
Kult oder Kultur? Apple's Vision Pro Konzept.
(Bild: apple.com)
Der Blog möchte nicht auf einen fahrenden Zug aufspringen, sondern erläutern, wie sich das Konzept der Vision Pro in industriellen Umgebungen nutzen lässt.
Auf der diesjährigen WWDC 2023 (World Wide Developer Conference) von Apple hat Tim Cook die seit Jahren "sagenumwobene" Vision Pro Brille vorgestellt. Auf YouTube finden sich hierzu viele Videos, weshalb sich dieser kurze Beitrag eine Wiederholung der dortigen Erkenntnisse spart.
Eines vorweg: es geht hier nicht primär um Apple und sein neuestes Produkt, sondern um die Betrachtung des zugrundeliegenden Konzepts und seiner möglichen Einsatzgebiete.
Aber etwas Kontext muss trotzdem sein: Jedenfalls soll die Vision Pro dank vieler Sensoren und Kameras sowie einer Auflösung von 4K für die beiden Bildschirme ein Augmented Reality der Zukunft bieten. Apple nennt dies bewusst Spatial Computing (räumliche Verarbeitung) statt auf überfrachtete Terminologie wie AR (Augmented Reality) oder MR (Mixed Reality) zurückzugreifen. So lassen sich im realen Raum virtuelle Hintergründe oder Umgebungen integrieren, in deren Kontext Anwender ihre Arbeits- oder Entertainment-Umgebung gestalten können. Der Grad an Virtualität ist also nach eigenem Gusto steuerbar.
Mit einem veranschlagten Preis von 3500 US-Dollar gehört das neue Gadget nicht gerade zu den Schnäppchen. Was aber viele übersehen: Apple sieht sich hier nicht im Wettbewerb mit Giganten wie Meta und deren Oculus-Produktfamilie, sondern adressiert eher das Marktsegment, das auch die 3200-US-Dollar teure Hololens von Microsoft abdeckt. Und das sind eher Businessanwender und vielleicht ein paar Technologie-Junkies mit großem Sparstrumpf. Ein Spielzeug für Gamer ist die Brille also nicht. Daher ist zu erwarten, dass Apps für die Vision Pro ebenfalls dieses Marktsegment adressieren und sich nicht unbedingt im unteren Preissegment tummeln.
Nach Ansicht des Autors könnte das Produkt gerade für geschäftliche und industrielle Umgebungen interessant sein. So erschließt das Konzept folgende Domänen und Anwendungsfälle:
Gerade die Mobilität der Brille erweist sich in diesen Szenarien als Vorteil, mal abgesehen von dem signifikanten Nachteil, dass der separat erhältliche Hochleistung-Akku gerade mal zwei Stunden durchhält. Natürlich stellt all das nur die Spitze des Eisbergs dar. Da noch niemand die Vision Pro in der Praxis prüfen konnte, gibt es viel Raum für reine Spekulation. Interessierte Entwicklungsschmieden und User sollten sich trotzdem schon jetzt ein paar Gedanken über mögliche Anwendungen machen.
All das führt natürlich unweigerlich zu Überlegungen hinsichtlich von Software- und Systemarchitektur der entsprechenden Systeme und Anwendungen. Auch die Kombination mit KI in einer Spatial-Computing-Anwendung könnte sinnvoll sein, etwa für die visuelle Einschätzung möglicher Fehlerursachen bei der Systemwartung.
Die Apple Vision Pro [1] ließe sich ergo als wichtiger Bestandteil neuer oder geänderter Anwendungsfelder etablieren. Ob die Konkurrenz dem etwas entgegensetzen will beziehungsweise kann, bleibt abzuwarten. Zumindest sollte das Konzept Entwickler und Anwender anregen, wie sie diese Art von Produkt sinnvoll und produktiv in ihren Domänen oder für sich selbst nutzen können. Die Zukunft beginnt jetzt.
URL dieses Artikels:
https://www.heise.de/-9181574
Links in diesem Artikel:
[1] https://www.heise.de/news/Apples-Vision-Pro-Apples-Mixed-Reality-Headset-enthuellt-9168785.html
[2] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Bogdan Vija / Shutterstock.com)
Wie kommuniziert ein Arduino-Board serverseitig mit einer REST API, um Sensor-Messungen über ein objektrelationales Mapping zu speichern?
Arduino-Boards, die über eine optionale Echtzeituhr (RTC = Real Time Clock) und ein WiFi-Modul verfügen, lassen sich ins Internet der Dinge integrieren, etwa über die Arduino Cloud oder AWS. Wer lieber On-premises agieren möchte, kann anders vorgehen und Server beziehungsweise Clients im heimischen Netz zur Verfügung stellen. Das bringt den Vorteil mit sich, immer die Kontrolle über die Bereitstellung (Deployment) zu behalten. Wie Entwicklerinnen und Entwickler dabei vorgehen können, zeigen dieser und der nachfolgende Artikel. Während zunächst die Server-Anwendung zur Sprache kommt, dreht sich der zweite Teil um die eingebetteten Clients.
Gleich vorweg: alle Implementierungsdateien liegen auf GitHub [1] parat. Eine gute Gelegenheit, um sich mühselige Handarbeit zu ersparen.
Im Beispielsszenario kommen ein Arduino Board mit C++-Sketch und ein Server mit Java und Spring Boot 3 zum Einsatz.
Die folgende Abbildung zeigt die Systemarchitektur:

Auf der linken Seite der Grafik ist das Arduino-Board, konkret ein Arduino Giga R1 WiFi, zu sehen. Verwendbar sind aber grundsätzlich alle Arduino-Boards oder Arduino-unterstützte Boards wie etwa ein ESP32. Am Arduino ist ein BME688-Sensor von Adafruit über I2C oder SPI angeschlossen. Der Arduino-Sketch macht periodisch Messungen von Temperatur, Feuchtigkeit, Luftdruck und Gaswiderstand, und verschickt das Ergebnis zusammen mit dem von der Echtzeituhr ausgelesenen Zeitstempel über einen POST-Aufruf an den Server: <hostname>:8080/measurement/api. <hostname> kann dabei die IP-Adresse oder der DNS- beziehungsweise Server-Name sein.
Serverseitig (rechte Seite in der Abbildung) fungiert eine in Java geschriebene Spring-Boot-3-REST-Anwendung als Kommunikationspartner für das Arduino-Board. Die zugehörige Datenbank läuft auf PostgreSQL, das die Anwendung als Docker-Container bereitstellt. So ist sichergestellt, dass Entwicklerinnen und Entwickler PostgreSQL auf dem eigenen Computer nicht extra installieren müssen.
Zur Laufzeit sendet das Arduino-Board POST-Nachrichten an den Server. Der dazugehörige REST-Endpunkt sorgt dann dafür, dass die Messung in die Datenbank übernommen wird.
Selbstverständlich lassen sich auch andere Datenbankmanagementsysteme nutzen, etwa mysql (maria). In diesem Fall müssten nur die Konfigurationsdateien application.yml sowie docker-compose.yml angepasst werden. Und in der Konfigurationsdatei pom.xml – das Projekt nutzt Maven für den Build-Prozess – sind entsprechend die PostgreSQL-Referenzenen durch die für die alternative Datenbank notwendigen Abhängigkeiten (<dependencies>) zu ersetzen. Wie aus folgender Abhängigkeits-Festlegung ersichtlich, gilt das nur für die zweite Abhängigkeit in Bezug auf PostgreSQL – in diesem Fall den pgJDBC-Treiber. Der soll übrigens nur zur Laufzeit aktiv sein, deshalb ist der benötigte Scope in der pom.xml-Datei mit runtime festgelegt. Alle anderen Abhängigkeiten beziehen sich auf Spring Boot, im Detail auf die Nutzung von Spring Web, Spring Data JPA (Java Persistence API) und Spring Test:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Als Adapter nutzt die Server-Anwendung einen über die URL [2] bereitstehenden JDBC-Treiber.
Für den Fall, dass Entwickler und Entwicklerinnen bereits eine lokale Instanz von postgreSQL einsetzen, ist in der Konfiguration des Docker-Containers ein Port-Mapping definiert. Dieses verbindet den Server-Port 5332 mit dem Container-Port 5432 und verhindert somit Konflikte mit lokalen postgreSQL-Installationen, die auf Port 5432 lauschen.
Sobald der Arduino-Client einen POST-Aufruf mit einer Messung auf die Reise schickt, nimmt die Server-Schnittstelle die Messung als JSON-Body im jeweiligen REST-POST-Endpunkt entgegen und speichert die Messdaten in der postgreSQL-Datenbank measurement.
Die REST-Anwendung nutzt Port 8080, was sich in der Konfigurationsdatei application.yml bequem ändern lässt.
server:
port: 8080
#turn off the web server
spring:
datasource:
url: jdbc:postgresql://localhost:5332/measurement
username: michael
password: michael
jpa:
hibernate:
ddl-auto: create-drop
properties:
hibernate:
dialect: org.hibernate.dialect.PostgreSQLDialect
format_sql: true
show-sql: true
main:
web-application-type: servletWer einfach loslegen will, startet nach Download der Quellen zunächst das Docker-Image. Dazu ist es erforderlich, auf dem eigenen Server beziehungsweise Desktop Docker zu installieren. Mittels der -> URL [3] bedeutet das zunächst, die entsprechende Docker-Implementierung für Linux, Windows oder macOS herunterzuladen und zu starten. In der Werkzeugleiste des Betriebssystems erscheint danach das für Docker typische Icon, ein Container-Frachtschiff.
Im nächsten Schritt sollten Entwickler und Entwicklerinnen die Konfiguration docker-compose.yml auf ihre Bedürfnisse anpassen:
services:
db:
container_name: postgres
image: postgres
environment:
POSTGRES_USER: michael
POSTGRES_PASSWORD: michael
PGDATA: /data/postgres
volumes:
- db:/data/postgres
ports:
- "5332:5432"
networks:
- db
restart: unless-stopped
networks:
db:
driver: bridge
volumes:
db:Am Anfang der Konfiguration sind die bereitgestellten Dienste spezifiziert. Als Basis soll der Container das auf Docker Hub bereitgestellte Postgres-Image verwenden.
Im Bereich environment erfolgt die Festlegung den Anwendernamens und des zugehörigen Passworts sowie des Ordners im Container, der die PostgreSQL-Dateien enthalten soll. Das interne Netzwerk heißt db und ist über eine Bridge erreichbar. Stoppt der Container, löscht er die Datenbanktabelle.
Wer ein anderes DBMS nutzt, muss diese YAML-Datei entsprechend anpassen.
Im Ordner, in dem die YAML-Datei liegt, erfolgt nun der Start des Containers über
%docker compose up -d
Nach Eingabe von
%docker container ls
in der Kommandozeile müsste der Container auftauchen:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d0cc2733c93a postgres "docker-entrypoint.s…" 4 hours ago Up 4 hours 0.0.0.0:5332->5432/tcp postgresDamit ist es allerdings nicht getan, denn es fehlt noch die Datenbank für die Messungen.
Zunächst öffnen wir dazu eine Shell im Container für den interaktiven Zugriff:
docker exec -it postgres bash
In der Container-Session ist im Falle von postgreSQL das Kommando:
psql - U michael
notwendig, wobei U für den Nutzer steht. Ohne Änderungen ist im Beispiel michael als Benutzername und Passwort für postgreSQL voreingestellt.
Über psql lassen sich mit \l die existierenden Datenbanken abrufen.
Hier erscheint in etwa die folgende Ausgabe:
Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges
-------------+---------+----------+------------+------------+------------+-----------------+---------------------
libc |
michael | michael | UTF8 | en_US.utf8 | en_US.utf8 | | libc |
postgres | michael | UTF8 | en_US.utf8 | en_US.utf8 | | libc |
template0 | michael | UTF8 | en_US.utf8 | en_US.utf8 | | libc | =c/michael +
| | | | | | | michael=CTc/michael
template1 | michael | UTF8 | en_US.utf8 | en_US.utf8 | | libc | =c/michael +
| | | | | | | michael=CTc/michael
(4 rows)Um eine neue Datenbank zu erzeugen, geben wir
CREATE DATABASE measurement;
ein.
Achtung: Der Strichpunkt ist unbedingt erforderlich. Mit \c measurement verbinden wir uns mit der Datenbank und können danach mit \dt die vorhandenen Tabellen beziehungsweise Datenbankschemas analysieren. Noch ist dort nichts zu sehen, weil für das Datenbankschema die Spring-Boot-3-Anwendung sorgt. Spring Boot kreiert zu diesem Zweck selbständig folgendes SQL-DDL-Kommando:
create table measurement (
id integer not null,
date date,
humidity float(53),
pressure float(53),
resistance float(53),
temperature float(53),
time time,
primary key (id)
)Wer eine professionelle IDE wie IntelliJ IDEA Ultimate nutzt, kann viele der beschriebenen und kommenden Schritte bequem über die IDE anstoßen.
Nun müssen wir noch die Java-basierte Spring-Boot-3-Anwendung starten (mittels Main.class), wobei wir eine ähnliche Ausgabe wie die folgende erhalten sollten – nur die letzten zwei Zeilen sind hier abgebildet.
…. noch viel mehr ….
2023-06-04T15:18:01.952+02:00 INFO 51585 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2023-06-04T15:18:01.959+02:00 INFO 51585 --- [ main] de.stal.Main : Started Main in 3.172 seconds (process running for 3.807)
Es ist aus der Konsolenausgabe ersichtlich, dass Spring Boot für Webanwendungen automatisch den eingebetteten Web-Server Tomcat startet. Alternativ könnten wir auch Jetty nutzen, was folgende Konfigurationsänderung im pom.xml von Maven erfordert:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency><dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
</dependency>In der Ausgabe befindet sich des Weiteren eine Warnung über Views, die wir in diesem Fall aber getrost ignorieren können.
Im Falle von gradle als Build-Tool wäre es stattdessen:
configurations {
compile.exclude module: "spring-boot-starter-tomcat"
}
dependencies {
compile("org.springframework.boot:spring-boot-starter-web:2.0.0.BUILD-SNAPSHOT")
}Das aber nur am Rande, weil das Beispielsprojekt wie schon erwähnt Maven einsetzt.
Möchte man den Server auch ohne Arduino-Client testen, leistet die Anwendung Postman [4] hierfür gute Dienste. Sie ermöglicht das Aufrufen von APIs und benutzt curl als Basis dafür.

Das implementierte REST-Beispiel unterstützt folgende Aufrufe von REST-Endpunkten, um CRUD-Funktionalität (CRUD = Create Read Update Delete) bereitzustellen.
hostname:port/measurements/api, wobei im Body ein JSON-Objekt mit den Messergebnissen enthalten sein muss.hostname:port/measurements/api brauchen keinen Body im HTTP-Paket (none). Der Endpunkt liefert die Liste aller gespeicherten Messungen zurück. Das gilt auch für das Auslesen von individuellen Einträgen über hostname:port/measurements/api/42. In diesem Fall beziehen wir uns auf die Messung mit der Id 42.hostname:port/measurements/api/1 benötigt ein JSON-Objekt als Body, das die Werte des zum Datenbankeintrag gehörigen Primärschlüssels 1 aktualisiert. hostname:port/measurements/api/2 löscht den Eintrag mit dem Primärschlüssel 2 aus der Datenbank. Ebenso wie bei GET ist kein Body (none) vonnöten.Ein Beispiel für ein mitgeliefertes JSON-Objekt bei POST- oder PUT-Aufrufen könnte wie folgt aussehen:
{
“temperature“: 23.5,
“humidity“: 12.7,
“pressure“: 990.5,
“resistance“: 23.8,
"date“: “2023-06-10“,
“time“: “06:24:56“
}Für die eigentliche Magie in der Server-Anwendung sorgt Spring Boot 3. Laut der Spring-Seite gilt für Spring Boot:
"Das Spring Framework bietet ein umfassendes Programmier- und Konfigurationsmodell für moderne Java-basierte Unternehmensanwendungen – auf jeder Art von Einsatzplattform.
Ein Schlüsselelement von Spring ist die infrastrukturelle Unterstützung auf der Anwendungsebene: Spring konzentriert sich auf das "Klempnerhandwerk" von Unternehmensanwendungen, sodass sich die Teams auf die Geschäftslogik auf Anwendungsebene konzentrieren können, ohne unnötige Bindungen an bestimmte Bereitstellungsumgebungen."
Das Java-Framework integriert einen Webserver mit Servlet-Unterstützung (Tomcat oder optional Jetty), über den es die REST-API im Web beziehungsweise Netzwerk zur Verfügung stellt. Die ganze Servlet-Maschinerie bleibt Entwicklerinnen und Entwicklern erspart. Zudem bietet es eine Repository-Schnittstelle, mit deren Hilfe die REST-Endpunkte neue Einträge beispielsweise speichern, ändern, löschen oder abrufen. Außerdem sorgt es über Annotationen für das objekt-relationale Mapping zwischen der measurement-Datenbanktabelle und dem entsprechenden Java-Objekt.

