Moderne Mikrocontroller-Boards müssen eine ganze Menge von Schnittstellen integrieren wie UARTs, IIS, IIC, SPI. Was aber, wenn eine benötigte Schnittstelle fehlt, etwa 1-Wire oder CAN? Für solche Fälle bietet der Raspberry Pi Pico die PIO (Programmable Input Output). Der vorliegende Blog-Post gliedert sich in zwei Teile: Im ersten ist die Funktionsweise einer PIO Gegenstand der Betrachtung, während der zweite Teil untersucht, wie sich PIOs in der Praxis nutzen lassen.
Auf einem Raspberry Pi Pico finden sich keine Komponenten für Bluetooth oder WiFi. Nicht nur deshalb wäre ein Vergleich mit Mikrocontrollern auf Basis von ESP8266 beziehungsweise ESP32 ein Vergleich von Äpfel und Birnen. Eher entspricht der Pico mit seinen Anwendungsmöglichkeiten leistungsfähigen Arduino-Boards.
Was den Pico aber gegenüber anderen Boards auszeichnet, ist seine Möglichkeit, I/O-Pins programmatisch über eine eigene Hardwarekomponente des RP2040-Chips namens PIO (Programmable I/O) zu steuern. Jeder der zwei vorhandenen PIO-Blöcke enthält zu diesem Zweck vier Zustandsmaschinen, auf denen in PIO-Assembler geschriebene Programme ablaufen. Assemblerprogrammierung mag bei manchem ungute Assoziationen wecken. Allerdings bestehen PIO-Programme beim Pico aus lediglich neun relativ einfachen Befehlen.
Vorteil des PIO-Konzepts ist die sich daraus ergebende große Flexibilität und Anwendungsvielfalt. Unter anderem haben Maker damit schon VGA-Bildschirme, WS2812b-LEDs und Schrittmotoren angesteuert oder HW-Schnittstellen wie UART realisiert. Natürlich sind diese Beispiele grundsätzlich auch über ein rein in Software gegossenes Bit-Banging umsetzbar, was aber in der Praxis mit vielen Problemen verbunden ist, etwa bezüglich genauem Timing und Wartbarkeit, sowie der hohen Belastung der Rechnerkerne.
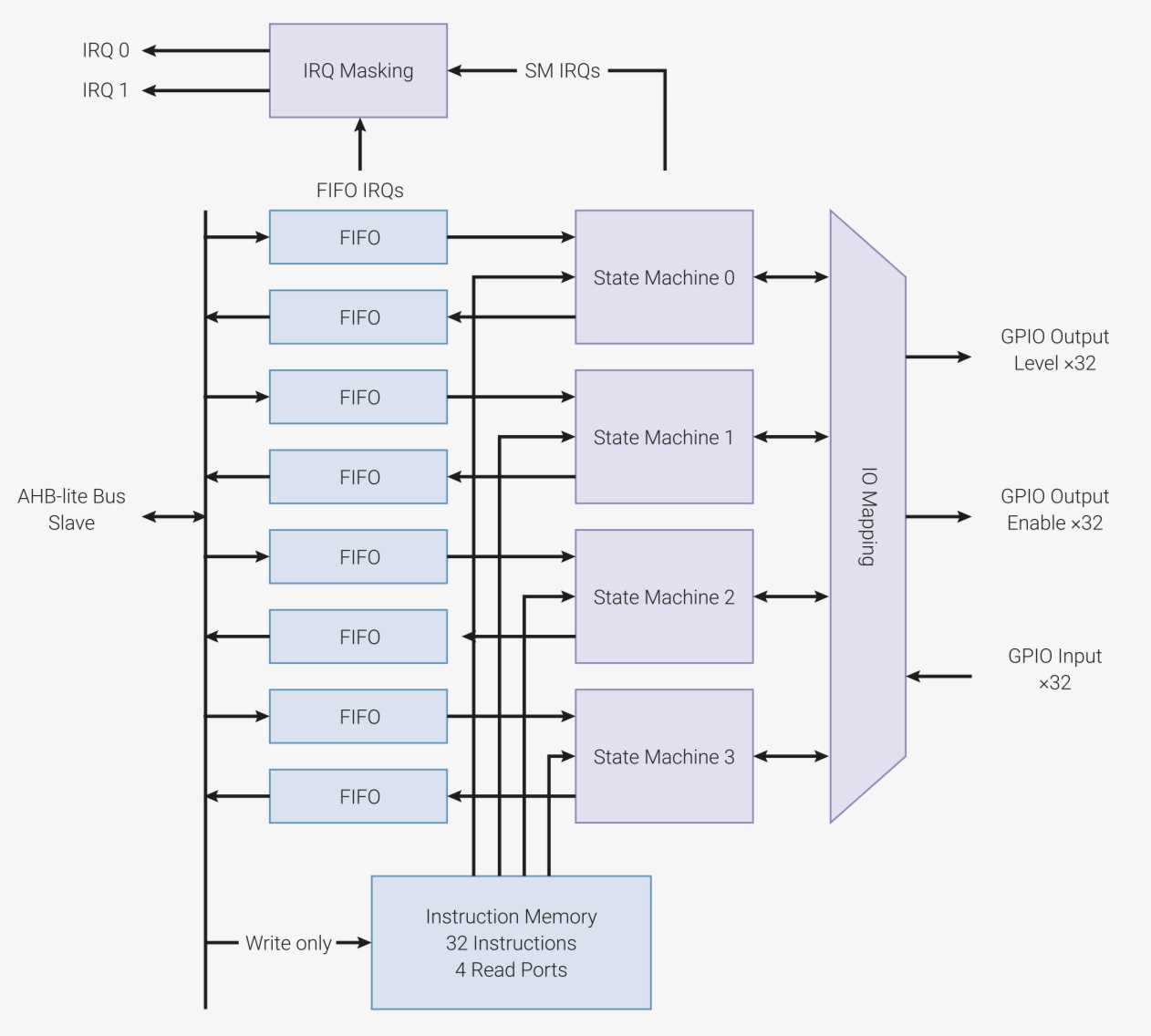
Ein Raspberry Pi Pico enthält zwei PIO-Blöcke (pio0 und pio1) mit je vier Zustandsmaschinen, die sich einen Speicher von 32 Instruktionen teilen. Instruktionen haben eine Länge von 16 Bit. Für jedes Programm auf einer Zustandsmaschine definieren Entwickler ein I/O-Mapping, das alle GPIO-Pins umfasst, die das Programm nutzen möchte. Ein Mapping legt ein Fenster fest, das aus einem GPIO-Start-Pin und der Zahl der im Mapping eingeschlossenen GPIOs besteht. Eigentlich bietet der Raspberry Pi Pico nur 30 GPIOs, aber das Mapping-Register hat zwei virtuelle GPIOs hinzugefügt (GPIO30 und GPIO31). Kein Wunder, besteht das Mapping-Register doch aus 32 Bits. Beispiels-Mappings sind etwa [GPIO4, GPIO5, GPIO6] oder [GPIO 28, GPIO29, GPIO30, GPIO31, GPIO0, GPIO1]. Insofern repräsentieren sie Fenster auf einen Bereich aufeinanderfolgender GPIOs. Wie im zweiten Beispiel zu sehen ist, folgt auf GPIO31 zyklisch wieder GPIO0. Die im Mapping enthaltenen Pins können sowohl zur Eingabe als auch zur Ausgabe dienen. Genau genommen sind es sogar vier Mappings:

Das Basis-GPIO jedes Mappings zählt aus Sicht der Zustandsmaschine als Pin 0, die darauffolgenden Pins sind dementsprechend Pin 1, Pin 2, Pin 3, usw. Die vier Mappings dürfen sich sogar überlappen. Es gibt in dieser Hinsicht keinerlei Einschränkungen.
Die Namen der Mappings (in, out, set, side-set) beziehen sich auf die gleichnamigen Kommandos für Einlesen, Auslesen, Setzen von GPIO-Pins, von denen später noch die Rede sein soll.
Zur Kommunikation mit der Außenwelt bieten sich einer PIO-Zustandsmaschine neben I/O zwei Möglichkeiten:
Da sich alle Zustandsmaschinen eines PIO-Blocks einen gemeinsamen Programmspeicher teilen, können mehrere Zustandsmaschinen dasselbe Programm ausführen.
Beispiel: Jede Zustandsmaschine bedient einen separaten LED-Strip.
Oder sie nehmen unterschiedliche Aufgaben für dieselbe Schnittstelle wahr.
Beispiel: Eine Zustandsmaschine implementiert den RX-Teil (Empfangen von Daten) eines UART, während sich eine andere Zustandsmaschine um die TX-Komponente (Senden von Daten) kümmert.
Sie können natürlich auch unterschiedliche Programme ausführen, um verschiedene Arten von I/O-Schnittstellen parallel zu implementieren.
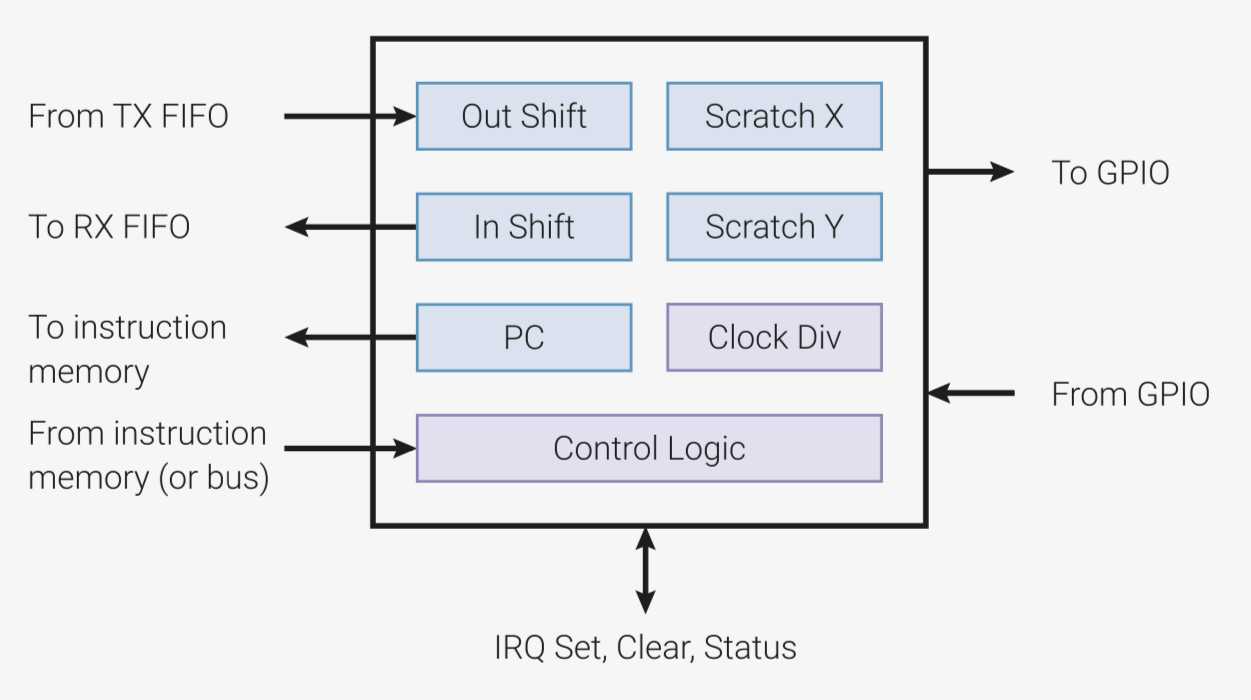
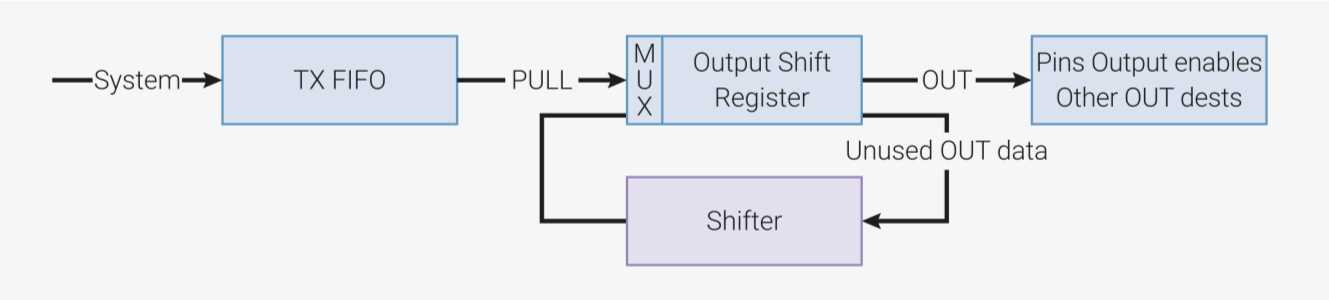
Eine Zustandsmaschine enthält eine Warteschlange TX-FIFO mit einer Kapazität von vier 32-Bit-Worten, die dem Entgegennehmen von Daten aus der CPU dient. Diese Daten holt sie sich über einen Pull-Befehl in das sogenannte OSR (Output-Shift-Register). Durch Links- oder Rechts-Schiebe-Operationen auf dem OSR lassen sich ein oder mehrere Bits zwecks Ausgabe an die GPIOs senden. Insofern stellt das OSR sowohl die Schnittstelle zwischen Zustandsmaschine und Ausgabe-GPIOs als auch die zwischen Zustandsmaschine und CPU-Cores dar. Durch Pull kann ein PIO-Programm Daten von der CPU über die TX-FIFO lesen.
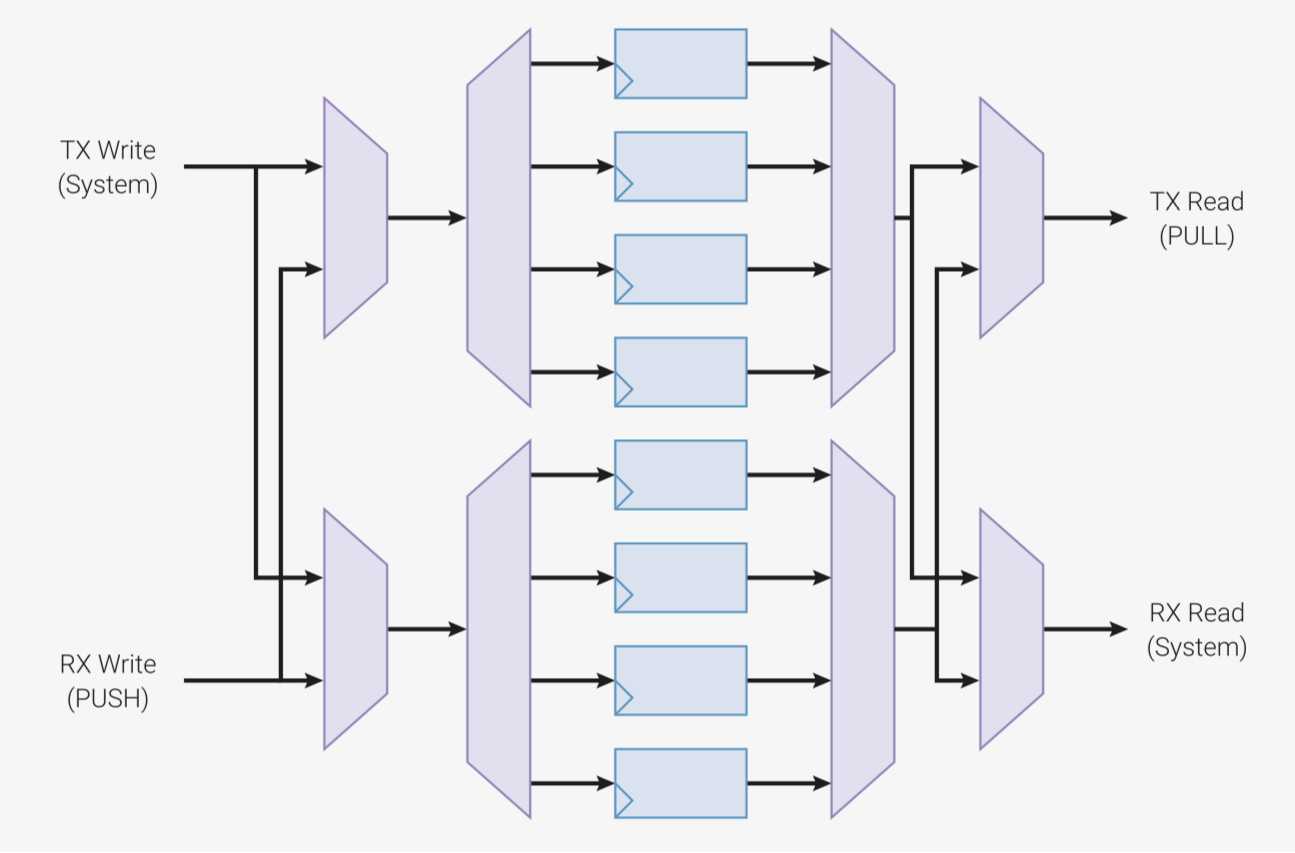
Es gibt eine weitere Warteschlange namens RX-FIFO, die ebenfalls eine Kommunikation mit der Außenwelt implementiert. Die RX-FIFO-Warteschlange umfasst vier Slots mit 32-Bit-Worten. Ihre Daten enthält sie im Normalfall vom Input-Shift-Register, dem ISR, das dem Einlesen von digitalen Pins dient. Somit bildet das ISR die Schnittstelle zwischen GPIO-Pins und der RX-FIFO. Werte der Eingabe-Pins lassen sich bitweise ins ISR übermitteln, das dazu mit (Left- oder Right-)Shift-Operationen arbeitet. Der push-Befehl überträgt den Inhalt des ISR an die RX-FIFO, von wo sie ein Hauptprogramm in der CPU / MCU übernimmt.

Die beiden FIFOs können Entwickler auch zu einer einzelnen Eingabe-Queue (RX-FIFO) oder zu einer einzigen Ausgabe-Queue (TX-FIFO) mit je acht 32-Bit-Worten kombinieren, das sogenannte FIFO-Join.
Ein Pull-Befehl auf der TX-FIFO blockiert, solange dort keine Daten vorliegen.
Ein Push-Befehl blockiert, solange die RX-FIFO voll ist, weil keine Daten von der CPU abgeholt wurden.
Des Weiteren besteht die Möglichkeit, für eine Zustandsmaschine Parameter wie AUTOPUSH oder AUTOPULL mit entsprechenden Schwellwerten zu definieren, die automatisiert push- und pull-Operationen beim Einreichen dieser Schwellwerte ausführen.
Eine weitere Möglichkeit soll nicht unerwähnt bleiben. Ein Raspberry Pi Pico enthält einen DMA-Controller, der ohne Belastung der Rechnerkerne schnelle Speichertransfers durchführen kann, ein 32-Bit-Wort pro Maschinenzyklus. Diese Daten können als Ziel auch eine Zustandsmaschine haben. Beispielanwendung: Die Zustandsmaschine implementiert eine VGA-Schnittstelle, und enthält die Grafikdaten über DMA. Würde dieser Transfer über die CPU erfolgen, wäre er zum einen langsamer und würde zum anderen die CPU belasten.
Neben den Registern ISR und OSR existieren noch zwei allgemein nutzbare Register X und Y, die sogenannten Scratch-Register.
Ein ungenutztes ISR oder OSR können Programme nach eigenem Gusto ebenfalls als Register einsetzen.
Zusätzlich gibt es einen PC (Program Counter), der auf den nächsten auszuführenden Befehl im gemeinsamen Befehlsspeicher verweist. Dieser ist sogar programmatisch nutzbar, wie weiter unten erläutert.
Programme auf der Zustandsmaschine können aus lediglich 9 Befehlen auswählen, die dafür einige Flexibilität erlauben. Wichtig zu wissen: Die Abarbeitung eines Befehls benötigt stets einen Maschinenzyklus, dessen Zeitdauer sich aus 1 geteilt durch 133.000.000 Hz berechnet. Das ergibt eine Zykluszeit von ungefähr 7,5 Nanosekunden. Wie wir später kennenlernen, lässt sich die Geschwindigkeit der PIO-Blöcke auch auf kleinere Frequenzen beziehungsweise höhere Zykluszeiten einstellen.

In den nachfolgenden Abschnitten folgt nun die komplette Liste der Instruktionen.

kopiert den Inhalt des ISR (Input-Shift-Register) in die RX-FIFO und löscht danach den Inhalt des ISR. Bei Angabe von iffull geschieht dies ausschließlich dann, wenn das ISR eine konfigurierbare Zahl von Bits enthält. Ist der Befehl mit der Option block versehen, wartet die Zustandsmaschine so lange bis die RX-FIFO Platz für die Daten aus dem ISR vorweist. Hingegen würde bei Angabe von noblock die Zustandsmaschine zum nächsten Befehl springen, sofern das RX-FIFO belegt sein sollte, aber gleichzeitig den Inhalt des ISR löschen. PUSH ohne Argumente ist übrigens gleichbedeutend mit PUSH block.

überträgt den Inhalt der TX-FIFO in das OSR (Output-Shift-Register). Eine Angabe von ifempty bewirkt, dass dieser Befehl nur durchgeführt wird, wenn das OSR keinen Inhalt aufweist - es ist folglich leer. Bei Angabe von block wartet die Zustandsmaschine solange blockierend bis Daten in der TX-FIFO vorliegen. Bei noblock springt die Zustandsmaschine unverrichteter Dinge zum nächsten Befehl, sollte die TX-FIFO leer sein. PULL ohne Argumente ist gleichbedeutend mit PULL block. C- oder Python-Programme können über die TX-FIFO direkt Instruktionen an die Zustandsmaschine senden.
Ebenso besteht die Option, direkt Instruktionen in das INSTRUCTION-Register der Zustandsmaschine zu schreiben, worauf sie die Instruktion ausführt. Danach setzt sie mit dem nächsten vom PC (Program Counter) adressierten Befehl fort. Achtung: Solche Instruktionen können auch gezielt den PC ändern. Wie das programmatisch aussieht, folgt weiter unten.

dient, nomen est omen, für bedingte und unbedingte Sprünge an eine Zieladresse. Das Sprungziel kann eine physikalische Adresse von 0 bis 31 sein, oder ein logisches Sprungziel, also ein Label, das der Assembler durch die Physikalische Adresse ersetzt. Die Bedingung ist optional, weshalb etwa
jmp ende
einen sofortigen Sprung zum Label „ende“ bewirkt.
Der Sprung kann auch abhängig von einer Bedingung erfolgen:
!X bzw. !Y => Sprung erfolgt, falls der Inhalt des X- bzw. Y-Registers gleich 0 ist.
X-- bzw. Y-- => Sprung erfolgt, sofern X beziehungsweise Y ungleich 0 ist. Mit dem Sprung wird gleichzeitig X bzw. Y dekrementiert.
X!=Y => Sprung erfolgt, wenn X und Y unterschiedliche Werte aufweisen.
PIN => Sprung erfolgt, falls Pin auf HIGH.
!OSRE => Sprung erfolgt, falls das OSR (Output-Shift-Register) nicht leer ist. Somit steht OSRE für Output-Shift-Register Empty.

bewirkt das Kopieren von 1-32 Bits aus einer Quelle in das Input-Shift-Register. Die Quelle kann sein:
ISR
OSR
PINS ————- PINS verwendet dabei das In-GPIO-Mapping.
X
Y
NULL

kopiert die definierte Zahl an Bits vom OSR zum Ziel, wobei das Ziel sein kann:
PINS —- GPIO-Pins gemäß dem Out-Mapping
X
Y
ISR
NULL
PINDIRS —- Durch Angabe von PINDIRS als Ziel lässt sich für die Pins des Out-Mappings festlegen, ob sie als Ausgabe-Pin dienen sollen (1) oder als Eingabe-Pin (0).
Mit
out pindirs, 3
würden somit die ersten 3 Pins des Mappings entweder als Ausgabe-oder Eingabe-GPIOs je nach Belegung der entsprechenden Bits im OSR festgelegt. Auch der Program Counter PC lässt sich mit OUT verändern.
Ein
out pc, 5
führt dazu, dass der Programmzähler auf den in den entsprechenden 5 Bits des OSR gespeicherten Werts eingestellt wird. Wie erwähnt: Der Programmspeicher besteht aus 32 16-Bit-Worten, weshalb zur Adressierung 5 Bits ausreichen.
Bei
out exec, 16
interpretiert die Zustandsmaschine 16 Bits des OSRs als Kommando und führt dieses aus. Der Wert wird im Instruktionsregister abgelegt.

kopiert den Wert (0..31) in das Ziel. Ziel kann sein:
PINS, also die im set-Mapping angegebenen GPIO-Pins. Es werden somit die entsprechenden Bits über die bis zu fünf Pins des set-Mappings ausgegeben.
PINDIRS set pindirs, 3 legt beispielsweise die ersten 2 Pins des set-Mappings als Ausgabe-Pins fest.
X Auch die Scratch-Register x und y können als Ziel auftauchen
Y

bewegt, wenig überraschend, den Inhalt der Quelle zum Ziel. Ziele können sein:
PINS gemäß out-Mapping EXEC ISR OSR PC X YQuellen können sein:
PINSXYISROSRNULLSTATUS Bislang blieb die Quelle STATUS unerwähnt. Sie lässt sich gemäß Anforderungen des Entwicklers konfigurieren, etwa als „TX-FIFO leer“ oder „TX-FIFO voll“.
Übrigens: Stellen Programmierer der Quelle ein ! oder ~ voran, kopiert MOV den invertierten Wert der Quelle. Beim Voranstellen von :: kopiert MOV die Bits der Quelle in umgekehrter Reihenfolge.

dient zum Auslösen eines der acht möglichen Interrupts 0 bis 7. Dadurch synchronisieren sich Zustandsmaschinen untereinander (siehe WAIT-Kommando) oder mit der CPU. Mit dem optionalen _rel sind IRQs abhängig von der Zustandsmaschine nutzbar.
Dabei erfolgt folgende Operation: ((0b11 & Nummer-des-IRQ) + Nummer-der Zustandsmachinen) mod 4. Die logische And-Operation extrahiert also die letzten 2 Bits der IRQ-Nummer.
Beispiel: Für IRQ 6 (= binär 0b110) und Zustandsmachine 2 (0b10) ergibt sich 4 % 4 = 0.
Mögliche Optionen:
set nowait IRQnr => das IRQ Flag ohne Prüfung setzen ohne zu warten.
set wait IRQnr => das Flag erst dann setzen, nachdem es woanders auf 0 gesetzt wurde. Das ist ein Mechanismus, um sich mit anderen Zustandsmaschinen zu synchronisieren.
set IRQnr clear => Flag löschen ohne zu warten.

WAIT Polarität GPIO Nummer
wartet bis das GPIO mit der angegebenen Nummer den in Polarität angebenen Wert (0 oder 1) erreicht. Mit Nummer ist die tatsächliche GPIO-Nummer auf dem Pico gemeint.
WAIT Polarität PIN Nummer
verhält sich wie obere Variante, nutzt aber das in-Mapping für die Nummerierung der Pins.
WAIT Polarität IRQ Nummer (_rel)
wartet auf das Setzen eines Interrupts von außen. Achtung! Polarität verhält sich hier anders als bei der ersten Variante: Ist Polarität = 1, löscht der Befehl das IRQ-Flag, sobald es gesetzt wurde. Ist Polarität = 0, bleibt das Flag hingegen unverändert. Das optionale _rel verhält sich wie bei der IRQ-Instruktion.
Teilweise ist in PIOASM-Programmen, etwa in MicroPython oder in C, auch der Befehl NOP zu sehen. Diese Instruktion gibt es nicht wirklich. Stattdessen ersetzt der Assembler diese Pseudoinstruktion durch
mov y,y
Wer I/O-Schnittstellen programmiert, ist sich im allgemeinen darüber bewusst, dass Timing-Probleme zu den häufigsten Herausforderungen zählen. Zum Beispiel sind für LEDs des Typs WS2812b genau getaktete Signal-Flanken notwendig, die sich über eine genau festgelegte Anzahl von Zyklen erstrecken. Zustandsmaschinen offerieren dafür Delays gemessen in Maschinenzyklen, die neben Befehlen in eckigen Klammern stehen, etwa:
set pins, 1 [4]
set pins, 0
Hier wird am ersten im set-Mapping definierten GPIO-Pin ein HIGH-Signal ausgegeben. Dieser Befehl benötigt einen Maschinenzyklus. Die Anweisung [4] rechts daneben veranlasst die Zustandsmaschine, weitere 4 Maschinenzyklen dranzuhängen, wodurch das HIGH-Signal für 5 Maschinenzyklen anliegt, bevor der nächste set-Befehl das GPIO-Pin wieder auf LOW setzt. Da für Delays 5 Bits vorhanden sind, lassen sich zu jeder Instruktion maximal 31 Wartezyklen hinzufügen.
Allerdings nützen Delays alleine nichts, würde die Zustandsmaschine stets mit der vollen Pico-Freqenz von 133 MHz laufen. Zum Glück können Entwickler die Frequenz konfigurieren, indem sie einen 16-Bit Teiler definieren, den Clock Divider.
Die minimal mögliche Taktfrequenz einer Zustandsmaschine liegt daher bei etwa 2029 Hz = 133.000.000 Hz / 65536. Daraus ergibt sich eine maximale Dauer des Zustandsmaschinenzyklus von 0,492 Millisekunden. Es lassen sich zwar niedrigere Frequenzen konfigurieren, die aber zu Instabilität führen beziehungsweise nicht funktionieren. Benötigt der Entwickler längere Zykluszeiten, kann er sie zusätzlich mit Delays kombinieren.
Wer sich gefragt hat, was es denn mit dem side-set-I/O-Mapping auf sich hat, erhält nun die Antwort: Wie gesagt, definiert das Mapping bis zu 5 aufeinanderfolgende GPIO-Pins. Mit dem side-set haben Entwickler die Möglichkeit parallel zu einer Instruktionsausführung bis zu 5 Pins auf HIGH oder LOW zu setzen.
Das sieht im Assemblercode folgendermaßen aus:
set pins, 1 side 0; Side-set erfolgt auch, wenn die Instruktion hängt
Es wird das erste Bit des OSR am GPIO-Pin ausgegeben (gemäß out-Mapping) und danach fünf Wartezyklen eingelegt. Parallel gibt die Zustandsmaschine 0 an allen im side-set-Mapping definierten GPIO-Pins aus. Ein „side 1“ würde an den entsprechenden GPIO-Pins 1 ausgeben.
Im PIO-Programm muss der Entwickler dafür spezifizieren:
.side_set 1
Mittels der Variante
.side_set 1 pindirs
lassen sich die side-Anweisungen alternativ dafür nutzen, um keine Ausgaben an den „side-Pins“ vorzunehmen sondern stattdessen deren Richtung festzulegen. Ein side 0 definiert in der Folge die entsprechenden Pins als Eingabe-Pins, während side 1 sie zu Ausgabe-Pins macht.
Das Einsetzen von side_set hat aber einen Preis, weil die Anweisung dafür 1 Bit vom möglichen Delay stiehlt. Dadurch bleiben nur 4 Bits für Delays übrig, was Werten von 0, 1, 2, ... ,15 entspricht. Zudem ist bei jeder Instruktion verpflichtend ein side 0 oder side 1 anzugeben.
Wer side-Befehle benötigt, aber sie nur bei einzelnen Instruktionen, also optional verwenden möchte, gibt im PIO-Assemblerprogramm .side_set 1 opt an, was aber ein weiteres Bit des Delays kostet, sodass nur noch Delays von 0 bis 7 möglich sind.
Ein PIO-Programm, das ein Blinken der eingebauten LED erzeugt, das richtige set-Mapping vorausgesetzt, könnte wie folgt aussehen:
.program blinker
; eventuell weitere Instruktionen
start:
set pins, 1 ; LED ein
set pins, 0 ; LED aus
jmp start ; Let‘s do it again
Da die meisten PIO-Programme mit einer unendlichen Schleife arbeiten, erweist sich der jmp-Befehl am Ende des Programms als notwendig. Diese Instruktion reduziert gleichzeitig die mögliche Zahl nutzbarer Anweisungen in einem PIO-Block um 1. Noch dazu ist das Programm „asymmetrisch“, da die Ausgabe von 1 einen Maschinenzyklus dauert, während die Ausgabe von 0 wegen jmp sich über zwei Maschinenzyklen erstreckt.
Abhilfe könnte natürlich ein Delay schaffen:
.program blinker
; eventuell weitere Instruktionen
start:
set pins, 1 [1] ; LED ein und einen Zyklus dranhängen
set pins, 0 ; LED aus
jmp start ; Let‘s do it again
Jetzt dauern sowohl die Erleuchtung als auch die Verdunklung gleich lang, nämlich zwei Maschinenzyklen.
Da die Endlosschleife einen verbreiteten Anwendungsfall darstellt, haben die Entwickler der PIO hierfür Abhilfe geschaffen:
.program blinker
; eventuell weitere Instruktionen
.wrap_target
set pins, 1 ; LED ein und einen Zyklus dranhängen
set pins, 0 ; LED aus
.wrap ; Let‘s do it again
Mittels .wrap legt der Entwickler einen Sprung fest, der an der mit .wrap_target markierten Stelle landet. Vorteil: Diese Anweisungen beziehungsweise Attribute benötigen keinen eigenen Befehl, sodass die Zahl der benötigten Anweisungen sich um 1 reduziert. Im obigen Beispiel liegt somit für einen Maschinenzyklus 1 und für einen Maschinenzyklus 0 an. Die LED blinkt regelmäßig.
MicroPython macht es Entwicklern leicht, mit den Möglichkeiten der PIO zu experimentieren. Programme für die Zustandsmaschine sind nicht (notwendig) in PIO-Assembler notiert, sondern verwenden Python-Wrapper. Das nachfolgende Beispielprogramm illustriert die Nutzung einer PIO-Zustandsmaschine. Das set-Mapping definiert GPIO25 als Ausgabe-Pin - es handelt sich um die eingebaute LED. Mit set(pins, 1) schaltet sich die LED ein, mit set(pins, 0) wieder aus. Mittels der Pseudoinstruktion nop()[31] legt das Programm 31 Wartezyklen ein (Delays).
# set-Mapping als Ausgabe-Pins
@rp2.asm_pio(set_init=rp2.PIO.OUT_LOW)def blink():
wrap_target()
set(pins, 1) [31] # LED an
nop() [31] # Viele Delays
nop() [31]
nop() [31]
nop() [31]
set(pins, 0) [31] # LED aus
nop() [31] # Viele Delays
nop() [31]
nop() [31]
nop() [31]
wrap()# Zustandsmaschine 0, PIO-Programm = blink, Frequenz = 2029,
# set-Mapping mit 1 Pin: GPIO25 => eingebaute LED
sm = StateMachine(0, blink, freq=2029, set_base=Pin(25))sm.active(1) # Zustandsmaschine starten
time.sleep_ms(3000) # 3 Sekunden warten
sm.exec('set(pins, 0)') # LED durch Senden einer PIO-Instruktion auf 0 setzen
sm.active(0) # Zustandsmaschine stoppen
Interessant ist der Aufruf von sm.exec(), mit dem sich eine Instruktion direkt an die Zustandsmaschine übertragen lässt. Im vorliegenden Fall schaltet die Instruktion die LED wieder aus, bevor das Hauptprogramm die Zustandsmaschine deaktiviert.
Um das Thema PIO praktisch durchzuspielen, bieten sich vor allem Beispiele an, die weder zu trivial noch zu komplex sind. Eine mögliche Option besteht aus dem Simulieren einer Verkehrsampel, wobei natürlich auch andere Signalanlagen in Frage kämen.
In Deutschland haben Ampelsteuerungen bekanntlich vier verschiedene Phasen:

