
Das c't-zockt-Team dreht die Zeit zurück und erweckt alte Adventures für Amiga, Atari, DOS und Windows zu neuem Leben – unter Linux.
Mit Linux und einem eigens gepatchten ScummVM-Emulator dreht das c't-zockt-Team die Zeit zurück: Heute um 21 Uhr startet die neue Retro-Serie, in der wir alte Point&Click-Adventures aus Amiga-, Atari-, DOS- und frühen Windows-Zeiten auf Twitch live aus dem Wohnzimmer streamen.

Den Anfang macht die deutsche DOS-Version von Zak McKracken and the Alien Mindbenders von Lucasfilm Games aus dem Jahr 1988. Hier stolpert Qualitätsjournalist Zak während der Recherche für eine Boulevard-Story über eine Alien-Verschwörung und muss zusammen mit Annie, Melissa und Leslie mal eben die Welt vor der Unterjochung retten – unter anderem, indem Zak Maja-Tempel, das Bermuda-Dreieck, Atlantis und schließlich den Mars bereist.
Bei der Vorbereitung gab es gleich mehrere Herausforderungen: Die erste war, die alten 5,25"-Disketten aus der Original-Spiele-Box auf einen modernen Rechner zu kopieren. Das gelang uns mit einem alten Windows-98-Rechner und einem FTP-Server: Mit modernen USB-Sticks, selbst kleinen Größen, konnte Windows nicht umgehen, sodass wir die geretteten Dateien der Disketten per FTP übertragen mussten. Erstaunlich: Obwohl die 5,25"-Disketten über 30 Jahre alt waren und das Laufwerk kaum jünger, gab es keinen einzigen Lesefehler.
Anspruchsvoll ist auch die Grafik des Spiels mit einer Auflösung von 320x200 Pixeln – das füllt heute nicht einmal den Bildschirm eines Smartphones. Das Adventure im DOS-Emulator in Originalgröße zu streamen war also keine Option. Der Emulator ScummVM, der neben Spielen von Lucasfilm Games auch viele Abenteuer von Sierra und anderen Spieleschmieden unterstützt, bietet immerhin eine zweifache, respektive dreifache Vergrößerung.

Doch selbst in dreifacher Vergrößerung wäre ein heute gängiger Full-HD-Bildschirm nur zu einem Viertel gefüllt, weshalb wir die Entwickler von ScummVM angesprochen haben. Diese stellten uns einen Patch für vierfache Vergrößerung bereit, mit dem wir dann eigens ein neues Debian-Paket des Emulators erzeugten. Zak McKracken wird also in einer Auflösung von 1280x800 Pixeln unter Linux zu sehen sein, ergänzt um ein Chat- und ein Kamerafenster, sodass der Stream insgesamt Full-HD-Auflösung haben wird. Trotz der hohen Auflösung geht von dem Original-Feeling nichts verloren, wir haben uns gegen Optimierungen von Grafik oder Schriften entschieden.
Der erste Teil von Zak McKracken and the Alien Mindbenders wird heute ab 21 Uhr auf dem Twitch-Kanal von c't zockt [1] zu sehen sein und voraussichtlich, aufgrund der zu erwartenden Gesamtspieldauer, an einem anderen Donnerstagabend fortgesetzt werden. Die Aufzeichnung werden wir in den nächsten Wochen im YouTube-Channel von c't zockt [2] veröffentlichen. Für Nachschub ist auch schon gesorgt, neben Zak McKracken haben wir bereits Monkey Island 1 und 2, Loom und die Space-Quest-Saga Teil 1 bis 6 von unserem Pile of Shame gerettet.
()
URL dieses Artikels:http://www.heise.de/-4456321
Links in diesem Artikel:[1] https://twitch.tv/ctzockt[2] https://www.youtube.com/ctzockt[3] mailto:mid@ct.de
Copyright © 2019 Heise Medien

Im Early-Access-Spiel "Empires of the Untergrowth" kontrolliert der Spieler eine Ameisenkolonie und lässt sie mit der richtigen Strategie wachsen, kämpfen und siegen.
Die Ameisenkönigin liegt in ihrer Brutkammer. Um sie herum wuseln einige Arbeiterinnen und versorgen die wenigen Eier. Doch die neue Kolonie muss wachsen und braucht Futter. Mit der richtigen Taktik hilft der Spieler den Ameisen im Early-Access-Spiel "Empires of the Undergrowth [1]", sich zu einer großen, wehrhaften Kolonie zu entwickeln.
Das Echtzeitstrategiespiel von Slug Disco Studios erinnert in mancher Hinsicht an den Klassiker Dungeon Keeper. Als übergeordnete Instanz gibt man den Arbeiterinnen den Befehl zu graben, Futter zu sammeln oder Nahrungs- und Brutfelder anzulegen. Letztere sorgen für mehr Arbeiter- oder Soldatenameisen und bei den unvermeidlichen Kampfverlusten für stetigen Nachschub – aber nur so lange, wie Futter vorhanden ist. Herz der Kolonie ist die Königin, die es unter allen Umständen zu verteidigen gilt. Stirbt sie, ist die Runde vorbei.
Verschiedene Spiele-Modi, Aufgaben und Herausforderungen und nicht zuletzt eine Vielzahl an Feinden sorgen für Überraschungen und viel Spaß. Der Spieler kann unterschiedliche Strategien ausprobieren und nicht nur im unterirdischen Bau sondern auch an der liebevoll gestalteten Oberfläche agieren.
Im Hauptspiel, dem Formicarium, lebt die Startkolonie – eine Königin mit sieben Arbeiterinnen – in einer Ameisenfarm, die auf dem Tisch einer Wissenschaftlerin steht. Während des Spiels hört man die Konversation mit ihrem Assistenten. Dieser führt Experimente durch (Herausforderungen) und ist etwas sadistisch veranlagt.
Grafisch macht Empires of the Undergrowth viel her – die Entwicker haben die Unreal-4-Engine benutzt –, allerdings dürfte es zumindest arachnophobisch veranlagten Spielern Unbehagen verursachen. Ameisen und besonders Feinde wie Moderkäfer, räuberische Larven, Krebse, Fangschrecken, verschiedene Spinnen und nicht zuletzt andere Ameisenvölker werden recht realistisch dargestellt und animiert.
Wer die Hauptaufgabe erfüllt hat, kann spezielle Maps spielen oder ein freies Spiel starten. Bei letzterem wählt man Schwierigkeit und Feinde individuell aus und lässt in der Arena verschiedene Krabbeltiere gegeneinander antreten.
Obwohl Empires of the Undergrowth noch ein unfertiges Early-Access-Spiel ist, fielen uns kaum grafische oder spielerische Fehler auf, wenn man von der wechselnden Maustaste beim Setzen von Pheromon-Markern (damit steuert man Kampf- und Arbeitseinheiten) absieht. Mal braucht es einen Doppelklick auf die rechte Maustaste, mal reicht ein Linksklick.
Besonders wichtig: Das Spiel versteht zu fesseln und lässt Spieler, die Spaß am Ausprobieren von Taktiken haben, auch die eine oder andere Niederlage verschmerzen. Die bisherigen Inhalte reichen bereits für viele Stunden Spielspaß; die Entwickler planen aber weitere Feinde und Ameisenvölker wie Schnappkiefer- und Blattschneiderameisen – von letzteren gibt es bereits eine spielbare Demo-Map.
Empires of the Undergrowth ist für Linux, macOS und Windows bei GOG [4], Itch.io [5] und Steam [6] erhältlich und kostet rund 20 Euro. Unser Angezockt-Video finden Sie im ctzockt-Kanal [7] von YouTube oder hier:
()
URL dieses Artikels:http://www.heise.de/-4454821
Links in diesem Artikel:[1] http://eotugame.com/[2] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4454421.html?back=4454821[3] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4454421.html?back=4454821[4] https://www.gog.com/game/empires_of_the_undergrowth[5] https://slugdisco.itch.io/empires-of-the-undergrowth[6] https://store.steampowered.com/app/463530/Empires_of_the_Undergrowth/[7] https://www.youtube.com/ctzockt[8] mailto:rop@ct.de
Copyright © 2019 Heise Medien
2016 stellte Espressif eine leistungsfähige Familie von Microcontrollern auf Basis des ESP32 vor. Dieses Blog hat den ESP32 zwar bereits früher thematisiert, aber zum Auftakt einer Reihe von Beiträgen zu diesem Thema werden ESP32 und entsprechende Boards noch mal genauer beleuchtet.
Das chinesische Chip-Unternehmen Espressif hat vor wenigen Jahren durch seinen ESP8266-Chip große Euphorie bei Makern ausgelöst. Der ESP8266 als System-on-a-Chip (SoC) integriert sowohl einen leistungsstarken Microcontroller als auch eine WiFi-Komponente. Entsprechende Boards sind inzwischen schon für eine Handvoll Euros zu haben. Ich habe ESP-01-Boards bereits in diesem Blog genutzt, um Arduinos preiswert mit dem WLAN beziehungsweise dem Internet zu verbinden. Es ist dabei aber leicht zu übersehen, dass der ESP8266 in vielen Aspekten mit Arduinos ATMEL-Chips mithalten kann.
Wie auch bei Vierrad-Enthusiasten üblich soll zuerst ein Blick unter die Motorhaube erfolgen. ESP32-Chips enthalten eine ganze Reihe von interessanten Merkmalen:

Allerdings gibt es nicht nur eine Variante des ESP32, sondern gefühlt ein gutes Dutzend. Die heißen dann auch mal ESP32S, firmieren je nach Größe als WROOM oder WROVER, haben verschiedene Erweiterungen. Uns sollen deren Unterschiede kalt lassen. Für die Hardware-Interessierten verweise ich auf die Webseite esp32.net [1].
Selbstredend existiert nicht das eine ESP32-Board, sondern Dutzende. Solche mit Display und solche ohne, solche mit LoRA-Kommunikation und solche ohne. Dazu verschiedenste Formfaktoren, nach außen gelegte Pins und dergleichen mehr.