In der Datei Main.java (siehe Listing unten) ist die Klasse Main als @SpringBootApplication annotiert. Das sorgt dafür, dass Spring Boot nach Komponenten und Entitäten sucht und weitere Handarbeiten automatisch erledigt. Gleichzeitig fungiert die Klasse auch als @RestController, weshalb sich in ihr REST-Endpunkte befinden müssen. Mittels der Annotation @RequestMapping("measurements/api") legt man fest, welches Prefix jeder REST-Endpunkt bekommen soll. Externe Aufrufe beginnen dann immer mit diesem Prefix, also zum Beispiel GET <hostname>:8080/measurements/api. Der Konstruktur der Klasse Main enthält als Parameter ein MeasurementRepository, über das die REST-Endpunkte Aktionen auf dem aktuellen persistierten Objekt durchführen, etwa um eine neue Messung in der Datenbank zu speichern:
public Main(MeasurementRepository measurementRepository) {
this.measurementRepository = measurementRepository;
}Die Schnittstelle MeasurementRepository erzeugt Spring Boot automatisch und übergibt sie per Dependency Injection an den Konstruktor. Es ist dementsprechend als @Repository definiert und leitet sich von JpaRepository ab. Die zwei Typparameter von JpaRepository beziehen sich auf die Persistenzklasse für Datenbankeinträge (Measurement) und auf den Datentyp des Primärschlüssels (Integer):
@Repository
public interface MeasurementRepository
extends JpaRepository<Measurement, Integer> {
}Einer der definierten REST-Endpunkte ist etwa folgendes parametrisiertes GET:
@GetMapping("{id}")
public Optional<Measurement> getMeasurementById(@PathVariable("id") Integer id)Die GetMapping-Annotation sorgt dafür, dass beim GET-Aufruf des Endpunkts mit der URL <hostname>:port/measurements/api/3 die Methode das entsprechende Datenbankobjekt mit Primärschlüssel 3 zurückliefert. Sie nimmt dabei das angesprochene MeasurementRepository zu Hilfe:
return measurementRepository.findById(id);
Wichtig in Zusammenhang mit REST-Endpunkten ist die Tatsache, dass bei Rückgaben von Ergebnissen Spring Boot dafür sorgt, diese zuvor in ein JSON-Objekt umzuwandeln – es wären im Übrigen auch andere Formate möglich. Zugleich erwartet jeder REST-Endpunkt, dass ihm entsprechende Messergebnisse im Body des HTTP-Pakets als JSON-Objekte übergeben werden. Das ist insbesondere bei POST und PUT notwendig, gilt aber nicht für in der URL angegebene Parameter wie etwa die gewünschte Id des "REST-Objektes" (siehe GET und DELETE). Letztere wird als Parameter in die URL integriert, zum Beispiel: localhost:8080/measurements/api/12
package de.stal;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.*;
import java.util.List;
import java.util.Optional;
@RestController
@SpringBootApplication
@RequestMapping("measurements/api")
public class Main {
private final MeasurementRepository measurementRepository;
public Main(MeasurementRepository measurementRepository) {
this.measurementRepository = measurementRepository;
}
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
}
@GetMapping
public List<Measurement> getMeasurement() {
return measurementRepository.findAll();
}
@GetMapping("{id}")
public Optional<Measurement> getMeasurementById(@PathVariable("id") Integer id){
return measurementRepository.findById(id);
}
@PostMapping
public void addMeasurement(@RequestBody NewMeasurementRequest request) {
Measurement measurement = new Measurement();
measurement.setDate(request.date);
measurement.setTime(request.time);
measurement.setTemperature(request.temperature);
measurement.setHumidity(request.humidity);
measurement.setPressure(request.pressure);
measurement.setResistance(request.resistance);
measurementRepository.save(measurement);
}
record NewMeasurementRequest(
java.sql.Date date,
java.sql.Time time,
Double temperature,
Double humidity,
Double pressure,
Double resistance
){}
@DeleteMapping("{measurementId}")
public void deleteMeasurement(@PathVariable("measurementId") Integer id) {
measurementRepository.deleteById(id);
}
// assignment
@PutMapping("{measurementId}")
public void updateMeasurement(@PathVariable("measurementId") Integer id,
@RequestBody NewMeasurementRequest msmUpdate) {
Measurement existingMeasurement = measurementRepository.findById(id)
.orElseThrow();
existingMeasurement.setDate(msmUpdate.date);
existingMeasurement.setTime(msmUpdate.time);
existingMeasurement.setTemperature(msmUpdate.temperature);
existingMeasurement.setHumidity(msmUpdate.humidity);
existingMeasurement.setPressure(msmUpdate.pressure);
existingMeasurement.setResistance(msmUpdate.resistance);
measurementRepository.save(existingMeasurement);
}
}Die Klasse Measurement.java (siehe Listing unten) definiert die eigentliche Entität, die über ein objektrelationales Mapping mit der Datenbank verbunden ist. Dementsprechend enthält die Klasse eine @Entity-Annotation.
Wer IntelliJ IDEA oder eine andere fortschrittliche IDE nutzt, kann "Boilerplate"-Code wie Setters, Getters, toString(), equals(), hashcode() und Konstruktoren von der IDE generieren lassen. Andernfalls ist manuelles Eintippen nötig, was sich bei späteren Refactoring-Maßnahmen als umständlich erweist.
Nicht zu vergessen: Die Klasse Measurement benötigt einen parameterlosen Konstrukteur mit leerem Rumpf, damit das objektrelationale Mapping von Spring Boot aus JSON-Nachrichten Java-Objekte generieren kann.
Die Datenfelder der Klasse Measurement entsprechen den gewünschten Attributen des Datenbankeintrags, in unserem Fall Temperatur, Feuchtigkeit, Luftdruck, Gaswiderstand, Datum und Zeit. Den Primärschlüssel Integer id lassen wir Spring Boot für das Datenbanksystem automatisch generieren. Dazu dienen die Annotationen: @Id, @SequenceGenerator und @GeneratedValue. Der Primärschlüssel soll mit 1 starten und bei jedem neuen Datenbankeintrag um 1 hochgezählt werden. Die Annotation @id weist das gleichnamige Datenfeld als Primärschlüssel aus.
package de.stal;
import jakarta.persistence.*;
import java.sql.Date;
import java.sql.Time;
import java.util.Objects;
@Entity
public class Measurement {
@Id
@SequenceGenerator(
name = "measurement_id_sequence",
sequenceName = "measurement_id_sequence",
allocationSize = 1
)
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "measurement_id_sequence"
)
private Integer id;
private Double temperature;
private Double humidity;
private Double pressure;
private Double resistance;
private java.sql.Date date;
private java.sql.Time time;
public Measurement(Integer id, Double temperature, Double humidity, Double pressure, Double resistance, Date date, Time time) {
this.id = id;
this.temperature = temperature;
this.humidity = humidity;
this.pressure = pressure;
this.resistance = resistance;
this.date = date;
this.time = time;
}
public Measurement() {
}
@Override
public String toString() {
return "Measurement{" +
"id=" + id +
", temperature=" + temperature +
", humidity=" + humidity +
", pressure=" + pressure +
", resistance=" + resistance +
", date=" + date +
", time=" + time +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Measurement that = (Measurement) o;
return Objects.equals(id, that.id) && Objects.equals(temperature, that.temperature) && Objects.equals(humidity, that.humidity) && Objects.equals(pressure, that.pressure) && Objects.equals(resistance, that.resistance) && Objects.equals(date, that.date) && Objects.equals(time, that.time);
}
@Override
public int hashCode() {
return Objects.hash(id, temperature, humidity, pressure, resistance, date, time);
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Double getTemperature() {
return temperature;
}
public void setTemperature(Double temperature) {
this.temperature = temperature;
}
public Double getHumidity() {
return humidity;
}
public void setHumidity(Double humidity) {
this.humidity = humidity;
}
public Double getPressure() {
return pressure;
}
public void setPressure(Double pressure) {
this.pressure = pressure;
}
public Double getResistance() {
return resistance;
}
public void setResistance(Double resistance) {
this.resistance = resistance;
}
public Date getDate() {
return date;
}
public void setDate(Date date) {
this.date = date;
}
public Time getTime() {
return time;
}
public void setTime(Time time) {
this.time = time;
}
}Um die (Web-Server-)Anwendung zu konfigurieren, gibt es eine YAML-Datei mit dem Namen application.yml im resources-Ordner:
server:
port: 8080
#turn off the web server
spring:
datasource:
url: jdbc:postgresql://localhost:5332/measurement
username: michael
password: michael
jpa:
hibernate:
ddl-auto: create-drop
properties:
hibernate:
dialect: org.hibernate.dialect.PostgreSQLDialect
format_sql: true
show-sql: true
main:
web-application-type: servletHier legen Entwickler und Entwicklerinnen unter anderem Port, Passwort und Benutzername fest, zudem die URL zum Zugriff auf die PostgreSQL-Datenbank. Benutzername und Passwort müssen mit der korrespondierenden Konfiguration in docker-compose.yml übereinstimmen. Mit ddl-auto weisen wir Spring Boot JPA an, die Tabelle measurement zu löschen, falls die Anwendung beziehungsweise Session terminiert (drop measurement). Über web-application-type: servlet bestimmt die Konfiguration, dass wir zum Bereitstellen unserer REST-API einen Webserver benötigen, der Java-Servlets unterstützt. Das können Tomcat oder Jetty sein.
Damit wären wir am Ende der notwendigen Java- und Konfigurationsdateien angekommen. Der Gesamtumfang aller Dateien liegt bei rund 250 Codezeilen zuzüglich Konfigurationsfestlegungen und inklusive der mittels IDE (IntelliJ IDEA) generierten Codes. Der Aufwand, um kleinere REST-APIs zu entwickeln, hält sich daher dank Spring Boot in Grenzen.
Durch Spring Boot fällt es leicht, recht schnell und effizient eine REST-API zusammenzubauen. Natürlich gäbe es auch Alternativen wie Quarkus oder Micronaut, aber Spring Boot ist sehr verbreitet und besitzt eine große Community. Das Beispiel ist für die Übergabe von Messungen des BME688 festgelegt. Es ist allerdings sehr leicht, die Anwendung für andere Sensoren oder andere Zwecke auszulegen.
Während sich dieser Beitrag auf die Server-Seite fokussiert hat, beschreibt der in Kürze nachfolgende Teil 2, wie sich auf Microcontroller-Boards wie dem Arduino Giga die dazu passenden REST-Clients erstellen lassen.
URL dieses Artikels:
https://www.heise.de/-9179764
Links in diesem Artikel:
[1] https://github.com/ms1963/RESTCommunication
[2] https://jdbc.postgresql.org/
[3] https://www.docker.com
[4] https://www.postman.com/
[5] mailto:map@ix.de
Copyright © 2023 Heise Medien

(Bild: Adafruit)
GPIO-Breakout-Boards wie das Adafruit FT232H ermöglichen den Zugriff auf elektronische Schaltungen von einem Computer.
Um von einem Computer aus auf Elektronikkomponenten zuzugreifen, existieren verschiedene Wege. Zum einen lassen sich Mikrocontroller über USB dazwischenschalten, um beispielsweise auf Arduino-Boards oder Raspberry Pi mittels einer auf den Boards laufenden Software die Elektronik zu kontrollieren. Für Arduino-kompatible Boards lässt sich zu diesem Zweck eine Firmata-Firmware installieren, die den mehr oder weniger direkten Zugriff auf Ports des Boards ermöglicht.
Eine weitere Option ist die RESTful-Kommunikation von einem Computer zu einem autonomen Mikrocontroller-Board, um über diesen Umweg auf Elektronik zuzugreifen. Das Programm auf dem Board fungiert als Vermittler zwischen Computer und Elektronik.
Ein dritter Weg besteht darin, ein sogenanntes GPIO-Breakout-Board über USB an den betreffenden Computer anzuschließen. In diesem Fall können Anwendungen direkt auf die am Breakout-Board befindlichen GPIO-Ports zugreifen. Zudem implementiert ein GPIO-Breakout-Board meistens Unterstützung für Protokolle wie SPI oder I2C. Dadurch ist auch das Ansteuern etwas komplexerer Hardware – zum Beispiel Displays und Sensoren – möglich.
Ein solches GPIO-Breakout-Board ist das Adafruit FT232H Breakout Board Blinka, das zu Straßenpreisen von rund 15 bis 18 Euro erhältlich ist, etwa bei BerryBase [1]. Es gibt natürlich auch andere GPIO-Boards, aber das Untersuchte besitzt eine ausreichende Zahl von GPIO-Ports und unterstützt zudem UART, I2C, SPI, Bit-Bang und JTAG. Entwicklerinnen und Entwickler können es über Python vom Computer aus ansteuern. Zudem sind für das FT232H-Board viele Informationsquellen verfügbar.
Für meine Experimente habe ich die neueste Variante des Boards erworben, die über einen USB-C-Port und einen Stemma-QT-Konnektor verfügt, der den Anschluss entsprechender Komponenten mit STEMMA/QT- beziehungsweise Qwiic-Interface erlaubt.

(Bild: Adafruit)

(Bild: Adafruit)
Das Board ist nach dem integrierten Chip benannt, einem FT232H von FTDI, der auch das komplette USB-Protokoll implementiert. Dadurch müssen sich Entwickler nicht mit systemnaher USB-Funktionalität herumschlagen. Im vielen Fällen ist keine Installation eines USB-Treibers auf dem Computer notwendig. Der FT232H unterstützt USB 2.0 Hi-Speed, was Übertragungsraten bis 480 MBit/s gewährleistet – im ebenfalls verfügbaren Full-Speed-Modus sind es stattdessen maximal 12 MBit/s. Die neue Boardversion besitzt einen USB-C-Port. Ein passendes Kabel findet sich nicht im Lieferumfang. Daher empfiehlt es sich, gleich ein entsprechendes Kabel mit zu bestellen, sofern nicht bereits vorhanden.
Der Chip-Kern arbeitet mit 1,8V, die Ein-/Ausgänge mit 3,3V. Letztere sind tolerant gegenüber 5V. Noch genauere Details finden sich auf dem Produktblatt des Chip-Herstellers [2].
Wie im Pinout-Diagramm ersichtlich (siehe obige Abbildungen), stellt die Adafruit-Lösung die GPIO-Ports D4-D7 sowie C0-C7 bereit.
Die Ports D0-D3 implementieren das SPI- oder das I2C-Protokoll. Das "oder" will sagen, dass zur Ansteuerung entweder I2C oder SPI verfügbar ist, aber nicht beides gleichzeitig.
Mit einem Schalter auf dem Board bestimmen Entwickler, ob sie I2C nutzen aber nicht SPI (Schalterstellung I2C auf on), oder ob sie SPI nutzen möchten aber nicht I2C (Schalterstellung I2C auf off). Im letzteren Fall gilt: D0 -> SCLK, D1 -> MOSI, D2 -> MISO, D3 -> CS0. Im ersteren Fall wiederum gibt es folgende Zuordnung: D0 -> SCL, D1 oder D2 -> SDA. Hierbei lässt sich einer der beiden Ports D1 und D2 nutzen, um das SDA-Signal von I2C zu übertragen. In der alten Version des Boards mussten Anwender für I2C noch den Port D1 mit dem Port D2 verdrahten, um dann D2 mit der eigentlichen Schaltung zu verbinden.
Zur Installation des Boards stellt Adafruit eine eigene Webseite mit Anleitung zur Verfügung [3]. Wichtig ist die Tatsache, dass die Programmierung auf dem Windows-, Mac- oder Linux-Computer eine Installation von Python 3 [4] und pip3 [5] erfordert.
Da Windows keine treiberlosen USB-Geräte unterstützt, müssen Anwender zunächst einen USB-Treiber von Zadig [6] installieren. Bei macOS und Linux ist das in den allermeisten Fällen nicht notwendig.
Danach folgen auf allen Betriebssystemen zum Zugriff über CircuitPython noch Installationen der libusb-Bibliothek sowie der speziellen Python-Bibliotheken pyftdi und adafruit-blinka – Blinka ist übrigens auch der Name des Breakout-Boards. Schließlich müssen noch udev-Rules (Linux only) festgelegt und eine Umgebungsvariable (alle Betriebssysteme) definiert werden. Diese Variable heißt BLINKA_FT232H und soll bei einem Wert von 1 das Vorhandensein eines Blinka-Boards signalisieren.
Wie bereits oben erwähnt, ist hier immer vorausgesetzt, dass auf dem Computer eine Installation von python3 und pip3 vorliegt.
Das Board wird übrigens ohne "vormontierte" Header ausgeliefert. Zunächst ist daher etwas Lötarbeit erforderlich.
Hier die verschiedenen Anleitungen:
Zur Ansteuerung von Schaltungen über das Breakout-Board Blinka muss dieses natürlich an den eigenen Computer angeschlossen sein. Softwaretechnisch dienen CircuitPython-Programme als Schnittstelle zum Board. Standard-Computer unter Windows, Linux, macOS verstehen zwar Python 3, aber wie können Entwickler CircuitPython nutzen? Dafür bedarf es zum einen der Blinka-Bibliothek für Python (adafruit-blinka) und entsprechender CircuitPython-Bibliotheken für die "ferngesteuerte" Hardware wie Sensoren, Bildschirme und dergleichen:

