes entsprechen, aber einfacher zu merken und zu verstehen sind. So wurde vom Binärcode abstrahiert. Hochsprachen führen Konzepte ein, die von Assembler abstrahieren und mit denen Algorithmen und Logik noch einfacher ausdrückbar ist. Parallel sind Aufgaben in die Infrastruktur gewandert und wurden so für Entwicklungsteams: Betriebssysteme und Datenbanken bieten Lösungen für Persistenz, Speicher- und Prozessverwaltung. Libraries und Frameworks bieten auf Code-Ebene fertige Lösungen für typische Teilfunktionalitäten an. Und die Cloud [2]bietet eine Abstraktion über viele vorhandene Infrastrukturelemente wie Datenbanken oder Computer, sodass Infrastruktur für Projekte einfacher umgesetzt werden kann.
KI ist ein weiterer Schritt auf diesem Weg. Tatsächlich sind die Fortschritte so beeindruckend, dass man sicher von einer neuen Abstraktionsstufe sprechen muss. Es gibt prototypische Werkzeuge wie GPT Engineer [3], die eine ganze Anwendung anhand einer Spezifikation erstellen und dabei Rückfragen stellen, falls Anforderungen unklar sind (Video [4]). Nur wie zuvor erwähnt: Softwareentwicklung mit klaren Anforderungen ist nicht das Problem. Also wird der weniger problematische Teil der Softwareentwicklung durch KI vereinfacht und nicht der Kern.
KI führt sogar zu Gefahren: Eine Studie [5] hat das Verhalten von Entwicklerinnen und Entwicklern beim Schreiben von sicherheitsrelevantem Code ausgewertet und kommt zu dem Schluss, dass diejenigen mit KI-Unterstützung ihre Lösungen als sicherer einstufen als solche ohne. Nur ist in der Realität genau das Gegenteil der Fall: Ihr Code ist weniger sicher. Und das ist offensichtlich gefährlich: Es geht eben nicht darum, Code zu produzieren, sondern ein Problem soll gelöst werden. Und sicherheitsrelevante Software mit Sicherheitsprobleme schafft in Wirklichkeit neue Probleme. Gerade der Unterschied zwischen der subjektiven Bewertung und der objektiven Realität kann verheerend sein: Man glaubt, die Software sei sicher. Das stimmt aber nicht. Sicherheitslücken sind nur leider anders als fachliche Fehler oder Performance-Probleme nicht offensichtlich und so kann der Schaden ganz im Verborgenen entstehen. Solche Risiken zu managen und Lösungen zu entwerfen, welche die Qualitäten beispielsweise bei Sicherheit bieten, kann eine KI ebenfalls kaum lösen. Au!
Das nächste Problem: Es geht meist nicht um das Produzieren von Code, sondern um das Ändern. Das bedeutet auch, dass Entwicklerinnen und Entwickler vorhandenen Code lesen und verstehen müssen, um ihn sinnvoll zu ändern. Offensichtlich wird Code am Anfang einmal geschrieben, aber öfter geändert und damit auch gelesen. Dann ist das größere Optimierungspotential aber nicht beim einmaligen Produzieren, sondern beim Lesen, Verstehen und Ändern, das viel öfter stattfindet. Aber auch in diesem Bereich kann KI helfen: Tatsächlich kann man ChatGPT darum bitten, Code zu erklären. Dabei geht es eher um kleinere Codeschnipsel. Aber das Potenzial ist sicher groß: Gerade für Legacy-Code könnte eine speziell auf ein System trainierte KI ein interessantes Werkzeug sein, um das Verständnis des Systems zu verbessern und damit Änderungen zu vereinfachen.
Das Problem der Softwareentwicklung ist nicht, Code zu produzieren, sondern zu verstehen, was implementiert werden soll. Die Produktivitätsvorteile durch KI lösen dieses Problem nicht. KI wird Softwareentwicklung wesentlich ändern, aber nicht das Kernproblem lösen.
URL dieses Artikels:
https://www.heise.de/-9336902
Links in diesem Artikel:
[1] https://heise-academy.de/schulungen/githup?wt_mc=intern.academy.ix.ws_github.newsticker.link.link
[2] https://www.heise.de/blog/Die-Cloud-Eine-Komponentenbibliothek-3354034.html
[3] https://github.com/AntonOsika/gpt-engineer
[4] https://www.youtube.com/watch?v=FPZONhA0C60&t=440s
[5] https://arxiv.org/abs/2211.03622
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien
This release contains mostly some bug fixes for the recent 1.22.0.
This version 1.22.x is also the last to support PHP 7.2 before requiring PHP 7.4+.
A few highlights ✨:
This release has been made by several contributors: @Alkarex, @Frenzie, @MHketbi, @XtremeOwnageDotCom, @math-GH, @mossroy
Full changelog:
: in OIDC_SCOPES #5753, #5764TRUSTED_PROXY environment variable #5733RemoteIPInternalProxy in Apache #5740In this release, besides adding some initial support for OpenID Connect, the focus has been on increasing the quality rather than adding new features (which will have more focus again in the next release).
This version 1.22.x is also the last to support PHP 7.2 before requiring PHP 7.4+.
A few highlights ✨:
x86_64, not Alpine, and not ARM) through libapache2-mod-auth-openidc. See our documentationThis release has been made by several contributors: @Alkarex, @Alwaysin, @ColonelMoutarde, @Exerra, @FromTheMoon85, @LleanaRuv, @Marjani, @NaeiKinDus, @Rufubi, @V-E-O, @aaronschif, @acbgbca, @aledeg, @andris155, @becdetat, @belidzs, @kemayo, @kgraefe, @marienfressinaud, @math-GH, @msdlr, @obrenckle, @otaconix, @robertdahlem, @sad270, @samc1213, @squaregoldfish, @vrachnis, @witchcraze, @yubiuser, @zhaofengli
Full changelog:
x86_64, not Alpine) through libapache2-mod-auth-openidcset_time_limit() #5675CLEANCACHE_HOURS #5144<meta name="theme-color" .../> #5105a2enmod #5464DATA_PATH to cron env #5531error_reporting for PHP 8.1+ #5199DATA_PATH environment variable) #5423lib_opml #5188lib/http-conditional #5277ConfigurationSetter #5251, #5580./data.back/ in .gitignore #5359
Dass die JavaLand 2024 nicht mehr im Phantasialand stattfindet, eröffnet der Community-Konferenz neue Möglichkeiten.
Vor kurzem ist die Bombe geplatzt: Die JavaLand 2024 [1] kann doch nicht wie geplant im Februar am gewohnten Ort stattfinden. Stattdessen wird sie das erste Mal seit ihrem Bestehen an eine neue Location umziehen. Im April wird sich die Java-Community nächstes Jahr nicht mehr im Freizeitpark, sondern am Nürburgring treffen. Wir sind uns sicher, dass diese Neuigkeiten bei vielen Community-Mitgliedern Fragen aufwerfen, allen voran: Warum geht ihr von dieser coolen Location weg? Wir möchten diesen Blogbeitrag nutzen, um unsere persönliche Sichtweise darzustellen, auch wenn die offizielle Pressemitteilung schon einige Fragen beantwortet [2]. Uns ist die Community wichtig und hier können wir etwas konkreter werden. Vor allem möchten wir Gerüchten vorbeugen.
Wie viele aus der Community fanden auch wir das Phantasialand als Location einen Lichtblick im Einheitsgrau der Hotel-Lobbys, Kongresszentren und Kinosäle (wobei die schon auch cool sind). Aber die Location war nicht der einzige Punkt, denn die JavaLand hat dank uns allen (Sprechern, Besuchern, Java User Groups, Aussteller ...) noch einiges mehr zu bieten und hebt sich positiv aus der Konferenzlandschaft ab. Diesen ganz eigenen Spirit empfinden wir bis heute als einmalig und wollen ihn als Mitglieder der Konferenzleitung auch in Zukunft sichern und weiter ausbauen.
Aber die Hürden, die JavaLand im Phantasialand durchzuführen, waren zuletzt zu hoch geworden. Es hatte sich bereits in den vergangenen Jahren gezeigt, dass das Event-Management des Phantasialand nicht in der Lage ist, eine JavaLand nach den Wünschen unserer Community durchzuführen. Leider haben die vielen Bemühungen nicht ausgereicht, um die problematischen Punkte zu klären. Das Phantasialand-Management hat nicht flexibler agiert. Vielmehr wurde die Situation für uns in der Planung und Durchführung der Konferenz jedes Jahr schwieriger. Nächstes Jahr hätten diese Punkte auch das erste Mal alle Besucher direkt betroffen. Wir hätten eine JavaLand im kühlen Februar ohne Nutzung der Fahrgeschäfte gehabt. Dazu kam, dass die Konferenzleitung auch die Preiserhöhungen (inklusive der Hotelpreise) nicht mehr sinnvoll abfangen konnte, sodass dem Rückgang beim Spirit eine deutliche Erhöhung der Kosten pro Besucher gegenübergestanden hätte. Wir möchten hier nicht noch konkreter werden und auch ein Bashing gegenüber dem Phantasialand vermeiden. Allerdings sind wir der Meinung, dass diese offene Begründung nötig ist, um Gerüchte oder Fehlinformationen zu vermeiden. Am Ende unterscheidet sich unsere Java Community zum Glück grundsätzlich von der Klientel, die sich das Phantasialand Event-Management offenbar als Kunden wünscht.
Das Ganze führt uns nun zur aktuellen Situation und der Bekanntmachung der großen Änderungen für die JavaLand 2024. Und das dann auch noch zum 10. Jubiläum. Wird es die gleiche Konferenz sein wie bisher? Ganz bestimmt nicht. Aber gerade wir als agile Entwickler wissen ja, Änderungen gehören zu unserem Alltag. Sie bringen auch immer Fortschritt und ganz neue Möglichkeiten. Aktuell gibt es viele Diskussionen in der Konferenzleitung, wie wir den Kern des JavaLand-Spirit an die neue Location mitnehmen und durch weitere Aspekte sinnvoll ergänzen können. Der Vorteil ist, dass der Nürburgring bereits einiges an Attraktionen zu bieten hat. Denkbar sind Rennen in E-Karts (uns ist auch ein gewisser Grad an Nachhaltigkeit wichtig) und es gibt zum Beispiel auch ein 3D Kino. Außerdem sprudeln bereits die Ideen, wie wir mit Ständen, Foodtrucks, großartigen Abend-Events mit Live-Musik und viele weiteren Attraktionen ein Festival erschaffen und aber auch das Themenpark-Feeling an den Ring holen können.
