+ sign #3489docker-compose #3353
remoteip to log the client remote IP instead of the local proxy IP #3226LISTEN to change the internal Apache port when running in host network mode #3343alpine:edge to test the latest PHP 8+ version #3294alpine:3.4 to test oldest supported PHP 5.6.36 version with Apache 2.4.43 #3274@-sign in database username (for Azure) #3241ceil() by intval() for edge cases with PHP8 #3404js_vars and nav_menu #3342phpcs (PHP_CodeSniffer) line length + whitespace #3488
*.phtml, *.css, *.js as well.png files as binary #3211PDO::ERRMODE_SILENT #3048Zugegeben, die Relevanz einiger GoF-Entwurfsmuster für JavaScript hält sich in Grenzen, wurden diese Entwurfsmuster doch ursprünglich dafür konzipiert, Rezepte für objektorientierte Programmiersprachen beziehungsweise das objektorientierte Programmierparadigma zu definieren.
Das Command-Pattern beispielsweise dient in erster Linie dazu, in der Objektorientierung Funktionen als Objekte zu behandeln und sie beispielsweise als Parameter einer anderen Funktion (bzw. im Kontext von Objekten: Methode) übergeben zu können. Dieses "Feature" ist in funktionalen Programmiersprachen bereits Teil des Programmierparadigmas: Funktionen sind hier "First-Class Citizens" und können wie Objekte behandelt werden, lassen sich beispielsweise Variablen zuweisen, einer anderen Funktion als Parameter übergeben oder ihr als Rückgabewert dienen.
Andere Entwurfsmuster hingegen wie das im Folgenden vorgestellte Adapter-Pattern ergeben durchaus auch in JavaScript Sinn. Der Einsatz des Adapter-Patterns in JavaScript ist vor allem dann in Betracht zu ziehen, wenn man es mit externem Code, sprich mit Third-Party-Bibliotheken zu tun hat.
Dazu ein kurzes fiktives Beispiel: Angenommen, wir haben eine Applikation, in der an verschiedensten Stellen HTTP-Anfragen ausgeführt werden müssen. Statt selbst einen HTTP-Client zu implementieren, machen wir uns auf die Suche nach einer entsprechenden Bibliothek. Schließlich soll man das Rad nicht immer neu erfinden. Zum Glück gibt es im JavaScript-Universum recht viele Bibliotheken beziehungsweise Packages, und wir werden schnell fündig: Die Wahl fällt auf das Package request [1] (Spoiler: Unser Beispiel beginnt 2018 und wir wissen noch nicht, dass diese Wahl eine weniger gute war).
Wann immer wir in unserer Applikation nun eine HTTP-Anfrage stellen möchten, binden wir request wie folgt ein:
request('https://www.heise.de', (error, response, body) => {
// usw.
});
Insgesamt machen wir das an 32 Stellen. Und weil wir so große Fans von HTTP-Anfragen sind, erhöht sich die Anzahl schon nach wenigen Wochen auf 128. Das geht einige Zeit gut, doch nach ein paar Monaten erhalten wir schlechte Nachrichten (es ist jetzt der 30. März 2019): Mikeal Rogers [2], der Hauptentwickler hinter request, markiert die Bibliothek als "deprecated" und verkündet, dass sie zukünftig nicht mehr aktiv weiterentwickelt werde [3]. Nach einigem Hin und Her und mehrstündigen Diskussionen im Team entscheiden wir uns, unseren Code auf eine andere Bibliothek zu migrieren.
Schnell fällt die Wahl dabei auf axios [4]. Über 82.000 Stargazer bei GitHub? Das ist schon mal ein gutes Zeichen. Dass wir jetzt 128 Stellen in der eigenen Applikation anpassen müssen, nehmen wir zähneknirschend in Kauf, sind dieses Mal aber schlauer. Einer im Team bringt kleinlaut hervor, dass wir vielleicht eines der GoF-Entwurfsmuster einsetzen könnten. Er habe da neulich was in einem Buch über JavaScript gelesen. Einige der Patterns seien wohl auch in JavaScript sinnvoll. Nach anfänglicher Skepsis hören wir uns den Vorschlag an.
Statt externe Bibliotheken wie request oder axios direkt zu verwenden, definieren wir uns einfach eine eigene API, gegen die wir innerhalb unserer Applikation entwickeln. Im Fall der HTTP-Client-Funktionalität könnte die API also beispielsweise wie folgt aussehen (ja, in Form einer Klasse!). Die API definiert die Methoden, die Parameter, die Rückgabewerte und in unserem Fall auch, dass es sich um eine asynchrone API auf Basis von Promises (und nicht etwa auf Basis von Callbacks) handelt. In Bezug auf das Adapter-Pattern ist diese API also die "Adapter"-Komponente, die wir innerhalb unserer Applikation (als "Client") verwenden.
class HTTPClient {constructor() {
// ...
}
async request(url, method, headers, body, config) {
return Promise.reject('Please implement');
}
async get(url, headers, body, config) {
return this.request(url, 'GET', headers, body, config)
}
async post(url, headers, body, config) {
return this.request(url, 'POST', headers, body, config)
}
// ...
}
Neben dieser internen API kommt jetzt die zweite (externe) API ins Spiel, die durch die externe Bibliothek (jetzt: axios) vorgegeben wird. Im Kontext des Adapter-Patterns handelt es sich bei dieser API um die "Adaptee"-Komponente. Das Bindeglied zwischen den beiden APIs (also zwischen "Adapter" und "Adaptee") kommt nun in Form eines "ConcreteAdapters", also einer konkreten Implementierung von HTTPClient. Für axios als Adaptee sähe eine – wohlgemerkt nur skizzierte – Implementierung wie folgt aus:
import HTTPClient from './HTTPClient';class AxiosAdapter extends HTTPClient {
constructor(axios) {
this._axios = axios;
}async request(url, method, headers, body, config) {
// hier Aufruf der "axios"-Bibliothek
// Adaptation der Parameter plus
// Adaptation des Rückgabewertes
}async get(url, headers, body, config) {
// ...
}// ...
}
Die Erzeugung der Adapter-Klasse lagern wir dabei aus, beispielsweise mit Hilfe einer Factory-Klasse (hey, noch ein GoF-Pattern!):
import axios from 'axios';
import AxiosAdapter from './AxiosAdapter';class HTTPClientFactory {
static createHTTPClient() {
return new AxiosAdapter(axios);
}}
Auf diese Weise können wir HTTP-Client-Instanzen in unserer Applikation wie folgt erzeugen und haben nichts direkt mit der externen API von axios zu tun:
import HTTPClientFactory from 'my-http-client';const client = HTTPClientFactory.createHTTPClient();
Knapp ein Jahr später – wir schreiben jetzt das Jahr 2020 – können wir uns glücklich schätzen, auf unseren Kollegen gehört zu haben. Mittlerweile wird unsere Klasse nicht mehr nur an 128 Stellen verwendet, sondern an 256! Diese würden wir nun wirklich nicht mehr alle ändern wollen.
Dass der Plan mit dem Adapter-Pattern aufgeht, merken wir auch, als es wieder soweit ist, die HTTP-Client-Bibliothek auszuwechseln: Nach einem Tweet [5] von Matteo Collina [6] werden wir auf die Bibliothek undici [7] aufmerksam. Zweimal so schnell wie der native HTTP-Client von Node.js soll sie sein. Das klingt sehr gut (zumal axios intern ja genau den nativen HTTP-Client verwendet). Sollten wir vielleicht wechseln? Klar, warum nicht?
Ist ja nicht viel Aufwand. Einfach eine neue Adapter-Klasse implementieren (hier wieder nur skizziert) ...
import HTTPClient from './HTTPClient';class UndiciAdapter extends HTTPClient {
constructor(undici) {
this._undici = undici;
}async request(url, method, headers, body, config) {
// hier Aufruf der "undici"-Bibliothek
// Adaptation der Parameter plus
// Adaptation des Rückgabewertes
}async get(url, headers, body, config) {
// ...
}// ...
}
... die Factory-Klasse anpassen ...
import undici from 'undici';
import UndiciAdapter from './UndiciAdapter';class HTTPClientFactory {
static createHTTPClient() {
return new UndiciAdapter(undici);
}}
... fertig!
Und falls wir doch wieder zur axios-Bibliothek zurückwechseln wollen, brauchen wir nur wenige Zeilen in der Factory ändern.
"Hätten wir aber auch ohne Adapter-Pattern lösen können", meint einer im Team. Ja, hätten wir. Wir hätten auch alles nur mit Funktionen funktional lösen können. Das macht die Sprache JavaScript ja gerade so vielseitig. Und ja, hinter der Klassensyntax stecken keine echten Klassen, wie man sie aus Sprachen wie Java kennt. Und ja, wegen fehlender Interfaces in JavaScript sind viele GoF-Patterns umständlich zu realisieren. Dennoch kann man nicht abstreiten, dass das objektorientierte Programmierparadigma inklusive der objektorientierten Denkweise (auch der Denkweise in Patterns) unter Entwicklern sehr verbreitet ist und sich auf diese Weise schnell ein gemeinsames Verständnis vom Code schaffen lässt.
In diesem Sinne bleibt in Bezug auf die Integration externer APIs festzuhalten:
"Objektorientiert oder funktional,
Hauptsache es passt, der Rest ist egal."
(Unbekannter Entwickler im Team)
URL dieses Artikels:https://www.heise.de/-5073865
Links in diesem Artikel:[1] https://github.com/request/request[2] https://twitter.com/mikeal[3] https://github.com/request/request/issues/3142[4] https://github.com/axios/axios[5] https://twitter.com/matteocollina/status/1298148085210775553[6] https://twitter.com/matteocollina[7] https://github.com/nodejs/undici
Copyright © 2021 Heise Medien
In den letzten Folgen war vom Raspberry Pi Pico die Rede. Bevor sich das Blog weiterhin dem Pico widmet, adressiert dieses Extra-Posting den neuen Microcontroller ESP32-C3 von Espressif. Da der Chip auf der offenen RISC-V-Architektur basiert, geht der Artikel auch auf deren Grundlagen ein.
Die intensive Nutzung von Open-Source-Software gehört für uns längst zum Alltag, egal ob Linux, OpenOffice, etliche IDEs, Bibliotheken oder Beispiele für Embedded-Entwicklung. Offene Hardware existiert zwar auch schon länger, ist aber weitaus weniger verbreitet. Mit der offenen RISC-V-Architektur könnte Open-Source-Hardware mehr Fahrt aufnehmen.
Der vorlegende Beitrag stellt zunächst die Grundlagen von RISC-V vor, um sich danach dem neuen Microcontroller ESP32-C3 von Espressif zu widmen, der RISC-V implementiert.
In der IT-Community kennt jeder die Systemfamilie der ARM-Architekturen, die Hersteller nach Zahlung von Lizenzgebühren zur Eigenentwicklung von Prozessoren nutzen können. Im Bereich der Embedded-Systeme, Mobilgeräte und SBCs (Einplatinencomputer) hat sich ARM längst durchgesetzt. Und Apple hat neuerdings begonnen, eigen entwickelte ARM-Chips sogar in Notebook- und Desktopsystemen zu verbauen.
Einer der Nachteile des ARM-Geschäftsmodells sind die Lizenzgebühren, was speziell für kleinere Hersteller zutrifft. Nicht alle Unternehmen können es sich schließlich leisten, Prozessoren zu entwerfen, die sich dem eigenen Anwendungsfall optimal anpassen. Mit der kostenfreien RISC-V-Architektur (ausgesprochen: “RISC-Five”) könnte sich daher ernsthafte Konkurrenz am Markt etablieren.
Während meines Studiums spielte RISC (Reduced Instruction Set Computer) eine wichtige Rolle. Den Anfang meines Arbeitslebens verbrachte ich folgerichtig vor RISC-basierten Sun-Workstations, unter deren Motorhaube SPARC-Chips steckten. RISC zeichnet sich gemäß der 80:20-Regel unter anderem dadurch aus, dass es sich auf wenige, häufig verwendete Maschineninstruktionen beschränkt, einen großen Satz an Registern besitzt und Instruktionen in der Regel mit der Breite von einem Maschinenwort, zum Beispiel mit 32 Bits oder 64 Bits, verwendet, deren Abarbeitung in einem CPU-Zyklus erfolgt. Das macht die Entwicklung solcher CPUs einfacher, den Bau von Compilern aber komplexer. Im Gegensatz dazu weisen CISC-CPUs (CISC = Complex Instruction Set Computer) wie die von AMD und Intel einen sehr mächtigen und dafür komplexen Befehlssatz auf. Weiterer positiver “Nebeneffekt”: Hersteller können sehr energieeffiziente RISC-CPUs bauen, womit sich Halbleiterriesen wie Intel oder AMD erfahrungsgemäß schwer tun.
Wesentliche Ingredienz jeder Prozessorfamilie ist der verwendete Befehlssatz (Instruction Set), weil er die Schnittstelle zwischen Hardwarearchitektur und Software vorgibt. Das betrifft Softwareentwickler zwar normalerweise wenig oder nicht, zumal sich durch Hardwareabstraktionsschichten wie dem Arduino Core, der JVM, der CLR oder einem Python-Interpreter die Hardware gut ausblenden lässt. Es betrifft aber die Entwickler von Compilern oder Interpretern, die für jede Hardware entsprechende Werkzeuge bereitstellen müssen. Daher wäre es von Vorteil, gäbe es einen einheitlichen Befehlssatz für Prozessoren. Das ist natürlich unrealistisch, aber ließe sich zumindest teilweise realisieren, womit wir bei RISC-V angelangt wären.
RISC-V [1]definiert einen offenen Befehlssatz, der nicht patentiert und stattdessen über eine BSD-Lizenz frei nutzbar ist. Seine Entwicklung begann 2010 an der University of California at Berkeley. Ziel war unter anderem das Bereitstellen einer eigenen Architektur für Lehrzwecke, speziell für die Vermittlung von Parallelisierung im Unterricht. Als die amerikanische DARPA und Unternehmen wie Microsoft und ST Microelectronics das Potenzial erkannten, hat sich aus dem akademischen Konzept eine Lösung für Universitäten und Industrie entwickelt.
Hauptgrund ist die Flexibilität: Die ISA (Instruction Set Architecture) von RISC-V lässt sich sowohl für die Kreierung von 32-Bit- als auch für die von 64-Bit-Prozessoren nutzen. Sogar 128-Bit-Prozessorerarchitekturen sind damit machbar, was die Zukunftssicherheit von RISC-V gewährleistet. Darüber hinaus eignet sich der zugrunde liegende Befehlssatz sehr gut für die Virtualisierung über Hypervisor, für Bare-Metal-Systeme oder als ideale Plattform für Betriebssysteme wie Linux.
Eine Hardwareplattform auf Basis von RISC-V enthält verschiedene Prozessorkerne, worunter sich auch solche befinden können, die nicht RISC-V-konform sind. Dazu stoßen gegebenenfalls Koprozessoren, die den Befehlssatz erweitern und sich in den RISC-V-Befehlsstrom integrieren. Zusätzlich existieren Accelerators (Beschleuniger), die eine abgeschlossene Funktion oder einen eigenen Kern definieren, und autonome Aufgaben leisten, etwa die der I/O-Verarbeitung.
Mithilfe dieses modularen Konzepts sind Hardwareimplementierungen vom Einkern-Microcontroller, über Many-Core-Systeme bis hin zu zu großen Clustern von Shared-Memory-basierten Netzwerkknoten denkbar.
Das Fundament von RISC-V bildet ein Befehlssatz für ganze Zahlen, der sich stark an die früheren RISC-Architekturen anlehnt. Eigentlich sind es sogar vier Befehlssätze, von denen sich einer auf 32-Bit-, ein anderer auf 64-Bit-Verarbeitung spezialisiert. Ein weiterer Befehlssatz reduziert die Zahl der Register für den Einsatz in Embedded-Controllern, während der vierte 128-Bit-Architekturen unterstützt. Alle genannten Basis-Befehlssätze sind erweiterbar. Sogar Befehle mit variablen Längen sind damit möglich (siehe RISC-V-Spezifikationen [2]).
Zu den Standarderweiterungen gehören unter anderem:
Obere Liste ist im übrigen nicht vollständig.
Wer den Befehlssatz einmal genauer unter die Lupe nehmen will, findet ihn zu Beispiel hier [3].
Die Komplexität eines RISC-V-Prozessorkerns, der alle Standard-Erweiterungen implementiert, kann also durchaus die luftigen Höhen einer General Purpose CPU erreichen.
Es gibt noch eine weitere spannende Dimension von RISC-V. Neben einer "Unprivileged"-Architektur, von der bislang die Rede war, existiert eine "Privileged"-Architektur, die einen Stack verschiedener Privilegierungsebenen definiert, angefangen von der Maschine über den Supervisor hin zu Anwendungen und Anwendern. Entwickler schreiben Code meistens für eine dieser Schichten. Code auf der Maschinenebene (M-mode) gilt üblicherweise als vertrauenswürdig und genießt die höchsten Privilegien. Dahingegen läuft Code auf der Supervisorebene (S-mode) mit weniger Privilegien ab. Hier tummeln sich zum Beispiel Betriebssysteme. Ganz oben – oder sollte ich lieber sagen ganz unten?! – laufen Anwendungen im "unterprivilegierten" U-Mode (U=User). Volume II des RISC-V Manuals zur Instruction Set Architecture adressiert die Privileged Architecture und führt entsprechende Erweiterungen ein, um Maschineninstruktionen mit verschiedenen Privilegierungsstufen zu unterstützen.
Da RISC-V "bloß" eine Spezifikation repräsentiert, heißt die Frage, ob an deren Umsetzung überhaupt jemand Interesse zeigt. Natürlich lautet die Antwort ja, weil sich dieses Posting sonst damit nicht beschäftigen würde. Beispielsweise entwickeln Western Digital und Nvidia entsprechende Implementierungen. Von der ETH Zürich stammt das RISC-V-basierte PULPino-Board.
Darf es etwas mehr sein? Zahlreiche weitere Produkte und Entwicklungen finden sich auf der Website von RISC-V. Daraus wird ersichtlich, dass RISC-V schon jetzt viele Anhänger besitzt, sowohl im universitären als auch im industriellen Bereich (siehe Liste [4]). Zum Üben mit dem RISC-V-Befehlssatz existiert eine Visual-Studio-Code-Erweiterung, die den Venus-Simulator verwendet (siehe hier [5]).
Der Embedded Bereich bietet inzwischen sogar einige Produkte für den "Hausgebrauch" wie:

Das Longan Nano lässt sich über Aliexpress für Preise ab rund 2,70 Euro erwerben und ist noch dazu kompatibel zu Arduino-Boards (siehe SiPEED-Webseite [6]).
Entwickler können folglich bereits entsprechende Produkte für bezahlbare und attraktive Preise erwerben. Daraus folgt: RISC-V ist inzwischen Realität und nicht bloß eine Sammlung von Spezifikationen. Das Explorieren kann somit beginnen.