(Bild: Adafruit)
Da ich zum Test des Blinka-Boards einen Mac-Computer benutzt habe, folgen nun exemplarisch die für macOS notwendigen Installationsschritte im Detail:
Sollte noch keine Installation des Package Managers Homebrew vorhanden sein, installieren wir ihn mittels:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
Anschließend ist die Installation von libusb mit Hilfe von Homebrew erforderlich:
brew install libusb
Danach die von pyftdi:
pip3 install pyftdi
Und im letzten Schritt das Installieren der eigentlichen Board-Bibliothek:
pip3 install adafruit-blinka
Nun sollte die Anwenderin die Umgebungsvariable BLINKA_FT232H mit 1 belegen:
export BLINKA_FT232H=1
Zu guter Letzt gilt es noch, die Python 3 REPL-Umgebung zu starten und schrittweise die folgenden zwei Anweisungen einzugeben:
import boarddir(board)
Verlief alles fehlerlos, gibt letztere Instruktion die Liste der verfügbaren Pins auf dem Terminal aus.
Fertig ist die Installation!
Zum Prüfen ob die Installation funktioniert, gibt es folgende Tests:
Zunächst ein Test, um sicherzustellen, dass das System das FT232H-Board erkennt:
from pyftdi.ftdi import Ftdi
Ftdi().open_from_url('ftdi:///?')
Normalerweise gibt es nur einen FTDI-Controller, weshalb die Ausgabe wie folgt aussehen könnte:
>>> from pyftdi.ftdi import Ftdi
>>> Ftdi().open_from_url('ftdi:///?')[Link auf https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/setup] [11]
Available interfaces:
ftdi://ftdi:232h:1/1 ()/code/p
pcodePlease specify the USB device/code/p
pDanach eine Verifikation, ob die Umgebungsvariable vorhanden und korrekt gesetzt ist:/p
pcodeimport os/code/p
pcodeos.environ["BLINKA_FT232H"]/code/p
pDie Ausgabe müsste schlicht lauten:/p
pre class="rte__tx--listing"codestrong´1´/strong/code/pre
pWie gesagt, diese Beschreibung kratzt nur an der Oberfläche. Die genauen Anweisungen lassen sich a href="https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/setup" rel="external noopener" target="_blank"strongauf der Anleitungs-Website von Adafruit nachvollziehen [12]/strong/a./p
pSollte es Probleme geben, finden sich auf der a href="https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/troubleshooting" rel="external noopener" target="_blank"strongAdafruit-Website Post-Install-Checks [13]/strong/a entsprechende Hinweise./p
h3 class="subheading" id="nav_programmierung_3"Programmierung/h3
pIch spare mir Beispiele für das obligatorische LED-Blinken oder das Erkennen des Zustands eines Druckknopfes. Stattdessen soll der Anschluss eines a href="https://sensirion.com/de/produkte/katalog/SHT40" rel="external noopener" target="_blank"strongSensirion SHT40 [14]/strong/a als Beispiel dienen./p
pDieser Sensor kostet nur wenige Euro und misst Temperatur und Feuchtigkeit relativ präzise. Die typische Genauigkeit bei der relativen Luftfeuchtigkeit beträgt 1,8% RH und bei der Temperatur 0,2°C. Verwendung findet in diesem Zusammenhang ein Adafruit-Board mit I2C-Anschluss. Das Messen kann entweder mit oder ohne Heizen (-gt;codesht.mode/code) erfolgen. Für das Programmbeispiel habe ich auf das Heizen verzichtet. Da es sich um ein I2C-basiertes Sensorboard handelt, ist der I2C-Switch des FT232H auf ON zu stellen./p
figure class="a-inline-image a-u-inline"
div
img alt class="legacy-img " decoding="async" height="522" loading="eager" src="https://heise.cloudimg.io/width/696/q85.png-lossy-85.webp-lossy-85.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildDerSchaltung-3584313b6978b464.JPG" srcset="https://heise.cloudimg.io/width/336/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildDerSchaltung-3584313b6978b464.JPG 336w, https://heise.cloudimg.io/width/1008/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildDerSchaltung-3584313b6978b464.JPG 1008w, https://heise.cloudimg.io/width/1392/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildDerSchaltung-3584313b6978b464.JPG 2x" width="696"
/div
figcaption class="a-caption " p class="a-caption__text"
/pdiv class="text"An das Breakout-Board wird über ein Qwiic/STEMMA-QT-Kabel der Sensirion SHT40 angeschlossen./div
/figcaption
/figure
pDer Sensor benötigt nach jeder Messung etwa vier Sekunden Verschnaufpause – zwei Sekunden bei der Temperaturmessung und vier Sekunden bei der Feuchtigkeitsmessung. Deshalb enthält die while-Schleife ein codesleep(4)/code./p
pVor dem Programmstart müssen Entwickler noch die benötigte Bibliothek von Adafruit installieren:/p
pre class="rte__tx--listing"pip3 install adafruit-circuitpython-sht4x/pre
pDas vorliegende Programmbeispiel stammt im Original von Adafruit./p
h3 class="subheading"
a-code language="python"
pre class="rte__tx--listing listing"codeimport time # zum Verzögern der Ausgaben
import board # zur Ausgabe über FT232H
import adafruit_sht4x # Einbinden der Bibliothek für den Sensor
i2c = board.I2C() # Am I2C-Anschluss (SDA/SCL des FT232H) hängt ein Adafruit SHT40-Breakout-Board
sht = adafruit_sht4x.SHT4x(i2c)
print("SHT4X mit folgender Seriennummer entdeckt: ", hex(sht.serial_number))
sht.mode = adafruit_sht4x.Mode.NOHEAT_HIGHPRECISION # ohne Heizen!
# alternativ mit: sht.mode = adafruit_sht4x.Mode.LOWHEAT_100MS
print("Augenblicklicher Modus: ", adafruit_sht4x.Mode.string[sht.mode])
while True:
temperature, relative_humidity = sht.measurements
print("Temperatur: %0.1f C" % temperature)
print("Feuchtigkeit: %0.1f %%" % relative_humidity)
print("")
time.sleep(4) # 4 Sekunden Verzögerung/code/pre
/a-code
/h3
pDie Bildschirmausgabe gestaltet sich wenig spannend wie folgt:/p
figure class="a-inline-image a-u-inline"
div
img alt class="legacy-img " decoding="async" height="463" loading="eager" src="https://heise.cloudimg.io/width/696/q85.png-lossy-85.webp-lossy-85.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildBildschirmausgabeBeispiel-59de146e93e58830.PNG" srcset="https://heise.cloudimg.io/width/336/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildBildschirmausgabeBeispiel-59de146e93e58830.PNG 336w, https://heise.cloudimg.io/width/1008/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildBildschirmausgabeBeispiel-59de146e93e58830.PNG 1008w, https://heise.cloudimg.io/width/1392/q70.png-lossy-70.webp-lossy-70.foil1/_www-heise-de_/imgs/18/3/5/4/2/8/9/0/BildBildschirmausgabeBeispiel-59de146e93e58830.PNG 2x" width="696"
/div
figcaption class="a-caption " p class="a-caption__text"
/pdiv class="text"Bildschirmausgabe mit den Messwerten des Sensirion SHT40./div
/figcaption
/figure
h3 class="subheading" id="nav_vorsicht_geboten_4"Vorsicht geboten/h3
pEine Warnung müssen Entwicklerinnen und Entwickler unbedingt berücksichtigen. Beim Anschluss von Komponenten an das Breakout-Board sollten sie sicherstellen, dass die jeweilige Schaltung keine Gefahr für den USB-Port darstellt. Ansonsten könnte eine Überlastung am USB-Port des Computers diesen in Mitleidenschaft ziehen. Adafruit weist darauf hin, dass das Board maximal 400-500mA aus dem USB-Port ziehen darf. Dafür gibt es diverse Abwehrmaßnahmen – darunter: Testen, die Absicherung gegenüber induktiver Lasten mittels Dioden, das Begrenzen von Stromstärken mittels Widerständen. Wer das vergisst, könnte den angeschlossenen Computer schädigen. Wie heißt es so schön: Vorsicht ist die Mutter der Porzellankiste./p
h3 class="subheading" id="nav_fazit_5"Fazit/h3
pGPIO-Breakout-Boards wie das Adafruit FT232H bieten eine sehr gute Möglichkeit, von Computern aus direkt auf Elektronik zuzugreifen, ohne ein Mikrocontroller-Board dazwischenschalten zu müssen. Das hat natürlich auch Grenzen hinsichtlich der möglichen Anwendungen. Beispielsweise erlauben Mikrocontroller-basierte Lösungen im Vergleich zu ihren PC-Pendants Echtzeitanforderungen und sind hinsichtlich der Verwendung verschiedener Protokolle wesentlich flexibler. Auf der anderen Seite besitzt eine Computer-gestützte Lösung ebenfalls Vorteile. Chip-Hersteller FTDI nennt unter anderem die Ansteuerung von Kameraschnittstellen, Bar-Code-Lesern, Settop-Boxen, Flash-Card-Lesern, MP3-Geräten sowie industrielle Anwendungen als mögliche Beispiele./p
pSchön wäre neben der Unterstützung für CircuitPython das Bereitstellen von C- beziehungsweise C++-Bibliotheken, um das Board auch in entsprechenden Anwendungen zu nutzen. Das ist allerdings Jammern auf hohem Niveau. Für die Arten von Anwendungen, die für einen FT232H in Frage kommen, reicht Python völlig aus. Speziell für das Rapid Prototyping eigener Experimente weist Python einige Vorteile auf./p
p
!-- RSPEAK_STOP --
!-- RSPEAK_START --
/p
hr
p
strongURL dieses Artikels:/strongbr
smallcodehttps://www.heise.de/-7091889/code/small
/p
p
strongLinks in diesem Artikel:/strongbr
smallcodestrong[1]/strongnbsp;https://www.berrybase.de/adafruit-ft232h-breakout-general-purpose-usb-zu-gpio-spi-i2c/code/smallbr
smallcodestrong[2]/strongnbsp;https://ftdichip.com/products/ft232hq//code/smallbr
smallcodestrong[3]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/setup/code/smallbr
smallcodestrong[4]/strongnbsp;https://www.python.org/downloads//code/smallbr
smallcodestrong[5]/strongnbsp;https://www.activestate.com/resources/quick-reads/how-to-install-and-use-pip3//code/smallbr
smallcodestrong[6]/strongnbsp;https://zadig.akeo.ie//code/smallbr
smallcodestrong[7]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/windows/code/smallbr
smallcodestrong[8]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/linux/code/smallbr
smallcodestrong[9]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/mac-osx/code/smallbr
smallcodestrong[10]/strongnbsp;https://cdn-learn.adafruit.com/downloads/pdf/circuitpython-on-any-computer-with-ft232h.pdf/code/smallbr
smallcodestrong[11]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/setup/code/smallbr
smallcodestrong[12]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/setup/code/smallbr
smallcodestrong[13]/strongnbsp;https://learn.adafruit.com/circuitpython-on-any-computer-with-ft232h/troubleshooting/code/smallbr
smallcodestrong[14]/strongnbsp;https://sensirion.com/de/produkte/katalog/SHT40/code/smallbr
smallcodestrong[15]/strongnbsp;mailto:map@ix.de/code/smallbr
/p
p class="printversion__copyright"
emCopyright © 2023 Heise Medien/em
/p
pstronga href="https://blockads.fivefilters.org"Adblock test/a/strong a href="https://blockads.fivefilters.org/acceptable.html"(Why?)/a/p

(Bild: Shutterstock)
Mit Java kann man Anwendung mittlerweile gut modularisieren, muss aber auch Abhängigkeiten beachten. Wenn diese keine Java-Module sind, wird es spannend.
In einem vorherigen Post habe ich über eine minimale Unterstützung für das Java Modulsystem (Java Platform Module System, JPMS) geschrieben und wie man helfen kann, sie zu erreichen. Nun kann es aber immer wieder passieren, dass Bibliotheken das Java-Modulsystem nicht unterstützen und es auch nicht absehbar ist, dass diese in Zukunft wenigstens als „Automatische Module“ verfügbar sein werden.
Wenn man seinen eigenen Code auf das JPMS umstellen will und von solchen Bibliotheken abhängig ist, muss man teilweise in die Trickkiste greifen. In diesem Post möchte ich einmal auf genau solche Abhängigkeiten eingehen und schauen, wie man damit umgehen kann.
Auch wenn ich mich eher bei Maven zu Hause fühle, habe ich erst neulich an der Umstellung eines großen Gradle-Projekts auf Java-Module gearbeitet. Da das Projekt Open Source ist, kann es einfach bei GitHub eingesehen werden [1]. In diesem Projekt gab es zu Beginn des Umbaus eine Vielzahl von Abhängigkeiten, die nicht das Java-Modulsystem unterstützt haben. Bei einigen konnten wir eine nachhaltige Lösung erzielen, indem wir direkt Pull Requests (PR) bei den jeweiligen Projekten erstellt haben, um diese um einen Automatic-Module-Name zu ergänzen. Wie man das einfach über ein Maven- oder Gradle-Plug-in erreichen kann, habe ich bereits im vorherigen Post zu dem Thema beschrieben. Ein Beispiel eines solchen PR kann hier [2] gefunden werden.
Nun gibt es aber auch Abhängigkeiten, bei denen man einen solchen PR nicht einfach stellen kann oder bei denen der PR nicht angenommen wird. Vielleicht hat man auch eine Abhängigkeit, deren Weiterentwicklung eingestellt wurde. In allen diesen Fällen wird eine andere Umsetzung benötigt. Im Grunde muss man sich selbst darum kümmern, aus den Abhängigkeiten Java-Module zu erstellen. Hierfür gibt es unterschiedliche Möglichkeiten. Man kann beispielsweise händisch einen Automatic-Module-Name-Eintrag zum Manifest des Jar hinzufügen und die abgeänderte Version dann in einem internen Maven Repository hosten. Für das erwähnte Gradle-Projekt haben wir auf das „extra-java-module-info“-Plug-in von Jendrik Johannes zurückgegriffen. Dieses als Open Source verfügbare Plug-in [3] erlaubt es, zur Build-Zeit einen Automatic-Module-Name Eintrag zu Abhängigkeiten hinzuzufügen. Konkret wird das Plug-in wie in folgendem Beispiel genutzt, wobei bei jedem automaticModule(…) Aufruf der Gradle Identifier der Abhängigkeit als erster Parameter und der zu nutzende Modulname als zweiter Parameter übergeben werden:
plugins {
id("org.gradlex.extra-java-module-info")
}
extraJavaModuleInfo {
failOnMissingModuleInfo.set(true)
automaticModule("io.prometheus:simpleclient",
"io.prometheus.simpleclient")
automaticModule("io.prometheus:simpleclient_common",
"io.prometheus.simpleclient_common")
automaticModule("io.prometheus:simpleclient_httpserver",
"io.prometheus.simpleclient.httpserver")
}
Zusammen mit dem Autor des Plug-ins konnten wir in einem sehr produktiven Austausch das Ganze sogar noch deutlich erweitern. Das Plug-in konnte neben automatischen Modulen schon immer Module mit einer module-info.java erstellen. Hierbei musste man allerdings händisch Angaben wie exports definieren. Durch neue Funktionalitäten kann man nun ein Modul so definieren, dass dessen vollständigen Packages exportiert werden (siehe weitere Infos [4]). Das hat den großen Vorteil, dass man nicht mit automatischen Modulen arbeiten muss, die einige Besonderheiten mich sich bringen, da unter anderem alle automatischen Module zu den „required“ Abhängigkeiten eines Moduls hinzugefügt werden, sobald ein automatischen Modul als „required“ in der module-info.java angegeben ist (siehe Java Spec [5]). Hier noch einmal ein großes Dankeschön an Jendrik Johannes als Maintainer der Bibliothek. Unsere Zusammenarbeit hat aus meiner Sicht extrem gut die Vorteile von Open Source aufgezeigt. Für alle, die hier noch tiefer einsteigen möchten, hat Jendrik mehrere Videos zu diesem Thema und anderen Themen rund um Gradle kostenlos auf YouTube gehostet [6].
Ein letztes großes Problem kann aber auch mit den hier vorgestellten Umsetzungen nicht behoben werden: Sobald ein JAR gegen die package split constraints des Java-Modulsystems verstößt, kann es nicht zum modulepath hinzugefügt werden. In diesem Fall müssen noch deutlich weitreichende Schritte vorgenommen werden. Diesen Punkt werde ich mich aber in einem zukünftigen Beitrag zuwenden.
URL dieses Artikels:
https://www.heise.de/-7536607
Links in diesem Artikel:
[1] https://github.com/hashgraph/hedera-services
[2] https://github.com/offbynull/portmapper/pull/48
[3] https://github.com/gradlex-org/extra-java-module-info
[4] https://github.com/gradlex-org/extra-java-module-info/issues/38
[5] https://docs.oracle.com/javase/specs/jls/se16/html/jls-7.html#jls-7.7.1
[6] https://www.youtube.com/@jjohannes
[7] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Pixels Hunter/Shutterstock.com)
Softwarearchitektur beeinflusst den Erfolg eines Projekts erheblich. Aber ausgerechnet "gute" Entwickler und Entwicklerinnen können Feinde der Architektur sein.
Warum ist Softwarearchitektur überhaupt so wichtig? Sie hilft uns, große Systeme zu implementieren. Durch die Strukturierung von Code in Module können wir sicherstellen, dass Entwicklerinnen und Entwickler für Änderungen nur das jeweils zu ändernde Modul im Detail verstehen müssen. Von anderen Modulen ist nur oberflächliches Wissen notwendig, beispielsweise über die Schnittstelle. Dieses Prinzip wird als "Information Hiding" bezeichnet: Details sind in den Modulen versteckt und können mit wenig Einfluss auf andere Module geändert werden. So lassen sich Module idealerweise in Isolation verstehen und ändern. Wenn die Architektur besonders gelungen ist, können Entwicklerinnen also mit wenig Wissen und daher besonders einfach Änderungen an der Software vornehmen.
Unter "guten" Developern möchten wir uns hier Personen vorstellen, die auch komplizierte Systeme verstehen und weiterentwickeln können. Solche Personen können auch mit Architektur-Fehlschlägen umgehen, bei denen Änderungen nicht so einfach sind und gegebenenfalls schwer zu verstehende Auswirkungen haben – manchmal auf völlig andere Stellen des Systems. Vielleicht finden sie es sogar intellektuell herausfordernd, sich mit solchen Problemen zu beschäftigen, und es macht ihnen Spaß. Außerdem sorgen diese Umstände nicht nur für einen sicheren Job, sondern auch für Prestige. Schließlich sind diese Personen oftmals die Einzigen, die wichtige Systeme noch ändern können und so für das Geschäft einen sehr einen hohen Wert haben.
Hinweise auf ein solches Verständnis von "guten" Entwicklern und Entwicklerinnen finden sich auch anderswo: Wer beispielsweise im Code die Feinheiten von einer Programmiersprache wie Java nutzt, die in einer Zertifizierung abgefragt werden, erstellt nicht besonders einfach zu verstehenden und zu ändernden Code, sondern gerade solchen, der die Features voll ausreizt und sich auf spezielle Eigenschaften der Sprache verlässt. Der Code ist besonders schwierig zu verstehen und damit zu ändern. Dennoch ist eine solche Zertifizierung als ein Hinweis auf das Können der Developer anerkannt. Wer also besonders unleserlichen Code schreiben oder lesen kann, gilt demnach als besonders gut.
Solche Entwickler und Entwicklerinnen mögen vielleicht "akademische" Architekturansätze nicht und bevorzugen eine "pragmatische" Herangehensweise. Schließlich profitieren sie von der Situation sogar. Bis zu einer gewissen Kompliziertheit funktioniert das ja auch. Bei "wirklich guten" Developern führt das bis zu einer erschreckend hohen Kompliziertheit. Sie verstehen dann Systeme, die für Außenstehende ein Mysterium sind. Dann fällt die Arbeit der Softwarearchitekten und -architektinnen aber vermutlich nicht auf fruchtbaren Boden. Schließlich kann man das System ja weiterentwickeln – warum es also besser strukturieren? In der Tat kann es passieren, dass die Architektin schließlich sogar das Team verlässt, um eine andere Position zu finden, wo ihre Mühen sinnvoller scheinen. Und daher sind "gute" Developer die natürlichen Feinde der Softwarearchitektur.
Das Problem ist das Verständnis, wann Entwicklerinnen als "gut" im Sinne von kompetent gelten. Natürlich müssen Entwickler Technologien verstehen. Es ist sicher vorteilhaft, wenn sie auch mit kompliziertem Code umgehen können, aber sie sollten solche Situationen vermeiden und auf keinen Fall auf sie hinarbeiten. Wirklich gute Developer arbeiten am liebsten an einfachem Code. Sie haben gerade eine Aversion gegen komplizierten Code – und dann haben Entwicklerinnen und "saubere" Architektur dasselbe Ziel.
Wir können in Projekten eine Umgebung schaffen, in der sich "saubere" Architektur durchsetzen kann. Dazu sollten wir Developer nicht beglückwünschen, weil sie eine komplizierte Änderung ganz alleine umgesetzt haben. Stattdessen sollte die Frage im Vordergrund stehen, wie sich solche komplizierten Änderungen in Zukunft vermeiden lassen und wie mehr Personen dazu befähigt werden können, solche Änderungen durchzuführen. Um die Entwicklung guter Softwarearchitektur zu fördern, sollten wir positive Arbeitsweisen belohnen und negative korrigieren. Statt den Fokus auf das individuelle Können eines Entwicklers beim Umgang mit kompliziertem Code zu legen, sollten wir uns auf die Qualität des Codes und die Umsetzung der Architektur konzentrieren.
Wichtig ist auch ein breites Interesse an Themen, die nicht mit den rein technischen Aspekten der Entwicklung zu tun haben. Das hilft dabei, die Domäne, die Anforderungen sowie die Nutzerinnen und Nutzer zu verstehen und die richtigen Features zu implementieren. Dazu muss man aber ein originäres Interesse an der Domäne und der Fachlichkeit haben – Personen mit einem breiten Interessenspektrum fällt das leichter.
Softwarearchitektur ist ein wichtiges Mittel, um die Kompliziertheit von Software einzudämmen. Developer, die auch mit komplizierten Systemen umzugehen vermögen, könnten einem solchen Architekturverständnis ablehnend gegenüberstehen.
URL dieses Artikels:
https://www.heise.de/-8971097
Links in diesem Artikel:
[1] mailto:sih@ix.de
Copyright © 2023 Heise Medien