Hinzu kommt, dass die Location deutlich mehr Möglichkeiten für Community-Aktivitäten bietet. Daher möchten wir euch erneut aufrufen, Ideen für eines der Highlights der JavaLand, das Community-Programm einzureichen. Die Community-Aktivitäten reichen vom direkten Austausch in Diskussionsrunden über kleine Hands-On-Sessions, dem Netzwerken, die Durchführung der JavaLand4Kids bis zu sportlichen Aktivitäten. Das Joggen ist auf jeden Fall wieder dabei, aber vielleicht drehen wir diesmal auch ein paar schnelle Fahrrad-Runden auf dem Nürburgring. Wer mag, kann sich bei der Anreise der JavaLand Fahrrad-Sternenfahrt anschließen, wenn auch diesmal mit ein paar mehr Höhenmetern. Die im vergangenen Jahr erstmals angebotene Unkonferenz wird ebenfalls wieder am Vortag stattfinden. Und im normalen Vortragsprogramm wird es erstmals Deep-Dive-Sessions von fast zwei Stunden geben. All das wird die Black Mamba, die Taron und die anderen coolen Fahrgeschäfte nicht ersetzen können, aber euch wird garantiert nicht langweilig. Und jetzt ist es vielleicht auch leichter, der Chefin oder dem Chef den Besuch bei der JavaLand zu verkaufen.
Wir sind sehr froh über die Neuerungen und sehr gespannt auf die Möglichkeiten, die sich uns bieten werden. Die Planung der JavaLand-Konferenz, die zähen Monate mit den schwierigen Verhandlungen (und den trotzdem nur sehr eingeschränkten Möglichkeiten im Phantasialand) sowie die schwierige Suche nach Alternativen hat uns das erste Mal nicht mehr wirklich Spaß gemacht. Aber diese neue Location bietet nun wieder interessante Optionen, diese ganz besondere Konferenz noch ein Stück besser zu machen. Und hier bitten wir natürlich auch euch, die Java-Community, kreativ zu werden. Macht mit euren Vorschlägen zu den Community-Aktivitäten die JavaLand 2024 wieder zu einem ganz besonderen Erlebnis. Gerade die zehnte JavaLand möchten wir lieber an einem alternativen Ort mit neuen Aktivitäten und Ideen durchführen als unter den leider immer größer werdenden Einschränkungen im Phantasialand.
URL dieses Artikels:
https://www.heise.de/-9322819
Links in diesem Artikel:
[1] https://www.heise.de/news/JavaLand-Konferenz-aendert-den-Termin-und-zieht-zum-Nuerburgring-9317740.html
[2] https://www.javaland.eu/de/home/news/details/javaland-2024-neuer-termin-und-neue-location-call-for-papers-verlaengert/
[3] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Natalia Hanin / Shutterstock.com)
Mit dem OpenJDK 21 ist gerade ein Release erschienen, für das Hersteller längeren Support (LTS) anbieten. Diese Version hat aber auch sonst einiges zu bieten.
Mit 15 JEPs (JDK Enhancement Proposals) bringt das OpenJDK 21 so vielen Themen wie lange nicht. Und es hält auch inhaltlich eine Menge interessanter Features für uns Java-Entwickler bereit. Einige Funktionen sind schon länger in Arbeit, darunter das Pattern Matching, die Virtual Threads, die Vector API oder auch die Foreign Function & Memory API. Während beim Pattern Matching und den Virtual Threads Teile finalisiert wurden, bleiben andere Aspekte weiterhin im Preview- oder auch Inkubator-Modus. Für Entwickler besonders spannend sind aber einige ganz neue Themen wie die String Templates, die "Unnamed Classes and Instance Main Methods" (beide zunächst als Preview dabei) und die Sequenced Collections
Beim Pattern Matching geht es darum, bestehende Strukturen mit Mustern abzugleichen, um komplizierte Fallunterscheidungen effizient und wartbar implementieren zu können. Es wird bereits seit einigen Jahren im Rahmen von Project Amber entwickelt. Bis zum letzten Release mit LTS-Support (OpenJDK 17) wurden zunächst nur Basis-Funktionen wie Switch Expressions, Sealed Classes, Records und Pattern Matching for instanceof abgeschlossen. Mit Java 21 kann es nun auch produktiv eingesetzt werden. Mit den Record Patterns und dem Pattern Matching for switch wurden zwei wichtige Bausteine finalisiert. Bei den Record Patterns handelt es sich um einen neuen Pattern Typ, der Records matched und gleichzeitig in ihre Bestandteile zerlegt (dekonstruiert), sodass direkt mit den Komponenten weitergearbeitet werden kann. Und mit Pattern Matching for switch werden alle bisherigen Funktionen zusammengebracht, sodass man in switch-Expressions nun neben den schon immer verfügbaren Constant Patterns auch Type- und Record Patterns inklusive der when-Clauses (früher Guarded Patterns genannt) einsetzen kann. Ganz frisch (in 21 als Preview eingeführt) sind die Unnamed Patterns. Dadurch lassen sich Platzhalter (der Unterstrich _) verwenden, wenn die Pattern Variablen nicht ausgewertet werden sollen. Das macht den Code kompakter, besser lesbar und weniger fehleranfällig (vermeidet toten Code). Dieses Konstrukt lässt sich auch in catch-Blöcken oder bei Lambda-Parametern als sogenannte Unnamed Variables einsetzen.
Da sind sich viele Experten einig und zeigen ihre Begeisterung für eines der wichtigsten Features in der Geschichte von Java, das sich direkt in eine Reihe mit Generics, Lambda-Ausdrücken und dem Plattform-Modul-System einreiht. Die Virtual Threads erlauben eine viel größere Anzahl gleichzeitiger Threads. Sie haben besonders beim Ressourcenverbrauch die Nase vorn gegenüber den klassischen Plattform-Threads. Dadurch können viel mehr (theoretisch Millionen) der virtuellen Threads in einem Prozess gestartet werden, ohne gleich an die Speichergrenzen der VM zu stoßen. Das ermöglicht eine bessere Auslastung der CPU. Die meisten Java Entwickler werden allerdings nicht direkt mit nebenläufiger Programmierung und Virtual Threads in Berührung kommen. Sie profitieren trotzdem, weil Framework-Hersteller (Spring, Quarkus, ...) Virtual Threads unter der Haube einbauen werden. Das ermöglicht gerade bei Webanwendungen eine bessere Auslastung, weil mehr eingehende Requests von Nutzern gleichzeitig verarbeitet werden können. Die Bremse sind ohnehin IO-Zugriffe (z. B. auf die Datenbank). Da die Requests aber sehr günstig zu erzeugen und zu betreiben sind (geringerer Speicherverbrauch) und so viel mehr gleichzeitig verwaltet werden können, lassen sich die vorhandenen Ressourcen besser nutzen.
Im Umfeld der nun abgeschlossenen Virtual Threads gibt es noch zwei, erneut als Preview erschienene Funktionen, die Structured Concurrency und die Scoped Values. Letzteres ist eine bessere Alternative zu den ThreadLocal-Variablen. Und Structured Concurrency ermöglicht die Bearbeitung von mehreren parallelen Teilaufgaben auf eine besonders les- und wartbare Art und Weise.
Einige der vom Funktionsumfang überschaubaren Features sind etwas überraschend im Release von Java 21 aufgetaucht. Besonders spannend sind die String Templates. Sie bringen nicht nur die lang ersehnte String Interpolation in die Java Welt. Die Implementierung ermöglicht in Zukunft sogar das einfache Erstellen eigener Template Prozessoren, die aus Texten mit Platzhaltern zum Beispiel JSON Objekte oder sichere Datenbankabfragen mit PreparedStatements erzeugen können.
Sequenced Collections bringen eine Handvoll neuer Methoden für Collections, deren Elemente in einer wohldefinierten Reihenfolge geordnet sind. Dazu zählen Lese- und Schreibzugriffe (inklusive Entfernen) auf das erste beziehungsweise letzte Element und das Umdrehen der Reihenfolge (reversed()). Dadurch wird das immer noch viel benutzte Collection Framework weiter aufgewertet.
Für Java-Einsteiger wird es in Zukunft auch leichter. Sie müssen zum Erstellen einer ausführbaren Klasse nicht mehr gleich die speziellen Konstrukte wie class, static, public, String[] args usw. verstehen. Mit dem "JEP 445: Unnamed Classes and Instance Main Methods (Preview)" kann man jetzt ausführbare main-Methoden kürzer und prägnanter definieren und sogar auf eine umschließende Klasse verzichten. In Kombination mit dem im JDK 11 veröffentlichten JEP "Launch Single-File Source-Code Programs" lassen sich sehr schlank kleine Java-Anwendungen in einer Textdatei mit einer simplen void main(){}-Methode von der Kommandozeile aufrufen. Und das kommt dann auch erfahrenen Java-Entwicklern zugute.
Die Vector API ist ein Dauerläufer und taucht seit Java 16 regelmäßig in den Releases auf, diesmal als sechster Inkubator (Vorstufe von Preview). Es geht dabei um die Unterstützung der modernen Möglichkeiten von SIMD-Rechnerarchitekturen mit Vektorprozessoren. Single Instruction Multiple Data (SIMD) lässt mehrere Prozessoren gleichzeitig unterschiedliche Daten verarbeiten. Durch die Parallelisierung auf Hardware-Ebene verringert sich beim SIMD-Prinzip der Aufwand für rechenintensive Schleifen.
Auch schon seit einigen Versionen mit an Bord ist die Foreign Function & Memory API, diesmal im 3. Preview. Wer schon sehr lange in der Java-Welt unterwegs ist, wird das Java Native Interface (JNI) kennen. Damit kann nativer C-Code aus Java heraus aufgerufen werden. Der Ansatz ist aber relativ aufwändig und fragil. Die Foreign Function API bietet einen statisch typisierten, rein Java-basierten Zugriff auf nativen Code (C-Bibliotheken). Zusammen mit dem Foreign-Memory Access API kann diese Schnittstelle den bisher fehleranfälligen und langsamen Prozess der Anbindung einer nativen Bibliothek beträchtlich vereinfachen. Mit letzterer bekommen Java-Anwendungen die Möglichkeit, außerhalb des Heaps zusätzlichen Speicher zu allokieren. Ziel der neuen APIs ist es, den Implementierungsaufwand um 90 Prozent zu reduzieren und die Leistung um Faktor 4 bis 5 zu beschleunigen. Beide APIs sind seit dem JDK 14 beziehungsweise 16 im JDK zunächst einzeln und ab 18 als gemeinsamer Inkubator-JEP enthalten. Vermutlich wird sich dieses Feature langsam der Finalisierung nähern.