Dankenswerterweise hat mir Espressif ein Vorserienmodell seines Boards mit dem Namen ESP32-C3-DevKitM-1 zur Verfügung gestellt. Das soll hier im Fokus stehen. Trotz des ESP32 in seinem Namen sollte man den Microcontroller ESP32-C3 eher als Evolution des ESP8266 betrachten. Genauer gesagt, positioniert er sich bezüglich Leistung und Fähigkeiten zwischen dem ESP8266 und dem ESP32.

Er soll auch zu sehr wettbewerbsfähigen Preisen auf den Markt kommen und zeigt sich wie seine Geschwister dank Bluetooth 5.0 und 2.4 GHz WiFi überaus kommunikativ. Der in 40-nm-Technik gefertigte RISC-V-Prozessor besitzt einen einzelnen Kern und erlaubt bis zu 160 MHz Taktfrequenz. Neben 384 KBytes ROM stehen 400 KBytes SRAM, darunter 16 KBytes als Cache zur Verfügung. Die Echtzeituhr verfügt darüber hinaus über 8 KByte Speicher.
Des Weiteren implementiert ein ESP32-C3 folgende Ports und Schnittstellen:

Eine integrierte PMU (Power Management Unit) sorgt mit fünf Energiestufen für die Anpassung an eigene Bedürfnisse, etwa für einen Tiefschlafmodus mit geringstmöglichem Energieverbrauch. Wer mehr Details über den ESP32-C3 erfahren möchte, findet im Web ein entsprechendes Datasheet [7].
Zum Experimentieren mit dem ESP32-C3 beziehungsweise dem Board ESP32-C3-DevKitM-1 gibt es eine gute Dokumentation [8] von Espressif. Programmieren können interessierte Entwickler entweder kommandozeilenorientiert über die ESP-IDF-Werkzeuge (siehe meinen früheren Artikel hier [9]) oder mit entsprechenden Plug-ins in Eclipse oder Visual Studio Code.
Das nachfolgende Beispiel führt zum Blinken der eingebauten LED. Das Programm nutzt die Multithreading-Unterstützung der FreeRTOS-Firmware, um den einzigen Thread jeweils gezielt für eine Sekunde anzuhalten. Der Rest der Anwendung definiert den GPIO für die eingebaute LED als Ausgang (gpio_set_direction())), setzt ihn mit reset()in einen definierten Zustand, um dann abwechselnd über ein gpio_set_level() erst ein 0- und dann ein 1-Signal auszugeben. Die printf()-Aufrufe sorgen für Textausgaben auf dem seriellen Terminal.
/* Blink Beispiel */
#include <stdio.h>
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "driver/gpio.h"
#include "sdkconfig.h"/* Genutzt wird der konfigurierte GPIO für die eingebaute LED */
#define BLINK_GPIO CONFIG_BLINK_GPIOvoid app_main(void) {
/* GPIO zurücksetzen */
gpio_reset_pin(BLINK_GPIO);
/* GPIO für die LED ist ein Ausgang */
gpio_set_direction(BLINK_GPIO, GPIO_MODE_OUTPUT);
while(1) {
/* LED aus */
printf("LED ausgeschalten");
/* das heisst 0 am GPIO ausgeben */
gpio_set_level(BLINK_GPIO, 0);
/* 1 Sekunde Wartezeit des Threads */
vTaskDelay(1000 / portTICK_PERIOD_MS);
/* LED ein */
printf("LED eingeschalten");
/* das heisst 1 am GPIO ausgeben */
gpio_set_level(BLINK_GPIO, 1);
/* 1 Sekunde Wartezeit des Threads */
vTaskDelay(1000 / portTICK_PERIOD_MS);
}
}
RISC-V hat großes Potenzial, sich zu einer Erfolgsgeschichte zu entwickeln. Gerade Halbleiterschmieden ergreifen die Chance der offenen Befehlsarchitektur, aber auch Embedded-Hersteller nutzen die Gunst der Stunde. Ob sich die Architektur auch auf Desktops oder Notebooks durchsetzen kann, bleibt abzuwarten. Für Entwickler ist es zunächst egal, welche Hardware ein System anbietet. Indirekt hätte aber eine einheitliche Befehlsarchitektur den Vorteil eines großen Software- und Hardware-Ökosystems. Und daher bleibt die weitere Entwicklung von RISC-V spannend.
In der nächsten Folge setzt sich dieser Blog wieder mit IDEs und Projekten für den Raspberry Pi Pico auseinander.
URL dieses Artikels:https://www.heise.de/-5072875
Links in diesem Artikel:[1] https://riscv.org/[2] https://riscv.org/specifications/[3] https://6004.mit.edu/web/_static/test/resources/references/6004_isa_reference.pdf[4] https://github.com/riscv/riscv-cores-list[5] https://marketplace.visualstudio.com/items?itemName=hm.riscv-venus[6] https://longan.sipeed.com/en/[7] https://www.espressif.com/sites/default/files/documentation/esp32-c3_datasheet_en.pdf[8] https://docs.espressif.com/projects/esp-idf/en/latest/esp32c3/get-started/index.html[9] https://www.heise.de/developer/artikel/ESP32-to-go-4452689.html
Copyright © 2021 Heise Medien
Es geht weiter mit der Reise durch das Pico-Land. Während in der letzten Folge die Python-IDE Thonny zur Sprache kam, konzentrieren sich die jetzige und die kommende Folge auf Visual Studio Code für die Pico-Entwicklung unter Python und C beziehungsweise C++.
Die Thonny-IDE eignet sich sowohl für den Einstieg in die Programmiersprache Python beziehungsweise MicroPython als auch für Experimente mit dem Raspberry Pi Pico. Deshalb war meine Andeutung in der vergangenen Folge etwas despektierlich, Thonny könnte bei (semi-)professionellen Entwicklern keinen Blumentopf gewinnen. Immerhin stellt es eine ideale Spielwiese zur Verfügung.
Für größere Projekten mit komplexerem Code und mehreren Beteiligten skaliert eine einfache IDE allerdings nicht. Dort benötigen Entwickler beispielsweise Werkzeuge für Sourcecode-Verwaltung, ausgereiftere Testmöglichkeiten und leistungsfähiges Management von Ressourcen wie Bibliotheken.
Doch woher nehmen und nicht stehlen? Vier Dinge brauchen anspruchsvollere Python-Entwickler, um auf einem Linux-, macOS- oder Windows-Host Anwendungen für den Raspberry Pi Pico zu entwickeln, wobei ausschließlich 64-Bit-Betriebssysteme infrage kommen:
Übrigens: Besitzer eines Computers mit Apple Silicon dürfen sich darüber freuen, dass alle Werkzeuge auch unter einem M1-basierten System zur Verfügung stehen.
Weitere gute Nachricht: Die genannten Anwendungen sind kostenlos verfügbar.
Für die Installation der Combo liefert der Entwickler von Pico-Go, Chris Wood, bereits eine ausführliche englischsprachige Dokumentation auf seiner Webseite [2]. Deshalb an dieser Stelle nur eine grobe Zusammenfassung der entsprechenden Referenzen:
Sind alle aufgezeigten Pakete betriebsbereit, lässt sich in VS Code die Erweiterung Pico-Go von Chris Wood installieren.

Zunächst empfiehlt es sich, einen Ordner für Python-Projekte zu kreieren, diesen unter VS Code zu öffnen, mit Ctrl + Shift + p (Windows, Linux) beziehungsweise Command + Shift + p (Mac) die Kommandopalette zu laden, um das Kommando Pico-Go | Configure project via Palette auszuführen. Dadurch sind unter anderem Code-Vervollständigung und Syntaxprüfung (Lint) nutzbar.
Sobald Nutzer einen Raspberry Pi Pico an das Hostsystem anschließen, erkennt ihn Pico-Go und teilt dies über die untere Statusleiste der IDE mit.
Jetzt können Entwickler unter VS Code eine Programmdatei (Endung .py) anlegen, um dort MicroPython-Quellcode einzufügen. Das fertige Programm lässt sich über das Run-Kommando (untere VS-Code-Statusleiste!) auf dem Pico ausführen, oder mittels Upload auf das Board kopieren, worauf der Pico einen Reset durchführt und danach das Programm automatisch startet. Wichtig: Vor dem Upload einer Programmdatei sollten Entwickler sie in main.py umtaufen, weil der Pico andernfalls nur das Programm ablegt, ohne es weiter zu beachten.
Nach erfolgreicher Installation und Konfiguration von Pico-Go ist es an der Zeit, sich dem eigentlichen Thema zu widmen, einem Embedded-Projekt für den Pico. Entstehen soll mithilfe des Sensors BME280 eine kleine Wetterstation, die periodisch Temperatur, Luftfeuchtigkeit und Luftdruck misst.

Grundsätzliche Idee: Über den Pico erfolgt der Zugriff auf den BME280-Sensor, der für die Erfassung der Messwerte für Temperatur, Luftfeuchtigkeit und Luftdruck zuständig ist. Die entsprechenden Werte stellt die Wetterstation auf dem SSD1306-Display dar. Zugleich gibt es eine kodierte Regel über das augenblickliche "Klima". Liegen die Werte im angenehmen Bereich, aktiviert das Programm die grüne LED. Sind Feuchtigkeit und Temperatur jenseits der eigenen Komfortzone, leuchtet die rote LED. Liegen die Werte irgendwo dazwischen, teilt die Anwendung dies über die gelbe LED mit. Diese Regel ist als eigene Funktion kodiert und lässt sich dementsprechend anpassen. Auch die Zeitdauer zwischen den Abfragen (SLEEPTIME ist konfigurierbar).

Übrigens können durch Auflegen einer Fingerspitze auf den BME280 Temperatur und Feuchtigkeit stark nach oben steigen. Insofern lässt sich die Klimaregel manuell testen.
Für das Projekt benötigen wir folgende Stückliste:
Gesamt: ca. 29 Euro
Wer bei den üblichen Verdächtigen in China zuschlägt, kann die Anschaffungssumme noch weiter reduzieren.
Auf dem mit Fritzing gezeichneten Schaltungsdiagramm sind rechts unten das OLED-Display SSD1306 mit 128x68 Punkten Auflösung abgebildet und rechts oben der Umweltsensor BME280. Beide sind mit dem I2C-Bus des Pico verbunden, SDA liegt dort auf Pin 6 (= GPIO 4) und SCL auf Pin 7 (= GPIO 5). GPIO steht für General Purpose IO.

Achtung: Die physikalischen Pins haben keinen direkten Bezug zu ihrer logischen Bezeichnung. Der physikalische Pin 6 entspricht zum Beispiel dem logischen Pin GPIO 4, der physikalische Pin 25 dem logischen Pin GPIO 19. In Anwendungen für den Pico oder einem anderen Raspberry Pi Board sind in der Regel die logischen Namen gemeint.

Damit ist schon alles Wesentliche über die Schaltung gesagt.
Kommen wir zur Software. Im ersten Schritt ist ein Treiber für das OLED-Display SSD1306 notwendig. Den hat bereits Stefan Lehmann vom Kunststoff-Zentrum Leipzig implementiert. Der Treiber lässt sich über seine Github-Seite [7] importieren.
Für die Ansteuerung des BME280 von Bosch habe ich einige Beispielimplementierungen unter die Lupe genommen und als Vorlage für einen eigenen Treiber kodiert. Bosch Sensortec stellt zu diesem Zweck ein hilfreiches Dokument über den Sensor auf seiner Webseite [8] zur Verfügung.
Der Sensor misst neben Temperatur (in Grad Celsius) und Feuchtigkeit (in Prozent) auch den Luftdruck (in mbar beziehungsweise HectoPascal). Wer auf die Messung der Luftfeuchtigkeit verzichten kann, sollte auf die billigere Variante BMP280 zugreifen. Dieser Sensor lässt sich teilweise bereits für unter einem Euro im Internet erwerben.
Damit niemand mühsam das Beispielprogramm abtippen oder mit Copy&Paste zusammenschneiden muss, habe ich den Code auf einer Github-Seite bereitgestellt. Hier der Link für das GitHub-Repository [9].
Im Folgenden kommen hauptsächlich einige wichtige Fragmente zur Sprache, die dem Verständnis dienen.
Für die Implementierung des Programmes sind einige Bibliotheken notwendig, die meisten davon aus den Pico- beziehungsweise Micropython-SDKs. Die Bibliothek für die Ansteuerung des OLED-Displays ist, wie bereits erwähnt, auf GitHub zu finden.
from machine import Pin, I2C # Wir brauchen Pin und I2C des Pico
from micropython import const
from ustruct import unpack as unp
from ssd1306 import SSD1306_I2C # Modul für SSD1306
import utime # Zwei Zeit-Bibliotheken
import time
Für die Entscheidung, ob das Wetter gut, schlecht, mittel ist, fungiert die Funktion condition(). Diese enthält eine eigene Regel, die jeder für sich selbst ändern kann:
#--Condition ----------------------
COND_RED = 1 # Schlechtes Klima
COND_GREEN = 2 # Angenehmes Klima
COND_YELLOW = 3 # Mittleres Klima
#----------------------------------ComfortZoneTemp = (15,25) # Meine Komfortzone für Temperatur liegt zwischen 15 und 25 Grad
ComfortZoneHumi = (10,40) # Meine Komfortzone für Feuchtigkeit liegt zwischen 10 und 40%
#
def condition(temperature, humidity, pressure):
niceTemperature = temperature >= ComfortZoneTemp[0] and temperature <= ComfortZoneTemp[1]
niceHumidity = humidity >= ComfortZoneHumi[0] and humidity <= ComfortZoneHumi[1]
if niceHumidity and niceTemperature:
return COND_GREEN
elif (niceHumidity != niceTemperature): # XOR
return COND_YELLOW
else:
return COND_RED
Die Anwendung initialisiert den I2C-Bus zum Zugriff auf BME280 und SSD1306:#
Die Anwendung initialisiert den I2C-Bus zum Zugriff auf BME280 und SSD1306:
sda = Pin(4) # BME280 und SSD1306 sind an GPIO 4 und 5 angeschlossen
scl = Pin(5)
i2c = I2C(0,sda=sda,scl=scl,freq=400000) # I2C-Bus 0
i2c_addr_bme = 0x76 # Ich gehe davon aus, der BME280 liegt an 0x76
Die LEDs befinden sich an den GPIO-Ports 19, 20, 21:
GreenLED = Pin(21, Pin.OUT) # Grüne LED an GPIO 21
YellowLED = Pin(20, Pin.OUT) # Gelbe LED an GPIO 20
RedLED = Pin(19, Pin.OUT) # Rote LED an GPIO 19
Die Variable SLEEPTIME legt die Zeit zwischen zwei Messungen fest:
SLEEPTIME = 5
Hinter der Klasse BMX280 verbirgt sich der Treiber für den Umweltsensor. Deren Konstruktor nimmt etliche Initialisierungen vor. Interessant für Anwender ist hauptsächlich die Methode measure(), weil sie Druck, Feuchtigkeit und Temperatur zurückliefert.
class BMX280:
# Im Konstruktor werden primäre Datenmember und Konstanten belegt
def __init__(self, i2c, i2c_addr_bme)
def measure(self)
# ... diverse Hilfsmethoden ...
Das Hauptprogramm der Software sucht zunächst nach Sensoren und Aktoren am I2C-Bus – optional, weil abhängig von der Belegung der boole’schen Variable debug.
if debug:
print('Ich habe an folgenden Adressen Komponenten am I2C-Bus entdeckt:')
devices = i2c.scan()
if devices:
for i in devices:
print(hex(i))
utime.sleep_ms(2000)
Gilt debug == True, erfolgt an weiteren Stellen die Bildschirmausgabe am Terminal der IDE.
Anschließend initialisiert die Anwendung die Treiber für SSD1306 (Klasse SSD1306_I2C) und BME280 beziehungsweise BMP280 (Klasse BMX280).
In der Hauptschleife liest der Code über measure() die Wetterwerte ein, aktiviert abhängig von den Messwerten entweder die rote, grüne oder gelbe LED, und stellt die Werte am OLED-Display dar. Nach einer Wartezeit folgt der Übergang zur nächsten Messrunde:
oled = SSD1306_I2C(128,64,i2c)
bme = BMX280(i2c = i2c, i2c_addr_bme = i2c_addr_bme)oled.fill(0)
oled.show()# HAUPTSCHLEIFE #
while True:
temperature, humidity, pressure = bme.measure()
#......................
currentState = condition(temperature, humidity, pressure)
if currentState == COND_GREEN:
GreenLED.value(1)
YellowLED.value(0)
RedLED.value(0)
if debug:
print("Angenehmes Klima")
elif currentState == COND_YELLOW:
GreenLED.value(0)
YellowLED.value(1)
RedLED.value(0)
if debug:
print("Geht so")
elif currentState == COND_RED:
GreenLED.value(0)
YellowLED.value(0)
RedLED.value(1)
if debug:
print("Unangenehmes Klima")
# ......................
oled.fill(0)
oled.text("Heise Wetter", 5, 10)
# Formatierte Ausgabe mit 7 Ziffern bei 2 Nachkommastellen
oled.text(str('% 7.2f' % temperature) + " Grad", 5,20)
oled.text(str('% 7.2f' % humidity) + " %",5,30)
oled.text(str('% 7.2f' % pressure) + " HPa",5,40)
# Und jetzt enthuellen
oled.show()
utime.sleep(SLEEPTIME) # Schlafen bis zur nächsten Messung
Der fertige und funktionierende Versuchsaufbau sieht folgendermaßen aus:

Das Beispielprojekt hat erste Einblicke in die MicroPython-Programmierung des Pico unter Visual Studio Code gegeben. Ein Problem, das sich momentan noch zeigt, sind fehlende Module für die Ansteuerung einiger Bauteile, insbesondere von Breakout-Boards und komplexeren Sensoren. Da der Pico noch sehr neu ist, dürfte sich dies in den nächsten Monaten ändern und dadurch ein ähnlich breites Ökosystem entstehen, wie es bei Arduino, Espressif (ESP32, ESP8266), Raspberry Pi Single-Board-Computer, Adafruit, Sparkfun und ST Microelectronics bereits der Fall ist.
Natürlich gibt es für das gezeigte Beispiel diverse Optimierungsmöglichkeiten, etwa:
Interessierte Leser haben also noch genug Möglichkeiten, sich weiter auszutoben.
Der Fokus dieses Artikels lag auf MicroPython. Übrigens existiert auch CircuitPython (entwickelt von Adafruit) als Alternative, aber davon soll nicht weiter die Rede sein, da die konzeptionellen Unterschiede eher marginal sind. In der nächsten Folge geht es um die Programmierung mit C beziehungsweise C++.
Bis dahin viel Spaß beim Picomentieren.
URL dieses Artikels:https://www.heise.de/-5066047
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/VS-Code-lebt-Entwicklung-von-Embedded-Software-mit-PlatformIO-4464669.html[2] http://pico-go.net/docs/start/quick/[3] https://www.python.org/downloads/[4] https://nodejs.org/en/download/[5] https://code.visualstudio.com/download[6] https://code.visualstudio.com/insiders/[7] https://github.com/stlehmann/micropython-ssd1306[8] https://www.bosch-sensortec.com/media/boschsensortec/downloads/datasheets/bst-bme280-ds002.pdf[9] https://github.com/ms1963/DerPragmatischeArchitekt-WetterStation
Copyright © 2021 Heise Medien
Der letzte Artikel [1]hat das neue Board Raspberry Pi Pico vorgestellt. In diesem und den nachfolgenden Teilen ist von den verschiedenen Möglichkeiten die Rede, wie sich das Board zum Leben erwecken lässt. Die Reise beginnt mit der kostenlosen Python-IDE Thonny.
Die Thonny-IDE bietet eine Python-Shell, die eher einfachen und mittleren Ansprüchen genügt. Für höhere Anforderungen haben ihre Schöpfer sie allerdings auch nicht entwickelt. Ihre Entwicklung erfolgte durch die University of Tartu in Estland, um einen einfachen Einstieg in das Programmieren mit Python zu ermöglichen.
Um die Programmierung für das Pico-Board zu illustrieren, ist das aber mehr als ausreichend. Bevor die Artikelreihe auf ausgefeilte IDEs für Pros zu sprechen kommt, verhilft Thonny-IDE zu ersten Erfahrungen mit dem Raspberry Pi Pico. Darüber hinaus ist die freie IDE auf Raspberry Pi OS bereits vorinstalliert, sodass Raspi-Nutzer nichts weiter zu tun haben und sich jetzt gemütlich zurücklehnen können. Zu guter Letzt sei angemerkt, dass die Programmierumgebung eine vollständige Implementierung von Python 3.7 mitbringt, weshalb sich keine weiteren Installationsorgien als notwendig erweisen.
Auf der Thonny-Webseite [2] lassen sich Versionen für Windows, macOS oder Linux-Distributionen herunterladen:
Nach Durchführung des Downloads auf Windows oder macOS starten Anwender die Installation durch Ausführung des Installationspakets. Linux-Anwender nutzen entweder ihren jeweiligen Paketmanager oder andere Möglichkeiten zur Installation (siehe Thonny auf GitHub [3]).
Exemplarisch die Illustration für Windows-PCs. Nach Start der Installation ergibt sich folgendes Bild:
Danach findet sich das Programm auf dem Zielsystem. Bei Start der fertig installierten IDE öffnet das schlichte IDE-Fenster von Thonny, das in der oberen Hälfte einen Editor und in der unteren Hälfte eine REPL-Shell (Read Eval Print Loop) enthält. Fürs interaktive Experimentieren bietet die Shell eine ideale Spielwiese.
Unten rechts im Fenster zeigt Thonny den aktuell genutzten Python-Interpreter textuell an, im vorliegenden Fall also Python 3.7.9. Allerdings laufen auf den meisten Embedded Boards nur abgespeckte Python-Varianten wie CircuitPython oder MicroPython, wobei der Pico per default Letzteres unterstützt.
Um die geeignete Variante zu erhalten, genügt ein Mausklick auf das Textfeld "Python 3.7.9". Anschließend bietet Thonny ein Auswahlmenü mit allen unterstützten Interpretern, unter anderem "MicroPython (Raspberry Pi Pico)":

Vor der Selektion von MicroPython sollten Entwickler das Raspberry-Pi-Pico-Board mit gedrückter BOOTSEL-Taste an einen USB-Eingang des Hostrechners anschließen. Dadurch identifiziert sich das Board gegenüber dem Host als Speichergerät, etwa als Speicherstick. Anschließend wählen Entwickler wie oben erwähnt in Thonny die Option "MicroPython (Raspberry Pi Pico)" als zu installierenden Interpreter, worauf folgender Dialog erscheint:
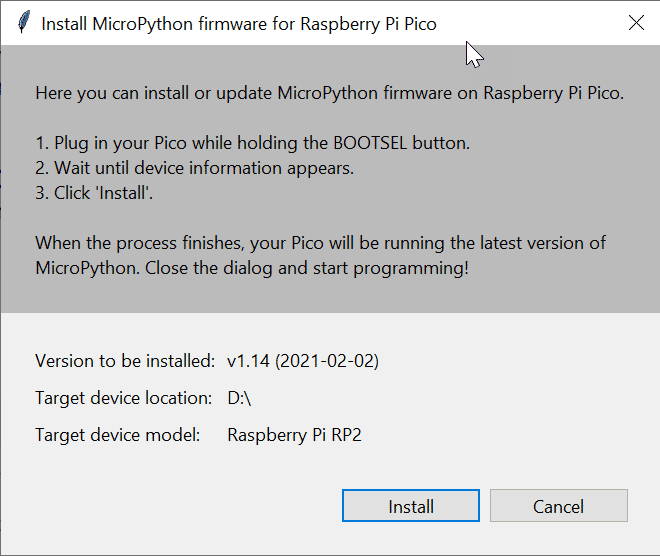
Klicken Anwender auf den Install-Button, startet die Installation der MicroPython-Firmware. Nach Beendigung der Firmware-Installation müssen Anwender nur noch das Dialogfenster schließen:
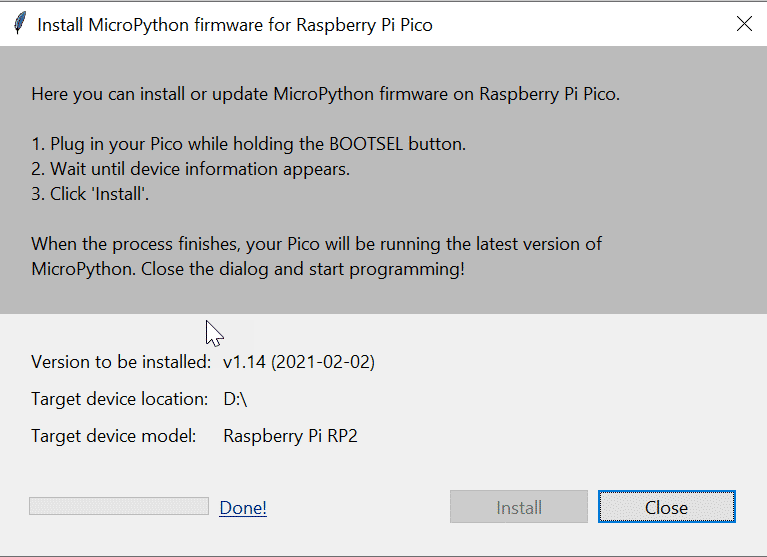
Die Firmware besteht aus einem lauffähigen Programm mit der Endung .UF2. Sie lässt sich auch manuell auf den Pico übertragen.
Nun sind Host und Pico miteinander verbunden, und Entwickler können entweder über die REPL-Shell direkt mit dem MicroPython-Interpreter arbeiten oder alternativ ein Programm in den Editor eingeben. Wichtig ist an dieser Stelle, dass nach Übertragen eines MicroPython-Programms auf das Board (Endung: .py) das Board erst herunter- und dann wieder hochfährt, worauf das Laufzeitsystem automatisch das Python-Programm ausführt.
Befinden sich allerdings mehrere Programmdateien auf dem Board, weiß der Pico zunächst nicht, welche er ausführen soll. In diesem Fall sucht er nach einer Datei namens main.py, um sie auszuführen oder verharrt regungslos, sollte er diese Datei nicht finden.
Jetzt ist es endlich an der Zeit, ein einfaches MicroPython-Programm zu schreiben, um den Zugriff auf das I/O-System des Boards zu testen. Wie traditionell üblich, soll das erste Programm die interne LED des Pico zum Blinken bringen, bevor wir in nachfolgenden Folgen weitere Möglichkeiten des Pico kennenlernen:
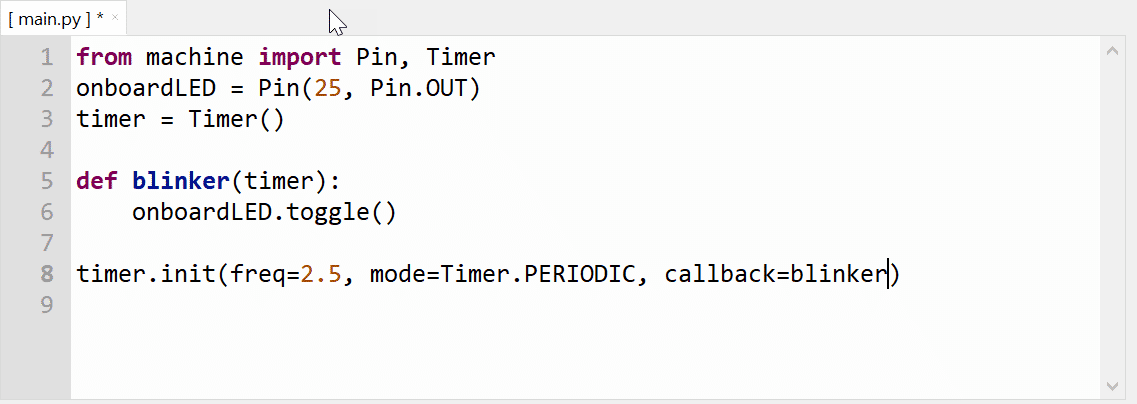
Nun sezieren wir das Programm Schritt für Schritt:
from machine import Pin, Timer
Die import-Anweisung nutzt aus der machine-Bibliothek die Komponenten Pin und Timer. Erstere erlaubt den Zugriff auf die I/O-Ports des Pico, Letztere stellt Funktionen zur zeitlichen Steuerung von Aktionen zur Verfügung. Überhaupt enthält – nomen est omen – machine diverse Komponenten zum Zugriff auf die Pico-Hardware.
onboardLED = Pin(25, Pin.OUT)
Nun erfolgt die Initialisierung der Variablen onboardLED. Sie soll GPIO-Port 25 repräsentieren, an dem sich die eingebaute LED befindet. Wichtig: Die Zahlen beziehen sich nicht auf das physikalische Pin 25, sondern auf den GPIO-Port 25, für den es noch nicht einmal einen physikalischen Pin gibt.

Der zweite Parameter im Konstruktor namens Pin teilt dem Interpreter mit, wie der I/O-Port verwendet werden soll, nämlich im vorliegenden Fall als Ausgabe-Port. Daher die Konfiguration mit Pin.OUT.
timer = Timer()
Hier initialisiert das Programm die Variable timer. Dazu gleich mehr.
def blinker(timer):
onboardLED.toggle()
Die Methode blinker erhält als Argument ein initialisiertes timer-Objekt. Immer wenn der timer dazu die Initiative gibt, erfolgt der Aufruf der toggle-Methode. Die setzt den Ausgang abhängig von deren momentanen Zustand entweder von 0 auf 1 oder von 1 auf 0, was folglich zum Blinken der LED führt.
timer.init(freq = 2.5, mode = Timer.PERIODIC, callback = blinker)
In der Initialisierungsmethode init definiert das Programm einen periodisch feuernden Timer (Timer.PERIODIC) mit einer Frequenz von 2,5. Daraus folgt eine Periode von 400 Millisekunden. timer ruft zu diesem Zweck alle 400 Millisekunden eine Callback-Funktion auf (callback = blinker). In unserem Fall ist das die blinker-Methode, die dementsprechend alle 400 Millisekunden das Ausgangssignal für die LED invertiert.
Nach getaner Arbeit können Entwickler entweder für die direkte Programmausführung auf dem Pico sorgen, indem sie auf das grüne Icon oder den entsprechenden Menüpunkt klicken. Oder sie sichern das Programm auf das Pico-Board, worauf das Board resettet, um anschließend mit der Programmausführung zu beginnen. Selbstredend lässt sich die Programmdatei auch auf dem Hostrechner abspeichern:
Wenig überraschend sollte sich jetzt folgendes Geschehen zeigen:

Damit wäre das erste MicroPython für den Raspberry Pi Pico geschafft. Zwar ein triviales Beispiel, aber ein lehrreicher erster Schritt.
Dieser Artikel hat sich in seichtem Wasser bewegt. Die Thonny-IDE taugt als ideale Spielwiese, um den Pico interaktiv kennenzulernen. Als professionelle Entwicklungsumgebung kann sie hingegen nicht fungieren. Sie macht allerdings den Einstieg sehr leicht, was schließlich der Sinn des vorliegenden Artikels war. Ich hoffe, Sie haben jetzt noch viel Spaß mit eigenen Experimenten. In den nächsten Teilen wird das Fahrwasser etwas rauer, aber auch unterhaltsamer.
URL dieses Artikels:https://www.heise.de/-5057160
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/Ein-Picobello-Microcontroller-Raspberry-Pi-Pico-Board-5045274.html[2] https://thonny.org[3] https://github.com/thonny/thonny/wiki/Linux[4] https://datasheets.raspberrypi.org/pico/raspberry-pi-pico-python-sdk.pdf[5] https://micropython.org[6] https://micropython.org/download/rp2-pico/
Copyright © 2021 Heise Medien
Micro Frontends verfolgen einen ähnlichen Ansatz wie Microservices, nur in einer völlig unterschiedlichen Umgebung. Daher ergeben sich auch andere Vor- und Nachteile sowie eine veränderte Herangehensweise bei der Konzeption und Umsetzung.
Serverseitig hat sich das Architekturmuster der Microservices gerade für umfangreiche Applikationen als Alternative zu einem monolithischen Ansatz etabliert. Einen ähnlichen Zweck verfolgen Entwickler mittlerweile auch im Frontend mit Micro Frontends. Die Idee dahinter ist, einige der Vorteile von Microservices auch im Frontend nutzbar zu machen. Doch bevor wir uns der Frage widmen, ob Micro Frontends der neue Standard für die Entwicklung von Web-Frontends werden, werfen wir einen Blick auf die Microservice-Architektur.
Die Idee hinter Microservices ist, ein großes Problem in mehrere Teilprobleme zu zerlegen und sie getrennt voneinander zu bewältigen. Dieser Architekturansatz geht noch einen Schritt weiter als eine gewöhnliche Modularisierung von Applikationen, da hier nicht der Schnitt an fachlichen Grenzen innerhalb einer Applikation gemacht wird, sondern das Ganze noch weiter geht und die Bereiche in einzelne, unabhängige Systeme teilt, die durch Schnittstellen miteinander verbunden sind. Die Vorteile, die durch eine solche Microservice-Architektur entstehen, sind:
Sicherlich hat eine Microservice-Architektur nicht nur ihre Vorteile. Die Komplexität in der Kommunikation zwischen den einzelnen Services steigt deutlich an. Hinzu kommt, dass es sich hierbei um Kommunikation zwischen eigenständigen Systemen handelt. Die Entwickler müssen sich also um Problemstellungen wie potenziellen Nachrichtenverlust, synchrone- und asynchrone Kommunikation kümmern. Entwickeln die einzelnen Service-Teams unabhängig voneinander, erfordert dies einen zusätzlichen Koordinationsaufwand, wenn es um die Versionierung der Services geht. Hierbei muss sichergestellt sein, dass die Services der Applikation untereinander kompatibel bleiben.
Micro Frontends verfolgen einen ähnlichen Ansatz wie Microservices, jedoch in einer völlig anderen Umgebung. Daraus ergibt sich eine andere Bewertung der Architekturform. Wo sich eine Microservice-Architektur für eine Vielzahl von Applikationen lohnt, sind die Anwendungsfälle für Micro Frontends deutlich eingeschränkter.
Doch werfen wir zunächst einen Blick auf die wesentlichen Unterschiede zwischen Frontend und Backend und wie sie sich auf die Architektur auswirken. Der Browser führt eine Applikation als einzelne Instanz aus. Im Gegensatz dazu sind Backend-Services unabhängig voneinander (man hat also mehrere Instanzen). Das wirkt sich vor allem auf die Skalierbarkeit der Applikation aus. Bei einer Lastspitze fährt die Backend-Infrastruktur zusätzliche Instanzen der betroffenen Services hoch und verteilt die Last entsprechend. Ist der Browser unter Last, bringt es zugegebenermaßen wenig, ein weiteres Browserfenster mit einer neuen Instanz der Applikation zu öffnen. Der Browser kann nur auf Worker-Prozesse zugreifen, die allerdings vom Rendering abgekapselt sind und lediglich für Berechnungen und Serverkommunikation eingesetzt werden können.
Das Skalierungsverhalten von Front- und Backend unterscheidet sich also grundlegend. Auch beim Thema Robustheit gibt es gravierende Unterschiede: Hier wird häufig das Bild von Pets vs. Cattle aufgegriffen, also der Unterschied zwischen Haustieren und Nutztieren. In einer Microservice-Architektur sind die einzelnen Instanzen wie Nutztiere, zu denen die Betreiber der Plattform ein eher distanziertes Verhältnis pflegen sollten. Stürzt ein Service ab, wird er durch eine neue Instanz ersetzt. Im Browser lässt sich eine solche Vorgehensweise nicht realisieren, denn es gibt nur den einen Hauptprozess. Stürzt dieser ab, war's das. Die Entwickler sollten ihn also mit umfangreicher Fehlerbehandlung hegen und pflegen wie ein Haustier.
Das Thema Einfachheit betrifft sowohl Front- als auch Backend. Kleinere Einheiten, die für sich stehen, sind in beiden Welten deutlich einfacher zu handhaben als ineinander verflochtene, umfangreiche Konstrukte. Die Flexibilität, die eine Microservice-Architektur im Backend hinsichtlich der Wahl der Sprachen und Technologien bietet, muss im Frontend auch wieder differenziert betrachtet werden. Im Backend können die Entwickler die für die jeweilige Problemstellung passende Kombination aus Programmiersprache, Frameworks und Bibliotheken auswählen. Der Browser schränkt diese Auswahl im Frontend deutlich ein. Neben JavaScript und zu einem geringen Teil WebAssembly lässt er keine weiteren Programmiersprachen direkt zu. Eine Ausnahme bilden hier nur Sprachen, die in JavaScript oder WebAssembly übersetzt werden, wie es mit TypeScript, CoffeeScript oder C# in Form von Blazor der Fall ist.
Bleibt also nur noch die Auswahl an Bibliotheken und Frameworks, die in diesem Bereich zugegebenermaßen sehr umfangreich ist. Besteht eine Applikation aus mehreren kleinen Teilen und sind diese mithilfe verschiedener Bibliotheken und Frameworks umgesetzt, lädt der Browser die erforderlichen Ressourcen zur Darstellung der Applikation vom Server, was einen erheblichen Overhead im Vergleich zu einer traditionell monolithisch aufgebauten Applikation bedeuten kann.
Bei einer Micro-Frontend-Architektur setzt sich die Applikation aus mehreren voneinander unabhängigen Micro Frontends zusammen. Diese einzelnen Bestandteile werden in einer Integrationsschicht zusammengefügt. Das wird nötig, da es für den Browser immer ein Dokument gibt, das er initial vom Server lädt. Beim Aufbau einer Micro-Frontend-Architektur gilt Ähnliches wie bei den Microservices im Backend: Es gibt nicht den einen richtigen Weg, sie umzusetzen, vielmehr existieren zahlreiche Facetten dieser Architekturform.
Die einfachste Möglichkeit besteht darin, die einzelnen Micro Frontends über iFrames einzubetten. Diese Variante ist zwar nicht sonderlich elegant, stellt jedoch sicher, dass die einzelnen Teile der Applikation tatsächlich unabhängig voneinander sind. Weitere Möglichkeiten sind die Kapselung der Micro Frontends in Web Components oder der Einsatz von zusätzlichen Bibliotheken wie single-spa, die die friedliche Koexistenz verschiedener Frontend-Frameworks in einer Applikation erlauben.
Ein großes Problem bei der Umsetzung von Micro Frontends mit verschiedenen Bibliotheken ist die bereits erwähnte Paketgröße, da im schlechtesten Fall mehrere vollwertige Frameworks parallel ausgeliefert werden müssen. Dieses Problem lässt sich nur auf zwei Arten lösen: Entweder werden keine größeren Bibliotheken eingesetzt oder die Entwicklerteams der einzelnen Micro Frontends einigen sich auf gewisse Konventionen. So kann die Verwendung nur eines Frameworks festgelegt werden, und die Teams entwickeln dann nicht komplett eigenständige Applikationen, sondern Module, die die Integrationsschicht zusammenführt. Der Entwicklungsprozess einer solchen Architektur ist also geprägt von Kompromissen und einer Gratwanderung zwischen völliger Flexibilität und Einschränkungen durch Konventionen. Wie die Vorgehensweise konkret aussieht, hängt stark vom Einsatzzweck und den Rahmenbedingungen der Gesamtapplikation ab.
Wie über so ziemlich jedes Thema in der Entwicklung, werden auch über Micro Frontends leidenschaftliche Diskussionen geführt. Und wie so oft sollte jeder auch dieser Architekturform seine Daseinsberechtigung zusprechen. Natürlich sind Micro Frontends nicht die Silver Bullet, die alle Probleme in der Web-Entwicklung lösen. Aber gerade für umfangreiche Applikationen mit mehreren beteiligten Teams kann eine Micro-Frontend-Architektur eine potenzielle Lösung sein.
Ein Szenario, in dem Micro Frontends ihre Stärke wirklich ausspielen, sind Migrationen. Hat eine bestehende Applikation ihren Zenit überschritten, steigen die Kosten für die Wartung und Weiterentwicklung deutlich an und für die Entwickler ist die Arbeit an einem solchen gewachsenen Stück Software kein wirkliches Vergnügen mehr. Also steht irgendwann die Frage eines Rewrites im Raum. Das Neuschreiben einer Applikation birgt jedoch beträchtliche Risiken, die bis hin zum Scheitern des Unterfangens reichen.
Eine Migration der alten Software mithilfe einer Micro-Frontend-Architektur auf die neue Version ist eine Möglichkeit, die Risiken in den Griff zu bekommen. Hierfür schaffen die Entwickler zunächst die Integrationsschicht, in die die bestehende Software eingebettet wird, sodass sie funktioniert wie bisher. Anschließend können sie sich schrittweise daran machen, die Features durch neue Versionen zu ersetzen. Die Integrationsschicht sorgt dann dafür, dass die Benutzer die neue Version erhalten und die alte Version wird abgeschaltet.
Sobald alle Features migriert sind, kann die alte Applikation gelöscht und auch die Integrationsschicht kann, falls sie nicht mehr benötigt wird, zurückgebaut werden. Der Vorteil dieser Vorgehensweise ist, dass es keinen Big-Bang-Release gibt, die Migration schleichend erfolgt und es zu keinem Stillstand bei der Entwicklung neuer Features kommen muss.
Abschließend bleibt nur noch zu sagen, dass jedes Team die Entscheidung für die Architektur seiner Applikation selbst treffen muss. Es ist dabei allerdings hilfreich, möglichst viele verschiedene Alternativen zu kennen und die jeweils beste auszuwählen. Ob es also ein sauber modularisierter Monolith oder eine Micro-Frontend-Architektur wird, hängt von der Problemstellung und den Vorlieben der Entwickler ab.
URL dieses Artikels:https://www.heise.de/-5057255
Copyright © 2021 Heise Medien
Für die Arbeit mit der Systemzwischenablage stellt die W3C-Spezifikation "Clipboard API and events" zwei APIs zur Verfügung: die synchrone "Clipboard Event API" und die asynchrone "Asynchronous Clipboard API".
Der programmatische Zugriff auf die Zwischenablage innerhalb einer Webanwendung hat in den letzten Jahren einen Wandel durchgemacht. Noch vor ein paar Jahren griff man gerne auf Bibliotheken wie ZeroClipboard [1] zurück, die unter der Haube Flash voraussetzten. Mit dem Verschwinden von Flash in die Bedeutungslosigkeit verloren allerdings auch diese Bibliotheken an Bedeutung. Die execCommand API [2] wiederum, über die man unter anderem programmatisch Befehle wie das Kopieren oder Einfügen ausführen kann, leidet unter Interoperabilitätsproblemen, gilt mittlerweile als veraltet [3] und wird aller Voraussicht auch nicht mehr über den Status eines "Unofficial Draft" hinauskommen. Hinzu kommt, dass hierüber Daten nur aus dem DOM gelesen und auch nur in das DOM geschrieben werden können:
// Achtung: veraltet!// Kopieren
const source = document.querySelector("#source");
source.select();
document.execCommand("copy");// Und Einfügen
const target = document.querySelector("#target");
target.focus();
document.execCommand("paste");
Beim W3C liegt der Fokus der Entwicklung daher auf der Spezifikation "Clipboard API and events" [4], die aktuell als Working Draft vorliegt. Sie definiert für die Arbeit mit der Systemzwischenablage zwei verschiedene APIs: die Clipboard Event API [5] (bzw. Synchronous Clipboard API) und die relativ neue Asynchronous Clipboard API [6].
Die Clipboard Event API [7] bietet zum einen die Möglichkeit, sich in die gängigen Operationen auf der Zwischenablage "einzuhaken", sprich auf Events zu reagieren, die beim Ausschneiden, Kopieren und Einfügen ausgelöst werden sowie zum anderen synchron schreibend und lesend auf die Zwischenablage zuzugreifen.
Für Ersteres definiert die API vier verschiedene Events:
Auf diese Events kann man, wie in folgendem Listing gezeigt, über entsprechende Event-Listener reagieren. Der EventListener für das copy-Event definiert, was passieren soll, wenn innerhalb der Webseite eine Kopieraktion durchgeführt wird. Über die Eigenschaft clipboardData des entsprechenden Events gelangt man an ein Objekt vom Typ DataTransfer. Zur Erinnerung: Dieses Objekt repräsentiert ein Objekt, das ursprünglich für den Datentransfer bei Drag&Drop-API-Aktionen [8] zuständig ist. Über die Methode setData() können an diesem Transferobjekt die zu übertragenden Daten definiert werden, wobei der Methode als erster Parameter das Format der Daten (in Form des MIME-Typen) und als zweiter Parameter die eigentlichen Daten übergeben werden. Auf der Gegenseite (innerhalb des Event-Listeners, der für die Einfügeoperation zuständig ist) werden analog über die Methode getData() unter Angabe des MIME-Typen die Daten aus dem Transferobjekt gelesen.
document.addEventListener('copy', (event) => {
const { clipboardData } = event;
clipboardData.setData(
'text/plain',
'Dieser Text kommt synchron in die Zwischenablage.'
);
event.preventDefault();
});document.addEventListener('paste', (event) => {
const { clipboardData } = event;
const data = clipboardData.getData('text/plain');
console.log(data);
// => "Dieser Text kommt synchron in die Zwischenablage."
event.preventDefault();
});
Grundsätzlich kann ein Transferobjekt Daten für verschiedene Formate enthalten. Auf diese Weise lassen sich in einer einzelnen Kopier- beziehungsweise Einfügeoperation die Daten direkt in mehreren Formaten übertragen. Das ist beispielsweise dann praktisch, um abhängig vom Ziel der Einfügeoperation die Daten entweder in dem einen oder dem anderen Format zu verarbeiten beziehungsweise. einzufügen. Folgendes Listing zeigt, wie auf diese Weise gleichzeitig Daten als einfacher Text, als formatierter HTML-Text und als JSON übertragen werden können (da sich die Daten nur als Zeichenkette übergeben lassen, muss im Fall von JSON entsprechend serialisiert (JSON.stringify()) und deserialisiert (JSON.parse()) werden).
document.addEventListener('copy', (event) => {
const { clipboardData } = event;
console.log(clipboardData);
clipboardData.setData(
'text/plain',
'Dieser Text kommt synchron in die Zwischenablage.'
);
clipboardData.setData(
'text/html',
'Dieser <strong>Text</strong> kommt synchron in die Zwischenablage.'
);
clipboardData.setData(
'application/json',
JSON.stringify({
message: 'Dieser Text kommt synchron in die Zwischenablage.'
}));
event.preventDefault();
}); document.addEventListener('paste', (event) => {
const { clipboardData } = event;
const data = clipboardData.getData('text/plain');
console.log(data);
// => "Dieser Text kommt synchron in die Zwischenablage."
const dataHTML = clipboardData.getData('text/html');
console.log(dataHTML);
// => "<meta charset='utf-8'>Dieser <strong>Text</strong> \
// kommt synchron in die Zwischenablage."
const dataJSON = JSON.parse(clipboardData.getData('application/json'));
console.log(dataJSON);
// => { message: "Dieser Text kommt synchron in die Zwischenablage." }
event.preventDefault();
});
Der oben beschriebene synchrone Zugriff auf die Zwischenablage eignet sich – weil die Ausführung der Webanwendung während der Kopier- beziehungsweise Einfügeoperation blockiert wird – nur für Daten, die eine überschaubare Größe haben. Möchte man dagegen komplexere oder größere Daten wie Bilddaten in die Zwischenablage kopieren oder aus der Zwischenablage in eine Webanwendung einfügen, greift man besser auf die Asynchronous Clipboard API [9] zurück. Wie der Name vermuten lässt, können Daten hierüber asynchron in die Zwischenablage geschrieben und aus ihr gelesen werden, ohne dass die entsprechenden Operationen dabei den Browser blockieren. Allerdings müssen Nutzer den Zugriff der entsprechenden Webanwendung auf die Zwischenablage erlauben, damit der Einsatz der Asynchronous Clipboard API überhaupt möglich ist.
Der Zugriff auf die API erfolgt über das Objekt navigator.clipboard, das entsprechende Methoden für das Schreiben (write()) sowie das Lesen (read()) bereitstellt. Beide Methoden liefern als Rückgabewert ein Promise-Objekt, sodass sie sich bequem sowohl über die Promise API als auch über async/await verwenden lassen.
Beim Schreiben werden der Methode write() die zu kopierenden Daten in Form eines Arrays von ClipboardItem-Objekten übergeben. Jedem einzelnen Objekt übergibt man die Daten mit einem Konfigurationsobjekt als Schlüssel/Wert-Paare, wobei der Schlüssel das Format repräsentiert und der Wert die Daten als Blob enthält:
const copy = async () => {
try {
const data = [
new ClipboardItem(
{
'text/plain': new Blob(
['Dieser Text kommt asynchron in die Zwischenablage.'],
{ type: 'text/plain' }
)
}) ];
await navigator.clipboard.write(data);
} catch (error) {
console.error(error);
}
}
Der lesende Zugriff geschieht über die Methode read(), über die man an die entsprechenden Daten in Form eines Arrays von ClipboardItem-Objekte gelangt. Die Eigenschaft types jedes einzelnen ClipboardItem-Objekts enthält die verschiedenen Datenformate, die mit dem Objekt übertragen wurden:
const paste = async () => {
try {
const items = await navigator.clipboard.read();
for (const item of items) {
for (const type of item.types) {
const data = await item.getType(type);
const text = await data.text();
console.log(text);
}
}
} catch (error) {
console.error(error);
}
}
Mit write() und read() können derzeit Texte und Bilder übertragen werden. Grundsätzlich sind weitere Formate denkbar, beispielsweise solche für Audio- oder Videodaten. Diese werden momentan aber in Bezug auf die Übertragung über die Zwischenablage noch nicht von allen Browsern unterstützt.
Für die Arbeit mit Texten stehen neben write() und read() noch die beiden Convenience-Methoden writeText() und readText() zur Verfügung, über die der Code von eben etwas einfacher gestaltet werden kann, weil man sich nicht mit ClipboardItem- und Blob-Objekten herumschlagen muss:
const copyText = async () => {
try {
await navigator.clipboard.writeText(
"Dieser Text kommt asychron in die Zwischenablage."
);
} catch (error) {
console.error(error);
}
}const pasteText = async () => {
try {
const text = await navigator.clipboard.readText();
console.log(text);
} catch (error) {
console.error(error);
}
}
Mit der Asynchronous Clipboard API wird der Zugriff auf die Zwischenablage um einen asynchronen Kommunikationskanal erweitert. Alle "großen" Browser bieten Support für die Clipboard API an, sowohl für die Synchronous Clipboard API [10] als auch für die Asynchronous Clipboard API, wobei der Support für Erstere auch ältere Browserversionen umschließt. Wer auf Nummer sicher gehen möchte, dass die neuere asychrone Version im jeweiligen Browser zur Verfügung steht, kann dies über Feature Detection [11] anhand des navigator.clipboard-Objekts überprüfen. Alternativ kann man auf eine Polyfill-Bibliothek wie clipboard-polyfill [12] oder auf beliebte Alternativen wie clipboard.js [13] zurückgreifen.
URL dieses Artikels:https://www.heise.de/-5048275
Links in diesem Artikel:[1] https://github.com/zeroclipboard/zeroclipboard[2] https://w3c.github.io/editing/docs/execCommand/[3] https://developer.mozilla.org/en-US/docs/Web/API/Document/execCommand[4] https://w3c.github.io/clipboard-apis[5] https://w3c.github.io/clipboard-apis/#clipboard-event-api[6] https://w3c.github.io/clipboard-apis/#async-clipboard-api[7] https://w3c.github.io/clipboard-apis/#clipboard-event-api[8] https://html.spec.whatwg.org/multipage/dnd.html#datatransfer[9] https://w3c.github.io/clipboard-apis/#async-clipboard-api[10] https://caniuse.com/clipboard[11] https://en.wikipedia.org/wiki/Feature_detection_(web_development)[12] https://github.com/lgarron/clipboard-polyfill[13] https://github.com/zenorocha/clipboard.js
Copyright © 2021 Heise Medien
Bisher galten das Arduino-Ökosystem, die Boards mit den Espressif-Microcontrollern ESP8266 und ESP32 und die Boards von ST Microelectronics als Lösung der Wahl für Elektronikprojekte. Nun treten der Microcontroller RP2040 und das zugehörige Raspberry Pi Pico Board an, um frischen Wind in die Maker-Bewegung zu bringen.
Der Microcontroller RP2040 der Raspberry Pi Foundation adressiert im Gegensatz zu bisherigen Produkten keine Einplatinencomputer (engl. SBC = Single Board Computer), sondern schließt die Lücke zu den Microcontrollern. Zwar ließen sich mit den Raspberry Pis bereits Lösungen beispielsweise für Heimautomatisierungsaufgaben erstellen, doch waren dazu häufig Zusatzkomponenten notwendig. Zudem ist der Einsatz eines vollwertigen Einplatinencomputers für Elektronikprojekte zum einen teuer, zum anderen auch platzintensiv.
Diese Lücke soll der Raspberry Pi Pico schließen, dessen Ziel hohe Leistung und niedriger Preis waren. Mit einem empfohlenen Preis von rund 4 Euro dürfte das Board viele Maker zu einem Erwerb verführen. Und auch die Leistungsdaten des Pico können sich sehen lassen.

Die zugehörige MCU (Micro Controller Unit) trägt den Namen RP2040, hat auf einem 7-mm-x-7-mm-IC-Die Platz und ist Ergebnis eines 40-nm-Herstellungsprozesses. Wer sich über den Namen des Chips wundert, sei auf folgende Tabelle verwiesen, die den Namen dekodiert:
RP steht für Raspberry Pi
2 ist die Anzahl der Rechenkerne
0 kodiert die Art des ARM-Prozessors, im vorliegenden Fall ein Cortex-M0+-Kern.
4 gibt nach folgender Formel die Größe des verfügbaren RAMs an floor(log2(RAM / 16k))
0 bezieht sich auf die Größe des nichtflüchtigen Speichers nach der Formel floor(log2(nonvolatile / 16k))

Die beiden Cortex-32-Bit-M0+-Prozessorkerne arbeiten mit variablen Taktfrequenzen mit bis zu 133 MHz Taktfrequenz, wobei mittlerweile auch schon von erfolgreichen Übertaktungen berichtet wurde. Der Chip enthält des Weiteren 264 KB statisches RAM, das sich auf sechs Speicherbänke verteilt. Dazu kommen 2 externer MByte Flash-Speicher.
Für Ein- und Ausgabe stehen 26 Multifunktions-GPIO-Ports mit 3,3 V zur Verfügung, davon 23 digital und drei für die Analog-Digital-Wandlung. Letztere bestehen aus 4-Kanal-ADCs mit 12-Bit-Auflösung. Dazu kommen jeweils zwei UARTs, zwei I2C-Anschlüsse, zwei SPI-Anschlüsse sowie 16 PWM-Kanäle. Sechs IO-Ports sind speziell für SPI-Flash reserviert.
Der Prozessor verfügt zudem über Timer, vier Alarme, einen internen Temperatursensor und eine Echtzeituhr. Zusätzliche Hardware ist häufig benutzten Peripheriegeräten gewidmet.