Die Phasen Grün und Rot sind individuell konfigurierbar, etwa abhängig von Verkehrsaufkommen. Die Dauer der Gelbphasen (Gelb und Rot-Gelb) ergibt sich aus der am Aufstellungsort erlaubten Höchstgeschwindigkeit.
Gesucht: ein Pico-Programm, das diese Steuerung implementiert. Die Implementierung erfolgt über C beziehungsweise C++ und PIO-Assemblerinstruktionen. Mögliche Variante: Statt C beziehungsweise C++ ließe sich auch MicroPython verwenden.
Es soll möglich sein, die Rot- beziehungsweise Grünphase von außerhalb des PIO zu konfigurieren.
Die verschiedenen Leuchten der Ampel ersetzt die sehr einfache Beispielschaltung durch LEDs mit Anschluss an GPIO-Pins des Pico. Diese Schaltung lässt sich später erweitern, etwa durch einen Schalter, der die Ampel außer Betrieb nimmt oder wieder aktiviert. Auf einem Pico stehen zwei PIO-Blocks mit je 4 Zustandsmaschinen zur Verfügung, sodass ebenfalls eine Schaltung mehrerer Ampeln möglich wäre.
Insgesamt ist die Schaltung also sehr einfach. Die LEDs sind an GPIO17 (weisse LED oder andere Empfänger), GPIO18 (rote LED), GPIO19 (gelbe LED), und GPIO20 (grüne LED) über jeweils einen 220 Ohm Widerstand und an GND angeschlossen.
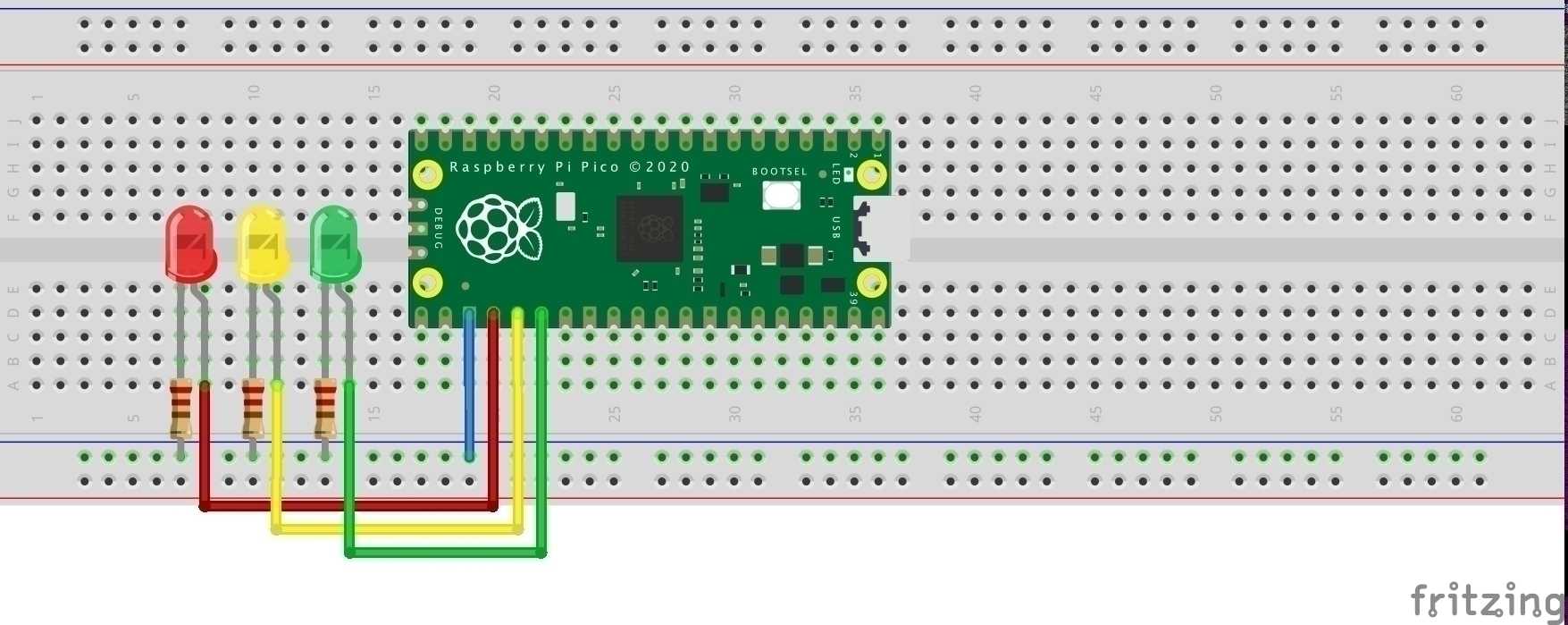
Gleich vorab: Den Code für dieses Beispiel finden Sie auf GitHub [1].
Die eigentliche Steuerungsaufgabe für die vier Ampelphasen übernimmt ein PIO-Programm, dem das Hauptprogramm zu Beginn die Länge der Rot- beziehungsweise Grünphase sowie ein Bit-Pattern übergibt. Die zwei Gelbphasen (Gelb, Rot-Gelb) dauern jeweils wenige Sekunden. Da die LEDs in der Reihenfolge Rot, Gelb, Grün angeschlossen sind, ergeben sich folgende Patterns. Das Bit für die frei verwendbare Ausgabe an GPI017 fehlt in folgenden Bit-Sequenzen:
Phase 1 (Rot) lässt sich durch eine Bitsequenz wie 1-0-0 repräsentieren (rote LED an, gelbe LED aus, grüne LED aus).
Phase 2 (Rot-Gelb) entspricht dann der Bitsequenz 1-1-0.
Phase 3 (Grün) lautet 0-0-1.
Phase 4 (Gelb) entspricht 0-1-0.
Die GPIO-Pins fungieren im PIO-Programm demzufolge als Ausgabe-GPIOs. Damit dies funktioniert, benötigen wir für das entsprechende I/O-Mapping, konkret für das Output-Mapping, benachbarte GPIOs. In dem Mapping sind GPIO-Pins 17, 18 (rot), 19 (gelb), 20 (grün) im Einsatz, wobei GPIO17 mit jeder Rot-Phase ein HIGH-Signal ausgibt. Das könnte man zur Ansteuerung einer weiteren LED benutzen oder für andere Zwecke. Die Bit-Sequenzen von jeweils 4 Bits legt die sm (state machine) per out-Kommando an die LEDs. Für einen vollständigen Durchlauf aller vier Phasen sind somit 16 Bit notwendig. Da die TX-FIFO mit 32 Bit arbeitet, übergeben wir das um einen kompletten Ampelzyklus verdoppelte Pattern als 32-Bit-Wort an das OSR (Output-Shift-Register). Bis das OSR leer ist, vergehen demzufolge zwei vollständige Iterationen durch alle vier Ampelphasen. Da der Entwickler das Pattern nach Belieben definieren kann, lässt sich die Signalisierung am GPIO17 beliebig einstellen, etwa HIGH-Signal in jeder Rot-Phase oder High Signal zu Beginn aller Phasen.
Das Pattern erthält das Programm vom C-Hauptprogramm, das zuvor die Zeit für die Rot- und Grünphase an die Zustandsmaschine übergibt:
pull ; Zeit aus der TX-Queue ins OSR holen
mov x,osr ; und ins Register x
mov isr,x ; sowie ins ungenutzte ISR
; kopieren
pull ; Pattern von CPU-Core aus
; der TX-Queue ins OSR holen
mov y,osr ; und zusätzlich in y speichern
Weil das Programm nach je zwei Ampelzyklen das OSR (Output-Shift-Register) komplett leer geräumt hat, ist das Pattern auch in y abgelegt, um es erneut ins OSR laden zu können:
jmp !OSRE cont ; OSR != EMPTY
; => weiter zu cont
mov osr,y ; Sonst: OSR neu laden
cont:
....
Ebenfalls wird das im Programm unbenutzte ISR (Input-Shift-Register) als Backup für die Zahl der Zeitschleifen benutzt:
mov x,isr ; ISR enthält Schleifenzahl für x
...
lgreen:
nop [31]
jmp x-- lgreen [31] ; hier wird x in jeder
; Schleife dekrementiert
Das PIO-Assembler-Programm schiebt das OSR immer um 4 Bit nach rechts, um mit den Bits die 4 Ausgabe-Pins anzusteuern:
out pins, 4 ; Schiebe 4 Bits aus dem OSR
; nach rechts zu den LEDs bzw. GPIOs
So entstehen nacheinander und zyklisch die vier Ampelphasen (rot, rotgelb, grün, gelb).
.program trafficlight
pull ; Zeit von CPU-Core holen
mov x,osr ; und in x speichern
mov isr,x ; sowie im ungenutzten ISR
pull ; Pattern von CPU-Core holen
mov y,osr ; und in y speichern
.wrap_target
jmp !OSRE cont; OSR != EMPTY => weiter bei cont
mov osr,y ; Sonst: OSR leer => neu aufladen
cont:
; ROT-PHASE
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lred:
nop [31]
jmp x-- lred [31]
; ROT-GELB-PHASE
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lredyellow:
nop [10]
jmp x-- lredyellow [10]
; GRÜN-PHASE
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lgreen:
nop [31]
jmp x-- lgreen [31]
; GELB-PHASE
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lyellow:
nop [10]
jmp x-- lyellow [10]
.wrap% c-sdk {
// Hilfsfunktion, um die Zustandsmaschine zu konfigurieren
void trafficlight_program_init(PIO pio, uint sm, uint offset,
uint pin, uint pincount, uint freq) {for (uint i = 0; i < pincount; i++) {
pio_gpio_init(pio, (pin+i) % 32); // initialisieren aller Pins
}// pins als Ausgabe-Pins (true) festlegen
pio_sm_set_consecutive_pindirs(pio, sm, pin, pincount, true);// Default Configuration holen
pio_sm_config c = trafficlight_program_get_default_config(offset);// Die vier Pins definieren das out-Mapping:
sm_config_set_out_pins(&c, pin, pincount);// div <= 65535 (= 2^16-1) - wird hier nicht geprüft
float div = (float)clock_get_hz(clk_sys) / freq;// Jetzt Clock Divider übergeben
sm_config_set_clkdiv(&c, div);// Wir kombinieren beide FIFOs zu einer TX_FIFO;
sm_config_set_fifo_join(&c, PIO_FIFO_JOIN_TX);// Rechts-Schieber, kein auto-pull, Schwellwert: 32 Bits
sm_config_set_out_shift(&c, true, false, 32);// Zustandsmaschine initialisieren
pio_sm_init(pio, sm, offset, &c);// und starten
pio_sm_set_enabled(pio, sm, true);
}
%}
Am Ende des Assemblercodes befindet sich die mit % c-sdk { beziehungsweise %} geklammerte C-Funktion void trafficlight_program_init(...), die der PIO-Assembler in die generierte xxxxpio.h-Datei übernimmt.
Diese Hilfsfunktion hat mehrere Aufgaben:
Zunächst teilt sie den einzelnen GPIOs über Aufrufe von pio_gpio_init()mit, dass sie unter Kontrolle der PIO stehen.
Die Anweisung
pio_sm_set_consecutive_pindirs()
legt fest, dass die hintereinander folgenden GPIO-Pins als Ausgabe-Pins fungieren.
Zur Konfiguration der Zustandsmaschine bedarf es einer entsprechenden Datenstruktur (offset ist die Anfangsadresse des Programmes):
pio_sm_config c = trafficlight_program_get_default_config(offset);
Nun erfolgt die Festlegung des out-Mappings:
sm_config_set_out_pins(&c, pin, pincount);
Die Zeitdauern für die verschiedenen Ampelphasen hängen von zwei Faktoren ab:
Der für die Zustandsmaschine gewählten Frequenz und den in Schleifen hinzugefügten Delays.
Die Frequenz einer Zustandsmaschine ist mittels des Clock Dividers beeinflussbar. Nimmt man mit 65535 das Maximum, liegt die Frequenz der Zustandsmaschine, wie bereits erwähnt, bei grob 2000 Hz (eigentlich 2029 Hz), was einer Zykluszeit von grob 0,5 Millisekunden entspricht. Mittels der Wahl der Delays in den PIO-Instruktionen und der von aussen übergebenen Verzögerungszeit können Entwickler die gewünschten Ampelphasen sehr gut annähern.
Um eine gewünschte Frequenz einzustellen, berechnet die Funktion einen Clock-Divider und konfiguriert damit die Zustandsmaschine:
float div = (float)clock_get_hz(clk_sys) / freq;
sm_config_set_clkdiv(&c, div);
Da das Programm die RX-FIFO nicht nutzt, verbinden wir sie mit der TX-Queue zu einer doppelt so großen TX-Queue, was eigentlich im Ampel-Beispiel nicht nötig ist, sondern lediglich zur Illustration dieser Möglichkeit dient:
sm_config_set_fifo_join(&c, PIO_FIFO_JOIN_TX);
Das OSR (Output-Shift-Register) schiebt die Bitmuster für die Ampelsignale nach rechts (erstes true), macht dies manuell statt automatisch (false) und hat einen Schwellwert von 32: Das heißt, nach geschobenen 32 Bits interpretiert die Zustandsmaschine das OSR als leer:
sm_config_set_out_shift(&c, true, false, 32);
Am Ende wird die Zustandsmaschine entsprechend der Konfiguration initialisiert:
pio_sm_init(pio, sm, offset, &c);
und scharf gestellt beziehungsweise gestartet:
pio_sm_set_enabled(pio, sm, true);
Nun folgt noch das in C geschriebene Hauptprogramm:
#include <stdio.h>
#include "pico/stdlib.h"
#include "hardware/pio.h"
#include "hardware/clocks.h"
#include "pio_trafficlight.pio.h"const uint freq = 2029; // Gewünschte Frequenz der Zustandsmaschine
const uint pin = 17; // Start-Pin
const uint pincount = 4; // Zahl der Ausgabe-Pins
// ==> RIGHT SHIFT ==>
// 2 x Ausgabe-Pattern für GPIOs
const uint32_t pattern = 0x48634863; // = 0100 1000 0110 0011 ...const uint32_t delay = 200; // initial Zeitdauer für Gelb-Phasen
int main() {
setup_default_uart();// Wir verwenden pio0
PIO pio = pio0;
// Programm zum Programmspeicher hinzufügen => offset
uint offset = pio_add_program(pio, &trafficlight_program);
printf("Programm geladen an Adresse %d\n", offset);
// Frei verfügbare Zustandsmaschine akquirieren
int sm = pio_claim_unused_sm(pio, true);
// Initialisieren und Konfigurieren der Zustandsmaschine
trafficlight_program_init(pio, sm, offset, pin, pincount, freq);
// Delay an TX-FIFO der Zustandsmaschine übergeben
pio_sm_put(pio, sm, delay);
// Bisschen warten
sleep_ms(500);
// Bitmuster zum LED-Schalten an Zustandsmaschine übergeben
pio_sm_put(pio, sm, pattern);
sleep_ms(1000000); // Lange laufen lassen
pio_sm_set_pins(pio, sm, 0); // Alle Pins auf Low
pio_sm_set_enabled(pio, sm, false); // Zustandsmaschine stoppen
}
Das Programm benutzt den Block pio0, fügt das PIO-Programm zu dessen Programmspeicher hinzu, um am Schluss eine freie Zustandsmaschine anzufordern:
PIO pio = pio0;
uint offset = pio_add_program(pio, &trafficlight_program);
int sm = pio_claim_unused_sm(pio, true);
Danach folgt der Aufruf der eben erwähnten Hilfsfunktion:
trafficlight_program_init(pio, sm, offset, pin, pincount, freq);
Erst sendet das Programm die gewünschte Zahl der Warteschleifen zur TX-Queue der Zustandsmaschine:
pio_sm_put(pio, sm, delay);
und danach das Bitmuster für die Ansteuerung der LEDs:
pio_sm_put(pio, sm, pattern);
Wichtig: Das Bit-Muster ist wegen der Right-Shifts zu den 4 GPIOs in 4er-Gruppen von rechts nach links zu lesen. Die 4er-Gruppen steuern jeweils mit dem LSBit GPIO17 (Kontrollausgabe zur beliebigen Verwendung), GPIO18 (Rot), GPIO19 (gelb) und mit dem MSBit GPIO20 (Grün). Das Muster 0x4863.... (= binär 0100 1000 0110 0011) bedeutet also die Abfolge:
Das Programm wartet nach den put()-Operationen für eine festgelegte Zeit von einer Million Millisekunden (etwa 16 Minuten), während die PIO die Ampel steuert:
sleep(1000000);
Nach dieser Wartezeit setzt es alle Ausgabe-Pins auf Low und deaktiviert die Zustandsmaschine wieder:
pio_sm_set_pins(pio, sm, 0);
pio_sm_set_enabled(pio, sm, false);
Mit Instruktionen sollten Entwickler gut haushalten, weil für alle vier Zustandsmaschinen eines PIO-Blocks nur insgesamt 32 Slots im gemeinsamen Programmspeicher verfügbar sind.
Wie also ließe sich das Programm optimieren? Im PIO-Teil der Ampelsteuerung durchläuft das Assemblerprogramm die vier Phasen einer Ampel. Eigentlich lässt sich das alles als zweimal zwei Phasen betrachten: je eine lange Phase (rot oder grün), gefolgt von einer kurzen Phase (gelb oder rot & gelb). Somit ist folgende gekürzte Version möglich:
.program trafficlight
pull ; Zeit von CPU-Core holen
mov x,osr ; und in x speichern
mov isr,x ; sowie im ungenutzten ISR
pull ; Pattern von CPU-Core holen
mov y,osr ; und in y speichern
.wrap_target
jmp !OSRE cont ; OSR != EMPTY => weiter bei cont
mov osr,y ; Sonst: OSR leer => neu aufladen
cont:
; ROT oder GRÜN
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lredgreen:
nop [31]
jmp x-- lredgreen [31]
; ROT-GELB oder Gelb
mov x,isr ; ISR enthält Schleifenzahl für x
out pins,4 ; 4 Bits aus OSR zur Ausgabe
lyellowred:
nop [10]
jmp x-- lyellowred [10]
.wrap
Nachteil:

Die Programmierbare Ein-/Ausgabe des Raspberry Pi Pico, kurz PIO, bietet einen echten Mehrwert für Entwickler. Natürlich ließen sich für den gleichen Zweck FPGAs nutzen, aber die sind teuer und benötigen wesentlich mehr Erfahrung in digitaler Schaltungstechnik. Gegenüber dem sonst üblichen Bit-Banging hat PIO den Vorteil, dass Zustandsmaschinen zeitlich genau arbeiten und nicht die beiden CPU-Kerne belasten. Sie offerieren einen kleinen, aber leistungsfähigen Satz von neun Instruktionen, erlauben dabei die Umsetzung auch komplexerer I/O-Schnittstellen, wofür sich im Internet bereits zahlreiche Beispiele finden. Das vorgestellte Beispiel ist bewusst einfach gehalten, sollte aber einen Einblick in die Möglichkeiten der PIO zeigen. Wie heißt es in der Werbung doch so schön: Entdecke die Möglichkeiten!
URL dieses Artikels:https://www.heise.de/-6018818
Links in diesem Artikel:[1] https://github.com/ms1963/RaspiPiPico-PIO-Trafficlight-Example[2] https://datasheets.raspberrypi.org/rp2040/rp2040-datasheet.pdf#page331[3] https://datasheets.raspberrypi.org/pico/raspberry-pi-pico-c-sdk.pdf#page29[4] https://datasheets.raspberrypi.org/pico/raspberry-pi-pico-python-sdk.pdf#page18
Copyright © 2021 Heise Medien
Das aktuelle MicroProfile 4.0 hat deutlich länger auf sich warten lassen als geplant. Grund hierfür waren vor allem politische Überlegungen. Aber es gab auch die eine oder andere interessante Änderung innerhalb der APIs.
Wie bereits im ersten Teil dieses Blog-Beitrags [1] berichtet, fand im Rahmen der Spezifikation des aktuellen MicroProfile 4.0 ein grundlegendes organisatorisches Alignment statt, das zu einer fast sechsmonatigen Verzögerung des ursprünglich geplanten Erscheinungsdatums geführt hatte.
Da die Mitglieder der einzelnen API-Spezifikationsgruppen für das vorliegende Release mit der konsequenten Migration der internen Abhängigkeiten weg von Java EE 8 hin zu Jakarta EE 8 beschäftigt waren, blieb in MicroProfile 4.0 kaum Zeit und Raum für bahnbrechende Neuerungen. Aber auch wenn sich die Änderungen innerhalb der einzelnen APIs in Grenzen halten, gibt es doch die eine oder andere interessante Neuerung.
Allein an fünf (von acht) der MicroProfile-spezifischen APIs fanden Änderungen statt, die mit der Abwärtskompatibilität brechen und daher einen genaueren Blick wert sind:
Mit der MicroProfile Config API können zur Laufzeit Konfigurationen aus externen Quellen herangezogen werden. Per Spezifikation muss eine MicroProfile-Config API-Implementierung mindestens die drei Quellen System Properties und Environment Variables und .properties-Datei unterstützen. Weitere externe Konfigurationsquellen, wie Datenbanken oder Cloud-basierte Key-Value-Stores, können durch Implementierung des Interfaces ConfigSource realisiert und eingebunden werden. Da die MicroProfile Config API von nahezu allen anderen MicroProfile APIs als Konfigurationsmechanismus genutzt wird, sind Änderungen an dieser API immer von besonderem Interesse.
Während in den bisherigen Versionen die Key-Value Paare der Konfigurationen jeweils einzeln aus einer der drei vorgegebenen Konfigurationsquellen beziehungsweise einer eigenen Implementierung des ConfigSource-Interfaces eingelesen werden mussten, erlaubt Version 2.0 der Config API zusätzlich einen komfortablen Bulk-Zugriff. Statt also mehrere Attribute einer Klasse mit @ConfigProperty annotieren zu müssen, reicht zukünftig die einmalige Annotation der Klasse mit @ConfigProperties, wie folgendes Beispiel aus der Config-2.0-Spezifikation [2] verdeutlicht.
Stellen wir uns einmal folgende Konfigurationsquelle vor, die unter anderem Detailinformationen zu einer Server-Konfiguration enthält:
...
server.host = localhost
server.port=9080
server.endpoint=query
server.old.location=London
...
Um die oben gezeigten Werte en bloc in eine Konfigurationsklasse einzulesen, muss diese lediglich mit @ConfigProperties annotiert und die Gruppe der einzulesenden Properties via Präfix – in diesem Fall "server" – angegeben werden:
@ConfigProperties(prefix="server")
@Dependent
public class ServerDetails {
// the value of the configuration property server.host
public String host;
// the value of the configuration property server.portpublic int port;
//the value of the configuration property server.endpoint
private String endpoint;
//the value of the configuration property server.old.location
public @ConfigProperty(name="old.location")
String location;public String getEndpoint() {
return endpoint;
}
}
Ebenfalls interessant ist die in Version 2.0 neu hinzugekommene Unterstützung von Property Expressions. Mit ihrer Hilfe ist es möglich, Konfigurationswerte innerhalb einer Konfigurationsquelle mittels Ausdrucks zu parametrisieren. Im folgenden Beispiel würde beim Einlesen der Ausdruck von server.url ausgewertet und durch den Wert von server.host ersetzt werden:
server.url=http://${server.host}/endpoint
server.host=example.org
Das Ergebnis der obigen Konfiguration wäre somit:
server.url=http://example.org/endpoint
Natürlich gelten für die Property Expressions dieselben Regeln, wie für alle anderen Konfigurationen auch. Die Konfigurationswerte können aus beliebigen Konfigurationsquellen stammen und bei Mehrfachvorkommen wird derjenige Wert herangezogen, dessen Konfigurationsquelle die höchste Ordinalität besitzt.
Neben einfachen Ausdrücken sind zusätzlich aneinandergehängte und verschachtelte Ausdrücke erlaubt. Und auch die Angabe von Default-Werten, für den Fall, dass ein Ausdruck nicht ausgewertet werden kann, ist möglich:
server.url=http://${server.host:example.org}:${server.port}/${server.endpoint}
server.port=8080
server.endpoint=${server.endpoint.path.${server.endpoint.path.bar}}
server.endpoint.path.foo=foo
server.endpoint.path.bar=foo
Im obigen Beispiel würde der Ausdruck server.host innerhalb der Konfiguration von server.url nicht aufgelöst werden können und daher durch den mittels ":" angegebenen Default-Wert example.org ersetzt werden. Der Ausdruck server.endpoint dagegen ergibt sich durch die verschachtelte Auswertung von server.endpoint.path.${server.endpoint.path.bar}, was wiederum dem Ausdruck server.endpoint.path.foo entspricht.
http://example.org:8080/foo
Was aber passiert, wenn einer der Ausdrücke nicht ausgewertet werden kann, gleichzeitig aber auch kein Default-Wert angegeben wurde? In dem Fall wird beim Einlesen des Ausdrucks eine NoSuchElementException geworfen beziehungsweise im Falle eines Optional Attribute ein leeres Optional zurückgegeben.
Weitere Details zu den Neuerungen und Änderungen finden sich in der MicroProfile-Config-2.0-Spezifikation [3] sowie im zugehörigen MicroProfile Config 2.0 GitHub Repository [4].
Die MicroProfile-Open-API-Spezifikation dient zur Bereitstellung von API-Beschreibungen. Mit ihrer Hilfe lassen sich mit OpenAPI v3 [5] konforme Dokumentationen der anwendungseigenen JAX-RS Schnittstellen generieren.
Innerhalb der neuen Version 2.0 der MicroProfile Open API haben hauptsächlich Aufräumarbeiten stattgefunden. So wurden zum Beispiel die beiden Model Interfaces Scope und ServerVariables, die bereits in der Version 1.1. als "deprecated" markiert wurden, endgültig entfernt. Gleiches gilt für etliche als "deprecated" markierte Methoden der Model Interfaces APIResponses, Callback, Content, OASFactory, OAuthFlow, OpenAPI, Path, PathItem, Schema, SecurityRequirement und Server. Grund für die Markierung als "veraltet" war in der Version 1.1 übrigens eine Vereinheitlichung der Namensgebung, die nun in der Version 2.0 der Open API voll zum Tragen kommt.
Neben den eben beschriebenen Aufräumarbeiten hat es vor allem Neuerungen im Bereich der Schema-Annotationen gegeben, also der Art und Weise, wie die Datentypen von Eingaben und Ausgaben definiert werden können. So können zum Beispiel dank der neu eingeführten Annotation @SchemaProperty die Properties für ein Schema inline definiert werden, was die bisher zusätzlich notwendigen Schema-Annotationen innerhalb der annotierten Klasse erspart:
@Schema(properties={
@SchemaProperty(name="creditCard", required=true),
@SchemaProperty(name="departureFlight", description="... ."),
@SchemaProperty(name="returningFlight")
})
public class Booking {
...
}
Und auch für den Request- und den Response-Body gibt es nun eigene Schema-Annotationen, um so deren Schema-Definition deutlich zu vereinfachen:
@RequestBodySchema(MyRequestObject.class)
@APIResponseSchema(MyResponseObject.class)
Weitere Details zu den Neuerungen und Änderungen finden sich in der MicroProfile-Open-API-2.0-Spezifikation [6] sowie im zugehörigen MicroProfile Open API 2.0 GitHub Repository [7].
Die MicroProfile Health API erlaubt die Abfrage des "Gesundheitszustands" einer Anwendung beziehungsweise eines Service mithilfe sogenannter Health Checks. Die Spezifikation unterscheidet dabei zwischen den beiden Varianten Liveness Check und Readiness Check.
Während das Ergebnis eines Liveness Check signalisiert, ob eine Anwendung zum Zeitpunkt der Anfrage läuft, kann mittels Readiness Check zusätzlich abgefragt werden, ob die Anwendung auch bereit ist, Anfragen entgegenzunehmen und zu verarbeiten.
Eine positive (UP) beziehungsweise negative (DOWN) Antwort auf einen Liveness Check hilft somit zum Beispiel, 3rd-Party-Services zu entscheiden, ob eine Anwendung in einem Zustand ist, dass sie ordnungsgemäß – also ohne Verluste von Daten – heruntergefahren beziehungsweise beendet werden kann. Eine positive oder negative Antwort auf einen Readiness Check dagegen hilft 3rd-Party-Services zu entscheiden, ob Anfragen an die Anwendung bezeihungsweise den Service weitergeleitet werden können.
Die MicroProfile-Health-Spezifikation sah bisher vor, dass ein MicroProfile-Container so lange eine negative Antwort, also ein DOWN, als Default für einen Readiness Check zurückliefern muss, bis eine selbstgeschriebene Implementierung eines HealtCheck-Interfaces vom Typ @Readiness diesen auf UP setzt. Mit der neuen Version 3.0 ist nun zusätzlich die Möglichkeit geschaffen worden, diesen Wert via Konfiguration
mp.health.default.readiness.empty.response
zu setzen, wodurch als Standardwert auch ein UP als Rückgabewert möglich ist, ohne dass eine entsprechende Implementierung vorliegen muss.
Darüber hinaus wurde die bereits seit der Version 2.0 als veraltet (deprecated) markierte @Health-Annotation auf optional (pruned) gesetzt. Das bedeutet, dass die eine oder andere Implementierung diese Annotation eventuell auch weiterhin anbieten wird, man aber keinesfalls davon ausgehen darf, dass sie weiterhin zur Verfügung steht. Dieser Schritt ergibt Sinn, da die @Health-Annotation bereits in der Version 2.0 durch die deutlich aussagekräftigeren Pendants @Liveness und @Readiness ersetzt wurde.
Weitere Details zu den Neuerungen und Änderungen finden sich in der MicroProfile-Health-3.0-Spezifikation [8] sowie im zugehörigen MicroProfile Health 3.0 GitHub Repository [9].
Die MicroProfile Metrics API stellt Telemetriedaten einer Anwendung über Zeitreihen hinweg mittels entsprechenden Monitoring-Endpoint /metrics in dem OpenMetrics Text Format (aka Prometheus Exposition Format [10]) oder alternativ in Form von JSON zur Verfügung.
Die wohl augenscheinlichste Änderung innerhalb der MicroProfile-Metrics-3.0-Spezifikation ist die Überführung der ehemals abstrakten Klasse MetricRegistry hin zu einem Interface. Einhergehend mit dieser Änderung sind dem neuen Interface gleich eine ganze Reihe neuer statischer Methoden zur Registrierung beziehungsweise zum Zugriff auf die verschiedenen Metriktypen spendiert worden.
Da der Zugriff auf eine konkrete Implementierung des Interfaces für die verschiedenen Scopes (Type.APPLICATION, Type.BASE, Type.VENDOR) allerdings in der Regel via Injection vollzogen wird, hat sich in der Verwendung durch Entwickler – mit Ausnahme der neuen Methoden – allerdings kaum etwas geändert:
@Inject
@RegistryType(type=MetricRegistry.Type.APPLICATION)
MetricRegistry appRegistry@Inject
@RegistryType(type=MetricRegistry.Type.BASE)
MetricRegistry baseRegistry;@Inject
@RegistryType(type=MetricRegistry.Type.VENDOR)
MetricRegistry vendorRegistry;
Eine weitere Änderung innerhalb der Metrics API betrifft die gezielte Wiederverwendung von Metriken. Musste bis zur Version 2.3 eine gewünschte Wiederverwendung einer Metrik – zum Beispiel eines Aufrufzählers – über mehrere Methoden hinweg noch explizit via reusable=true bei der Registrierung der Metrik angegeben werden, ist dieses Verhalten seit der Version 3.0 Standard und kann auch nicht ausgeschaltet werden. Eine Ausnahme bildet hier lediglich die Gauge-Metrik, die weiterhin keine Wiederverwendung ein und derselben Metric-ID über mehrere Methoden hinweg erlaubt und im Falle eines Mehrfachvorkommens automatisch zu einer IllegalArgumentException beim Start der Anwendung führt.
Ebenfalls entfallen ist die Möglichkeit, die @Metric-Annotation zur Registrierung von durch CDI-Producer-Methoden erzeugten Metriken zu nutzen. Diese müssen nun über einen anderen Weg, zum Beispiel durch die Verwendung des MetricRegestry-Interfaces, registriert werden. Die @Metric-Annotation kann somit zukünftig nur noch als Injection-Point im Zusammenspiel mit der @Inject-Annotation auf Feld- oder Parameterebene verwendet werden.
Änderungen gab es auch im Bereich der Timer-Metriken, die jetzt nicht mehr mit Parametern vom Typ long und java.util.concurrent.TimeUnit, sondern stattdessen einfach mit einem Parameter vom Typ java.time.Duration aktualisiert werden können.
Weitere Details zu den Neuerungen und Änderungen finden sich in der MicroProfile-Metrics-3.0-Spezifikation [11] sowie im zugehörigen MicroProfile Metrics 3.0 GitHub Repository [12].
Die MicroProfile Fault Tolerance API bietet eine Reihe etablierter Resilience-Strategien – Timeout, Retry, Fallback, Bulkhead und Circuit Breaker – zur Behandlung von Fehlersituationen innerhalb einer MicroProfile-basierten Anwendung.
Die Liste der Änderungen innerhalb der neuen Version 3.0 der MicroProfile Fault Tolerance API ist recht überschaubar und erstreckt sich im Wesentlichen auf zwei Punkte:
@RequestScoped Bean mit @CircuitBreaker annotiert, so muss sichergestellt werden, dass alle Aufrufe der Methode sich – trotz unterschiedlicher Bean Instanzen – ein und denselben State des Circuit Breaker teilen. @Retry, @Timeout, @CircuitBreaker, @Bulkhead und @Fallback automatisch generierten Metriken. Diese finden sich zukünftig aus Gründen der Konsistenz mit den anderen MicroProfile APIs nicht mehr im Scope application: sondern im Scope base: und werden entsprechend über den Endpunkt /metrics/base statt /metrics/application zur Verfügung gestellt. Darüber hinaus nutzen die Metriken von Fault Tolerance 3.0 zukünftig die in MicroProfile Metrics 2.0 eingeführten Tags zur genaueren Spezifizierung der jeweiligen Metrik.
Eine annotierte Klasse
package com.exmaple;@Timeout(1000)
public class MyClass {@Retry
public void doWork() {
// do some very important work
}}
würde somit aufgrund der eben genannten Änderungen im Bereich der Scopes und Tags unter anderem zu folgender Metrik führen:
base:ft.timeout.calls.total{method=“com.example.MyClass.doWork“, timedOut=”true”}
statt wie bisher zu
application:ft.com.example.MyClass.doWork.timout.callsTimedOut.total
In Konsequenz bedeutet dies, dass bestehende Dashboards und Abfragen, die auf die verschiedenen Metriken der Fault-Tolerance-3.0-Annotationen zugreifen, entsprechend angepasst werden müssen.
Weitere Details zu den Neuerungen und Änderungen finden sich in der MicroProfile-Fault-Tolerance-3.0-Spezifikation [13] sowie im zugehörigen MicroProfile Fault Tolerance 3.0 GitHub Repository [14].
Auch wenn die Neuerungen und Änderungen innerhalb der MicroProfile 4.0 APIs eher als überschaubar zu bezeichnen sind, haben die verschiedenen API-Spezifikationsgruppen doch die Chance des anstehenden Major-Release-Sprungs genutzt, um ein wenig innerhalb ihrer API aufzuräumen.
Besonders positiv fällt dabei ins Auge, dass alle Spezifikationsgruppen anscheinend großen Wert auf eine MicroProfile-weite und somit API-übergreifende Vereinheitlichung zu setzen. Das spiegelt sich zum Beispiel in der Umbenennung von Methoden oder aber der Namensgebung erzeugter Metriken wieder.
Ebenfalls großer Wert wurde auf eine gute Developer Experience gelegt, was sich unter anderem an der neu eingeführten @ConfigProperties-Annotation zum Bulk-Einlesen von Konfigurationsdaten innerhalb der Config-API-Spezifikation oder aber der vereinfachten Schema-Definition innerhalb der Open-API-Spezifikation zeigt.
Aus der Praxis für die Praxis. Diesem Motto ist man trotz der Einführung von Working Group und Specification Process treu geblieben – und das ist auch gut so.
URL dieses Artikels:https://www.heise.de/-6006676
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/MicroProfile-4-0-ein-ueberfaelliges-politisches-Statement-5064494.html[2] https://download.eclipse.org/microprofile/microprofile-config-2.0/microprofile-config-spec-2.0.html[3] https://download.eclipse.org/microprofile/microprofile-config-2.0/microprofile-config-spec-2.0.html[4] https://github.com/eclipse/microprofile-config[5] https://swagger.io/specification/[6] https://download.eclipse.org/microprofile/microprofile-open-api-2.0/microprofile-openapi-spec-2.0.html[7] https://github.com/eclipse/microprofile-open-api[8] https://download.eclipse.org/microprofile/microprofile-health-3.0/microprofile-health-spec-3.0.html[9] https://github.com/eclipse/microprofile-health[10] https://prometheus.io/docs/instrumenting/exposition_formats[11] https://download.eclipse.org/microprofile/microprofile-metrics-3.0/microprofile-metrics-spec-3.0.html[12] https://github.com/eclipse/microprofile-metrics[13] https://download.eclipse.org/microprofile/microprofile-fault-tolerance-3.0/microprofile-fault-tolerance-spec-3.0.html[14] https://github.com/eclipse/microprofile-fault-tolerance
Copyright © 2021 Heise Medien
Einen Tag vor Weihnachten, und somit noch gerade eben so im alten Jahr, wurde MicroProfile 4.0 veröffentlicht. Offiziell war dieses Release bereits für den Sommer 2020 angekündigt. Ein grundlegendes organisatorisches Alignment sorgte aber für eine fast sechsmonatige Verzögerung der Java-Technik. Hat sich das Warten gelohnt?
Ein erster Blick auf die verschiedenen APIs von MicroProfile 4.0 zeigt zwar die eine oder andere sinnvolle Ergänzung, wirklich Neues oder Innovatives dagegen sucht man vergebens. Trotzdem musste die Community deutlich länger als sonst auf die neue Version warten. Und gleichzeitig gab es einen Sprung in der Major-Release-Version. Warum das?
Zum einen wurden die vier Java EE 8 APIs – CDI 2.0, JSON-P 1.1, JAX-RS 2.1 und JSON-B 1.0 – durch ihre gleichnamigen Pendants aus Jakarta EE 8 ersetzt. Gleiches gilt auch für die intern verwendete Annotation API 1.3. Parallel dazu wurden alle Abhängigkeiten der anderen MicroProfile APIs zu den eben genannten APIs aktualisiert.
Zum anderen, und das ist sicherlich deutlich gewichtiger, ist die aktuelle Version des MicroProfile das erste Release, das unter der Regie der neu geformten MicroProfile Working Group [1] veröffentlicht wurde und somit dem ebenfalls neu definierten MicroProfile Specification Process folgt.
Als sich vor gut fünf Jahren eine Gruppe von "Interessierten" – vornehmlich Hersteller von Enterprise-Java-Application-Servern – zusammenschloss und die Initiative MicroProfile.io [2] ins Leben rief, hat wohl kaum einer von ihnen geahnt, wie erfolgreich die Reise in den kommenden Jahren werden sollte. Angetreten mit dem Ziel, einen herstellerunabhängigen De-facto-Standard für Microservices im Enterprise-Java-Universum zu etablieren, erfreut sich das MicroProfile mittlerweile einer großen Fangemeinde.
Von Beginn an zeichnete sich die Initiative MicroProfile.io durch einen leichtgewichtigen Spezifikationsprozess, Transparenz in der Kommunikation, Herstellerunabhängigkeit und einen hohen Innovationscharakter aus. Aus der Praxis für die Praxis, so die Devise, die sich unter anderem auch in dem gelebten Implementation-First-Spezifikationsansatz widerspiegelt. Das Resultat dieses Ansatzes kann sich durchaus sehen lassen: Dreizehn Releases (inkl. MicroProfile 4.0) und somit im Schnitt zwei bis drei Releases pro Jahr, umgesetzt in bis zu zehn verschiedenen Implementierungen!
Aber mit dem wachsenden Erfolg stieg auch die Verantwortung. Reichte es anfangs noch aus, die konkreten Inhalte eines Release extrem agil, das heißt mit einem minimalen Prozess-Overhead und sehr späten Entscheidungen zu definieren, wuchs mit zunehmender Verbreitung der Wunsch nach mehr Planbarkeit innerhalb der stetig wachsenden Anwender-Community.
So kommt es nicht von ungefähr, dass sich die MicroProfile.io-Initiative in den letzten Wochen vor dem Release 4.0 – nicht auch zuletzt auf den eindringlichen Wunsch der Eclipse Foundation hin – vornehmlich mit organisatorischen Herausforderungen auseinandergesetzt hat und weniger mit der Weiterentwicklung von APIs. Im Fokus standen dabei insbesondere eine Reorganisation der ursprünglichen Initiative hin zu einer Eclipse Working Group (MicroProfile Working Group, kurz MPWG), sowie die Ausarbeitung eines Spezifikationsprozesses (MicroProfile Specification Process, kurz MPSP) für alle aktuellen und zukünftigen APIs.
Die Wesentliche Aufgabe der MPWG besteht darin, die fortwährende Weiterentwicklung des MicroProfile-Projekts für die kommenden Jahre sowohl technologisch als auch organisatorisch und finanziell zu sichern. Die Institutionalisierung der Working Group ist somit ein eindeutiges Signal der Eclipse Foundation an die Enterprise-Java-Community in Richtung Zukunftssicherheit und damit einhergehend eine Aufforderung, auch weiterhin auf den De-facto-Standard MicroProfile zur Entwicklung, zum Deployment und zum Management Coud-nativer Microservices zu setzen.
Den Kern der MPWG bildet ein Lenkungsausschuss, der sich aus verschiedenen Unternehmen und Java User Groups zusammensetzt (Atlanta JUG, IBM, Jelastic, Garden State JUG, Oracle, Payara, Red Hat, Fujitsu und Tomitribe sowie bald auch der iJUG). Zu seinen Aufgaben gehören neben der generellen zukünftigen Ausrichtung des MicroProfile insbesondere auch die Koordination der Weiterentwicklung der verschiedenen Spezifikationen.
Neben Unternehmen (Coorporate Members) und individuellen Committern (Commit Members) können auch durch den Lenkungsausschuss geladene Organisation (Guest Members) wie JUGs, R&D-Partner oder Universitäten temporär Teil der MPWG werden. Letztere werden dabei für ein Jahr eingeladen, um in dieser Zeit dedizierte Problemstellungen anzugehen oder Aktivitäten voranzutreiben. Anders als Cooperate Members und Commit Members haben Guest Members allerdings niemals Stimmrechte. Durch diesen Schritt soll es zukünftig möglich werden, punktuell Partner für bestimmte Fragestellungen mit ins Boot zu nehmen, ohne dabei die Working Group langfristig unnötig groß werden lassen zu müssen.
Weitere Details zur MPWG und deren Vision finden sich in der MicroProfile Working Group Charter [3].
Ein wichtiges Instrument für die Schaffung von mehr Transparenz bei der Spezifikation neuer APIs beziehungsweise der Weiterentwicklung bestehender APIs ist der zugehörige, formalisierte Prozess. Mehr Transparenz schafft eine verbesserte Planbarkeit und somit eine erhöhte Akzeptanz innerhalb der Community. Das gilt sowohl für die überschaubare Gruppe der Hersteller von MicroProfile-Implementierungen als auch für die deutlich größere Gruppe der Anwender eben dieser Implementierungen, also die Entwickler.
Während die Spezifikation neuer APIs beziehungsweise die Weiterentwicklung bestehender APIs bisher bis zum Release 3.3 eher pragmatisch und vor allem innerhalb der einzelnen APIs selbst geregelt wurden, setzt man ab Version 4.0 bewusst auf den etablierten Eclipse Foundation Specification Process v1.2 [4] (kurz: EFSP). So verwundert es auch nicht, dass der eigentliche MPSP – in gedruckter Form – mit weniger als einer DIN-A4-Seite auskommt und neben dem Verweis auf den EFSP im Wesentlichen nur die Angabe der Zeiträume zwischen den einzelnen Prozessschritten angibt (s. Abb.).