Bei den Garbage Collectors hat sich auch etwas getan. Der vor wenigen Jahren im OpenJDK 15 eingeführte ZGC (Scalable Low-Latency Garbage Collector) gehört zu einer neuen Generation. Das Ziel ist, große Datenmengen (TB von RAM) mit möglichst kurzen GC-Pausen (kleiner 10 ms) aufzuräumen und so die Anwendung nahezu immer antwortbereit zu halten. Bisher machte der ZGC keine Unterscheidung zwischen frischen und schon länger existierenden Objekten. Die Idee ist, dass Objekte, die bereits einen oder mehrere GC-Läufe überlebt haben, auch in Zukunft wahrscheinlich noch lange weiterleben werden. Diese werden dann in einen extra Bereich (Old Generation) verschoben und müssen so bei den Standard-Läufen nicht mehr verarbeitet werden. Das kann einen Schub bei der Performance einer Anwendung geben.
Es gibt noch einige weitere, für Entwickler nicht so relevante JEPs. Für die vielen Details lohnt auch ein Blick auf die Release Notes [3]. Änderungen am JDK (Java Klassenbibliothek) lassen sich zudem sehr schön über den Java Almanac [4] nachvollziehen. In dieser Übersicht finden sich unter anderem alle Neuerungen zu den String Templates und den Sequenced Collections. In der String-Klasse gab es auch kleine Erweiterungen: Beispielsweise wurde die Methode indexOf(String str, int beginIndex, int endIndex) eingeführt, die in einem bestimmten Bereich nach einem Teil-String sucht. Die Klassen StringBuffer und StringBuilder wurden jeweils um zwei ähnliche Methoden erweitert, die ein Zeichen oder eine Zeichenkette wiederholt mal an das bestehende Objekt anhängen: repeat(CharSequence, int). Die Klasse Character wurde wiederum um eine Vielzahl von Methoden erweitert, die prüfen, ob eine Unicode-Zeichen ein Emoji oder eine Variante davon darstellt. Java geht also auch hier mit der Zeit.
Einen ausführlichen Überblick über das Java-21-Release findet sich im frisch erschienen iX-Artikel [5]. Durch die Finalisierung der Virtual Threads wird Java 21 in ein paar Jahren auf eine Stufe mit Java 5 (Generics), Java 8 (Lambdas, Stream-API) und Java 9 (Plattform Modul System) gestellt werden. Auch wenn sich das Potenzial dieser Idee noch nicht vollständig erfassen lässt, werden die virtuellen Threads die Implementierung von hochskalierbaren Server-Anwendungen in Zukunft stark vereinfachen. Aber Java 21 hält noch viele andere Highlights bereit. Beim Pattern Matching wurden das Kernstück (Pattern Matching for switch) sowie die Record Patterns finalisiert und die Unnamed Patterns als Preview eingeführt. Die String Templates (im Moment noch als Preview) und auch die Sequenced Collections erleichtern Java-Entwicklern das Leben. Das steigert schon jetzt die Vorfreude auf das nächste Release im März 2024.
URL dieses Artikels:
https://www.heise.de/-9309203
Links in diesem Artikel:
[1] https://java.bettercode.eu/
[2] https://java.bettercode.eu/index.php#programm
[3] https://jdk.java.net/21/release-notes
[4] https://javaalmanac.io/jdk/21/apidiff/17/
[5] https://www.heise.de/tests/Java-21-Version-mit-LTS-String-Templates-und-Virtual-Threads-vorgestellt-9302335.html
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Der Community Day für Java Developers bietet am 16. Oktober Expertenvorträgen und Demos, die sich auf Java und Open Source konzentrieren.
Der iJUG e.V. [1] (Interessenverbund der Java User Groups) hat sich mit der Eclipse Foundation [2] zusammengetan, um im Rahmen der EclipseCon am 16. Oktober ein Tagesevent speziell für die (deutschsprachige) Java Community zu gestalten. Hier gibt es einen ganzen Tag voll Java Themen zu einem fairen Preis.

Der Community Day für Java Developers [3] auf der EclipseCon [4] ist ein ganztägiges Programm mit Expertenvorträgen, Demos und anregenden Sessions, die sich auf Java und die Entwicklung von Unternehmensanwendungen unter Verwendung von quelloffenen, herstellerunabhängigen Prozessen und Technologien konzentrieren. Die Open-Source-Projekte Jakarta EE [5], Adoptium [6] und MicroProfile [7] sowie andere von der Eclipse Foundation gehostete Java-Projekte und -Communities werden von weltweit führenden Java-Innovatoren wie Azul [8], Google [9], IBM [10], Microsoft [11], Open Elements [12], Oracle [13], Red Hat [14] und Tomitribe [15] unterstützt.
Mit 14 technischen Sessions, Networking und Verpflegung kostet das eintägige Event weniger als 50 Euro. Das wird durch die Zusammenarbeit zwischen der Eclipse Foundation, dem iJUG e.V. und den Sponsoren der EclipseCon ermöglicht.
Die Veranstaltung ist eine gute Gelegenheit, um herauszufinden, wie andere diese Technologien nutzen, sich mit Expertinnen und Experten aus der Community zu treffen, die wichtigsten Aspekte der Jakarta EE-, Adoptium- und MicroProfile-Technologien besser zu verstehen und Ideen mit innovativen Personen und Unternehmen des Ökosystems zu teilen.
URL dieses Artikels:
https://www.heise.de/-9192048
Links in diesem Artikel:
[1] https://www.ijug.eu/
[2] https://www.eclipse.org/
[3] https://www.eclipsecon.org/2023/java-community-day
[4] https://www.eclipsecon.org/2023
[5] https://jakarta.ee/
[6] https://adoptium.net/
[7] https://microprofile.io/
[8] https://www.azul.com/
[9] https://about.google/
[10] https://www.ibm.com/
[11] https://www.microsoft.com/
[12] https://open-elements.com/
[13] https://www.oracle.com/
[14] https://www.redhat.com/
[15] https://www.tomitribe.com/
[16] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: (c) Flickr)
Wer in Crowdfunding-Projekte investiert, muss sich den Risiken bewusst sein. Die Plattformen weisen meist jede Verantwortung von sich.
Crowdfunding hilft beim Anstoßen von Projekten, indem zahlreiche Unterstützer in ein Projekt investieren, an das sie glauben. Der Erfolg ist aber nicht garantiert, und es gilt auf Betrugsmaschen zu achten, zumal die Crowdfunding-Plattformen das Risiko auf die Investoren abwälzen.
Ich möchte mit einer Erfolgsgeschichte beginnen:
Bambu Lab war völlig unbekannt, als das aufstrebende 3D-Drucker-Unternehmen seine X1/X1C-Kampagne über Kickstarter startete. Es sammelte schließlich fast 55 Millionen HK-$ von 5575 Unterstützern. In den folgenden Monaten stellte Bambu Lab die X1/X1C-Produktlinie fertig und schickte alle Perks an die Unterstützer. Dieser neue CoreXY 3D-Drucker erwies sich als revolutionäres, preisgekröntes und äußerst erfolgreiches Produkt, dem bald weitere Produkte wie der P1P und der P1S folgten. Es erübrigt sich zu sagen, dass Bambu Lab eine riesige Erfolgsgeschichte mit einem glücklichen Ende für das Crowdfunding-Unternehmen, den Kampagneninhaber und die Unterstützer war.
Einer der Vorteile von Crowdfunding lässt sich wie folgt zusammenfassen: Crowdfunding-Plattformen bringen innovative Kampagnenmacher und begeisterte Unterstützer zusammen. Sie ermöglichen es Start-ups und etablierten Unternehmen, Finanzmittel für innovative Produkte zu erhalten.
Im Nachhinein betrachtet, funktionieren nicht alle Kampagnen so gut. In einigen Fällen liefern die Werber kein Produkt, stellen nur ein unterdurchschnittliches Produkt her, haben kein Geld mehr oder entpuppen sich als Betrüger. Jahr für Jahr gehen auf diese Weise Millionen von US-Dollar verloren. Es ist nie vorhersehbar, ob ein Projekt erfolgreich sein wird, wie es bei Joint Ventures ebenfalls der Fall ist. Gründe für das Scheitern können die Undurchführbarkeit der Innovation, Budgetüberschreitungen, enorme Projektverzögerungen durch unglückliche Umstände wie Covid-19, zu niedrig angesetzte Kosten oder drastische Preiserhöhungen für notwendige Komponenten sein.
Das Scheitern von Projekten lässt sich zwar nie vermeiden, aber Betrug schon.
Ein chinesischer Kampagnenbetreiber sammelte mit seiner Indiegogo-Kampagne für den kleinsten Mini-PC der Welt über eine Million US-Dollar ein, schaffte aber keine der versprochenen Perks. Nach einiger Zeit gab es sogar keine Kommunikation mehr zwischen den Unterstützern und dem Kampagnenbesitzer. Es schien, als sei der Eigentümer einfach von der Bildfläche verschwunden. Als die Unterstützer Indiegogo um Hilfe baten, fühlte sich das Crowdfunding-Unternehmen nicht zuständig. Sie sperrte einfach alle weiteren Beiträge, versah die Projektwebsite mit dem Hinweis "Diese Kampagne wird derzeit untersucht", lieferte aber weder die Ergebnisse der sogenannten Untersuchung noch eine Rückerstattung an die betrogenen Kunden.
Lektion 1: Crowdfunding-Unternehmen kümmern sich nicht (allzu sehr) um die Unterstützer. Sie verdienen Geld, indem sie eine Plattform für verschiedene Parteien bereitstellen, und behandeln die Geldgeber wie Risikokapitalgeber, die alle Risiken selbst tragen sollen.
Indiegogo und Kickstarter agieren im Grunde wie Wettbüros für Pferderennen, bei denen fast keine Transparenz über die Pferdebesitzer (auch Kampagnenbesitzer genannt) herrscht. Jeder Teilnehmer an solchen Szenarien trägt hohe Risiken, wobei das Wettbüro die einzige Ausnahme ist. Offensichtlich sind die Regeln zwischen den Kunden und der Crowdfunding-Plattform so definiert, dass die Bank (oder das Wettbüro) immer gewinnt.
Lektion 2: Wer sich an einer Crowdfunding-Kampagne beteiligen möchte, sollte mit einem Scheitern des Projekts und dem vollständigen Verlust der Beiträge leben können.