Auf dem Chip befinden sich integrierte Bibliotheken zur Beschleunigung von Fließkommaberechnungen.
Um effizientes Multithreading zu ermöglichen, umfasst der Microcontroller FIFO-Speicher, die als Mailboxen zwischen den beiden Kernen fungieren. 32 hardwarebasierte Spinlocks dienen der Synchronisation zwischen Threads.
Hinsichtlich seines geplanten Einsatzzweckes ist der RP2040 also bestens bestückt.
Für viele Elektronikprojekte ist die Frage des Energieverbrauchs essenziell. Bisherige Raspberry Pi Boards besaßen dieses Problem nicht, da sie mehr als stationäre Einplatinencomputer zum Einsatz kamen. Bei Microcontroller-Lösungen hingegen stellt sich die Frage des Energieverbrauchs, speziell wenn sie für den ortsunabhängigen beziehungsweise batteriebetriebenen Einsatz konzipiert sind.
Das Pico Board verbraucht selbst bei Volllast lediglich 0,33 Watt, ganz im Gegensatz zu anderen Raspberry Pi Boards, die im Optimalfall (Raspberry Pi Zero) zwischen 1 und 2 Watt landen. Um den Energieverbrauch möglichst niedrig zu halten, implementiert der RP2040 Modi für Schlummer- und Schlafbetrieb. In diesen Modi verbraucht das Pico Board 6 Milliwatt (0,006 Watt) bei weniger als 2 mA Stromstärke (P = U * I = 3.3V * 0.002A). Mit der entsprechenden Batterie beziehungsweise Zelle ausgestattet und bei hinsichtlich Energieeffizienz optimierter Programmierung könnte ein Pico also Tage, wenn nicht sogar Wochen durchhalten, ohne eine Energieauffrischung zu benötigen. Das sind beeindruckende Werte.
Ein interessantes Merkmal des RP2040 ist die programmierbare Ein-/Ausgabe (engl. PIO = Programmable IO). Dahinter stecken zwei PIO-Blöcke mit je vier Zustandsmaschinen. Das "programmierbar" ist dabei durchaus wörtlich zu nehmen, denn Entwickler können sogenannte PIO-Programme schreiben und sie mit einem Assembler namens pioasm assemblieren. Klingt zunächst alles sehr abstrakt.
PIO dient dazu, um eigene Ein-/Ausgabeprotokolle zu integrieren und eigene Peripheriegeräte zu unterstützen, ohne den Hauptprozessor zu belasten. Häufig verwenden Entwickler für diese Aufgabe das sogenannte Bit-Banging (Emulation einer Hardwareschnittstelle mittels Software), was aber den Prozessor bisweilen in die Knie zwingt. Dieses Problem umschifft PIO. Ein einfaches Beispiel: Der RP2040 soll ein Rechteckssignal als Ausgabe erzeugen. Auf diese Weise ließe sich ein Pico als Funktionsgenerator einsetzen. Dafür schreiben Entwickler folgendes PIO-Programm:
7 .program squarewave
8 set pindirs, 1 ; Pin als Ausgabepin festlegen
9 again:
10 set pins, 1 [1] ; Pin auf 1 setzen und dann 1 Zyklus Pause
11 set pins, 0 ; Pin auf 0 setzen
12 jmp again ; Zu Label ‘again’ springen
Der Anschluss an den Host erfolgt beim Pico über einen USB-1.1-Port (Micro-USB). Dabei sind sowohl Host- als auch Gerätemodus möglich. So lässt sich Drag and Drop nutzen, um den Pico mit neuer Software zu versorgen. Drücken Entwickler die BOOTSEL-Taste auf dem Board und schließen dieses an den Host-Rechner (Windows, macOS, Linux) an, erkennt der Hostrechner den Pico als USB-Massenspeichergerät. Auf dem Host erscheint infolgedessen das Dateiverzeichnis des Pico. Sobald Entwickler eine Programmdatei auf das richtige Zielverzeichnis kopieren, erfolgt zunächst ein Reset des Pico und anschließend ein Neustart, worauf automatisch die Ausführung der Programmdatei beginnt. Die jeweilige Programmdatei muss im UF2-Format vorliegen – UF2 steht für USB Flashing Format.