Als NodeMCU firmieren die Boards, die im Auslieferungszustand die Skriptsprache LUA und die entsprechende Firmware beherbergen. Grundsätzlich gibt es unterschiedliche Firmware-Optionen, die auf ESP32-Boards laufen, darunter zum Beispiel MicroPython (oder CircuitPython auf Adafruit-Boards), FreeRTOS (RTOS = Real-Time Operating System), und der Arduino Core für ESP32. Letztere Option nutze ich für den Rest dieses Blog-Postings.
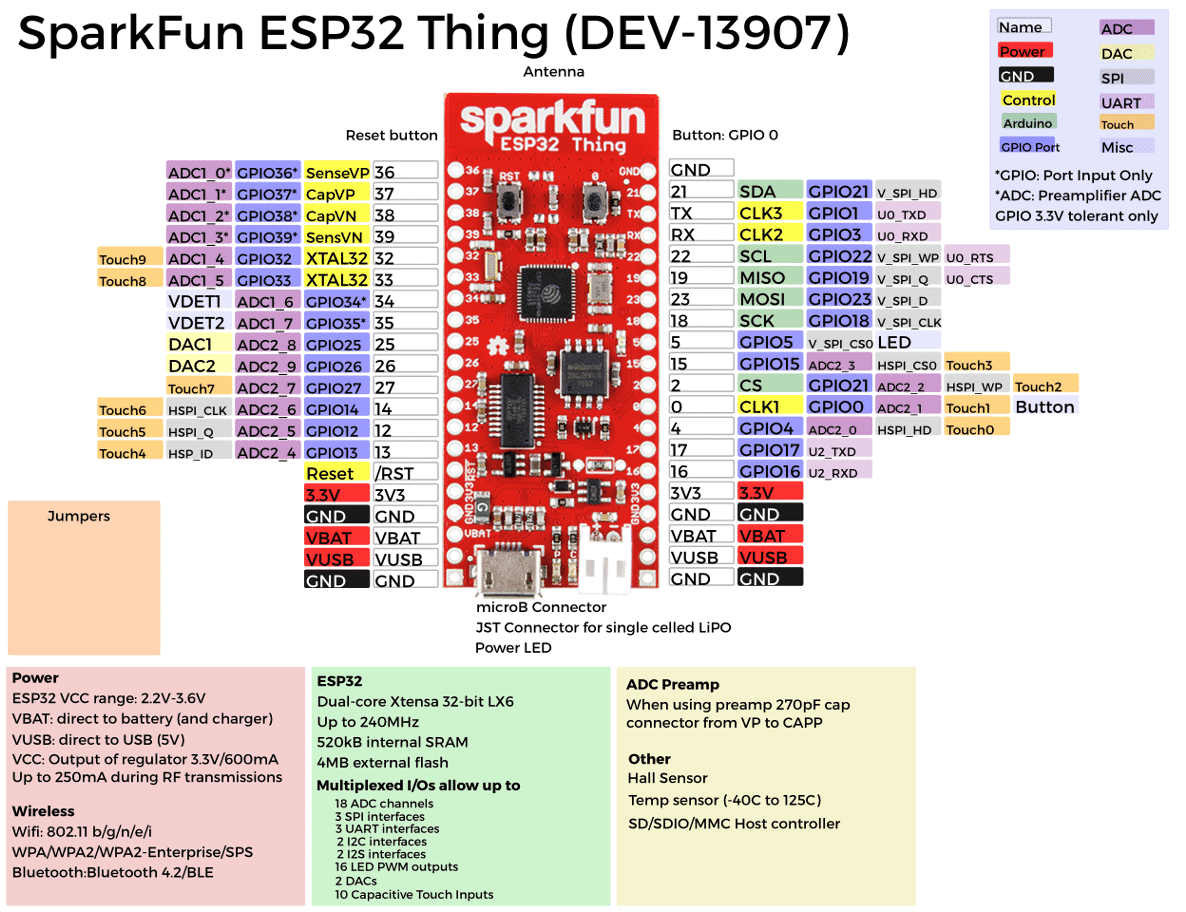
Zu den häufig anzutretenden Vertreter ihrer Gattung gehören beispielsweise das Original-ESP32-Dev-Modul von Espressif und seine zahlreichen Klone sowie das DOIT ESP32 DevKit V1. Diese gibt es in der Regel für Preise von 5 bis 10 Euro bei den üblichen Verdächtigen (eBay, Amazon, Watterott, EXP-TECH, Alibaba ....). Das finanzielle Risiko hält sich also in Grenzen. Eine Bestellung in China kommt noch etwas billiger, lohnt sich wegen der längeren Lieferzeiten aber nur, wenn es einem nicht schon in den Fingern juckt.
Es gibt diverse Optionen, die eine Host-/Target-Entwicklung mit ESP32-Boards unterstützen:
In Rahmen dieses Blogs dient die Arduino IDE in Kombination mit dem Arduino Core für ESP32 als Werkzeug der Wahl. Sie ist kostenlos und bietet ausreichende Funktionalität. Man könnte sie gewissermaßen als MVP (Minimal Viable Produkt) bezeichnen. Aber keine Sorge! In späteren Folgen kommt auch noch die Alternative Visual Studio Code zur Sprache.
Um ESP32-Boards unter der Arduino IDE zu nutzen, müssen Entwickler zunächst eine möglichst aktuelle Version der IDE für Windows, Linux, oder macOS herunterladen. Das Installationspaket steht auf der Downloadseite von arduino.cc [2] zur Verfügung. Auf die Installation gehe ich an dieser Stelle nicht weiter ein und verweise auf frühere Postings. Dazu gibt es YouTube-Ressourcen wie die hier [3].

Nach Installation der Arduino IDE ist folgende URL des gewünschten ESP32-Boardmanagers in der Einstellungsseite (Windows: File | Preferences, macOS: Arduino | Preferences) einzutragen: https://dl.espressif.com/dl/package_esp32_index.json.

Anschließend sollte man im Boardsmanager (Tools | Boards | Boardsmanager) nach "ESP32" suchen. Dort müsste das Paket "esp32 by Espressif Systems" auftauchen, das sich mit Install installieren lässt.

Das war es auch schon. Besser gesagt fast. Die (chinesischen) ESP32-Boards enthalten häufig einen UART-to-USB-Baustein von SiLabs. UART steht für Universal Asynchronous Receiver Transmitter und dient der seriellen Kommunikation zwischen Host-PC und Embedded Board über USB. Um am Windows-, Linux-, macOS-Computer mit dem Board kommunizieren zu können, ist ein entsprechender Treiber notwendig. Den gibt es über das Internet unter der URL <SiLabs> [4]).
Um die verschiedenen Pins eines ESP32-Boards mit symbolischem Namen innerhalb der Arduino IDE anzusprechen, existieren sogenannte Mappings, bereitgestellt durch den Arduino Core. Dazu finden sich im Installationsverzeichnis der IDE (Arduino | hardware | espressif | esp32 | variants | esp32) entsprechende Deklarationen in pins_arduino.h. Wie aus dem folgenden Bild ersichtlich, erweist sich ein solches Mapping als wichtig, um etwas Ordnung ins Namenschaos zu bringen.
Im Regelfall befinden sich zwei Tasten auf einem ESP32-Board, eine EN-Taste und eine BOOT-Taste. Der ESP32 kennt zwei Betriebsmodi, Normalmodus und Firmware-Update-Modus. Für das Einspielen neuer Software (eigenes Programm plus Laufzeitumgebung/Firmware) müssen Entwickler das Board daher in den Uploadmodus versetzen. Die EN-Taste sorgt lediglich für einen Restart. Stattdessen ist für den Software-Upload folgendes Vorgehen notwendig:
Achtung:

Sollte beim Kompilieren eines Programms innerhalb der IDE zu einer Fehlermeldung mit roter Schrift kommen, genügt es meist, die BOOT-Taste ein bisschen gedrückt zu halte, um sie anschließend wieder los zu lassen.
Nun erfolgt die erste Prüfung des jungfräulichen ESP32-Boards. Die Arduino IDE soll einen ersten Einblick vermitteln, dass die Programmierung exakt auf dieselbe Weise erfolgen kann wie bei Arduino-Boards.
Sobald der ESP32 am Hostcomputer angeschlossen ist, sucht man im Tools-Menü nach dem benutzten Board und stellt es ein. Zudem gibt im Ports-Bereich den vom Board verwendeten seriellen (SLab-)Port ein.
Ich selbst nutze zum Experimentieren das ESP32 Smart Thing von SparkFun sowie ein ESP32-Board von Watterott, besitze aber aus Preisgründen zahlreiche Boards des Typs NodeMCU32 sowie Lolin32 aus chinesischer Produktion.