Jeder Unterstützer sollte sich dieser Realität bewusst sein. Er/sie könnte seinen/ihren gesamten Beitrag verlieren oder ein überbezahltes oder sogar nutzloses Produkt erhalten. Sicher, die Mehrheit der Kampagnen ist letztlich erfolgreich. Es gibt jedoch auch eine beträchtliche Anzahl von Kampagnen, die scheitern. Ich mache mir keine Sorgen um das Scheitern von Projekten trotz der enormen Anstrengungen der Kampagnenbetreiber. Das ist ein bekanntes und akzeptables Risiko, das die Geldgeber im Hinterkopf behalten sollten, wenn sie einen Beitrag leisten. Aber ich mache mir Sorgen um betrügerische Kampagnen, bei denen die Betreiber einfach die gesammelten Beiträge nehmen und verschwinden.
Lektion 3: Wer dringend ein bestimmtes Produkt benötigt, sollte sich nicht an einer Crowdfunding-Kampagne beteiligen, sondern es stattdessen bei etablierten Quellen kaufen.
Lektion 4: Derzeit gibt es keine Sicherheitsnetze für Unterstützer. Auch gibt es keine Transparenz oder Rechenschaftspflicht gegenüber den Kampagnenbetreibern. Eine Kampagne gleicht einem Spiel oder einer Wette auf die Zukunft, ohne ausreichende Transparenz in Bezug auf die Eigentümer der Kampagne.
Lektion 5: Man sollte nicht den Videos und Dokumenten trauen, die von Kampagnenbetreibern bereitgestellt werden. Diese Informationen sollte man als eine reine Marketing- und Werbekampagne betrachten und niemals irgendwelchen Versprechungen trauen, vor allem nicht solchen, die unrealistisch oder sehr, sehr schwierig zu erfüllen scheinen. Sätze wie "das weltweit erste", "das weltweit schnellste" oder "das weltweit kleinste" sollten die Unterstützer skeptisch machen.
Was könnte man tun, um solche Situationen zu vermeiden? Oder ist die Crowdfunding-Plattform von Natur aus nicht in der Lage, die Unterstützer zu schützen?
Eigentlich sollte es eine Art Vertrauensverhältnis zwischen allen Akteuren im Spiel geben – ja, es ist ein Spiel beziehungsweise eine Wette! Um das richtige Maß an Vertrauen zu erreichen, muss ein Crowdfunding-Unternehmen folgende Dienstleistungen anbieten:
Eigene Gegenmaßnahmen
Für Backer bzw. Sponsoren einer Crowdfunding-Kampagne existieren aufgrund der beschriebenen Tatsachen zurzeit nur wenige Möglichkeiten, Risiken zu vermeiden. Eine offensichtliche, wenn auch radikale Option wäre, einfach nicht an Crowdfunding-Kampagnen teilzunehmen. Würden alle Nutzer so verfahren, gingen allerdings Anbieter wie Kickstarter in kürzester Zeit pleite. Zudem hätten die ehrlichen, kleinen Kampagnenbetreiber das Nachsehen, die ohne diese Geldquelle ihre Projekte nicht umsetzen könnten.
Daher ist das erste Gebot, sich über den jeweiligen Kampagnenbetreiber detaillierte Informationen zu beschaffen. Natürlich hat diese Informationsakquise ihre Grenzen. Ist der Kampagnenbetreiber eine renommierte, bekannte Firma, die bereits seit Längerem im Geschäft ist und gute Produkte auf den Markt bringt? Falls ja, dürfte das Risiko erheblich geringer sein als bei "dubiosen" oder mehr oder weniger "anonymen" Geschäftspartnern. Inzwischen nutzen auch renommierte Unternehmen zunehmend die Möglichkeit des Crowdfunding.
Eine weitere Möglichkeit besteht darin, sich auf dem Markt nach ähnlichen Produkten umzusehen. Nicht jedes als innovativ angepriesenes Produkt ist es wirklich. Gibt es bereits stark verwandte Alternativen, sollte man besser zu diesen greifen. Es hat insbesondere Vorteile, Produkte von einem Shop zu beziehen, wenn Käufe dort abgesichert sind wie bei Zahlung über Paypal oder Kreditkarte der Fall.
Fast jedes über Kickstarter oder Indiegogo erworbene Produkt ist nach Beendigung der Kampagne über Stores verfügbar, wenn auch zu höheren Preisen. Die Ersparnis durch Finanzierung einer Kampagne gegenüber dem UVP kann schon einiges ausmachen. In manchen Fallen könnte sich ein Abwarten trotzdem vor allem lohnen, wenn die Differenz zwischen Crowdfunding-Preis und Endpreis eher marginal ist. Abwarten hat auch den Vorteil, dass relativ zeitnah nach Produktveröffentlichungen in der Regel auch einige Produktreviews folgen, denen Interessierte die Vorteile und Nachteile des Produkts entnehmen können. Bei Crowdfunding kauft man schließlich die Katze im Sack.
Teilweise finden sich bei der Websuche auch Bewertungen von Kampagnen, bei denen zum Teil Experten ihre Einschätzung verlautbaren. Diese Quellen erweisen sich oft als sehr hilfreich.
Crowdfunding-Sponsoren sollten sich nicht von virtuellen Demo-Videos oder Lobpreisungen des Anbieters mit Superlativen täuschen lassen. Zeigt ein Demovideo nur das grafisch simulierte Produkt, kann das zwar die einzige Option des Herstellers sein, aber auch ein bewusst produziertes Fake. Beispielsweise hat eine Kampagne für 3D-Drucker den Druckkopf in unterschiedlichen Varianten gezeigt, wovon aber bei den angebotenen Perks nie die Rede war. Aber auch bei der Illustration echter Prototypen ist Vorsicht geboten. Dahinter kann sich schließlich Dummy-Funktionalität verbergen. Stutzig sollten Interessierte werden, wenn das Produkt nie im Detail erscheint. Gehen aus der Beschreibung technische Spezifikationen und die Funktionsweise detailliert hervor, so lässt es sich besser einschätzen als bei vagen, lückenhaften, unrealistischen oder schwammigen Aussagen.
Wie bereits erwähnt, sollten Geldgeber ihre eigene Risikobereitschaft unter die Lupe nehmen. Handelt es sich um höhere Geldbeträge, deren Verlust sehr schmerzhaft wäre, sollte man von einer Kampagne Abstand nehmen. Das ist zugegebenermaßen schwer, weil sich Kampagnen unseren instinktiven Hang nach Vergünstigungen und coolen Gadgets zunutze machen. Es geht darum, unsere Entscheidungen bewusst und vernünftig zu treffen. Eine Nacht darüber zu schlafen, ist hier immer die bessere Option, auch wenn dann statt den Super-Early-Bird-Angeboten nur noch Early-Bird-Angebote übrigbleiben. Es empfiehlt sich, nicht gleich zu dem eigentlichen Produkt alles mögliche Zubehör mitzubestellen. Ist das Projekt erfolgreich, lässt sich Zubehör auch im Nachhinein bestellen. Dadurch bleibt der eingesetzte Geld- beziehungsweise Wettbetrag geringer.
Einige mögen argumentieren, dass all diese Maßnahmen die Freiheit der Kampagnenbesitzer einschränken. In dieser Hinsicht haben sie recht. Allerdings besteht derzeit ein Ungleichgewicht zwischen Geldgebern, Kampagneninitiatoren und Crowdfunding-Plattformen, sodass die meisten Risiken bei den Geldgebern liegen. Daher erscheint es mehr als fair, diese Risiken unter allen Beteiligten aufzuteilen. Ich bin der festen Überzeugung, dass sich Crowdfunding zu einer Sackgasse entwickelt, wenn Unternehmen wie Indiegogo weiterhin alle Lasten auf die Unterstützer abwälzen, sich nicht um Betrug kümmern, sich weigern, Sicherheitsnetze zu schaffen, oder die hohe Intransparenz beibehalten. Wenn sie jedoch alle oder zumindest einige der oben genannten Maßnahmen umsetzen, wird sich dies eindeutig als ein Win/Win/Win-Szenario herausstellen.
URL dieses Artikels:
https://www.heise.de/-9297529
Links in diesem Artikel:
[1] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: raigvi / Shutterstock)
Eine Artikelserie führt in die Grundlagen von Edge AI ein und zeigt, wie sich künstliche neuronale Netze auf eingebetteten System ausführen lassen.
Wenn Softwareentwicklerinnen und Softwareentwickler von Artificial Intelligence (AI) und Machine Learning (ML) sprechen, meinen sie überwiegend künstliche neuronale Netze (KNN), deren Training und Inferenz vorzugsweise auf leistungsfähiger Enterprise-Hardware erfolgt. Dank Werkzeugen wie TensorFlow Lite (Micro) und Edge Impulse ist es heute möglich, zumindest die Inferenz eines neuronalen Netzes auch auf eingebetteten Systemen mit beschränkten Ressourcen durchzuführen. Dies hat den Charme, dass die Verarbeitung von Daten dort stattfinden kann, wo die Daten auch anfallen. Beispiele hierfür umfassen autonomes Fahren und die Automatisierungstechnik.
In einer dreiteiligen Artikelserie bespreche ich ab dem 18. August 2023 zunächst wichtige KI-Grundlagen (Teil 1), danach die Arbeit mit TensorFlow Lite (Teil 2), und zu guter Letzt die Anwendung des MLOps-Online-Werkzeugs Edge Impulse (Teil 3). Im dritten Teil kommt außerdem der KI-gestützte Entwicklerassistent GitHub Copilot zur Sprache, der das Entwickeln eingebetteter Software erlaubt.
Ziel dieser Rundreise ist es, interessierte Leserinnen und Leser mit KI-Technologien und Werkzeugen für eingebettete Systeme vertraut zu machen, sodass sie eigene Experimente durchführen können.
URL dieses Artikels:
https://www.heise.de/-9234664
Links in diesem Artikel:
[1] mailto:map@ix.de
Copyright © 2023 Heise Medien

(Bild: Sundry Photography/Shutterstock.com)
Es gibt nicht nur einen Anbieter für Java-Distributionen und Support. Gartner hat in einem Report die Optionen analysiert, und Oracle schneidet nicht gut ab.
Für die meisten Unternehmen gehören sowohl Java als Programmiersprache als auch die JVM als Laufzeitumgebung zur kritischen Infrastruktur, auf der ein großer Teil unserer digitalen Welt aufgebaut ist. Da für die kritische Infrastruktur im Enterprise-Umfeld immer geraten wird, über passende Support-Möglichkeiten zu verfügen, besitzen viele Firmen einen kommerziellen Support-Vertrag für Java. Diese Verträge wurden historisch oft mit Oracle geschlossen, da das Unternehmen lange Zeit der prominenteste Anbieter für Java-Distributionen war. Da sich aber in den letzten Jahren viel in diesem Bereich getan hat, stellt sich die Frage, ob Oracle hier noch immer der beste Partner für den kommerziellen Support von Java ist.