Der Raspberry Pi Pico verfügt keine angelöteten Header-Pins, um ihn auch direkt auf einer Platine nutzen zu können. Zu diesem Zweck gibt es Aussparungen (Edge Castellations), die ein Anlöten auf der Platine erlauben. Zum Debuggen komplexerer Programme existiert ein 3-Pin ARM Serial Wire Debug Port.
Bei all diesen Leistungsdaten fragen sich interessierte Maker, ob das Pico-Board auch etwas nicht kann. Solche Dinge gibt es in der Tat. So stellt der Pico für die Kommunikation über WiFi oder Bluetooth keine Funktionalität zur Verfügung. Allerdings könnte sich das in Zukunft ändern, zumal auch andere Elektronikschmieden den RP2040 für eigene Boards nutzen wollen. Das in einigen Wochen verfügbare Arduino Nano RP2040 Connect Board [1] enthält ebenfalls eine RP2040-MCU, stellt darüber hinaus weitere Komponenten bereit, etwa Funktionalität für WiFi und Bluetooth.
Für die Programmierung eines Pico Board hat die Raspberry Pi Foundation ein SDK für C beziehungsweise C++ entwickelt. Auch an der Integration in Visual Studio hat man schon gearbeitet. Das "Hello World" der Maker-Elektronik in Gestalt des Blinkens einer LED gestaltet sich in C wie folgt:
#include "pico/stdlib.h"int main() {
const uint LED_PIN = 25;
gpio_init(LED_PIN);
gpio_set_dir(LED_PIN, GPIO_OUT);
while (true) {
gpio_put(LED_PIN, 1);
sleep_ms(250);
gpio_put(LED_PIN, 0);
sleep_ms(250);
}
}
Alternativ lässt sich aber auch Micropython einsetzen. Dazu müssen Entwickler eine MicroPython-UF2-Datei über USB auf das Board laden. Der Zugriff auf das REPL (Read-Eval-Print-Loop) lässt sich über USB Serial bewerkstelligen. Das oben präsentierte Blink-Programm würde in MicroPython wie folgt aussehen:
from machine import Pin, Timer
led = Pin(25, Pin.OUT)
timr = Timer()
def tick(timer):
global led
led.toggle()
timr.init(freq=2.5, mode=Timer.PERIODIC, callback=tick)
Das Arduino-Team hat angekündigt, einen sogenannten Arduino IDE Core für Pico Boards bereitzustellen. Dadurch lässt sich ein Pico in die Arduino IDE integrieren und programmatisch nutzen, als ob ein Arduino Board vorläge. Auch für die PlatformIO IDE soll in Kürze eine entsprechende Integration des Raspberry Pi Pico möglich sein.
Ebenfalls laufen nach Auskunft der Raspberry Pi Foundation die Arbeiten an einem Echtzeitbetriebssystem (RTOS). Visual Studio Code von Microsoft ist hingegen schon jetzt für die Pico-Entwicklung einsetzbar.
Eine weitere positive Nachricht: Google hat Tensorflow Lite for Microcontrollers auf den Pico portiert.
Wie bereits erwähnt, wollen auch andere Hersteller den RP2040 in ihre eigenen Boards integrieren. Die folgende Aufzählung erhebt keinen Anspruch auf Vollständigkeit:
Das neue Raspberry Pi Board und insbesondere der Microcontroller-Chip RP2040 haben das Potenzial, eine große Verbreitung zu finden. Neben einem günstigen Preis sticht das Board durch gute Leistungsdaten hervor. Noch dazu haben andere bekannte Hersteller angekündigt, den RP2040-Microcontroller auf eigenen Boards zu integrieren.
Daher dürfte der RP2040 auch in zukünftigen Artikeln meines Blogs eine wichtige Rolle spielen.
URL dieses Artikels:https://www.heise.de/-5045274
Links in diesem Artikel:[1] https://blog.arduino.cc/2021/01/20/welcome-raspberry-pi-to-the-world-of-microcontrollers/[2] https://www.sparkfun.com/news/3708[3] https://www.adafruit.com/?q=rp2040&sort=BestMatch[4] https://blog.arduino.cc/2021/01/20/welcome-raspberry-pi-to-the-world-of-microcontrollers/[5] https://projects.raspberrypi.org/en/projects/getting-started-with-the-pico[6] https://datasheets.raspberrypi.org/pico/getting-started-with-pico.pdf[7] https://datasheets.raspberrypi.org/pico/pico-datasheet.pdf[8] https://datasheets.raspberrypi.org/pico/pico-product-brief.pdf[9] https://www.raspberrypi.org/blog/new-book-get-started-with-micropython-on-raspberry-pi-pico/[10] https://www.berrybase.de/raspberry-pi-co/raspberry-pi/boards/raspberry-pi-pico[11] https://thepihut.com/products/raspberry-pi-pico[12] https://www.reichelt.de/de/de/raspberry-pi-pico-rp2040-cortex-m0-microusb-rasp-pi-pico-p295706.html?r=1[13] https://www.rasppishop.de/Raspberry-Pi-Pico-RP2040-ARM-Cortex-SBC
Copyright © 2021 Heise Medien
Eines der zentralen Themen in der Webentwicklung ist Sicherheit. Mit der Web Crypto API bieten moderne Browser mittlerweile ein Werkzeug, mit dem Entwickler auch clientseitig Informationen signieren und verschlüsseln können.
Sicherheit wird im Web großgeschrieben. Nicht umsonst gibt es beispielsweise die Secure-Contexts-Spezifikation des W3C, nach der der Browser bestimmte Features wie Service Workers oder die Payment Request API nur aktiviert, wenn die Applikation über eine sichere Verbindung ausgeliefert wird. Doch der Schutz der Anwender geht noch weiter. Ein Browser ermöglicht den Zugriff auf zahlreiche Schnittstellen des Systems, auf dem die Applikation ausgeführt wird. Typischerweise sind das Mikrofon oder Kamera, aber auch systemseitige Push-Mitteilungen fallen hierunter. Entwickler können über JavaScript auf diese Schnittstellen zugreifen, allerdings erst, nachdem die Anwender diesen Zugriff erlaubt haben. Es ist also nicht möglich, beispielsweise das Mikrofon im Hintergrund zu aktivieren und damit nahezu jedes Endgerät in ein Spionagegerät zu verwandeln.
Eine Problemstellung blieb jedoch lange Zeit unberührt: Verschlüsselung von Informationen im Browser. Selbst für einfache Standardaufgaben wie das Hashen von Informationen mussten entweder selbst Funktionen geschrieben oder auf eine externe Bibliothek zurückgegriffen werden. Das bringt nicht nur den Nachteil von zusätzlichem Quellcode in der Applikation mit sich, der zum Client zu transferieren ist, auch ist die Ausführungsgeschwindigkeit solcher Algorithmen in JavaScript nicht so performant, als wenn sie nativ im Browser implementiert wären. Dieses Problem geht die Web Crypto API an. Diese Schnittstelle bietet eine Reihe von Funktionen, mit denen sich beispielsweise Signaturen und Verschlüsselung clientseitig umsetzen lassen.
Ein Blick auf caniuse.com [1] verrät, dass sowohl Chrome als auch Firefox, Edge und Safari die Web Crypto API vollumfänglich unterstützen. Lediglich der Internet Explorer und Opera Mini machen hier noch Probleme. Wobei der Internet Explorer 11 die Web Crypto API schon unterstützt, allerdings in einer älteren Version der Spezifikation.
Nachdem die Web Crypto API fester Bestandteil des Browsers ist, können Entwickler die Funktionen der Schnittstelle direkt, also ohne Import-Statements, verwenden. Das folgende Codebeispiel zeigt, wie im Browser ein PBKDF2-Schlüssel auf Basis eines Passworts erzeugt werden kann, den die Applikation anschließend für die Generierung eines weiteren Schlüssels für die eigentliche Verschlüsselung oder Signatur nutzen kann:
(async () => {
const enc = new TextEncoder();
const pw = 'T0p5ecret!';
const key = await crypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);// ... work with the key
})();
Der Zugriff auf die Web Crypto API erfolgt über das window.crypto-Objekt (bzw. abgekürzt nur crypto). Die meisten Funktionen dieser Schnittstelle sind asynchron und arbeiten mit Promises und lassen sich wie im Beispiel mit async/await verwenden.
Neben der mittlerweile guten Browserunterstützung hat die Web Crypto API auch Einzug in Node.js gehalten. Seit Version 15 ist das aktuell noch experimentelle Modul Bestandteil des Node.js-Kerns (dieses neue Model "webcrypto" sollte allerdings nicht mit dem bereits bestehenden Modul "crypto" verwechselt werden). Im Gegensatz zum Browser müssen Entwickler hier die Funktionalität zunächst wie im folgenden Codebeispiel einbinden:
import {webcrypto} from 'crypto';const enc = new TextEncoder();
const pw = 'T0p5ecret!';
const key = await webcrypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);
console.log(key);
Ein erster Einsatzzweck für die Web Crypto API ergibt sich aus dem relativ trivialen Problem der Erzeugung von Zufallszahlen.
Der JavaScript-Standard sieht zur Erzeugung von Zufallszahlen die Methode Math.random() vor. Sie gibt eine zufällige Fließkommazahl zwischen 0 und 1 zurück, mit der in einer JavaScript-Applikation gearbeitet werden kann. Die genaue Implementierung dieser Methode überlässt der Standard den Browserherstellern, und so gibt es von Plattform zu Plattform unterschiedliche Implementierungen. Allen gemeinsam ist jedoch, dass keine kryptographisch sichere Variante dabei ist. Das bedeutet, dass Entwickler diese Methode nicht für sicherheitskritische Algorithmen nutzen sollten. Glücklicherweise sieht die Web Crypto API für diesen Zweck die getRandomValues()-Methode vor, die dieses Problem löst und sichere Zufallszahlen generiert. Wie diese Methode in der Praxis verwendet wird, zeigt der folgende Codeblock:
const randomNumbers = new Uint32Array(1);
crypto.getRandomValues(randomNumbers);
console.log(randomNumbers[0]);
Die getRandomValues()-Methode akzeptiert ein typisiertes Integer-Array, also ein Uint8Array, Uint16Array oder Uint32Array. Je nach Größe des Arrays werden unterschiedlich viele Zufallszahlen erzeugt. In unserem Beispiel wird eine 32 Bit große Zufallszahl generiert. Diese ist kryptografisch sicher und kann entsprechend auch zur Lösung sicherheitsrelevanter Probleme verwendet werden.
Die wirklich interessanten Features der Web Crypto API verbergen sich hinter dem SubtleCrypto Interface oder konkret hinter der subtle-Eigenschaft des crypto-Objekts. In den folgenden Abschnitten werfen wir mit Signatur und Verschlüsselung einen Blick auf zwei typische Einsatzgebiete für die Web Crypto API.
Bei Webapplikationen setzen die Entwickler digitale Signaturen normalerweise ein, um sicherzustellen, dass keine unberechtigten Dritten eine Information manipuliert wurde, die zwischen dem Sender und Empfänger ausgetauscht wird. Die Web Crypto API unterstützt eine Reihe von Algorithmen für das Signieren von Informationen. Beispiele hierfür sind RSA-PSS, AES-GCM oder der im folgenden Beispiel verwendete HMAC. Die Web Crypto API nutzt beim Signieren Schlüssel, die die Applikation entweder selbst generiert, oder einen importierten externen Schlüssel. Je nach Variante nutzen Entwickler hier entweder die generateKey()- oder die importKey()-Methode. Damit das folgende Beispiel problemlos ausführbar ist, erzeugt der Code den HMAC-Schlüssel selbst und nutzt ihn zum Signieren und zur anschließenden Überprüfung der Signatur:
(async () =>{
const message = (new TextEncoder()).encode('Hallo Welt');// generate the key
const key = await crypto.subtle.generateKey({
name: 'HMAC',
hash: {name: 'SHA-256'}
}, false, ['sign', 'verify']);
// sign the message
const signature = await crypto.subtle.sign(
{name: 'HMAC'},
key,
message
);
// print the signature
console.log(new Uint8Array(signature));
// verify the signature
const isValid = await crypto.subtle.verify(
{name: 'HMAC'},
key,
signature,
message
);
console.log('isValid?', isValid);
})();
Der Code zeigt zwei zentrale Merkmale der Web Crypto API sehr schön:
sign()- und verify()-Methoden ein Uint8Array-Objekt, das mithilfe des TextEncoders erzeugt wird. Die Rückgabe der sign()-Methode ist ein ArrayBuffer, der, in ein typisiertes Array umgewandelt, auf der Konsole angezeigt werden kann. Der Grund für den Einsatz dieser Datenstrukturen ist, dass sie zur Verarbeitung und zum Austausch von Informationen besser geeignet sind als beispielsweise Zeichenketten.Der Quellcode im Beispiel sorgt zunächst dafür, dass die zu verschlüsselnde Zeichenkette als Uint8Array, dem Eingabeformat für die sign()- und verify()-Methode vorliegt. Anschließend erzeugt er einen neuen Schlüssel. Die generateKey()-Methode erwartet, dass die Entwickler beim Aufruf die Einsatzzwecke des Schlüssels angeben, in diesem Fall sind dies "sign" und "verify". Nutzt eine Applikation einen Schlüssel für eine Operation, die hier nicht genannt wird, wirft die JavaScript eine DOMException, die aussagt, dass der Schlüssel für diese Art Operation nicht erlaubt ist. Mit dem Schlüssel und der codierten Zeichenkette erzeugt die sign()-Methode eine Signatur und gibt sie in Form eines ArrayBuffers zurück.
Das Gegenstück zur sign()-Methode ist die verify()-Methode. Sie akzeptiert ein Konfigurationsobjekt, das beispielsweise den Namen des verwendeten Algorithmus enthält. Außerdem müssen der Schlüssel, die Signatur und die zu überprüfende Zeichenketten übergeben werden. Das Ergebnis des sign()-Aufrufs ist ein boolscher Wert, der angibt, ob die Signatur gültig ist.
Die Signatur kann eine Applikation beispielsweise nutzen, um sensible Informationen mit einem Server auszutauschen. Beide Seiten können dann überprüfen, ob die Nachrichten auf dem Weg manipuliert wurden. Voraussetzung hierfür ist, dass beide Seiten den Schlüssel der jeweils anderen Seite kennen.
Das Verschlüsseln von Daten mithilfe der Web Crypto API funktioniert ähnlich wie das Signieren von Daten, nur dass das Ergebnis eben die verschlüsselten Informationen statt der Signatur sind. Das folgende Codebeispiel nutzt eine Kombination von Schlüsseln. Zunächst erzeugt der Quellcode einen passwortbasierten Schlüssel mit dem Verwendungszweck deriveKey, von dem anschließend ein zweiter Schlüssel abgeleitet wird. Dies bietet zum einen die Möglichkeit, für die Ver- und Entschlüsselung ein Passwort zu nutzen, und zum anderen wird die Sicherheit durch die Kombination von zwei Verschlüsselungsmechanismen zusätzlich erhöht. Die encrypt()-Methode nutzt dann den zweiten Schlüssel, um einen Text mit dem AES-GCM-Algorithmus zu verschlüsseln. Die Entschlüsselung erfolgt anschließend mit der decrypt()-Methode und ebenfalls mit dem zweiten Schlüssel.
(async () => {
const enc = new TextEncoder();
const dec = new TextDecoder();
const pw = 'T0p5ecret!';// create the first key
const key1 = await crypto.subtle.importKey(
'raw',
enc.encode(pw),
'PBKDF2',
false,
['deriveKey']
);
// create the second key
const key2 = await crypto.subtle.deriveKey(
{
name: "PBKDF2",
salt: crypto.getRandomValues(new Uint8Array(10)),
iterations: 250000,
hash: "SHA-256",
},
key1,
{ name: "AES-GCM", length: 256 },
false,
['encrypt', 'decrypt']
);
const iv = crypto.getRandomValues(new Uint8Array(10));
const encryptedMessage = await crypto.subtle.encrypt(
{
name: "AES-GCM",
iv,
},
key2,
new TextEncoder().encode('Hallo Welt')
);
console.log('encrypted data: ', new Uint8Array(encryptedMessage));
const decryptedBuffer = await window.crypto.subtle.decrypt(
{
name: "AES-GCM",
iv: iv,
},
key2,
encryptedMessage
);
const decryptedMessage = dec.decode(decryptedBuffer);
console.log('decrypted data: ', decryptedMessage);
})();
Die encrypt()- und decrypt()-Methoden arbeiten, wie schon sign() und verify(), mit typisierten Arrays und ArrayBuffer-Objekten, um mit den Schlüsseln sowie den Ergebnissen zu arbeiten.
Ein Einsatzzweck für die clientseitige Verschlüsselung ist beispielsweise die Absicherung von Informationen, die im Client gespeichert werden. Mit der zunehmenden Umsetzung offlinefähiger Applikationen steigt auch die Menge der Daten, die im Browser unter anderem in der IndexedDB gespeichert werden. Der Nachteil dieser Speichermechanismen ist, dass sie über die Entwicklerwerkzeuge des Browsers problemlos ausgelesen werden können. Verschaffen sich also unberechtigte Dritte Zugriff zum Browser, ist es ihnen möglich, die komplette Web Storage des Browsers auszulesen. Liegen die Daten dort jedoch verschlüsselt, wird es für die Angreifer zumindest etwas aufwändiger an die Informationen zu kommen. Voraussetzung dafür ist natürlich, dass der Schlüssel, der zum Entschlüsseln verwendet wird, nicht auch im Browser gespeichert wird.
Die Web Crypto API ist eine mittlerweile von allen wichtigen Browserherstellern unterstützte Low-Level-API zum Umgang mit Kryptographie in JavaScript. Die Schnittstelle ist nicht nur im Client, sondern auch serverseitig in Node.js verfügbar, sodass Quellcode und auch Bibliotheken auf beiden Seiten der Kommunikationsstrecke wiederverwendet werden können. Die Web Crypto API unterstützt verschiedene Anwendungsfälle von der Erzeugung kryptografisch sicherer Werte über Signatur bis hin zur Verschlüsselung von Informationen, die in Web-Applikationen zum Einsatz kommen. Der Vorteil dieser Schnittstelle ist, dass keine zusätzlichen Bibliotheken installiert werden müssen und, nachdem die Schnittstelle nativ vom Browser implementiert wird, sie auch noch verhältnismäßig performant ist.
Die Web Crypto API ist ein weiterer Schritt in Richtung sicherer Web-Applikationen, die die Daten ihrer Nutzer vor dem Zugriff Unberechtigter schützen.
URL dieses Artikels:https://www.heise.de/-5035591
Links in diesem Artikel:[1] https://caniuse.com
Copyright © 2021 Heise Medien
Das Entwicklerteam hinter React verfolgt einen interessanten Ansatz, der dafür sorgt, dass Single-Page-Applikationen nicht mehr reine Client-Monolithen sind. Die Idee ist Client und Server wieder näher zusammenzubringen und das Beste aus dieser Kombination herauszuholen.
Da erfindet Facebook einmal wieder das Backend neu. Die Rede ist vom neuesten Vorstoß von React: Server Components. Was sich auf den ersten Blick liest wie nur eine weitere Template Engine auf Basis von JavaScript, ist nur ein weiterer Schritt auf dem Weg, den das Entwicklerteam schon vor Jahren eingeschlagen hat, um Applikationen, die mit React erzeugt werden, noch performanter für die Benutzer zu machen.
Die Idee, die das React-Team verfolgt, ist jedoch nicht exklusiv für React, sondern findet sich in verschiedenen Varianten auch in den anderen großen JavaScript-Frameworks wieder. Doch worum geht es eigentlich? Die vergangenen Jahre waren in der Webentwicklung vor allem von Single Page-Applikationen (SPA) geprägt und damit einhergehend mit dem Siegeszug "großer" JavaScript-Frameworks und Bibliotheken wie Angular, Vue oder React. Eine solche SPA hat jedoch eine architekturelle Schwachstelle: Sie besteht, wie der Name schon andeutet, aus nur einer einzelnen HTML-Seite. Das bedeutet, dass auch alle benötigten Ressourcen in der Regel bereits zum Startzeitpunkt der Applikation geladen werden müssen.
Die Benutzer im Web warten nicht gerne. Man muss sich hier nur an die eigene Nase fassen: Ich rufe eine bestimmte Website auf oder lade eine Webapplikation. In den meisten Fällen habe ich ein konkretes Ziel. Das kann das Lesen eines Artikels, ein Einkauf oder die Erledigung einer Aufgabe im Arbeitsumfeld sein. Werde ich jedoch von einer weißen Seite oder einer sich vor mir schwerfällig aufbauenden Webpräsenz begrüßt, ist der gute erste Eindruck dahin und die Gegenseite muss mich ab diesem Zeitpunkt schon mit sehr guten Argumenten überzeugen, da ich mich ansonsten sehr schnell auf die Suche nach einer Alternative begebe. Das Motto lautet also "Load fast, stay fast". Dieser Ausdruck wird unter anderem von Google mitgeprägt. Und das aus gutem Grund: Die Ergebnisse, die eine Suchmaschine präsentiert, sollen zur Zufriedenheit der Benutzer sein und eine schnelle Auslieferung der Inhalte trägt zur Zufriedenheit bei. Das bedeutet, dass eine schnell ausgelieferte Applikation bessere Chancen auf eine gute Platzierung in der Ergebnisliste hat.
Doch zurück zu den SPAs. Es gibt zwei Metriken, die im Zusammenhang mit dem Laden einer Applikation von Bedeutung sind: Die Zeit, die es braucht, bis alle erforderlichen Ressourcen geladen sind, und die Zeit, bis die Benutzer in der Lage sind, mit der Applikation zu interagieren.
Eine der wichtigsten Maßzahlen bei der Entwicklung einer SPA ist die sogenannte Bundlesize. Diese Größenangabe bezieht sich auf den gebauten Code der Applikation, der initial ausgeliefert wird. In der Regel werden SPAs in reinem JavaScript oder TypeScript entwickelt und mit einem Bundler wie Webpack oder Rollup gebaut. Dieser Build-Prozess umfasst eine Vielzahl einzelner Schritte. Die wichtigsten sind der Transpile-Prozess, falls TypeScript zum Einsatz kommt, das Zusammenfügen des Quellcodes sowie die Optimierung. Für React gibt es mit Create React App ein Kommandozeilenwerkzeug, das diesen Build-Prozess vorbereitet und den Code für den Produktivbetrieb optimiert.
Immer mehr SPAs, auch im React-Umfeld, werden mit TypeScript umgesetzt. Die Sprache fügt allerdings nicht nur ein Typsystem in JavaScript ein, sondern ist auch in der Lage, verschiedene JavaScript-Features zu emulieren. Die Entwickler einer Applikation können über eine Konfigurationsdirektive angeben, in welcher JavaScript-Version der generierte Quellcode erzeugt werden soll. Je älter die Version, desto mehr Features von modernem JavaScript müssen emuliert werden. Das bedeutet aber auch, dass die Bundlesize negativ beeinflusst wird. Das Ziel ist also, eine möglichst neue Version zu verwenden, falls dies die Browser der Benutzer zulassen. Die TypeScript-Konfiguration gibt die Version des generierten JavaScript-Quellcodes vor.
Eine Applikation besteht aus vielen einzelnen Dateien, die sich jeweils um bestimmte Aspekte der Applikation kümmern: Komponenten, die die Struktur und das Aussehen der Applikation bestimmen, Services, die die Businesslogik der Applikation enthalten, und Hilfsklassen und -funktionen, die helfen, bestimmte Routinen auszulagern. Das JavaScript-Modulsystem verbindet die einzelnen Bestandteile der Applikation und hilft dabei, Abhängigkeiten aufzulösen. Zwar unterstützen die meisten modernen Browser das Modulsystem mittlerweile, sodass theoretisch der Quellcode auch in Einzelteilen zum Client übertragen werden kann. Dennoch ist es praktikabler, die Applikation in wenigen großen Dateien auszuliefern, da dadurch der Verbindungs-Overhead wegfällt und die verfügbaren parallelen Verbindungen des Browsers zum Server optimal ausgenutzt werden können. Der Bundler übernimmt die Aufgabe, die Dateien zusammenzuführen. Dabei löst beispielsweise Webpack nicht nur JavaScript-Abhängigkeiten auf, sondern ist auch in der Lage, andere Ressourcen wie CSS-Dateien in das Bundle zu integrieren.
Zur weiteren Optimierung des Ladeprozesses einer Applikation wird der Quellcode mithilfe eines Minifiers umgeschrieben. Dieser Prozessschritt sorgt dafür, dass Variablennamen verkürzt werden, unnötige Whitespaces entfernt und Kommentare gelöscht werden.
Eine weitere Möglichkeit der Optimierung bieten Bundler wie Webpack mit dem sogenannten Tree Shaking. Dabei wird ungenutzter Code im Projekt während des Build-Prozesses eliminiert, sodass nur der tatsächlich genutzte Code ausgeliefert wird. Tree Shaking ist vor allem beim Einsatz von Bibliotheken interessant, von denen nur ein Teil der Funktionalität wirklich benötigt wird.
Neben dem Tree Shaking gibt es auch innerhalb einer Applikation Bestandteile, die zwar nicht überflüssig sind, jedoch nicht initial angezeigt werden müssen. Um die initiale Bundlesize weiter zu reduzieren, können Teile der Applikation dynamisch nachgeladen werden. Diese Vorgehensweise, oft als Lazy Loading bezeichnet, sorgt dafür, dass sich der ausgelieferte Quellcode weiter verkleinert und die zusätzlichen Komponenten erst geladen werden, wenn die Benutzer sie anfragen.
Lazy Loading hat vor allem beim Route Based Lazy Loading, also dem dynamischen Laden von Komponenten basierend auf Pfaden innerhalb der Applikation, den Nachteil, dass die Benutzer warten müssen, bis der Ladevorgang abgeschlossen ist, bevor ihnen die neue Ansicht präsentiert wird. An dieser Stelle gibt es die Möglichkeit, die Ressourcen bereits vorzuladen, sodass beim Pfadwechsel bereits alle Ressourcen vorhanden sind und nur noch gerendert werden müssen. Diese Verbesserungen tragen dazu bei, dass die SPA schneller zu den Benutzern ausgeliefert werden kann und die Zeitspanne bis zur Anzeige der Applikation deutlich verkürzt wird.
An dieser Stelle kommt jedoch ein weiteres Problem der SPAs zum Tragen: Die Applikation wird komplett über JavaScript aufgebaut. Das bedeutet, dass der Browser zunächst ein leeres div-Element, also eine leere Seite, anzeigt und die Benutzer erst etwas von der Applikation sehen, nachdem React seine Arbeit verrichtet hat und alle Komponenten der Applikation erzeugt und in das DOM eingehängt hat. Diese Phase weist ebenfalls enormes Potenzial für Verbesserungen auf: Statt eine leere Seite auszuliefern und sie dann mittels JavaScript zu befüllen, gehen die Entwickler von SPAs einen Schritt in der Geschichte der Webentwicklung zurück und überlassen dem Webserver die Arbeit, die HTML-Struktur der Applikation vorzubereiten und bereits fertig auszuliefern. Dieser Schritt hat nur noch wenig mit den traditionellen Template-Engines zu tun.
Stattdessen bietet beispielsweise React mit dem ReactDOMServer ein Objekt, das verschiedene Methoden zur Erzeugung von HTML-Strukturen auf Serverseite enthält. Diese werden dann wie traditionelle HTML-Seiten zum Browser der Benutzer gesendet. Dort übernimmt dann das Framework die Kontrolle über die HTML-Struktur. Dieser Prozess wird in React Hydration genannt. Erst wenn dieser Prozess abgeschlossen ist, können die Benutzer vollständig mit der Applikation interagieren. Der Vorteil von diesem Server-Side Rendering genannten Prozess ist, dass den Benutzern die Informationen bereits sehr früh zur Verfügung stehen und der Hydration-Prozess vergleichsweise schnell abläuft.
Die Idee, eine Applikation komplett im Client umzusetzen, hat sich also als nicht optimal herausgestellt, und so schlagen die Entwickler von React gerade einen sehr interessanten Weg ein, indem sie versuchen, Client und Server noch enger miteinander zu verknüpfen, als es bislang schon mit Server-Side Rendering der Fall ist.
Das Ergebnis sind die Server Components. Dabei handelt es sich um reguläre React-Komponenten, die allerdings nicht zum Client gesendet werden, sondern direkt auf dem Server ausgeführt werden. Sie können auf die Ressourcen des Servers zugreifen und sich so selbst mit Daten versorgen. Außerdem können sie bestimmen, welche Komponenten für die clientseitige Darstellung gerendert werden. Durch Server Components können Entwickler schon serverseitig viel tiefer in den Aufbau einer Applikation eingreifen, sodass wirklich nur noch die Strukturen zum Client gesendet werden, die dort benötigt werden. Außerdem können hier serverseitige Caching-Mechanismen eingesetzt werden, um die Auslieferung der Applikationen noch weiter zu beschleunigen.
Noch befindet sich dieses Feature in einem sehr frühen Stadium, jedoch zeigen dieses und ähnliche Features, wo die Reise für Frontend-Entwickler hingehen könnte.
URL dieses Artikels:https://www.heise.de/-5026838
Copyright © 2021 Heise Medien
Gemeinsam macht das Bloggen noch mehr Spaß! Ab sofort gibt es wieder neue Tales from the Web side – mit Verstärkung.
Liebe Leserinnen, liebe Leser,
in letzter Zeit war es hier auf diesem Blog merklich ruhig. Was mich hauptsächlich in der Zeit, die ich normalerweise für die Arbeit am Blog einplane, beschäftigt hat, war die Arbeit an meinem neuen Buch: "Webentwicklung – Das Handbuch für Fullstack-Entwickler" [1] steht kurz vor der Fertigstellung und erscheint Ende März nächsten Jahres beim Rheinwerk Verlag. Auf rund 650 Seiten geht es hier um alle wichtigen Themen der Webentwicklung, von den drei wichtigsten Sprachen des Web – HTML, CSS und JavaScript – über Web APIs, Web Services, Datenbanken bis hin zur Versionsverwaltung mit Git und Deployment mit Docker.
Als guten Vorsatz für das nächste Jahr soll es hier auf diesem Blog aber wieder etwas regelmäßiger Beiträge geben. Und da die Arbeit an einem Blog gemeinsam noch mehr Spaß macht, freue ich mich sehr, dass mir ab sofort Sebastian Springer [2] als Verstärkung zur Seite steht. Oder anders gesagt: ab sofort werden Sebastian und ich gemeinsam diesen Blog mit Inhalt füllen.
Sebastian dürfte den meisten ohnehin schon bekannt sein. Er ist Fachbuchautor verschiedener Bücher über Node.js und React, Speaker auf Konferenzen wie der von heise Developer organisierten enterJS [3] und schreibt darüber hinaus regelmäßig Artikel für Fachmagazine wie die iX. Sebastian und ich kennen uns bereits einige Jahre (er war unter anderem Fachgutachter meines JavaScript-Profibuches [4] und meines Node.js-Kochbuchs [5], ich umgekehrt Fachgutachter seines Node.js-Handbuchs [6] und seines React-Handbuchs [7]). Darüber hinaus schreibt Sebastian gerade ein Gastkapitel für mein weiter oben genanntes Handbuch zur Webentwicklung. Insofern sind wir was die Zusammenarbeit beim Schreiben angeht, bereits seit Jahren ein eingespieltes Team.
Thematisch werden wir der Ausrichtung des Blogs treu bleiben, das heißt in erster Linie wird es auch weiterhin um alle interessanten Themen rund um die Webentwicklung gehen – einen Blick über den Tellerrand wollen wir uns natürlich hin und wieder dennoch gestatten.
Wir freuen uns auf die Zusammenarbeit und wünschen Ihnen, liebe Leserinnen und Leser, einen guten Start ins neue Jahr. Bleiben Sie gesund!
Beste Grüße,
Philip Ackermann [8] & Sebastian Springer [9]
URL dieses Artikels:https://www.heise.de/-5000657
Links in diesem Artikel:[1] https://www.rheinwerk-verlag.de/webentwicklung-das-Handbuch-fuer-fullstack-entwickler/[2] https://twitter.com/basti_springer[3] https://enterjs.de/[4] https://www.rheinwerk-verlag.de/professionell-entwickeln-mit-javascript-design-patterns-praxistipps/[5] https://www.rheinwerk-verlag.de/nodejs-rezepte-und-loesungen/[6] https://www.rheinwerk-verlag.de/nodejs-das-umfassende-handbuch/[7] https://www.rheinwerk-verlag.de/react-das-umfassende-handbuch/[8] https://twitter.com/cleancoderocker[9] https://twitter.com/basti_springer
Copyright © 2021 Heise Medien
In einer modernen Welt ist es wichtig, Kinder an Robotik und Embedded Systems heranzuführen. Was aber tun, ohne die Kleinen zu überfordern? mTiny von makeblock liefert einen möglichen Ansatz.
Nach langer gesundheitlich und beruflich bedingter Abstinenz möchte ich meinen Blog wieder regelmäßig fortsetzen. Dabei fange ich mit leichter Kost an. In diesem Special geht es um mTiny [1] vom chinesischen Unternehmen makeblock [2], das sich auf Baukästen spezialisiert hat. Im Gegensatz zu den anderen Produkten des Unternehmens wendet sich mTiny an Kinder ab vier Jahren. Es besteht aus einem kleinen Robotervehikel, einem Controller, verschiedenen Programmierkärtchen sowie Spielfeldern, auf denen Kinder ab vier Jahren verschiedene Aufgaben lösen können.

Die Eingabe der Programme besteht darin, verschiedene Programmierkärtchen inklusive je einer für Anfangs- und Endzustand hintereinander zu legen. Anschließend fährt die Junior-Programmiererin mit dem Controller über die Kärtchen des Programms. Sie beginnt immer mit dem Kärtchen für den Programmanfang. Mit einem Vibrieren erfährt die angehende Entwickler:in, dass der Controller das jeweilige Kärtchen erfolgreich eingelesen hat. Ganz am Schluss liest sie noch das Kärtchen für den Endzustand ein, worauf mTiny unmittelbar mit der Programmausführung startet.

Neben der Karte für den Beginn der Programmierung (Input card) und der Karte für den Start der Ausführung (GO! Card) bietet das Paket folgende Kategorien von Anweisungen:
Mit der Starttaste des Controllers lässt sich ein Programm erneut starten, mit dessen Stop-Taste die Programmausführung anhalten.
In einem kleinen Handbuch beschreibt der Hersteller verschiedene Aufgaben mit wachsender Schwierigkeitsstufe, die Kinder lösen sollen. Basis sind dafür mit großen Karten gelegte Spielwelten.

Leider ist gerade dieses Manual in Englisch gehalten, erfordert also das Beisein eines Erwachsenen, was aber ohnehin zumindest anfangs geboten ist, um Kindern hilfreich zur Seite zu stehen.
Übrigens lässt sich mTiny auch über die Joystick-Taste des Controllers fernsteuern. Die Verbindung funktioniert laut Hersteller mit einer Reichweite von bis zu zehn Metern ohne dazwischenliegende Hindernisse. Insofern lässt sich mTiny also auch als normales Spielzeug ohne Programmierung einsetzen.
Um mTiny und den Controller in Betrieb zu nehmen, müssen beide zunächst über Bluetooth gekoppelt werden. Anschließend sollte der Benutzer die Joystick-Taste des Controllers mit mTiny kalibrieren. Um diese Initialisierung durchzuführen, empfiehlt sich für beide Geräte ein Ladezustand von mindestens 50 Prozent.
Wichtige Empfehlung: Im Test hat die Kopplung erst dann funktioniert, als beide Geräte außerhalb des heimischen 2,4-GHz-WLANs positioniert waren. Nachdem die Kopplung einmalig erfolgreich zustande kam, traten indes keine Verbindungsprobleme mehr auf.