(Bild: Shutterstock)
NullPointerExceptions sind mit die häufigste Fehlerquelle in Java. Durch statische Codeanalyse kann man diese Fehler deutlich minimieren.
Neue Projekte bringen neue Herausforderungen und neues Wissen mit sich. In meinem aktuellen Projekt [1] habe ich vor Kurzem eine Definition zum Umgang von null-Checks bei der statischen Codeanalyse erstellt. Vielen im Projekt war es wichtig, dass Parameter nicht nur zur Laufzeit beispielsweise durch Objects.requireNonNull(…)) überprüft werden, sondern auch direkt beim Kompilieren. Daher haben wir beschlossen, hier auch auf statischen Codeanalyse zur Überprüfung des Umgangs mit null zu setzen.
Bevor wir uns auf die verschieben Annotation und Checker Libraries stürzen, die es für Java gibt, möchte ich einmal kurz erläutern, worum es sich bei einer statischen Codeanalyse handelt. Hierbei wird der Programmcode beim Kompilieren durch ein Tooling überprüft. Das aktuell gängigste Tool in Java ist sicherlich SpotBugs, das sich in Builds mit Maven oder Gradle einbinden lässt und dessen Ergebnisse auch automatisiert auf Plattformen wie SonarCloud veröffentlicht werden können. Mit einer statische Codeanalyse kann man Probleme wie einen Speicherüberlauf, eine Endlosschleife oder "Out of Bound“-Fehler finden. Ein einfaches Beispiel ist eine Division durch 0. Sollte so etwas im Code vorkommen, kann die Analyse eine Warnung liefern oder je nach Konfiguration den kompletten Build fehlerhaft beenden. In unserem Projekt haben wir einen solchen Check in GitHub Actions, das die Ergebnisse direkt in SonarCloud [2] und einem Pull Request anzeigt.
Ein Problem beim Programmieren mit Java ist sicherlich der Umgang mit null. Wobei ich persönlich klar die Meinung vertrete, dass null seine Berechtigung hat, auch wenn Tony Hoare, der Erfindern der null-Referenz in der Programmierung, hierüber mittlerweile als ein „Billion-Dollar Mistake“ spricht
Allerdings kann man in Java nicht nativ definieren, ob ein Parameter null sein darf. Das hat man mittlerweile versucht, über verschiedene Mittel in der Klassenbibliothek zu lösen. Beispiele hierfür sind java.util.Optional, Objects.requireNonNull(…) oder auch JSR305 [3].
Ein anschauliches Beispiel für eine Programmiersprache, die eine native Unterstützung für null-Referenzen hat, ist Kotlin. Sie unterscheidet explizit zwischen nullable-Referenzen und nonnull-Referenzen. Hierbei sind Letztere der Standard, wobei einer Variablen mit einer solchen Referenz nie null zugewiesen werden kann. Benötigt man eine Variable, die null umfassen kann, muss man mit einer nullable-Referenz arbeiten. Diese wird über das ? Zeichen angegeben. Der folgende Code beinhaltet ein Kotlin Beispiel für beide Referenzen:
var a: String = "abc" // Regular initialization means
// non-null by default
a = null // compilation error
var b: String? = "abc" // can be set to null
b = null // okDa es eine solche native Unterstützung in Java nicht gibt, versucht man sie über statische Codeanalyse so gut wie möglich zu integrieren. Generell werden hier zwei Annotationen benötigt, wobei eine (@Nullable) definiert, dass ein Wert beziehungsweise eine Variable null sein kann, und die andere Annotation definiert, dass ein Wert oder eine Variable nie null sein darf (@NonNull).
Zum Verständnis soll ein Code Beispiel dienen, das eine Methode definiert und per Annotation die Information hinzufügt, dass der Rückgabewert der Methode nie null sein kann:
@NonNull String getName() {
if(isUnique()) {
return „Item „ + getId();
} else {
return null;
}
}Wie man in der Implementierung der Methode sehen kann, ist es durchaus möglich, dass sie null zurückgibt. Das wär ein Fall, in dem die statische Codeanalyse eine Verletzung aufzeigt. Wer möchte, kann beispielsweise IntelliJ so konfigurieren, dass es solche Probleme direkt anzeigt.
Der folgende Code, der die @Nullable Annotation verwendet, führt zu einer Warnung in der Analyse:
void check(@Nullable String value) {
Objects.hash(value.toLowerCase());
}In diesem Beispiel wird durch die Annotation @Nullable für die Variable value definiert, dass diese den Wert null haben kann. Dass der Code allerdings direkt auf die Variable zugreift, führt potenziell zu einer NullPointerException zur Laufzeit. Auch das würde durch die statische Codeanalyse ausgewertet und als Problem ausgegeben.
Wer eine solche statische Codeanalyse im eigenen Projekt integrieren möchte, muss ein paar einfache Voraussetzungen schaffen. Als Erstes muss man sich für eins oder mehrere Analysetools entscheiden. Hier empfehle ich Spotbugs [4], das der Nachfolger von Findbugs ist. Das Tool kann entweder über die Kommandozeile oder integriert in einen Gradle oder Maven Build gestartet werden. Um die gefundenen Probleme zu analysieren, kann man sich diese entweder im Spotbugs eigenen Swing-Client anschauen oder beispielsweise als HTML-basierte Übersicht als Bestandteil einer generierten Maven-Site mittels des Maven site-Ziels. Man kann das Tool so konfigurieren, dass es die Ergebnisse beispielsweise in ein Sonar beziehungsweise die SonarCloud hochlädt.
Wer @Nullable- und @NonNull-Annotationen im Projekt nutzen möchte, benötigt eine Library, die die Annotation bereitstellt. Das eigene Projekt muss nur zur Compile-Zeit von der Library abhängig sein. Auch hier gibt es (leider) eine ganze Fülle an Bibliotheken, die Annotationen bereitstellen. Die einzelnen Libraries basierend auf ihren Vor- und Nachteilen zu beleuchten, wird Bestandteil eines eigenen Posts sein. Daher empfehle ich zunächst Spotbugs Annotations als Abhängigkeit, die man unter den folgenden Maven-Koordinaten finden kann:
<dependency>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-annotations</artifactId>
<version>4.7.3</version>
</dependency> Die Fülle an Tools und Libraries macht es einem bedauerlicherweise nicht leicht, die perfekte und zukunftsorientierte Kombination zu finden. Als ich tiefer in das Thema eingetaucht bin, war ich erschrocken, dass vieles in diesem Bereich noch immer nicht durch Standards oder allgemein genutzte Best Practices definiert ist. Zwar gab es hier verschiedene Ansätze wie etwa mit demJSR305 [5], aber diese sind immer irgendwann im Sande verlaufen und werden heute teils in einem wilden Mix genutzt. Deswegen werde ich auch diesem Problem in naher Zukunft einen eigenen Post widmen.
URL dieses Artikels:
https://www.heise.de/-7351944
Links in diesem Artikel:
[1] https://github.com/hashgraph/hedera-services
[2] https://sonarcloud.io/project/overview?id=com.hedera.hashgraph%3Ahedera-services
[3] https://jcp.org/en/jsr/detail?id=305
[4] https://spotbugs.github.io
[5] https://jcp.org/en/jsr/detail?id=305
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Andrey VP/Shutterstock.com)
Der Livestream bringt am Mittwoch um 18 Uhr spannende Einblicke und Hintergründe zur enterJS, interessante Gespräche mit Gästen und ein Gewinnspiel.
Auf dem YouTube-Kanal der the native web GmbH [1] findet alle drei Wochen – immer am Mittwochabend um 18 Uhr – ein Livestream zu verschiedenen Themen rund um die Softwareentwicklung statt. Meistens programmiere ich live, gelegentlich gibt es aber auch andere Formate wie ein Ask-me-Anything (AMA) oder Ähnliches.
Der nächste Livestream findet am Mittwoch, 19. April statt, und es gibt ein ganz besonderes Highlight: Er dreht sich um die enterJS-Konferenz [2], eine der im deutschsprachigen Raum bedeutendsten Veranstaltungen rund um JavaScript und Webentwicklung, die am 21. und 22. Juni 2023 in Darmstadt stattfinden wird.
Anlässlich des zehnjährigen Jubiläums erwarten wir interessante Gäste aus dem Programmbeirat der enterJS: Zum einen Maika Möbus, Redakteurin bei der iX und bei heise Developer, zum anderen Melanie Andrisek, Technikjournalistin und Lektorin im dpunkt.verlag. Beide werden spannende Einblicke in die Welt der JavaScript- und Webentwicklung sowie in die Organisation der enterJS geben.
Zum ersten Mal in unserer Livestream-Geschichte veranstalten wir außerdem ein Gewinnspiel. Zu gewinnen gibt es als Hauptpreis ein Freiticket für die enterJS 2023, ein iX-Plus-Abo sowie dreimal jeweils ein Buch aus dem Sortiment des dpunkt.verlag. Die Teilnahme wird ausschließlich während des Livestreams möglich sein, Voraussetzung sind ein Mindestalter von 18 Jahren und ein YouTube-Account.
Wir freuen uns auf Eure Teilnahme am Livestream am 19. April um 18 Uhr [4] und hoffen, dass Ihr genauso gespannt seid wie wir! Nutzt die Gelegenheit, um Eure Fragen und Kommentare im Livestream oder vorab auf Twitter [5] zu hinterlassen. Bis dahin, bleibt neugierig und wir sehen uns im Livestream!
URL dieses Artikels:
https://www.heise.de/-8964534
Links in diesem Artikel:
[1] https://www.youtube.com/@thenativeweb
[2] https://enterjs.de/
[3] https://www.heise.de/Datenschutzerklaerung-der-Heise-Medien-GmbH-Co-KG-4860.html
[4] https://www.youtube.com/watch?v=l2uZL4UXXUg
[5] https://twitter.com/thenativeweb
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: Peshkova/Shutterstock.com)
Die jährliche Befragung zu Jakarta EE läuft bis zum 25. Mai. Sie dient der Arbeitsgruppe als Richtlinie für die Weiterentwicklung der Spezifikation.
Jedes Jahr führt die Eclipse Foundation [1] beziehungsweise die Jakarta EE Working Group [2] eine große Umfrage durch, um Informationen zur Nutzung und Verbreitung von Jakarta EE zu sammeln. Diese Daten helfen der Arbeitsgruppe, die Nutzer von Jakarta EE, deren Bedürfnisse und Probleme besser verstehen zu können und sinnvolle Weiterentwicklung und Prioritäten für die Zukunft zu definieren.
Die Ergebnisse der Umfrage bleiben aber nicht nur innerhalb der Arbeitsgruppe, sondern sind als aufbereitetes PDF verfügbar [3]. Die Eclipse Foundation arbeitet die Zahlen grafisch auf. Beispielsweise zeigt folgendes Diagramm aus der letztjährigen Befragung die Beliebtheit der unterschiedlichen Application Server:

Auch 2023 gibt es wieder eine Umfrage, die bis zum 25. Mai online verfügbar ist [4]. Hierbei bitten wir jeden Entwickler und jede Entwicklerin an der Umfrage teilzunehmen, um ein möglichst diverses und breites Bild der Community zu erhalten.
URL dieses Artikels:https://www.heise.de/-8006410
Links in diesem Artikel:[1] https://www.eclipse.org[2] https://jakarta.ee[3] https://outreach.eclipse.foundation/jakarta-ee-developer-survey-2022[4] https://www.surveymonkey.com/r/63FSHRM[5] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: insta_photos/Shutterstock.com)
Meetings nerven! Also: abschaffen! Aber: Kommunikation ist wesentlicher Teil der Softwareentwicklung und Meetings ein wichtiges Kommunikationswerkzeug. Was nun?
Auslöser dieses Blog-Posts ist eine Twitter-Diskussion [1]. Dort ging es um die Idee, bei einem Video-Call im Hintergrund eine Anzeige zu installieren. Sie soll basierend auf dem Gehalt beziehungsweise dem Tagessatz der Beteiligten anzeigen, wie viel Geld der Video-Call kostet.
Vermutlich geht es bei der Anzeige aber nicht nur um die Kosten. Video-Calls nerven Technikerinnen und Techniker und halten sie von der wirklichen Arbeit ab. Es gibt nämlich eigentlich nur einen Indikator dafür, ob wir etwas erreicht haben: lauffähiger Code. Diesen zu entwickeln, erfordert Konzentration. Ein Video-Call kostet nicht nur Zeit, sondern unterbricht auch die Konzentration. Es dauert lange, bis man wieder produktiv am Code arbeiten kann. Die negativen Auswirkungen von Meetings auf die Produktion von lauffähigem Code sind also noch schlimmer, als es diese Anzeige nahelegen würde.
Tatsächlich hilft die Anzeige aber nicht weiter. Schlimmer: Der Idee liegt eine falsche Wahrnehmung über Softwareentwicklung zugrunde. Nicht Code zu produzieren, ist unser größtes Problem. Das größte Problem ist es, die gemeinsame Arbeit an der Software zu koordinieren und die Anforderungen zu verstehen. Ein großes Optimierungspotential ist, Features korrekt zu implementieren und die richtigen Features zu implementieren. Kleine Unterschiede können schon massive Auswirkungen haben. Ein krasses Beispiel: Ein einziges zusätzliches Eingabefeld kann 90 % des Umsatzes kosten [2]. Es ist also kontraproduktiv, dieses Eingabefeld umzusetzen – egal wie schnell oder effizient das passiert. Der lauffähige Code mag einem zwar das Gefühl geben, dass man etwas erreicht hat, aber in Wirklichkeit war es ein Schritt in die falsche Richtung. Die beste Option wäre gewesen, diesen Code gar nicht zu schreiben. Den Code möglichst schnell und effizient zu schreiben, ist eine Scheinoptimierung.
Um zu verstehen, was zu entwickeln ist, muss man wohl Meetings abhalten. Schriftliche Anforderungen können nicht alle Informationen transportieren. Rückfragen, das gemeinsame Entwickeln von Ideen, Hinterfragen – das alles verlangt direkte Kommunikation und Meetings. Aber die Meetings nerven ja dennoch, und das Problem muss irgendwie angegangen werden. Die Kosten des Meetings explizit zu machen, ist naheliegend, weil es relativ einfach ist. Es ist aber die falsche Optimierungsgröße. Meetings, bei denen relevante Informationen ausgetauscht oder wichtige Entscheidungen getroffen werden, sind nützlich und nerven daher vermutlich nicht. Leider ist Nützlichkeit nicht ganz so einfach messbar, wie die Kosten. Dieses Problem des Fokus auf Kosten, weil sie leichter messbar sind, haben auch anderen Bereichen der IT, wie in einem anderen Blog-Post [3] diskutiert. Gerade weil die gemeinsame Arbeit die große Herausforderung in der Softwareentwicklung ist, sind Optimierungen an der gemeinsamen Arbeite sehr sinnvoll.
Also sollten wir die Qualität von Meetings verbessern. Beispielsweise kann man nach jedem Meeting die Frage stellen, wie hilfreich die Teilnehmenden das Meeting fanden. Oder man kann ein Keep / Try Feedback zur Verbesserung einholen: Was sollten man beim nächsten Meeting beibehalten (Keep)? Was kann man ausprobieren (Try)? Auch alle Meetings firmenweit schlicht abzusagen, wie Shopify dies getan hat [4], hat den Vorteil, dass vermutlich nur die Meetings wieder aufgenommen werden, die wertvoll sind. Es geht jedoch vielleicht zu weit, weil gegebenenfalls wichtige Meetings auch abgesagt werden.
So oder so ist eine Bewertung und kontinuierliche Verbesserung von Meetings ein konstruktiver Weg, um den Wert der Meetings zu maximieren. Und daher sollten wir den Wert von Meetings maximieren - und nicht etwa die Anzahl oder die Kosten.
Das Problem der Softwareentwicklung ist die Koordination und die Arbeit an den richtigen Herausforderungen. Dafür sind Meetings notwendig. Also sollten wir Meetings nicht einfach abschaffen, sondern den Wert maximieren.
URL dieses Artikels:
https://www.heise.de/-7549813
Links in diesem Artikel:
[1] https://twitter.com/ewolff/status/1574378678796144640
[2] https://ai.stanford.edu/~ronnyk/2009controlledExperimentsOnTheWebSurvey.pdf
[3] https://www.heise.de/blog/IT-Projekte-Kostenfaktor-statt-Wettbewerbsvorteil-6007620.html
[4] https://www.heise.de/news/Schluss-mit-Gruppenmeetings-Shopify-holt-zum-Kalender-Kahlschlag-aus-7448427.html
[5] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: fizkes/Shutterstock.com)
Stellenanzeigen gleichen sich üblicherweise wie ein Ei dem anderen, statt den ersten individuellen Eindruck zu vermitteln, den man von einem Unternehmen erhält.
Wer sich heutzutage auf eine Stelle in der IT bewirbt, bekommt in der Regel über kurz oder lang ein PDF zu Gesicht, in dem die ausgeschriebene Position näher umrissen wird. Vergleicht man mehrere dieser Stellenausschreibungen, fällt auf, dass sie einander so stark ähneln, dass kaum ein Unterschied zwischen zwei Unternehmen auszumachen ist.
Abgesehen von etlichen Jahren technischer Expertise und einem abgeschlossenen Hochschulstudium oder einer vergleichbaren Ausbildung werden üblicherweise Teamfähigkeit, Flexibilität und ähnliche nicht näher definierte "Werte" gefordert.
Geboten wird im Gegenzug die Mitarbeit in einem mehr oder weniger jungen und dynamischen Team in einem spannenden Umfeld, eine Monatskarte für den ÖPNV, Vergünstigungen im ortsansässigen Fitnessstudio oder dem Supermarkt, und ein täglich frisch gefüllter Obstkorb.
Das ist das, womit Unternehmen im 21. Jahrhundert glauben, sich von anderen Unternehmen abheben zu können. Weil aber alle Unternehmen dieser Meinung sind, gleichen die Stellenausschreibungen abgesehen von Unternehmensname und -logo wie ein Ei dem anderen. Mit anderen Worten: Sie sind praktisch austauschbar.
Für die Unternehmen ist das in verschiedener Hinsicht kritisch. Zum einen verpassen sie bereits die erste Möglichkeit, einen individuellen Eindruck zu hinterlassen. Stattdessen bleibt hängen, dass anscheinend kaum ein Unternehmen verstanden hat, dass heutzutage mehr gefordert werden darf als eine lieblos in PDF-Form gebrachte Zeitungsanzeige, die inhaltlich und stilistisch aus den 90er-Jahren stammt.
Zum zweiten führen derartige Stellenausschreibungen aber auch dazu, dass sich potenzielle Bewerberinnen und Bewerber kein adäquates Bild von einem Unternehmen machen können – und sich dann entweder nicht oder auf unpassende Jobs bewerben. Das erste Szenario ist schade, weil ein Mensch und ein Unternehmen, die gut zusammenpassen würden, nicht zueinanderfinden. Das zweite ist lästig, weil es letztlich Zeitverschwendung ist, und zwar für beide Parteien.
All das habe ich im Juli 2022 auf YouTube in einem Video mit dem Titel Stellenanzeigen sind alle gleich (schlecht) [1] thematisiert. Gleichzeitig habe ich aber auch einen Vorschlag gemacht, wie eine Alternative aussehen könnte.
Denn ob es letztlich zwischen einer Bewerberin oder einem Bewerber auf der einen Seite und einem Unternehmen auf der anderen langfristig passt, hängt nur sehr bedingt von Technologien ab: Diese wandeln sich ohnehin alle paar Jahre, und stetige Weiterbildung ist in der IT daher unabdingbar. Zudem lässt sich die technische Eignung relativ schnell ermitteln.
Ob sich beide Parteien miteinander wohlfühlen, hängt auch nicht von einer ÖPNV-Fahrkarte oder einem Obstkorb ab. Beides sind natürlich nette Schmankerl, aber kaum jemand dürfte allein davon die Wahl des künftigen Arbeitgebers abhängig machen.
Viel wichtiger und grundlegend entscheidend ist hingegen, ob es ein gemeinsames Wertesystem gibt und ob die Chemie stimmt: Ein Unternehmen kann technologisch noch so passend sein und die denkbar tollsten Benefits anbieten – wenn es grundlegend unterschiedliche Überzeugungen gibt, wird man auf Dauer kaum gemeinsam glücklich werden.
Das ist aber unter Umständen schwierig herauszufinden. Ob man technologisch zueinander kompatibel ist, ist eine Sache von wenigen Sätzen: Entweder kann man sich auf einen gemeinsamen Nenner einigen oder nicht. Wichtiger ist das Drumherum: Entwicklerinnen oder als Entwickler, denen etwa das Testen wichtig ist, werden nicht in einem Unternehmen glücklich werden, das Tests als lästig ansieht.
Doch wie ein Unternehmen "tickt", das merkt man unter Umständen erst nach Wochen oder Monaten. Theoretisch ließe sich das auch bereits im Bewerbungsgespräch thematisieren, immerhin gibt es dafür in der Regel die berühmten abschließenden zehn Minuten, in denen es heißt: "Haben Sie denn noch Fragen an uns?"
Die Erfahrung zeigt, dass (zu) viele Bewerberinnen und Bewerber oftmals nicht wissen, was sie in dieser Situation fragen sollen – und wenn man wirklich vorbereitet ist und viele Fragen mitbringt, reicht die Zeit in den seltensten Fällen aus, weil Unternehmen nicht darauf eingestellt sind, dass jemand tatsächlich mehr als zwei Fragen stellt.
Wie könnte also eine Alternative zu den heutigen Stellenausschreibungen aussehen?
Statt zu versuchen, sich auf mehr oder weniger formale Art in einem Dokument mit ein paar Schlagworten auszuzeichnen, könnten Unternehmen stärker auf einen persönlichen und vor allem authentischen Austausch zu setzen. Das Problem dabei ist allerdings, dass das im Vorfeld schwierig zu gestalten ist, denn man möchte ja bereits im Vorfeld sicherstellen, dass Bewerberinnen und Bewerber einen weitaus besseren Eindruck erhalten, und sich dann viel zielgerichteter bewerben können – was nicht nur die Chancen für beide Seiten erhöht, sondern auch allen Beteiligten Zeit spart.
Was also tun?
Aus dieser Frage heraus ist die Idee entstanden, dass ich mich selbst (quasi stellvertretend) bei Unternehmen "bewerbe", wir davon ausgehen, dass wir technologisch zueinanderpassen, und wir dann ein sehr ausführliches Gespräch führen, in dem ich all meine Fragen stellen kann. Im Prinzip also eine nachgestellte Bewerbungssituation, die dabei (natürlich mit dem Einverständnis aller Beteiligten) auf Video aufgezeichnet wird.
Dieses Format haben wir im vergangenen Jahr bereits einige Male durchgeführt, und auf dem Weg sind drei Videos entstanden:
Auch wenn die Situation in den Videos nicht ganz einer echten Bewerbung entspricht, zeichnet ein solches Gespräch doch ein deutlich genaueres Bild von dem jeweiligen Unternehmen als es ein knappes PDF je könnte.
Hoch anzurechnen ist den beteiligten Unternehmen aus meiner Sicht vor allem, dass sie sich auf dieses Experiment eingelassen und an dem Format teilgenommen haben, was – wie man hört – auch von Erfolg gekrönt war: Die ein oder andere Einstellung hat es bedingt durch diese Videos bereits gegeben.
Wir möchten dieses Format auch in diesem Jahr fortsetzen. Das heißt: Wer ein Unternehmen vertritt, das auf der Suche nach weiteren Mitarbeiterinnen und Mitarbeitern ist, darf sich gerne bei mir melden. Die Kontaktmöglichkeiten finden sich unter diesem Video [5].
Viel wichtiger jedoch: Wer auf der Suche nach einem neuen Job ist oder jemanden kennt, für die oder den eine der genannten Stellen interessant sein könnte, kann sich gerne das jeweilige Video anschauen beziehungsweise weiterleiten. Vielleicht gelingt es uns auf dem Weg gemeinsam, die Situation mit den Stellenanzeigen zumindest etwas zu verbessern.
URL dieses Artikels:
https://www.heise.de/-7544246
Links in diesem Artikel:
[1] https://www.youtube.com/watch?v=Ub0oEmv147A
[2] https://www.youtube.com/watch?v=G9VAtkKS7ZE
[3] https://www.youtube.com/watch?v=_PgZQgzVSIE
[4] https://www.youtube.com/watch?v=8njAGQBpN_0
[5] https://www.youtube.com/watch?v=Ub0oEmv147A
[6] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Gleisanlagen in Maschen
(Bild: MediaPortal der Deutschen Bahn)
In den letzten Jahren gab es verschiedene Veränderungen im Java Release Train, die zu Verwirrung und Missverständnissen in der Community geführt haben.
Bereits seid dem Release von Java 9 in 2017 werden neue Java-Plattform-Releases durch einen neuen und deutlich besser definierten Release Train veröffentlicht. Leider waren die Aussagen zu den verschiedenen Änderungen und Verbesserungen des Release Train oft nur sehr vage und teils gab es sogar falsche Gerüchte in der Community. Vor allem Oracle hat hier eine schlechte Pressearbeit geliefert und den neuen Release Train nicht so transparent und sauber beschrieben, wie es hätte sein müssen. Da mit dem Release von Java 17 erneut Änderungen in den Release Train eingeflossen sind, möchte ich diesen Post nutzen, um den konkreten Ablauf zu beschreiben.
Bevor wir aber auf den neuen Release Train schauen, ist es sinnvoll, einmal auf die Releases von alten Java-Versionen zu blicken. Das folgende Diagramm zeigt den Release-Zeitpunkt und die Lebensdauer (Lifecycle) von Java 6, 7 und 8. Der Lifecycle der Versionen ist hierbei durch die Verfügbarkeit von kostenlosen Security-Updates der jeweiligen Version definiert. Sobald es für eine der Versionen keine kostenlosen Updates mehr gab oder gibt, endet im Diagramm deren Lebensdauer.

Im Diagramm kann man unterschiedliche Punkte erkennen. Wichtig ist erst einmal, dass immer ein Zeitraum existiert, in dem noch wenigstens zwei Releases mit Security-Updates unterstützt werden. Diese Zeit dient Usern der Plattform als Zeitspanne zur Migration ihrer Anwendungen auf die jeweils neuere Java-Version. Hinzu kommt, dass die Abstände der Releases von neuen Versionen unterschiedlich sind. Das liegt daran, dass diese Java-Versionen veröffentlicht wurden, sobald alle für die jeweilige Version definierten Features implementiert wurden.
Für jede dieser alten Java-Versionen wurden die zu implementierenden Features innerhalb eines Java Specification Requests (JSR) im Java Community Process (JCP) definiert. Für Java 8 kann man beispielsweise unter JSR 337 [1] in Sektion 3 eine Liste der einzelnen Features finden. Diese sind hierbei wiederum auch als JSRs spezifiziert, wobei die Einführung von Lambda-Ausdrücken in Java im JSR 335 und die Date & Time API in JSR 310 definiert wurde.
Da im Vorfeld fest definierte wurde, welche JSRs in einer neuen Java-Version umgesetzt werden sollen, konnte der Release-Zeitpunkt nie fest definiert werden. Das hat teils zu langen Zeitspannen zwischen den Veröffentlichungen der Versionen geführt.
Bei dem gesamten Prozess ist es noch wichtig anzumerken, dass diese Releases keine Versionen sind, die beispielsweise für das Oracle-JDK spezifisch sind. Alle diese Versionen werden im OpenJDK erstellt. Somit kann jeder Java-Vendor einen Build seiner Runtime mit der aktuellen Version anbieten, ohne dass es Unterschiede in der Funktionalität gibt.
Mit Java 9 hat sich diese Vorgehensweise aber stark verändert. Statt langlebiger Releases mit einem unbestimmten Erscheinungsdatum und Lebenszyklus erscheint nun alle sechs Monate ein neues Major Release der Java-Plattform. Das passiert wie bisher im OpenJDK, aber die Sourcen des OpenJDK sind seit Java 17 komplett zu GitHub migriert, wo man die genauen Workflows deutlich besser nachvollziehen kann. Da der Veröffentlichungszeitpunkt eines Release fest definiert ist, können die Features nicht mehr im Vorfeld bestimmt werden. Viel mehr enthält eine neue Java Version alle zu diesem Zeitpunkt abgeschlossen Features. Diese Features werden als JDK Enhancement Proposals (JEP) definiert und können alle auf der Webseite des OpenJDK eingesehen werden [2]. Diese JEPs kann man sich hierbei ähnlich zu Epic Issues vorstellen. Ab Java 10 kann man dann auch auf der jeweiligen Seiten des Releases die Liste der im Release enthaltenen JEPs sehen (siehe Beispiel für Java 11 [3]).
Da manche diese Features längere Zeit zum Entwickeln benötigen und starke Auswirkung auf die Java-Plattform haben, wurde für JEPs der Preview- und Incubator-Status eingeführt. Neue APIs können durch Letzteren bereits zum Testen in Java-Versionen landen, bevor sie in einer künftigen Version finaler Bestandteil der Java-Klassenbibliothek werden. Solche APIs liegen in einem speziellen Incubator Package und werden erst mit ihrem finalen Release an ihr korrektes Package verschoben. Der Preview-Status kann genutzt werden, um neue Sprachfeatures der Java-Plattform bereits im Vorfeld verfügbar zu machen. Solche Features muss man über einen Kommandozeilenparameter aktivieren:
$ javac HelloWorld.java
$ javac --release 14 --enable-preview HelloWorld.java
$ java --enable-preview HelloWorldMit einem neuen Release alle sechs Monate hat sich auf die Lebensdauer von Java-Versionen deutlich verändert. Hierbei wird nun zwischen Long-Term Support (LTS) und normalen (non LTS) Versionen unterschieden. Letztere haben eine Lebensdauer von genau sechs Monaten bis zum Release der nächsten Version. So hatte Java 14 eine Lebensspanne von März 2020 bis September 2020. Als LTS gekennzeichnete Versionen werden im OpenJDK länger gepflegt und erhalten über einen längeren Zeitraum Sicherheitsupdates.
Für das LTS-Release Java 17 wird es nach heutigem Kenntnisstand bis 2027 Updates geben. Eine gute Übersicht der LTS Versionen bietet Eclipse Adoptium in der Supportübersicht [4]. Auch wenn LTS-Updates keine neuen Features enthalten, fixen sie doch alle bekannten Sicherheitslücken. Daher heißen solche Releases auch Critical Patch Update (CPU). Für Java-Versionen, die nicht als LTS-Versionen definiert sind, erscheinen zwei geplante CPU-Releases. So wurde für Java 16 nach dem ersten Release im März 2021 die Version 16.0.1 im April 2021 und 16.0.2 im Juli 2021 als CPU veröffentlicht. Mit dem Erscheinen von Java 17 wurde festgelegt, dass es alle zwei Jahre ein neues LTS Release von Java geben wird. Hierdurch wird Java 21 im September 2023 das nächste LTS-Release sein.
Basierend auf diesen Definitionen sieht der Release-Graph der Java Versionen seid Java 9 folgendermaßen aus:

Da alle Arbeit im OpenJDK erfolgt, kann der Veröffentlichungszeitpunkt von einzelnen Java Distributionen leicht abweichen. Sobald das Release im OpenJDK freigegeben ist, startet die Arbeit zum Erstellen der Distributionen wie Eclipse Temurin, Oracle JDK oder Azul Zulu. Hierbei ist jedem Hersteller freigestellt, die Sourcen des OpenJDK um zusätzliche Funktionen zu erweitern, um sich durch Alleinstellungsmerkmal abzuheben. Manche wie Azul oder Bellsoft bündeln beispielsweise JavaFX in ihren Builds.
In früheren Versionen hat vor allem Oracle mit Tools wie WebStart oder Mission Control versucht, sich von anderen OpenJDK-Builds abzuheben. Das hat allerdings zu Kompatibilitätsproblemen in der Community geführt und wird zum Glück heute in der Regel nicht mehr praktiziert.
URL dieses Artikels:https://www.heise.de/-7350614
Links in diesem Artikel:[1] https://www.jcp.org/en/jsr/detail?id=337[2] https://openjdk.java.net/jeps/0[3] https://openjdk.java.net/projects/jdk/11/[4] https://adoptium.net/de/support/[5] mailto:rme@ix.de
Copyright © 2023 Heise Medien

(Bild: SWstock / Shutterstock.com)
Web-Platform-APIs erlauben Zugriff auf das lokale Dateisystem oder die Zwischenablage. Zur bequemen Nutzung der Schnittstellen in C# stehen NuGet-Pakete bereit.
Progressive Web Apps [1] (PWA) sind ein webbasiertes Anwendungsmodell. Einmal implementiert lassen sie sich überall dort ausführen, wo ein halbwegs moderner Webbrowser zur Verfügung steht – Offlinebetrieb sowie Icon auf dem Homescreen oder in der Taskleiste inklusive.
Dazu passend brachten Initiativen wie Project Fugu [2] in der Vergangenheit weitere Web-Plattform-Schnittstellen ins Web. Dazu zählen etwa die File System Access API zum Zugriff auf das lokale Dateisystem, die Async Clipboard API zum Verwenden der Zwischenablage oder die Web Share API zur Integration in die Funktionalität des Betriebssystems zum Teilen von Inhalten. Diese Schnittstellen stehen allen Webanwendungen zur Verfügung.
Andere APIs setzen voraus, dass die Webanwendung auf dem System des Users installiert ist. Das gilt beispielsweise für die Badging API, die eine kleine Plakette auf dem Symbol der PWA darstellt, oder die File Handling API, die eine PWA bei Installation als Bearbeitungsprogramm für bestimmte Dateierweiterungen registriert.
Auch Microsofts Single-Page-App-Framework Blazor WebAssembly [3] eignet sich zum Implementieren von PWAs. In der Projektvorlage für Blazor-WebAssembly-Projekte können Entwickler und Entwicklerinnen einfach ein Kontrollkästchen setzen, um die PWA-Unterstützung zu aktivieren.
Blazor WebAssembly wird gerne von .NET-Entwicklern gewählt, die ihre Webanwendung in C# schreiben möchten. Natürlich kommen die Web-Plattform-Schnittstellen sämtlichen Webentwicklerinnen zugute, auch Nutzern von Blazor WebAssembly. Da die APIs in der Regel aber JavaScript-basiert sind, braucht es zur einfachen Nutzung in der C#-Welt geeignete Wrapper.
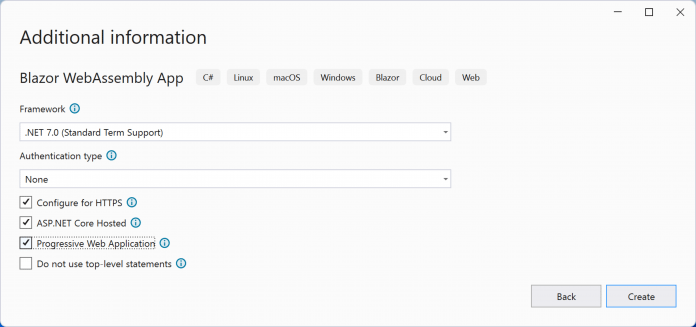
Glücklicherweise stehen für viele interessante APIs bereits quelloffene Wrapper zur Verfügung, die sich via NuGet in das Blazor-WebAssembly-Projekt installieren lassen. Hinweise zum Verwenden der NuGet-Pakete und zum Browser-Support der Schnittstellen finden sich jeweils in Klammern verlinkt:
Nachstehend wird das NuGet-Paket Thinktecture.Blazor.Badging vorgestellt. Die Badging API eignet sich etwa für Todo-Listen-Apps oder E-Mail-Clients, die darüber die Liste zu erledigender Todos oder ungelesener E-Mails darstellen. Ein prominenter Verwender der API ist die Twitter-PWA.
Die API wird von Chromium-basierten Browsern seit Version 81 auf macOS und Windows unterstützt. In der aktuellen Beta-Version 1 von iOS und iPadOS 16.4 liefert auch Apple die Unterstützung für die Schnittstelle mit [16].
Zunächst muss das NuGet-Paket ins Blazor-WebAssembly-Projekt aufgenommen werden:
dotnet add package Thinktecture.Blazor.BadgingAls Nächstes muss der BadgingService bei der IServiceCollection registriert werden. Dies geschieht üblicherweise in der Datei Program.cs:
builder.Services.AddBadgingService();Nicht alle APIs werden auf jedem Browser und jedem Betriebssystem unterstützt. So zeigen App-Badges unter Android etwa die Anzahl der Notifications dieser App an, weswegen die Schnittstelle hier nicht anwendbar ist. Auch steht die Schnittstelle nur dann zur Verfügung, wenn die App installiert wurde.
Daher sollten Entwickler innen und Entwickler immer das Prinzip des Progressive Enhancement [17] nutzen: Nur wenn eine Schnittstelle verfügbar ist, sollte man sie auch nutzen. Andernfalls könnte es zur Laufzeit zu einem Fehler kommen.
Ist eine Schnittstelle nicht verfügbar, sollte die Funktion in der App versteckt oder ausgegraut werden. Manchmal stehen auch Fallback-Ansätze zur Verfügung, auf die Entwicklerinnen zurückgreifen können. Im Falle der Badging API könnte etwa der Fenstertitel angepasst werden, indem die Anzahl der Mitteilungen dem Anwendungstitel in Klammern vorangestellt wird: "(3) My Cool App".
Um eine Unterscheidung zu ermöglichen, bieten die Pakete in der Regel die Methode IsSupportedAsync() an, mit der Entwickler das Vorhandensein der API prüfen können:
var isSupported = await badgingService.IsSupportedAsync();
if (isSupported)
{
// enable badging feature
}
else
{
// use alternative implementation
}Steht die API zur Verfügung, lässt sich das Badge über die Methode SetAppBadgeAsync() setzen. Diese Methode nimmt eine Zahl entgegen, die auf dem Badge dargestellt werden sollen. Alternativ kann auch "null" übergeben werden, in diesem Fall wird eine generische Plakette dargestellt.
await badgingService.SetAppBadgeAsync(3);Und so erscheint dann das gewünschte Badge auf dem App-Icon:
Über die vergangenen Jahre ist das Web immer leistungsfähiger geworden: Microsoft hat dank der File System Access API seinen Codeeditor Visual Studio Code in den Browser bringen können [18] (vscode.dev [19]). Adobe nutzt die File System API in seiner Webversion von Photoshop [20]. Gleich mehrere APIs vereinigt der webbasierte Microsoft-Paint-Klon paint.js.org [21] (paint.js.org [22]) in sich.
Dank der Wrapper-Pakete können auch Blazor-WebAssembly-Anwendungen bequem auf die neuen, leistungsfähigen Web-Plattform-APIs zugreifen. Die Schnittstellen integrieren sich meistens nahtlos in die C#-Welt. Und damit können auch .NET-Entwickler komplexe Produktivitätsanwendungen direkt für den Browser schreiben.
URL dieses Artikels:
https://www.heise.de/-7520799
Links in diesem Artikel:
[1] https://www.heise.de/blog/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html
[2] https://www.heise.de/blog/Fugu-Die-Macht-des-Kugelfisches-4255636.html
[3] https://www.heise.de/blog/Angular-oder-Blazor-Eine-Entscheidungshilfe-fuer-Webentwickler-6197138.html
[4] https://www.w3.org/TR/clipboard-apis/#async-clipboard-api
[5] https://www.nuget.org/packages/Thinktecture.Blazor.AsyncClipboard
[6] https://w3c.github.io/badging/
[7] https://www.nuget.org/packages/Thinktecture.Blazor.Badging
[8] https://fs.spec.whatwg.org/
[9] https://www.nuget.org/packages/KristofferStrube.Blazor.FileSystem
[10] https://wicg.github.io/file-system-access/
[11] https://www.nuget.org/packages/KristofferStrube.Blazor.FileSystemAccess
[12] https://github.com/WICG/file-handling/blob/main/explainer.md
[13] https://nuget.org/packages/Thinktecture.Blazor.FileHandling
[14] https://www.w3.org/TR/web-share/
[15] https://www.nuget.org/packages/Thinktecture.Blazor.WebShare
[16] https://www.heise.de/blog/Web-Push-und-Badging-in-iOS-16-4-Beta-1-Mega-Update-fuer-Progressive-Web-Apps-7518359.html
[17] https://developer.mozilla.org/en-US/docs/Glossary/Progressive_Enhancement
[18] https://www.heise.de/news/Visual-Studio-Code-laeuft-ab-sofort-im-Browser-6224465.html
[19] https://vscode.dev
[20] https://www.heise.de/blog/Analyse-Photoshop-jetzt-als-Webanwendung-verfuegbar-6229321.html
[21] https://www.heise.de/blog/paint-js-org-MS-Paint-Remake-als-PWA-mit-Web-Components-und-modernen-Web-Capabilities-6058723.html
[22] https://paint.js.org
[23] mailto:map@ix.de
Copyright © 2023 Heise Medien
A few highlights ✨:
cli/sensitive-log.sh to help e.g. Apache clear logs for sensitive information such as credentials #5001
This release has been made by several new contributors @axeleroy, @hippothomas, @mincerafter42, @sad270, @zhzy0077, in addition to our regular contributors @Alkarex, @ColonelMoutarde, @Frenzie, @myuki, @aledeg, @marienfressinaud, @math-GH, @miicat, @nicofrand, @yzqzss ... Thank you!
Detailed tracked changes.
Full changelog:
\( or \) #4989mailto: links for webmail services #4680cli/sensitive-log.sh to help e.g. Apache clear logs for sensitive information such as credentials #5001cli/access-permissions.sh to help apply file permissions correctly #5062./extensions/ #4956font/woff #4894latest branch (instead of a tag) to track the latest FreshRSS stable releases #5148is_writable() checks #4780lib_opml #4403
(Bild: metamorworks/Shutterstock.com)
Mit aktuellen Programmierparadigmen und Features stellt sich die Frage, ob Java die stets beworbene Abwärtskompatibilität noch gewährleisten kann.
Mit dem Slogan "Write Once, Run Anywhere" (WORA) hat Sun Microsystems ab 1995 für die Java- Plattform geworben. Dieser Slogan vereinte zwei unterschiedliche Vorteile von Java: Durch die Nutzung der JVM (Java Virtual Machine) können kompilierte Programme auf allen Plattformen ausgeführt werden, auf denen eine JVM verfügbar ist. So kann eine auf Windows kompilierte Java-Anwendung beispielsweise problemlos auf Linux in einer JVM ausgeführt werden.
Der zweite Aspekt des Slogans ist die Abwärtskompatibilität von Java. Software, die mit einer Java-Version kompiliert wurde, soll auch problemlos auf zukünftigen Java-Versionen ausgeführt werden. In den vergangenen Jahren hat sich aber bezüglich dieses Versprechens einiges geändert.
Abwärtskompatibilität sollte in Java schon immer durch die Trennung der Public und Private APIs in der Java Class Library (JCL) ermöglicht werden. Die JCL beinhaltet alle Klassen der Java-API, mit denen wir täglich arbeiten, wie etwa java.lang.String oder java.util.List. Aber auch exotischere Klassen wie sun.misc.Unsafe sind Bestandteil der JCL. Die JCL definiert zusammen mit der Java Virtual Machine (JVM) und verschiedenen Tools wie dem Java-Compiler (javac) das JDK von JavaSE, mit dem Entwickler täglich arbeiten.

Die Private API des JCL liegt zwar auf dem Classpath, sollte von Anwendungen aber nie direkt genutzt werden. Interne Änderungen im OpenJDK werden oft in diesem Bereich implementiert, wodurch mögliche Änderungen in den Schnittstellen der Private API entstehen konnten. Generell kann man sagen, dass alle Klassen der JCL, deren Packages nicht mit java.* oder javax.* beginnen, zur Private API gehören, da manche Java-Distributionen JavaFX enthalten, kann man für diese noch javafx.* hinzufügen.
Software, die zur Compile-Zeit oder Laufzeit Klassen aus der Private API nutzte, war somit bei jedem (Major-)Release von Java gefährdet, nicht mehr lauffähig zu sein. Während man die Nutzung zur Compile-Zeit direkt feststellen konnte, kam es teils bei der Nutzung zur Laufzeit beispielsweise durch Reflexion oder transitive Abhängigkeiten sogar zu unerwarteten Problemen in Produktion.
Mit Java 9 und der Einführung des Modulsystems hat sich das Ganze aber geändert. Das Modulsystem erlaubt es, APIs vor der Außenwelt zu verbergen und sie somit nur noch innerhalb des eigenen Moduls nutzbar zu machen. Hierdurch konnten die Private APIs von Java komplett verborgen werden.