Noch einmal zurück zur Ausgangsfrage: Hat sich das verhältnismäßig lange Warten auf die Version 4.0 des MicroProfile denn nun gelohnt oder eher nicht?
Betrachtet man nur die politische Komponente, dann stellt das aktuelle Release wahrscheinlich einen der wichtigsten, wenn nicht sogar den wichtigsten Meilenstein seit der Einführung des MicroProfile in der Version 1.0 im September 2016 dar.
Dank neu gegründeter MicroProfile Working Group inklusive zugehörigem Spezifikationsprozess ist das MicroProfile endgültig den Kinderschuhen entwachsen und ins Lager der Erwachsenen gewechselt. Der Prozess wurde dabei bewusst so flexibel ausgelegt, dass die bisherige, erfreuliche hohe Frequenz an Releases pro Jahr nahezu unverändert beibehalten werden kann, ohne dabei an Qualität zu verlieren.
Dass der Prozess am Ende tatsächlich auch funktionieren wird, zeigt das aktuelle Release, das als eine Art internes Proof of Concept gesehen werden kann. Denn auch wenn der Fokus des MicroProfile 4.0 eher auf dem organisatorischen Alignment lag, gibt es natürlich auch die eine oder andere Änderung an den APIs. Dazu aber mehr in meinem nächsten Blog-Beitrag.
URL dieses Artikels:https://www.heise.de/-5064494
Links in diesem Artikel:[1] https://microprofile.io/workinggroup/[2] https://microprofile.io[3] https://www.eclipse.org/org/workinggroups/microprofile-charter.php[4] https://www.eclipse.org/projects/efsp/?version=1.2
Copyright © 2021 Heise Medien
Lange genug hat es geheißen, dass IT-Projekte einen Wettbewerbsvorteil versprechen. Schaut man der Realität ins Auge, wird ein IT-Projekt jedoch wie ein Kostenfaktor behandelt – nicht anders als Strom oder Miete. Dabei könnte es anders sein.
Wohl alle in der IT denken, dass eine effiziente IT einen Wettbewerbsvorteil verschaffe. Daten sind bekanntermaßen das neue Öl. Digitalisierung macht alles zu Software, und wer Software beherrscht, beherrscht den Markt. IT-Projekte sind offensichtlich notwendig, um diese Vorteile tatsächlich zu realisieren.
Schauen wir uns ein typisches IT-Projekt an. Die Kosten sind praktisch immer bekannt. Die laufenden Personalkosten lassen sich relativ einfach ermitteln, die Projektlaufzeit ist ebenfalls bekannt und auch Faktoren wie Hardwarekosten werden meistens sehr genau ermittelt. Zeiten und Termine werden geschätzt, Budgets festgelegt, und wenn sie überschritten werden, wird das natürlich gemanagt. Und deutliche Überschreitungen haben ernsthafte Konsequenzen.
Wenn die IT-Projekte einen Wettbewerbsvorteil erzeugen sollen, dann müssen die Business-Ziele ebenfalls gemanagt werden – sei es das Erschließen neuer Märkte oder das Optimieren bekannter Prozesse. Die Ziele müssen eigentlich sogar im Mittelpunkt stehen. Natürlich basieren Projekte oft auf einem Business Case, der beispielsweise in einer Präsentation festgehalten worden ist und dazu dient, ein Projekt zu rechtfertigen und zu starten. Aber das bedeutet noch lange nicht, dass die Ziele tatsächlich das Geschehen in den laufenden Projekten bestimmen.
In den verschiedenen Projekten, die man als Berater sieht, sind den Teams die Business-Ziele der Projekte nicht immer klar. In einigen Projekten gibt es beispielsweise Ziele wie einen Nutzen für Endkunden, aber sie sind dem Team nicht kommuniziert oder bestimmen nicht die tägliche Arbeit. Bei anderen Projekten bleiben die Ziele dauerhaft unklar.
Werkzeuge wie Burn-Down-Charts, die den noch verbliebenen Aufwand und damit letztlich die verbliebene Zeit und das verbleibende Budget zeigen und an alle klar kommunizieren, sind hingegen üblich. Wie gesagt: Kosten und Budgets werden eigentlich immer gemanagt. Interessanterweise ist ein Burn-Down-Chart gerade bei agilen Projekten üblich, die eigentlich versprechen, Business-Ziele besser zu erreichen.
Ein Beispiel für die Vernachlässigung von Business-Zielen können Projekte für die Migration auf eine neue Technologie sein. An den Funktionalitäten ändert sich nichts. So wird zwar ein Business-Ziel wie niedrigere Betriebskosten oder ein langfristig stabiler Betrieb ermöglicht, aber solche Projekte könnten oft zusätzlich andere Business-Ziele durch Änderungen an der Logik recht einfach umsetzen. Schließlich wird das System ja sowieso komplett umgestellt. Man kann diese Chance nutzen, um das System zu verbessern und so mehr Business-Werte zu schaffen. Das Projekt kann dadurch aber auch zu komplex und risikoreich werden. Eine solche Abwägung zwischen zusätzlichem Business-Wert und Risiko erfolgt oft aber nicht – die Kosten hingegen werden auch bei diesen Projekten überwacht.
Wenn man IT als Wettbewerbsvorteil leben will, muss man nicht nur die Business-Ziele kennen, sondern den Business Case als Geldbetrag schätzen. Wer beispielsweise durch ein Projekt mehr Umsatz oder Gewinn erwartet, kann ausrechnen, wie viel Geld das wert ist. Der Wert eines Unternehmens wird auch anhand finanzieller Kenngrößen ermittelt – warum also bei einem Projekt nicht genauso vorgehen?
Nun kann man argumentieren, dass der Business-Wert eines Projekts viel schwieriger zu ermitteln ist als das verbrauchte und das übrige Budget. Aber der Aufwand für ein Softwareprojekt ist ebenfalls schwierig zu schätzen. Eigentlich ist das sogar unmöglich, weil Softwareprojekte so komplex sind, dass sie sich einer detaillierten Planung entziehen. Deswegen nutzt man iterativ-inkrementelle Methoden, die in einzelnen kleinen Inkrementen vorgehen, die wegen der geringeren Größe einfacher abzuschätzen sind. Softwareentwicklungsteams müssen sich also darin bewähren, trotz widriger Umstände Aufwände und Budgets abzuschätzen. Ist es tatsächlich schwieriger, den Business-Wert der Projekte abzuschätzen? Zumindest probieren könnte man es, aber selbst ein solcher Versuch bleibt meistens aus. Strukturierte Ansätze, solche Werte zu ermitteln, existieren – man muss sie nur anwenden.
Außerdem kann man gerade beim Business-Wert große Überraschungen erleben: Ein Produkt, dass keine Kunden findet, ist wertlos. Daher ist es eigentlich noch wichtiger, den Business-Wert zu ermitteln und als das Budget nachzuhalten. Denn wenn man Geld für etwas Wertloses ausgibt, ist das schlicht unsinnig. Wenn man hingegen die Chance verpasst, Projekte, die bei Kunden sehr beliebt und daher wertvoll sind, besser zu unterstützen, ist das ebenso schlecht.
Der Wert eines Projekts kann dabei erheblich sein. Mir ist ein Projekt in Erinnerung, das sich bereits vor dem Start amortisiert hatte, weil der Auftraggeber in Erwartung der neuen Software andere Finanzgeschäfte abschließen konnte und dadurch das Projekt-Budget erwirtschaften konnte. Und weil Software immer wichtiger wird, steigt auch der Wert guter Software.
Hätte man eine solche finanzielle Bewertung, würden sich die Bedingungen in den Projekten ändern. Statt die Frage zu stellen, wo man Aufwand sparen kann, wird die Frage, wo man mehr Werte schaffen kann, plötzlich genauso wichtig. Es geht nicht nur um Budgetüberschreitungen, sondern auch um die geschaffenen Werte. Ohne eine solche finanzielle Kenngröße für den Business-Wert liegt es nahe, die Projekte nach den Kosten zu beurteilen und zu optimieren, weil es die einzige finanziellen Kenngrößen sind, die eigentlich immer bekannt sind.
Neben dem Business-Wert eines Projekts gibt es eine weitere Kenngröße, die angeblich wichtig für IT ist: Durchlaufzeit, bis ein Feature tatsächlich in Produktion ist. Aber auch hier ist stellt sich die Frage, ob diese Größe wirklich aktiv gemanagt wird. Projekte wissen sicherlich, wie schnell sie eine Änderung in Produktion bringen können. Ob sie diese Zahl reporten und danach gemessen werden, ist eine ganz andere Frage. Außerdem gilt auch hier: Einen Wert sollte man als Geldbetrag ausdrücken können. Dazu bietet sich eine Größe an: Wie viele Kosten entstehen, wenn ein Feature sich verzögert? Man spricht vom "Cost of Delay".
Im "State of DevOps 2018 [1]"-Report gibt es dazu eine interessante Grafik von Maersk (Seite 46). Sie zeigt, dass es drei Features gibt, deren Verzögerung um eine Woche 7 Millionen US-Dollar kosten würde – vermutlich, weil Kunden abspringen oder Prozesse nicht rechtzeitig optimiert werden können. Solche Grafiken oder Aufstellungen haben in Projekten Seltenheitswert. Mit anderen Worten: Durchlaufzeit ist so unwichtig, dass man sich noch nicht einmal die Mühe macht, den möglichen Vorteil überhaupt finanziell zu bewerten.
Es ist also üblich, die Kosten eines Projekts finanziell zu bewerten und im Auge zu behalten. Business-Ziele sind oft schlecht kommuniziert. Und es ist sehr ungewöhnlich, den Business-Wert eines Projekts tatsächlich als Geldbetrag auszudrücken. So verschiebt sich der Fokus von dem Schaffen von Werten auf die Optimierung der Kosten, die als einzige Größe wirklich bekannt sind. IT wird dann unfreiwillig und ungeplant zu einem Kosten- statt zu einem Wettbewerbsfaktor. Das muss natürlich nicht so sein: Dazu müssen aber Business-Ziele, der Business-Wert, der Business Case und damit die erzeugten Werte bekanntund idealerweise als finanzielle Kenngrößen etabliert sein.
Die Kosten von IT-Projekten werden typischerweise gemanagt, aber der potenziell geschaffene Wert noch nicht einmal als Geldbetrag ermittelt. So wird die IT zu einem reinen Kostenfaktor.
Vielen Dank an meine Kolleg:innen Gerrit Beine, Matthias Déjà, Anja Kammer und Stefan Tilkov für die Kommentare zu einer früheren Version des Artikels.
URL dieses Artikels:https://www.heise.de/-6007620
Links in diesem Artikel:[1] https://services.google.com/fh/files/misc/state-of-devops-2018.pdf
Copyright © 2021 Heise Medien
Bei mobilen eingebetteten Lösungen spielt der Energieverbrauch oft eine entscheidende Rolle. Je höher der Verbrauch, desto schneller muss das Gerät wieder an die "Tankstelle". Der ESP32-Microcontroller ist diesbezüglich nicht gerade als die sparsamste Option bekannt. Kann man trotzdem ein ESP32-Board mit Niedrigenergieverbrauch bauen? Man kann! Das trigBoard v8 lässt grüßen.
Kevin Darrah hat das trigBoard V8 entwickelt, damit ein ESP32 auch Anwendungen unterstützen kann, die niedrigen Stromverbrauch erfordern. Ursprünglich war das trigBoard für solche IoT-Geräte konzipiert, die via WiFi melden, sobald sie über einen angeschlossenen Sensor das Öffnen oder Schließen eines Fensters oder einer Tür feststellen. Das Board hat sich inzwischen als Lösung herauskristallisiert, die sich durchaus auch für Problemstellungen mit anderen Sensoren eignet.
Das trigBoard v8 hatte diverse Vorgänger, die auf dem ESP8266 basierten. Es ist aber mit dem ESP32 nicht nur ein neuer Microcontroller an Bo(a)rd, sondern diverse Verbesserungen gegenüber früheren Versionen.
Als Grundlage verwendet das trigBoard v8 ein ESP32-Modul des Typs ESP32-WROOM-32D mit 16-MByte-Flash. Um den Stromverbrauch zu minimieren, erfolgt die Spannungsversorgung nicht direkt von der Versorgungsspannung zum ESP32, sondern nimmt den Umweg über eine "Wake Circuitry"(Aufweckschaltkreis).


Die Stromstärke im Standby-Modus beträgt mit einer 3V-Spannungsquelle gerade einmal 1,5 uA. Zum Vergleich: ein handelsüblicher Rauchmelder kommt auf circa 7 uA. Eine exemplarische Modellrechnung beim Einsatz einer LiPo-Batterie mit 3,7 V und 1200 mAh Kapazität fällt folgendermaßen aus: Angenommen, das trigBoard verbraucht pro Stunde etwa fünf Sekunden lang 50 mA und wartet dazwischen im Tiefschlaf auf neue Ereignisse. In diesem Fall kommt die Batterie mehr als 1,5 Jahre ohne Neuaufladung aus.
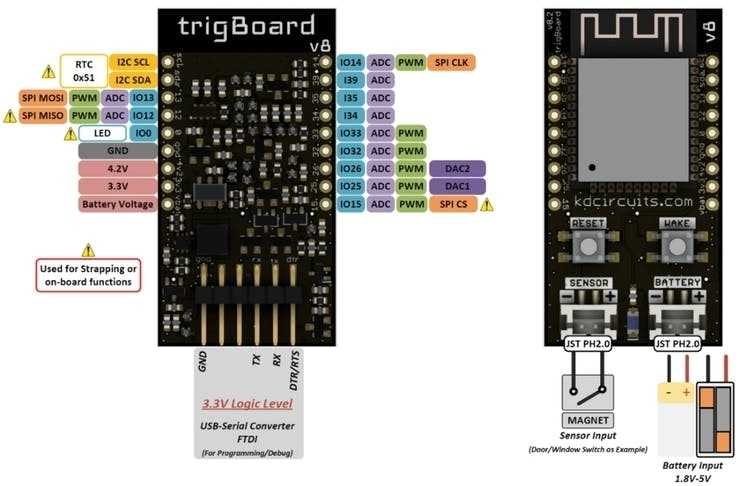
Wie erreicht das trigBoard dieses Ziel? Grundsätzlich verfügt das Board neben dem ESP32 über sechs Funktionsblöcke:

Die folgenden Pins sind Teil dieser Funktionalitäten und lassen sich vom Nutzer für eigene Zwecke konfigurieren:
Spannungsseitig läuft das Board mit Versorgungsspannungen zwischen 1,8 V und 5 V. Die empfohlene Betriebsspannung beträgt jedoch zwischen 2,5 V und 5 V. Das trigBoard prüft beim Einlegen von Batterien deren Polarität und erleidet in den meisten Fällen keinen Schaden, sollten Batterien falsch herum angeschlossen werden.
Wichtige Pins des trigBoard sind nach außen gelegt. Durch Anlöten von Header-Leisten können Entwickler das Board prototypisch auf einem Breadboard einsetzen oder alternativ Anschlussklemmen installieren. Auf der Webseite für das trigBoard [1] gibt es außerdem STL [2]-Dateien, um per 3D-Drucker ein geeignetes Gehäuse zu erzeugen.
Die bereitgestellte Firmware [3] unterstützt mehrere Internetdienste, um Push-Meldungen zu versenden, unter anderem IFTTT, Pushsafer und Pushover. Ebenso sind eigene Lösungen möglich, die auf den Kommunikationsprotokollen TCP, UDP oder MQTT basieren. Meldungen können dabei auch mehrere Wege nehmen, zum Beispiel einen über MQTT, einen anderen über IFTTT. Notiz am Rande: Sogar der "Weck"-Knopf am Board ist optional in der Lage, das Versenden von Push-Meldungen zu initiieren.
Für das Bereitstellen neuer Firmware implementiert das Board OTA-Downloads (Over the Air). Das ist sinnvoll, weil niemand willens wäre, alle vorhandenen Boards mit einem Notebook auf den neuesten Stand zu bringen, obwohl auch das problemlos machbar ist.
Was muss genau passieren, damit das trigBoard aus seinem Dornröschenschlaf erwacht? Entsprechende Trigger lassen sich rein softwareseitig konfigurieren. Ein auslösender Trigger könnte beispielsweise darin bestehen, dass ein Kontakt von offen auf geschlossen wechselt oder dass der Kontakt sich von geschlossen auf offen ändert. Möglich ist auch die Kombination beider Fälle, etwa "Garagentor hat sich geöffnet" und später "Garagentor wurde geschlossen". Das Aufwecken des Boards erfordert einen Abfall oder Anstieg der Spannung am Sensoreingang um 3 V. Der Zielzustand muss mindestens 200 Millisekunden anliegen, um das Board zu wecken. Da sich dieses Verhalten nicht für alle Sensoren realisieren lässt, beispielsweise für CO/Rauchdetektoren oder PIR-Sensoren, können sich Entwickler mit einem MOS-FET-Transistor oder anderen Schaltungen behelfen (sogenannter Hair-Trigger).
Eine möglichst exakte Zeitnehmung erweist sich in vielen Anwendungsfällen als relevant, weshalb das ESP32-Board eine genaue Echtzeituhr (RTC) integriert, die das Aufwecken des Boards aus dem Tiefschlaf erlaubt. Dabei kann das Board zum Beispiel periodisch die Spannungsquelle auf Restkapazität prüfen und gegebenenfalls eine Alarmmeldung versenden, sobald die Spannung unter einen bestimmten Pegel fällt.
Ein Problem durch das Design für niedrigen Energieverbrauch resultiert aus Szenarien wie dem folgenden: Jemand läuft aus dem Haus, öffnet die Tür und schließt sie gleich wieder hinter sich. In diesem Fall könnte es sein, dass das trigBoard zwar das Öffnen der Tür bemerkt, nicht aber das Schließen. Als Ausweg kann ein periodischer Alarm der Echtzeituhr fungieren, der den aktuellen Status der Tür detektiert, also ob sie nach wie vor offen oder geschlossen ist.
Für die Anpassung des trigBoards an eigene Bedürfnisse kombinieren Nutzer Google Chrome mit einem Konfigurationswerkzeug, um alle Boardparameter und -einstellungen auf einem per Bluetooth angeschlossenen trigBoard durchzuführen. Als Basis fungiert dabei ein Host mit macOS, Linux oder Windows 10. Das Konfigurationsprogramm [4] ist über GitHub beziehbar.


Die Software für das trigBoard entstand unter der Arduino IDE mit dem entsprechenden Boardsmanager [5]. Es handelt sich um ein ESP32 Dev Module mit folgenden Einstellungen in der IDE:
Benutzt haben Firmware-Entwickler die Arduino IDE Version 1.8.10. Zusätzlich benötigt die Firmware

Um eigene Experimente durchzuführen, habe ich folgende Komponenten eingesetzt:
Der folgende Versuchsaufbau stellt fest, ob eine Tür (oder ein Fenster) geöffnet oder geschlossen wird:

Das trigBoard ist so konfiguriert, dass es Türöffnen oder Türschließen über den Dienst Pushover meldet:

Es geht also doch, wenn ein Elektronikexperte Hand anlegt. Das trigBoard v8 verbindet die Vorteile des ESP32 mit denen des Niedrigenergiebetriebs. Sicherlich ist das trigBoard kein Mittel für alle Fälle, sondern speziell darauf getrimmt, Lösungen mit geringem Stromverbrauch zu ermöglichen. Genau das macht es, und zwar nicht nur richtig, sondern richtig gut. Mit umgerechnet 25,29 Euro (US-$ 29,99) gehört das Board mit Sicherheit nicht zu den Schnäppchen (Bezugsquelle: tindie [6]), aber – den entsprechenden Einsatzzweck vorausgesetzt – ist es auf jeden Fall sein Geld wert.
Ich möchte Kevin Darrah an dieser Stelle dafür danken, dass er diesem Blog ein Testexemplar des trigBoards bereitgestellt hat.
URL dieses Artikels:https://www.heise.de/-6005505
Links in diesem Artikel:[1] https://trigboard-docs.readthedocs.io/en/latest/index.html#[2] https://de.wikipedia.org/wiki/STL-Schnittstelle[3] https://github.com/krdarrah/trigBoardv8_basefirmware/[4] https://github.com/krdarrah/trigBoardConfigurator/[5] https://dl.espressif.com/dl/package_esp32_index.json[6] https://www.tindie.com/products/kdcircuits/trigboard-ultra-low-power-esp32-iot-platform/
Copyright © 2021 Heise Medien
Leistungsstarke Prozessoren wie der im Pico verwendete ARM-M0+ haben mehrere Kerne. Dadurch ist die parallele Abarbeitung verschiedener Aufgaben durch Threads möglich. Von sehr seltenen Situationen abgesehen, müssen sich Threads miteinander synchronisieren, sobald sie auf gemeinsame Ressourcen zugreifen. Der vorliegende Beitrag erläutert, welche Mechanismen das Pico-SDK dafür bereitstellt und wie sie Entwickler einsetzen können.
Der Mikrocontroller des Raspberry Pi Pico besitzt zwei Rechenkerne, genannt Core0 und Core1, die eine Parallelisierung über Threads ermöglichen.
Während das Hauptprogramm, egal ob bei Verwendung von Python oder C beziehungsweise C++, im Kern "Core0" läuft, steht der Kern "Core1" für einen zweiten Thread zur Verfügung. Dafür gibt es im Pico-SDK die Funktion multicore_launch_core1(), die als Argument eine Funktion ohne Rückgabewert erwartet. Diese Funktion enthält dementsprechend den vom zweiten Thread durchlaufenen Code. In MicroPython erfolgt der Start eines zweiten Threads übrigens über die Bibliotheksfunktion _thread.start_new_thread().
Das Pico-SDK erlaubt nur einen Thread pro Rechenkern, insgesamt also zwei in einem Programm. Um mehrere Threads pro Kern zu verwalten, bräuchte es ein geeignetes Betriebssystem, das Kernel-Komponenten für Task-Scheduling und Prioritätsmanagement umfasst.
Für Pico-Entwickler könnte sich alles durch das Echtzeitbetriebssystems FreeRTOS ändern, das in Zukunft auch den RP2040 unterstützen soll.
Multithreading macht im Allgemeinen nur dann Sinn, wenn Threads in der Lage sind, sich miteinander zu koordinieren. Zu diesem Zweck existiert für jeden Kern eine Warteschlange (FIFO), in die ein Thread eines Kerns Nachrichten platziert (push) und von der der Thread des anderen Kerns Nachrichten lesen (pop) kann. Folglich gibt es insgesamt zwei Warteschlangen. Lesen geschieht über Funktionen wie multicore_fifo_pop_blocking(), Schreiben über Funktionen wie multicore_fifo_push_blocking().
Das "blocking" besagt, dass der jeweilige Thread so lange warten muss, bis er eine Nachricht lesen kann – das heißt, es sind Nachrichten vorhanden – beziehungsweise eine Nachricht schreiben kann – das heißt, die Warteschlange ist nicht voll.
Das C-Programmbeispiel unten instanziiert zwei Threads, nämlich den im Kern laufenden Main-Thread, und einen im Kern 1 laufenden Thread, der die Funktion playerOne() abarbeitet. Beide Threads spielen miteinander ein simples Würfelspiel mit zwei Würfeln. Die Regeln sind denkbar einfach: Wer die höhere Augensumme erzielt, gewinnt. Dafür nutzt das Programm die rand()-Funktion zur Würfelsimulation. Der Ausdruck rand() % 6 + 1 liefert einen ganzzahligen Wert zwischen 1 und 6. Der initiale Seed lautet im Programmbeispiel 42, was im Normalfall keine gute Idee ist, aber für den illustrativen Zweck genügt.
Das Ergebnis als Summe ihrer zwei Würfel übermitteln die Threads blockierend über die Warteschlange an den Gegenspieler. In jeder Spielrunde passiert Folgendes: Spieler 2 (main()-Funktion im Kern 0) würfelt, und schreibt sein Ergebnis blockierend in die Warteschlange. Spieler 1 liest das Ergebnis ebenfalls blockierend aus derselben Warteschlange.
Dann dreht sich das Verfahren um: Jetzt schreibt Spieler 1 (Kern 1) die eigene Augenzahl blockierend, während sie Spieler 2 (Kern 0) blockierend liest. Nur durch diese Reihenfolge lässt sich ein Deadlock verhindern.
#include <stdio.h>
#include "pico/stdlib.h"
#include "pico/multicore.h"void playerOne() {
uint32_t my_result; // own sum of dice
uint32_t opponent_result; // opponent's result
uint32_t dice1, dice2;
while (true) {
dice1 = rand() % 6 + 1;
dice2 = rand() % 6 + 1;
printf("Player 1: I got %d and %d\n", dice1, dice2);
my_result = dice1 + dice2;
opponent_result = multicore_fifo_pop_blocking(); // obtain result from player 1
sleep_ms(1000);
multicore_fifo_push_blocking(my_result); // send own result to player 1
sleep_ms(1000);
if (my_result > opponent_result) {
puts("Player 1: I won :-)");
}
else
if (my_result < opponent_result) {
puts("Player 1: I lost :-(");
}
else
puts("Player 1: Draw :-!");
}
}
int main() { // player 2
stdio_init_all();
int32_t seed = 42; // note: this is a bad seed in general. Use time()-function instead
srand(seed); // initialize random number generator
uint32_t dice1, dice2; // own dice
multicore_launch_core1(playerOne); // start player One as opponent
uint32_t my_result; // own sum of dice
uint32_t opponent_result; // opponent's result
while (true) {
dice1 = rand() % 6 + 1;
dice2 = rand() % 6 + 1;
my_result = dice1 + dice2;
printf("Player 2: I got %d and %d\n", dice1, dice2);
multicore_fifo_push_blocking(my_result); // send own result to player 2
sleep_ms(1000);
opponent_result = multicore_fifo_pop_blocking(); // obtain result from player 2
sleep_ms(1000);
if (my_result > opponent_result) {
puts("Player 2: I won :-)");
}
else
if (my_result < opponent_result) {
puts("Player 2: I lost :-(");
}
else
puts("Player 2: Draw :-!");
}
return 0;
}
Zum Beobachten des Spielverlaufs kommt ein serieller Monitor zum Einsatz. Auf dem Mac benutze ich dafür die (kostenpflichtige) App Serial 2 von decisivetactics. Natürlich tut es jeder andere serielle Monitor auch.