In vielen Bereichen der heutigen Welt ist Diversität ein wichtiges Thema, da hierdurch neue Ansichten, Lösungen und Möglichkeiten entstehen. Auch im Bereich der Java-Laufzeitumgebungen hat sich hier in den letzten Jahren einiges getan. Die Zeit, in der Entwicklerinnen und Entwickler Java prinzipiell von Oracle heruntergeladen haben, da es der Platzhirsch bei Java-Distributionen war, ist lange vorbei. Durch die fortschreitende Beliebtheit von Open Source arbeiten mehr und mehr Firmen am OpenJDK [1] mit, der quelloffenen Implementierung der Java Standard Edition. Da auch die Distributionen von Oracle aus diesen Quellen gebaut werden, kann man somit auch problemlos zu Alternativen greifen. Dazu kommt, dass durch das Java Test Compatibility Kit (TCK) viele der Laufzeitumgebungen auf ihre Kompatibilität zum Standard hin überprüft werden.
Eclipse hat einen Marketplace eröffnet [2], in dem alle TCK und AQAvit verifizierten beziehungsweise lizenzierten Java-Laufzeitumgebungen zum Download angeboten werden. Neben verschiedenen Builds von Firmen wie Microsoft oder Azul tut sich hier vor allem Eclipse Temurin [3] hervor, das als einzige Java Distribution eine herstellerunabhängige Variante ist. Verantwortlich ist die Eclipse-Adoptium-Arbeitsgruppe, der Firmen wie Microsoft [4], Red Hat [5], Google [6] und Open Elements [7] angehören. Mit über 200 Millionen Downloads [8] gibt es auch keine andere Java-Distribution, die aufgrund ihrer Zahlen auch nur ansatzweise an die Verbreitung von Eclipse Temurin herankommt. Dies unterstreicht ein aktueller Gartner-Bericht [9], laut dem 2026 über 80 Prozent aller Java Anwendungen voraussichtlich nicht auf einer Oracle-Distribution laufen werden. Eclipse Temurin macht hier am Ende sicherlich das größte Stück des Kuchens aus.

Neben der Analyse verschiedener Distributionen hat Gartner die verschiedenen Möglichkeiten der kommerziellen Support-Optionen für Java untersucht. Hierbei hat vor allem der Oracle-Support nicht wirklich gut abgeschnitten:
Oracle hat erneut die Lizenzregeln für seine Java-Distributionen geändert. Am 23. Januar 2023 führte das Unternehmen eine neue Lizenzmetrik ein, die SE Universal Subscription [10]. Das kontroverse Preismodell zieht als Basis die Gesamtzahl der Kundenmitarbeiter heran und nicht die Anzahl der Mitarbeiter, die die Software nutzen. Möglicherweise versucht Oracle so, dass Kunden keine anderen Support-Modelle für Java in Erwägung ziehen. Für Kunden führt das in vielen Fällen dazu, dass die Support-Kosten für Java durch die Decke gehen. Laut Gartner entstehen hier für die meisten Organisationen zwei- bis fünfmal so hohe Kosten. Dazu kommt natürlich, dass man durch einen kommerziellen Support bei Oracle nur Support für die Oracle-Distribution erhält und nicht etwa für das immer beliebter werdende Eclipse Temurin. Vielleicht ist daher genau jetzt der richtige Zeitpunkt, sich einmal nach alternativen Angeboten für Java Support umzuschauen.
Natürlich haben Organisationen wie Azul oder auch die Arbeitsgruppe von Eclipse Adoptium auf diese Ereignisse reagiert. Mike Milinkovich, der Executive Director der Eclipse Foundation [11], kommentierte das Ganze wie folgt auf X / Twitter:

(Bild: Twitter / X)
Aber neben diesem Kommentar ließ Adoptium auch Taten sprechen und hat eine Seite für kommerziellen Support für Eclipse Temurin [12] eingerichtet. Auf dieser wird mit Red Hat, IBM und Open Elements gleich durch drei Experten der Branche Support für Eclipse Temurin angeboten. Hervorzuheben ist hierbei für den deutschsprachigen Raum Open Elements, da diese mit ihrem "Support & Care"-Paket [13] nicht nur aktiv Temurin als Open-Source-Projekt fördern, sondern auch Support in deutscher Sprache anbieten.
Wie man sehen kann, ist auch das Angebot an Support-Optionen für die Java Laufzeitumgebung in den letzten Jahren deutlich diverser geworden. Neben dem Angebot von Oracle gibt es nun verschiedene Möglichkeiten, die oft deutlich besser auf die eigenen Anforderungen zugeschnitten sind. Natürlich bedeutet das auch, dass jede Firma über den Tellerrand schauen und Alternativen zum bereits vor Jahren abgeschlossenen Oracle-Support begutachten und bewerten muss. Für Firmen, die bisher über keinen Support-Vertrag verfügen, eignen sich einige der Angebote vielleicht deutlich eher, als direkt mit dem Riesen Oracle einen Vertrag zu schließen. Aber auch das Angebot von Oracle hat seine Berechtigung und wird für einige Firmen das passende sein. Daher will ich hier nicht ein Angebot als Gewinner darstellen, sondern die Vielfalt der Möglichkeiten dank Firmen wie IBM, Red Hat, Azul, Open Elements und natürlich Oracle als Gewinn für die gesamte Java Community aufzeigen.
URL dieses Artikels:
https://www.heise.de/-9232113
Links in diesem Artikel:
[1] https://openjdk.org/
[2] https://adoptium.net/marketplace/
[3] https://adoptium.net/de/
[4] https://www.microsoft.com/openjdk
[5] https://www.redhat.com
[6] https://cloud.google.com/java
[7] https://open-elements.com/
[8] https://dash.adoptium.net/
[9] https://www.gartner.com/en/documents/4540799
[10] https://www.oracle.com/us/corporate/pricing/price-lists/java-se-subscription-pricelist-5028356.pdf
[11] https://www.eclipse.org
[12] https://adoptium.net/temurin/commercial-support/
[13] https://open-elements.com/temurin-support/
[14] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Die Verbindung von eingebetteten Systemen und Servern kann über REST-Kommunikation erfolgen
(Bild: pixabay.com)
Wie kommuniziert ein Arduino-Board serverseitig mit einer REST-API, um Sensor-Messungen zu speichern? Nach dem Server in Teil 1 steht die Client-Seite an.
Arduino-Boards oder andere Microcontroller-Boards beziehungsweise eingebettete Systeme oder Einplatinencomputer können mit einer REST-Anwendung kommunizieren, wenn sie einen WiFi- oder Ethernet-Anschluss integrieren. Da ein typischer Anwendungsfall wie der hier vorgestellte überwiegend Messungen mit Sensoren durchführt, erweist eine Echtzeituhr (RTC) als Vorteil. Dadurch lassen sich zusätzlich zu den Messdaten Zeitstempel (Datum und Zeit) hinzufügen, die später eine historische Analyse ermöglichen, etwa den Verlauf der Temperatur über einen bestimmten Zeitraum.
Auch wenn hier vom Arduino Giga die Rede ist, beschränkt sich die Anwendung keineswegs nur auf dieses Board, sondern lässt sich relativ leicht für andere Arduino-, STM- oder ESP-Boards anpassen, für die funktional ähnliche Bibliotheken wie WiFi, WiFiUdp und HTTPClient in der Arduino IDE oder in Visual Studio Code mit PlatformIO-Plug-in bereitstehen.
Notwendig ist ein Sensor von Bosch Sensortec aus der BME-Familie (BME68x, BME58x, BME38x, BME28x), den Maker über I2C oder SPI anschließen. Für das Beispiel kam ein BME688 zum Einsatz, den es als Breakout-Board von verschiedenen Herstellern wie Pomoroni oder Adafruit gibt. Wer möchte, kann auch ein Bosch Development Kit kaufen. Dieses Board besteht aus einem BME688-Adapter, der huckepack auf einem Adafruit Huzzah32 Feather Board (ESP32) sitzt. Das schlägt mit rund 100 Euro zu Buche, hat aber den Charme, sich mittels der kostenlosen BME-AI-Studio-Software trainieren zu lassen. Der Sensor lernt dabei, über ein neuronales Netz verschiedene Gasmoleküle in der Luft zu erkennen, wie Kaffee, CO₂ oder Chlor. Er ermittelt für die Moleküle in der Luft Widerstände in Ohm und kann über die elektrische Charakteristik Gase klassifizieren. Diese spezifischen ML-Trainings sind mit Breakout-Boards freilich nicht möglich – der Anwender erfährt dort nur den Widerstand des Gases ohne Zuordnung zu einem konkreten Molekül. Dafür kosten die einfachen Boards auch nur zwischen 20 und 30 Euro.
Wie bereits im ersten Teil [1] erwähnt, findet sich der Quellcode für die Beispiele in dem GitHub Repository [2].
Ein Hinweis vorab: Als mögliche Alternative für die hier vorgestellte Integration über eine RESTful-Architektur käme beispielsweise der Einsatz von MQTT infrage, das eine ereignis- beziehungsweise nachrichtenorientierte Kommunikation zwischen Client und Server ermöglicht. In vielen Fällen, vielleicht auch für den hier vorliegenden, ist MQTT eine sehr gute Option. Allerdings fokussieren sich die beiden Artikelteile speziell darauf, Kommunikation und Backend-Integration über REST-APIs zu veranschaulichen. Ein vom Backend betriebener Microservice stellt schließlich typischerweise eine REST-API bereit.
In der konkreten Schaltung sind die folgenden Verbindungen notwendig:
Arduino ........ BME688
3.3V ............ Vin
GND ............. GND
SCL ............. SCK
SDA ............. SDI
Folgendes Fritzing-Diagramm veranschaulicht dies:

Beim Entwickeln der Arduino-Software sind folgende Verantwortlichkeiten zu beachten:
Initiales Setup:
Kontinuierliche Loop:
Nebenbei soll der Sketch Informationen über den seriellen Monitor zu Test- und Beobachtungszwecken ausgeben.
Der Arduino-Sketch erwartet im selben Verzeichnis eine Datei arduino_secrets.h, die Definitionen für das gewünschte WLAN enthalten, konkret die SSID und den WLAN-Key. Für die Nutzung des Arduino-WiFis bedarf es einer entsprechenden WiFi-Bibliothek, deren Header wir inkludieren, zum Beispiel: #include <WiFi.h>. Zusätzlich benötigen wir die Bibliothek ArduinoHttpClient, die wir über den Library Manager der Arduino IDE oder VS Code & PlatformIO installieren.