Um das ESP32-Board zum ersten Mal zu programmieren, öffnet man in der Arduino IDE ein neues Projekt beziehungsweise einen neuem Sketch und gibt nachfolgenden Code ein. Der Sketch geht davon aus, dass sich die eingebaute LED an Pin 2 befindet. Sollte Entwickler ein anderes Board besitzen, lesen sie dessen Beschreibung und definieren sie gegebenenfalls für die Konstante LED einen anderen Wert. Danach lässt man das Programm übersetzen und aufs Board übertragen. Nach dem Öffnen des seriellen Monitors gibt man 115.200 Baud als Geschwindigkeit ein. Um den seriellen Monitor zu öffnen, navigiert man über den Menüpfad Tools | Serial Monitor.
Jetzt müsste sowohl die Onboard-LED im Einsekundentakt blinken als auch der Text “Hallo, ESP32” wiederholt auf dem seriellen Monitor erscheinen.
const int LED = 5; // Eingebaute blaue LED an Pin 5
// Setup - läuft nach jedem Reset genau einmal
void setup() {
// Digitaler Ausgang steuert die LED
pinMode(LED, OUTPUT);
Serial.begin(115200); // Seriellen Port mit 115200 Baud initialisieren
}// Unendliche Ereignisschleife; HIGH & LOW sind Spannungslevels!
void loop() {
Serial.println(“Hallo, ESP32”); // Ausgabe an seriellen Monitor senden
digitalWrite(LED, HIGH); // Es werde Licht
delay(1000); // Wartezeit von einer Sekunde
digitalWrite(LED, LOW); // Licht aus
delay(1000); // Wartezeit von einer Sekunde
}
Damit ist die Jungfernfahrt bereits erledigt. Wer experimentieren will, könnte zum Beispiel an Pin 5 auch eine externe LED anschließen oder andere Schikanen einbauen.
Da der ESP32 eine Mehrkernarchitektur aufweist, lassen sich echt parallele Threads beziehungsweise Tasks einsetzen. Das folgende Programm nutzt diese Möglichkeit exemplarisch, um Tasks mittels xTaskCreatePinnedToCore() zu erzeugen und sie an einen der beiden Kerne zu binden. Der erste Task taskOne läuft auf dem ersten Kern 0 der zweite taskTwo auf dem zweiten Kern 1. Beide Tasks haben Priorität 1 und erhalten 10.000 Bytes Stackgröße.
taskOne lässt die eingebaute LED jede halbe Sekunde blinken, während taskTwo jede halbe Sekunde Text am seriellen Monitor ausgibt.
TaskHandle_t task1; // Jeder Task benötigt einen Handle
TaskHandle_t task2;
// LED Pin ist die eingebaute Pin
const int ledPIN = 5;void setup() {
Serial.begin(115200);
pinMode(ledPIN, OUTPUT);
// task ausgeführt in taskOne()
// auf dem ersten Core (Core 0), Prio: 1
xTaskCreatePinnedToCore(
taskOne, /* Funktion mit Code des Tasks */
"TaskOne", /* Name des Tasks */
10000, /* Stackgröße des Tasks */
NULL, /* Parameter des Tasks */
1, /* Priorität des Tasks */
&task1, /* Handle auf Task */
0); /* Task soll auf Kern 1 laufen */
delay(500);// task ausgeführt in taskTwo()
// auf dem zweiten Core (Core 1), Prio: 1
xTaskCreatePinnedToCore(
taskTwo, /* Funktion mit Code des Tasks */
"TaskTwo", /* Name des Tasks */
10000, /* Stackgröße des Tasks */
NULL, /* Parameter des Tasks */
1, /* Priorität des Tasks */
&task2, /* Handle auf Task */
1); /* Task soll auf Kern 2 laufen */
delay(500);
}// taskOne: LED soll alle 2 Sekunden blinken
void taskOne( void * optionalArgs ){
for(;;){
digitalWrite(ledPIN, HIGH);
delay(500);
digitalWrite(ledPIN, LOW);
delay(500);
}
}// taskTwo: Ausgabe am seriellen Monitor alle 100 msec
void taskTwo( void * optionalArgs ){
Serial.print("Task 2 läuft auf Kern ");
Serial.println(xPortGetCoreID())
for(;;){
Serial.println("LED an");
delay(500);
Serial.println("LED aus");
delay(500);
}
}
void loop() { /* braucht es nicht */ }
Die Methode loop() bleibt in diesem Fall ungenutzt, weil sich die Ereignisschleife ohnehin in den endlos laufenden Tasks abspielt.
Das Beispiel ist zwar lehrreich, aber etwas theoretisch. In der Praxis könnte einer der Tasks die Kommunikation mit der Außenwelt übernehmen, während der zweite Messwerte von Sensoren liest.
In jedem Fall wäre es hilfreich, würden Tasks auch Information austauschen. Genau das demonstriert das nachfolgende Beispiel. Mittels xQueueCreate legt das Hauptprogramm eine Queue mit einem Slot des Datentyps unsigned long an. Das Kreieren der Tasks bewerkstelligt diesmal die Methode xTaskCreate. Das Programm implementiert eine simple Produzenten-Konsumenten-Konstellation.
Der Aufruf von vTaskDelay ist das ESP32-Pendant zu Arduinos delay, arbeitet aber mit höherer Auflösung, weshalb wir die gewünschte Zeitdauer noch durch die Konstante portTICK_PERIOD_MS teilen müssen. Die Konstante gibt an, wie viele Taktzyklen pro Millisekunde durchgeführt werden.
Um sicherzustellen, dass ein Wert in der Queue vorhanden und ungelesen ist oder bereits ein neuer geschrieben werden kann, fragt der Produzent queue auf Null ab, bevor er schreibt. Entsprechend prüft der Konsument, ob tatsächlich ein Wert in der Queue vorliegt.
QueueHandle_t queue = NULL; // Queue anlegenvoid setup()
{
printf("Starte zwei Tasks und eine Queue /n /n");
queue = xQueueCreate(20,sizeof(unsigned long));
if(queue != NULL){
printf("Queue kreiert \n");
vTaskDelay(1000/portTICK_PERIOD_MS); // Eine Sekunde warten
xTaskCreate(&produzent,"produzent",2048,NULL,5,NULL);
printf("Produzent gestartet \n");
xTaskCreate(&konsument,"konsument",2048,NULL,5,NULL);
printf("Konsument gestarted \n"); // Hier nutzen wir mal C/C++
} else {
printf("Queue konnte nicht angelegt werden \n");
}
}
void konsument(void *pvParameter)
{
unsigned long counter;
if (queue == NULL){
printf("Queue nicht bereit \n");
return;
}
while(1){
xQueueReceive(queue,&counter,(TickType_t )(1000/portTICK_PERIOD_MS));
printf("Empfangener Wert über Queue: %lu \n",counter);
vTaskDelay(500/portTICK_PERIOD_MS); // halbe Sekunde warten
}
}
void produzent(void *pvParameter){
unsigned long counter=1;
if(queue == NULL){
printf("Queue nicht bereit \n");
return;
}
while(1){
printf("An Queue gesendeter Wert: %lu \n",counter);
xQueueSend(queue,(void *)&counter,(TickType_t )0);
// ... schreibt den wert von Counter in die Queue
counter++;
vTaskDelay(500/portTICK_PERIOD_MS); // halbe Sekunde warten
}
}
void loop() {}
Ein ESP32-Board braucht im aktiven Zustand schon einige mA, im Schnitt etwa 150 bis 260 mA. Im aktiven Modus inklusive aller Komponenten wie WiFi und Bluetooth können das sogar bis zu 800 mA bei Spitzenlasten sein. Innerhalb von IoT-Anwendungen kommt es aber durchaus häufig vor, dass Geräte mittels Sensoren nur alle Minuten oder sogar Stunden kurzzeitige Messungen vornehmen, um sie anschließend per Kommunikationsprotokoll nach außen zu übertragen. Es macht also keinen Sinn, einen Embedded-Controller ständig aktiv arbeiten zu lassen. Bei einem autonomen, batteriebetriebenen Gerät müsste man ansonsten alle paar Stunden die Batterie ersetzen. Stellt man sich vor, dass das Gerät auf einem Baum in großer Höhe angebracht ist, dürfte die praktische Dimension dieses Problems klar sein.
Deshalb unterstützt der ESP32 diverse Sparmodi. Beim Deep-Sleep-Modus sind nur noch der RTC (Echtzeituhr) und der ULP-Koprozessor (ULP = Ultra Low Power) aktiv. Der benötigte Reststrom beträgt in diesem Fall gerade einmal 2,5 micro Ampere. Damit lässt sich gut auskommen.
Um vom Tiefschlaf zu erwachen, braucht der ESP32 keinen schönen Prinzen, obwohl auch das möglich wäre. Es gibt drei Optionen: Betätigen eines Touch-Pins, Ereignis an einem externen Pin (= Signalflanke) oder zeitgesteuertes Aufwecken mittels des ULP-Koprozessors. Diesen letzteren Fall beleuchtet nachfolgendes Beispiel.
Allerdings führt der Tiefschlaf auch eine Art digitale Demenz nach sich, weil die Daten (= Variablen) bis auf eine Ausnahme verloren gehen. Alle Daten, die mit dem Schlüsselattribut RTC_ATTR_DATA deklariert sind, bleiben erhalten. Immerhin beherbergt dieser persistente Speicher rund viermal so viele Daten wie ein gewöhnlicher Arduino Uno/Mega/Nano Speicher insgesamt mitbringt.
Im folgenden Programm liegt die Variable restarted im besagten Speicher. Sie zählt einfach mit, wie oft bereits ein Neustart erfolgte. Beim ersten Start (restarted == 0) blinkt die eingebaute LED kurz. Sind schon mehrere Restarts nach Tiefschafphasen erfolgt (restarted != 0), blinkt die LED häufiger.
Die Einleitung eines zeitgesteuerten Tiefschlafs beginnt mit dem Aufruf von esp_sleep_enable_timer_wakeup(TIME_TO_SLEEP * uS_TO_S_FACTOR. Die Zeit in Sekunden gibt TIME_TO_SLEEP wieder. Da intern die Berechnung in Microsekunden erfolgt, muss der Umrechnungsfaktor uS_TO_S_FACTOR noch dazu multipliziert werden. Den eigentlichen Tiefschlaf leitet der folgende Aufruf ein: esp_deep_sleep_start():
#define uS_TO_S_FACTOR 1000000 // Microsekunden => Sekunden
#define TIME_TO_SLEEP 3 // Schlaflänge in Sekunden :-)
RTC_DATA_ATTR int restartet = 0;
#define LEDPIN 2 // eingebaute LED
#define BLINK_DELAY 200 // Blinkfrequenz = 200 / BLINK_DELAY
void setup() {
Serial.begin(115200);
Serial.println(“Deep Sleep mittels Timer - Demo”);
pinMode(LEDPIN,OUTPUT); // LED
delay(500); // a bisserl Geduld
if(restartet == 0) // das erste Mal
{
Serial.println(“Initialer Start”);
digitalWrite(LEDPIN, HIGH); // Licht an
delay(10 * BLINK_DELAY);
digitalWrite(LEDPIN, LOW); // Spot aus
restartet++;
} else // nicht mehr jungfräulich
{
Serial.println(“Schon ein paar Mal aus Schlaf erwacht: “ + String(restartet)));
blinken(restartet);
}
// In Tiefschlaf versetzen
Serial.print(“Tiefschlaf wird initiiert für “ + String(TIME_TO_SLEEP));
Serial.println(“ Sekunden”);
esp_sleep_enable_timer_wakeup(TIME_TO_SLEEP * uS_TO_S_FACTOR);
esp_deep_sleep_start(); // Schlaf beginnt
}
void blinken(byte n) { // n mal Blinken im BLINK_DELAY msec Abstand
Serial.println(“Blinken startet”);
for (i = 0; i < n; i++) {
Serial.println(“LED an”);
digitalWrite(LEDPIN, HIGH);
delay(BLINK_DELAY);
Serial.println(“LED aus”);
digitalWrite(LEDPIN, LOW);
}
}
void loop() {
Serial.println(“Unerreichter Code”);
}
Da das Programm den Tiefschlaf in setup() durchführt, kommt es in diesem Beispiel natürlich nie zur Ausführung der Methode loop().
Nun sind wir am Ende dieses Beitrags angekommen, womit die Basis für eigene Experimente gelegt wäre. Dabei lag der Fokus auf die inneren Werte des ESP32. Wir haben die funktionale Architektur beleuchtet, einige besondere Aspekte wie Parallelisierung und Tiefschlaf betrachtet und dazu Beispiele kennen gelernt. Im Mittelpunkt der Programmierung stand dabei die Arduino IDE.
Beim nächsten Beitrag kommt die Interaktion des ESP32 mit der Außenwelt zur Sprache. Themen sind dann insbesondere die WiFi-Funktionalität des Microcontrollers.
Bis dahin viel Spaß beim Experimentieren!
URL dieses Artikels:http://www.heise.de/-4452689
Links in diesem Artikel:[1] http://esp32.net[2] https://www.arduino.cc/en/Main/Software[3] https://www.youtube.com/watch?v=39yjdj1b9bs[4] https://www.silabs.com/products/development-tools/software/usb-to-uart-bridge-vcp-drivers
Copyright © 2019 Heise Medien
Dieser Blog war krankheitsbedingt verwaist. Jetzt ist es an der Zeit, ihn wieder mit neuen Beiträgen zu füllen. In der nahen Zukunft soll wieder das Thema IoT (Internet of Things) und Mikroelektronik zur Sprache kommen.
In den letzten Postings – also vor einer gefühlten Ewigkeit – habe ich mich mit IoT und Embedded Microcontrollerboards beschäftigt. Das geschah hauptsächlich auf Basis des Arduino-Ökosystems.
Das Thema Arduino spielt auch weiterhin eine wichtige Rolle. Immerhin hat sich in der Zwischenzeit einiges getan, was neue Arduino-Boards betrifft. In den zukünftigen Beiträgen verschiebt sich mein Fokus allerdings in Richtung Espressifs ESP32-Plattform. Auch andere Mütter haben schließlich hübsche Töchter. Dabei soll der Blog gelegentlich auch Themen wie KI @ Microcontrollers und Cloud Computing adressieren.
Microcontroller-Boards mit ESP32 unter der Motorhaube bieten für wenige Euro viel Leistung und Funktionalität. Speziell die eingebaute WiFi-Funktionalität springt dabei ins Auge. Daher bieten sich diese Boards auch für komplexere Projekte an. Die Menge von Möglichkeiten ist schier unüberschaubar.
In den ersten Beiträgen soll die Architektur des ESP32 im Schwerpunkt stehen, natürlich auch mit dem Blick auf passende Entwicklungswerkzeuge. Da die Community einen sogenannten Arduino-Core für den ESP32 entwickelt hat, lassen sich Anwendungen auch weiterhin mit der vertrauten Arduino IDE erstellen. Es gibt dafür aber auch leistungsstärkere Alternativen wie Visual Studio Code, die bei den Betrachtungen ebenfalls zur Sprache kommen.
Sollten Sie spezielle Themenwünsche haben, würde ich mich über entsprechendes Feedback sehr freuen. Ein Blog lebt schließlich auch von der Interaktion des Autors mit seinen Lesern.
Ich freue mich auf Ihre Rückmeldungen.
URL dieses Artikels:http://www.heise.de/-4446767
Copyright © 2019 Heise Medien