Das Pico-Würfelspiel-Programm definiert einen fest vorgegebenen Seed für die Zufallsverteilung. Für eine echte Anwendung würde man natürlich einen zufälligen Seed nutzen. Andernfalls wäre die Zufallsverteilung vorhersagbar. Um den Seed zu ermitteln, können Entwickler zum Beispiel die Echtzeituhr (RTC) des Pico einsetzen. Im nachfolgenden Programmbeispiel geben Entwickler das aktuelle Datum und die aktuelle Zeit fest in den Code ein (Datenstruktur datetime_t) und können damit die Echtzeituhr initialisieren.
Aus der von rtc_get_datetime() zurückgelieferten Struktur lässt sich damit ein geeigneter Seed berechnen, etwa durch Addieren aller Datums- und Zeitwerte bei vorhergehender Normalisierung des Jahres (nur die letzten zwei Ziffern des Jahres finden Berücksichtigung).
#include <stdio.h>
#include "hardware/rtc.h"
#include "pico/stdlib.h"
#include "pico/util/datetime.h"int main() {
stdio_init_all();
char datetime_buf[256];
char *datetime_str = &datetime_buf[0];
// Start jetzt: am 23.3.2021 um 16:29
datetime_t t = {
.year = 2021,
.month = 03,
.day = 23,
.dotw = 2, // 0 = Sonntag, 1 = Montag, 2 = Dienstag, ...
.hour = 16,
.min = 29,
.sec = 00
};
// Initialisieren der Echtzeituhr
rtc_init();
rtc_set_datetime(&t);
// ……………… weiterer Code ………………
rtc_get_datetime(&t);
datetime_to_str(datetime_str, sizeof(datetime_buf), &t);
printf("\r%s ", datetime_str);
// ……………… weiterer Code ………………
}
Die bisherigen Funktionen für Multithreading beziehungsweise Thread-Management stellen nur die Spitze des Eisbergs dar. In der zugehörigen Bibliothek gibt es weitere Möglichkeiten.

Das Würfel-Programm nutzt eine der Funktionen zum Start eines Threads in Kern 1 namens multicore_launch_core1().
Zusätzlich existiert die Möglichkeit, den Thread auch mittels multicore_launch_core1_with_stack() zu starten, wobei diese Funktion als Argumente einen Zeiger auf die auszuführende Funktion sowie die Adresse eines benutzerdefinierten Laufzeitstacks und dessen Startadresse erwartet. Eine weitere Funktion multicore_launch_core1_raw() startet Kern 1 neu, führt darauf die als erstes Argument angegebene Funktion aus. Wichtig: Hier gibt es allerdings keinen Stack Guard.
Es liegt in der Verantwortung der Programmierer, dass der Stack nicht überläuft. Schließlich existiert noch eine Funktion multicore_reset_core1(), die Kern 1 zurücksetzt.
FIFO-Warteschlangen zur Inter-Core-Kommunikation besitzen acht Einträge zu je 32 Bit. Für das Verwenden dieser FIFO-Warteschlangen gibt es ebenfalls noch weitere Funktionen in der Bibliothek.
multicore_fifo_rvalid() prüft nichtblockierend, ob Daten zum Lesen bereits sind. Falls ja, kann ein Thread beim Vorliegen von Einträgen mit multicore_fifo_pop_blocking() die Daten beziehen. Liegen keine Daten vor, kann er sich inzwischen um andere Angelegenheiten kümmern und später erneut den Zugriff versuchen.
Für das Schreiben von Daten gibt es analog das nichtblockierende multicore_fifo_wready(), dem ein multicore_fifo_push_blocking() folgt. Mittels multicore_fifo_status() ermitteln Programmierer, ob die Warteschlange nicht voll (->1) oder nicht leer ist (-> 0) beziehungsweise ob es einen Versuch gab, die leere FIFO zu lesen (->3) oder auf die volle FIFO zu schreiben (->2).

Übrigens liegt in der Bibliothek pico_util (Pico-SDK) auch der Datentyp Queue vor (siehe hier [1]), der allgemeiner als die oben verwendete FIFO-Queue, aber ebenfalls Thread-sicher ist. "Allgemeiner" soll heißen, dass Queues keine Längenbeschränkung besitzen und beliebige Arten von Elementen enthalten können. Dieser Datentyp aus der Bibliothek lässt sich entsprechend als Alternative zu den systemnahen FIFO-Queues nutzen.
Hier sehen wir das auf die Thread-sicheren Queues umgestellte Programmbeispiel. Gegenüber obigen Beispiel hat sich nicht viel geändert. Es läuft, semantisch gesehen, analog ab:
#include <stdio.h>
#include "pico/stdlib.h"
#include "pico/util/queue.h"
#include "pico/multicore.h"typedef struct
{
uint32_t dice1;
uint32_t dice2;
} queue_entry_t;
queue_t playerOneQueue; // queue used by playerOne to send results
queue_t playerTwoQueue; // queue used by playerTwo to send results
void playerOne() {
queue_entry_t playerTwoResult, playerOneResult;
while (true) {
sleep_ms(1000);
playerOneResult.dice1 = rand() % 6 + 1;
playerOneResult.dice2 = rand() % 6 + 1;
printf("Player 1: I got %d and %d\n", playerOneResult.dice1, playerOneResult.dice2);
queue_remove_blocking(&playerTwoQueue, &playerTwoResult); // obtain result from player 2
sleep_ms(1000);
queue_add_blocking(&playerOneQueue, &playerOneResult);
sleep_ms(1000);
if ((playerTwoResult.dice1 + playerTwoResult.dice2) < (playerOneResult.dice1 + playerOneResult.dice2)) {
puts("Player 1: I won :-)");
}
else
if ((playerTwoResult.dice1 + playerTwoResult.dice2) > (playerOneResult.dice1 + playerOneResult.dice2)) {
puts("Player 1: I lost :-(");
}
else
puts("Player 1: draw :-!");
}
}
void playerTwo() { // player 2
queue_entry_t playerTwoResult, playerOneResult;
while (true) {
playerTwoResult.dice1 = rand() % 6 + 1;
playerTwoResult.dice2 = rand() % 6 + 1;
printf("Player 2: I got %d and %d\n", playerTwoResult.dice1, playerTwoResult.dice2);
queue_add_blocking(&playerTwoQueue, &playerTwoResult);
sleep_ms(1000);
queue_remove_blocking(&playerOneQueue, &playerOneResult); // obtain result from player 1
sleep_ms(1000);
if ((playerTwoResult.dice1 + playerTwoResult.dice2) > (playerOneResult.dice1 + playerOneResult.dice2)) {
puts("Player 2: I won :-)");
}
else
if ((playerTwoResult.dice1 + playerTwoResult.dice2) < (playerOneResult.dice1 + playerOneResult.dice2)) {
puts("Player 2: I lost :-(");
}
else
puts("Player 2: draw :-!");
}
}
int main() {
stdio_init_all();
int32_t seed = 42; // note: this is a bad seed in general. Use time()-function instead
srand(seed); // initialize random number generator
queue_init(&playerOneQueue, sizeof(queue_entry_t), 2); // initialize queues
queue_init(&playerTwoQueue, sizeof(queue_entry_t), 2);
multicore_launch_core1(playerOne); // start player One as opponent
playerTwo(); // start player Two
return 0;
}
Ein Hinweis, wenn statt C die Programmiersprache C++ zum Einsatz kommen sollte: In diesem Fall ergeben sich beim abgedruckten Beispiel Fehlermeldungen während des Kompilierens und Bindens. Daher müssen die betreffenden Include-Anweisungen im Code wie etwa
#include "pico/util/queue.h"
folgendermaßen "umklammert" werden:
extern "C" {
#include "pico/util/queue.h"
}Queues besitzen nicht nur die oben benutzten Funktionen, sondern auch weitere, etwa solche zum nichtblockierenden Prüfen wie queue_is_empty(), queue_is_full(), queue_try_peek() und Funktionalität zum nichtblockierenden Hinzufügen oder Entnehmen von Elementen wie queue_try_add() oder queue_try_remove().

Falls Entwickler selbst Thread-sichere Datentypen wie Queues erstellen wollen, benötigen sie dafür geeignete Mechanismen. Zur Synchronisation von Threads stellt die Bibliothek pico_sync des Pico-SDKs verschiedene Primitive bereit, insbesondere Mutexes, Semaphores und Critical Sections. Ein wichtiger Hinweis in diesem Zusammenhang: Die vorgestellten Mechanismen schützen bei oberflächlicher Betrachtung Teile des Programmes vor parallelem Betreten. Das ist aber nicht ihr eigentlicher Zweck. Ihr Zweck ist es vielmehr, gemeinsame Ressourcen vor inkonsistenten Änderungen abzusichern und inkonsistente Sichten zu verhindern. Unter Ressourcen sind Speicherbereiche zu verstehen, aber auch andere gemeinsam genutzte Entitäten wie serielle Schnittstellen, Sensoren oder Aktuatoren.
Kritische Bereiche (Critical Sections) basieren auf Spinlocks. Diese sind im PICO-SDK systemnah implementiert und nutzen ARM-Maschineninstruktionen. Sie stellen akquirierbare Ressourcen dar, auf die ein Thread in einer Schleife so lange aktiv warten muss, bis der Spinlock nicht mehr belegt ist. Daher auch der Name – der Thread "spint" also in gewisser Weise. Nach Beendigung seiner Tätigkeit gibt er den Spinlock wieder frei. Weil die Akquisition eines Spinlocks wie die jedes Synchronisationsprimitive mit aktivem Warten verbunden ist, sollte ihn jeder Thread nur sehr kurz behalten und auch schnell wieder freigeben. Insbesondere sollten alle hier vorgestellten Synchronisationsmechanismen nicht oder nur in sehr wenigen und vor allem nur in berechtigten Ausnahmefällen innerhalb von Interrupt-Handlern auftauchen.
Kritische Bereiche definieren Programmteile, die immer nur ein Thread zu einem Zeitpunkt exklusiv durchlaufen kann, nämlich der, der gerade im Besitz des zugehörigen Spinlocks ist. Sie erinnern sich sicher noch an den Begriff Mutual Exclusion (= gegenseitiger Ausschluss), der diesen Sachverhalt beschreibt. Sinn des kritischen Bereichs ist der exklusive Zugriff auf eine geschützte Ressource durch maximal einen Thread. Das Betreten eines kritischen Bereichs erfolgt mittels
critical_section_enter_blocking()
und dessen Verlassen mit
critical_section_exit()
In diesen Funktionen läuft dementsprechend die Akquisition eines Spinlocks beziehungswesie dessen Freigabe ab. Das Beispiel der Critical Sections zeigt, dass sich letztlich alle Synchronisationsmechanismen tief im Inneren auf atomare Operationen wie das exklusive Prüfen und Schreiben (Test-and-Set) von Variablen zurückführen lassen. Innerhalb des kritischen Bereichs greift der jeweilige Thread exklusiv auf gemeinsame Ressourcen zu. Insofern fasst der kritische Bereich die in ihm durchgeführten Aktivitäten zu einer atomaren Operation zusammen.

Im dazugehörigen Programmbeispiel schreiben zwei Threads über die Methode changeText() immer denselben Text in die Variable buffer. Der Thread in Core 0 (Funktion: entry_core0()) schreibt 00000, während der Thread in Core 1 (Funktion: entry_core1()) 11111 schreibt. Ohne den kritischen Bereich zwischen
critical_section_enter_blocking()
und
critical_section_exit() (siehe changeText())
kommen sich die Threads beim Schreiben von buffer in die Quere, sodass dessen Inhalt bisweilen auch Werte wie 00110 oder 01000 statt immer nur entweder 00000 oder 11111 annimmt. Probieren Sie das einfach mal selbst aus, indem Sie die Funktionen für kritische Abschnitte in Kommentare setzen und an interessanten Stellen Ausgaben auf die serielle stdio-Schnittstelle schreiben.
Erklärung für das beobachtete Phänomen: Die Buchstaben des Texts werden in der Funktion changeText() einzeln geschrieben und jeweils mit einer zufälligen Wartezeit abgeschlossen, um reale Situationen zu simulieren. In der "echten" Welt würde jeder Thread hier nützliche Schritte durchführen, etwa das Einlesen von Sensorwerten oder die Ansteuerung angeschlossener Komponenten. Der Sachverhalt bleibt der gleiche. Nur durch Schutzmechanismen ist zu gewähleisten, dass ein Thread seine Aktivitäten ausführen kann, ohne dass ihm ein anderer Thread dazwischenfunkt. Viele Köche verderben den Brei.
Das Initialisieren eines kritischen Bereichs erfordert entweder die Funktion critical_section_init() oder critical_section_init_with_lock_num(). In ersterer Funktion stellt das Laufzeitsystem implizit einen unsichtbaren Spinlock zur Verfügung. Der letzteren Funktion können Programmierer explizit einen eigenen Spinlock übergeben.
#include "pico/stdlib.h"
#include "pico/multicore.h"
#include "pico/sync.h"
#include <string.h>
#include <stdio.h>// Declaration of a critical section:
critical_section_t cs1;
// buffer containing 5 characters:
char buffer[5] = "-----";
// The function used to overwrite buffer:
void changeText(char *text) {
// Wait until door opens:
critical_section_enter_blocking(&cs1);
// Overwrite the buffer char by char
for (uint16_t i = 0; i < 5; i++) {
buffer[i] = text[i];
// random delay:
sleep_ms(100 + rand() % 100);
}
// leave room:
critical_section_exit(&cs1);
}
void core1_entry() {
// core 1 thread writes 5 ones to the buffer
while (1) {
changeText("11111");
}
}
void core0_entry() {
// core 0 thread writes 5 zeros to the buffer
while(1) {
changeText("00000");
}
}
int main() {
stdio_init_all();
// initialize random number generator:
srand(42);
// Initialize critical section:
critical_section_init(&cs1);
// Start new thread in core 1:
multicore_launch_core1(core1_entry);
// Start main routine of core 0 thread:
core0_entry();
return 0;
}
Genau genommen basieren kritische Abschnitte auf Mutexes (Mutex = Mutual Exclusion). Daher können Programmierer Mutexe anstelle von Critical Sections verwenden. Im oberen Programm ließe sich ein Mutex mittels
mutex_t mx1;
vereinbaren, um es über
mutex_init(&mx1);
zu initialisieren.
Um das Mutex blockierend zu akquirieren, ist der Aufruf
mutex_enter_blocking(&mx1);
notwendig, während für die Freigabe ein
mutex_exit(&mx1);
genügt.
Das Pico-SDK bietet beim Einsatz von Mutexes wesentlich mehr Möglichkeiten als bei kritischen Abschnitten. Beispielsweise erlaubt der Aufruf von
mutex_enter_timeout_ms(&mx1, timeout)
ein zeitlich beschränktes Warten auf die Verfügbarkeit des Mutex, während
mutex_enter_block_until(&mx1, abstime);
das Warten bis zu einer absoluten Zeit erlaubt. Durch den Rückgabewert erfahren die Aufrufer, ob sie den Mutex erfolgreich akquiriert haben oder nicht. Auch Deadlocks sind dadurch vermeidbar. Es gibt noch weitere Funktionen im Pico-SDK, aber das soll es zum Thema Mutex gewesen sein.

Semaphore (altgriechisch für Signalgeber) dienen zum Signalisieren von Zuständen. Im Gegensatz zu Mutexes erlauben sie mehrere parallele Zugänge zu kritischen Bereichen, die sogenannten permits (Zugangsberechtigungen). Theoretisch könnte man binäre Semaphore, also solche mit einer einzigen Zugangsberechtigung, als Mutex betrachten – in manchen Echtzeitbetriebssystemen wie FreeRTOS basieren Mutex und Semaphor sogar auf einer gemeinsamen Implementierung. Allerdings unterscheiden sich beide Abstraktionen in der Praxis, was aber nicht Gegenstand der Diskussion sein soll (für nähere Details siehe Wikipedia-Artikel zu Semaphore [2]).
Auf dem Raspberry Pi Pico erlaubt das Pico-SDK ohnehin nur einen Thread pro Kern, weshalb die volle Flexibilität von Semaphores nur beschränkt nutzbar ist.
Was sind die wichtigen Semaphore-Funktionen in der Bibliothek?
Über
semaphore_t mySignal;sem_init(&mySignal, 1, 2);
erfolgt eine Definition eines Semaphore und seine Initialisierung. Im vorliegenden Fall besitzt das Semaphore initial eine einzige Zugangsberechtigung, kann aber maximal zwei vergeben. Die Zahl der noch nicht vergebenen Berechtigungen errechnet sich durch Aufruf von
sem_available(mySignal);
Um ein Semaphore blockierend zu akquirieren, nutzt man:
sem_acquire_blocking(&mySignal);
Soll keine Blockierung bei Nichtverfügbarkeit erfolgen, ist ein Timeout festzulegen:
sem_acquire_timeout_ms(&mySignal, 1000); // Timeout == 1000 Millisekunden
Soll sich die Zahl der Berechtigungen zur Laufzeit ändern, lässt sich folgende Funktionalität einsetzen:
sem_reset(&mySignal, newNumberOfPermits);
Zur Freigabe einer Berechtigung reicht der Aufruf:
sem_release(&mySignal);
Semaphore eignen sich übrigens auch für das Verwenden in Interrupt-Handlern, ganz im Gegensatz zu ihren Pendants wie FIFO-Queues, Queues, kritische Abschnitte und Mutexes.

Das illustrative Anwendungsbeispiel für Semaphore stammt von der Stanford University (siehe Seite 8 des Dokuments [3]). Es handelt sich um ein Erzeuger-Verbraucher-Problem. Der Erzeuger (Thread in Core 0) erzeugt zufällige Großbuchstaben in der Funktion Writer() mittels der Funktion PrepareData(). Ihm steht der Verbraucher (Thread in Core 1) gegenüber, der die Buchstaben mittels der Funktion Reader()ausliest. Zur temporären Speicherung der Buchstaben existiert ein Buffer (buffers) mit einer Kapazität von NUM_TOTAL_BUFFERS (im Beispiel auf 5 gesetzt). Für das Signalisieren der Lese- beziehungsweise Schreibmöglichkeit definiert das Programm zwei Semaphore:
emptyBuffers signalisiert, ob der Buffer geschrieben werden kann, und fullBuffers, ob der Buffer gelesen werden kann. Beide Semaphore vergeben fünf Berechtigungen. Zum Beginn der Programmausführung verfügt emptyBuffers über fünf Berechtigungen, fullBuffers über 0.Der Writer akquiriert bei jedem Schreibvorgang blockierend eine Berechtigung von emptyBuffers und gibt nach dem Schreiben eines Buchstabens eine Berechtigung von fullBuffers frei. Der Reader akquiriert umgekehrt bei jedem Lesevorgang blockierend eine Berechtigung von fullBuffers und gibt nach jedem Buchstabenlesen eine Berechtigung von emptyBuffers frei.
Da das Programm mit Berechtigungen von fullBuffers startet, ist garantiert, dass der lesende Thread erst dann Zugriff auf den Buffer erhält, sobald der schreibende Thread dort etwas hineinschreiben konnte. Die vom Reader nach jedem Lesevorgang aufgerufene Funktion ProcessData() symbolisiert eine mögliche Verarbeitung der gelesenen Daten. Im Beispiel verbringt sie lediglich eine zufällige Zeitdauer mit Warten.
Analoges gilt für PrepareData(), das die Vorverarbeitung beziehungsweise das Heranschaffen der Daten illustriert. Im Beispiel erzeugt sie einfach einen zufälligen Großbuchstaben, nachdem sie zuvor eine zufällige Zeitspanne untätig gewartet hat:
/**
* readerWriter.c
* --------------
* The canonical consumer-producer example. This version has just one reader
* and just one writer (although it could be generalized to multiple readers/
* writers) communicating information through a shared buffer. There are two
* generalized semaphores used, one to track the num of empty buffers, another
* to track full buffers. Each is used to count, as well as control access.
*/
#include "pico/stdlib.h"
#include "pico/multicore.h"
#include "pico/sync.h"
#include <stdio.h>#define NUM_TOTAL_BUFFERS 5
#define DATA_LENGTH 20
char buffers[NUM_TOTAL_BUFFERS]; // the shared buffer
semaphore_t emptyBuffers, fullBuffers; // semaphores used as counters
/**
* ProcessData
* -----------
* This just stands in for some lengthy processing step that might be
* required to handle the incoming data. Processing the data can be done by
* many reader threads simultaneously since it doesn't access any global state
*/
static void ProcessData(char data)
{
sleep_ms(rand() % 500);
// sleep random amount
}
/**
* PrepareData
* -----------
* This just stands in for some lengthy processing step that might be
* required to create the data. Preparing the data can be done by many writer
* threads simultaneously since it doesn't access any global state. The data
* value is just randomly generated in our simulation.
*/
static char PrepareData(void)
{
sleep_ms(rand() % 500);
return (65 + rand() % 26); // random uppercase letter
// sleep random amount
// return random character
}
/**
* Writer
* ------
* This is the routine forked by the Writer thread. It will loop until
* all data is written. It prepares the data to be written, then waits
* for an empty buffer to be available to write the data to, after which
* it signals that a full buffer is ready.
*/
static void Writer()
{
int i, writePt = 0;
char data;
for (i = 0; i < DATA_LENGTH; i++) {
data = PrepareData();
sem_acquire_blocking(&emptyBuffers);
buffers[writePt] = data;
printf("%s: buffer[%d] = %c\n", "Writer", writePt, data);
writePt = (writePt + 1) % NUM_TOTAL_BUFFERS;
sem_release(&fullBuffers);
// announce full buffer ready
}
}
/**
* Reader
* ------
* This is the routine forked by the Reader thread. It will loop until
* all data is read. It waits until a full buffer is available and the
* reads from it, signals that now an empty buffer is ready, and then
* goes off and processes the data.
*/
static void Reader()
{
int i, readPt = 0;
char data;
for (i = 0; i < DATA_LENGTH; i++) {
sem_acquire_blocking(&fullBuffers); // announce empty buffer
// wait til something to read
data = buffers[readPt]; // pull value out of buffer
printf("\t\t%s: buffer[%d] = %c\n", "Reader", readPt, data);
readPt = (readPt + 1) % NUM_TOTAL_BUFFERS;
sem_release(&emptyBuffers); // announce empty buffer
ProcessData(data); // now go off & process data
}
}
/**
* Initially, all buffers are empty, so our empty buffer semaphore starts
* with a count equal to the total number of buffers, while our full buffer
* semaphore begins at zero. We create two threads: one to read and one
* to write, and then start them off running. They will finish after all
* data has been written & read.
*/
int main()
{
stdio_init_all();
sem_init(&emptyBuffers, NUM_TOTAL_BUFFERS, NUM_TOTAL_BUFFERS);
sem_init(&fullBuffers, 0, NUM_TOTAL_BUFFERS);
multicore_launch_core1(Reader);
Writer(); // runs in this thread
sem_release(&fullBuffers);
sem_release(&emptyBuffers);
printf("All done!\n");
while(true);
return 0;
}
In der Ausgabe des Beispiels am seriellen Monitor ist Folgendes zu beobachten:
DATA_LENGTH) beendet sich das Programm.
Das alles funktioniert nur deshalb so gut und abgestimmt, weil die Semaphore dafür sorgen, dass der Buffer als kritische Resource keine Inkonsistenzen aufweist. Die Semaphore dienen in diesem Kontext als Signale für "Du darfst jetzt (nicht) lesen" oder "Du darfst jetzt (nicht) schreiben".
Im Pico-SDK ist Parallelisierung nur eingeschränkt möglich. Das Hauptprogramm läuft in einem Thread auf Core und kann zusätzlich einen Thread erzeugen, der auf Core 1 läuft. Erst die Verfügbarkeit von Echtzeitbetriebssystemen auf dem Pico überwindet diese Beschränkung. Trotzdem ergibt auch Multithreading mit zwei Threads Sinn. Wichtig ist dabei allerdings, die vorhandenen Synchronisationsmechanismen zu verstehen. Das gilt für die Hardware-basierte FIFO-Queue, den abstrakten und Thread-sicheren Datentyp Queue aus der Pico-Bibliothek und selbstredend auch für die bereitgestellten Synchronisationsprimitive Critical Sections, Mutexes, und Semaphores, mit denen sich eigene Bibliotheken Thread-sicher machen lassen.
Manche Entwickler scheuen sich vor dem Einsatz von Multithreading. Zu schwierig erscheint das Aufspüren von Fehlerquellen in Problemcode. Durch die Berücksichtigung bekannter Best Practices überwiegt der potenzielle Nutzen aber weit die möglichen Herausforderungen.
Damit wäre der kurze Rundgang durch Multithreading und Koordination von Threads beendet, und das Rüstzeug bereitgestellt, um responsive und effiziente Mikrocontroller-Anwendungen für den Pico zu erstellen.
URL dieses Artikels:https://www.heise.de/-6000386
Links in diesem Artikel:[1] https://raspberrypi.github.io/pico-sdk-doxygen/group__queue.html[2] https://en.m.wikipedia.org/wiki/Semaphore_(programming)[3] https://see.stanford.edu/materials/icsppcs107/23-Concurrency-Examples.pdf
Copyright © 2021 Heise Medien
Bibliotheken und Frameworks setzen auf Dependency Injection, um mehr Flexiblität im Umgang mit Abhängigkeiten innerhalb einer Applikation zu erhalten.
In Programmiersprachen wie Java und PHP ist Dependency Injection als Entwurfsmuster seit vielen Jahren etabliert. Und es hat in den letzten Jahren auch Einzug in die JavaScript-Welt gehalten. Der wohl bekannteste Vertreter der Frameworks, der dieses Entwurfsmuster nahezu durchgängig einsetzt, ist Angular. Aber auch serverseitig wird Dependency Injection (DI) beispielsweise von Nest verwendet. Stellt sich nur die Frage, warum viele andere etablierte Bibliotheken wie React dieses Entwurfsmuster komplett links liegen lassen.
Bevor wir uns im nächsten Schritt mit der konkreten Umsetzung von DI in JavaScript beschäftigen, sehen wir uns zunächst die Theorie hinter dem Entwurfsmuster an. Bei DI geht es darum Abhängigkeiten zur Laufzeit zur Verfügung zu stellen. Im Gegensatz zum Modulsystem, bei dem die einzelnen Elemente schon zum Compile- beziehungsweise Startzeitpunkt festgelegt werden, erlaubt DI eine deutlich feinere Kontrolle über die Applikation. Außerdem erleichtert DI das Testen von Objekten, indem Abhängigkeiten für die Testumgebung ausgetauscht werden. Damit DI funktioniert, stellen DI umsetzende Bibliotheken einen Mechanismus bereit, über den die injizierbaren Klassen registriert werden. Eine Klasse in der Applikation gibt dann nur noch an, welche Abhängigkeiten sie benötigt, und die Bibliothek kümmert sich darum, dass die Klasse eine Instanz der Abhängigkeit erhält. Das klingt recht abstrakt, sehen wir uns also ein konkretes Beispiel in Nest an.
Nest ist ein serverseitiges JavaScript-Framework [1], das Entwickler bei der Umsetzung von Web-Schnittstellen unterstützt. Die Funktionalität wird meist in ein oder mehrere Module aufgeteilt. Jedes Modul verfügt über Controller, die die Endpunkte der Schnittstelle enthalten. Die eigentliche Businesslogik liegt in Providern, die über DI geladen werden. Für unser DI-Beispiel setzen wir eine Schnittstelle um, die die Distanz zwischen zwei GPS-Koordinaten berechnet. Die Grundlage bildet ein fachliches Modul, das alle Belange kapselt, die mit dem Thema GPS zu tun haben, in unserem Fall ist das die Distanzberechnung. Das Modul ist im weitesten Sinn ein Container für die DI, enthält aber auch die Einstiegspunkte in das Modul. Nest arbeitet, wie auch Angular im Frontend, mit TypeScript und Decorators. Ein solcher Decorator fügt Metainformationen zu einer Klasse oder Funktion hinzu. Der nachfolgende Code zeigt das Modul, in dem bereits der Controller und der Service registriert sind:
import { Module } from '@nestjs/common';
import { DistanceController } from './distance/distance.controller';
import { DistanceService } from './distance/distance.service';
@Module({
controllers: [DistanceController],
providers: [DistanceService]
})
export class GpsModule {}
Den Einstieg stellen die Controller dar. Sie sind, wie auch Module, einfache TypeScript-Klassen, die mit Dekoratoren erweitert werden. Das folgende Listing enthält den Code des Controllers:
import { Body, Controller, Get } from '@nestjs/common';
import { Point } from 'src/point.interface';
import { DistanceService } from './distance.service';
@Controller('gps/distance')
export class DistanceController {
constructor(private readonly distanceService: DistanceService) {}
@Get() distance(@Body() coordinates: Point[]): number {
const a = coordinates[0];
const b = coordinates[1];
return this.distanceService.calculate(a, b);
}
}
Die Decorators des Controllers bestimmen das Verhalten der Schnittstelle. Der Decorator der Klasse legt den URL-Pfad fest und der Decorator der distance-Methode definiert, dass diese Methode ausgeführt wird, wenn Benutzer den Pfad gps/distance mit einem HTTP GET-Request aufrufen. Über den Body-Decorator kann die Methode direkt auf den Request-Body zugreifen. Der Controller kümmert sich lediglich um die Schnittstelle, die Extraktion der Daten aus dem Request und die Validierung der eingehenden Daten. Die eigentliche Businesslogik liegt dann nicht mehr im Controller, sondern in einem Service. Der Vorteil dieser Aufteilung ist, dass die Logik getrennt vom Request- und Response-Handling getestet werden kann.
Der Austausch des Algorithmus ist vergleichsweise einfach, da der Controller selbst nicht modifiziert werden muss, sondern lediglich die injizierte Abhängigkeit angepasst wird. Den Schlüssel bildet die sogenannte Constructor Injection. Hierbei enthält der Constructor einen Parameter, der vom Injector von Nest ausgewertet wird. Erzeugt Nest beim Start der Applikation eine Instanz des Controllers, wird der Injector tätig und generiert anhand der Konfiguration des Moduls eine Instanz des angegebenen Services. Dieser steht dann innerhalb der Controller-Klasse über die distanceService-Eigenschaft zur Verfügung. Der Code des Services selbst ist relativ unspektakulär. Er berechnet anhand zweier übergebener GPS-Koordinaten die Distanz in Metern und gibt sie zurück:
import { Injectable } from '@nestjs/common';
import { Point } from 'src/point.interface';
@Injectable()
export class DistanceService {
calculate(a: Point, b: Point): number {
const earthRadius = 6371e3;
const latARad = a.lat * Math.PI/180;
const latBRad = b.lat * Math.PI/180;
const deltaLatRad = (b.lat - a.lat) * Math.PI/180;
const deltaLonRad = (b.lon - a.lon) * Math.PI/180;
const x = Math.sin(deltaLatRad/2) * Math.sin(deltaLatRad/2) + Math.cos(latARad) * Math.cos(latBRad) * Math.sin(deltaLonRad/2) * Math.sin(deltaLonRad/2);
const c = 2 * Math.atan2(Math.sqrt(x), Math.sqrt(1-x));
return earthRadius * c;
}
}
Im einfachsten Fall sind der Name des Services, den der Injector verwendet, und der Klassenname gleich. Angenommen, der Distanz-Algorithmus soll jetzt durch eine optimierte Version ersetzt werden, kann dies entweder durch ein Ersetzen der Klasse oder durch eine Konfigurationsänderung am Modul erfolgen. Der Service wird in diesem Fall nicht mehr direkt referenziert, sondern in Form eines Objekts, wie im nachfolgenden Code zu sehen ist. In diesem Fall wird die OptimizedDistanceService-Klasse verwendet:
@Module({
controllers: [DistanceController],
providers: [{
provide: DistanceService,
useClass: OptimizedDistanceService,
}]
})
export class GpsModule {}
Neben der Flexibilität zum Austausch von Algorithmen bringt die DI gerade auch beim Testen deutliche Vorteile mit sich. Auch hier werfen wir wieder einen Blick auf die konkrete Implementierung in Nest:
import { Test, TestingModule } from '@nestjs/testing';
import { DistanceController } from './distance.controller';
import { DistanceService } from './distance.service';
const newYork = { lat: 40.6943, lon: -73.9249 };
const tokyo = { lat: 35.6897, lon: 139.6922 };
const distance = 10853705.986613212;
describe('DistanceController', () => {
let controller: DistanceController;
beforeEach(async () => {
const module: TestingModule = await Test.createTestingModule({
controllers: [DistanceController],
providers: [DistanceService]
}).overrideProvider(DistanceService).useValue({
calculate() { return distance; }
}).compile();
controller = module.get<DistanceController>(DistanceController);
});
it('should calculate the distance between New York and Tokyo', () => {
const result = controller.distance([newYork, tokyo]);
expect(result).toBe(distance);
});
});
Die Nest CLI legt für alle Strukturen, die mit ihr generiert werden, standardmäßig einen Test an. So auch für den DistanceController. Die Setup-Routine, die mit der beforeEach-Funktion definiert wird, sorgt dafür, dass vor jedem Test ein neues Test-Modul erzeugt wird. Hier können Entwickler alle Strukturen registrieren, die für einen Testlauf erforderlich sind. In unserem Fall sind das der DistanceController und der DistanceService. Wobei die Tests nicht den ursprünglichen Service, sondern einen speziell für den Test definierten Mock-Service nutzen.
Die Injector-Komponente von Nest weiß aufgrund dieser Konfiguration, dass bei jeder Anforderung nach der DistanceService-Abhängigkeit der unter useValue angegebene Wert verwendet werden soll. Dieser Mock-Service gibt für die calculate-Methode immer einen konstanten Wert für die Distanz zurück, unabhängig davon, wie er aufgerufen wird. Das hat den Vorteil, dass der Controller-Test nur den Controller selbst, nicht aber den Service testet. Die Konsequenz daraus ist, dass der Test auch nur wegen Fehlern im Controller fehlschlagen kann. Der Test selbst ruft die distance-Methode des Controllers mit einem Array aus Koordinatenpunkten auf, die an die Stelle des Request-Bodys treten. Da die Rückmeldung des Controllers synchron erfolgt, sind keine weiteren Maßnahmen wie das Einfügen von async/await erforderlich. Bleibt nur noch die Überprüfung des Ergebnisses mittels Aufrufs der expect-Funktion.
Bisher haben wir uns mit der DI von Nest nur eine integrierte Lösung angesehen. Es gibt allerdings auch Bibliotheken, die DI unabhängig vom verwendeten Framework anbieten. Diese eignen sich vor allem für individuelle Lösungen und eigene Framework-Ansätze. Ein recht populärer Vertreter dieser Art von Bibliotheken ist Inversify [2]. Die Umsetzung ist etwas aufwendiger als bei einer integrierten Lösung wie bei Nest oder Angular:
@injectable-Decorator kennzeichnet Klassen, die mit DI arbeiten. Der @inject-Decorator markiert die Stellen im Code, an denen die Abhängigkeiten eigensetzt werden.get-Methode der Container-Instanz erlaubt das Auflösen der Abhängigkeiten und somit die Arbeit mit den konkreten Objekten.React ist ein prominenter Vertreter einer verbreiteten Bibliothek, die komplett auf DI verzichtet. Im Gegensatz zu Frameworks wie Nest arbeitet React viel weniger mit Klassen. Der Großteil der Komponenten in modernen React-Applikationen sind als Funktionen umgesetzt. Diese Funktionen erhalten Informationen über die sogenannten Props in Form von Argumenten. Die Props können bei der Einbindung der Komponente beeinflusst werden, was das Testen der Komponenten einfach macht. Services in der Form, wie es sie in Nest oder Angular gibt, existieren in React nicht. In den meisten Fällen greifen Entwickler für diesen Zweck auf reine Funktionen zurück, die wiederum über die übergebenen Argumente gesteuert werden.
Beim Testen geht React auch einen anderen Weg und empfiehlt, die Komponenten mehr aus der Benutzerperspektive in Form eines Blackbox-Tests zu überprüfen. Die Testumgebung rendert die Komponenten, wie sie auch in der produktiven Applikation gerendert werden, und interagiert dann wie ein Benutzer damit, löst verschiedene Events aus und überprüft deren Auswirkungen auf die gerenderten Strukturen. Aufgaben, die typischerweise von Services abstrahiert werden, wie die Kommunikation mit einer Backend-Schnittstelle, können an den Systemgrenzen durch einen Mock des HTTP-Clients überprüft werden.
Dependency Injection ist ein Entwurfsmuster, das sich dank Frameworks wie Angular oder Nest auch in der JavaScript-Welt etabliert hat. Es eignet sich jedoch nicht in jeder Umgebung. Wo sie in klassenorientierten Applikationen ihre Stärken sehr gut ausspielen kann, ist der Einsatz von DI in einem funktionalen Ansatz eher fragwürdig. In der passenden Umgebung verwendet, erleichtert DI das Testen einzelner Einheiten deutlich und sorgt für eine Entkopplung der Strukturen, was sich wiederum förderlich beim Austausch von einzelnen Teilen der Applikation auswirkt.
URL dieses Artikels:https://www.heise.de/-5992734
Links in diesem Artikel:[1] https://nestjs.com/[2] https://inversify.io/
Copyright © 2021 Heise Medien
Bislang war in diesem Blog MicroPython das Mittel der Wahl für Projekte mit dem Raspberry Pi Pico. In der Embedded-Entwicklung spielen noch immer C beziehungsweise C++ eine herausragende Rolle. Der vorliegende Artikel illustriert deshalb, wie sich C/C++-Entwicklung für den Pico durchführen lässt.
Nach den Empfehlungen für die Installation der benötigten Werkzeugkette kommt der Beitrag auf ein kleines Beispielprojekt zu sprechen.
Nutzer können unterschiedliche Betriebssysteme einsetzen, wenn sie für den Pico als Zielsystem programmieren wollen:
Es gibt somit unterschiedliche Host-Umgebungen. Daher sind die nachfolgenden Beschreibungen bewusst allgemein formuliert. Wo nötig, erfolgen Details zu den jeweiligen Betriebssystemen. Voraussetzung für den weiter unten beschriebenen Installationsprozess ist die Verfügbarkeit von Python 3.x und Git auf dem jeweiligen Betriebssystem.
Auf Linux-Distributionen wie Debian oder Ubuntu sind folgende Schritte nötig:
sudo apt install git-all
gefolgt von:
sudo apt-get install python3 python3-pip
Mac-Besitzer benutzen Homebrew:
brew install git
brew install python3
Sofern sich bereits Xcode auf dem System befindet, ist der erste Schritt nicht notwendig, zumal Xcode eine Git-Implementierung mitbringt.
Windows-Nutzer holen sich die Git-Installation über die Downloadseite [1]. Für die Installation von Python 3 existiert ebenfalls eine Downloadseite [2].
Als Erstes ist an dieser Stelle zu erwähnen, dass sich C/C++-Programmierer unbedingt die Dokumentation zum Pico-SDK für C/C++ besorgen sollten, die sich hier [3] befindet. Dort stehen alle wesentlichen Informationen über das SDK für den Pico bereit. Als gute Einführung eignet sich darüber hinaus das Dokument "Getting started with Raspberrry Pi Pico – C/C++ development with Raspberry Pi Pico and other RP2040-based microcontroller boards [4]". [5]
Im ersten Schritt geht es um die Inbetriebnahme der notwendigen Werkzeugkette. Zunächst ist die Installation des Pico-SDKs notwendig. Dieses kopieren Entwickler über Git in ein eigenes Verzeichnis:
git clone -b master —-recurse-submodules https://github.com/raspberrypi/pico-sdk.git
Anschließend bedarf es folgender Anweisung:
cd /path/to/pico-sdk git submodule update --init
Es existiert zusätzlich ein GitHub-Repository mit Beispielen, dessen Herunterladen lohnt:
git clone -b master https://github.com/raspberrypi/pico-examples.git
Damit die Werkzeuge das SDK finden, lässt sich die Umgebungsvariable PICO_SDK_PATH definieren:
PICO_SDK_PATH="/path/to/pico-sdk“
Als nächstes sind CMake und die Entwicklungswerkzeuge von ARM erforderlich, deren Installation sich beispielsweise auf macOS wie folgt gestaltet:
brew install cmake
brew tap ArmMbed/homebrew-formulae
brew install arm-none-eabi-gcc
Für Windows 10 gibt es die notwendigen Binärdateien zum Herunterladen auf der entsprechenden CMake [6]- beziehungsweise auf der ARM-Webseite [7]. Zusätzlich installieren Windows-Nutzer die Build-Tools for Visual Studio 2019 [8].
Linux-Nutzer verwenden stattdessen:
sudo apt-get install cmake
sudo apt install gcc-arm-none-eabi
An dieser Stelle soll eine (optionale) IDE zum Einsatz kommen. Hinsichtlich C/C++ bieten sich CLion, Eclipse oder Visual Studio Code als Alternativen an. Die meisten Seiten im Internet konzentrieren sich auf Visual Studio Code, weshalb im Folgenden ausschließlich davon die Rede sein soll. Im Anschluss an die eigentliche Installation von Visual Studio Code [9] suchen Entwicklerinnen in der IDE nach der Extension CMake Tools und installieren diese zusätzlich.
Um Visual Studio Code (wie bei Windows oder Linux ohnehin der Fall) auf der Kommandozeile über „code“ aufrufen zu können, starten macOS-Nutzer die IDE, wählen mit Cmd + Shift + p oder über das View-Command Palette-Menü die Command-Palette.
Der Suchbegriff "Shell Command" führt zu einem Eintrag "Shell Command: Install 'code' command in PATH", dessen Aktivierung die IDE aus der Kommandozeile aufrufbar macht. Durch Eingabe von code öffnet sich fortan Visual Studio Code auch über die Shell. Als Argument lässt sich optional der Pfad zum gewünschten Projektordner angeben.
Um einen Build von Pico-Projekten durchführen zu können, bedarf es in der IDE verschiedener Erweiterungen, insbesondere Python, CMake und CMake Tools. Nach deren Installation in Visual Studio Code müssen In den Einstellungen für die CMake Tools noch diverse Einträge erfolgen:
Cmake: Build Environment: Hier ist als Schlüssel PICO_SDK_PATH und als Wert der entsprechende Pfad einzugeben.
Cmake: Configure Environment beziehungsweise Cmake: Environment: hier erfolgt derselbe Eintrag.