Den Verbindungsaufbau zum WLAN übernimmt nachfolgender Code:
void setup() {
// Seriellen Stream starten
Serial.begin(9600);
// Verbindungsaufbau WiFi
while (status != WL_CONNECTED) {
Serial.print("Versuche Verbindungsaufbau zum WLAN-Netz: ");
Serial.println(ssid); // print the network name (SSID);
// Verbinden mit WPA/WPA2 Netzwerk:
status = WiFi.begin(ssid, pass);
}
// Name des WLANs nach erfolgtem Verbindungsaufbau:
Serial.print("SSID: ");
Serial.println(WiFi.SSID());Anschließend soll der Zugriff auf einen NTP-Server zum Einstellen der Echtzeituhr verhelfen.
Beim Giga R1 Board sind dazu folgende Header-Dateien notwendig:
#include <WiFiUdp.h> // zum Versenden von NTP-Paketen notwendig
#include <mbed_mktime.h>
Das schaut auf anderen Boards natürlich anders aus und wäre diesbezüglich zu ändern.
Der eigentliche Code für das Setzen der Echtzeituhr befindet sich in der Methode setNtpTime(), die ihrerseits eine UDP-Verbindung mit einem lokalen Port öffnet, ein Anfragepaket an den gewünschten Zeitserver verschickt (sendNTPacket()), um danach die Antwort über parseNtpPacket() zu empfangen, zu verarbeiten und die Echtzeituhr mit der aktuellen Zeit einzustellen. Hat dies erfolgreich geklappt, lässt sich fortan über die Methode getLocalTime() stets die aktuelle Zeit aus der Echtzeituhr auslesen. Zurückgeliefert wird jeweils ein Datetime-String, der sich aus Datum und Zeit zusammensetzt: „2023-06-05 12:31:45“.
// NTP-Anfrage senden, Antwort erhalten und parsen
void setNtpTime()
{
status = WL_IDLE_STATUS;
Udp.begin(localPort);
sendNTPpacket(timeServer);
delay(1000);
parseNtpPacket();
}
// Rufe einen Zeitserver auf
unsigned long sendNTPpacket(const char * address)
{
memset(packetBuffer, 0, NTP_PACKET_SIZE);
packetBuffer[0] = 0b11100011; // LI, Version, Modus
packetBuffer[1] = 0; // Stratum, Art der Uhr
packetBuffer[2] = 6; // Abfrageintervall
packetBuffer[3] = 0xEC; // Präzision der Uhr
// 8 Bytes von Nullen für Root Delay & Root Dispersion
packetBuffer[12] = 49;
packetBuffer[13] = 0x4E;
packetBuffer[14] = 49;
packetBuffer[15] = 52;
Udp.beginPacket(address, 123); // NTP Aufrufe erfolgen über Port 123
Udp.write(packetBuffer, NTP_PACKET_SIZE);
Udp.endPacket();
}
// Hier wird das NTP-Antwortobjekt empfangen und geparst:
unsigned long parseNtpPacket()
{
if (!Udp.parsePacket())
return 0;
Udp.read(packetBuffer, NTP_PACKET_SIZE); // Paket vom NTP-Server empfangen
const unsigned long highWord = word(packetBuffer[40], packetBuffer[41]);
const unsigned long lowWord = word(packetBuffer[42], packetBuffer[43]);
const unsigned long secsSince1900 = highWord << 16 | lowWord;
constexpr unsigned long seventyYears = 2208988800UL;
const unsigned long epoch = secsSince1900 - seventyYears;
set_time(epoch);
// Folgende ausführliche Beschreibung lässt sich ausgeben,
// sobald man DETAILS definiert
#if defined(DETAILS)
Serial.print("Sekunden seit Jan 1 1900 = ");
Serial.println(secsSince1900);
// NTP time in "echte" Zeit umwandeln:
Serial.print("Unix Zeit = ");
// Ausgabe der Unix time:
Serial.println(epoch);
// Stunde, Minute, Sekunde ausgeben:
Serial.print("Die UTC Zeit ist "); // UTC entspricht Greenwich Meridian (GMT)
Serial.print((epoch % 86400L) / 3600); // Stunde ausgeben (86400 sind die Sekunden pro Tag)
Serial.print(':');
if (((epoch % 3600) / 60) < 10) {
// In den ersten 10 Minuten einer Stunde brauchen wir eine führende Null
Serial.print('0');
}
Serial.print((epoch % 3600) / 60); // Minute ausgeben (3600 = Sekunden pro Stunde)
Serial.print(':');
if ((epoch % 60) < 10) {
// In den ersten 10 Minuten einer Stunde brauchen wir eine führende Null
Serial.print('0');
}
Serial.println(epoch % 60); // Sekunde ausgeben
#endif
return epoch;
}
// Lokale Zeit mittels RTC (Real Time Clock) ermitteln:
String getLocaltime()
{
char buffer[32];
tm t;
_rtc_localtime(time(NULL), &t, RTC_FULL_LEAP_YEAR_SUPPORT);
strftime(buffer, 32, "%Y-%m-%d %k:%M:%S", &t);
return String(buffer);
}
Für Interessierte, die mehr über das NTP (Network Time Protocol) erfahren möchten, eine Abbildung mit anschließenden Erläuterungen, die den Aufbau eines NTP-Pakets veranschaulichen:

Die Header-Einträge eines NTP-Pakets gestalten sich oben wie folgt:
LI
Leap Indicator (2 bits)
Dieses Attribut zeigt an, ob die letzte Minute des aktuellen Tages eine Zusatzsekunde benötigt.
0: Keine Sekundenanpassung nötig
1: Letzte Minute soll 61 sec haben
2: Letzte Minute soll 59 sec haben
3: Uhr wird nicht synchronisiert
VN
NTP-Versionsnummer (3 Bits) (etwa Version 4).
Mode
NTP-Paketmodus (3 Bits)
0: Reserviert
1: Symmetrisch aktiv
2: Symmetrisch passiv
3: Client
4: Server
5: Broadcast
6: NTP-Kontrollnachricht
7: Für private Nutzung reserviert
Stratum
Stratum-Ebene der Zeitquelle (8 bits)
0: Unspezifiziert oder ungültig
1: Primärer Server
2–15: Sekundärer Server
16: Unsynchronisiert
17–255: Reserviert
Poll
Poll Interval (8-Bit Ganzzahl mit Vorzeichen), die in Sekunden definiert, was das maximale Zeitintervall zwischen aufeinander folgenden NTP-Nachrichten sein soll.
Precision
Präzision der Uhr (8-Bit Ganzzahl mit Vorzeichen)
Root Delay
Die Round-Trip-Verzögerung vom Server zur primären Zeitquelle. Es handelt sich um eine 32-Bit Gleitpunktzahl, die Sekunden festlegt. Der Dezimalpunkt befindet sich zwischen Bits 15 und 16. Sie ist nur für Server-Nachrichten relevant.
Root Dispersion
Der maximale Fehler aufgrund der Toleranz bezüglich der Uhr-Frequenz. Es handelt sich um eine 32-Bit Gleitpunktzahl, die Sekunden festlegt. Der Dezimalpunkt befindet sich zwischen Bits 15 und 16. Sie ist nur für Servernachrichten relevant
Reference Identifier
Bei Stratum-1-Servern beschreibt dieser Wert (ein ASCII-Wert mit 4 Bytes) die externen Referenzquellen. Für sekundäre Server beschreibt der Wert (4 Bytes) die IPv4-Adresse der Synchronisationsquelle, oder die ersten 32 Bit des MDA-Hashes (MDA = Message Digest Algorithm 5) der IPv6-Adresse des Synchronisationsservers.
Um den BME688-Sensor über I2C anzusteuern, müssen wir Bibliotheken von Adafruit über den Bibliotheksmanager laden - der Code lässt sich einfach umstellen, um stattdessen SPI zu verwenden. Importieren muss man die Bibliotheken Adafruit BME680 und Adafruit Unified Sensor. Es kann natürlich auch die Bibliothek eines anderen Sensors aus der BME-Familie von Bosch sein, etwa die eines BME280.
Die Initialisierung des Sensors ist in setup() integriert. Hier die Vereinbarung des BME-Proxies:
Adafruit_BME680 bme; // Vereinbarung der Variablen bme
Und hier die eigentliche Initialisierung:
// Verbindung mit Sensor BME680 etablieren
if (!bme.begin()) {
Serial.println(F("Konnte keinen Sensor finden. Bitte Schaltung überprüfen!"));
while (1);
}
// Oversampling-Werte setzen und IIR-Filter initialisieren
bme.setTemperatureOversampling(BME680_OS_8X);
bme.setHumidityOversampling(BME680_OS_2X);
bme.setPressureOversampling(BME680_OS_4X);
bme.setIIRFilterSize(BME680_FILTER_SIZE_3);
bme.setGasHeater(320, 150); // 320*C für 150 ms
}Ab geht die POST
Die Methode createJSONString() konstruiert aus Messdaten und Zeitstempel ein JSON-Objekt. Ich habe hier bewusst ein manuelles Erstellen gewählt, statt ArduinoJson zu verwenden, weil der Aufwand sehr übersichtlich bleibt:
// Hier wird ein String generiert, der ein JSON-Objekt enthält
String createJSONString(double temp, double humi, double pres, double resi, String date, String time) {
String result = "{";
const String up = "\"";
const String delim = ",";
const String colon = ":";
result += up + "temperature" + up + colon + String(temp,2) + delim;
result += up + "humidity" + up + colon + String(humi,2) + delim;
result += up + "pressure" + up + colon + String(pres,2) + delim;
result += up + "resistance" + up + colon + String(resi,2) + delim;
result += up + "date" + up + colon + up + date + up + delim;
result += up + "time" + up + colon + up + time + up;
result += "}";
return result;
}Wer einen Sensor besitzt, der einige dieser Messdaten nicht enthält, stutzt das JSON-Objekt entsprechend. In der Server-Datenbank wird für jedes nicht übergebene Attribut einfach ein null eingetragen.
Für das Versenden der Messdaten über HTTP-POST ist callAPIPost() verantwortlich, das anschließend auch die Antwort des Servers ausgibt, der im Erfolgsfall mit Status-Code 200 antwortet:
// Hier erfolgt die Vorbereitung und die eigentliche Durchführung des POST-Aufrufes / REST-PUSH
void callAPIPost(double temperature, double humidity, double pressure, double resistance, const String& date, const String& time){
Serial.println("Durchführung eines neuen REST API POST Aufrufs:");
String contentType = "application/json"; // Wir übergeben ein JSON-Objekt
// JSON Nutzlast (Body) kreieren
String postData = createJSONString(temperature, humidity, pressure, resistance, date, time);
Serial.println(postData); // ... und ausgeben
// Per WiFi-Verbindung POST aufrufen und dabei "application/json" und das JSON-Objekt übergeben
client.post("/measurements/api", contentType, postData);
// Status und Body aus Antwort extrahieren
int statusCode = client.responseStatusCode();
String response = client.responseBody();
// Ausgabe der Ergebnisse:
Serial.print("Status code: ");
Serial.println(statusCode);
Serial.print("Antwort: ");
Serial.println(response);
}Aufrufe der vorgenannten Methoden finden in der loop()-Methode statt, außer natürlich die Initialisierungen beim Programmstart.