Unser Videotutorial zeigt, wie Sie den ersten Tag im Alpha 17 des Survival-Games "7 Days To Die" überleben und die performancehungrige Grafik optimieren können.
Fiese Zombies, Hunde, Wölfe und Bären: Die Gefahren in "7 Days To Die" sind reichlich. Auch Hunger, Durst oder eine Infektion können das Leben in der Postapokalypse schnell beenden. c't-Redakteur Rudolf Opitz liefert in Teil 1 unseres Videotutorials zu "7 Days To Die" Tipps, die durch den ersten Spieltag helfen.
Mit der im Dezember 2018 erschienenen Alpha 17 [1] haben die Entwickler von The FunPimps noch eine Schippe draufgelegt und viele neue Features ins Spiel eingebaut. Über 120 neue "Points of Interest" sind dazugekommen, die riesigen Gebäude mit unterirdischen Gängen und viel versteckter Beute lassen so schnell keine Langeweile aufkommen. Die Erkundung jedes einzelnen gleicht einer kleinen Quest.
Umfangreiches Crafting verschafft Waffen, Nahrungsmittel und Fahrzeuge, mit denen die Postapokalypse leichter zu bewältigen ist. Erst im Laufe des Spiels schaltet man weitere Fähigkeiten frei. Neben der liebevoll gestalteten Standardmap Navezgane lassen sich beliebig viele neue zufallsgenerierte Maps starten, die für Abwechslung sorgen.
So komplex und spannend das Spiel ist: In vielen Dingen merkt man, dass "7 Days To Die" noch in der Early-Access-Phase steckt – auch wenn die Bezeichnung "Alpha" ein starkes Understatement ist. Besonders die Performance lässt häufig noch zu wünschen übrig. Fallen die Frameraten zu tief, kann man glücklicherweise an vielen Schräubchen in den Einstellungen drehen, um mehr herauszuholen. Wenn man die richtigen findet, sieht die Grafik auch in der Early-Access-Phase gut aus. In Folge 00 unseres 7 Days To Di-Tutorials zeigen wir, wo Anpassungen sinnvoll sind und wo eher nicht.
Weitere Episoden unseres 7-Days-To-Die-Tutorials erscheinen jeweils donnerstags im c't-zockt-YouTube-Channel [2].
"7 Days To Die" gibt es für Linux, macOS und Windows bei Steam für rund 23 Euro [3]. Der Kauf schließt alle künftigen Versionen bis zur Fertigstellung ein.
()
URL dieses Artikels:http://www.heise.de/-4415885
Links in diesem Artikel:[1] https://www.heise.de/ct/artikel/Harte-Zeiten-c-t-zockt-LIVE-ab-17-Uhr-die-neue-Version-von-7-Days-To-Die-4242808.html[2] https://www.youtube.com/ctzockt/[3] https://store.steampowered.com/app/251570/7_Days_to_Die/[4] mailto:lmd@heise.de
Copyright © 2019 Heise Medien
Mike Milinkovich, Executive Director der Eclipse Foundation, hat einen ernüchternden Lagebericht [1] zu den mittlerweile mehr als 18 Monate anhaltenden Verhandlungen zwischen der Eclipse Foundation und Oracle bezüglich Jakarta EE und der Verwendung von Oracles Markenrechten an Java veröffentlicht. Offiziell geht es um das Recht zur Verwendung der Namensrechte, unter anderen des Namensraums javax. Inoffiziell geht es um nicht weniger als die Zukunft des Enterprise-Java-Standards: Jakarta EE (vormals Java EE).
Vor rund anderthalb Jahren verkündete Oracle die Öffnung von Java EE [2] und übergab wenig später die zugehörigen Sourcen inklusive Technology Compability Kits (TCKs) an die Eclipse Foundation [3]. In den darauffolgenden Monaten investierte die Open-Source-Organisation viel Zeit und Energie in die Portierung der aktuellen Java-EE-Version 8 hin zu einem zu 100 Prozent kompatiblen Jakarta EE 8.
Parallel zu diesen Bemühungen wurde ein eigener Spezifikationsprozess namens Jakarta EE Specification Process (JESP) [4] etabliert, der den bis dato gültigen Java Community Process (JCP) von Oracle ablösen soll. Die Portierung ist mittlerweile abgeschlossen, wie in dem Blog Post "Jakarta EE has landed [5]" von Ian Robinson und Kevin Sutter zu lesen ist.
Nachdem es zunächst so aussah, als ob es nach Oracles "Donation" an die Eclipse Foundation auch bezüglich der Verwendung der damit einhergehenden Marken- und Namensrechte zu einer sinnvollen Einigung kommen könnte, schreibt Milinkovich nun, dass genau damit leider nicht zu rechnen ist:
"It had been the mutual intention of the Eclipse Foundation and Oracle to agree to terms that would allow the evolution of the javax package namespace in Jakarta EE specifications. Unfortunately, following many months of good-faith negotiations, the Eclipse Foundation and Oracle have been unable to agree on terms of an agreement for the Eclipse Foundation community to modify the javax package namespace or to use the Java trademarks currently used in Java EE specifications. Instead, Eclipse and Oracle have agreed that the javax package namespace cannot be evolved by the Jakarta EE community. As well, Java trademarks such as the existing specification names cannot be used by Jakarta EE specifications."
Bei der Portierung der Java-EE-Sourcen ist man bei der Eclipse Foundation, nach ersten Gesprächen mit Oracle, zunächst stillschweigend davon ausgegangen, dass bestehende APIs unter dem Namensraum javax weiterverwendet und dort auch im gewissen Rahmen modifiziert werden dürfen. Neue Spezifikationen dagegen sollten unter dem neuen Namensraum jakarta eingeführt werden. Bei einem derartigen Vorgehen wäre eine schrittweise Weiterentwicklung der Plattform bei gleichzeitiger Sicherstellung der Abwärtskompatibilität bestehender Java-EE-Anwendungen problemlos möglich. Eine essenzielle Voraussetzung für die Zukunft des Enterprise-Java-Standards, bedenkt man das seit mittlerweile 20 Jahren gewachsene Ökosystem mit seinen vielen tausend Anwendungen.
Der bisherige Status quo der Verhandlung zwischen der Eclipse Foundation und Oracle aber verbietet genau das. Änderungen an APIs mit dem Namensraum javax sind nicht erlaubt. Finden Änderungen statt, muss das Package umbenannt werden – und auch die zugehörige API. Und als wäre das noch nicht genug, obliegen Spezifikation, die weiterhin auf dem javax-Namensraum basieren, den bisherigen Auflagen von Oracle, die unter anderem das Vorhandensein einer von Oracle lizenzierten Runtime vorsehen: Dazu Milinkovich:
“In addition to the above, any specifications which use the javax namespace will continue to carry the certification and container requirements which Java EE has had in the past. I.e., implementations which claim compliance with any version of the Jakarta EE specifications using the javax namespace must test on and distribute containers which embed certified Java SE implementations licensed by Oracle. These restrictions do not apply to Jakarta EE specifications which do not utilize javax, including future revisions of the platform specifications which eliminate javax.”
Laut Milinkovich haben die Verhandlungen einen Status erreicht, bei dem für beide Seiten das bestmögliche Resultat erzielt wurde. Anders formuliert ist mit weiteren Kompromissen seitens Oracle definitiv nicht zu rechnen.
Aber ist das überhaupt ein Problem? Gehen wir einmal davon aus, dass die Eclipse Foundation, wie im Fall der Portierung von Java EE 8 zu Jakarta 8, zunächst keine Änderung an den bestehenden APIs vornimmt und somit die bestehenden Strukturen – inklusive Spezifikationen und TCKs – beibehalten kann. Bliebe zunächst einmal nur das Problem mit der Runtime. Dies wiederum würde einen dedizierten Hersteller, nämlich Oracle, gegenüber anderen Herstellern bevorzugen, was wiederum gegen die Statuten der Eclipse Foundation verstößt.
Gut, mag sich jetzt der eine oder die andere denken. Man kann in Ausnahmesituationen ja durchaus auch einmal über den eigenen Schatten springen. Schließlich verdankt man Oracle ja den aktuellen Stand der Sourcen. Ganz so einfach ist es allerdings nicht. Für die Eclipse Foundation könnte das punktuelle Aufgeben der bisher vielbeschworenen Herstellerneutralität im schlimmsten Fall bedeuten, dass sie einen Teil ihrer Gemeinnützigkeit und den damit verbundenen Steuervergünstigungen verlieren würde und sich somit nicht mehr von selbst tragen könnte. Für die Organiisation ist es also nicht nur eine Frage von Marken- und Namensrechten, sondern vielmehr eine existenzielle Frage und ein entsprechender Kompromiss mit Oracle somit per Definition nicht gangbar.
Wie aber sähe dann die Alternative aus? Realistisch gesehen bleibt der Eclipse Foundation für alle Versionen nach Jakarta EE 8 nur die Möglichkeit, alle Packages von javax nach jakarta zu portieren. Und das so schnell wie möglich, möchte man nicht noch länger auf eine längst überfällige Weiterentwicklung der Plattform und damit einhergehender Innovationen verzichten müssen. Natürlich müssten auch alle Spezifikationen und die zugehörigen TCKs angepasst beziehungsweise neu geschrieben werden.
Für Projekte, die auf der grünen Wiese starten, wäre das sicherlich kein Problem. Anders dagegen für die vielen, vielen bestehenden Enterprise-Anwendungen, die in den letzten 20 Jahren entstanden sind. Selbst wenn man willens wäre, die notwendigen Refactorings am eigenen Code, inklusive hoffentlich vorhandener Tests, vorzunehmen, setzt dieser mit hoher Wahrscheinlichkeit auf Libraries, Frameworks und proprietären Erweiterungen von Anwendungsservern auf, die noch nicht kompatibel mit dem neuen Standard sind. Das Chaos scheint vorprogrammiert.
Macht es dann überhaupt noch Sinn am Standard festzuhalten? Welchen Mehrwert hätte dieser dann noch? Ein großes Plus wäre nach wie vor, vorausgesetzt alle Application-Server-Hersteller spielen weiter mit, die Herstellerunabhängigkeit. Es wird auch weiterhin unabhängige TCKs geben, welche die Kompatibilität der verschiedenen Implementierungen sicherstellen.
Ein weiteres, nicht zu unterschätzendes Plus stellt der Spezifikationsprozess (JESP) dar. Durch die Beteiligung unterschiedlichster Interessengruppen ist sichergestellt, dass nicht nur durch die Belange eines einzelnen Herstellers die zukünftige Entwicklung des Standards vorangetrieben wird. Ganz im Gegenteil. Nimmt man einmal die jüngste Entwicklung des Eclipse-Foundation-Projekts MicroProfile als Muster, bekommt man einen Eindruck davon, wie schnell und Community-getrieben es zukünftig vorangehen könnte.
Bleibt nach wir vor die Herausforderung der Abwärtskompatibilität. Ein sicherlich unschönes, aber nicht unlösbares Problem, wie David Blevins (Gründer und CEO von Tomitribe) in seinem Blog-Post "Jakarta EE: a new hope [6]" im Abschnitt "Backwards compability is possible" beschreibt. Die Application Server müssten lediglich das tun, was sie heute sowie schon machen und mittels Bytecode-Creation und/oder -Manipulation die alten Java-EE-Sourcen für die neue Wunderwelt Jakarta EE aufbereiten. Blevins:
"For a Jakarta EE implementation to migrate your bytecode from javax to jakarta is ‘more of the same.’ There will be some challenges, but it is ultimately how everything works anyway."
Bleibt zu hoffen, dass David Recht behält und die Application-Server-Hersteller willens sind, diesen Schritt zu gehen. Wenn ja, dann steht der Zukunft von Jakarta EE als Enterprise-Java-Standard nichts im Wege. Wenn nicht, wird Jakarta EE zukünftig lediglich eines von vielen Enteprise-Java-Frameworks sein.
URL dieses Artikels:http://www.heise.de/-4413537
Links in diesem Artikel:[1] https://eclipse-foundation.blog/2019/05/03/jakarta-ee-java-trademarks/[2] https://www.heise.de/meldung/Oracle-will-Java-EE-an-die-Open-Source-Community-uebertragen-3806673.html[3] https://www.heise.de/meldung/Jakarta-EE-Eclipse-Foundation-uebernimmt-die-Verantwortung-fuer-Enterprise-Java-4030557.html[4] https://www.heise.de/meldung/Jakarta-EE-Goodbye-JCP-willkommen-EFSP-4193449.html[5] https://developer.ibm.com/announcements/jakarta-ee-has-landed/[6] https://www.tomitribe.com/blog/jakarta-ee-a-new-hope/
Copyright © 2019 Heise Medien