Cmake: Generator: An dieser Stelle bittet CMake um die Angabe des verwendeten Build-Werkzeugs. Auf Unix-Systemen ist dies für gewöhnlich Unix Makefiles, unter Windows NMake Makefiles. Bei Nutzung von ninja als Generator ergeben sich Probleme, weshalb Entwickler lieber auf die vorgenannten Werkzeuge vertrauen sollten.

Nun lässt sich auf einem beliebigen Ordner ein neues Projekt anlegen, und die Datei /path/to/pico-sdk/external/pico_sdk_import.cmake in den jeweiligen Ordner kopieren. Zusätzlich ist im Projektverzeichnis die Datei CMakeLists.txt bereitzustellen, die folgendermaßen aussehen muss:
# Minimal zulässige Version von CMake:
cmake_minimum_required(VERSION 3.15)
# Inkludieren des Pico-SDK:
include(pico_sdk_import.cmake)
# Name und Version des Projekts:
project(MeinPicoProjekt VERSION 1.0.0)
# Das Projekt mit einer Quelldatei verknüpfen, das das Hauptprogramm enthält:
add_executable(MeinPicoProjekt MeinPicoProjekt.c)
# Angabe der benötigten Bibliothek(en):
target_link_libraries(MeinPicoProjekt hardware_i2c pico_stdlib)
# Initialisieren des SDK:
pico_sdk_init()
# Zugriff auf USB und UART ermöglichen (1 = enable, 0 = disable):
pico_enable_stdio_usb(MeinPicoProjekt 1)
pico_enable_stdio_uart(MeinPicoProjekt 1)
# Definition notwendiger Extra-Zieldateien. Hieraus generiert das Tooling
# die für die Übertragung auf den Pico benötigte UF2-Datei:
pico_add_extra_outputs(MeinPicoProjekt)
Natürlich kann die Implementierung auch mehrere Quelldateien a.c, b.c, z.c enthalten, die alle in add_executable() auftauchen müssen.
Im Projektordner sollten nun die Dateien MeinPicoProjekt.h und MeinPicoProjekt.c (sowie eventuell andere C-/C++-Programmdateien) bereitgestellt werden. In macOS/Linux zum Beispiel über:
touch MeinPicoProjekt.h
echo '#include "MeinPicoProjekt.h"' > MeinPicoProjekt.c
Noch eine kleine Information am Rande: Falls in target_link_libraries() innerhalb von CMakeLists.txt eine Bibliothek wie hardware_i2c oder pico_stdlib als Argument auftaucht, gibt es dazu Header-Dateien, die Anwender in ihren Quelltextdateien einfügen müssen, etwa folgendermaßen:
#include "hardware/i2c.h"
#include "pico/stdlib.h"
Sie erkennen jetzt sicher das Namensschema sowie die Korrelation zwischen Bibliotheksnamen und Header-Dateien. Die oben beschriebene Datei CMakeLists.txt enthält bereits die benötigten Bibliotheken hardware_i2c und pico_stdlib.
Es empfiehlt sich zusätzlich die Bereitstellung des Werkzeugs Doxygen, das aus Quelldateien Kommentare entnimmt und daraus eine Dokumentation erzeugt. Näheres dazu findet sich auf der Doxygen-Webseite [10].
Sobald Visual Studio Code nach dem verwendeten Kit für das Projekt fragt – gemeint sind die C/C++-Compiler-Werkzeuge –, ist GCC for arm-none-eabi ?.?.? anzugeben. Auch in der unteren Statusleiste ist die Eingabe des Kits möglich (Icon mit gekreuzten Werkzeugen). Dort finden sich ebenfalls Icons zur Auswahl der gewünschten Ausgabedateien (Icon CMake mit den Optionen Debug, Release, MinSizeRel, RelWithDebInfo) sowie ein Build-Icon mit Zahnrad, das den Build-Prozess anstößt. Über die Command Palette (Submenü von View) lässt sich der Build-Prozess für das Projekt ebenfalls initiieren (Kommando CMake : Build).

Ist alles erfolgreich eingerichtet lassen sich Projekte kompilieren, übertragen und debuggen. Mit dem Kommando CMake : Build in der Command Palette lässt sich der Prozess anstoßen.

Weil diese Schritte viel Mühe machen, müsste man sie bei jedem Projekt erneut durchlaufen, hat die Raspberry Pi Foundation dafür ein spezielles Werkzeug bereitgestellt, den Raspberry Pi Pico Project Generator [11].
Dieses Werkzeug ist in Python geschrieben, lässt sich mit einer GUI starten oder auch über die Kommandozeile. Jedenfalls ersparen sich Entwickler dadurch die oberen Schritte für das Anlegen eines neuen Projekts. Dieser hilfreiche Generator findet leider viel zu selten Erwähnung.

Achtung: Der Code des Pico-Python-Generators geht davon aus, dass die ARM-Werkzeuge auf dem Pfad /usr/bin/arm-none-eabi-gcc liegen, was aber nicht stimmen muss. In meinem Fall befinden sich die Werkzeuge unter macOS auf /usr/local/bin/arm-none-eabi.gcc. Es reicht, den richtigen Pfad in der Python-Datei einzutragen oder diesen Vorgang mit einem sed-Kommando zu automatisieren.
Natürlich ist nicht zwingend eine IDE wie Visual Studio Code, CLion oder Eclipse notwendig, um C/C++-Entwicklung für den Pico durchzuführen. Information über das Arbeiten mit diesen IDEs findet sich übrigens im Getting Started Manual [12] ab Seite 31, und zwar in den Kapiteln 8, 9 und 10.
Die Arbeit auf der Kommandozeile ist mitunter sehr hilfreich, die dafür notwendigen Schritte relativ einfach – die Mithilfe des Project Generators vorausgesetzt.
Entwickler können unter der Kommandozeile beziehungsweise Shell in den Unterordner build des Projektordners wechseln, dort
cmake ..
aufrufen, und anschließend das jeweilige Make-Tool des Hostsystems, etwa make unter Unix oder nmake unter Windows, starten. CMake generiert zu diesem Zweck die passenden Makefiles. Für CMake sollten Entwickler natürlich den Pfad (Umgebungsvariable PATH) mit dem Verzeichnis der CMake-Werkzeuge ergänzen.
Zur Beobachtung des USB-Ports, an dem der Pico hängt, empfehlen sich bei kommandozeilenorientierter Entwicklung Werkzeuge wie screen (macOS), minicom (macOS, Linux), CoolTerm (macOS, Windows, Linux) oder PuTTY (Windows).
Ein Hardware-Debugger für die Pico-Entwicklung lässt sich übrigens mit Hilfe eines zweiten Pico leicht und kostengünstig realisieren. Entsprechende Anleitungen finden sich auf verschiedenen Webseiten, etwa hier [13] oder hier [14] oder hier [15].
Die Dokumentation für den Raspberry Pi Pico spricht in diesem Zusammenhang von Picoprobe. Dabei werden die SWD-Pins des Entwicklungsboards (im unteren Bild rechts) mit dem zur Probe umfunktionierten zweiten Pico verbunden (im Bild unten links). Die Firmware für die Picoprobe basiert auf OpenOCD (Open On-Chip Debugger), das ein Debuggen verschiedenster Zielsysteme ermöglicht (siehe die OpenOCD-Webseite [16]).

Die notwendige Software für die Picoprobe lässt sich über GitHub beziehen (Webseite [17]). Es genügt, die Software mit cmake und (n)make zu generieren, um sie dann als UF2-Binärdatei auf den als Hardware-Debugger genutzten "Zweit"-Pico zu übertragen. Nähere Information über Picoprobe finden sich auf dem "Getting Started"-Dokument der Raspberry Pi Foundation im Anhang A [18].
Um in Visual Studio Code die Picoprobe einzusetzen, bedarf es einzig der Extension Cortex-Debug und einer speziellen Konfigurationsdatei launch.json, die sich im Unterverzeichnis .vscode des Projektordners befinden muss. Nähere Information und den Code für Cortex-Debug sind auf dem GitHub-Repository von Marus [19] einsehbar.

Zum Schluss präsentiert dieser Beitrag ein kleines C/C++-Projekt für den Pico. Dieses Projekt kratzt nur an der Oberfläche des Pico und dient allein der Illustration. In dem Beispiel prüft ein mit Infrarot arbeitender Bewegungssensor des Typs HC-SR501 die Umgebung auf Bewegungen. Es handelt sich um einen sogenannten PIR-Sensor, wobei PIR für Passive Infrared steht.
Die Grundlagen dieser Sensoren und ein ähliches Programm für den Arduino gab es übrigens schon einmal in diesem Blog. Wen es interessiert, kann sich das damalige Posting [20] gerne noch einmal zu Gemüte führen.
Beim Erkennen einer Bewegung aktiviert das System eine LED. Statt der LED ließe sich natürlich auch eine über ein Relais geschaltete Lampe nutzen.
Bill of Material:
Komponente Preis
HC-SR501 2 Euro
LED,Drähte,220 Ohm-Widerstand 1 Euro
RPi Pico 5 Euro
Gesamt 8 Euro
Die zugehörige Schaltung sieht folgendermaßen aus:

Der PIR-Sensor wird durch GPIO-Port 10 des Pico eingelesen, die LED durch GPIO-Port 11 angesteuert. Versorgungsspannung und Erde erhält der Sensor durch den 3.3V-Ausgang des Pico sowie einen seiner GND-Pins. Ein 220-Ohm-Widerstand sorgt dafür, dass die LED nicht durchbrennt.
Alle Projektdateien befinden sich auf einem eigenen GitHub-Repository [21]. Sollten Entwickler Picoprobe zum Hardware-unterstützten Debuggen benutzen, finden sie im Repository unter .vscode auch die notwendige und dazu passende Konfigurationsdatei namens launch.json. Das Projektverzeichnis hat der Raspberry Pi Project Generator erzeugt.
Das Programm benutzt einen Interrupthandler pir_irq_handler(), der auf steigende oder fallende Flanken des Eingangspins PIR_PIN reagiert – an diesem ist der Ausgang des PIR-Sensors angeschlossen. Die Registrierung des Handlers passiert in der Methode gpio_set_irq_enabled_with_callback(), der wir unter anderem den jeweiligen Pin und die zu behandelnden Ereignisse übergeben.
Bei einer ansteigenden Signalflanke (0 => 1) hat der Sensor eine Bewegung entdeckt, weshalb das Programm die Lampe (= LED) einschaltet. Deren Ausschaltung erfolgt bei einer fallenden Flanke (1 => 0). Die Methode calibrate() wartet, bis der Sensor etwas "eingeschwungen" ist, und lässt solange die eingebaute LED des Pico im Sekundentakt blinken.
Am PIR-Sensor ist es möglich, über zwei Potentiometer jeweils Empfindlichkeit der Erkennung und die Art beziehungsweise Dauer der Erkennung einstellen. Wer mag, kann hier etwas experimentieren.

#include <stdio.h>
#include "pico/stdlib.h"
#include "hardware/irq.h"
#include "hardware/gpio.h"
#include "pico/time.h"const uint PIR_PIN = 10;
const uint LED_PIN = 11; // LED that signals motion detection
const uint BUSY_PIN = 25; // Built-in LED of Pico
const uint CALIBRATION_TIME = 6; // Calibration time in seconds
//
// IRQ handler called when rising or falling edge is detected
//
void pir_irq_handler(uint gpio, uint32_t event) {
if (event == GPIO_IRQ_EDGE_RISE) // rising edge => detection of movement
gpio_put(LED_PIN, 1); // turn LED on
else // falling edge
gpio_put(LED_PIN, 0);
}
//
// function used to calibrate PIR sensor
//
void calibrate () {
for (uint counter = 0; counter < CALIBRATION_TIME; counter++){
gpio_put(BUSY_PIN, 1);
sleep_ms(500);
gpio_put(BUSY_PIN, 0);
sleep_ms(500);
}
puts("Calibration completed");
}
int main()
{
stdio_init_all();
gpio_init(LED_PIN); // init LED Pin: used to signal motion detection
gpio_set_dir(LED_PIN, GPIO_OUT); // LED Pin is an output pin
gpio_init(BUSY_PIN); // init BUSY Pin: used to blink during calibration
gpio_set_dir(BUSY_PIN, GPIO_OUT); // BUSY Pin is an output pin
// Calibrate PIR for CALIBRATION_TIME seconds
calibrate();
// Enable interrupt handling for PIR Pin:
// Interrupt handling for rising or falling edges
gpio_set_irq_enabled_with_callback(PIR_PIN, GPIO_IRQ_EDGE_RISE | GPIO_IRQ_EDGE_FALL, true, &pir_irq_handler);
while(true); // wait forever
return 0;
}