Da diese privaten APIs von vielen Programmen und Libraries genutzt wurden, hätte dieser Einschnitt mit Java 9 sicherlich zu immensen Umbauten geführt. Daher hat man sich im OpenJDK dafür entschieden, dass die privaten APIs von Java 9 bis Java 15 weiterhin genutzt werden können. Hier wird lediglich eine Warnung ausgegeben, wenn die Software auf Private APIs zugreift. Dafür wurde der Parameter illegal-access eingeführt, der bei Java 9 bis 15 per Default auf warn gesetzt ist. Geändert werden konnte der Parameter einfach zum Start der JVM als Kommandozeilenparameter.
So konnte man auch in diesen Versionen durch Hinzufügen von --illegal-access=deny bereits dafür sorgen, dass ein Javaprogramm die Private APIs des JCL nicht mehr nutzen kann. Dies war dann auch das Standardverhalten von JDK 16. Hier muss man das Flag aktiv auf warn setzen, wenn man der eigenen Anwendung noch die Nutzung von Private APIs ermöglichen möchte. Mit dem LTS-Release von Java 17 wurde diese Option dann allerdings komplett entfernt. Die Werte permit, warn und debug wurden für das illegal-access Flag entfernt, wodurch es nicht mehr möglich ist, den generellen Zugriff auf Private APIs zu erlauben. Ist man mit Java 17 noch immer gezwungen Private APIs zu nutzen, so kann man dieses noch immer über das --add-opens-Flag oder dem Add-Opens-Attribut im Manifest für spezifische Module ermöglichen.
Auch Änderungen in den Tools oder der JVM können sich auf die Abwärtskompatibilität von Java auswirken. Mit Java 10 wurde beispielsweise durch das JEP 286 [1] die Java Language um die Nutzung von var erweitert. Hierdurch muss der Typ einer Variable in Java nicht mehr händisch angegeben werden, wenn er vom Compiler bestimmt werden kann. Hier einmal ein Beispiel:
var list = new ArrayList<String>(); // infers ArrayList<String>
var stream = list.stream(); // infers Stream<String> Die Einführung von var in die Java Language hat hierbei einige Auswirkungen nach sich gezogen. Zwar wurde var nicht als Keyword zur Java-Syntax hinzugefügt, wodurch es noch immer möglich ist, var als Variablennamen zu nutzen. Der Status von var in der Java Language ist als "Reserved Type Name" (siehe JEP 286 [2]) definiert. Hierdurch ist es allerdings nicht mehr möglich, Klassen oder Interfaces var zu nennen. Auch wenn dies nur in sehr wenigen Javaprogrammen je vorgekommen sein mag, ist es doch ein Bruch in der Abwärtskompatibilität zu Java.
Die erste Version von Java wurde 1996 veröffentlicht. Da sich nicht nur Java als Programmiersprache, sondern auch Programmierparadigmen seit dieser Zeit immer weiter entwickelt haben, wurden viele APIs in Java umgestellt. Patterns, die 1996 noch typisch waren, sind heutzutage teils als veraltet. Dazu kommt, dass auch die Entwickler des OpenJDK gelegentlich Fehler machen und dadurch APIs entstehen, die man nach heutiger Kenntnis besser nicht mehr nutzen sollte.
Um Java allerdings abwärtskompatibel zu halten, wurden solche APIs nicht entfernt, wenn sie Bestandteil der Public APIs der JCL sind. Hier wurde initial in der JavaDoc vor der Nutzung gewarnt und oft wurden auch direkt alternative APIs vorgeschlagen. Durch die Einführung von Annotation mit Java 1.5 konnte dies durch die Nutzung der @Deprecated-Annotation noch einmal verbessert werden. Diese Annotation zeigt nicht nur dem Nutzer, dass eine API nicht mehr genutzt werden sollte, sondern lässt auch den Java Compiler eine Warnung (oder je nach Konfiguration sogar einen Fehler) erzeugen. Auch in IDEs wird das Ganze heute deutlich hervorgehoben, sodass man schnell sieht, ob Programmcode auf APIs zugreift, die als deprecated (veraltet) markiert sind.
Obschon das Verfahren lange funktioniert hat, entstand über die Jahre doch immer mehr Code im OpenJDK, der mit @Deprecated annotiert war und somit bei jeder Version und Änderung mit gepflegt werden musste. Auch wurde die Java-API somit immer aufgeblähter. Mit dem Einzug des Java-Modulsystems und der Aufteilung der JCL in einzelne Module tauchten noch ganz andere Probleme auf: Durch die vielen veralteten Codestellen, die nie entfernt wurden, gab es völlig wilde Abhängigkeiten im OpenJDK, die nicht einfach aufgelöst werden konnten.
Daher wurde mit Java 9 die @Deprecated-Annotation um das Attribut forRemoval erweitert. Dieses Attribut gibt an, dass eine API, die mit @Deprecated(forRemoval=true) annotiert ist, in einer zukünftigen Version von Java entfernt werden kann. Durch den neuen Release Train von Java und neuen Versionen im Sechsmonatstakt kann dies mitunter äußerst schnell gehen. Und die letzten Versionen von Java zeigen auch, dass hiervon Gebrauch gemacht wird. So wurden unter anderem die CORBA-API, verschiedene Interfaces unter java.security.acl.* oder Methoden aus dem java.lang.SecurityManager entfernt. Der java.lang.SecurityManager soll sogar komplett aus dem JCL entfernt werden.
Um die Unterschiedene und Änderungen zwischen zwei Java-Versionen überprüfen und beurteilen zu können, gibt es seit einiger Zeit die Webseite javaalmanac.io [3]. Hier können alle Unterschiede in der Java Class Library zwischen zwei Java-Versionen angezeigt werden. Da hier nicht nur Versionen mit Long-term Support (LTS) gelistet sind, sondern alle Major Releases seit Java 1.0, kann man einfach auch schon vor einer Umstellung oder sogar vor dem Erscheinen einer neuen LTS-Version von Java mit der Umstellung der eigenen Software beginnen. Neben Änderungen zeigt das Tool auch alle Klassen, Funktionen und weitere Elemente an, die mit @Deprecated annotiert wurden.

Java hat gezeigt, dass sich Programmiersprachen irgendwann zwischen einer innovativen und agilen Weiterentwicklung und einer ständigen Abwärtskompatibilität entscheiden müssen. Je älter eine Sprache wird, desto mehr Altlasten bringt sie mit sich. Viele Teile der API sind nicht mehr zeitgemäß und lassen sich nur schwer auf moderne Paradigmen adaptieren. Daher ist es sinnvoll, dass eine Sprache auch mal Altlasten über Bord wirft. Natürlich darf man dabei die User nicht vergessen und muss sensibel mit diesen Themen umgehen.
Aus meiner Sicht haben die Verantwortlichen für Java diesen Spagat gut bewältigt, indem sie die neuen Konzepte wie das Entfernen von deprecated APIs über einen langen Zeitraum angekündigt haben. Auch sind sie auf Kritik und Feedback der Community eingegangen. Hier gilt sicherlich der Umgang mit der Klasse sun.misc.Unsafe als gutes Beispiel. Deren Entfernen aus dem OpenJDK wurde sehr lange diskutiert. Für Entwickler von Frameworks und Libraries wurden auch weitere Funktionen zum OpenJDK hinzugefügt, um Abwärtskompatibilität gewährleisten zu können. Mit Multi-Release JAR-Files (JEP 238 [4]) können Jars somit spezifische Klassen für verschiedene Java-Versionen enthalten und so die Kompatibilität deutlich erhöhen.
Trotzdem kommt durch solche Änderungen mehr Arbeit auf Entwicklerinnen und Entwickler zu, die lange mit dem Wechsel zwischen Java-Versionen warten. Wenn man aber immer auf die jeweils aktuelle LTS-Version von Java umstellt und die hier beschriebenen Konzepte und Tools kennt, bleiben die Arbeiten generell überschaubar.
URL dieses Artikels:https://www.heise.de/-7342188
Links in diesem Artikel:[1] https://openjdk.org/jeps/286[2] https://openjdk.org/jeps/286[3] https://javaalmanac.io[4] https://openjdk.org/jeps/238[5] mailto:rme@ix.de
Copyright © 2023 Heise Medien
(Bild: Apple)
Apple liefert in Safari für iOS und iPadOS 16.4 Beta 1 gleich mehrere Programmierschnittstellen aus, die Webanwendungen deutlich leistungsfähiger machen.
In einem Blogbeitrag hat das WebKit-Team bekannt gegeben, dass Webanwendungen mit der frisch veröffentlichten Beta 1 von iOS und iPadOS 16.4 endlich Push-Benachrichtigungen über das Web-Push-Verfahren empfangen können [1]. Damit folgt Apple seiner Ankündigung aus dem Sommer 2022 [2]. Das ist jedoch nicht die einzige interessante Programmierschnittstelle, auf die Webentwickler in der neuen Vorabversion von Safari Zugriff haben.
Voraussetzung für die folgenden Schnittstellen und Funktionen ist unter iOS und iPadOS, dass die Webanwendung zum Home-Bildschirm des Gerätes hinzugefügt wurde. Anwender können die Installation über das Teilen-Menü und die Auswahl des Menüeintrags Zum Home-Bildschirm hinzufügen veranlassen. Das Hinterlegen von Web-Clips auf dem Home-Bildschirm ist seit dem im Januar 2008 veröffentlichten iPhone OS 1.1.3 möglich. Apple nennt auf diese Art hinterlegte Webanwendungen Homescreen Web Apps, was synonym zu Progressive Web Apps [3] (PWA) zu verstehen ist. Vom Home-Bildschirm aus gestartet erscheinen sie wie plattformspezifische Apps ohne Browserwerkzeugleisten und inklusive Auftritt im App Switcher. Einmal implementiert laufen sie überall von Mobile bis Desktop dank der zugrundeliegenden W3C-Spezifikationen Service Worker [4] und Web Application Manifest [5].
Das Web-Push-Verfahren ist eine Kombination verschiedener Spezifikationen von W3C und IETF (Push API, Notifications API und HTTP Web Push), die es Entwicklern ermöglichen, Benachrichtigungen proaktiv an ihre Benutzer zu schicken [6]. Die Information, etwa eine Instant Message oder ein Preisalarm, wird auf dem Endgerät in Form eines Notification-Banners dargestellt. Das API-Tandem wird seit vielen Jahren von Microsoft Edge, Google Chrome und Mozilla Firefox unterstützt. Unter Safari für macOS ist die Web Push API seit Version 16 verfügbar, die im September 2022 veröffentlicht wurde. Mit iOS und iPadOS erhalten nun die letzten größeren Betriebssysteme die Unterstützung dafür. Der große Vorteil des Web-Push-Verfahrens ist, dass es nur einmal implementiert werden muss und danach plattformübergreifend verwendet werden kann. Unter iOS und iPadOS erscheinen die Benachrichtigungsbanner genau so, wie sie auch von anderen Apps bekannt sind, inklusive Übertragung auf die Apple Watch und Integration in die Fokus-App.
Weniger aufdringlich als Benachrichtigungsbanner sind Badges, kleine rote Plaketten, die auf dem Symbol einer Anwendung dargestellt werden. Die Badging API [7] erlaubt es Webanwendungen, ein Badge auf dem Symbol der Anwendung auf dem Home-Bildschirm, im Dock beziehungsweise der Taskleiste darzustellen. E-Mail-Programme oder To-do-Listen-Apps nutzen diese Möglichkeit, um die Anzahl ungelesener Nachrichten oder zu erledigender Aufgaben darzustellen. Die Schnittstelle wird seit vielen Jahren von Google Chrome und Microsoft Edge unter macOS und Windows unterstützt. Auch die Twitter-PWA greift auf diese Schnittstelle zurück, um die ungelesenen Mitteilungen und Direktnachrichten zu kommunizieren. Voraussetzung dafür ist unter iOS und iPadOS, dass der Benutzer zuvor dem Empfang von Pushbenachrichtigungen zugestimmt hat.

Ebenso unterstützt die neue Safari-Version die "id"-Eigenschaft des Web Application Manifest [8]. Diese erlaubt eine eindeutige Identifizierung einer auf dem Gerät installierten Webanwendung, um mehrere Installationen zu vermeiden und die Benachrichtigungseinstellungen über mehrere Geräte hinweg zu synchronisieren. Allerdings gibt Safari Usern die Möglichkeit in die Hand, den Anzeigenamen der Anwendung anzupassen. Wählt der Benutzer einen anderen Namen, werden doch wieder mehrfache Installationen einer App möglich, etwa um sie mit unterschiedlichen Profilen nutzen zu können.
Erstmals erhalten Browser von Drittanbietern die Möglichkeit, selbst Verknüpfungen für Webanwendungen auf dem Home-Bildschirm zu hinterlegen. Dies war zuvor ausschließlich Safari vorbehalten. Unter Android, macOS und Windows war es schon früher üblich, dass Fremdbrowser Webanwendungen installieren konnten. Allerdings müssen auch die Browser von Drittanbietern unter iOS und iPadOS zwingend die WebKit-Engine nutzen. An dieser Vorgabe ändert sich nichts.
Neben den oben genannten APIs sind in iOS und iPadOS 16.4 Beta 1 auch weitere Programmierschnittstellen zu finden: Etwa die Screen Wake Lock API [9], die den Bildschirm aktiviert lässt (etwa für Präsentationsprogramme) sowie die Screen Orientation API [10], die Informationen zur Ausrichtung des Bildschirms zugänglich macht. Für diese Schnittstellen ist allerdings keine vorherige Installation der App erforderlich.
Einmal mehr schließt sich die Lücke zwischen plattformspezifischen Apps und Webanwendungen. Mit der Verfügbarkeit von Push-Benachrichtigungen wird wohl eine der häufigsten Anfragen von Webentwicklern über die letzten Jahre nun auf allen relevanten Plattformen abgehakt. Die Integration von Web Push und Badging API ist in der Betaversion von iOS und iPadOS richtig gut umgesetzt, von plattformspezifischen Apps sind die Benachrichtigungsmethoden nicht zu unterscheiden. Auch die Verfügbarkeit weiterer Programmierschnittstellen zeigt, dass es Apple ernst meint und das Web als Anwendungsplattform stetig besser wird.
URL dieses Artikels:
https://www.heise.de/-7518359
Links in diesem Artikel:
[1] https://webkit.org/blog/13878/web-push-for-web-apps-on-ios-and-ipados/
[2] https://www.heise.de/blog/Web-Push-kommt-auf-iOS-und-iPadOS-Pushbenachrichtigungen-fuer-PWAs-jetzt-ueberall-7134230.html
[3] https://www.heise.de/blog/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html
[4] https://www.heise.de/blog/Progressive-Web-Apps-Teil-2-Die-Macht-des-Service-Workers-3740464.html
[5] https://www.heise.de/blog/Progressive-Web-Apps-Teil-3-Wie-die-Web-App-zur-App-App-wird-3464603.html
[6] https://www.thinktecture.com/pwa/push-notifications-api/
[7] https://developer.chrome.com/articles/badging-api/
[8] https://www.w3.org/TR/appmanifest/#id-member
[9] https://developer.mozilla.org/en-US/docs/Web/API/Screen_Wake_Lock_API
[10] https://developer.mozilla.org/en-US/docs/Web/API/Screen_Orientation_API
[11] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Logging ist ein wichtiges Instrument, aber es ist nicht einfach, das richtige Maß der zu protokollierenden Informationen zu finden.
Ein Thema, mit dem sich früher oder später jeder (Java-)Developer auseinandersetzen muss, ist Logging. Während bei kleinen Beispielprogrammen, dem Lernen der Programmiersprache oder dem schnellen Debuggen von Code ein System.out.println ausreichen mag, ist das für den Produktivbetrieb einer Software ein ganz klares No-Go. An dieser Stelle muss der Output einer Anwendung gewissen Qualitätsmerkmalen genügen, damit er zur Überprüfung, Überwachung und Analyse der Anwendung genutzt werden kann. Aus diesem Grund gibt es eine ganze Fülle an Logging-Frameworks und APIs, und für Entwickler ist es hier oft nicht leicht zu Entscheiden welche Strategie hier die richtige ist.
Aus diesem Grund habe ich mich dazu entschlossen, eine Reihe an Best-Practice-Beiträgen zum Thema Logging zu schreiben. In diesem Beitrag starte ich mit den generellen Grundlagen von Logging. In naher Zukunft wird nicht nur eine Übersicht der verschiedenen Logging-Frameworks im Java Ökosystem geben, sondern auch ein Einblick, wie man das Thema Logging in großen Softwarearchitekturen betrachten muss. Abgerundet wird das Themenpaket Logging mit einem Einblick in "Centralized Logging" und moderne Tools, die eine bessere Aufbewahrung und Analyse von Logging erlauben.
Wie manche bereits bei der Überschrift ahnen können, möchte ich einmal kurz über die wirklich grundlegende Dokumentation von Logging sprechen. Denn der Begriff hängt tatsächlich mit dem Logbuch aus der Seefahrt zusammen. Das Logbuch soll generell dazu dienen, Ereignisse aufzuschreiben, die während einer Seefahrt passieren. Und genau das machen wir mit Logging in einer Anwendung auch: Wir schreiben zu bestimmten Ereignissen während der Lebenspanne der Anwendung Nachrichten nieder. Ob diese nun technisch in eine Log-Datei geschrieben oder nur auf der Konsole ausgegeben werden, lassen wir einmal außen vor. Wichtig ist allerdings, dass alle diese Nachrichten Metadaten wie beispielsweise den Zeitpunkt des festzuhaltenden Ereignisses beinhalten.
Genau wie in der Seefahrt gibt es verschiedene sehr gute Gründe, warum man in einer Anwendung auf Logging setzen sollte. Anhand der Historie in einem gut gepflegten Log kann man erkennen, warum bestimmte Ereignisse ausgelöst wurden. Das ist in der IT vor allem sinnvoll, um zu erkennen, wie es zu Fehlern während der Laufzeit einer Anwendung kam. Aber nicht nur in diesen Problemfällen kann Logging hilfreich sein. Generell kann man sagen, dass man aus Logging Informationen über die Nutzung und den Ablauf der Software erfährt. Hierdurch kann man aus der Vergangenheit der Software für zukünftige Integrationen lernen. Wenn man im Logging beispielsweise erkennt, dass 97 % aller Benutzer den "Like"-Button unserer Software erst nach längerer Nutzung betätigen, kann man sich überlegen, ob dieser prominenter in der Software platziert werden muss.
Um die genannten Vorteile aus dem Logging einer Anwendung ziehen zu können, muss es allerdings auch sinnvoll in die Anwendung eingebunden sein. Um dies etwas zu konkretisieren, schauen wir uns im folgenden einmal generelle Best Practices und Anti Pattern beim Logging an.
Um besser zu verstehen, wie wir Logging konkret in unserer Anwendung nutzen sollten, ist es sinnvoll, sich genau zu überlegen, was im Idealfall über einen Logger ausgegeben werden soll. Hier sehe ich drei verschiedene Kategorien, die eigentlich immer geloggt werden sollten:
Aber auch bei diesen Kategorien sollte man es mit dem Logging nicht übertreiben. Hier muss man aufpassen, dass man Informationen nicht in einem Loop loggt. Auch wenn Nutzereingaben als Input von außerhalb gelten, sollte man nicht jeden Tastendruck direkt loggen. Das folgende Beispiel zeigt einen Auszug aus einem problematischen Log-Verlauf, in dem genau das passiert ist:
08:34:23 User mutates id field with new value 'J'
08:34:23 User mutates id field with new value 'JA'
08:34:23 User mutates id field with new value 'JAV'
08:34:23 User mutates id field with new value 'JAVA'
Man kann sich gut vorstellen, wie schwierig es wird, wichtige Informationen aus einer Log-Datei mit solchen Einträgen zu extrahieren.
Ähnlich verhält es sich mit Log-Nachrichten, die zu viele Informationen enthalten. Auch wenn wir wissen, an welchem Tag ein User Geburtstag hat, müssen wir diese Informationen nicht in unsere Log-Nachrichten unterbringen:
08:34:23 User 'Max' with birthday '01/01/1970' \
mutates id field with new value 'JAVA'
Während der Benutzername in der Nachricht sicherlich für eine spätere Analyse interessant sein kann, um diese Nachricht in Relation zu anderen Log-Einträgen zu bringen, so ist das Geburtsdatum eher störend und macht das Lesen der Nachrichten für das menschliche Auge nur komplizierter.
Ein dritter wichtiger Punkt, den man beim Erstellen von Log-Nachrichten immer im Hinterkopf haben sollte, ist die Datensensibilität. Während wir in den bisherigen Meldungen immer die Änderung einer ID im Log gesehen haben, sollte folgende Nachricht nie in einem Log-File auftauchen:
08:34:23 User 'Max' mutates password with new value '12#Agj!j7
In diesem Fall würde das Logging eine echte Sicherheitslücke der Anwendung darstellen. Solche sensitiven Daten wie das Nutzerpasswort dürfen selbstverständlich nie in Log-Nachrichten ersichtlich sein.
Basierend auf den bisherigen Erkenntnissen sehen folgende Log-Nachrichten sinnvoll und gut aus:
08:34:23 User 'Max' mutates id field with new value 'JAVA'
08:34:23 User 'Max' mutates password
Neben diesen Tipps sollte man auch immer schauen, dass man den Sourcecode einer Anwendung nicht so sehr mit Log-Aufrufen vollstopft, dass der Sourcecode am Ende nicht mehr sinnvoll zu lesen und verstehen ist. Folgender Ausschnitt aus einem Java-Programm zeigt, was passiert, wenn man es mit den Logging-Aufrufen übertreibt:
LOG.log("We start the transaction");
manager.beginTransaction();
LOG.log("DB query will be executed");
LOG.log("DB query: select * from users");
long start = now();
users = manager.query("select * from users");
LOG.log("DB query executed");
LOG.log("DB query executed in " + (now() - start) + " ms");
LOG.log("Found " + users.size() + " entities");
manager.endTransaction();
LOG.log("Transaction done");Hier ist der Code und dessen genaue Funktion kaum zu erkennen. Fehlen die Logging-Aufrufe schaffen wir das aber auf einen einzigen Blick:
manager.beginTransaction();
users = manager.query("select * from users");
manager.endTransaction();Nun soll man aber natürlich nicht das gesamte Logging außen vor lassen, und vielleicht ist genau dies eine Stelle, bei der man gerne viele Informationen im Logging sehen möchte. In diesem Fall muss man die Logging-Aufrufe geschickter in die Struktur und die API der Anwendung integrieren. Alle Informationen, die wir im ersten Beispiel gesehen haben, könnten auch direkt innerhalb der beginTransaction-, query- und endTransaction-Methoden geloggt werden. So wird die Business-Logik von den Logging-Aufrufen gesäubert und wir bekommen trotzdem alle Informationen.
Sollte es aus verschiedenen Gründen nicht möglich sein, dass Logging direkt in der API unterzubringen, kann man auch Komplexität in Verbindung mit Logging relativ einfach in wiederverwendbaren Lambdas oder Methoden "verstecken". Das folgende Beispiel zeigt eine generische Funktion, die eine Query innerhalb einer Transaktion ausführt und alle benötigten Informationen weiterhin als Log-Nachrichten weitergibt.
final Function<String, T> queryInTransaction = query -> {
LOG.log("We start the transaction");
manager.beginTransaction();
LOG.log("DB query: " + query);
long start = now();
T result = manager.query(query);
LOG.log("DB query found " + result.size() + " entities in "
+ (now() - start) + " ms");
manager.endTransaction();
LOG.log("Transaction done");
return result;
}Das führt dazu, dass wir in der Business-Logik unsere Aufrufe in einer lesbaren Form mit maximalem Logging aufrufen können:
LOG.log("Loading all users from database");
users = queryInTransaction("select * from users");Jedem, der schon einmal mit Logging-Frameworks gearbeitet hat, fehlt in den bisherigen Beispielen sicherlich das Logging-Level als wichtiges und zentrales Element. Dieses wollen wir uns zum Abschluss einmal genauer anschauen. Auch wenn unterschiedliche Logger nicht immer die gleichen Level definieren, haben doch alle die gleiche Funktionalität: auf einer eindimensionalen Skala wird durch das Level angegeben, wie wichtig die Nachricht im Kontext aller Nachrichten ist.