In der jüngsten Folge des c't uplink sprechen wir über Fritzboxen, eine VR-Brille mit besonders großem Sichtfeld und faltbaren Smartphones mit Mängeln.
Bei Problemen mit der Wiedergabe des Videos aktivieren Sie bitte JavaScript
Fritzboxen sind beliebt, es muss aber nicht immer das Top-Modell sein. Dušan Živadinović erklärt uns, worauf man beim Kauf achten sollte, wie Mesh-Netzwerke funktionieren und für wen sie vielleicht die Lösung für das heimische WLAN-Loch sind.
Jan-Keno Janssen hat die Pimax VR 5K ausprobiert. Die chinesische Virtual-Reality-Brille hat nicht nur ein 5K-Display sondern bietet mit 200-Grad Sichtfeld fast doppelt so viel Sichtbreite wie Oculus, Vive und Co. Ob man damit vergisst, dass man gar nicht wirklich durchs Weltall schwebt?
Außerdem sprechen wir über den Note-7-Nachfolger im Geiste: Könnte das faltbare Samsung Galaxy Fold ein ähnliches Schicksal treffen wie das akkugeplagte Note 7 und wegen technischer Probleme nie wirklich auf dem Markt kommen? Die ersten Testgeräte haben als Special-Feature nämlich ausfallende Displays.
Mit dabei: Dušan Živadinović, Johannes Börnsen, Jan-Keno Janssen und Hannes Czerulla
Die komplette Episode 27.2 zum Nachhören und Herunterladen:
Bei Problemen mit der Wiedergabe des Videos aktivieren Sie bitte JavaScript
Die c't 10/2019 [8] gibt's am Kiosk, im Browser [9] und in der c't-App [10] für iOS [11] und Android [12].
Alle früheren Episoden unseres Podcasts findet ihr unter www.ct.de/uplink [13].
()
URL dieses Artikels:http://www.heise.de/-4406778
Links in diesem Artikel:[1] http://ct.de/uplink[2] http://blog.ct.de/ctuplink/ctuplink.rss[3] http://blog.ct.de/ctuplink/ctuplinkvideohd.rss[4] https://itunes.apple.com/de/podcast/ct-uplink/id835717958[5] https://itunes.apple.com/de/podcast/ct-uplink-video/id927435923?mt=2[6] https://www.youtube.com/playlist?list=PLUoWfXKEShjdcawz_wBJVqkv0pVIakmSP[7] https://www.facebook.com/ctuplink[8] https://www.heise.de/select/ct/2019/10[9] https://www.heise.de/select/ct[10] https://www.heise.de/ct/Das-digitale-Abo-1818298.html[11] https://itunes.apple.com/de/app/ct-magazin/id380266921[12] https://play.google.com/store/apps/details?id=de.heise.android.ct.magazin[13] https://www.ct.de/uplink[14] mailto:mho@heise.de
Copyright © 2019 Heise Medien
Softwareentwicklung ist nicht wegen der technischen Herausforderungen schwierig, sondern weil so viele Menschen daran beteiligt sind. Ein Blick über den Tellerrand zeigt, wie andere Branchen mit diesen Herausforderungen umgehen und was sie dabei gelernt haben.
Als Beispiel dient eine Geschichte über eine Autofabrik [1]. General Motors (GM) eröffnete die Fabrik 1962 als Fremont Assembly [2]. Leider erwarb sie sich schnell einen katastrophalen Ruf: Die Arbeiter sollen die schlechtesten in der gesamten US-Automobilindustrie gewesen sein. Alkohol war genauso an der Tagesordnung wie unentschuldigtes Fehlen, sodass manchmal die Produktion gar nicht anlaufen konnte. Ebenso sabotierten die Arbeiter die Produktion. Dem Management war die Perspektive der Arbeiter egal. Und natürlich ging es wie so oft in der Massenproduktion um Menge und nicht um Qualität.
1984 wurde die gesamte Belegschaft gefeuert. GM und Toyota gründeten in der Fabrik ein Joint Venture. Natürlich musste man Arbeiter einstellen, was schwierig war. Am Ende arbeiteten dann 85 Prozent der alten GM-Belegschaft in der Fabrik. Einige von ihnen schickte Toyota nach Japan, damit sie dort das Toyota-Produktionssystem [3] erlernten. Am Ende erreichte das Werk dieselbe Produktivität und Fehlerzahl wie die Werke von Toyota in Japan und damit deutlich bessere Ergebnisse als GM.
Das Toyota-Produktionssystem orientiert sich an Werten wie kontinuierlicher Verbesserung, Respekt gegenüber Menschen und langfristigem Denken. Im NUMMI-Werk sind die Werte auch direkt umgesetzt worden: Der Fokus lag auf der Arbeit im Team und auf Qualität. Alle Mitarbeiter – egal ob sie im Management oder in der Produktion arbeiteten – trugen dieselbe Uniform, hatten dieselben Parkplätze und eine gemeinsame Cafeteria. Ebenso gab es keine Entlassungen, ein Vorschlagsprogramm und Entscheidungen im Konsens.
Ein wichtiger Teil des Toyota-Produktionssystems ist Jidōka [4]. Es steht für "Autonomation", eine autonome Automation oder auch "intelligente Automation" beziehungsweise. "Automation mit menschlichem Touch". Bei Anomalien stoppt die Maschine. Das Ziel ist keine vollständige Automatisierung. Dann müssten die Maschinen selber mit Anomalien umgehen können. Das ist aber kaum kosteneffizient realisierbar.
Stattdessen identifiziert der Arbeiter das Kernproblem und beseitigt es. Dazu kann er die Produktionslinie stoppen und die Hilfe der Kollegen anfordern. Produktionsstillstand kann erhebliche Kosten verursachen. Natürlich gibt es Maßnahmen, um so etwas zu vermeiden, aber die Möglichkeit zum Stoppen der Produktion zeigt eindeutig, wie wichtig für das Ziel der Qualität ist.
1998 hatte GM es trotz des Joint Ventures nur in Ausnahmefällen geschafft, die Ideen des Toyota-Produktionssystems in einem anderen Werk umzusetzen. 2009 beendete GM dann das Joint Venture, und 2010 schloss Toyota schließlich die Fabrik.
Das hört sich zwar wie ein Ende an, aber kurz darauf eröffnete Tesla dort sein Werk und bis heute ist das Werk in der Hand von Tesla. Und so geht von diesem Werk heute die Elektro-Mobilitätsrevolution aus.
Aus dieser Geschichte lassen sich mehrere Lehren für die Softwareentwicklung ableiten:
Die NUMMI-Fabrik ist kein zufällig gewähltes Beispiel. Agile Softwareentwicklung orientiert sich an Lean Production und dem Toyota-Produktionssystem. Die wesentlichen Konzepte hat die Agilität aus diesem Bereich übernommen, sodass sich ein Blick auf Beispiele aus der Produktion lohnen.
Die NUMMI-Fabrik zeigt, dass Kultur entscheidend für den Erfolg eines Unternehmens sein kann, aber diese auch schwer zu ändern ist. Das dort praktizierte Toyota-Produktionssystem ist genauso wie agile Softwareentwicklung im Wesentlichen eine Änderung der Kultur.
URL dieses Artikels:http://www.heise.de/-4374683
Links in diesem Artikel:[1] https://en.wikipedia.org/wiki/NUMMI[2] https://en.wikipedia.org/wiki/Fremont_Assembly[3] https://de.wikipedia.org/wiki/Toyota-Produktionssystem[4] https://de.wikipedia.org/wiki/Jid%C5%8Dka
Copyright © 2019 Heise Medien
COPY_SYSLOG_TO_STDERR #2260cli/user-info.php for accounts using a version of the database older than 1.12.0 #2291