Das Aufladen sowohl von mTiny als auch seines Controllers erfolgt gleichzeitig über ein Micro-USB-Y-Kabel. Beim Anschluss an einen PC über USB erkennt der Computer mTiny als USB-Laufwerk. Das Bereitstellen neuer Firmware geschieht über die mTiny-Service-Seite [3]. Zum Update kopieren Anwender die extrahierte Zip-Datei auf das Hauptverzeichnis von mTiny. Nach Aus- und Wiedereinschalten erfolgt der Update von mTiny und Controller in wenigen Minuten automatisch.
Der offizielle Listenpreis von mTiny beträgt 159 Euro, wobei der Straßenpreis durchaus bei lediglich 98,80 Euro liegen kann – zumindest bot reichelt.de während des Zeitraums der Artikelerstellung mTiny zu diesem Preis an. Ein Preisvergleich lohnt sich also.
mTiny eignet sich gut dafür, um Kinder ab vier Jahren spielerisch an Robotik und Programmierung heranzuführen. Das Konzept wirkt durchdacht und ausbaufähig. Insgesamt ist das Produkt also empfehlenswert.
Es gibt kleinere Schönheitsfehler:
Für einen Straßenpreis um die 100 bis 130 Euro ergibt sich insgesamt ein gutes Preis-Leistungs-Verhältnis.
Mein Dank geht an die Firma solectric [4], die mir mTiny für diesen Artikel leihweise zur Verfügung gestellt hat.
URL dieses Artikels:https://www.heise.de/-5000961
Links in diesem Artikel:[1] https://www.makeblock.com/mtiny[2] https://www.makeblock.com[3] https://www.makeblock.com/support/ps-mtiny[4] https://shop.solectric.de/
Copyright © 2021 Heise Medien
In diesem Jahr ist aufgrund der Corona-Pandemie wohl vieles anders gelaufen als geplant. Ein Rückblick auf das vergangene Jahr lohnt sich dennoch: Das HTTP Archive veröffentlicht zum Jahresende die zweite Ausgabe seines HTTP-Jahrbuchs. Im Mittelpunkt steht die Frage: Wie steht das Web im Jahr 2020 da?
Das HTTP Archive [1] wurde 2010 ins Leben gerufen. Es ist eine Unterorganisation des bekannten Internet Archive, das Snapshots von Websites für die Nachwelt erhalten will. Nach dessen Vorbild crawlt das HTTP Archive monatlich rund 7,5 Millionen Websites und sammelt diverse Metadaten wie Dokumentengröße oder eingesetzte Technologien sowie Performancemetriken.

Seit 2019 gibt das HTTP Archive den Web Almanac heraus. Dieses kostenfreie Jahrbuch befasst sich mit der Frage, in welchem Zustand sich das Web im jeweiligen Jahr befindet – basierend auf den gesammelten Daten. Für die diesjährige Ausgabe des Web Almanac [2] wurden 31,3 Terabyte an Daten verarbeitet. In insgesamt 22 Kapiteln widmen sich die Autoren unterschiedlichsten Aspekten der Webentwicklung, angefangen beim Aufbau von Websites (z. B. Verwendung von CSS, Schriftarten) über Fragen der User Experience (z. B. SEO, Performance) bis hin zu Transportthemen (z. B. Kompression, HTTP/2). Auch der Autor dieses Blogs ist mit einem Kapitel zu brandneuen Web-Capabilities [3] vertreten. Insgesamt waren 116 Personen aus der Community an der Entstehung des 2020 Web Almanac beteiligt, der sich auch zum Offline-Lesen als PDF-E-Book herunterladen lässt.
Neben vielen interessanten Erkenntnissen fördert das Jahrbuch fördert auch Kurioses zu Tage: Das Markup-Kapitel [4] zeigt, dass die im HTML-Sprachstandard gar nicht enthaltene h7-Überschrift 30.073 Mal verwendet wird. Die Mitwirkenden des Accessibility-Kapitels [5] untersuchten die Alt-Texte von Bildern. Der Median-Text ist 18 Zeichen lang, der längste bekannte Alt-Text ganze 15.357.625 Zeichen. Dies und vieles weitere mehr zeigt der 2020 Web Almanac auf. Viel Spaß beim Lesen!
URL dieses Artikels:https://www.heise.de/-4985201
Links in diesem Artikel:[1] https://httparchive.org/[2] https://almanac.httparchive.org/en/2020/[3] https://almanac.httparchive.org/en/2020/capabilities[4] https://almanac.httparchive.org/en/2020/markup#headings[5] https://almanac.httparchive.org/en/2020/accessibility#other-facts-about-alt-text
Copyright © 2020 Heise Medien
Vom 1. bis 24. Dezember 2020 können Webentwickler beim PWA-Adventskalender unter pwadvent.dev [1] täglich ein neues Türchen mit je einem Feature aus dem Bereich der Progressive Web Apps (PWA) öffnen.
PWAdvent ist eine Initiative des Schweizer Softwareentwicklers Nico Martin, unterstützt von zahlreichen Mitgliedern der PWA-Community, die jeweils einen kurzen Artikel zu einem mehr oder minder bekannten PWA-Feature geschrieben haben. Zu den Themen gehören die technischen Grundlagen der PWA-Entwicklung [2], aber auch einige Features, die weniger bekannt sind und man dem Web vielleicht gar nicht zugetraut hätte. So finden sich auch einige Fugu-Features [3] darunter.

PWAdvent ist selbst natürlich auch eine Progressive Web App, lässt sich also auf den gängigen Betriebssystemen auf Mobil- und Desktop-Geräten installieren. Über die Push API wird zudem eine Erinnerungsfunktion angeboten, sodass kein Türchen vergessen wird. Auch die technische Basis von PWAdvent ist interessant: Im Backend kommt ein Headless WordPress als CMS zum Einsatz, im Frontend Preact. Der Adventskalender wird per CSS Grid gezeichnet. Der Quelltext der Anwendung ist auf GitHub [4] abrufbar.
URL dieses Artikels:https://www.heise.de/-4973877
Links in diesem Artikel:[1] https://pwadvent.dev[2] https://www.heise.de/developer/artikel/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html[3] https://www.heise.de/developer/artikel/Google-Projekt-Fugu-Die-Macht-des-Kugelfisches-4255636.html[4] https://github.com/nico-martin/PWAdvent/
Copyright © 2020 Heise Medien
Eine Datei doppelt anklicken, bearbeiten und wieder abspeichern: Auf genau diese Art funktionieren praktisch alle bekannten Produktivitätsanwendungen wie Bild- und Texteditoren, Office-Programme oder IDEs auf dem Desktop. Webanwendungen war dieser Workflow bislang vorenthalten, Entwickler mussten auf alternative Ansätze ausweichen. Mithilfe der File System Access und File Handling API kommen Progressive Web Apps in Chromium-basierten Browsern auf dasselbe Level.
Progressive Web Apps (PWA) sind seit über zwei Jahren auf allen relevanten Plattformen verfügbar, unterstützt werden insbesondere die Installation und Offline-Verfügbarkeit von Webanwendungen. Für Anwendungen, die nicht mit Dateien arbeiten, oder SaaS-Angeboten, die Dateien nicht auf dem Zielsystem ablegen (etwa Google Docs) genügt der PWA-Funktionsumfang bereits.
Mit dem Fugu [1] wollen die Beitragenden des Chromium-Projekts den nächsten Schritt gehen und weitere Schnittstellen mit nativer Power ins Web bringen – unter Beachtung von Sicherheit und Privatsphäre. Fugu-APIs werden alle in den passenden Standardisierungsgremien diskutiert, starten parallel jedoch schon in Chromium sowie allen darauf aufbauenden Browsern (zum Beispiel Microsoft Edge, Brave, Opera) und sind dort zunächst einmal proprietär. Dieses Vorgehen ist im Web allerdings nicht unüblich; die Web Share API oder die Async Clipboard API haben auf diesem Weg bereits Einzug in die anderen Browser erhalten.

Mit der aktuellen Version 86 von Google Chrome und anderen auf Chromium basierenden Browsern wurde die File System Access API [2] standardmäßig verfügbar gemacht. Über diese Schnittstelle können Entwickler über die von nativen Plattformen bekannten Open- und Save-Dialoge Zugriff auf eine Datei oder ein Verzeichnis anfordern, die Dateien manipulieren und anschließend überschreiben oder an anderer Stelle abspeichern. Das Öffnen von Dateien – teilweise auch Ordnern – aus dem lokalen Dateisystem war im Web per <input type="file"> [3] auch bisher schon möglich, per <a download> [4] auch das Speichern von Dateien in das Download-Verzeichnis. Weiterhin erlaubt die Schnittstelle auch das Öffnen von Dateien und Verzeichnissen per Drag and Drop. Da Anwender auf Mobilgeräten typischerweise nicht direkt mit dem Dateisystem agieren, wird die Schnittstelle nur auf dem Desktop unterstützt.

Während die File System Access API in Chromium-basierten Browsern schon gestartet ist, ist die File Handling API [5] noch nicht ganz so weit. Sie befindet sich derzeit noch hinter dem Flag #file-handling-api und muss über die Flags-Seite des jeweiligen Browsers (in Chrome chrome://flags) manuell aktiviert werden. Aufgrund eines Bugs in früheren Versionen ist das nur ab der aktuellen Beta-Version 87 sinnvoll. Anschließend können sich Entwickler für bestimmte MIME-Typen beziehungsweise Dateierweiterungen registrieren. Damit wird die PWA nach Installation im Betriebssystem als Handler für die jeweiligen Dateierweiterungen hinterlegt. Fortan können Anwender per Doppelklick auf eine passende Datei direkt die PWA starten oder die PWA aus der Liste der kompatiblen Programme auswählen.
Die Anwendung Excalidraw [6] (Quellcode auf GitHub [7]) ist ein schönes Beispiel für eine Produktivitätsanwendung, die diese Schnittstellen einsetzt. Sie erstellt Skizzen, die wie von Hand gezeichnet aussehen. Diese können über die File System Access API anschließend mit der Dateiendung ".excalidraw" abgespeichert werden. Ebenso erlaubt die Anwendung das Öffnen von Dateien via File-Open-Dialog sowie per Drag and Drop. Wird die Anwendung auf dem Gerät installiert, hinterlegt sich Excalidraw zudem als Handler für Dateien mit ".excalidraw"-Dateiendung. Auf Browsern ohne Unterstützung für die File System Access API werden die oben genannten Fallback-Ansätze per input- und a-Element gewählt, sodass sich die Anwendung auch in anderen Browsern ohne Unterstützung für diese Schnittstelle sinnvoll bedienen lässt. Dieses Verhalten bezeichnet man auch als Progressive Enhancement [8].
Mithilfe der beiden Fugu-Schnittstellen schließt sich nun der Kreis für webbasierte Produktivitätsanwendungen auf Desktop-Niveau. Aktuell sind die Schnittstellen lediglich in Chromium-basierten Browsern verfügbar. Mozilla möchte sich derzeit noch nicht auf eine offizielle Position zu beiden APIs festlegen [9]. Apple äußert sich grundsätzlich nicht zu Produktplänen, hat die beiden Schnittstellen jedoch nicht auf seiner Liste blockierter APIs [10] stehen. Insofern wird die Zeit zeigen, ob die Schnittstellen auch Einzug in die anderen Browser erhalten. Webentwickler können dabei unterstützen, indem Sie die Schnittstellen über die oben genannten Fallbacks abwärtskompatibel implementieren und den übrigen Browserherstellern von ihren Use Cases über die jeweiligen Bugtracker erzählen.
URL dieses Artikels:https://www.heise.de/-4963752
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/Google-Projekt-Fugu-Die-Macht-des-Kugelfisches-4255636.html[2] https://web.dev/file-system-access/[3] https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input/file[4] https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a#download[5] https://web.dev/file-handling/[6] https://excalidraw.com/[7] https://github.com/excalidraw/excalidraw[8] https://www.heise.de/developer/artikel/Faktencheck-zu-Progressive-Web-Apps-Teil-1-Plattformen-Plug-ins-4259135.html[9] https://mozilla.github.io/standards-positions/[10] https://webkit.org/tracking-prevention/#anti-fingerprinting
Copyright © 2020 Heise Medien
<time datetime=""> for entry dates #3106quickadd #3051Das Wasserfall-Modell ist recht alt, aber taucht dennoch bei der Diskussion über Softwareentwicklungsprozesse immer noch sehr häufig auf. Die Geschichte dieses Modells ist weitgehend unbekannt – dabei zeigt sie die Herausforderungen des Modells und warum man es nicht nutzen sollte.
Das einfache Wasserfall-Modell beschreibt ein Prozessmodell für die Softwareentwicklung. Es hat folgende Eigenschaften:
Die Visualisierung ist dementsprechend ein Wasserfall, bei dem die Phasen von oben links nach unten rechts angeordnet sind. Das "Wasser" entspricht jeweils den Ergebnisdokumenten, die dann in die Folgephase einfließen. Die einzelnen Phasen können sich dabei in jedem Projekt unterscheiden.