Damit ist der Arduino-Sketch fertig, der den REST-Server aus Teil 1 mit neuen Messungen versorgt. Natürlich gibt es wie immer Erweiterungsmöglichkeiten:

Hier werden der Anschluss für 3.3V, GND, SDA, SCL vom Arduino auf ein Breadboard geführt, von wo sie IIC-Display und IIC-Sensor abgreifen können.
Und das ist immer noch nicht das Ende der Fahnenstange. Die Möglichkeiten sind fast unendlich. Client- und Server-Anwendungen des Beispiels sollten das Vorgehen dabei gut veranschaulichen und zu eigenen Experimenten anreizen. Die Implementierungen für Client und Server lassen sich entsprechend anpassen.
Ich hoffe jedenfalls, der hier vorgestellte Showcase bietet viel Nutzen und macht Spaß.
URL dieses Artikels:
https://www.heise.de/-9179967
Links in diesem Artikel:
[1] https://www.heise.de/blog/Gib-mir-den-REST-Teil-1-Der-REST-Server-9179764.html
[2] https://github.com/ms1963/RESTCommunication
[3] https://www.heise.de/blog/Fernsteuerung-per-Computer-GPIO-Breakout-Boards-als-Schweizer-Taschenmesser-7091889.html
[4] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Shutterstock)
Das ehemals kostenpflichtige GraalVM Enterprise ist jetzt als Oracle GraalVM frei verfügbar. Die Versionsnummerierung wurde zudem dem OpenJDK angepasst.
GraalVM ist eine in Java implementierte JVM (Java Virtual Machine) und ein JDK (Java Developement Kit) basierend auf der Hotspot-VM und dem OpenJDK. Es unterstützt mit GraalVM Native Image unter anderem die AOT-Kompilierung (Ahead of Time) von Java Anwendungen für schnellere Startzeiten und geringeren Speicherverbrauch zur Laufzeit. Initial bei Sun gestartet wird es nun bei den Oracle Labs parallel zu dem klassischen Java OpenJDK entwickelt und war bisher sowohl in einer Open Source lizenzierten Community Edition als auch einer kommerziellen Enterprise Edition verfügbar.
Die Besonderheiten zum normalen Java JDK sind:
Ende 2022 hat Oracle die GraalVM Community Edition an das OpenJDK-Projekt übergeben [1] und damit die Basis des Projekts als Open Source bereitgestellt. Dabei wurde angekündigt, zukünftig die Versionen und Nummerierungen an die Release-Zyklen des OpenJDK anzugleichen. Die erste produktionsreife Version war GraalVM 19.0 im Mai 2019 [2]. Mit GraalVM 22.3.2 kam im April 2023 das bisher letzte Release nach dem alten Nummerierungsschema.
Nun sind Oracle GraalVM für das JDK 17 und Oracle GraalVM für das JDK 20 erschienen [3]. Diese früher als kommerzielle Oracle GraalVM Enterprise bekannten Versionen stehen ab sofort kostenfrei unter der GraalVM Free Terms and Conditions (GFTC) Lizenz zur Verfügung. Diese Lizenz erlaubt die kostenlose Nutzung für alle Benutzer, auch für den Produktionseinsatz. Die Weiterverbreitung ist erlaubt, wenn sie nicht gegen eine Gebühr erfolgt. Entwickler und Organisationen können Oracle GraalVM jetzt einfach herunterladen, verwenden, weitergeben und weiterverteilen, ohne dass sie eine Lizenzvereinbarung durchklicken müssen. Oracle wird weiterhin die GPL-lizenzierten Versionen der GraalVM Community Edition zu den gleichen Bedingungen wie die Oracle-Builds des OpenJDK anbieten.
Etwas unklar ist im Moment die Frage, ob man die eigene Software, die als GraalVM Native Image gebaut wurde, nach GFTC-Lizenz verkaufen darf. Unser Leser Michael Paus hat uns auf eine Diskussion im GraalVM Slack [4] aufmerksam gemacht (um diesen Beitrag lesen zu können, muss man sich zuvor als Benutzer registrieren [5]). Nach dem aktuellen Stand der Diskussion darf man als GraalVM Native Image gebaute Software in Produktion nur kostenfrei für die interne Nutzung oder als Open Source betreiben. Verlangt man eine Gebühr für die eigene Software, muss man auf eine kommerzielle Lizenz von GraalVM ausweichen. Die Kosten dafür richten sich entweder nach den Prozessorkernen, auf denen das Native Image laufen wird oder es wird ein nicht geringer Pauschalbetrag fällig. Auskünfte dazu holt man sich am besten direkt beim Sales & Tech Team bei Oracle ein.
Kurzer Blick auf das klassische Java OpenJDK: Im September 2021 hatte Oracle angekündigt, dass das Oracle JDK (Oracles Variante des OpenJDK) wieder kostenfrei zur Verfügung steht (unter der Oracle No-Fee Terms and Conditions Lizenz - NFTC). Zuvor hatte Oracle 2018 mit dem JDK 8 und 11 eine kommerzielle Lizenz für die produktive Nutzung des Oracle JDK eingeführt.
Alternativ gab es zwar noch das binär-kompatible Oracle OpenJDK kostenfrei, welches aber immer nur maximal ein halbes Jahr mit Updates und Patches versorgt wurde und somit die Entwickler zu halbjährlichen JDK Versionsupdates gezwungen hätte. Seit dieser Zeit sind viele andere auf dem OpenJDK basierende Distributionen von Amazon, IBM, SAP, Microsoft usw. herausgekommen beziehungsweise haben an Bedeutung gewonnen.
Die bekannteste Variante ist das AdoptOpenJDK (mittlerweile Temurin vom Eclipse Projekt Adoptium [6]), welches durch Oracles Lizenz-Wirrwar zum meistverwendeten JDK wurde. Oracle hat das erkannt und durch die erneute kostenfreie Weitergabe des Oracle JDK versucht, Marktanteile zurückzugewinnen. Diesen Ansatz weiten sie nun auch auf Oracle GraalVM mit der GraalVM Free Terms and Conditions (GFTC)-Lizenz aus.
Analog dem OpenJDK wird es nun ebenfalls Long Term Support Releases (aktuell GraalVM für JDK 17) geben, die bis zu einem vollen Jahr nach der Veröffentlichung des nachfolgenden LTS-Release (GraalVM für JDK 21) kostenlos mit Updates versorgt werden. Releases, die nicht als LTS-Releases gekennzeichnet sind (wie GraalVM für JDK 20), werden so lange mit Aktualisierungen versorgt, bis sie durch das nächste Release abgelöst werden. Entwickler können somit jetzt auch bei GraalVM alle sechs Monate auf die neueste JDK-Version aktualisieren und erhalten so sofort Zugang zu den neuesten Java-Funktionen. Alternativ haben Sie die Möglichkeit, zwischen den LTS-Versionen zu wechseln.
Die neuen Oracle GraalVM-Releases lassen sich dank neuer stabiler Download-URLs jetzt leichter in CI/CD-Build-Pipelines einbinden. Die Download-Artefakte enthalten zudem das Native-Image-Dienstprogramm. Somit ist alles in einem einzigen Paket unter derselben Lizenz verfügbar, was für die Entwicklung mit der GraalVM benötigt wird. Für containerisierte Anwendungen oder Container-basierte Builds werden zudem bald neue GraalVM Container-Images auf der Oracle Container Registry verfügbar sein.
Das GraalVM Projekt hat in den vergangenen Jahren eine Menge Aufmerksamkeit erhalten. Das Ziel ist, Javas Rückstand auf moderne Programmiersprachen wie Go in Bezug auf schnelle Startzeiten und effizientes Speicherverhalten zur Laufzeit zu verkleinern. Java ist zwar weiterhin als stabile Laufzeitumgebung für serverseitige Anwendungen vertreten, verliert aber insbesondere beim Umzug in die Cloud Marktanteile an Go & Co. Mit der GraalVM hat man nun auf der Java Plattform die Wahl und kann mit den bestehenden Programmierkenntnissen beide Welten unterstützen. Die Angleichung der Release-Zyklen und der Versionierung an das OpenJDK lassen uns die neuesten Features sowohl im "normalen" Java als auch bei der GraalVM nutzen.
Die Änderungen an den neuen, im Juni 2023 erschienenen GraalVM-Versionen hat Alina Yurenko in ihrem Blog-Post [7] zusammengefasst.
Die neuen Oracle GraalVM Versionen können von der Java-Download-Seite [8] bezogen werden. Weitere Informationen [9] finden sich in den Installationsanleitungen, der Dokumentation und den Versionshinweisen. In der Oracle Cloud Infrastruktur kann Oracle GraalVM übrigens kostenfrei genutzt werden.
Nach Hinweis eines Lesers wurde der Beitrag um einen Absatz ergänzt, der sich den Unklarheiten bezüglich der Bedingungen zum Verkauf eigener Software widmet, die mit GraalVM Native Image gebaut wurden.
URL dieses Artikels:
https://www.heise.de/-9199872
Links in diesem Artikel:
[1] https://www.heise.de/news/Virtuelle-Maschine-Oracle-uebergibt-GraalVM-Community-Edition-an-OpenJDK-7320608.html
[2] https://www.heise.de/news/GraalVM-19-das-erste-offiziell-produktionsreife-Release-4420777.html
[3] https://blogs.oracle.com/cloud-infrastructure/post/graalvm-free-license
[4] https://t.co/Ga1lgeLr91
[5] https://t.co/JFAWTJ9niQ
[6] https://www.heise.de/news/AdoptOpenJDK-landet-bei-der-Eclipse-Foundation-4789835.html
[7] https://medium.com/graalvm/a-new-graalvm-release-and-new-free-license-4aab483692f5
[8] https://www.oracle.com/java/technologies/downloads/
[9] https://docs.oracle.com/en/graalvm/jdk/20/
[10] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Black Jack/Shutterstock.com)
Logging ein wichtiger Teil der Fehleranalyse. Allerdings ist das Zusammenführen unterschiedlicher Logging Libs in Java-Anwendungen immer eine Herausforderung.