"Sekiro: Shadows Die Twice" entsendet Spieler*innen ins feudale Japan zu Schwertkämpfen, Mystik und Meucheleien. Der knackige Schwierigkeitsgrad treibt auch und besonders Veteranen der Vorgänger in den Wahnsinn – und wir wollen mit! Um 21 Uhr gehts auf unserem Twitch-Channel live ins Getümmel.
Der spirituelle Nachfolger der Dark-Souls- und Bloodborne-Spiele "Sekiro: Shadows Die Twice" ist frisch am 22. März erschienen. Mit Schwert, Heimlichkeit, Wurfsternen, Akrobatik und allerlei Shinobi-Spielereien tritt man gegen Samurai, Kami, Oger, Riesenschlangen und diverse weitere Feinde an – alles vor der fast immer idyllischen Kulisse einer fiktiven japanischen Provinz während der Sengoku-Ära im späten 16. Jahrhundert.
Live-Video von ctzockt auf www.twitch.tv ansehen [1]
Unser c't-zockt-Kollege Julius Beineke nimmt euch live mit in die ersten Stunden des Action-Epos – heute Abend ab 21 Uhr auf unserem offiziellen c't-zockt-Twitch-Channel [2]. Wir wünschen viel Spaß beim Zusehen und Mitfiebern – und hoffen auf eure Unterstützung live im Twitch-Chat.
Die Verbindung aus rasanter Action, Schleicheinlagen, Plattforming und ein paar Rollenspielelementen zusammen mit der mystischen, tragischen Story und dem verträumten Setting funktioniert wunderbar, macht Spaß und fordert – und das mit nur ein paar wenigen Mankos. Mehr darüber ist im Sekiro-Review [5] bei Heise Online nachzulesen.
()
URL dieses Artikels:http://www.heise.de/-4347829
Links in diesem Artikel:[1] https://www.twitch.tv/ctzockt?tt_content=text_link&tt_medium=live_embed[2] https://www.twitch.tv/ctzockt[3] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4347150.html?back=4347829[4] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4347150.html?back=4347829[5] https://www.heise.de/meldung/Sekiro-Shadows-Die-Twice-angespielt-Meisterhaftes-Schwertspektakel-4347147.html[6] mailto:jube@heise.de
Copyright © 2019 Heise Medien
Eigentlich gibt es keine "Silver Bullets". Aber Continuous Delivery verspricht so viele Vorteile, dass es ein solches Silver Bullet sein könnte. Was stimmt also: Gibt es sie doch oder ist Continuous Delivery überbewertet?
Der Ausdruck "Silver Bullet" kommt von einem Paper [1] aus dem Jahr 1986 von Frederick Brooks. Dieser ist Autor des Buchs "The Mythical Man-Month", das über die Entwicklung von IBMs OS/360-Betriebssystem berichtet. Er hat dieses Projekt geleitet. Es hatte ein Budget von 5 Milliarden US-Dollar und wurde in den Sechzigern nur durch die Mondlandung in den Schatten gestellt. Das Buch enthält Erkenntnisse, die auch heute noch wichtig sind – beispielsweise dass ein Projekt zunächst langsamer wird, wenn man mehr Personen mit dem Projekt betraut, weil die Personen sich erst mal einarbeiten müssen.
Silberkugeln dienen eigentlich zur Jagd auf Werwölfe. Brooks argumentiert, dass viele IT-Projekte irgendwann zu einem Monster mutieren und wir daher Silberkugeln brauchen. Die gibt es aber nicht: Seiner Meinung nach verspricht keine einzelne Entwicklung in einem Jahrzehnt eine Größenordnung bessere Produktivität, Zuverlässigkeit oder Einfachheit. Eine Größenordnung ist ein Faktor von 10.
Brooks argumentiert, dass die technischen Komplexitätstreiber bereits eliminiert sind. Wenn aber die meiste Komplexität mittlerweile durch die Anforderungen, Designs und Tests entstehen, kann man die Komplexität nicht einfach durch einen einfachen Trick lösen. Vielversprechend findet er das Kaufen, statt irgendwas selbst zu bauen, besserer Umgang mit Anforderungen, das "Züchten" von Software durch inkrementelle Entwicklung und schließlich gute Designer.
Continuous Delivery bezeichnet das kontinuierlich Ausliefern von Software. Es ist klar, dass durch eine höhere Deployment-Frequenz die Zeit abnimmt, bis eine Änderung in Produktion ist. Mittlerweile gibt es eine Studie [2] ("2018 State of DevOps Report"), die weitere Effekte aufzeigt. Sie unterscheidet "Elite Performer", die nach Bedarf mehrmals pro Tag deployen, und "Low Performer", die zwischen einmal pro Woche und einmal pro Monat deployen. Teams mit Quartalsreleases sind also noch nicht einmal "Low Performer.
Elite-Performer erreichen logischerweise höhere Geschwindigkeit, mit denen Änderungen in Produktion gelangen:
Aber es gibt auch andere positive Effekte:
Also steigen Produktivität und Zuverlässigkeit. Continuous Delivery könnte demnach eine "Silberkugel" sein, obgleich es sie nach Brooks ja nicht geben dürfte. Wie kann dieser Widerspruch geklärt werden?
Eine Erklärung könnte sein, dass Brooks nicht recht hat. Zu beweisen, dass etwas nicht existiert, ist prinzipiell schwierig. Sein Paper nennt keine Belege, sondern gibt im Wesentlichen die Meinung des Autors wieder. Es ist mittlerweile 30 Jahre alt, sodass sich vielleicht mittlerweile etwas geändert hat.
Auf der anderen Seite ist Brooks sehr erfahren und eine der wichtigsten Personen in der Softwareentwicklungsszene. Also kann man das Paper nicht so ohne weiteres ignorieren.
Die genannte Studie könnte auch fehlerhaft sein. Hinter der Studie steht Gene Kim, der unter anderem das DevOps-Handbuch und das Buch über das Phoenix-Projekt geschrieben hat. Beides Bücher, die Continuous Delivery positiv sehen. Ein weiterer Protagonist der Studie ist Jez Humble, einer der Autoren des ersten Continuous-Delivery-Buchs. Es wäre erstaunlich, wenn diese Personen eine Studie schreiben, die zeigt, dass Continuous Delivery doch keine erheblichen Vorteile bringt.
Aber die dritte Autorin im Bunde ist die Wissenschaftlerin Dr. Nicole Forsgren. So kann man sicher sein, dass die Studie einer wissenschaftlichen Überprüfung standhält und entsprechend wissenschaftlicher Standards ausgewertet worden ist. Und schließlich kann die Studie eine große Datenbasis vorweisen: Insgesamt haben 30.000 Personen an ihr teilgenommen. Eine große Datenbasis und eine professionelle Auswertung der Daten führt eigentlich zu aussagekräftigen Ergebnissen.
Ich glaube, dass es gar keinen Widerspruch gibt. Die Studie und Brooks haben beide recht.
Dafür gibt es mehrere Gründe:
Continuous Delivery hat tatsächlich viele deutliche Vorteile. Die Studie zeigt diese klar und sehr gut belegt auf. Das hilft dabei, die Vorteile von Continuous Delivery eindeutig darzustellen. Dennoch ist auch Continuous Delivery wohl nicht das Silver Bullet. Dennoch gehen die Vorteile von Continuous Delivery weit über das schnelle Ausliefern von Software und neuen Features hinaus. Es lohnt sich also, in diesen Bereich zu investieren, selbst wenn nicht schneller Features in Produktion gebracht werden müssen, weil auch Produktivität und Zuverlässigkeit signifikant besser werden.
Silver Bullets sollen Softwarentwicklung um mindestens eine Größenordnung verbessern, aber es gibt leider keine. Continuous Delivery hat dennoch nachweisbare erhebliche Vorteile auch für Zuverlässigkeit und Produktivität.
URL dieses Artikels:http://www.heise.de/-4341288
Links in diesem Artikel:[1] http://www.cs.nott.ac.uk/~pszcah/G51ISS/Documents/NoSilverBullet.html[2] https://puppet.com/resources/whitepaper/state-of-devops-report
Copyright © 2019 Heise Medien
Die Hibernate-Tipps-Serie bietet schnelle und einfache Lösungen zu verbreiteten Hibernate-Fragen. Dieses Mal geht es um die Abbildung des Rückgabewerts einer SQL-Funktion auf das Attribut einer Entität.
Der Wert eines meiner Entity-Attribute wird durch eine SQL-Funktion berechnet. Wie kann ich das mit Hibernate abbilden?
Hibernates @Formula-Annotation ermöglicht es, ein SQL-Schnipsel bereitzustellen, den Hibernate ausführt, wenn es die Entität aus der Datenbank liest. Der Rückgabewert des SQL-Schnipsel wird dann auf ein schreibgeschütztes Entity-Attribut abgebildet. Dies kann vorteilhaft sein, wenn die Datenbank bereits eine komplexe Funktion bereitstellt, die auf einer großen Datenmenge arbeitet.
Das folgende, vereinfachte Beispiel verwendet die @Formula-Annotation, um das Alter eines Autors zu berechnen. Alternativ könnte dies in diesem Beispiel natürlich auch durch eine Java-Methode erfolgen:
@Entity
public class Author {@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;@Column
private LocalDate dateOfBirth;@Formula(value = “date_part(‘year’, age(dateOfBirth))”)
private int age;…
public int getAge() {
return age;
}
}
Wenn Hibernate eine Author-Entität aus der Datenbank holt, fügt es das durch die @Formular-Annotation definierte SQL-Schnipsel zur SQL-Anweisung hinzu:
05:35:15,762 DEBUG [org.hibernate.SQL] – select author0_.id as id1_0_, author0_.dateOfBirth as dateOfBi2_0_, author0_.firstName as firstNam3_0_, author0_.lastName as lastName4_0_, author0_.version as version5_0_, date_part(‘year’, age(author0_.dateOfBirth)) as formula0_ from Author author0_ where author0_.id=1
Die @Formula-Annotation bietet eine einfache Möglichkeit, das Ergebnis eines SQL-Schnipsel auf ein Entity-Attribut abzubilden. Aber es hat auch einige Nachteile, die man beachten sollten:
Mehr als 70 solcher Rezepte zu Themen wie einfache und komplexe Mappingdefinitionen, Logging, Unterstützung von Java 8, Caching sowie die statische und dynamische Erzeugung von Abfragen gibt es in meinem Buch "Hibernate Tips: More than 70 solutions to common Hibernate problems". Es ist als Taschenbuch und E-Book auf Amazon und als PDF auf hibernate-tips.com [1] erhältlich.
URL dieses Artikels:http://www.heise.de/-4329792
Links in diesem Artikel:[1] http://hibernate-tips.com
Copyright © 2019 Heise Medien
Gute Kenntnisse über die Java Persistence API (JPA) und ihre Implementierungen sind nach wie vor eine der gefragtesten Fähigkeiten unter Java-Entwicklern. Es ist daher nicht verwunderlich, dass es viele Blogartikel, Bücher und Kurse [1] gibt, die zeigen, wie eine Persistenzschicht mit der JPA-Spezifikation implementiert werden kann.
Aber Neulinge fragen sich wahrscheinlich trotz aller Beliebtheit, warum JPA so oft verwendet wird und was man darüber wissen muss. Daher werfe ich einen Blick auf die fünf wichtigsten Dinge, die man als Entwickler über JPA wissen sollte.
Beginnen wir mit dem Offensichtlichsten: Die JPA-Spezifikation definiert eine objektrelationale Abbildung zwischen Tabellen in einer relationalen Datenbank und Java-Klassen. Das Tolle daran ist, dass JPA diese Zuordnung sehr einfach macht. Sehr oft muss eine Klasse lediglich mit einer @Entity-Annotation versehen werden. Alle ihre Attribute werden dann automatisch auf gleichnamige Datenbankspalten abgebildet.
Hier ist ein Beispiel für ein solches Basis-Mapping:
@Entity
public class Professor {@Id
private Long id;private String firstName;
private String lastName;
public String getFirstName() {
return firstName;
}public void setFirstName(String firstName) {
this.firstName = firstName;
}public String getLastName() {
return lastName;
}public void setLastName(String lastName) {
this.lastName = lastName;
}public void setId(Long id) {
this.id = id;
}public Long getId() {
return id;
}
}
Die Professor-Klasse wird durch JPA auf eine Datenbanktabelle mit dem Namen professor und den Spalten id, firstname und lastname abgebildet. Ich erläutere die Abbildung dieser Klasse im Detail in der auf YouTube verfügbaren Beispiellektion meines Kurses "JPA for Beginners [2]":
Und man kann nicht nur einfache Attribute auf Datenbankspalten abbilden, sondern auch Assoziationen zwischen den Entitäten modellieren. Auf diese Weise können die Fremdschlüsselspalten und Beziehungstabellen des Tabellenmodells als Entitätsattribute mit Getter- und Setter-Methoden dargestellt werden. Diese Attribute können dann wie jedes andere Entitätsattribut verwendet werden. Die verwendete JPA-Implementierung stellt dabei sicher, dass die erforderlichen Datensätze entweder während der Initialisierung der Entität oder bei der erstmaligen Verwendung geladen werden.
Das folgende Beispiel zeigt die Abbildung einer typischen Viele-zu-Eins-Beziehung zwischen der professor- und der course-Tabelle. Das Attribut der Professor-Klasse modelliert die Beziehung, und die JPA-Implementierung sorgt dafür, dass die erforderlichen Lese- und Schreiboperationen durchgeführt werden:
@Entity
public class Course {@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "course_generator")
@SequenceGenerator(name = "course_generator", sequenceName = "course_seq")
private Long id;private String name;
private LocalDate startDate;
private LocalDate endDate;
@ManyToOne
private Professor professor;...
}
JPA ist nur eine Spezifikation, die eine Reihe von Schnittstellen und deren Funktionen definiert. Das bedeutet, dass man die Spezifikation zur Implementierung Ihrer Anwendung verwenden kann, aber das zum Ausführen eine Implementierung hinzugefügt werden muss. Zwei bekannte JPA-Implementierungen sind EclipseLink, die Referenzimplementierung der Spezifikation, und Hibernate, die wahrscheinlich beliebteste JPA-Implementierung.
Ich habe zu Beginn dieses Artikels erklärt, dass JPA Java-Klassen auf Datenbanktabellen abbildet und dies sogar Beziehungen zwischen diesen Klassen beinhaltet. Diese Abbildung führt offensichtlich zu einer Abstraktion. Der Abstraktionsgrad zwischen einem einfachen Attribut und einer Datenbankspalte mag eher gering sein, ist aber bei Beziehungen deutlich höher. Die JPA-Implementierung muss dann nicht nur die Typkonvertierung zwischen dem JDBC-Typ der Datenbankspalte und dem Java-Typ des Entitätsattributs durchführen, sondern auch zusätzliche Abfragen verwalten, um die zugehörigen Datensätze abzurufen.
Aus diesem Grund ist es äußerst wichtig, dass jeder Entwickler das Mapping und seine Auswirkungen genau versteht. Andernfalls wird die JPA-Implementierung diese Beziehungen ineffizient behandeln, und die Anwendung wird unter schwerwiegenden Performanzproblemen leiden. Deshalb beschäftige ich mich in vier Lektionen meines "JPA for Beginners Online Training" [3] mit den Abbildungen verschiedener Beziehungstypen [4] und deren, als Fetching bezeichneten Ladeverhalten.
Neben der Abstraktion durch die Attributszuordnungen löst JPA auch die erforderlichen Einfüge-, Aktualisierungs- und Entfernungsoperationen auf Basis eines komplexen Lebenszyklusmodells aus. Das Gute daran ist, dass für diese Operationen keine SQL-Anweisungen geschrieben werden müssen. Aber gleichzeitig verliert man dadurch die Kontrolle über die SQL-Anweisung und den Zeitpunkt ihrer Ausführung.
Die automatische Erstellung und Ausführung von SQL-Anweisungen macht es sehr einfach, die Geschäftslogik zu implementieren, und verbessert die Entwicklerproduktivität. Es macht es aber auch schwierig vorherzusagen, wann welche SQL-Anweisungen ausgeführt wird. Daher ist ein fundiertes Verständnis des Lebenszyklusmodells und dessen Auswirkungen auf die Ausführung von SQL-Anweisungen erforderlich.
JPA abstrahiert den Datenbankzugriff und verbirgt ihn hinter einer Reihe von Annotationen und Schnittstellen. Das bedeutet aber nicht, dass man die Datenbank ignorieren könnte. Auch wenn man nicht direkt mit auf einem Tabellenmodell arbeitet, müssen dennoch die Möglichkeiten und Grenzen von relationalen Tabellenmodellen berücksichtigt werden. Tut man dies nicht, führt dies früher oder später zu Performanzproblemen [5].
Des Weiteren sollte man darauf achten, dass die Entitäten so ähnlich wie möglich zu den abgebildeten Datenbanktabellen sind. Dadurch wird sichergestellt, dass die JPA-Implementierung ein schnelles und effizientes objektrelationales Mapping zur Verfügung stellen kann.
Es muss außerdem berücksichtigt werden, dass die Datenbank weiterhin SQL-Anweisungen ausführt. Durch die Verwendung von JPA müssen viele dieser Anweisungen nicht mehr selbst geschrieben werden, aber man sollte trotzdem in der Lage sein, dies zu lesen und zu verstehen. Dies ist notwendig, um die Interaktion der JPA-Implementierung mit der Datenbank zu verstehen und eine effiziente Datenbankanbindung zu realisieren.
Um die ausgeführten SQL-Anweisungen überprüfen zu können, müssen diese von der JPA-Implementierung zuerst protokolliert werden. Die erforderliche Konfiguration ist abhängig von der jeweiligen JPA-Implementierung. Im folgenden Beispiel zeige ich eine Konfiguration für Hibernate [6]:
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{HH:mm:ss,SSS} %-5p [%c] - %m%nlog4j.rootLogger=info, stdout
# basic log level for all messages
log4j.logger.org.hibernate=info# SQL statements and parameters
log4j.logger.org.hibernate.SQL=debug
log4j.logger.org.hibernate.type.descriptor.sql=trace
Mit dieser Konfiguration schreibt Hibernate alle ausgeführten SQL INSERT-, UPDATE- und DELETE-Anweisungen in die Logdatei. So kann man genau sehen, wann und welche Anweisungen Hibernate ausgeführt hat.
19:13:35,772 DEBUG [org.hibernate.SQL] -
select
professor0_.id as id1_1_0_,
professor0_.firstName as firstNam2_1_0_,
professor0_.lastName as lastName3_1_0_
from
Professor professor0_
where
professor0_.id=?
19:13:35,773 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [1] as [BIGINT] -[1]
19:13:35,774 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([firstNam2_1_0_] : [VARCHAR]) - [Jane]
19:13:35,774 TRACE [org.hibernate.type.descriptor.sql.BasicExtractor] - extracted value ([lastName3_1_0_] : [VARCHAR]) - [Doe]
19:13:35,775 DEBUG [org.hibernate.SQL] -
update
Course
set
endDate=?,
name=?,
professor_id=?,
startDate=?
where
id=?
19:13:35,776 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [1] as [DATE] - [2019-05-31]
19:13:35,776 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [2] as [VARCHAR] - [Software Development 1]
19:13:35,776 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [3] as [BIGINT] - [1]
19:13:35,776 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [4] as [DATE] - [2018-08-15]
19:13:35,777 TRACE [org.hibernate.type.descriptor.sql.BasicBinder] - binding parameter [5] as [BIGINT] - [1]
Auf den ersten Blick erscheint es oft so, als würde man mit JPA nur ein paar wenige Annotationen benötigen um eine vollständige Persistenzschicht zu implementieren. Während der praktischen Umsetzung stellt sich dann aber schnell heraus, dass die Verwendung der Spezifikation deutlich komplexer ist als erwartet und ein gutes Verständnis der grundlegenden Konzept erfordert.
Mit meinem Onlinekurs "JPA for Beginners [7]" biete ich eine einfache und schnelle Möglichkeit diese Kenntnisse zu erlernen. Mit kurzen Videolektionen und dazu passenden Aufgaben erlernen die Teilnehmer innerhalb kurzer Zeit, eine Persistenzschicht auf Basis der JPA-Spezifikation zu erstellen und dabei häufig auftretende Fehler zu vermeiden.
Zur Einführung der zweiten,. überarbeiteten Version des Kurses gibt es diesen noch bis zum 15 März zum reduzierten Preis auf https://thoughts-on-java.org/jpa-for-beginners/ [8].
URL dieses Artikels:http://www.heise.de/-4329959
Links in diesem Artikel:[1] https://thoughts-on-java.org/jpa-for-beginners/[2] https://thoughts-on-java.org/jpa-for-beginners/[3] https://thoughts-on-java.org/jpa-for-beginners/[4] https://www.thoughts-on-java.org/ultimate-guide-association-mappings-jpa-hibernate/[5] http://www.thoughts-on-java.org/tips-to-boost-your-hibernate-performance/[6] http://www.thoughts-on-java.org/hibernate-logging-guide[7] https://thoughts-on-java.org/jpa-for-beginners/[8] https://thoughts-on-java.org/jpa-for-beginners/
Copyright © 2019 Heise Medien