Das initiale Aufsetzen von C/C++-Werkzeugen und -Projekten für den Raspberry Pi Pico erfordert einen hohen Aufwand. Sind die Hürden erst einmal gemeistert, geht das Entwickeln von Lösungen zügig voran. Es wäre schön, wenn auch "Embedded"-IDEs wie PlatformIO und die Arduino IDE bald eine Pico-Unterstützung anbieten, was nur noch eine Frage der Zeit sein dürfte, zumal Arduino bereits entsprechende Schritte für das hauseigene Board Arduino Nano RP2040 Connect angekündigt hat.
Vorläufig stürzen sich viele Autoren und Firmen im Internet eher auf das Programmieren des Pico mit MicroPython oder CircuitPython, was daran liegen könnte, dass die MicroPython-Bibliotheken viel Komplexität des SDKs verbergen, während dem C/C++-Entwickler der raue Wind der Embedded-Entwicklung ins Gesicht bläst. Allerdings bieten sich Anhängern von C/C++ dadurch auch mehr Flexibilität und Potenziale beim Ausschöpfen der Möglichkeiten des RP2040-Microcontrollers.
Konnte das vorliegende Posting nur mit einem kleinen Projekt aufwarten, erkunden zukünftige Folgen komplexere Beispiele.
Bis dahin viel Spaß bei den eigenen Explorationen.
URL dieses Artikels:https://www.heise.de/-5991042
Links in diesem Artikel:[1] https://git-scm.com/download/win[2] https://www.python.org/downloads/windows/[3] https://datasheets.raspberrypi.org/pico/raspberry-pi-pico-c-sdk.pdf[4] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf[5] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf[6] https://cmake.org/download/[7] https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm/downloads[8] https://visualstudio.microsoft.com/de/thank-you-downloading-visual-studio/?sku=BuildTools&rel=16[9] https://code.visualstudio.com/download[10] https://www.doxygen.nl/index.html[11] https://github.com/raspberrypi/pico-project-generator[12] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf#page31[13] https://wiki.freepascal.org/ARM_Embedded_Tutorial_-_Raspberry_Pi_Pico_Setting_up_for_Development[14] https://hackaday.io/project/177198-pi-pico-picoprobe-and-vs-code[15] https://smittytone.wordpress.com/2021/02/05/how-to-debug-a-raspberry-pi-pico-with-a-mac-swd/[16] http://openocd.org/[17] https://github.com/raspberrypi/picoprobe[18] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf#page58[19] https://github.com/Marus/cortex-debug[20] https://www.heise.de/developer/artikel/Bewegungserkennung-durch-Infrarot-Strahlung-3221542.html[21] https://github.com/ms1963/PirSensorRPiPico
Copyright © 2021 Heise Medien
+ sign #3489docker-compose #3353
remoteip to log the client remote IP instead of the local proxy IP #3226LISTEN to change the internal Apache port when running in host network mode #3343alpine:edge to test the latest PHP 8+ version #3294alpine:3.4 to test oldest supported PHP 5.6.36 version with Apache 2.4.43 #3274@-sign in database username (for Azure) #3241ceil() by intval() for edge cases with PHP8 #3404js_vars and nav_menu #3342phpcs (PHP_CodeSniffer) line length + whitespace #3488
*.phtml, *.css, *.js as well.png files as binary #3211PDO::ERRMODE_SILENT #3048Zugegeben, die Relevanz einiger GoF-Entwurfsmuster für JavaScript hält sich in Grenzen, wurden diese Entwurfsmuster doch ursprünglich dafür konzipiert, Rezepte für objektorientierte Programmiersprachen beziehungsweise das objektorientierte Programmierparadigma zu definieren.
Das Command-Pattern beispielsweise dient in erster Linie dazu, in der Objektorientierung Funktionen als Objekte zu behandeln und sie beispielsweise als Parameter einer anderen Funktion (bzw. im Kontext von Objekten: Methode) übergeben zu können. Dieses "Feature" ist in funktionalen Programmiersprachen bereits Teil des Programmierparadigmas: Funktionen sind hier "First-Class Citizens" und können wie Objekte behandelt werden, lassen sich beispielsweise Variablen zuweisen, einer anderen Funktion als Parameter übergeben oder ihr als Rückgabewert dienen.
Andere Entwurfsmuster hingegen wie das im Folgenden vorgestellte Adapter-Pattern ergeben durchaus auch in JavaScript Sinn. Der Einsatz des Adapter-Patterns in JavaScript ist vor allem dann in Betracht zu ziehen, wenn man es mit externem Code, sprich mit Third-Party-Bibliotheken zu tun hat.
Dazu ein kurzes fiktives Beispiel: Angenommen, wir haben eine Applikation, in der an verschiedensten Stellen HTTP-Anfragen ausgeführt werden müssen. Statt selbst einen HTTP-Client zu implementieren, machen wir uns auf die Suche nach einer entsprechenden Bibliothek. Schließlich soll man das Rad nicht immer neu erfinden. Zum Glück gibt es im JavaScript-Universum recht viele Bibliotheken beziehungsweise Packages, und wir werden schnell fündig: Die Wahl fällt auf das Package request [1] (Spoiler: Unser Beispiel beginnt 2018 und wir wissen noch nicht, dass diese Wahl eine weniger gute war).
Wann immer wir in unserer Applikation nun eine HTTP-Anfrage stellen möchten, binden wir request wie folgt ein:
request('https://www.heise.de', (error, response, body) => {
// usw.
});
Insgesamt machen wir das an 32 Stellen. Und weil wir so große Fans von HTTP-Anfragen sind, erhöht sich die Anzahl schon nach wenigen Wochen auf 128. Das geht einige Zeit gut, doch nach ein paar Monaten erhalten wir schlechte Nachrichten (es ist jetzt der 30. März 2019): Mikeal Rogers [2], der Hauptentwickler hinter request, markiert die Bibliothek als "deprecated" und verkündet, dass sie zukünftig nicht mehr aktiv weiterentwickelt werde [3]. Nach einigem Hin und Her und mehrstündigen Diskussionen im Team entscheiden wir uns, unseren Code auf eine andere Bibliothek zu migrieren.
Schnell fällt die Wahl dabei auf axios [4]. Über 82.000 Stargazer bei GitHub? Das ist schon mal ein gutes Zeichen. Dass wir jetzt 128 Stellen in der eigenen Applikation anpassen müssen, nehmen wir zähneknirschend in Kauf, sind dieses Mal aber schlauer. Einer im Team bringt kleinlaut hervor, dass wir vielleicht eines der GoF-Entwurfsmuster einsetzen könnten. Er habe da neulich was in einem Buch über JavaScript gelesen. Einige der Patterns seien wohl auch in JavaScript sinnvoll. Nach anfänglicher Skepsis hören wir uns den Vorschlag an.
Statt externe Bibliotheken wie request oder axios direkt zu verwenden, definieren wir uns einfach eine eigene API, gegen die wir innerhalb unserer Applikation entwickeln. Im Fall der HTTP-Client-Funktionalität könnte die API also beispielsweise wie folgt aussehen (ja, in Form einer Klasse!). Die API definiert die Methoden, die Parameter, die Rückgabewerte und in unserem Fall auch, dass es sich um eine asynchrone API auf Basis von Promises (und nicht etwa auf Basis von Callbacks) handelt. In Bezug auf das Adapter-Pattern ist diese API also die "Adapter"-Komponente, die wir innerhalb unserer Applikation (als "Client") verwenden.
class HTTPClient {constructor() {
// ...
}
async request(url, method, headers, body, config) {
return Promise.reject('Please implement');
}
async get(url, headers, body, config) {
return this.request(url, 'GET', headers, body, config)
}
async post(url, headers, body, config) {
return this.request(url, 'POST', headers, body, config)
}
// ...
}
Neben dieser internen API kommt jetzt die zweite (externe) API ins Spiel, die durch die externe Bibliothek (jetzt: axios) vorgegeben wird. Im Kontext des Adapter-Patterns handelt es sich bei dieser API um die "Adaptee"-Komponente. Das Bindeglied zwischen den beiden APIs (also zwischen "Adapter" und "Adaptee") kommt nun in Form eines "ConcreteAdapters", also einer konkreten Implementierung von HTTPClient. Für axios als Adaptee sähe eine – wohlgemerkt nur skizzierte – Implementierung wie folgt aus:
import HTTPClient from './HTTPClient';class AxiosAdapter extends HTTPClient {
constructor(axios) {
this._axios = axios;
}async request(url, method, headers, body, config) {
// hier Aufruf der "axios"-Bibliothek
// Adaptation der Parameter plus
// Adaptation des Rückgabewertes
}async get(url, headers, body, config) {
// ...
}// ...
}
Die Erzeugung der Adapter-Klasse lagern wir dabei aus, beispielsweise mit Hilfe einer Factory-Klasse (hey, noch ein GoF-Pattern!):
import axios from 'axios';
import AxiosAdapter from './AxiosAdapter';class HTTPClientFactory {
static createHTTPClient() {
return new AxiosAdapter(axios);
}}
Auf diese Weise können wir HTTP-Client-Instanzen in unserer Applikation wie folgt erzeugen und haben nichts direkt mit der externen API von axios zu tun:
import HTTPClientFactory from 'my-http-client';const client = HTTPClientFactory.createHTTPClient();
Knapp ein Jahr später – wir schreiben jetzt das Jahr 2020 – können wir uns glücklich schätzen, auf unseren Kollegen gehört zu haben. Mittlerweile wird unsere Klasse nicht mehr nur an 128 Stellen verwendet, sondern an 256! Diese würden wir nun wirklich nicht mehr alle ändern wollen.
Dass der Plan mit dem Adapter-Pattern aufgeht, merken wir auch, als es wieder soweit ist, die HTTP-Client-Bibliothek auszuwechseln: Nach einem Tweet [5] von Matteo Collina [6] werden wir auf die Bibliothek undici [7] aufmerksam. Zweimal so schnell wie der native HTTP-Client von Node.js soll sie sein. Das klingt sehr gut (zumal axios intern ja genau den nativen HTTP-Client verwendet). Sollten wir vielleicht wechseln? Klar, warum nicht?
Ist ja nicht viel Aufwand. Einfach eine neue Adapter-Klasse implementieren (hier wieder nur skizziert) ...
import HTTPClient from './HTTPClient';class UndiciAdapter extends HTTPClient {
constructor(undici) {
this._undici = undici;
}async request(url, method, headers, body, config) {
// hier Aufruf der "undici"-Bibliothek
// Adaptation der Parameter plus
// Adaptation des Rückgabewertes
}async get(url, headers, body, config) {
// ...
}// ...
}
... die Factory-Klasse anpassen ...
import undici from 'undici';
import UndiciAdapter from './UndiciAdapter';class HTTPClientFactory {
static createHTTPClient() {
return new UndiciAdapter(undici);
}}
... fertig!
Und falls wir doch wieder zur axios-Bibliothek zurückwechseln wollen, brauchen wir nur wenige Zeilen in der Factory ändern.
"Hätten wir aber auch ohne Adapter-Pattern lösen können", meint einer im Team. Ja, hätten wir. Wir hätten auch alles nur mit Funktionen funktional lösen können. Das macht die Sprache JavaScript ja gerade so vielseitig. Und ja, hinter der Klassensyntax stecken keine echten Klassen, wie man sie aus Sprachen wie Java kennt. Und ja, wegen fehlender Interfaces in JavaScript sind viele GoF-Patterns umständlich zu realisieren. Dennoch kann man nicht abstreiten, dass das objektorientierte Programmierparadigma inklusive der objektorientierten Denkweise (auch der Denkweise in Patterns) unter Entwicklern sehr verbreitet ist und sich auf diese Weise schnell ein gemeinsames Verständnis vom Code schaffen lässt.
In diesem Sinne bleibt in Bezug auf die Integration externer APIs festzuhalten:
"Objektorientiert oder funktional,
Hauptsache es passt, der Rest ist egal."
(Unbekannter Entwickler im Team)
URL dieses Artikels:https://www.heise.de/-5073865
Links in diesem Artikel:[1] https://github.com/request/request[2] https://twitter.com/mikeal[3] https://github.com/request/request/issues/3142[4] https://github.com/axios/axios[5] https://twitter.com/matteocollina/status/1298148085210775553[6] https://twitter.com/matteocollina[7] https://github.com/nodejs/undici
Copyright © 2021 Heise Medien
In den letzten Folgen war vom Raspberry Pi Pico die Rede. Bevor sich das Blog weiterhin dem Pico widmet, adressiert dieses Extra-Posting den neuen Microcontroller ESP32-C3 von Espressif. Da der Chip auf der offenen RISC-V-Architektur basiert, geht der Artikel auch auf deren Grundlagen ein.
Die intensive Nutzung von Open-Source-Software gehört für uns längst zum Alltag, egal ob Linux, OpenOffice, etliche IDEs, Bibliotheken oder Beispiele für Embedded-Entwicklung. Offene Hardware existiert zwar auch schon länger, ist aber weitaus weniger verbreitet. Mit der offenen RISC-V-Architektur könnte Open-Source-Hardware mehr Fahrt aufnehmen.
Der vorlegende Beitrag stellt zunächst die Grundlagen von RISC-V vor, um sich danach dem neuen Microcontroller ESP32-C3 von Espressif zu widmen, der RISC-V implementiert.
In der IT-Community kennt jeder die Systemfamilie der ARM-Architekturen, die Hersteller nach Zahlung von Lizenzgebühren zur Eigenentwicklung von Prozessoren nutzen können. Im Bereich der Embedded-Systeme, Mobilgeräte und SBCs (Einplatinencomputer) hat sich ARM längst durchgesetzt. Und Apple hat neuerdings begonnen, eigen entwickelte ARM-Chips sogar in Notebook- und Desktopsystemen zu verbauen.
Einer der Nachteile des ARM-Geschäftsmodells sind die Lizenzgebühren, was speziell für kleinere Hersteller zutrifft. Nicht alle Unternehmen können es sich schließlich leisten, Prozessoren zu entwerfen, die sich dem eigenen Anwendungsfall optimal anpassen. Mit der kostenfreien RISC-V-Architektur (ausgesprochen: “RISC-Five”) könnte sich daher ernsthafte Konkurrenz am Markt etablieren.
Während meines Studiums spielte RISC (Reduced Instruction Set Computer) eine wichtige Rolle. Den Anfang meines Arbeitslebens verbrachte ich folgerichtig vor RISC-basierten Sun-Workstations, unter deren Motorhaube SPARC-Chips steckten. RISC zeichnet sich gemäß der 80:20-Regel unter anderem dadurch aus, dass es sich auf wenige, häufig verwendete Maschineninstruktionen beschränkt, einen großen Satz an Registern besitzt und Instruktionen in der Regel mit der Breite von einem Maschinenwort, zum Beispiel mit 32 Bits oder 64 Bits, verwendet, deren Abarbeitung in einem CPU-Zyklus erfolgt. Das macht die Entwicklung solcher CPUs einfacher, den Bau von Compilern aber komplexer. Im Gegensatz dazu weisen CISC-CPUs (CISC = Complex Instruction Set Computer) wie die von AMD und Intel einen sehr mächtigen und dafür komplexen Befehlssatz auf. Weiterer positiver “Nebeneffekt”: Hersteller können sehr energieeffiziente RISC-CPUs bauen, womit sich Halbleiterriesen wie Intel oder AMD erfahrungsgemäß schwer tun.
Wesentliche Ingredienz jeder Prozessorfamilie ist der verwendete Befehlssatz (Instruction Set), weil er die Schnittstelle zwischen Hardwarearchitektur und Software vorgibt. Das betrifft Softwareentwickler zwar normalerweise wenig oder nicht, zumal sich durch Hardwareabstraktionsschichten wie dem Arduino Core, der JVM, der CLR oder einem Python-Interpreter die Hardware gut ausblenden lässt. Es betrifft aber die Entwickler von Compilern oder Interpretern, die für jede Hardware entsprechende Werkzeuge bereitstellen müssen. Daher wäre es von Vorteil, gäbe es einen einheitlichen Befehlssatz für Prozessoren. Das ist natürlich unrealistisch, aber ließe sich zumindest teilweise realisieren, womit wir bei RISC-V angelangt wären.
RISC-V [1]definiert einen offenen Befehlssatz, der nicht patentiert und stattdessen über eine BSD-Lizenz frei nutzbar ist. Seine Entwicklung begann 2010 an der University of California at Berkeley. Ziel war unter anderem das Bereitstellen einer eigenen Architektur für Lehrzwecke, speziell für die Vermittlung von Parallelisierung im Unterricht. Als die amerikanische DARPA und Unternehmen wie Microsoft und ST Microelectronics das Potenzial erkannten, hat sich aus dem akademischen Konzept eine Lösung für Universitäten und Industrie entwickelt.
Hauptgrund ist die Flexibilität: Die ISA (Instruction Set Architecture) von RISC-V lässt sich sowohl für die Kreierung von 32-Bit- als auch für die von 64-Bit-Prozessoren nutzen. Sogar 128-Bit-Prozessorerarchitekturen sind damit machbar, was die Zukunftssicherheit von RISC-V gewährleistet. Darüber hinaus eignet sich der zugrunde liegende Befehlssatz sehr gut für die Virtualisierung über Hypervisor, für Bare-Metal-Systeme oder als ideale Plattform für Betriebssysteme wie Linux.
Eine Hardwareplattform auf Basis von RISC-V enthält verschiedene Prozessorkerne, worunter sich auch solche befinden können, die nicht RISC-V-konform sind. Dazu stoßen gegebenenfalls Koprozessoren, die den Befehlssatz erweitern und sich in den RISC-V-Befehlsstrom integrieren. Zusätzlich existieren Accelerators (Beschleuniger), die eine abgeschlossene Funktion oder einen eigenen Kern definieren, und autonome Aufgaben leisten, etwa die der I/O-Verarbeitung.
Mithilfe dieses modularen Konzepts sind Hardwareimplementierungen vom Einkern-Microcontroller, über Many-Core-Systeme bis hin zu zu großen Clustern von Shared-Memory-basierten Netzwerkknoten denkbar.
Das Fundament von RISC-V bildet ein Befehlssatz für ganze Zahlen, der sich stark an die früheren RISC-Architekturen anlehnt. Eigentlich sind es sogar vier Befehlssätze, von denen sich einer auf 32-Bit-, ein anderer auf 64-Bit-Verarbeitung spezialisiert. Ein weiterer Befehlssatz reduziert die Zahl der Register für den Einsatz in Embedded-Controllern, während der vierte 128-Bit-Architekturen unterstützt. Alle genannten Basis-Befehlssätze sind erweiterbar. Sogar Befehle mit variablen Längen sind damit möglich (siehe RISC-V-Spezifikationen [2]).
Zu den Standarderweiterungen gehören unter anderem:
Obere Liste ist im übrigen nicht vollständig.
Wer den Befehlssatz einmal genauer unter die Lupe nehmen will, findet ihn zu Beispiel hier [3].
Die Komplexität eines RISC-V-Prozessorkerns, der alle Standard-Erweiterungen implementiert, kann also durchaus die luftigen Höhen einer General Purpose CPU erreichen.
Es gibt noch eine weitere spannende Dimension von RISC-V. Neben einer "Unprivileged"-Architektur, von der bislang die Rede war, existiert eine "Privileged"-Architektur, die einen Stack verschiedener Privilegierungsebenen definiert, angefangen von der Maschine über den Supervisor hin zu Anwendungen und Anwendern. Entwickler schreiben Code meistens für eine dieser Schichten. Code auf der Maschinenebene (M-mode) gilt üblicherweise als vertrauenswürdig und genießt die höchsten Privilegien. Dahingegen läuft Code auf der Supervisorebene (S-mode) mit weniger Privilegien ab. Hier tummeln sich zum Beispiel Betriebssysteme. Ganz oben – oder sollte ich lieber sagen ganz unten?! – laufen Anwendungen im "unterprivilegierten" U-Mode (U=User). Volume II des RISC-V Manuals zur Instruction Set Architecture adressiert die Privileged Architecture und führt entsprechende Erweiterungen ein, um Maschineninstruktionen mit verschiedenen Privilegierungsstufen zu unterstützen.
Da RISC-V "bloß" eine Spezifikation repräsentiert, heißt die Frage, ob an deren Umsetzung überhaupt jemand Interesse zeigt. Natürlich lautet die Antwort ja, weil sich dieses Posting sonst damit nicht beschäftigen würde. Beispielsweise entwickeln Western Digital und Nvidia entsprechende Implementierungen. Von der ETH Zürich stammt das RISC-V-basierte PULPino-Board.
Darf es etwas mehr sein? Zahlreiche weitere Produkte und Entwicklungen finden sich auf der Website von RISC-V. Daraus wird ersichtlich, dass RISC-V schon jetzt viele Anhänger besitzt, sowohl im universitären als auch im industriellen Bereich (siehe Liste [4]). Zum Üben mit dem RISC-V-Befehlssatz existiert eine Visual-Studio-Code-Erweiterung, die den Venus-Simulator verwendet (siehe hier [5]).
Der Embedded Bereich bietet inzwischen sogar einige Produkte für den "Hausgebrauch" wie:

Das Longan Nano lässt sich über Aliexpress für Preise ab rund 2,70 Euro erwerben und ist noch dazu kompatibel zu Arduino-Boards (siehe SiPEED-Webseite [6]).
Entwickler können folglich bereits entsprechende Produkte für bezahlbare und attraktive Preise erwerben. Daraus folgt: RISC-V ist inzwischen Realität und nicht bloß eine Sammlung von Spezifikationen. Das Explorieren kann somit beginnen.

Dankenswerterweise hat mir Espressif ein Vorserienmodell seines Boards mit dem Namen ESP32-C3-DevKitM-1 zur Verfügung gestellt. Das soll hier im Fokus stehen. Trotz des ESP32 in seinem Namen sollte man den Microcontroller ESP32-C3 eher als Evolution des ESP8266 betrachten. Genauer gesagt, positioniert er sich bezüglich Leistung und Fähigkeiten zwischen dem ESP8266 und dem ESP32.

Er soll auch zu sehr wettbewerbsfähigen Preisen auf den Markt kommen und zeigt sich wie seine Geschwister dank Bluetooth 5.0 und 2.4 GHz WiFi überaus kommunikativ. Der in 40-nm-Technik gefertigte RISC-V-Prozessor besitzt einen einzelnen Kern und erlaubt bis zu 160 MHz Taktfrequenz. Neben 384 KBytes ROM stehen 400 KBytes SRAM, darunter 16 KBytes als Cache zur Verfügung. Die Echtzeituhr verfügt darüber hinaus über 8 KByte Speicher.
Des Weiteren implementiert ein ESP32-C3 folgende Ports und Schnittstellen:

Eine integrierte PMU (Power Management Unit) sorgt mit fünf Energiestufen für die Anpassung an eigene Bedürfnisse, etwa für einen Tiefschlafmodus mit geringstmöglichem Energieverbrauch. Wer mehr Details über den ESP32-C3 erfahren möchte, findet im Web ein entsprechendes Datasheet [7].
Zum Experimentieren mit dem ESP32-C3 beziehungsweise dem Board ESP32-C3-DevKitM-1 gibt es eine gute Dokumentation [8] von Espressif. Programmieren können interessierte Entwickler entweder kommandozeilenorientiert über die ESP-IDF-Werkzeuge (siehe meinen früheren Artikel hier [9]) oder mit entsprechenden Plug-ins in Eclipse oder Visual Studio Code.
Das nachfolgende Beispiel führt zum Blinken der eingebauten LED. Das Programm nutzt die Multithreading-Unterstützung der FreeRTOS-Firmware, um den einzigen Thread jeweils gezielt für eine Sekunde anzuhalten. Der Rest der Anwendung definiert den GPIO für die eingebaute LED als Ausgang (gpio_set_direction())), setzt ihn mit reset()in einen definierten Zustand, um dann abwechselnd über ein gpio_set_level() erst ein 0- und dann ein 1-Signal auszugeben. Die printf()-Aufrufe sorgen für Textausgaben auf dem seriellen Terminal.
/* Blink Beispiel */
#include <stdio.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "driver/gpio.h"
#include "sdkconfig.h"/* Genutzt wird der konfigurierte GPIO für die eingebaute LED */
#define BLINK_GPIO CONFIG_BLINK_GPIOvoid app_main(void) {
/* GPIO zurücksetzen */
gpio_reset_pin(BLINK_GPIO);
/* GPIO für die LED ist ein Ausgang */
gpio_set_direction(BLINK_GPIO, GPIO_MODE_OUTPUT);
while(1) {
/* LED aus */
printf("LED ausgeschalten");
/* das heisst 0 am GPIO ausgeben */
gpio_set_level(BLINK_GPIO, 0);
/* 1 Sekunde Wartezeit des Threads */
vTaskDelay(1000 / portTICK_PERIOD_MS);
/* LED ein */
printf("LED eingeschalten");
/* das heisst 1 am GPIO ausgeben */
gpio_set_level(BLINK_GPIO, 1);
/* 1 Sekunde Wartezeit des Threads */
vTaskDelay(1000 / portTICK_PERIOD_MS);
}
}
RISC-V hat großes Potenzial, sich zu einer Erfolgsgeschichte zu entwickeln. Gerade Halbleiterschmieden ergreifen die Chance der offenen Befehlsarchitektur, aber auch Embedded-Hersteller nutzen die Gunst der Stunde. Ob sich die Architektur auch auf Desktops oder Notebooks durchsetzen kann, bleibt abzuwarten. Für Entwickler ist es zunächst egal, welche Hardware ein System anbietet. Indirekt hätte aber eine einheitliche Befehlsarchitektur den Vorteil eines großen Software- und Hardware-Ökosystems. Und daher bleibt die weitere Entwicklung von RISC-V spannend.
In der nächsten Folge setzt sich dieser Blog wieder mit IDEs und Projekten für den Raspberry Pi Pico auseinander.
URL dieses Artikels:https://www.heise.de/-5072875
Links in diesem Artikel:[1] https://riscv.org/[2] https://riscv.org/specifications/[3] https://6004.mit.edu/web/_static/test/resources/references/6004_isa_reference.pdf[4] https://github.com/riscv/riscv-cores-list[5] https://marketplace.visualstudio.com/items?itemName=hm.riscv-venus[6] https://longan.sipeed.com/en/[7] https://www.espressif.com/sites/default/files/documentation/esp32-c3_datasheet_en.pdf[8] https://docs.espressif.com/projects/esp-idf/en/latest/esp32c3/get-started/index.html[9] https://www.heise.de/developer/artikel/ESP32-to-go-4452689.html
Copyright © 2021 Heise Medien
Es geht weiter mit der Reise durch das Pico-Land. Während in der letzten Folge die Python-IDE Thonny zur Sprache kam, konzentrieren sich die jetzige und die kommende Folge auf Visual Studio Code für die Pico-Entwicklung unter Python und C beziehungsweise C++.
Die Thonny-IDE eignet sich sowohl für den Einstieg in die Programmiersprache Python beziehungsweise MicroPython als auch für Experimente mit dem Raspberry Pi Pico. Deshalb war meine Andeutung in der vergangenen Folge etwas despektierlich, Thonny könnte bei (semi-)professionellen Entwicklern keinen Blumentopf gewinnen. Immerhin stellt es eine ideale Spielwiese zur Verfügung.
Für größere Projekten mit komplexerem Code und mehreren Beteiligten skaliert eine einfache IDE allerdings nicht. Dort benötigen Entwickler beispielsweise Werkzeuge für Sourcecode-Verwaltung, ausgereiftere Testmöglichkeiten und leistungsfähiges Management von Ressourcen wie Bibliotheken.
Doch woher nehmen und nicht stehlen? Vier Dinge brauchen anspruchsvollere Python-Entwickler, um auf einem Linux-, macOS- oder Windows-Host Anwendungen für den Raspberry Pi Pico zu entwickeln, wobei ausschließlich 64-Bit-Betriebssysteme infrage kommen:
Übrigens: Besitzer eines Computers mit Apple Silicon dürfen sich darüber freuen, dass alle Werkzeuge auch unter einem M1-basierten System zur Verfügung stehen.
Weitere gute Nachricht: Die genannten Anwendungen sind kostenlos verfügbar.
Für die Installation der Combo liefert der Entwickler von Pico-Go, Chris Wood, bereits eine ausführliche englischsprachige Dokumentation auf seiner Webseite [2]. Deshalb an dieser Stelle nur eine grobe Zusammenfassung der entsprechenden Referenzen:
Sind alle aufgezeigten Pakete betriebsbereit, lässt sich in VS Code die Erweiterung Pico-Go von Chris Wood installieren.

Zunächst empfiehlt es sich, einen Ordner für Python-Projekte zu kreieren, diesen unter VS Code zu öffnen, mit Ctrl + Shift + p (Windows, Linux) beziehungsweise Command + Shift + p (Mac) die Kommandopalette zu laden, um das Kommando Pico-Go | Configure project via Palette auszuführen. Dadurch sind unter anderem Code-Vervollständigung und Syntaxprüfung (Lint) nutzbar.
Sobald Nutzer einen Raspberry Pi Pico an das Hostsystem anschließen, erkennt ihn Pico-Go und teilt dies über die untere Statusleiste der IDE mit.
Jetzt können Entwickler unter VS Code eine Programmdatei (Endung .py) anlegen, um dort MicroPython-Quellcode einzufügen. Das fertige Programm lässt sich über das Run-Kommando (untere VS-Code-Statusleiste!) auf dem Pico ausführen, oder mittels Upload auf das Board kopieren, worauf der Pico einen Reset durchführt und danach das Programm automatisch startet. Wichtig: Vor dem Upload einer Programmdatei sollten Entwickler sie in main.py umtaufen, weil der Pico andernfalls nur das Programm ablegt, ohne es weiter zu beachten.
Nach erfolgreicher Installation und Konfiguration von Pico-Go ist es an der Zeit, sich dem eigentlichen Thema zu widmen, einem Embedded-Projekt für den Pico. Entstehen soll mithilfe des Sensors BME280 eine kleine Wetterstation, die periodisch Temperatur, Luftfeuchtigkeit und Luftdruck misst.

Grundsätzliche Idee: Über den Pico erfolgt der Zugriff auf den BME280-Sensor, der für die Erfassung der Messwerte für Temperatur, Luftfeuchtigkeit und Luftdruck zuständig ist. Die entsprechenden Werte stellt die Wetterstation auf dem SSD1306-Display dar. Zugleich gibt es eine kodierte Regel über das augenblickliche "Klima". Liegen die Werte im angenehmen Bereich, aktiviert das Programm die grüne LED. Sind Feuchtigkeit und Temperatur jenseits der eigenen Komfortzone, leuchtet die rote LED. Liegen die Werte irgendwo dazwischen, teilt die Anwendung dies über die gelbe LED mit. Diese Regel ist als eigene Funktion kodiert und lässt sich dementsprechend anpassen. Auch die Zeitdauer zwischen den Abfragen (SLEEPTIME ist konfigurierbar).

Übrigens können durch Auflegen einer Fingerspitze auf den BME280 Temperatur und Feuchtigkeit stark nach oben steigen. Insofern lässt sich die Klimaregel manuell testen.
Für das Projekt benötigen wir folgende Stückliste:
Gesamt: ca. 29 Euro
Wer bei den üblichen Verdächtigen in China zuschlägt, kann die Anschaffungssumme noch weiter reduzieren.
Auf dem mit Fritzing gezeichneten Schaltungsdiagramm sind rechts unten das OLED-Display SSD1306 mit 128x68 Punkten Auflösung abgebildet und rechts oben der Umweltsensor BME280. Beide sind mit dem I2C-Bus des Pico verbunden, SDA liegt dort auf Pin 6 (= GPIO 4) und SCL auf Pin 7 (= GPIO 5). GPIO steht für General Purpose IO.

Achtung: Die physikalischen Pins haben keinen direkten Bezug zu ihrer logischen Bezeichnung. Der physikalische Pin 6 entspricht zum Beispiel dem logischen Pin GPIO 4, der physikalische Pin 25 dem logischen Pin GPIO 19. In Anwendungen für den Pico oder einem anderen Raspberry Pi Board sind in der Regel die logischen Namen gemeint.

Damit ist schon alles Wesentliche über die Schaltung gesagt.
Kommen wir zur Software. Im ersten Schritt ist ein Treiber für das OLED-Display SSD1306 notwendig. Den hat bereits Stefan Lehmann vom Kunststoff-Zentrum Leipzig implementiert. Der Treiber lässt sich über seine Github-Seite [7] importieren.
Für die Ansteuerung des BME280 von Bosch habe ich einige Beispielimplementierungen unter die Lupe genommen und als Vorlage für einen eigenen Treiber kodiert. Bosch Sensortec stellt zu diesem Zweck ein hilfreiches Dokument über den Sensor auf seiner Webseite [8] zur Verfügung.
Der Sensor misst neben Temperatur (in Grad Celsius) und Feuchtigkeit (in Prozent) auch den Luftdruck (in mbar beziehungsweise HectoPascal). Wer auf die Messung der Luftfeuchtigkeit verzichten kann, sollte auf die billigere Variante BMP280 zugreifen. Dieser Sensor lässt sich teilweise bereits für unter einem Euro im Internet erwerben.
Damit niemand mühsam das Beispielprogramm abtippen oder mit Copy&Paste zusammenschneiden muss, habe ich den Code auf einer Github-Seite bereitgestellt. Hier der Link für das GitHub-Repository [9].
Im Folgenden kommen hauptsächlich einige wichtige Fragmente zur Sprache, die dem Verständnis dienen.
Für die Implementierung des Programmes sind einige Bibliotheken notwendig, die meisten davon aus den Pico- beziehungsweise Micropython-SDKs. Die Bibliothek für die Ansteuerung des OLED-Displays ist, wie bereits erwähnt, auf GitHub zu finden.
from machine import Pin, I2C # Wir brauchen Pin und I2C des Pico
from micropython import const
from ustruct import unpack as unp
from ssd1306 import SSD1306_I2C # Modul für SSD1306
import utime # Zwei Zeit-Bibliotheken
import time
Für die Entscheidung, ob das Wetter gut, schlecht, mittel ist, fungiert die Funktion condition(). Diese enthält eine eigene Regel, die jeder für sich selbst ändern kann:
#--Condition ----------------------
COND_RED = 1 # Schlechtes Klima
COND_GREEN = 2 # Angenehmes Klima
COND_YELLOW = 3 # Mittleres Klima
#----------------------------------ComfortZoneTemp = (15,25) # Meine Komfortzone für Temperatur liegt zwischen 15 und 25 Grad
ComfortZoneHumi = (10,40) # Meine Komfortzone für Feuchtigkeit liegt zwischen 10 und 40%
#
def condition(temperature, humidity, pressure):
niceTemperature = temperature >= ComfortZoneTemp[0] and temperature <= ComfortZoneTemp[1]
niceHumidity = humidity >= ComfortZoneHumi[0] and humidity <= ComfortZoneHumi[1]
if niceHumidity and niceTemperature:
return COND_GREEN
elif (niceHumidity != niceTemperature): # XOR
return COND_YELLOW
else:
return COND_RED
Die Anwendung initialisiert den I2C-Bus zum Zugriff auf BME280 und SSD1306:#
Die Anwendung initialisiert den I2C-Bus zum Zugriff auf BME280 und SSD1306:
sda = Pin(4) # BME280 und SSD1306 sind an GPIO 4 und 5 angeschlossen
scl = Pin(5)
i2c = I2C(0,sda=sda,scl=scl,freq=400000) # I2C-Bus 0
i2c_addr_bme = 0x76 # Ich gehe davon aus, der BME280 liegt an 0x76
Die LEDs befinden sich an den GPIO-Ports 19, 20, 21:
GreenLED = Pin(21, Pin.OUT) # Grüne LED an GPIO 21
YellowLED = Pin(20, Pin.OUT) # Gelbe LED an GPIO 20
RedLED = Pin(19, Pin.OUT) # Rote LED an GPIO 19
Die Variable SLEEPTIME legt die Zeit zwischen zwei Messungen fest:
SLEEPTIME = 5
Hinter der Klasse BMX280 verbirgt sich der Treiber für den Umweltsensor. Deren Konstruktor nimmt etliche Initialisierungen vor. Interessant für Anwender ist hauptsächlich die Methode measure(), weil sie Druck, Feuchtigkeit und Temperatur zurückliefert.
class BMX280:
# Im Konstruktor werden primäre Datenmember und Konstanten belegt
def __init__(self, i2c, i2c_addr_bme)
def measure(self)
# ... diverse Hilfsmethoden ...
Das Hauptprogramm der Software sucht zunächst nach Sensoren und Aktoren am I2C-Bus – optional, weil abhängig von der Belegung der boole’schen Variable debug.
if debug:
print('Ich habe an folgenden Adressen Komponenten am I2C-Bus entdeckt:')
devices = i2c.scan()
if devices:
for i in devices:
print(hex(i))
utime.sleep_ms(2000)
Gilt debug == True, erfolgt an weiteren Stellen die Bildschirmausgabe am Terminal der IDE.
Anschließend initialisiert die Anwendung die Treiber für SSD1306 (Klasse SSD1306_I2C) und BME280 beziehungsweise BMP280 (Klasse BMX280).
In der Hauptschleife liest der Code über measure() die Wetterwerte ein, aktiviert abhängig von den Messwerten entweder die rote, grüne oder gelbe LED, und stellt die Werte am OLED-Display dar. Nach einer Wartezeit folgt der Übergang zur nächsten Messrunde:
oled = SSD1306_I2C(128,64,i2c)
bme = BMX280(i2c = i2c, i2c_addr_bme = i2c_addr_bme)oled.fill(0)
oled.show()# HAUPTSCHLEIFE #
while True:
temperature, humidity, pressure = bme.measure()
#......................
currentState = condition(temperature, humidity, pressure)
if currentState == COND_GREEN:
GreenLED.value(1)
YellowLED.value(0)
RedLED.value(0)
if debug:
print("Angenehmes Klima")
elif currentState == COND_YELLOW:
GreenLED.value(0)
YellowLED.value(1)
RedLED.value(0)
if debug:
print("Geht so")
elif currentState == COND_RED:
GreenLED.value(0)
YellowLED.value(0)
RedLED.value(1)
if debug:
print("Unangenehmes Klima")
# ......................
oled.fill(0)
oled.text("Heise Wetter", 5, 10)
# Formatierte Ausgabe mit 7 Ziffern bei 2 Nachkommastellen
oled.text(str('% 7.2f' % temperature) + " Grad", 5,20)
oled.text(str('% 7.2f' % humidity) + " %",5,30)
oled.text(str('% 7.2f' % pressure) + " HPa",5,40)
# Und jetzt enthuellen
oled.show()
utime.sleep(SLEEPTIME) # Schlafen bis zur nächsten Messung
Der fertige und funktionierende Versuchsaufbau sieht folgendermaßen aus:

Das Beispielprojekt hat erste Einblicke in die MicroPython-Programmierung des Pico unter Visual Studio Code gegeben. Ein Problem, das sich momentan noch zeigt, sind fehlende Module für die Ansteuerung einiger Bauteile, insbesondere von Breakout-Boards und komplexeren Sensoren. Da der Pico noch sehr neu ist, dürfte sich dies in den nächsten Monaten ändern und dadurch ein ähnlich breites Ökosystem entstehen, wie es bei Arduino, Espressif (ESP32, ESP8266), Raspberry Pi Single-Board-Computer, Adafruit, Sparkfun und ST Microelectronics bereits der Fall ist.
Natürlich gibt es für das gezeigte Beispiel diverse Optimierungsmöglichkeiten, etwa:
Interessierte Leser haben also noch genug Möglichkeiten, sich weiter auszutoben.
Der Fokus dieses Artikels lag auf MicroPython. Übrigens existiert auch CircuitPython (entwickelt von Adafruit) als Alternative, aber davon soll nicht weiter die Rede sein, da die konzeptionellen Unterschiede eher marginal sind. In der nächsten Folge geht es um die Programmierung mit C beziehungsweise C++.
Bis dahin viel Spaß beim Picomentieren.
URL dieses Artikels:https://www.heise.de/-5066047
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/VS-Code-lebt-Entwicklung-von-Embedded-Software-mit-PlatformIO-4464669.html[2] http://pico-go.net/docs/start/quick/[3] https://www.python.org/downloads/[4] https://nodejs.org/en/download/[5] https://code.visualstudio.com/download[6] https://code.visualstudio.com/insiders/[7] https://github.com/stlehmann/micropython-ssd1306[8] https://www.bosch-sensortec.com/media/boschsensortec/downloads/datasheets/bst-bme280-ds002.pdf[9] https://github.com/ms1963/DerPragmatischeArchitekt-WetterStation
Copyright © 2021 Heise Medien
Der letzte Artikel [1]hat das neue Board Raspberry Pi Pico vorgestellt. In diesem und den nachfolgenden Teilen ist von den verschiedenen Möglichkeiten die Rede, wie sich das Board zum Leben erwecken lässt. Die Reise beginnt mit der kostenlosen Python-IDE Thonny.
Die Thonny-IDE bietet eine Python-Shell, die eher einfachen und mittleren Ansprüchen genügt. Für höhere Anforderungen haben ihre Schöpfer sie allerdings auch nicht entwickelt. Ihre Entwicklung erfolgte durch die University of Tartu in Estland, um einen einfachen Einstieg in das Programmieren mit Python zu ermöglichen.
Um die Programmierung für das Pico-Board zu illustrieren, ist das aber mehr als ausreichend. Bevor die Artikelreihe auf ausgefeilte IDEs für Pros zu sprechen kommt, verhilft Thonny-IDE zu ersten Erfahrungen mit dem Raspberry Pi Pico. Darüber hinaus ist die freie IDE auf Raspberry Pi OS bereits vorinstalliert, sodass Raspi-Nutzer nichts weiter zu tun haben und sich jetzt gemütlich zurücklehnen können. Zu guter Letzt sei angemerkt, dass die Programmierumgebung eine vollständige Implementierung von Python 3.7 mitbringt, weshalb sich keine weiteren Installationsorgien als notwendig erweisen.
Auf der Thonny-Webseite [2] lassen sich Versionen für Windows, macOS oder Linux-Distributionen herunterladen:
Nach Durchführung des Downloads auf Windows oder macOS starten Anwender die Installation durch Ausführung des Installationspakets. Linux-Anwender nutzen entweder ihren jeweiligen Paketmanager oder andere Möglichkeiten zur Installation (siehe Thonny auf GitHub [3]).
Exemplarisch die Illustration für Windows-PCs. Nach Start der Installation ergibt sich folgendes Bild:
Danach findet sich das Programm auf dem Zielsystem. Bei Start der fertig installierten IDE öffnet das schlichte IDE-Fenster von Thonny, das in der oberen Hälfte einen Editor und in der unteren Hälfte eine REPL-Shell (Read Eval Print Loop) enthält. Fürs interaktive Experimentieren bietet die Shell eine ideale Spielwiese.
Unten rechts im Fenster zeigt Thonny den aktuell genutzten Python-Interpreter textuell an, im vorliegenden Fall also Python 3.7.9. Allerdings laufen auf den meisten Embedded Boards nur abgespeckte Python-Varianten wie CircuitPython oder MicroPython, wobei der Pico per default Letzteres unterstützt.
Um die geeignete Variante zu erhalten, genügt ein Mausklick auf das Textfeld "Python 3.7.9". Anschließend bietet Thonny ein Auswahlmenü mit allen unterstützten Interpretern, unter anderem "MicroPython (Raspberry Pi Pico)":