Vorbedingung für dieses Modell ist, dass die Anforderungen sich nicht wesentlich ändern. Sonst geht schon das Ergebnis der ersten Phase von falschen Voraussetzungen aus und damit auch alle weiteren Phasen und deren Ergebnisse. Anforderungen sind in der Praxis oft nicht fest oder vollständig bekannt. Dann sind agile Methoden, die auf diesen Umstand Rücksicht nehmen, die bessere Wahl. Aber nehmen wir für den Rest des Texts an, dass dieser Umstand alleine das Wasserfall-Modell noch nicht ausschließt.
Ansätze für Softwareentwicklung können sich nur an dem Erfolg in der Praxis messen lassen. Die Frage ist nun, welche Erfahrungen es zum Wasserfall-Modell gibt.
Das Wasserfall-Modell für die Softwareentwicklung hat den Ursprung in den Fünfzigerjahren. Damals haben die USA das SAGE-System [1] entworfen (Semi-Automatic Ground Environment). Es diente zur Koordination der Luftverteidigung insbesondere gegen einen möglichen Angriff der UdSSR. Im Wesentlichen sollte es ein umfassendes, konsolidiertes Bild aus den verschiedenen Radarstationen erzeugen und dann das Bekämpfen der Ziele koordinieren. Das ist ein Bereich, in dem die Anforderungen relativ klar und unveränderlich sein sollten.
Zu diesem Zeitpunkt gab es keine höheren Programmiersprachen, keine Terminals und kein Time Sharing. Es gab nur Lochkarten und Röhrenrechner. Jedes SAGE Direction Center bekam einen AN/FSQ-7 Computer [2]. Das waren damals die leistungsfähigsten Computer mit einer Fläche von 2.000 m2, 49.000 Röhren, 75.000 Instruktionen pro Sekunde und einem Magnetkernspeicher von 65.536 32-Bit-Wörtern.
Weil Hardware damals um viele Größenordnungen teurer und weniger leistungsfähig war als heute, mussten Projekte bei der Unterstützung der Entwicklung viel sparsamer mit Rechenzeit umgehen. Daher können moderne Softwareentwicklungsprozesse viel mehr Rechenzeit für die Unterstützung von Entwickler:innen aufwenden.
Das SAGE-Projekt war kostspieliger als das Manhattan-Projekt zum Bau der Atombombe, gegen dessen Resultat es ja schützen sollte. Wesentliches Ergebnis war die Software mit insgesamt 0,5 Millionen Instruktionen. Ein Viertel des Codes ist das eigentliche System, der Rest diente zur Unterstützung der Entwicklung.
1956 beschrieb Herbert Benington die grundlegenden Ideen zur Implementierung dieses Systems. Das Paper beschreibt, in welchen Phasen die Implementierung stattfinden soll, und einen linearen Ablauf durch diese Phasen wie in einem Wasserfall-Modell. Diese Beschreibung nimmt jedoch nur circa zwei Seiten ein und stellt lediglich einen Teil der vorgestellten Arbeitsweisen dar. Darüber hinaus diskutiert es unter anderem eine Art Architektur und verschiedene Werkzeuge zur Entwicklung von Systemen.
Prinzipiell sind die Anforderungen für die SAGE-Software wahrscheinlich im Wesentlichen fest, sodass ein solches Modell nicht unsinnig erscheint. Auch wenn der Prozess in dem Paper nicht "Wasserfall-Modell" genannt wird, zeigt sich scheinbar ein relativer Erfolg des Wasserfall-Modells. Schließlich hat das Projekt Software geliefert, die auch genutzt wird, auch wenn das Projekt die ursprüngliche Deadline um ein Jahr gerissen hat.
1983 wurde das Paper erneut in den "IEEE Annals of the History of Computing [3]" veröffentlicht. Der Herausgeber macht dabei eine wichtige Bemerkung: SAGE war eines der ersten Systeme, das so groß war, dass es eine Person alleine nicht mehr entwickeln und verstehen konnte, während vorher einzelne Personen Programme sehr erfolgreich entworfen und geschrieben haben. Es war also der Beginn der Herausforderung, welche heute die Softwareentwicklung dominiert: ein komplexes Softwaresystem mit einem Team koordiniert umzusetzen.
Noch interessanter als diese Ausführung des Herausgebers ist das Vorwort des Autors zur Wiederveröffentlichung. Das SAGE-Projekt hat zunächst einen Prototypen mit 35.000 Instruktionen geschrieben. Das alleine ist schon eine wesentliche Abwandlung des einfachen Wasserfall-Modells, da für diesen Prototypen alle Phasen einmal durchlaufen werden müssen, während der einfache Wasserfall nur einen einmaligen Durchlauf vorsieht. Zwanzig Personen haben dieses Prototypen entwickelt, durch den alle Module, Schnittstellen und Performance-Anforderungen klar waren. Diese Personen haben die Implementierung des eigentlichen Systems wesentlich beeinflusst.
Außerdem steht im Vorwort weiter, dass der größte Fehler des Projekts der Sprung von 35.000 Instruktionen im Prototypen zu mehr als 100.000 Instruktionen im realen System war. Im Nachhinein wäre es sinnvoller gewesen, ein "Framework" für 250.000 Instruktionen zu schaffen, als den 35.000-Instruktionen-Prototypen in dieses "Framework" einzugliedern und weiterzuentwickeln. So hätten schätzungsweise 50 Prozent der Kosten eingespart werden können. Das ist dann aber kein einfacher Wasserfall mehr, weil Code für neue Funktionalitäten ergänzt wird, sodass mindestens Phasen wie Design, Implementierung und Verifikation mehrmals durchlaufen werden.
Die Erfahrungen mit einem der ersten komplexen Softwareentwicklungsprojekte legt also schon nahe, dass ein einfacher Wasserfall keine Lösung für Softwareentwicklung ist – und das trotz relativ klarer Anforderungen.
Abgesehen davon war das SAGE-System einschließlich der Röhrenrechner bis in die Achtzigerjahre in Gebrauch. Aufgrund des technologischen und sonstigen Wandels über die Jahrzehnte scheint die Bezeichnung "Wartung" für diese Phase unzureichend. In dieser Zeit sind sicherlich auch neue, wesentliche Features entstanden. Dazu müssen die Phasen aus dem einfachen Wasserfall wie Anforderung, Design und Implementierung erneut durchlaufen werden.
Manchmal wird die Erfindung des Wasserfalls auch Winston Royce zugeschrieben, der 1970 ein Paper zu seinen Erfahrungen mit Softwareentwicklung großer Systeme [4]verfasst hatte. Royce arbeitete im Bereich Luft- und Raumfahrt, in welchem Anforderungen eher stabil sind und eine weitestgehende Fehlerfreiheit von Anfang an wünschenswert erscheint. Also ein Bereich, für den das einfache Wasserfall-Modell sinnvoll sein könnte. Und tatsächlich findet sich eine Abbildung in dem Paper, die dem einfachen Wasserfall gleicht – der Name "Wasserfall-Modell" taucht allerdings nicht auf.
Aber auch hier zeigt der Rest des Papers mehrere wesentliche Abwandlungen vom reinen Wasserfall, zum Beispiel:
Dementsprechend finden sich in dem Paper weitere Abbildungen, die andere, wesentlich vom einfachen Wasserfall abweichende Prozesse beschreiben.
In seinem Buch "The Leprechauns of Software Engineering [5]" setzt sich Laurent Bossavit mit verschiedenen Mythen im Bereich der Softwareentwicklung auseinander. Das Buch ist ein Plädoyer dafür, fundamentale Grundlagen der Softwareentwicklung kritisch zu hinterfragen.
Ein Kapitel beschäftigt sich mit dem Wasserfall-Modell. Dabei setzt sich Bossavit vor allem mit der Interpretation des Royce-Papers auseinander. Seiner Meinung nach sehen Verfechter der agilen Bewegung das Wasserfall-Modell als eine Fehlinterpretation des Royce-Papers. Der Sichtweise der Agilisten nach hat das Paper eigentlich einen agil-iterativen Ansatz proklamiert. Dabei fehlt dem Royce-Prozess aber in Wirklichkeit ein erneuter Durchlauf der Anforderungsphase.
Kritiker der agilen Bewegung sehen den einfachen Wasserfall als ein Modell, das niemand proklamiert, sondern welches nur zum Diskreditieren formaler Prozesse dient. Royces Modell ist schließlich nicht so unflexibel und empfiehlt auch keinen einmaligen, sequenziellen Durchlauf durch die Phasen. Tatsächlich sind laut Bossavit aber beide Interpretationen ungenügend.
Bossavit zeigt weiter, dass Royces Paper zumindest eine Quelle der bekannten grafischen Darstellung des Wasserfalls ist. Es wurde populär, weil Barry Boehm und seine Firma TRW in den Achtzigern dieses Paper als Rechtfertigung für existierende Top-down-Ansätze begriffen und entsprechend zitierten. Sie publizierten das Royce- und das SAGE-Paper erneut. Wenig später führte Boehm das iterativ-inkrementelle Spiral-Modell ein und interpretierte das Royce-Paper als dessen Vorläufer, da es ja schon eine Prototypphase etabliert hatte. So weist Bossavit darauf hin, dass Boehm auch eine wichtige Rolle in der Geschichte des Wasserfall-Projekts spielt. Wie Benington und Royce zuvor empfiehlt auch Boehme den einfachen Wasserfall nicht, sondern entwickelt ihn weiter.
Teilweise werden US-Militärstandards als weitere Quellen für Wasserfall-Vorgehen zitiert. Genau genommen diskutiert MIL-STD-490a von 1985 jedoch Spezifikationen und MIL-STD-483a von 1985 Konfigurationsmanagement. MIL-STD-2167 (1985) definiert Softwareentwicklungsstandards. Dort ist tatsächlich von einem Softwareentwicklungszyklus mit verschiedenen Phasen die Rede. Dieser Zyklus kann jedoch laut Abschnitt 4.1.1 in mehreren Iterationen durchgeführt werden und die Phasen sollen sich typischerweise überlappen. Auch das ist nicht unbedingt ein einfacher, sequenzieller Durchlauf, wie ihn der einfache Wasserfall vorsieht. Es ist natürlich vorstellbar, dass ältere Revisionen der Standards oder ältere Standards sich unterscheiden, aber über 35 Jahre alte Empfehlungen im Bereich Softwareentwicklung sind vermutlich nicht mehr der Stand der Technik.
Wenn man Wikipedia [6] trauen kann, ist es auch beim deutschen V-Modell-Entwicklungsstandard der öffentlichen Hand möglich, “die Aktivitäten des V-Modells zum Beispiel auf ein Wasserfallmodell oder ein Spiralmodell abzubilden”. Das V-Modell XT von 2005 orientiert sich sogar an agilen und inkrementellen Ansätzen. Auch mit diesen Modell ist ein ein einfacher Wasserfall also nicht zwingend.
Die Personen, denen das einfache Wasserfall-Modell zugeschrieben wird, haben es weder erfunden noch proklamierten sie es. Und das trotz Umgebungen, in denen Anforderungen vermutlich relativ fest sind und ein rigider Prozess noch sinnvoll war, um die bestehenden Limitationen beispielsweise bei der für die Entwickler:innen bei der Entwicklung nutzbaren Hardware einzuhalten.
Natürlich ist es denkbar, auch mit einem einfachen Wasserfall-Prozess erfolgreich zu sein – aber spätestens seit Royce und damit seit 50 Jahren sind andere Vorgehensmodelle zu empfehlen. Eigentlich sind diese Probleme aber schon seit dem SAGE-Projekt und damit seit Anbeginn der Softwareentwicklung im Team klar.
Wenn Anforderungen sich ändern, hat dieser Prozesse weitere offensichtliche und erhebliche Schwächen, da man dann bei einer wesentlichen Änderung im Prinzip von vorne anfangen müsste. Wer also einen einfachen Wasserfall empfiehlt, versteht den Stand der Technik vor 50 beziehungsweise 65 Jahren nicht. Und in diesen Jahrzehnten hat sich die Technologie weiterentwickelt, was viele Dinge wesentlich vereinfacht und es erlaubt, den Entwicklungsprozess selbst besser mit Software zu unterstützen. Das benachteiligt Wasserfall-artige Prozesse weiter.
Der einfache Wasserfall dient vermutlich in erster Linie als Gegenmodell zu Agilität und damit als ein Beispiel, wie man es nicht machen sollte. Das ignoriert aber die Abwandlungen, die von Anfang an genutzt wurden.
Vielleicht ist es auch verführerisch, endlich einen "sauberen" Prozess durchzuführen. Es mag intuitiv sinnvoll erscheinen, Dinge zu Ende zu führen, zu konsolidieren und dann darauf aufzubauen. Auch ich habe mich schon dabei ertappt, ein solches Vorgehen nach Phasen als "eigentlich richtigen" und "sauberen" Weg zu bewerten. Auch kann ein einfacher Wasserfall eine Illusion von Kontrolle geben: Es gibt eine klare Aufteilung in Phasen mit klaren Ergebnissen. Aber Probleme werden oft erst offensichtlich, wenn Software ausgeliefert wird und Benutzer die Software tatsächlich verwenden. Dieses Feedback verzögert der einfache Wasserfall, weil erst alle Phasen vollständig abgeschlossen sein müssen, statt möglichst schnell eine teilweise Lösung auszuliefern und Feedback dazu einzusammeln.
Zum Abschluss ein Vorschlag für ein Experiment: Wenn jemand das nächste Mal einen Wasserfall-Prozess vorschlägt, fragen Sie die Person, wer den Prozess erfunden und empfohlen hat.
Der einfache Wasserfall-Prozess war vor 65 Jahren schon nicht zu empfehlen – und damals fing Softwareentwicklung im Team erst an. Recherche in Original-Quellen ist hilfreich.
Vielen Dank an meine Kolleg:innen Lena Kraaz, Martin Kühl, Tammo van Lessen, Torsten Mandry, Jörg Müller, Joachim Praetorius, Gernot Starke und Stefan Tilkov für die Kommentare zu einer früheren Version des Artikels.
URL dieses Artikels:https://www.heise.de/-4878614
Links in diesem Artikel:[1] https://en.wikipedia.org/wiki/Semi-Automatic_Ground_Environment[2] https://en.wikipedia.org/wiki/AN/FSQ-7_Combat_Direction_Central[3] https://web.archive.org/web/20110718084251/http://sunset.usc.edu/csse/TECHRPTS/1983/usccse83-501/usccse83-501.pdf[4] http://www-scf.usc.edu/~csci201/lectures/Lecture11/royce1970.pdf[5] https://leanpub.com/leprechauns/[6] https://de.wikipedia.org/w/index.php?title=V-Modell_(Entwicklungsstandard)&oldid=201987938
Copyright © 2020 Heise Medien
Softwaresysteme sind kompliziert. Best Practices für den Systementwurf könnten dabei helfen, die Komplexität möglichst einfach zu bändigen. Leider nützen sie wenig.
Dave Snowden teilt mit dem Cynefin [1]-Framework [2] Probleme, Systeme und Aufgaben in unterschiedliche Domänen ein:
Diese Blog-Post kann keine vollständige Einführung in das Cynefin-Framework sein. Aber aus dem Cynefin-Framework ergibt sich, dass Best Practices nur bei einfachen Systemen mit klaren Ursache-Wirkung-Beziehungen sinnvoll sind. Softwaresysteme sind jedoch in den meisten Fällen nicht nur technologisch komplex: Die Entwicklung findet in einem komplexen sozialen System statt, in dem die verschiedenen Rollen im Entwicklungsteam mit den Stakeholdern interagieren. Wie das technologische Softwaresystem auf der einen und die soziale Entwicklungsstruktur auf der anderen Seite miteinander interagieren, lässt sich schwer vorhersagen. Wir reden also von komplizierten oder komplexen Systemen. Es mag Ausnahmen geben, aber einfache Systeme rechtfertigen wohl kaum den Aufwand für die Implementierung von Individualsoftware, weil die Probleme eben einfach lösbar sind – beispielsweise durch Standardsoftware.
Wenn Softwareprojekte aber komplex oder kompliziert sind, dann gibt es in der Softwareentwicklung im Wesentlichen nur Good Practices oder gar Emergent Practices. Wer also einfach Ansätze aus einem anderen Kontext übernimmt und auf Best Practices setzt, wählt gegebenenfalls eine für diese Aufgabe ungeeignete Lösung. Wir arbeiten an einer Aneinanderreihung von unterschiedlichen, speziellen Herausforderungen und müssen uns jedes Mal auf diese andere Umgebung passend einstellen und Lösungen anbieten, die den aktuellen Herausforderungen gerecht werden.
Wer dennoch auf Best Practices setzt, macht es den am Projekt Beteiligten schwer, die gewählten Ansätze zu hinterfragen. Schließlich sind es ja Best Practices. Aber in Wirklichkeit können sie eben ungeeignet sein, weil man in einer anderen Domäne ist. Daher finde ich Aussagen wie "Microservices sind eine Architektur-Best-Practice" oder "Monolithen sind eine Architektur-Best-Practice" nicht hilfreich. Aber natürlich ist es sinnvoll, sich mit Ansätzen zu beschäftigen, die in einem bestimmten Kontext erfolgreich waren, und davon zu lernen.
Der Umgang mit Good oder Best Practice kann auch darüber hinaus problematisch sein. In einem mir bekannten Projekt haben Architekt:innen Schnittstellen, die nur zwei Teams nutzen, als Best Practice kommuniziert. Da immer nur zwei Teams beteiligt sind, können die Schnittstellen einfacher geändert und abgestimmt werden, als wenn mehrere Teams die Schnittstellen nutzen. Wenn man also mehreren Teams Funktionalitäten anbieten will, kann man für jedes Team eine Schnittstelle umsetzen, um so unabhängig zu arbeiten.
Eines der Teams in dem Projekt hatte diese Idee befolgt, obwohl die Schnittstellen relativ ähnlich waren und sich absehbar nicht ändern würden. Der Vorteil der Unabhängigkeit bei Änderungen ist also in diesem Fall unerheblich. Dennoch hat das Team keine einheitliche Schnittstelle umgesetzt. Diese Alternative hatte das Team selbst als bessere bewertet. Ohne die kommunizierte Best Practice der Architekt:innen hätte das Team vielleicht schon früher den eigenen, besseren Ansatz nutzen können. Denn natürlich hat der Ansatz mit vielen Schnittstellen Nachteile. Es entsteht so eine Vielzahl von Schnittstellen, die gewartet und implementiert werden müssen.
Die kommunizierte Best Practice ist vielleicht also nur eine Good Practice – oder der Kontext, in dem sie eine Best Practice ist, muss genauer definiert werden. Der zentrale Punkt ist, dass kommunizierte Best oder Good Practices dazu verleiten, diesen Beispielen einfach zu folgen und eigene, bessere Lösungen nicht zu nutzen. Daher sollte man solche Ansätze immer kritisch hinterfragen.
Entscheidungsvorlagen mit Kernfragen sind flexibler und können bei der Entscheidung zwischen verschiedenen Best oder Good Practices helfen. Solche Vorlagen finden viele nützlich, aber auch sie schränken den Lösungsraum ein, weil sie niemals alle denkbaren Fälle abdecken können.
Am Ende werden also die am Projekt Beteiligten individuelle Entscheidungen treffen und verantworten müssen. Sie müssen sie auch begründen. Sich hinter einer Best Practice oder einem "Das macht man heute so!" zu verstecken, ist nicht ausreichend.
Außerdem gibt es unterschiedliche Good Practices. Wenn also jemand einen Ansatz wählt, der vom eigenen bevorzugten Ansatz abweicht, kann das immer noch eine Good Practice sein – oder gar eine Emergent Practice, die speziell auf die Herausforderung angepasst ist. Dann sollte man sich davon verabschieden, die eigene “Best Practice” zu empfehlen. Natürlich kann der gewählte Ansatz gar keinen Sinn ergeben – dann kann man sicherlich einen anderen empfehlen.
Softwareentwicklung ist oft für Best Practices zu komplex. Sie können zwar Orientierung geben, werden sie aber ohne kritische Reflektion angewendet, können für die spezifische Herausforderung suboptimale Architekturentwürfe entstehen.
Vielen Dank an meine Kolleg:innen Robert Glaser, Anja Kammer, Martin Kühl, Joachim Praetorius und Hermann Schmidt für die Kommentare zu einer früheren Version des Artikels.
URL dieses Artikels:https://www.heise.de/-4872398
Links in diesem Artikel:[1] https://de.wikipedia.org/wiki/Cynefin-Framework[2] https://www.cybay.de/blog/das-cynefin-framework/
Copyright © 2020 Heise Medien
Mithilfe von PhoneGap konnten Entwickler seit 2008 hybride Apps für mobile Betriebssysteme schreiben: Einmal entwickelte Webanwendungen werden dabei in Anwendungscontainer verpackt, die Zugriff auf Schnittstellen der nativen Plattform gewähren. Nun stellt Adobe das Produkt ein. Betroffene Entwickler sollten auf andere Systeme umsteigen.
In seinem Update for Customers Using PhoneGap und PhoneGap Build [1] hat Adobe angekündigt, sein Produkt PhoneGap einzustellen. Zum 1. Oktober 2020 wird auch der Dienst PhoneGap Build abgeschaltet, der App-Pakete für verschiedene Betriebssysteme komfortabel in der Cloud kompiliert hat. Gleichzeitig beendet das Softwareunternehmen seine Unterstützung für Apache Cordova, den Open-Source-Fork von PhoneGap. Adobe begründet seine Entscheidung unter anderem mit dem Erstarken der Progressive Web Apps [2] (PWA), die die Lücke zwischen Web und Native zunehmend schließen [3], ohne Containerlösungen zu bedürfen.
Das quelloffene Projekt Apache Cordova [4] wird auch weiterhin von der Community getragen. Adobe empfiehlt betroffenen Entwicklern, von PhoneGap auf Cordova umzusteigen. Eine weitere Alternative wird von Ionic zur Verfügung gestellt: Dieses Unternehmen bietet ein umfassendes Ökosystem zur Entwicklung webbasierter Cross-Platform-Apps, das deutlich moderner und in Teilen umfangreicher ist als die Cordova- und PhoneGap-Welt. Ionics Open-Source-Tool Capacitor [5] ist kompatibel zu PhoneGap und Cordova und kann diese komplett ersetzen.
Nutzer von PhoneGap Build müssen ihre Daten bis zum 30. September 2020 sichern. Mit Ionic Appflow steht ein vergleichbarer kommerzieller Service zur Verfügung, zu dem Entwickler ihre PhoneGap-Build-Projekte übertragen können [6]. Adobe arbeitete mit Ionic zusammen, um eine reibungslose Migration zu ermöglichen. Die einzelnen Schritte finden sich in der Ionic-Dokumentation zum Thema Migrating from PhoneGap Build to Ionic Appflow [7].
Bereits in den vergangenen Jahren zeichnete sich Adobes schwindendes Interesse an PhoneGap ab: Viele Plug-ins zur Kommunikation mit den nativen Schnittstellen des Betriebssystems sind in die Jahre gekommen. Mit PhoneGap Build erstellte iOS-App-Pakete konnten aufgrund einer veralteten iOS-SDK-Version auf dem Cloud-Buildserver nicht mehr in den App Store hochgeladen werden. Ob die Community alleine Apache Cordova in einem stabilen Zustand erhalten kann, wird sich zeigen.
Doch das Ende von PhoneGap ist mehr Chance denn Drama: Plattformübergreifend einsetzbare Webanwendungen werden heute ohnehin am besten in Form einer Progressive Web App entwickelt. Dieses Anwendungsmodell setzt nicht zwingend native Container voraus. Nur für Deployments über Apples App Store sowie den Zugriff auf APIs, die noch nicht im Web verfügbar sind, braucht es einen Wrapper-Ansatz. In diesem Fall finden Entwickler bei Ionic ein umfassendes Ökosystem vor; der Umstieg dürfte sich einfach gestalten. Auch die Zukunftsaussichten sind gut: Denn Ionics Geschäftsmodell ist – im Gegensatz zu Adobes – komplett auf die Entwicklung plattformübergreifender Anwendungen auf Basis von Webtechnologien ausgerichtet.
URL dieses Artikels:https://www.heise.de/-4868133
Links in diesem Artikel:[1] https://blog.phonegap.com/update-for-customers-using-phonegap-and-phonegap-build-cc701c77502c[2] https://www.heise.de/developer/artikel/Progressive-Web-Apps-Teil-1-Das-Web-wird-nativ-er-3733624.html[3] https://www.heise.de/hintergrund/Project-Fugu-Brueckenschlag-zwischen-progressive-Web-und-nativen-Apps-4684369.html[4] https://cordova.apache.org/[5] https://capacitorjs.com/[6] https://ionicframework.com/blog/phonegap-build-no-longer-maintained-by-adobe/[7] https://ionicframework.com/docs/appflow/cookbook/phonegap-build-migration
Copyright © 2020 Heise Medien