Mit Apex Legend versucht auch EA, an den Erfolg von Fortnite und Co. anzuknüpfen. Ab 17 Uhr trifft sich das c’t-zockt-Team im Livestream zum Überlebenskampf.
Spätestens seit dem Start von Playerunknown’s Battlegrounds (PUBG) [1] und Fortnite vor zwei knapp Jahren ist Battle Royale in aller (Spieler-)Munde. Das Prinzip ist schnell erklärt: Dutzende Spieler messen sich in einem großen, sich aber stetig verkleinernden Kampfgebiet und ringen – je nach Spiel – allein oder im Team um den Sieg. EA ergänzt das mit eigenen Ansätzen, um sich von der Konkurrenz abzusetzen. Und das nicht ohne Erfolg: Bereits nach einer Woche konnte man 25 Millionen Spieler melden [2].
Der erste große Unterschied zwischen Apex Legends, PUBG und Fortnite ist die Begrenzung auf Dreierteams sowie die Wahl eines Charakters. Letzteres rückt das Spiel in die Nähe von Blizzards Overwatch; auch dort spielt die Charakterwahl innerhalb eines Teams eine große Rolle. Mit der traditionellen Unterteilung in Charakterklassen nimmt Apex Legends es nicht ganz so genau. Schließlich kann auch die Heilerin ordentlich Schaden austeilen. Aber auch beim Gameplay versucht EA es mit eigenen Akzenten. Wildes durch die Gegend hüpfen wie in Fortnite bringt hier ebenso wenig Erfolg wie minutenlanges Verharren wie in PUBG.
Umstellen müssen sich PUBG- und Fortnite-Spieler, wenn es um die Ausrüstung geht. Denn anders als in den beiden bekannten Battle-Royale-Titeln geht Apex Legends vergleichsweise sparsam mit Waffen und sonstigen Gegenständen um. Welchen Stellenwert Teamplay einnimmt, sieht man an der Möglichkeit, gefallene Team-Mitglieder wiederzubeleben.
Entwickelt wurde Apex Legends von den Titanfall-Machern Respawn Entertainment. Das weckte bei Fans der Shooter-Reihe zunächst die Hoffnung, dass Mechs und Walljumps essentieller Gameplay-Bestandteil sein werden. Beides fehlt, dennoch ist Bewegung ein wichtiger Faktor im Gefecht. Gleiches gilt für die Spezialfähigkeiten der Charaktere. So kann die Sanitäterin Lifeline eine Heildrohne starten, ein Carepaket anfordern und Teammitglieder schneller wiederbeleben. Bloodhound hingegen übernimmt die Rolle des Aufklärers, der Gegnerspuren erkennt, per Radar den Standort von Gegnern bestimmen und zeitweise schneller laufen kann.
Voraussetzung für das Spielen von Apex Legends ist ein EA-Konto. Auf Windows-PCs wird zusätzlich der Origin-Launcher benötigt, Xbox-One- und Playstation-4-Spieler benötigen das jeweilige Online-Abo. Genauso wie Fortnite ist der Titel selbst kostenlos, für die Finanzierung wird auf Mikrotransaktionen und Loot-Boxen zurückgegriffen. Angeboten werden allerdings kosmetische Items, die keine spielerischen Auswirkungen haben. Die meisten davon lassen sich aber auch durch erspielbare In-Game-Währung erwerben. Wie sich das c’t-zockt-Team in Apex Legends schlägt, zeigt sich heute ab 17 Uhr im Livestream auf YouTube [5] und Twitch [6]. ()
URL dieses Artikels:http://www.heise.de/-4313309
Links in diesem Artikel:[1] https://www.heise.de/ct/artikel/c-t-zockt-Spiele-Review-Playerunknown-s-Battlegrounds-3796401.html[2] https://www.heise.de/meldung/25-Millionen-Spieler-probieren-Apex-Legends-aus-4305454.html[3] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4309239.html?back=4313309[4] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4309239.html?back=4313309[5] https://www.youtube.com/watch?v=n9hr4mdWlRM[6] https://www.twitch.tv/ctzockt[7] mailto:pbe@heise.de
Copyright © 2019 Heise Medien