Vor der Selektion von MicroPython sollten Entwickler das Raspberry-Pi-Pico-Board mit gedrückter BOOTSEL-Taste an einen USB-Eingang des Hostrechners anschließen. Dadurch identifiziert sich das Board gegenüber dem Host als Speichergerät, etwa als Speicherstick. Anschließend wählen Entwickler wie oben erwähnt in Thonny die Option "MicroPython (Raspberry Pi Pico)" als zu installierenden Interpreter, worauf folgender Dialog erscheint:
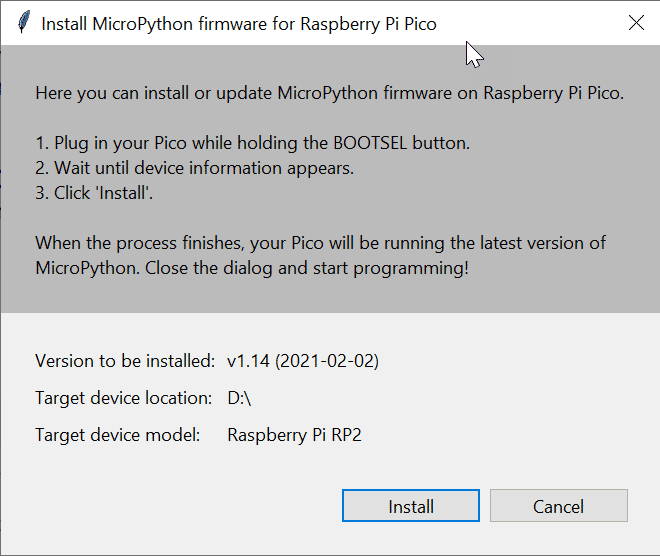
Klicken Anwender auf den Install-Button, startet die Installation der MicroPython-Firmware. Nach Beendigung der Firmware-Installation müssen Anwender nur noch das Dialogfenster schließen:
Die Firmware besteht aus einem lauffähigen Programm mit der Endung .UF2. Sie lässt sich auch manuell auf den Pico übertragen.
Nun sind Host und Pico miteinander verbunden, und Entwickler können entweder über die REPL-Shell direkt mit dem MicroPython-Interpreter arbeiten oder alternativ ein Programm in den Editor eingeben. Wichtig ist an dieser Stelle, dass nach Übertragen eines MicroPython-Programms auf das Board (Endung: .py) das Board erst herunter- und dann wieder hochfährt, worauf das Laufzeitsystem automatisch das Python-Programm ausführt.
Befinden sich allerdings mehrere Programmdateien auf dem Board, weiß der Pico zunächst nicht, welche er ausführen soll. In diesem Fall sucht er nach einer Datei namens main.py, um sie auszuführen oder verharrt regungslos, sollte er diese Datei nicht finden.
Jetzt ist es endlich an der Zeit, ein einfaches MicroPython-Programm zu schreiben, um den Zugriff auf das I/O-System des Boards zu testen. Wie traditionell üblich, soll das erste Programm die interne LED des Pico zum Blinken bringen, bevor wir in nachfolgenden Folgen weitere Möglichkeiten des Pico kennenlernen:
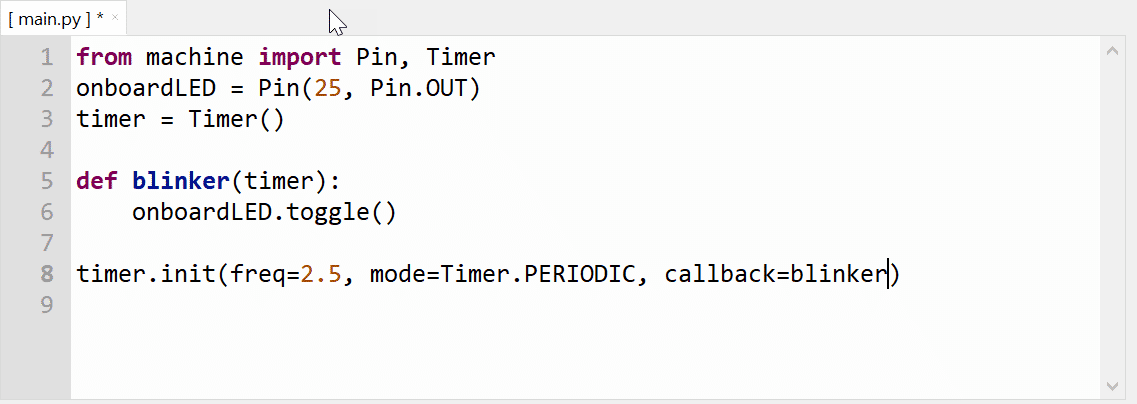
Nun sezieren wir das Programm Schritt für Schritt:
from machine import Pin, Timer
Die import-Anweisung nutzt aus der machine-Bibliothek die Komponenten Pin und Timer. Erstere erlaubt den Zugriff auf die I/O-Ports des Pico, Letztere stellt Funktionen zur zeitlichen Steuerung von Aktionen zur Verfügung. Überhaupt enthält – nomen est omen – machine diverse Komponenten zum Zugriff auf die Pico-Hardware.
onboardLED = Pin(25, Pin.OUT)
Nun erfolgt die Initialisierung der Variablen onboardLED. Sie soll GPIO-Port 25 repräsentieren, an dem sich die eingebaute LED befindet. Wichtig: Die Zahlen beziehen sich nicht auf das physikalische Pin 25, sondern auf den GPIO-Port 25, für den es noch nicht einmal einen physikalischen Pin gibt.

Der zweite Parameter im Konstruktor namens Pin teilt dem Interpreter mit, wie der I/O-Port verwendet werden soll, nämlich im vorliegenden Fall als Ausgabe-Port. Daher die Konfiguration mit Pin.OUT.
timer = Timer()
Hier initialisiert das Programm die Variable timer. Dazu gleich mehr.
def blinker(timer):
onboardLED.toggle()
Die Methode blinker erhält als Argument ein initialisiertes timer-Objekt. Immer wenn der timer dazu die Initiative gibt, erfolgt der Aufruf der toggle-Methode. Die setzt den Ausgang abhängig von deren momentanen Zustand entweder von 0 auf 1 oder von 1 auf 0, was folglich zum Blinken der LED führt.
timer.init(freq = 2.5, mode = Timer.PERIODIC, callback = blinker)
In der Initialisierungsmethode init definiert das Programm einen periodisch feuernden Timer (Timer.PERIODIC) mit einer Frequenz von 2,5. Daraus folgt eine Periode von 400 Millisekunden. timer ruft zu diesem Zweck alle 400 Millisekunden eine Callback-Funktion auf (callback = blinker). In unserem Fall ist das die blinker-Methode, die dementsprechend alle 400 Millisekunden das Ausgangssignal für die LED invertiert.
Nach getaner Arbeit können Entwickler entweder für die direkte Programmausführung auf dem Pico sorgen, indem sie auf das grüne Icon oder den entsprechenden Menüpunkt klicken. Oder sie sichern das Programm auf das Pico-Board, worauf das Board resettet, um anschließend mit der Programmausführung zu beginnen. Selbstredend lässt sich die Programmdatei auch auf dem Hostrechner abspeichern:
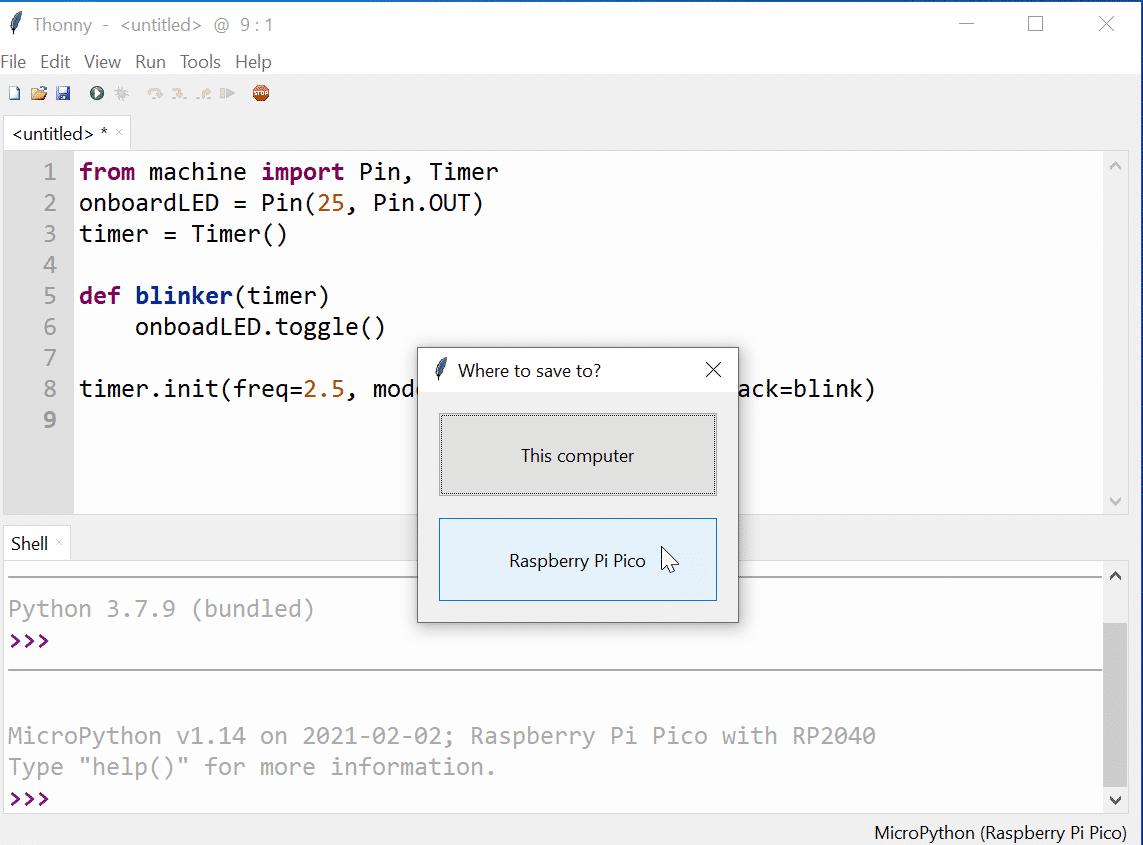
Wenig überraschend sollte sich jetzt folgendes Geschehen zeigen:

Damit wäre das erste MicroPython für den Raspberry Pi Pico geschafft. Zwar ein triviales Beispiel, aber ein lehrreicher erster Schritt.
Dieser Artikel hat sich in seichtem Wasser bewegt. Die Thonny-IDE taugt als ideale Spielwiese, um den Pico interaktiv kennenzulernen. Als professionelle Entwicklungsumgebung kann sie hingegen nicht fungieren. Sie macht allerdings den Einstieg sehr leicht, was schließlich der Sinn des vorliegenden Artikels war. Ich hoffe, Sie haben jetzt noch viel Spaß mit eigenen Experimenten. In den nächsten Teilen wird das Fahrwasser etwas rauer, aber auch unterhaltsamer.
URL dieses Artikels:https://www.heise.de/-5057160
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/Ein-Picobello-Microcontroller-Raspberry-Pi-Pico-Board-5045274.html[2] https://thonny.org[3] https://github.com/thonny/thonny/wiki/Linux[4] https://datasheets.raspberrypi.org/pico/raspberry-pi-pico-python-sdk.pdf[5] https://micropython.org[6] https://micropython.org/download/rp2-pico/
Copyright © 2021 Heise Medien
Micro Frontends verfolgen einen ähnlichen Ansatz wie Microservices, nur in einer völlig unterschiedlichen Umgebung. Daher ergeben sich auch andere Vor- und Nachteile sowie eine veränderte Herangehensweise bei der Konzeption und Umsetzung.
Serverseitig hat sich das Architekturmuster der Microservices gerade für umfangreiche Applikationen als Alternative zu einem monolithischen Ansatz etabliert. Einen ähnlichen Zweck verfolgen Entwickler mittlerweile auch im Frontend mit Micro Frontends. Die Idee dahinter ist, einige der Vorteile von Microservices auch im Frontend nutzbar zu machen. Doch bevor wir uns der Frage widmen, ob Micro Frontends der neue Standard für die Entwicklung von Web-Frontends werden, werfen wir einen Blick auf die Microservice-Architektur.
Die Idee hinter Microservices ist, ein großes Problem in mehrere Teilprobleme zu zerlegen und sie getrennt voneinander zu bewältigen. Dieser Architekturansatz geht noch einen Schritt weiter als eine gewöhnliche Modularisierung von Applikationen, da hier nicht der Schnitt an fachlichen Grenzen innerhalb einer Applikation gemacht wird, sondern das Ganze noch weiter geht und die Bereiche in einzelne, unabhängige Systeme teilt, die durch Schnittstellen miteinander verbunden sind. Die Vorteile, die durch eine solche Microservice-Architektur entstehen, sind:
Sicherlich hat eine Microservice-Architektur nicht nur ihre Vorteile. Die Komplexität in der Kommunikation zwischen den einzelnen Services steigt deutlich an. Hinzu kommt, dass es sich hierbei um Kommunikation zwischen eigenständigen Systemen handelt. Die Entwickler müssen sich also um Problemstellungen wie potenziellen Nachrichtenverlust, synchrone- und asynchrone Kommunikation kümmern. Entwickeln die einzelnen Service-Teams unabhängig voneinander, erfordert dies einen zusätzlichen Koordinationsaufwand, wenn es um die Versionierung der Services geht. Hierbei muss sichergestellt sein, dass die Services der Applikation untereinander kompatibel bleiben.
Micro Frontends verfolgen einen ähnlichen Ansatz wie Microservices, jedoch in einer völlig anderen Umgebung. Daraus ergibt sich eine andere Bewertung der Architekturform. Wo sich eine Microservice-Architektur für eine Vielzahl von Applikationen lohnt, sind die Anwendungsfälle für Micro Frontends deutlich eingeschränkter.
Doch werfen wir zunächst einen Blick auf die wesentlichen Unterschiede zwischen Frontend und Backend und wie sie sich auf die Architektur auswirken. Der Browser führt eine Applikation als einzelne Instanz aus. Im Gegensatz dazu sind Backend-Services unabhängig voneinander (man hat also mehrere Instanzen). Das wirkt sich vor allem auf die Skalierbarkeit der Applikation aus. Bei einer Lastspitze fährt die Backend-Infrastruktur zusätzliche Instanzen der betroffenen Services hoch und verteilt die Last entsprechend. Ist der Browser unter Last, bringt es zugegebenermaßen wenig, ein weiteres Browserfenster mit einer neuen Instanz der Applikation zu öffnen. Der Browser kann nur auf Worker-Prozesse zugreifen, die allerdings vom Rendering abgekapselt sind und lediglich für Berechnungen und Serverkommunikation eingesetzt werden können.
Das Skalierungsverhalten von Front- und Backend unterscheidet sich also grundlegend. Auch beim Thema Robustheit gibt es gravierende Unterschiede: Hier wird häufig das Bild von Pets vs. Cattle aufgegriffen, also der Unterschied zwischen Haustieren und Nutztieren. In einer Microservice-Architektur sind die einzelnen Instanzen wie Nutztiere, zu denen die Betreiber der Plattform ein eher distanziertes Verhältnis pflegen sollten. Stürzt ein Service ab, wird er durch eine neue Instanz ersetzt. Im Browser lässt sich eine solche Vorgehensweise nicht realisieren, denn es gibt nur den einen Hauptprozess. Stürzt dieser ab, war's das. Die Entwickler sollten ihn also mit umfangreicher Fehlerbehandlung hegen und pflegen wie ein Haustier.
Das Thema Einfachheit betrifft sowohl Front- als auch Backend. Kleinere Einheiten, die für sich stehen, sind in beiden Welten deutlich einfacher zu handhaben als ineinander verflochtene, umfangreiche Konstrukte. Die Flexibilität, die eine Microservice-Architektur im Backend hinsichtlich der Wahl der Sprachen und Technologien bietet, muss im Frontend auch wieder differenziert betrachtet werden. Im Backend können die Entwickler die für die jeweilige Problemstellung passende Kombination aus Programmiersprache, Frameworks und Bibliotheken auswählen. Der Browser schränkt diese Auswahl im Frontend deutlich ein. Neben JavaScript und zu einem geringen Teil WebAssembly lässt er keine weiteren Programmiersprachen direkt zu. Eine Ausnahme bilden hier nur Sprachen, die in JavaScript oder WebAssembly übersetzt werden, wie es mit TypeScript, CoffeeScript oder C# in Form von Blazor der Fall ist.
Bleibt also nur noch die Auswahl an Bibliotheken und Frameworks, die in diesem Bereich zugegebenermaßen sehr umfangreich ist. Besteht eine Applikation aus mehreren kleinen Teilen und sind diese mithilfe verschiedener Bibliotheken und Frameworks umgesetzt, lädt der Browser die erforderlichen Ressourcen zur Darstellung der Applikation vom Server, was einen erheblichen Overhead im Vergleich zu einer traditionell monolithisch aufgebauten Applikation bedeuten kann.
Bei einer Micro-Frontend-Architektur setzt sich die Applikation aus mehreren voneinander unabhängigen Micro Frontends zusammen. Diese einzelnen Bestandteile werden in einer Integrationsschicht zusammengefügt. Das wird nötig, da es für den Browser immer ein Dokument gibt, das er initial vom Server lädt. Beim Aufbau einer Micro-Frontend-Architektur gilt Ähnliches wie bei den Microservices im Backend: Es gibt nicht den einen richtigen Weg, sie umzusetzen, vielmehr existieren zahlreiche Facetten dieser Architekturform.
Die einfachste Möglichkeit besteht darin, die einzelnen Micro Frontends über iFrames einzubetten. Diese Variante ist zwar nicht sonderlich elegant, stellt jedoch sicher, dass die einzelnen Teile der Applikation tatsächlich unabhängig voneinander sind. Weitere Möglichkeiten sind die Kapselung der Micro Frontends in Web Components oder der Einsatz von zusätzlichen Bibliotheken wie single-spa, die die friedliche Koexistenz verschiedener Frontend-Frameworks in einer Applikation erlauben.
Ein großes Problem bei der Umsetzung von Micro Frontends mit verschiedenen Bibliotheken ist die bereits erwähnte Paketgröße, da im schlechtesten Fall mehrere vollwertige Frameworks parallel ausgeliefert werden müssen. Dieses Problem lässt sich nur auf zwei Arten lösen: Entweder werden keine größeren Bibliotheken eingesetzt oder die Entwicklerteams der einzelnen Micro Frontends einigen sich auf gewisse Konventionen. So kann die Verwendung nur eines Frameworks festgelegt werden, und die Teams entwickeln dann nicht komplett eigenständige Applikationen, sondern Module, die die Integrationsschicht zusammenführt. Der Entwicklungsprozess einer solchen Architektur ist also geprägt von Kompromissen und einer Gratwanderung zwischen völliger Flexibilität und Einschränkungen durch Konventionen. Wie die Vorgehensweise konkret aussieht, hängt stark vom Einsatzzweck und den Rahmenbedingungen der Gesamtapplikation ab.
Wie über so ziemlich jedes Thema in der Entwicklung, werden auch über Micro Frontends leidenschaftliche Diskussionen geführt. Und wie so oft sollte jeder auch dieser Architekturform seine Daseinsberechtigung zusprechen. Natürlich sind Micro Frontends nicht die Silver Bullet, die alle Probleme in der Web-Entwicklung lösen. Aber gerade für umfangreiche Applikationen mit mehreren beteiligten Teams kann eine Micro-Frontend-Architektur eine potenzielle Lösung sein.
Ein Szenario, in dem Micro Frontends ihre Stärke wirklich ausspielen, sind Migrationen. Hat eine bestehende Applikation ihren Zenit überschritten, steigen die Kosten für die Wartung und Weiterentwicklung deutlich an und für die Entwickler ist die Arbeit an einem solchen gewachsenen Stück Software kein wirkliches Vergnügen mehr. Also steht irgendwann die Frage eines Rewrites im Raum. Das Neuschreiben einer Applikation birgt jedoch beträchtliche Risiken, die bis hin zum Scheitern des Unterfangens reichen.
Eine Migration der alten Software mithilfe einer Micro-Frontend-Architektur auf die neue Version ist eine Möglichkeit, die Risiken in den Griff zu bekommen. Hierfür schaffen die Entwickler zunächst die Integrationsschicht, in die die bestehende Software eingebettet wird, sodass sie funktioniert wie bisher. Anschließend können sie sich schrittweise daran machen, die Features durch neue Versionen zu ersetzen. Die Integrationsschicht sorgt dann dafür, dass die Benutzer die neue Version erhalten und die alte Version wird abgeschaltet.
Sobald alle Features migriert sind, kann die alte Applikation gelöscht und auch die Integrationsschicht kann, falls sie nicht mehr benötigt wird, zurückgebaut werden. Der Vorteil dieser Vorgehensweise ist, dass es keinen Big-Bang-Release gibt, die Migration schleichend erfolgt und es zu keinem Stillstand bei der Entwicklung neuer Features kommen muss.
Abschließend bleibt nur noch zu sagen, dass jedes Team die Entscheidung für die Architektur seiner Applikation selbst treffen muss. Es ist dabei allerdings hilfreich, möglichst viele verschiedene Alternativen zu kennen und die jeweils beste auszuwählen. Ob es also ein sauber modularisierter Monolith oder eine Micro-Frontend-Architektur wird, hängt von der Problemstellung und den Vorlieben der Entwickler ab.
URL dieses Artikels:https://www.heise.de/-5057255
Copyright © 2021 Heise Medien
Für die Arbeit mit der Systemzwischenablage stellt die W3C-Spezifikation "Clipboard API and events" zwei APIs zur Verfügung: die synchrone "Clipboard Event API" und die asynchrone "Asynchronous Clipboard API".
Der programmatische Zugriff auf die Zwischenablage innerhalb einer Webanwendung hat in den letzten Jahren einen Wandel durchgemacht. Noch vor ein paar Jahren griff man gerne auf Bibliotheken wie ZeroClipboard [1] zurück, die unter der Haube Flash voraussetzten. Mit dem Verschwinden von Flash in die Bedeutungslosigkeit verloren allerdings auch diese Bibliotheken an Bedeutung. Die execCommand API [2] wiederum, über die man unter anderem programmatisch Befehle wie das Kopieren oder Einfügen ausführen kann, leidet unter Interoperabilitätsproblemen, gilt mittlerweile als veraltet [3] und wird aller Voraussicht auch nicht mehr über den Status eines "Unofficial Draft" hinauskommen. Hinzu kommt, dass hierüber Daten nur aus dem DOM gelesen und auch nur in das DOM geschrieben werden können:
// Achtung: veraltet!// Kopieren
const source = document.querySelector("#source");
source.select();
document.execCommand("copy");// Und Einfügen
const target = document.querySelector("#target");
target.focus();
document.execCommand("paste");
Beim W3C liegt der Fokus der Entwicklung daher auf der Spezifikation "Clipboard API and events" [4], die aktuell als Working Draft vorliegt. Sie definiert für die Arbeit mit der Systemzwischenablage zwei verschiedene APIs: die Clipboard Event API [5] (bzw. Synchronous Clipboard API) und die relativ neue Asynchronous Clipboard API [6].
Die Clipboard Event API [7] bietet zum einen die Möglichkeit, sich in die gängigen Operationen auf der Zwischenablage "einzuhaken", sprich auf Events zu reagieren, die beim Ausschneiden, Kopieren und Einfügen ausgelöst werden sowie zum anderen synchron schreibend und lesend auf die Zwischenablage zuzugreifen.
Für Ersteres definiert die API vier verschiedene Events:
Auf diese Events kann man, wie in folgendem Listing gezeigt, über entsprechende Event-Listener reagieren. Der EventListener für das copy-Event definiert, was passieren soll, wenn innerhalb der Webseite eine Kopieraktion durchgeführt wird. Über die Eigenschaft clipboardData des entsprechenden Events gelangt man an ein Objekt vom Typ DataTransfer. Zur Erinnerung: Dieses Objekt repräsentiert ein Objekt, das ursprünglich für den Datentransfer bei Drag&Drop-API-Aktionen [8] zuständig ist. Über die Methode setData() können an diesem Transferobjekt die zu übertragenden Daten definiert werden, wobei der Methode als erster Parameter das Format der Daten (in Form des MIME-Typen) und als zweiter Parameter die eigentlichen Daten übergeben werden. Auf der Gegenseite (innerhalb des Event-Listeners, der für die Einfügeoperation zuständig ist) werden analog über die Methode getData() unter Angabe des MIME-Typen die Daten aus dem Transferobjekt gelesen.
document.addEventListener('copy', (event) => {
const { clipboardData } = event;
clipboardData.setData(
'text/plain',
'Dieser Text kommt synchron in die Zwischenablage.'
);
event.preventDefault();
});document.addEventListener('paste', (event) => {
const { clipboardData } = event;
const data = clipboardData.getData('text/plain');
console.log(data);
// => "Dieser Text kommt synchron in die Zwischenablage."
event.preventDefault();
});
Grundsätzlich kann ein Transferobjekt Daten für verschiedene Formate enthalten. Auf diese Weise lassen sich in einer einzelnen Kopier- beziehungsweise Einfügeoperation die Daten direkt in mehreren Formaten übertragen. Das ist beispielsweise dann praktisch, um abhängig vom Ziel der Einfügeoperation die Daten entweder in dem einen oder dem anderen Format zu verarbeiten beziehungsweise. einzufügen. Folgendes Listing zeigt, wie auf diese Weise gleichzeitig Daten als einfacher Text, als formatierter HTML-Text und als JSON übertragen werden können (da sich die Daten nur als Zeichenkette übergeben lassen, muss im Fall von JSON entsprechend serialisiert (JSON.stringify()) und deserialisiert (JSON.parse()) werden).
document.addEventListener('copy', (event) => {
const { clipboardData } = event;
console.log(clipboardData);
clipboardData.setData(
'text/plain',
'Dieser Text kommt synchron in die Zwischenablage.'
);
clipboardData.setData(
'text/html',
'Dieser <strong>Text</strong> kommt synchron in die Zwischenablage.'
);
clipboardData.setData(
'application/json',
JSON.stringify({
message: 'Dieser Text kommt synchron in die Zwischenablage.'
}));
event.preventDefault();
}); document.addEventListener('paste', (event) => {
const { clipboardData } = event;
const data = clipboardData.getData('text/plain');
console.log(data);
// => "Dieser Text kommt synchron in die Zwischenablage."
const dataHTML = clipboardData.getData('text/html');
console.log(dataHTML);
// => "<meta charset='utf-8'>Dieser <strong>Text</strong> \
// kommt synchron in die Zwischenablage."
const dataJSON = JSON.parse(clipboardData.getData('application/json'));
console.log(dataJSON);
// => { message: "Dieser Text kommt synchron in die Zwischenablage." }
event.preventDefault();
});
Der oben beschriebene synchrone Zugriff auf die Zwischenablage eignet sich – weil die Ausführung der Webanwendung während der Kopier- beziehungsweise Einfügeoperation blockiert wird – nur für Daten, die eine überschaubare Größe haben. Möchte man dagegen komplexere oder größere Daten wie Bilddaten in die Zwischenablage kopieren oder aus der Zwischenablage in eine Webanwendung einfügen, greift man besser auf die Asynchronous Clipboard API [9] zurück. Wie der Name vermuten lässt, können Daten hierüber asynchron in die Zwischenablage geschrieben und aus ihr gelesen werden, ohne dass die entsprechenden Operationen dabei den Browser blockieren. Allerdings müssen Nutzer den Zugriff der entsprechenden Webanwendung auf die Zwischenablage erlauben, damit der Einsatz der Asynchronous Clipboard API überhaupt möglich ist.
Der Zugriff auf die API erfolgt über das Objekt navigator.clipboard, das entsprechende Methoden für das Schreiben (write()) sowie das Lesen (read()) bereitstellt. Beide Methoden liefern als Rückgabewert ein Promise-Objekt, sodass sie sich bequem sowohl über die Promise API als auch über async/await verwenden lassen.
Beim Schreiben werden der Methode write() die zu kopierenden Daten in Form eines Arrays von ClipboardItem-Objekten übergeben. Jedem einzelnen Objekt übergibt man die Daten mit einem Konfigurationsobjekt als Schlüssel/Wert-Paare, wobei der Schlüssel das Format repräsentiert und der Wert die Daten als Blob enthält:
const copy = async () => {
try {
const data = [
new ClipboardItem(
{
'text/plain': new Blob(
['Dieser Text kommt asynchron in die Zwischenablage.'],
{ type: 'text/plain' }
)
}) ];
await navigator.clipboard.write(data);
} catch (error) {
console.error(error);
}
}
Der lesende Zugriff geschieht über die Methode read(), über die man an die entsprechenden Daten in Form eines Arrays von ClipboardItem-Objekte gelangt. Die Eigenschaft types jedes einzelnen ClipboardItem-Objekts enthält die verschiedenen Datenformate, die mit dem Objekt übertragen wurden:
const paste = async () => {
try {
const items = await navigator.clipboard.read();
for (const item of items) {
for (const type of item.types) {
const data = await item.getType(type);
const text = await data.text();
console.log(text);
}
}
} catch (error) {
console.error(error);
}
}
Mit write() und read() können derzeit Texte und Bilder übertragen werden. Grundsätzlich sind weitere Formate denkbar, beispielsweise solche für Audio- oder Videodaten. Diese werden momentan aber in Bezug auf die Übertragung über die Zwischenablage noch nicht von allen Browsern unterstützt.
Für die Arbeit mit Texten stehen neben write() und read() noch die beiden Convenience-Methoden writeText() und readText() zur Verfügung, über die der Code von eben etwas einfacher gestaltet werden kann, weil man sich nicht mit ClipboardItem- und Blob-Objekten herumschlagen muss:
const copyText = async () => {
try {
await navigator.clipboard.writeText(
"Dieser Text kommt asychron in die Zwischenablage."
);
} catch (error) {
console.error(error);
}
}const pasteText = async () => {
try {
const text = await navigator.clipboard.readText();
console.log(text);
} catch (error) {
console.error(error);
}
}
Mit der Asynchronous Clipboard API wird der Zugriff auf die Zwischenablage um einen asynchronen Kommunikationskanal erweitert. Alle "großen" Browser bieten Support für die Clipboard API an, sowohl für die Synchronous Clipboard API [10] als auch für die Asynchronous Clipboard API, wobei der Support für Erstere auch ältere Browserversionen umschließt. Wer auf Nummer sicher gehen möchte, dass die neuere asychrone Version im jeweiligen Browser zur Verfügung steht, kann dies über Feature Detection [11] anhand des navigator.clipboard-Objekts überprüfen. Alternativ kann man auf eine Polyfill-Bibliothek wie clipboard-polyfill [12] oder auf beliebte Alternativen wie clipboard.js [13] zurückgreifen.
URL dieses Artikels:https://www.heise.de/-5048275
Links in diesem Artikel:[1] https://github.com/zeroclipboard/zeroclipboard[2] https://w3c.github.io/editing/docs/execCommand/[3] https://developer.mozilla.org/en-US/docs/Web/API/Document/execCommand[4] https://w3c.github.io/clipboard-apis[5] https://w3c.github.io/clipboard-apis/#clipboard-event-api[6] https://w3c.github.io/clipboard-apis/#async-clipboard-api[7] https://w3c.github.io/clipboard-apis/#clipboard-event-api[8] https://html.spec.whatwg.org/multipage/dnd.html#datatransfer[9] https://w3c.github.io/clipboard-apis/#async-clipboard-api[10] https://caniuse.com/clipboard[11] https://en.wikipedia.org/wiki/Feature_detection_(web_development)[12] https://github.com/lgarron/clipboard-polyfill[13] https://github.com/zenorocha/clipboard.js
Copyright © 2021 Heise Medien
Bisher galten das Arduino-Ökosystem, die Boards mit den Espressif-Microcontrollern ESP8266 und ESP32 und die Boards von ST Microelectronics als Lösung der Wahl für Elektronikprojekte. Nun treten der Microcontroller RP2040 und das zugehörige Raspberry Pi Pico Board an, um frischen Wind in die Maker-Bewegung zu bringen.
Der Microcontroller RP2040 der Raspberry Pi Foundation adressiert im Gegensatz zu bisherigen Produkten keine Einplatinencomputer (engl. SBC = Single Board Computer), sondern schließt die Lücke zu den Microcontrollern. Zwar ließen sich mit den Raspberry Pis bereits Lösungen beispielsweise für Heimautomatisierungsaufgaben erstellen, doch waren dazu häufig Zusatzkomponenten notwendig. Zudem ist der Einsatz eines vollwertigen Einplatinencomputers für Elektronikprojekte zum einen teuer, zum anderen auch platzintensiv.
Diese Lücke soll der Raspberry Pi Pico schließen, dessen Ziel hohe Leistung und niedriger Preis waren. Mit einem empfohlenen Preis von rund 4 Euro dürfte das Board viele Maker zu einem Erwerb verführen. Und auch die Leistungsdaten des Pico können sich sehen lassen.