Wie beispielhaft im Bild gezeigt, gehen wir einmal davon aus, dass wir in unserem Logging drei verschiedene Level nutzen können (Anmerkung: Je nach konkretem Logging-Framework gibt es einige mehr). Im Level ERROR wollen wir alles fehlerhafte Verhalten der Anwendung loggen, während wir den Level INFO für generelle Informationen über den Ablauf und Status der Anwendung nutzen. Mit dem DEBUG-Level loggen wir Detailinformationen, die nur in Ausnahmefällen wichtig sind. Java-Quellcode der die verschiedenen Level im Logging einsetzt, könnte somit wie folgt aussehen:
try {
LOG.info("Loading all users from database");
users = query("select * from users");
LOG.debug("Found " + users.size() + " users in db");
} catch (Exception e) {
LOG.error("Error while loading all users");
}Zur Laufzeit der Anwendung kann man das Level des Loggers nun konfigurieren und somit filtern, welche Nachrichten wirklich im Log landen sollen. In der Regel filtert man hier die Nachricht im DEBUG-Level heraus und nimmt diese nur bei Fehleranalysen oder ähnlichen Szenarien in das Log mit auf. Der Vorteil ist, dass man den Sourcecode der Anwendung nicht ändern muss, um mehr Informationen zu erhalten. Nur die Konfiguration muss angepasst werden, und das kann je nach genutztem Logging-Framework sogar dynamisch zur Laufzeit passieren. Zusätzlich lässt sich eine solche Filterung auch nutzen, um unterschiedliche Informationen in einem Test- beziehungsweise Produktivsystem zu loggen.
Basierend auf den in diesem Blog-Post aufgezeigten generellen Regeln lassen sich bereits Definitionen für das Logging einer Anwendung oder einer kompletten Systemlandschaft erarbeiten. Wichtige Fragen, die man sich beim Erstellen von Regeln zum Logging stellen sollte, sind unter anderem:
Wie beschrieben, gibt es verschiedene Punkte, die beim Logging zu beachten sind. Generell ist es sinnvoll, ein Konzept zum Umgang mit Logging zu definieren. Hier kann man Richtlinien und Best Practices zum internen Umgang mit Logging definieren und festhalten. In ein solches Konzept gehören auch technische Aspekte wie präferierte Libraries oder Pattern. Diese werden wir uns im nächsten Teil der Reihe zu Java-Logging genauer anschauen.
URL dieses Artikels:https://www.heise.de/-7336005
Links in diesem Artikel:[1] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Der Blog „Neuigkeiten von der Insel“ geht endlich weiter! Hier gibt es News und Meinungen zu Java, dem OpenJDK und aktuellen Themen der Java Community
Man könnte meinen, Java erlebt mit dem seit Java 9 etablierten Release Train und vielen modernen Features wie virtuellen Threads oder allen Neuerungen rund um Pattern Matching seine Renaissance. Allerdings wäre es unserer Meinung nach hier falsch von einer Wiedergeburt zu sprechen, da Java nie weg war. Viel mehr gehört Java seit über zwei Jahrzehnten zu den meistgenutzten Programmiersprachen [1].
Allerdings hat sich die Dynamik und somit auch die Weiterentwicklung von Java seit Einführung des neuen Release Train mit Java 9 deutlich erhöht. Und das wirkt sich nicht nur auf die Performance und Nutzbarkeit der Sprache, sondern natürlich auf generell auf dessen Attraktivität aus. Grund genug, den Java-Blog „Neuigkeiten von der Insel“ von heise Developer wieder aufleben zu lassen.
Wir, das sind konkret Falk Sippach und Hendrik Ebbers, haben uns für die nahe bis mittlere Zukunft des Blogs vorgenommen, das Thema Java SE und OpenJDK in den Mittelpunkt zu stellen. Sicherlich wird es auch immer wieder Ausflüge in Enterprise-Themen wie JakartaEE oder Spring geben und auch bisherige Themen wie JPA und generelle Nutzung von Daten wie Streaming werden behandelt. Zentral wollen wir aber den Kern von Java in den Vordergrund stellen. Dieser setzt sich nach unserer Meinung aus folgenden Teilen zusammen: der JVM, der Java Class Library (JCL), den Tools des JDK und dem OpenJDK an sich.

Alleine für diese Punkte haben wir viele Ideen, die wir in Zukunft hier im Blog angehen wollen. Da wir das Ganze neben unserer normalen Arbeit machen, können wir zwar keine festen Termine versprechen, werden aber versuchen, einen kontinuierlichen Output an interessanten Themen zu veröffentlichen.
Und damit ihr eine noch bessere Vorstellung darüber habt, wer hier überhaupt schreibt, mal ein paar persönliche Worte der Vorstellung von uns.

Im Informatikunterricht in der Schule wurde ich zunächst mit Turbo Pascal sozialisiert. Aber im Studium durfte ich die Hände an Java, damals in der Version 1.1, legen. Dadurch blicke ich auf eine 25-jährige Vergangenheit zurück; ich bin mit der Sprache Java und seinem Ökosystem quasi groß geworden. Alleine fast 15 Jahre war ich als Trainer, Berater und Entwickler für die Mannheimer Firma Orientation in Objects tätig.
Mittlerweile hat sich bei meinem jetzigen Arbeitgeber embarc der Fokus in Richtung Softwarearchitektur verändert. Ich berate Kunden (teilweise auch noch im Java-Umfeld) und führe Architektur-Reviews sowie iSAQB-Trainings durch. Dabei bin ich aber weiterhin ein Teil der Java Community geblieben, organisiere seit über 10 Jahre die JUG Darmstadt mit und unterstütze als Programmbeirat diverse Konferenzen wie JavaLand, Herbstcampus und andere. Besonders am Herzen liegt mir der Austausch mit Gleichgesinnten. Ich teile mein Wissen darum gern in Artikeln und Blogbeiträgen sowie über Schulungen, Workshops und Vorträgen auf Konferenzen und bei User Group Treffen.
Bei meinen Kunden, Teilnehmern und Kollegen versuche ich immer den Funken Leidenschaft überspringen zu lassen. Denn meine Überzeugung ist, dass lebenslanges Lernen zu unserer täglichen Arbeit dazugehört und dass wir uns nicht auf dem bereits Erreichten ausruhen sollten. Trotz der Begeisterung für Neues behalte ich aber auch die Menschen und gewachsene Strukturen im Blick, um ausgewogene Lösungen entwickeln zu können.
Im Rahmen dieses Java-Blogs werde ich zunächst von den Neuerungen in den anstehenden Releases berichten. Das zählen unter anderem Pattern Matching, Virtual Threads und Value-/Primitive-Types. Zusätzlich könnt ihr mich bei Twitter unter @sippsack [2] finden.

Ich bin schon seit vielen Jahren ein Teil der Java Community. Um ehrlich zu sein, habe ich – vielen Dank an meinen Lehrer – bereits im Informatikunterricht der Mittelstufe mit Java 1.2 angefangen. Durch meinen Einstieg in das Thema Open Source und der Gründung der Java User Group Dortmund vor fast 15 Jahren habe ich immer mehr Kontakte in der Java Community knüpfen können und habe vor etwa zehn Jahren angefangen, international Vorträge zu Java zu halten. Nach mehreren Java-Rockstar-Speaker-Awards auf der JavaOne, meinem offiziellen JavaFX Buch von Oracle Press und der Mitarbeit in JCP Expert Groups bin ich 2016 zum Java Champion ernannt worden.
Heute setze ich mit meinem eigenen Unternehmen Open Elements den Fokus weiterhin auf Java und Open Source, wobei ein Schwerpunkt bei der Mitarbeit an Eclipse Adoptium liegt, da ich Mitglied der Working Group und des Project Management Committee bin. Im deutschsprachigen Bereich werden die meisten mich durch meine Arbeit in der Konferenzleitung der JavaLand oder den Aktivitäten der Cyberland kennen. Wer sich mit mir über Java, Open Source oder eines meiner anderen Interessen (Brettspiele, Star Wars, Hunde, Hardrock) austauschen möchte, kann mich jederzeit über @hendrikEbbers [3] auf Twitter erreichen.
URL dieses Artikels:https://www.heise.de/-7464768
Links in diesem Artikel:[1] https://www.tiobe.com/tiobe-index/java/[2] https://twitter.com/sippsack[3] https://twitter.com/hendrikEbbers[4] mailto:rme@ix.de
Copyright © 2023 Heise Medien

Ist das verbilligte Netflix-Abo mit Werbung sinnvoll oder bleibt es ein verzweifelter Versuch, die Talfahrt der Abonnentenzahlen zu stoppen? Wir haben nachgefragt.
Kürzlich haben wir eine Umfrage unter unseren Abonnenten gestartet. Wir wollten wissen, was unsere Leser vomwerbefinanzierten Netflix-Abo halten. Die Ergebnisse waren nicht grundsätzlich überraschend, in ihrer Eindeutigkeit aber doch bemerkenswert.
So fanden unter über 1000 Teilnehmenden nicht einmal 30 das Netflix-Angebot mit Werbung interessant. 422 Teilnehmer lehnten es ab, 570 finden Netflix ohnehin irrelevant. Letzteres brachte Malte D. knallhart auf den Punkt: "Wenn ich Netflix und Co. zum Leben brauche, mache ich grundsätzlich was falsch."

Ganz so heftig fiel das Urteil bei anderen nicht aus. Viele lehnen Netflix nicht grundsätzlich ab, finden aber Werbung sehr nervig und würden sie keinesfalls für den gebotenen Abo-Preisnachlass akzeptieren. So schrieb uns Ralf S.: "Wegen 3 Euro Differenz Werbung? Oh, nicht doch," und Mirko V.: "Werbung nervt einfach. Zwischen den Filmen mag es noch gehen, aber einen Film dafür unterbrechen? Willkommen bei RTL und Co.."
In die gleiche Kerbe schlägt auch Heinz G: "Für mich sind in erster Linie die Inhalte, also die angebotenen Filme interessant – und diese ohne Werbeunterbrechung. Ob das Abo nun 5 oder 8 Euro kostet, spielt nur eine untergeordnete Rolle."
Andreas H. neigt eher zum Netflix-Totalboykott. Er schrieb uns: "Nachdem das Sharing verboten wurde, ist alles andere egal geworden."
In den Kommentaren zu unserer Umfrage hagelte es weitere grundsätzliche Kritik an Netflix. So findet Hubert F.: "Netflix hat an Qualität und Bandbreite des Angebots verloren und verliert deshalb die Kunden." Einige forderten Netflix zu Kooperationen mit anderen Diensten auf. Manfred K. findet, dass es Zeit ist für einen Allrounder-Streaming-Dienst.
Frank H. hat stattdessen konkrete Vorschläge, wie Netflix der Konkurrenz enteilen könnte: "Netflix sollte vielleicht mehr in die Kooperationen mit den Filmgesellschaften investieren, sodass diese kaum einen Sinn darin sehen, selbst einen eigenen Streaming-Dienst zu erstellen." Das klingt nach einem interessanten Ansatz, die Konkurrenz in Schach zu halten. Am Ende würden davon auch die Abonnenten der Streamingdienste profitieren.
URL dieses Artikels:https://www.heise.de/-7347558
Links in diesem Artikel:[1] https://www.heise.de/select/ct/2022/24/2228607501257193933[2] mailto:uk@ct.de
Copyright © 2022 Heise Medien