Im skurrilen 2D-Indie-Adventure "39 Days To Mars" starten Sie mit zwei verschrobenen Forschern des 19. Jahrhunderts und einem dampfbetriebenen Luftschiff auf eine Forschungsreise zum Mars.
Wie auf Pergament gezeichnet wirkt dieses hübsche 2D-Indie-Adventure mit Steampunk-Flair. Tee und Scones sind in "39 Days To Mars" von genauso großer Bedeutung wie die Lösung vieler Rätsel.
Sir Albert Wickes und der ehrenwerte Mr. Clarence Baxter beschließen im Jahr 1876, mit der klapprigen HMS Fearful zum Mars aufzubrechen. Die Forscher sind jedoch alles andere als trainierte Astronauten, daher muss man die beiden schrulligen Engländer mit perfekt zubereitetem Tee und passend belegten Scones bei Laune halten. Das dampfbetriebene Fluggefährt droht derweil ständig auseinanderzufallen.
Am besten spielt sich das skurrile 2D-Koop-Adventure zu zweit, zum Beispiel mit Controller an einem großen Bildschirm. Aber auch mit Tastatur und Maus lässt es sich bedienen. Ist mal kein Spielpartner zur Hand, kann eine vom Spiel per KI gesteuerte Katze einspringen. Weil zum Lösen der meisten Rätsel ein zweites Paar Hände gebraucht wird, muss man dann allerdings beide gleichzeitig steuern – einmal mit der Tastatur und einmal mit der Maus. Das kann ganz schön mühsam sein.
"39 Days To Mars" ist im Jahr 2014 erfolgreich mit einer Kickstarter-Kampagne [3] finanziert worden. Mittlerweile wurde das Spiel von Philip Buchanan in verschiedene Sprachen übersetzt, darunter auch Deutsch. Allerdings gilt das nur für die Sprechblasen, die Stimmen bleiben auf Englisch. Das ist auch gut so, denn ohne den britischen Akzent würde dem Spiel einiges verloren gehen.
39 Days To Mars ist kein hektisches Spiel. Es ist mit beruhigender Klaviermusik unterlegt, die beiden Charaktere sind witzig und die Rätsel abwechslungsreich. Allerdings ist die Bedienung ein wenig umständlich und die Zubereitung von Scones und Tee nach Geschmack von Albert und Clarence erfordert viel Geduld.
"39 Days To Mars" ist für Linux, macOS und Windows erhältlich auf Steam [4] (12,50 Euro) und Itch.io [5] (15 US-Dollar, ca. 13,20 Euro, Steam-Key und Download). Für unser Review haben wir die Linux-Version angespielt. Versionen für Xbox One und Nintendo Switch sind in Arbeit. ()
URL dieses Artikels:http://www.heise.de/-4286929
Links in diesem Artikel:[1] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4287096.html?back=4286929[2] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4287096.html?back=4286929[3] https://www.kickstarter.com/projects/philipbuchanan/39-days-to-mars[4] https://store.steampowered.com/app/504920/[5] https://its-anecdotal.itch.io/39-days-to-mars[6] mailto:lmd@heise.de
Copyright © 2019 Heise Medien
Anfang 2018 stieß der Vorgänger dieses Beitrags [1] auf reges Interesse. Es scheint, dass ich nicht der Einzige bin, der sich gerne gute Vorträge über Java auf YouTube anschaut. Es ist eine der einfachsten und komfortabelsten Möglichkeiten, von einigen der besten unserer Branche zu lernen.
Aus diesem Grund habe ich mich entschieden, eine aktualisierte Version dieses Artikels mit meinen empfohlenen YouTube-Kanälen für 2019 zu veröffentlichen. Hier ist eine unsortierte Liste meiner Lieblingskanäle.
Der Java-Kanal von Oracle war eine meiner letztjährigen Empfehlungen, und er ist immer noch ein großartiger Kanal für alle, die sich für das Java-Ökosystem interessieren. Hier findest Du Vorträge von der CodeOne sowie vom JVM Language Summit und Interviews mit bekannten Größen aus der Java-Community.
Da Du bereits meine empfohlene Liste von YouTube-Kanälen liest, kann ich mir natürlich nicht die Chance entgehen lassen meinen eigenen Kanal zu bewerben. Jede Woche veröffentliche ich zwei neue Videos über JPA, Hibernate und verwandte Persistenztechnologien. Wenn Du Deine Daten in einer relationalen Datenbank speicherst, solltest Du diese Videos nicht verpassen.
Wenn Du Deine Anwendungen in einer zeitgemäßen Umgebung bereitstellst, sind Container inzwischen nicht mehr weg zu denken. Du solltest also mindestens einem Kanal folgen, der sich auf diese Kerntechnologie konzentriert. Für mich ist das der Docker-Kanal mit aufgezeichneten Webinaren und Vorträgen von der DockerCon.
Der Devoxx-Kanal ist ideal für alle Konferenzliebhaber. Hier gibt es regelmäßig neue Vorträge von den Devoxx- und Voxxed Days-Konferenzen. Seien wir ehrlich, das Ansehen von aufgezeichneten Konferenzvorträgen von zu Hause oder Deinem Büro ist nicht so gut wie die Teilnahme an der Konferenz. Aber es ist viel bequemer und gibt Dir freien Zugang zu einigen der interessantesten Vorträge.
Java User Groups bieten eine ideale Möglichkeit, um sich mit gleichgesinnten Entwicklern zu treffen und mehr über die Sprache, populäre Frameworks und Softwareentwicklung im Allgemeinen zu erfahren. Die virtuelle Java User Group (vJUG) ist wahrscheinlich der komfortabelste Weg, um regelmäßig an User Group Meetings teilzunehmen. Das Team überträgt Webinare mit einigen der besten Java-Experten.
Wenn Du Dich für das Java Module System oder die neuesten Features der Java-Sprache interessierst, kennst Du wahrscheinlich Nicolai und seinen Blog codefx.org [8]. Seit neustem hat er auch einen YouTube-Kanal. In seinen Videos gelingt es ihm komplexe Themen verständlich und unterhaltsam zu erklären.
Die brasilianische Organisation SouJava bietet auf ihrem Kanal eine Mischung aus Interviews und Webinaren über Java und Jakarta EE.
Du hast vielleicht nicht immer die Zeit, Dir ein einstündiges Webinar oder einen Konferenzvortrag anzusehen. In diesen Fällen könnte ein kurzes Interview oder Panel besser passen. Diese findest du auf dem NightHacking-Kanal.
Wenn Du mit Spring arbeitest, kennst Du wahrscheinlich bereits den Spring-Developer-Kanal. Das Team von Pivotal veröffentlicht dort viele aufgezeichnete Konferenzvorträge, Webinare und Tutorials über Spring.
Du kennst wahrscheinlich JetBrains, das Unternehmen, das für die IntelliJ IDE und die Programmiersprache Kotlin verantwortlich ist. Sie haben auch einen YouTube-Kanal, auf dem sie Vorträge von der KotlinConf, Webinare zu verschiedenen Themen der Softwareentwicklung und Tutorials zu ihren Tools anbieten.
Wenn Du Amazon Web Services nutzt oder Dich nur für Cloud-Technologien im Allgemeinen interessierst, solltest Du einen Blick auf den Amazon-Web-Services-Kanal werfen. Ich ignoriere die meisten ihrer Werbe- und Support-Videos, aber ich habe mir bereits einige interessante Vorträge der AWS:reinvent und des AWS Summit gesehen.
Der InfoQ-Kanal bietet viele interessante Vorträge der QCon-Konferenzen zu verschiedenen Themen der Architektur und Softwareentwicklung.
Sebastian hat in 2018 nur wenige Videos veröffentlicht und ich habe mich gefragt, ob ich seinen Kanal noch in diese Liste aufnehmen sollte. Aber am Ende überzeugten mich die Qualität seiner Inhalte und sein Fokus auf die moderne MicroProfile- und Jakarta EE-Entwicklung. Wenn Du Jakarta EE oder Eclipse MicroProfile verwendest, solltest Du seine Videos nicht verpassen.
GOTO Conferences ist eine weitere beliebte Konferenzreihe, die ihre Vorträge aufzeichnet und auf YouTube bereitstellt.
Das waren meine Empfehlungen für 2019. Welche Kanäle hast Du in den letzten Monaten gesehen? Welche kannst Du empfehlen?
URL dieses Artikels:http://www.heise.de/-4288840
Links in diesem Artikel:[1] https://www.heise.de/developer/artikel/12-YouTube-Kanaele-die-du-2018-nicht-verpassen-solltest-3937979.html[2] https://www.youtube.com/user/java[3] https://www.youtube.com/c/thoughtsonjava[4] https://www.youtube.com/user/dockerrun[5] https://www.youtube.com/channel/UCCBVCTuk6uJrN3iFV_3vurg[6] https://www.youtube.com/user/virtualJUG[7] https://www.youtube.com/channel/UCngKKOnBxYtLAV8pgUBNDng[8] http://blog.codefx.org/[9] https://www.youtube.com/channel/UCH0qj1HFZ9jy0w87YfMSA7w[10] https://www.youtube.com/channel/UCT0bL2CQIk1eANeXk57mxaA[11] https://www.youtube.com/user/SpringSourceDev[12] https://www.youtube.com/user/JetBrainsTV[13] https://www.youtube.com/user/AmazonWebServices[14] https://www.youtube.com/user/MarakanaTechTV[15] https://www.youtube.com/channel/UCG21GE2Go3vkj7mrs675ysA[16] https://www.youtube.com/user/GotoConferences
Copyright © 2019 Heise Medien
X-Forwarded-Prefix in cookie path behind a reverse-proxy #2201.htaccess for HTTP authenticationCOPY_SYSLOG_TO_STDERR or in constants.local.php to copy PHP syslog messages to STDERR #2213TZ timezone environment variable #2153X-WebAuth-User for delegated HTTP Authentication #2204freshrss:openArticle JavaScript event #2222

Beim Brettspiel kNOW! von Ravensburger geht's um aktuelles Wissen. Der Google Assistant macht mit und stellt Fragen und Aufgaben zu Allgemeinwissen und Kreativität – und checkt, ob Antworten hier und jetzt korrekt sind.
Ein Mix aus Trivial Pursuit, Tabu & Co., immer auf aktuellem Stand. Das verspricht das Wissensspiel kNOW! von Ravensburger. Das Brettspiel für drei bis sechs Spielende bringt in den vier Kategorien Wissen, Intuition, Kreativität und Fun insgesamt zwölf verschiedene Quizformen und Minispiele mit.
Im Vergleich zu anderen Quizklassikern sind die rund 1500 Fragen nicht viel. Der Clou: Der Google Assistant ist als Spielhelfer und Quizmaster im Smartphone oder Lautsprecher stets mit dabei. Viele Aufgaben sind so konzipiert, dass die richtige Lösung von Spielzeit und Ort abhängt und sich so mit der Zeit verändern kann. Google löst die Rätsel dann auf.
Viele der Quizaufgaben lassen sich nur mit aktivem Google Assistant spielen, andere auch offline, wenn man möchte. Ein On-/Offline-Symbol markiert die Spielkarten entsprechend. Offline-Fragen sind üblicherweise zeitlos im Vergleich zu den kontextabhängigen. Die korrekten Antworten stehen in diesem Fall direkt mit auf der Karte.
Nacheinander übernehmen Spielende die Quizmaster-Rolle. Er oder sie zieht eine Karte passend zum Feld, auf dem die eigene Spielfigur steht, stellt die Frage oder Aufgabe und interagiert mit dem Google Assistant. Alle anderen versuchen, die Frage am schnellsten oder kreativsten zu beantworten oder bei Minispielen zu punkten und so die eigene Figur mehrere Felder vorwärts zu bewegen – wer das Spielbrett zuerst umrundet hat, gewinnt.

Das einzige Spiel der Kategorie Wissen ist "Schnellerwisser" – das klassische Quiz: Wer die Antwort weiß, haut schnell auf den beiliegenden Buzzer und antwortet hoffentlich richtig. Hier sind die Fragen oft abhängig von Zeit und Kontext – etwa "In wie vielen Filmen hat Jennifer Lawrence mitgespielt?".
Auf Intuition-Karten sind "Let's Schätz" und "Toptreffer" verortet. Schätzen muss man beispielsweise, wie lange man mit dem Auto vom Spielort nach Ravensburg braucht. Bei "Toptreffer" gibt der Google Assistant ein Wort vor, das die Spielenden mit einem anderen zu einem Begriff ergänzen und im Geheimen notieren müssen. Aus "Baum" wird also etwa "Baumhaus" oder "Baumarkt". Reihum fragt man Google dann nach den Suchmaschinentreffern für den Begriff – wer die meisten Ergebnisse hat, punktet.
Bei "Gute Frage" und "Dreierlei" der Kategorie Kreativität muss man wiederum den Google Assistant dazu bringen, bestimmte Worte auszuspucken. "Gute Frage" ähnelt Tabu – man muss Google eine Frage stellen, die den auf der Karte gesuchten Begriff als Antwort hat, darf diesen selbst jedoch nicht nennen. Bei Dreierlei sind beispielsweise bekannte Songs der Beatles gesucht. Hat man möglichst viele notiert, fragt man Google nach den drei Toptreffern und rückt pro richtiger Antwort ein Feld vor.
Auf Fun-Karten finden sich kurzweilige Minispiele. Bei "Summsalabim" gilt es, gesummte Lieder zu erkennen. Bei "Stolperfalle" muss man dem Assistant Zungenbrecher fehlerfrei nachsprechen, bei "Phrasendrescher" Redewendungen vervollständigen. Bei "Quiz Ungewiss" tippt man auf eine Frage Antwort A, B oder C, bei "Ton für Ton" spielt der Google Assistant zwei Geräusche vor, aus denen man einen gesuchten Begriff erraten muss. Quaken und Streichinstrumente ergeben beispielsweise "Froschkonzert". "Sekunde noch" erfordert Timing und Schnelligkeit, "Nice Dice" eher Würfelglück.
Bei beispielsweise "Quiz Ungewiss" oder "Ton für Ton" spricht man Google als "Professor Know" an – Anweisungen dazu stehen auf den jeweiligen Karten. Besonders bei "Toptreffer" fällt auf, dass der Fundus an Begriffen und Aufgaben, den der Professor zur Verfügung hat, noch recht beschränkt ist.
Ansonsten wird schnell deutlich, dass man besonders bei "Gute Frage" und "Schnellerwisser" etwas Finesse im Umgang mit Sprachassistenten braucht, um dem Google Assistant die gesuchten Begriffe und Antworten aus der Nase zu kitzeln. Unbefriedigend, wenn Google manchmal nur unkommentiert Wikipedia-Seiten ausspuckt.

Der Google Assistant ist so fehlbar wie Google selbst. So beharrte er im Test darauf, dass der originale "Krieg der Sterne"-Film im Februar 1978 erschienen sei. Dass dies das Release-Datum für Deutschland, nicht die Ersterscheinung für das Ursprungsland USA war, wollte er auch bei gezielteren Fragen – nämlich nach dem Release in den USA – nicht einsehen. Grund dafür dürfte der Standort des verknüpften Gerätes und Google-Kontos sein.
Der Google Home Mini liegt der limitierten Edition von kNOW! bei und ist in diesem Bundle ziemlich preiswert. Es geht allerdings auch einfach mit einem Google-Assistant-fähigen Smartphone. Eine zusätzliche App braucht es dazu nicht – "Professor Know" weiß Bescheid und erklärt auch die Regeln der einzelnen Spiele.
kNOW! zeigt sich als ein kurzweiliges Vergnügen für Familien- oder Partyabende, am besten in größerer Runde. Der Mix aus spaßigen Minispielen und oft knackig schweren Fragen, die sich nur durch tagesaktuelles Allgemeinwissen beantworten lassen, sorgt für Spielspaß.
Wenn Google sich immer mal wieder verschluckt, hemmt das, wenn auch nicht zu schlimm den Spielfluss. Wie gut kNOW! zukünftig noch wird und ob es dem Immer-Aktuell-Anspruch gerecht wird, hängt maßgeblich von den Fähigkeiten des Google Assistant ab.
()
URL dieses Artikels:http://www.heise.de/-4282413
Links in diesem Artikel:[1] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4278396.html?back=4282413[2] https://www.heise.de/ct/bilderstrecke/bilderstrecke_4278396.html?back=4282413[3] mailto:jube@heise.de
Copyright © 2019 Heise Medien