Die zugehörige MCU (Micro Controller Unit) trägt den Namen RP2040, hat auf einem 7-mm-x-7-mm-IC-Die Platz und ist Ergebnis eines 40-nm-Herstellungsprozesses. Wer sich über den Namen des Chips wundert, sei auf folgende Tabelle verwiesen, die den Namen dekodiert:
RP steht für Raspberry Pi
2 ist die Anzahl der Rechenkerne
0 kodiert die Art des ARM-Prozessors, im vorliegenden Fall ein Cortex-M0+-Kern.
4 gibt nach folgender Formel die Größe des verfügbaren RAMs an floor(log2(RAM / 16k))
0 bezieht sich auf die Größe des nichtflüchtigen Speichers nach der Formel floor(log2(nonvolatile / 16k))

Die beiden Cortex-32-Bit-M0+-Prozessorkerne arbeiten mit variablen Taktfrequenzen mit bis zu 133 MHz Taktfrequenz, wobei mittlerweile auch schon von erfolgreichen Übertaktungen berichtet wurde. Der Chip enthält des Weiteren 264 KB statisches RAM, das sich auf sechs Speicherbänke verteilt. Dazu kommen 2 externer MByte Flash-Speicher.
Für Ein- und Ausgabe stehen 26 Multifunktions-GPIO-Ports mit 3,3 V zur Verfügung, davon 23 digital und drei für die Analog-Digital-Wandlung. Letztere bestehen aus 4-Kanal-ADCs mit 12-Bit-Auflösung. Dazu kommen jeweils zwei UARTs, zwei I2C-Anschlüsse, zwei SPI-Anschlüsse sowie 16 PWM-Kanäle. Sechs IO-Ports sind speziell für SPI-Flash reserviert.
Der Prozessor verfügt zudem über Timer, vier Alarme, einen internen Temperatursensor und eine Echtzeituhr. Zusätzliche Hardware ist häufig benutzten Peripheriegeräten gewidmet.

Auf dem Chip befinden sich integrierte Bibliotheken zur Beschleunigung von Fließkommaberechnungen.
Um effizientes Multithreading zu ermöglichen, umfasst der Microcontroller FIFO-Speicher, die als Mailboxen zwischen den beiden Kernen fungieren. 32 hardwarebasierte Spinlocks dienen der Synchronisation zwischen Threads.
Hinsichtlich seines geplanten Einsatzzweckes ist der RP2040 also bestens bestückt.
Für viele Elektronikprojekte ist die Frage des Energieverbrauchs essenziell. Bisherige Raspberry Pi Boards besaßen dieses Problem nicht, da sie mehr als stationäre Einplatinencomputer zum Einsatz kamen. Bei Microcontroller-Lösungen hingegen stellt sich die Frage des Energieverbrauchs, speziell wenn sie für den ortsunabhängigen beziehungsweise batteriebetriebenen Einsatz konzipiert sind.
Das Pico Board verbraucht selbst bei Volllast lediglich 0,33 Watt, ganz im Gegensatz zu anderen Raspberry Pi Boards, die im Optimalfall (Raspberry Pi Zero) zwischen 1 und 2 Watt landen. Um den Energieverbrauch möglichst niedrig zu halten, implementiert der RP2040 Modi für Schlummer- und Schlafbetrieb. In diesen Modi verbraucht das Pico Board 6 Milliwatt (0,006 Watt) bei weniger als 2 mA Stromstärke (P = U * I = 3.3V * 0.002A). Mit der entsprechenden Batterie beziehungsweise Zelle ausgestattet und bei hinsichtlich Energieeffizienz optimierter Programmierung könnte ein Pico also Tage, wenn nicht sogar Wochen durchhalten, ohne eine Energieauffrischung zu benötigen. Das sind beeindruckende Werte.
Ein interessantes Merkmal des RP2040 ist die programmierbare Ein-/Ausgabe (engl. PIO = Programmable IO). Dahinter stecken zwei PIO-Blöcke mit je vier Zustandsmaschinen. Das "programmierbar" ist dabei durchaus wörtlich zu nehmen, denn Entwickler können sogenannte PIO-Programme schreiben und sie mit einem Assembler namens pioasm assemblieren. Klingt zunächst alles sehr abstrakt.
PIO dient dazu, um eigene Ein-/Ausgabeprotokolle zu integrieren und eigene Peripheriegeräte zu unterstützen, ohne den Hauptprozessor zu belasten. Häufig verwenden Entwickler für diese Aufgabe das sogenannte Bit-Banging (Emulation einer Hardwareschnittstelle mittels Software), was aber den Prozessor bisweilen in die Knie zwingt. Dieses Problem umschifft PIO. Ein einfaches Beispiel: Der RP2040 soll ein Rechteckssignal als Ausgabe erzeugen. Auf diese Weise ließe sich ein Pico als Funktionsgenerator einsetzen. Dafür schreiben Entwickler folgendes PIO-Programm:
7 .program squarewave
8 set pindirs, 1 ; Pin als Ausgabepin festlegen
9 again:
10 set pins, 1 [1] ; Pin auf 1 setzen und dann 1 Zyklus Pause
11 set pins, 0 ; Pin auf 0 setzen
12 jmp again ; Zu Label ‘again’ springen
Der Anschluss an den Host erfolgt beim Pico über einen USB-1.1-Port (Micro-USB). Dabei sind sowohl Host- als auch Gerätemodus möglich. So lässt sich Drag and Drop nutzen, um den Pico mit neuer Software zu versorgen. Drücken Entwickler die BOOTSEL-Taste auf dem Board und schließen dieses an den Host-Rechner (Windows, macOS, Linux) an, erkennt der Hostrechner den Pico als USB-Massenspeichergerät. Auf dem Host erscheint infolgedessen das Dateiverzeichnis des Pico. Sobald Entwickler eine Programmdatei auf das richtige Zielverzeichnis kopieren, erfolgt zunächst ein Reset des Pico und anschließend ein Neustart, worauf automatisch die Ausführung der Programmdatei beginnt. Die jeweilige Programmdatei muss im UF2-Format vorliegen – UF2 steht für USB Flashing Format.

Der Raspberry Pi Pico verfügt keine angelöteten Header-Pins, um ihn auch direkt auf einer Platine nutzen zu können. Zu diesem Zweck gibt es Aussparungen (Edge Castellations), die ein Anlöten auf der Platine erlauben. Zum Debuggen komplexerer Programme existiert ein 3-Pin ARM Serial Wire Debug Port.
Bei all diesen Leistungsdaten fragen sich interessierte Maker, ob das Pico-Board auch etwas nicht kann. Solche Dinge gibt es in der Tat. So stellt der Pico für die Kommunikation über WiFi oder Bluetooth keine Funktionalität zur Verfügung. Allerdings könnte sich das in Zukunft ändern, zumal auch andere Elektronikschmieden den RP2040 für eigene Boards nutzen wollen. Das in einigen Wochen verfügbare Arduino Nano RP2040 Connect Board [1] enthält ebenfalls eine RP2040-MCU, stellt darüber hinaus weitere Komponenten bereit, etwa Funktionalität für WiFi und Bluetooth.
Für die Programmierung eines Pico Board hat die Raspberry Pi Foundation ein SDK für C beziehungsweise C++ entwickelt. Auch an der Integration in Visual Studio hat man schon gearbeitet. Das "Hello World" der Maker-Elektronik in Gestalt des Blinkens einer LED gestaltet sich in C wie folgt:
#include "pico/stdlib.h"int main() {
const uint LED_PIN = 25;
gpio_init(LED_PIN);
gpio_set_dir(LED_PIN, GPIO_OUT);
while (true) {
gpio_put(LED_PIN, 1);
sleep_ms(250);
gpio_put(LED_PIN, 0);
sleep_ms(250);
}
}
Alternativ lässt sich aber auch Micropython einsetzen. Dazu müssen Entwickler eine MicroPython-UF2-Datei über USB auf das Board laden. Der Zugriff auf das REPL (Read-Eval-Print-Loop) lässt sich über USB Serial bewerkstelligen. Das oben präsentierte Blink-Programm würde in MicroPython wie folgt aussehen:
from machine import Pin, Timer
led = Pin(25, Pin.OUT)
timr = Timer()
def tick(timer):
global led
led.toggle()
timr.init(freq=2.5, mode=Timer.PERIODIC, callback=tick)
Das Arduino-Team hat angekündigt, einen sogenannten Arduino IDE Core für Pico Boards bereitzustellen. Dadurch lässt sich ein Pico in die Arduino IDE integrieren und programmatisch nutzen, als ob ein Arduino Board vorläge. Auch für die PlatformIO IDE soll in Kürze eine entsprechende Integration des Raspberry Pi Pico möglich sein.
Ebenfalls laufen nach Auskunft der Raspberry Pi Foundation die Arbeiten an einem Echtzeitbetriebssystem (RTOS). Visual Studio Code von Microsoft ist hingegen schon jetzt für die Pico-Entwicklung einsetzbar.
Eine weitere positive Nachricht: Google hat Tensorflow Lite for Microcontrollers auf den Pico portiert.
Wie bereits erwähnt, wollen auch andere Hersteller den RP2040 in ihre eigenen Boards integrieren. Die folgende Aufzählung erhebt keinen Anspruch auf Vollständigkeit:
Das neue Raspberry Pi Board und insbesondere der Microcontroller-Chip RP2040 haben das Potenzial, eine große Verbreitung zu finden. Neben einem günstigen Preis sticht das Board durch gute Leistungsdaten hervor. Noch dazu haben andere bekannte Hersteller angekündigt, den RP2040-Microcontroller auf eigenen Boards zu integrieren.
Daher dürfte der RP2040 auch in zukünftigen Artikeln meines Blogs eine wichtige Rolle spielen.
URL dieses Artikels:https://www.heise.de/-5045274
Links in diesem Artikel:[1] https://blog.arduino.cc/2021/01/20/welcome-raspberry-pi-to-the-world-of-microcontrollers/[2] https://www.sparkfun.com/news/3708[3] https://www.adafruit.com/?q=rp2040&sort=BestMatch[4] https://blog.arduino.cc/2021/01/20/welcome-raspberry-pi-to-the-world-of-microcontrollers/[5] https://projects.raspberrypi.org/en/projects/getting-started-with-the-pico[6] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf[7] https://datasheets.raspberrypi.org/pico/pico-datasheet.pdf[8] https://datasheets.raspberrypi.org/pico/pico-product-brief.pdf[9] https://www.raspberrypi.org/blog/new-book-get-started-with-micropython-on-raspberry-pi-pico/[10] https://www.berrybase.de/raspberry-pi-co/raspberry-pi/boards/raspberry-pi-pico[11] https://thepihut.com/products/raspberry-pi-pico[12] https://www.reichelt.de/de/de/raspberry-pi-pico-rp2040-cortex-m0-microusb-rasp-pi-pico-p295706.html?r=1[13] https://www.rasppishop.de/Raspberry-Pi-Pico-RP2040-ARM-Cortex-SBC
Copyright © 2021 Heise Medien
Eines der zentralen Themen in der Webentwicklung ist Sicherheit. Mit der Web Crypto API bieten moderne Browser mittlerweile ein Werkzeug, mit dem Entwickler auch clientseitig Informationen signieren und verschlüsseln können.
Sicherheit wird im Web großgeschrieben. Nicht umsonst gibt es beispielsweise die Secure-Contexts-Spezifikation des W3C, nach der der Browser bestimmte Features wie Service Workers oder die Payment Request API nur aktiviert, wenn die Applikation über eine sichere Verbindung ausgeliefert wird. Doch der Schutz der Anwender geht noch weiter. Ein Browser ermöglicht den Zugriff auf zahlreiche Schnittstellen des Systems, auf dem die Applikation ausgeführt wird. Typischerweise sind das Mikrofon oder Kamera, aber auch systemseitige Push-Mitteilungen fallen hierunter. Entwickler können über JavaScript auf diese Schnittstellen zugreifen, allerdings erst, nachdem die Anwender diesen Zugriff erlaubt haben. Es ist also nicht möglich, beispielsweise das Mikrofon im Hintergrund zu aktivieren und damit nahezu jedes Endgerät in ein Spionagegerät zu verwandeln.
Eine Problemstellung blieb jedoch lange Zeit unberührt: Verschlüsselung von Informationen im Browser. Selbst für einfache Standardaufgaben wie das Hashen von Informationen mussten entweder selbst Funktionen geschrieben oder auf eine externe Bibliothek zurückgegriffen werden. Das bringt nicht nur den Nachteil von zusätzlichem Quellcode in der Applikation mit sich, der zum Client zu transferieren ist, auch ist die Ausführungsgeschwindigkeit solcher Algorithmen in JavaScript nicht so performant, als wenn sie nativ im Browser implementiert wären. Dieses Problem geht die Web Crypto API an. Diese Schnittstelle bietet eine Reihe von Funktionen, mit denen sich beispielsweise Signaturen und Verschlüsselung clientseitig umsetzen lassen.
Ein Blick auf caniuse.com [1] verrät, dass sowohl Chrome als auch Firefox, Edge und Safari die Web Crypto API vollumfänglich unterstützen. Lediglich der Internet Explorer und Opera Mini machen hier noch Probleme. Wobei der Internet Explorer 11 die Web Crypto API schon unterstützt, allerdings in einer älteren Version der Spezifikation.
Nachdem die Web Crypto API fester Bestandteil des Browsers ist, können Entwickler die Funktionen der Schnittstelle direkt, also ohne Import-Statements, verwenden. Das folgende Codebeispiel zeigt, wie im Browser ein PBKDF2-Schlüssel auf Basis eines Passworts erzeugt werden kann, den die Applikation anschließend für die Generierung eines weiteren Schlüssels für die eigentliche Verschlüsselung oder Signatur nutzen kann:
(async () => {
const enc = new TextEncoder();
const pw = 'T0p5ecret!';
const key = await crypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);// ... work with the key
})();
Der Zugriff auf die Web Crypto API erfolgt über das window.crypto-Objekt (bzw. abgekürzt nur crypto). Die meisten Funktionen dieser Schnittstelle sind asynchron und arbeiten mit Promises und lassen sich wie im Beispiel mit async/await verwenden.
Neben der mittlerweile guten Browserunterstützung hat die Web Crypto API auch Einzug in Node.js gehalten. Seit Version 15 ist das aktuell noch experimentelle Modul Bestandteil des Node.js-Kerns (dieses neue Model "webcrypto" sollte allerdings nicht mit dem bereits bestehenden Modul "crypto" verwechselt werden). Im Gegensatz zum Browser müssen Entwickler hier die Funktionalität zunächst wie im folgenden Codebeispiel einbinden:
import {webcrypto} from 'crypto';const enc = new TextEncoder();
const pw = 'T0p5ecret!';
const key = await webcrypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);
console.log(key);
Ein erster Einsatzzweck für die Web Crypto API ergibt sich aus dem relativ trivialen Problem der Erzeugung von Zufallszahlen.
Der JavaScript-Standard sieht zur Erzeugung von Zufallszahlen die Methode Math.random() vor. Sie gibt eine zufällige Fließkommazahl zwischen 0 und 1 zurück, mit der in einer JavaScript-Applikation gearbeitet werden kann. Die genaue Implementierung dieser Methode überlässt der Standard den Browserherstellern, und so gibt es von Plattform zu Plattform unterschiedliche Implementierungen. Allen gemeinsam ist jedoch, dass keine kryptographisch sichere Variante dabei ist. Das bedeutet, dass Entwickler diese Methode nicht für sicherheitskritische Algorithmen nutzen sollten. Glücklicherweise sieht die Web Crypto API für diesen Zweck die getRandomValues()-Methode vor, die dieses Problem löst und sichere Zufallszahlen generiert. Wie diese Methode in der Praxis verwendet wird, zeigt der folgende Codeblock:
const randomNumbers = new Uint32Array(1);
crypto.getRandomValues(randomNumbers);
console.log(randomNumbers[0]);
Die getRandomValues()-Methode akzeptiert ein typisiertes Integer-Array, also ein Uint8Array, Uint16Array oder Uint32Array. Je nach Größe des Arrays werden unterschiedlich viele Zufallszahlen erzeugt. In unserem Beispiel wird eine 32 Bit große Zufallszahl generiert. Diese ist kryptografisch sicher und kann entsprechend auch zur Lösung sicherheitsrelevanter Probleme verwendet werden.
Die wirklich interessanten Features der Web Crypto API verbergen sich hinter dem SubtleCrypto Interface oder konkret hinter der subtle-Eigenschaft des crypto-Objekts. In den folgenden Abschnitten werfen wir mit Signatur und Verschlüsselung einen Blick auf zwei typische Einsatzgebiete für die Web Crypto API.
Bei Webapplikationen setzen die Entwickler digitale Signaturen normalerweise ein, um sicherzustellen, dass keine unberechtigten Dritten eine Information manipuliert wurde, die zwischen dem Sender und Empfänger ausgetauscht wird. Die Web Crypto API unterstützt eine Reihe von Algorithmen für das Signieren von Informationen. Beispiele hierfür sind RSA-PSS, AES-GCM oder der im folgenden Beispiel verwendete HMAC. Die Web Crypto API nutzt beim Signieren Schlüssel, die die Applikation entweder selbst generiert, oder einen importierten externen Schlüssel. Je nach Variante nutzen Entwickler hier entweder die generateKey()- oder die importKey()-Methode. Damit das folgende Beispiel problemlos ausführbar ist, erzeugt der Code den HMAC-Schlüssel selbst und nutzt ihn zum Signieren und zur anschließenden Überprüfung der Signatur:
(async () =>{
const message = (new TextEncoder()).encode('Hallo Welt');// generate the key
const key = await crypto.subtle.generateKey({
name: 'HMAC',
hash: {name: 'SHA-256'}
}, false, ['sign', 'verify']);
// sign the message
const signature = await crypto.subtle.sign(
{name: 'HMAC'},
key,
message
);
// print the signature
console.log(new Uint8Array(signature));
// verify the signature
const isValid = await crypto.subtle.verify(
{name: 'HMAC'},
key,
signature,
message
);
console.log('isValid?', isValid);
})();
Der Code zeigt zwei zentrale Merkmale der Web Crypto API sehr schön:
sign()- und verify()-Methoden ein Uint8Array-Objekt, das mithilfe des TextEncoders erzeugt wird. Die Rückgabe der sign()-Methode ist ein ArrayBuffer, der, in ein typisiertes Array umgewandelt, auf der Konsole angezeigt werden kann. Der Grund für den Einsatz dieser Datenstrukturen ist, dass sie zur Verarbeitung und zum Austausch von Informationen besser geeignet sind als beispielsweise Zeichenketten.Der Quellcode im Beispiel sorgt zunächst dafür, dass die zu verschlüsselnde Zeichenkette als Uint8Array, dem Eingabeformat für die sign()- und verify()-Methode vorliegt. Anschließend erzeugt er einen neuen Schlüssel. Die generateKey()-Methode erwartet, dass die Entwickler beim Aufruf die Einsatzzwecke des Schlüssels angeben, in diesem Fall sind dies "sign" und "verify". Nutzt eine Applikation einen Schlüssel für eine Operation, die hier nicht genannt wird, wirft die JavaScript eine DOMException, die aussagt, dass der Schlüssel für diese Art Operation nicht erlaubt ist. Mit dem Schlüssel und der codierten Zeichenkette erzeugt die sign()-Methode eine Signatur und gibt sie in Form eines ArrayBuffers zurück.
Das Gegenstück zur sign()-Methode ist die verify()-Methode. Sie akzeptiert ein Konfigurationsobjekt, das beispielsweise den Namen des verwendeten Algorithmus enthält. Außerdem müssen der Schlüssel, die Signatur und die zu überprüfende Zeichenketten übergeben werden. Das Ergebnis des sign()-Aufrufs ist ein boolscher Wert, der angibt, ob die Signatur gültig ist.
Die Signatur kann eine Applikation beispielsweise nutzen, um sensible Informationen mit einem Server auszutauschen. Beide Seiten können dann überprüfen, ob die Nachrichten auf dem Weg manipuliert wurden. Voraussetzung hierfür ist, dass beide Seiten den Schlüssel der jeweils anderen Seite kennen.
Das Verschlüsseln von Daten mithilfe der Web Crypto API funktioniert ähnlich wie das Signieren von Daten, nur dass das Ergebnis eben die verschlüsselten Informationen statt der Signatur sind. Das folgende Codebeispiel nutzt eine Kombination von Schlüsseln. Zunächst erzeugt der Quellcode einen passwortbasierten Schlüssel mit dem Verwendungszweck deriveKey, von dem anschließend ein zweiter Schlüssel abgeleitet wird. Dies bietet zum einen die Möglichkeit, für die Ver- und Entschlüsselung ein Passwort zu nutzen, und zum anderen wird die Sicherheit durch die Kombination von zwei Verschlüsselungsmechanismen zusätzlich erhöht. Die encrypt()-Methode nutzt dann den zweiten Schlüssel, um einen Text mit dem AES-GCM-Algorithmus zu verschlüsseln. Die Entschlüsselung erfolgt anschließend mit der decrypt()-Methode und ebenfalls mit dem zweiten Schlüssel.
(async () => {
const enc = new TextEncoder();
const dec = new TextDecoder();
const pw = 'T0p5ecret!';// create the first key
const key1 = await crypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);
// create the second key
const key2 = await crypto.subtle.deriveKey(
{
name: "PBKDF2",
salt: crypto.getRandomValues(new Uint8Array(10)),
iterations: 250000,
hash: "SHA-256",
},
key1,
{ name: "AES-GCM", length: 256 },
false,
['encrypt', 'decrypt']
);
const iv = crypto.getRandomValues(new Uint8Array(10));
const encryptedMessage = await crypto.subtle.encrypt(
{
name: "AES-GCM",
iv,
},
key2,
new TextEncoder().encode('Hallo Welt')
);
console.log('encrypted data: ', new Uint8Array(encryptedMessage));
const decryptedBuffer = await window.crypto.subtle.decrypt(
{
name: "AES-GCM",
iv: iv,
},
key2,
encryptedMessage
);
const decryptedMessage = dec.decode(decryptedBuffer);
console.log('decrypted data: ', decryptedMessage);
})();
Die encrypt()- und decrypt()-Methoden arbeiten, wie schon sign() und verify(), mit typisierten Arrays und ArrayBuffer-Objekten, um mit den Schlüsseln sowie den Ergebnissen zu arbeiten.
Ein Einsatzzweck für die clientseitige Verschlüsselung ist beispielsweise die Absicherung von Informationen, die im Client gespeichert werden. Mit der zunehmenden Umsetzung offlinefähiger Applikationen steigt auch die Menge der Daten, die im Browser unter anderem in der IndexedDB gespeichert werden. Der Nachteil dieser Speichermechanismen ist, dass sie über die Entwicklerwerkzeuge des Browsers problemlos ausgelesen werden können. Verschaffen sich also unberechtigte Dritte Zugriff zum Browser, ist es ihnen möglich, die komplette Web Storage des Browsers auszulesen. Liegen die Daten dort jedoch verschlüsselt, wird es für die Angreifer zumindest etwas aufwändiger an die Informationen zu kommen. Voraussetzung dafür ist natürlich, dass der Schlüssel, der zum Entschlüsseln verwendet wird, nicht auch im Browser gespeichert wird.
Die Web Crypto API ist eine mittlerweile von allen wichtigen Browserherstellern unterstützte Low-Level-API zum Umgang mit Kryptographie in JavaScript. Die Schnittstelle ist nicht nur im Client, sondern auch serverseitig in Node.js verfügbar, sodass Quellcode und auch Bibliotheken auf beiden Seiten der Kommunikationsstrecke wiederverwendet werden können. Die Web Crypto API unterstützt verschiedene Anwendungsfälle von der Erzeugung kryptografisch sicherer Werte über Signatur bis hin zur Verschlüsselung von Informationen, die in Web-Applikationen zum Einsatz kommen. Der Vorteil dieser Schnittstelle ist, dass keine zusätzlichen Bibliotheken installiert werden müssen und, nachdem die Schnittstelle nativ vom Browser implementiert wird, sie auch noch verhältnismäßig performant ist.
Die Web Crypto API ist ein weiterer Schritt in Richtung sicherer Web-Applikationen, die die Daten ihrer Nutzer vor dem Zugriff Unberechtigter schützen.
URL dieses Artikels:https://www.heise.de/-5035591
Links in diesem Artikel:[1] https://caniuse.com
Copyright © 2021 Heise Medien
Das Entwicklerteam hinter React verfolgt einen interessanten Ansatz, der dafür sorgt, dass Single-Page-Applikationen nicht mehr reine Client-Monolithen sind. Die Idee ist Client und Server wieder näher zusammenzubringen und das Beste aus dieser Kombination herauszuholen.
Da erfindet Facebook einmal wieder das Backend neu. Die Rede ist vom neuesten Vorstoß von React: Server Components. Was sich auf den ersten Blick liest wie nur eine weitere Template Engine auf Basis von JavaScript, ist nur ein weiterer Schritt auf dem Weg, den das Entwicklerteam schon vor Jahren eingeschlagen hat, um Applikationen, die mit React erzeugt werden, noch performanter für die Benutzer zu machen.
Die Idee, die das React-Team verfolgt, ist jedoch nicht exklusiv für React, sondern findet sich in verschiedenen Varianten auch in den anderen großen JavaScript-Frameworks wieder. Doch worum geht es eigentlich? Die vergangenen Jahre waren in der Webentwicklung vor allem von Single Page-Applikationen (SPA) geprägt und damit einhergehend mit dem Siegeszug "großer" JavaScript-Frameworks und Bibliotheken wie Angular, Vue oder React. Eine solche SPA hat jedoch eine architekturelle Schwachstelle: Sie besteht, wie der Name schon andeutet, aus nur einer einzelnen HTML-Seite. Das bedeutet, dass auch alle benötigten Ressourcen in der Regel bereits zum Startzeitpunkt der Applikation geladen werden müssen.
Die Benutzer im Web warten nicht gerne. Man muss sich hier nur an die eigene Nase fassen: Ich rufe eine bestimmte Website auf oder lade eine Webapplikation. In den meisten Fällen habe ich ein konkretes Ziel. Das kann das Lesen eines Artikels, ein Einkauf oder die Erledigung einer Aufgabe im Arbeitsumfeld sein. Werde ich jedoch von einer weißen Seite oder einer sich vor mir schwerfällig aufbauenden Webpräsenz begrüßt, ist der gute erste Eindruck dahin und die Gegenseite muss mich ab diesem Zeitpunkt schon mit sehr guten Argumenten überzeugen, da ich mich ansonsten sehr schnell auf die Suche nach einer Alternative begebe. Das Motto lautet also "Load fast, stay fast". Dieser Ausdruck wird unter anderem von Google mitgeprägt. Und das aus gutem Grund: Die Ergebnisse, die eine Suchmaschine präsentiert, sollen zur Zufriedenheit der Benutzer sein und eine schnelle Auslieferung der Inhalte trägt zur Zufriedenheit bei. Das bedeutet, dass eine schnell ausgelieferte Applikation bessere Chancen auf eine gute Platzierung in der Ergebnisliste hat.
Doch zurück zu den SPAs. Es gibt zwei Metriken, die im Zusammenhang mit dem Laden einer Applikation von Bedeutung sind: Die Zeit, die es braucht, bis alle erforderlichen Ressourcen geladen sind, und die Zeit, bis die Benutzer in der Lage sind, mit der Applikation zu interagieren.
Eine der wichtigsten Maßzahlen bei der Entwicklung einer SPA ist die sogenannte Bundlesize. Diese Größenangabe bezieht sich auf den gebauten Code der Applikation, der initial ausgeliefert wird. In der Regel werden SPAs in reinem JavaScript oder TypeScript entwickelt und mit einem Bundler wie Webpack oder Rollup gebaut. Dieser Build-Prozess umfasst eine Vielzahl einzelner Schritte. Die wichtigsten sind der Transpile-Prozess, falls TypeScript zum Einsatz kommt, das Zusammenfügen des Quellcodes sowie die Optimierung. Für React gibt es mit Create React App ein Kommandozeilenwerkzeug, das diesen Build-Prozess vorbereitet und den Code für den Produktivbetrieb optimiert.
Immer mehr SPAs, auch im React-Umfeld, werden mit TypeScript umgesetzt. Die Sprache fügt allerdings nicht nur ein Typsystem in JavaScript ein, sondern ist auch in der Lage, verschiedene JavaScript-Features zu emulieren. Die Entwickler einer Applikation können über eine Konfigurationsdirektive angeben, in welcher JavaScript-Version der generierte Quellcode erzeugt werden soll. Je älter die Version, desto mehr Features von modernem JavaScript müssen emuliert werden. Das bedeutet aber auch, dass die Bundlesize negativ beeinflusst wird. Das Ziel ist also, eine möglichst neue Version zu verwenden, falls dies die Browser der Benutzer zulassen. Die TypeScript-Konfiguration gibt die Version des generierten JavaScript-Quellcodes vor.
Eine Applikation besteht aus vielen einzelnen Dateien, die sich jeweils um bestimmte Aspekte der Applikation kümmern: Komponenten, die die Struktur und das Aussehen der Applikation bestimmen, Services, die die Businesslogik der Applikation enthalten, und Hilfsklassen und -funktionen, die helfen, bestimmte Routinen auszulagern. Das JavaScript-Modulsystem verbindet die einzelnen Bestandteile der Applikation und hilft dabei, Abhängigkeiten aufzulösen. Zwar unterstützen die meisten modernen Browser das Modulsystem mittlerweile, sodass theoretisch der Quellcode auch in Einzelteilen zum Client übertragen werden kann. Dennoch ist es praktikabler, die Applikation in wenigen großen Dateien auszuliefern, da dadurch der Verbindungs-Overhead wegfällt und die verfügbaren parallelen Verbindungen des Browsers zum Server optimal ausgenutzt werden können. Der Bundler übernimmt die Aufgabe, die Dateien zusammenzuführen. Dabei löst beispielsweise Webpack nicht nur JavaScript-Abhängigkeiten auf, sondern ist auch in der Lage, andere Ressourcen wie CSS-Dateien in das Bundle zu integrieren.
Zur weiteren Optimierung des Ladeprozesses einer Applikation wird der Quellcode mithilfe eines Minifiers umgeschrieben. Dieser Prozessschritt sorgt dafür, dass Variablennamen verkürzt werden, unnötige Whitespaces entfernt und Kommentare gelöscht werden.
Eine weitere Möglichkeit der Optimierung bieten Bundler wie Webpack mit dem sogenannten Tree Shaking. Dabei wird ungenutzter Code im Projekt während des Build-Prozesses eliminiert, sodass nur der tatsächlich genutzte Code ausgeliefert wird. Tree Shaking ist vor allem beim Einsatz von Bibliotheken interessant, von denen nur ein Teil der Funktionalität wirklich benötigt wird.
Neben dem Tree Shaking gibt es auch innerhalb einer Applikation Bestandteile, die zwar nicht überflüssig sind, jedoch nicht initial angezeigt werden müssen. Um die initiale Bundlesize weiter zu reduzieren, können Teile der Applikation dynamisch nachgeladen werden. Diese Vorgehensweise, oft als Lazy Loading bezeichnet, sorgt dafür, dass sich der ausgelieferte Quellcode weiter verkleinert und die zusätzlichen Komponenten erst geladen werden, wenn die Benutzer sie anfragen.
Lazy Loading hat vor allem beim Route Based Lazy Loading, also dem dynamischen Laden von Komponenten basierend auf Pfaden innerhalb der Applikation, den Nachteil, dass die Benutzer warten müssen, bis der Ladevorgang abgeschlossen ist, bevor ihnen die neue Ansicht präsentiert wird. An dieser Stelle gibt es die Möglichkeit, die Ressourcen bereits vorzuladen, sodass beim Pfadwechsel bereits alle Ressourcen vorhanden sind und nur noch gerendert werden müssen. Diese Verbesserungen tragen dazu bei, dass die SPA schneller zu den Benutzern ausgeliefert werden kann und die Zeitspanne bis zur Anzeige der Applikation deutlich verkürzt wird.
An dieser Stelle kommt jedoch ein weiteres Problem der SPAs zum Tragen: Die Applikation wird komplett über JavaScript aufgebaut. Das bedeutet, dass der Browser zunächst ein leeres div-Element, also eine leere Seite, anzeigt und die Benutzer erst etwas von der Applikation sehen, nachdem React seine Arbeit verrichtet hat und alle Komponenten der Applikation erzeugt und in das DOM eingehängt hat. Diese Phase weist ebenfalls enormes Potenzial für Verbesserungen auf: Statt eine leere Seite auszuliefern und sie dann mittels JavaScript zu befüllen, gehen die Entwickler von SPAs einen Schritt in der Geschichte der Webentwicklung zurück und überlassen dem Webserver die Arbeit, die HTML-Struktur der Applikation vorzubereiten und bereits fertig auszuliefern. Dieser Schritt hat nur noch wenig mit den traditionellen Template-Engines zu tun.
Stattdessen bietet beispielsweise React mit dem ReactDOMServer ein Objekt, das verschiedene Methoden zur Erzeugung von HTML-Strukturen auf Serverseite enthält. Diese werden dann wie traditionelle HTML-Seiten zum Browser der Benutzer gesendet. Dort übernimmt dann das Framework die Kontrolle über die HTML-Struktur. Dieser Prozess wird in React Hydration genannt. Erst wenn dieser Prozess abgeschlossen ist, können die Benutzer vollständig mit der Applikation interagieren. Der Vorteil von diesem Server-Side Rendering genannten Prozess ist, dass den Benutzern die Informationen bereits sehr früh zur Verfügung stehen und der Hydration-Prozess vergleichsweise schnell abläuft.
Die Idee, eine Applikation komplett im Client umzusetzen, hat sich also als nicht optimal herausgestellt, und so schlagen die Entwickler von React gerade einen sehr interessanten Weg ein, indem sie versuchen, Client und Server noch enger miteinander zu verknüpfen, als es bislang schon mit Server-Side Rendering der Fall ist.
Das Ergebnis sind die Server Components. Dabei handelt es sich um reguläre React-Komponenten, die allerdings nicht zum Client gesendet werden, sondern direkt auf dem Server ausgeführt werden. Sie können auf die Ressourcen des Servers zugreifen und sich so selbst mit Daten versorgen. Außerdem können sie bestimmen, welche Komponenten für die clientseitige Darstellung gerendert werden. Durch Server Components können Entwickler schon serverseitig viel tiefer in den Aufbau einer Applikation eingreifen, sodass wirklich nur noch die Strukturen zum Client gesendet werden, die dort benötigt werden. Außerdem können hier serverseitige Caching-Mechanismen eingesetzt werden, um die Auslieferung der Applikationen noch weiter zu beschleunigen.
Noch befindet sich dieses Feature in einem sehr frühen Stadium, jedoch zeigen dieses und ähnliche Features, wo die Reise für Frontend-Entwickler hingehen könnte.
URL dieses Artikels:https://www.heise.de/-5026838
Copyright © 2021 Heise Medien