Nachdem ich im ersten Post zum Thema Java Logging [1] auf Best Practices und Pitfalls eingegangen bin, möchte ich nun einmal auf die Nutzung von Logging in einem großen Projekt eingehen. In diesem Bereich kommt es oft zu Problemen zwischen verschiedenen Logging Frameworks und eine Zusammenführung des gesamten Anwendung-Logging kann sich mitunter schwer gestalten.
Um die Problematik besser zu verstehen, fange ich mit einem ganz einfachen Beispiel, quasi dem Hello World im Logging, an. Der folgende Code zeigt eine minimale Java-Anwendung, welche einfach eine Nachricht loggt:
public class HelloLogging {
private static final Logger LOG = Logger.getLogger("HelloLogging");
public static void main(final String[] args) {
LOG.info("Hello World");
}
}Bereits in dieser trivialen Anwendung kann das Logging durch die Features des Logging Frameworks, im Beispiel etwa java.util.Logging (JUL), konfiguriert und in einer Datei oder der Konsole (Shell) ausgegeben werden. Das folgende Diagramm zeigt den Aufbau und die Konfiguration des Logging in einem schematischen Aufbau.

Während der gegebene Aufbau für ein kleines Projekt gut funktioniert, wird es manchmal schon problematisch, sobald die ersten Abhängigkeiten hinzukommen. Stellen wir uns einmal vor, dass wir zwei Abhängigkeiten für unsere Anwendung benötigen: eine Library, um den Zugriff zu einer Datenbank zu gewährleisten und eine weitere Abhängigkeit zu einer Security Library, um unsere Anwendung sicher vor Angriffen zu machen. Da die Entwickler dieser Bibliotheken auch Information über dessen Zustand, Nutzung und Laufzeitfehler ausgeben wollen, nutzen diese ebenfalls Logging. Allerdings wird bei diesen Bibliotheken nicht java.util.Logging, sondern es werden andere Logging Libraries genutzt. Wie man im folgenden Diagramm sehen kann, nehmen wir an, dass Log4J2 [2] und Logback [3] im Einsatz sind.

Nun haben wir das Problem, dass das Logging unserer Anwendung über drei verschiedene Logging-Frameworks geleitet wird. Zwar bieten Log4J und Logback auch genug Möglichkeiten der Konfiguration, aber da die Logging Frameworks sich nicht gegenseitig synchronisieren, wäre es eine ganz dumme Idee, alle Frameworks in die gleiche Datei schreiben zu lassen. Hier kann es passieren, dass mehrere der Frameworks in die gleiche Zeile schreiben und es somit zu einem unleserlichen Haufen zufällig aneinandergereihter Textbausteine oder sogar zu Deadlocks kommen kann. Eine andere Idee ist es, dass jedes Framework in eine eigene Datei loggt, wie es im folgenden Diagramm angedeutet ist.

Dieser Aufbau führt dazu, dass die Loggings völlig unabhängig voneinander agieren und sich nicht in die Quere kommen können. Hierdurch hat man zwar ein sauberes Logging, das aber auf mehrere Dateien verteilt ist, die man manuell oder mithilfe von Tools synchronisieren muss. Dazu kommt, dass man immer alle vorhandenen Loggingsysteme konfigurieren muss, wenn man beispielsweise einmal ein höheres Logging-Level zur Analyse der Anwendung aktivieren möchte. Erschwerend kommt hinzu, dass man in einem echten Projekt mehr als nur zwei Abhängigkeiten hat uns es somit zu noch deutlich mehr Logging-Frameworks kommen kann, die im Einsatz sind.
Logging Facades schaffen hier Abhilfe. Durch eine Facade kann man den Code von einer konkreten Implementierung trennen. Die Simple Logging Facade for Java [4] (SLF4J) hat sich hier ganz klar als Standard durchgesetzt. SLF4J bietet eine Logging-API, die als einzelne Abhängigkeit ohne transitiven Abhängigkeiten daher kommt und problemlos in so ziemlich jedes System eingebunden werden kann. Die API kann in diesem Fall genutzt werden, um konkrete Log-Aufrufe im Code zu genieren. Der folgende Code zeigt ein „Hello World“ Logging Beispiel:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HelloLogging {
private static final Logger logger =
LoggerFactory.getLogger(HelloLogging.class);
public static void main(String[] args) {
logger.info("Hello World!");
}
}
Betrachtet man rein diesen Code kann man sich fragen, welche Vorteile SLF4J gegenüber dem klassischen Java-Logging bringen soll. Einer der wichtigsten Punkte ist, dass es sich bei org.slf4j.Logger um ein Interface handelt. Das Modul slf4j-api, das die SLF4J-Api und somit das genannte Interface enthält, liefert keine Implementierung des Interfaces. Das gesamte Modul definiert lediglich die öffentliche API api von SLF4J, die Logging Facade.
Um sie zu nutzen, müssen wir eine Implementierung bereitstellen. Hierfür muss ein sogenanntes Binding als Abhängigkeit hinzugefügt werden, das eine Implementierung der Logging Facade bereitstellt. In der Regel leitet ein solches Binding die Logging-Events an ein konkretes Logging-Framework weiter. Möchte man beispielsweise Apache Commons Logging als konkrete Logging-Implementierung nutzen, muss man nur das slf4j-jcl-VERSION.jar Modul zum Classpath hinzufügen. Solche Bindings werden nicht zur Compiletime benötigt und können daher in Maven per Runtime-Scope bzw. in Gradle als „RuntimeOnly“-Abhängigkeit angegeben werden. Da SLF4J intern das Java-SPI nutzt, muss keinerlei Code angepasst werden, um die konkrete Logging-Implementierung zu verwenden. Dieses Feature können wir nun für unsere Beispielanwendung nutzen:
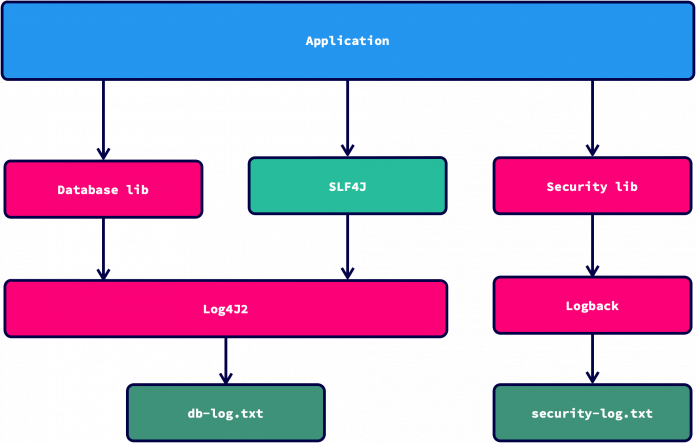
Im Diagramm wird Log4J2 als Logging-Implementierung genutzt, und durch das Hinzufügen eines passenden Bindings werden alle Log-Nachrichten, die über den org.slf4j.Logger-Logger erstellt werden, automatisch an Log4J2 weitergereicht. Da in diesem Beispiel unsere „Database lib“ Abhängigkeit offenbar auch Log4J2 nutzt, werden so direkt die Nachrichten von verschiedenen internen und externen Modulen über Log4J2 abgehandelt. Neben den Bindings zu speziellen Logging Implementierung bietet SLF4J auch noch die Library slf4j-simple welche eine minimale Implementierung von SLF4J bietet und Nachrichten auf der Konsole (System.error) ausgibt.
Allerdings gibt es im Beispiel auch noch ein Problem: Die genutzte „Security lib“ benutzt Logback als Logger und dessen Nachrichten landen daher weiterhin in einer anderen Ausgabe. Für solche Fälle können sogenannte Adapter für SLF4J genutzt werden. Diese ermöglichen, dass Log-Nachrichten, die direkt zu einer Logging-API geschickt werden, an SLF4J weitergeleitet werden. Hierbei gibt es je nach Logging Framework völlig unterschiedliche Implementierungsansätze für solche Adapter. Während SLF4J einige solcher Adapter anbietet, werden ie auch teils von Logging-Frameworks direkt geliefert. Für Log4J2 muss beispielsweise folgende Abhängigkeit hinzugefügt werden, wenn man Nachrichten von Log4J2 an SLF4J weiterleiten möchte:
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
Durch das Hinzufügen dieser Abhängigkeit, die man am besten nur zur Runtime zum Classpath hinzufügt, entsteht ein Verlauf des Logging wie in der folgenden Grafik :
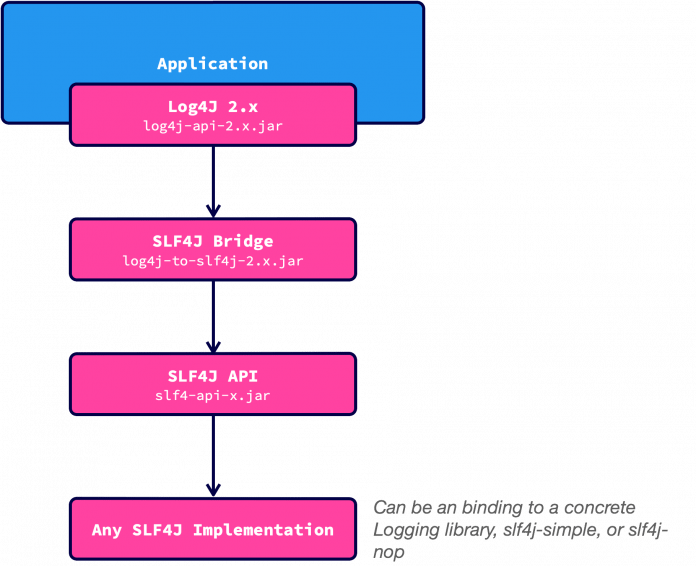
SLF4J bietet für verschiedene Logging-Libraries eine gute Übersicht bezüglich der Integration durch Bindings und Adapter auf ihrer Webseite [5].
Wenn wir uns basierend auf den Erkenntnissen nun unsere Beispielanwendung anschauen, kann durch das Hinzufügen eines Adapters für Logback unser Ziel erreicht werden. Wie im folgenden Diagramm gezeigt, werden alle Log-Nachrichten des gesamten Systems über Log4J2 geleitet und wir haben somit den Vorteil, dass wir nur eine zentrale Stelle dokumentieren müssen.
URL dieses Artikels:
https://www.heise.de/-7355974
Links in diesem Artikel:
[1] https://www.heise.de/blog/Best-Practices-und-Anti-Pattern-beim-Logging-in-Java-und-anderen-Sprachen-7336005.html
[2] https://logging.apache.org/log4j/2.x/
[3] https://github.com/qos-ch/logback
[4] https://www.slf4j.org
[5] https://www.slf4j.org/legacy.html
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien